veRL fully async training 全异步方案
VeRL仓的贡献者:https://github.com/meituan-search(美团)作为前作,one step off主要在更新权重的Step之间,直接做了一步的错位,这样的实现最简单,通过一步错位来实现异步训练,能够把训练时间掩盖掉,推理持续进行。缺点包括训练空泡较大,并且一步的推理时长取决长尾句子,空泡更显著。
作者:昇腾实战派
知识地图链接:强化学习知识地图
简介:veRL实现了 fully async training,在现有的one step off(https://github.com/volcengine/verl/pull/2231)策略代码的基础上,将训练流程进一步拆分为Trainer和Rollouter,样本通过messageQueue进行传输。 在该系统下,128卡训练qwen2.5-7B模型取得了2.35x-2.67x的性能提升,同时效果没有显著受到影响。
代码仓:https://github.com/volcengine/verl/pull/2981
贡献者:https://github.com/meituan-search(美团)<br data-vt-id="alyetj6s"/>
README.md:https://github.com/volcengine/verl/blob/main/recipe/fully_async_policy/README_zh.md,或许直接看这个就行了,写得挺好
1. 前言
1.1 one step off:
VeRL仓的贡献者:https://github.com/meituan-search(美团)
作为前作,one step off主要在更新权重的Step之间,直接做了一步的错位,这样的实现最简单,通过一步错位来实现异步训练,能够把训练时间掩盖掉,推理持续进行。
缺点包括训练空泡较大,并且一步的推理时长取决长尾句子,空泡更显著。

1.2 StreamRL:
https://arxiv.org/pdf/2504.15930
流式系统,训练过程中通过可以mini-batch拆分并且做dynamic-batch把训推流式异步起来,拆碎batch来削减空泡,这里还对one step async做了改造做成了流式的。
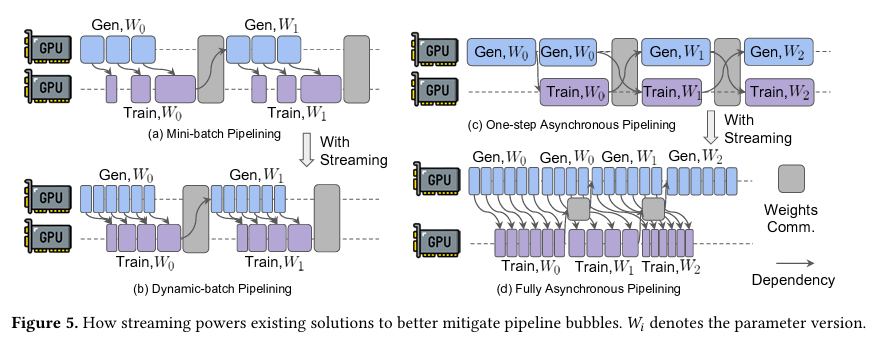
1.3 Partial Rollout:
https://arxiv.org/pdf/2505.24298
在Areal 方案中除了参考以上方面,更加激进得使用了Partial rolloot方案,通过截断最后的序列,放到下一步权重更新后重新计算推理,来进一步掩盖长尾空泡。
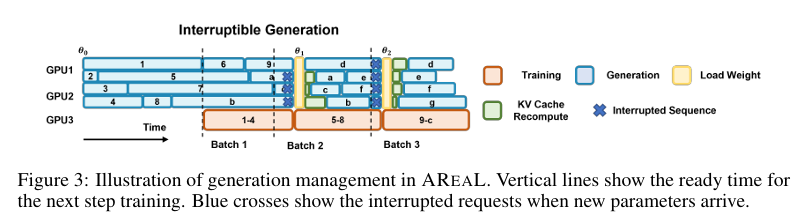
2. 背景
rollout和train分离架构相较于colocate的架构能够更加灵活地分配资源,设计更加灵活的训练逻辑,从而处理长尾等问题带来的GPU利用率低,训练效率低的问题。 one_step_off_policy通过分离架构的设计并进行rollout和train一轮异步的训练方法,缓解了rollout时间过长的问题,并在训练效率上取得了一些收益, 但其强制使用一轮异步的数据,存在不够灵活等问题,而且并不能完全去除长尾对训练效率带来的的影响;在其他框架如areal、Magistral、streamrl、asyncflow上, 已经基于分离架构实现了异步训练、流式训练,并取得了收益;我们借鉴其方法,在VeRL上进行了实现。fully_async_policy支持异步、流式、partial rollout的训练, 通过合理设置资源分配情况、参数同步频率等参数,fully_async_policy能够显著提高训练效率。
特点:在one step off上改进,借鉴了areal、streamrl、asyncflow等方案,在实现fully_async_policy异步方案同时,支持流式、partial rollout的训练,从而实现不同程度的异步方案,最极端的情况下可以实现系统的全异步,最极端情况下其实和Areal的方案是一致的。
3. 核心贡献
- 资源隔离:与使用hybrid_engine不同,Rollouter和Trainer使用分离的计算资源,需要分别指定所占用的资源。
- 生成与训练并行:Trainer在训练的同时,Rollouter在生成新的样本。
- 多步异步: 相比 one step off policy 支持0.x步到多步的异步设定,异步方案更加灵活。
- nccl参数同步:使用nccl通信原语进行Rollouter与Trainer参数的通信。
- Stream推理与训练:Rollouter逐样本生成数据,同时数据传输以单个sample为最小传输单位。
- 异步训练与新鲜度控制:通过设置参数async_training.staleness_threshold,支持使用旧参数生成的样本进行训练。
- PartialRollout: Rollouter推理过程支持partial rollout逻辑,通过参数同步时,添加
sleep()和resume()逻辑,保存进行中的rollout的样本,并在下一次rollout中继续使用,减少参数同步等待进行中的任务结束时间。
目前支持使用模式为 fsdp+vllm。vllm必须使用基于AgentLoop的server模式。
**解读:**从上面这些贡献描述中,有工作量和排坑的点主要是nccl参数同步和agentloop的server推理
1. 参数同步:涉及到的ray collective 不支持问题(ray.util.collective import collective),可以参考此前对one step off的适配,其中有对collective规避的方案。
NPU对one step off的适配:https://github.com/volcengine/verl/pull/2924/files
**2. vllm server模式:**和之前的spmd模式不一样,采用AsyncLLM,此前retool是可以通的。
4. 设计
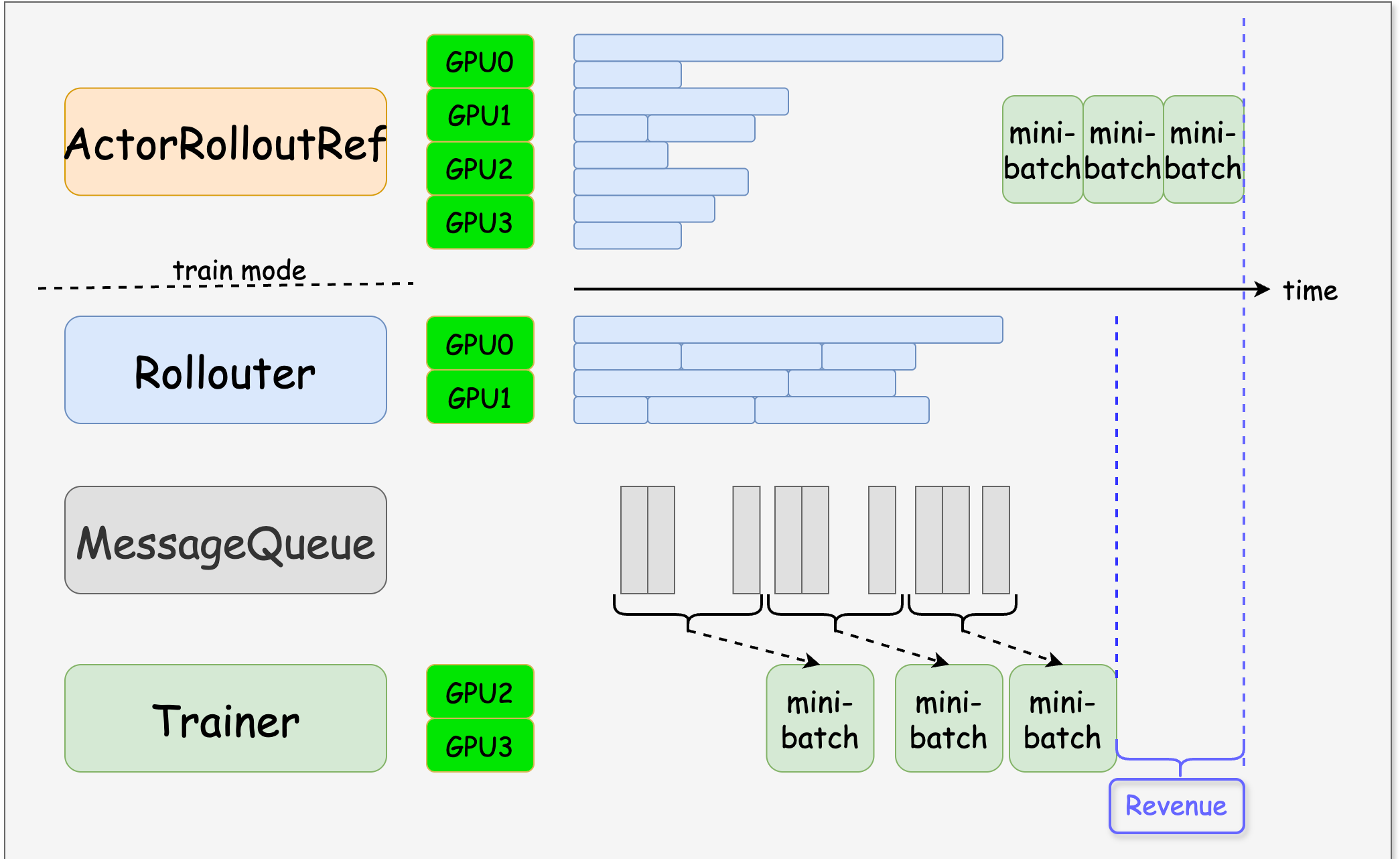
fully_async_policy的整体架构如下图所示,fully_async_policy主要由Rollouter、MessageQueue、Trainer、ParameterSynchronizer四部分组成。
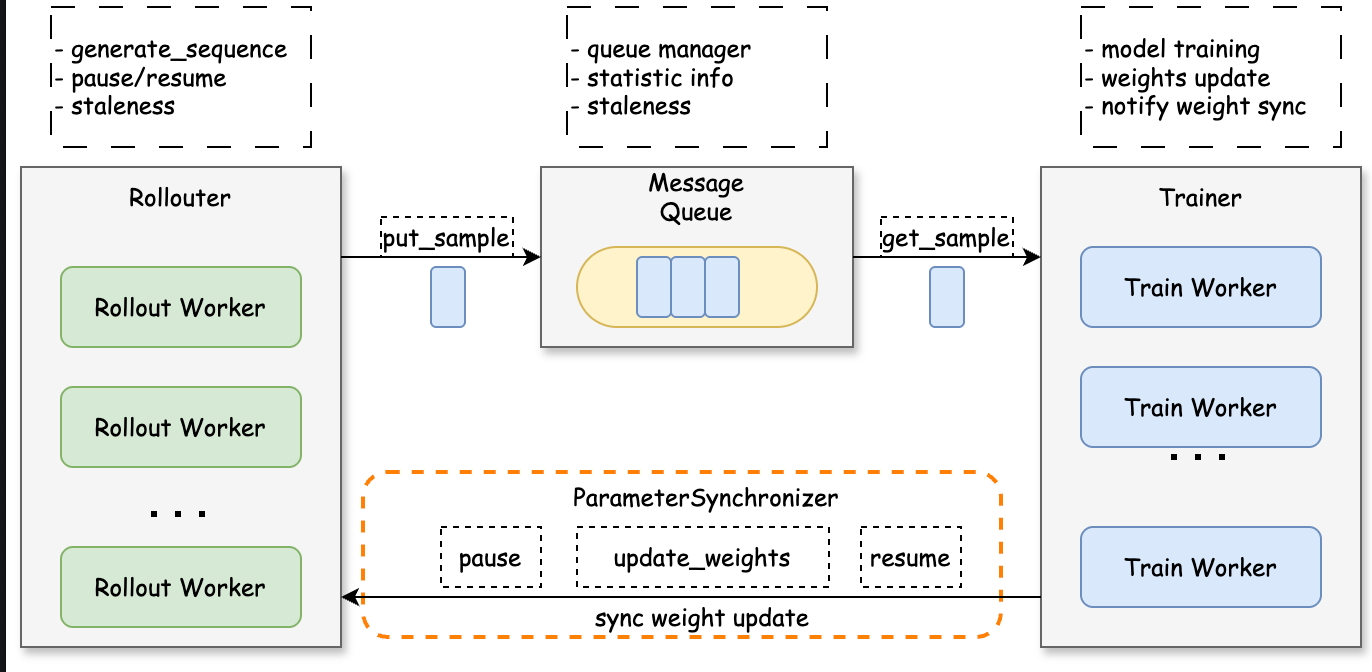
- Rollouter逐样本生成序列,并将生成的sample放入MessageQueue中,生产的速度受新鲜度控制。
- MessageQueue用于暂存Rollouter生成的sample。
- Trainer逐样本从MessageQueue中获取,获取到
require_batches*ppo_mini_batch_size数量的样本后,就会进行训练,训练async_training.trigger_parameter_sync_step轮后,触发与Rollouter的一次参数同步。 - ParameterSynchronizer 实现了Nccl的同步参数同步能力。
解读:
这个方案将rollout推理单独分离,其他如reward、compute_log_prob、update等都纳入训练阶段,如下代码在训练阶段,没有对reward、log_prob的计算进行分拆,获取到rollout数据都,都传递给_process_batch_common计算。相对来说,reward这些阶段的计算耗时更低,这点与asyncFlow有差异,这套方案只定义了训和推两个阶段,形成了一个环状的流程,也简化了整体流程。
当前方案对比base的收益来源,在于colocate情况下,rollout使用更多的资源无法解决长尾样本带来的空闲, 当我们进行资源隔离后,rollout的时间和train的时间都可能相较于之前更长(因为使用的资源变少了), 但是相互之间的耗时overlap,端到端的耗时反而有所缩减。和我们常规理解的异卡方案是一致的,训推单模块时间变长,总时间变短
5. 模式支持
四种不同程度的异步和overlap:
trigger_parameter_sync_step:控制是否开启异步训练
**+**staleness_threshold:****新鲜度,控制Rollouter两次参数更新之间是否将会生成固定数量的样本,实现数据样本异步。第一步剩余的一点旧样本推完可以加入下一步参数更新,而不在本次更新,节省掉第一步最后一次更新时rollout的空闲,以及第二步启动第一次等待rollout数据的时间,但是新引入了剩余的一点旧样本rollout的空闲时间
****+**partial_rollout:******partial_rollout只会在staleness_threshold>0时才起作用,在长序列情况下,剩余的一点旧样本rollout的空闲时间会非常大,更加激进的措施是,开启partial_rollout直接把长序列阶段,用第二次的权重继续推,将空闲都做掩盖。
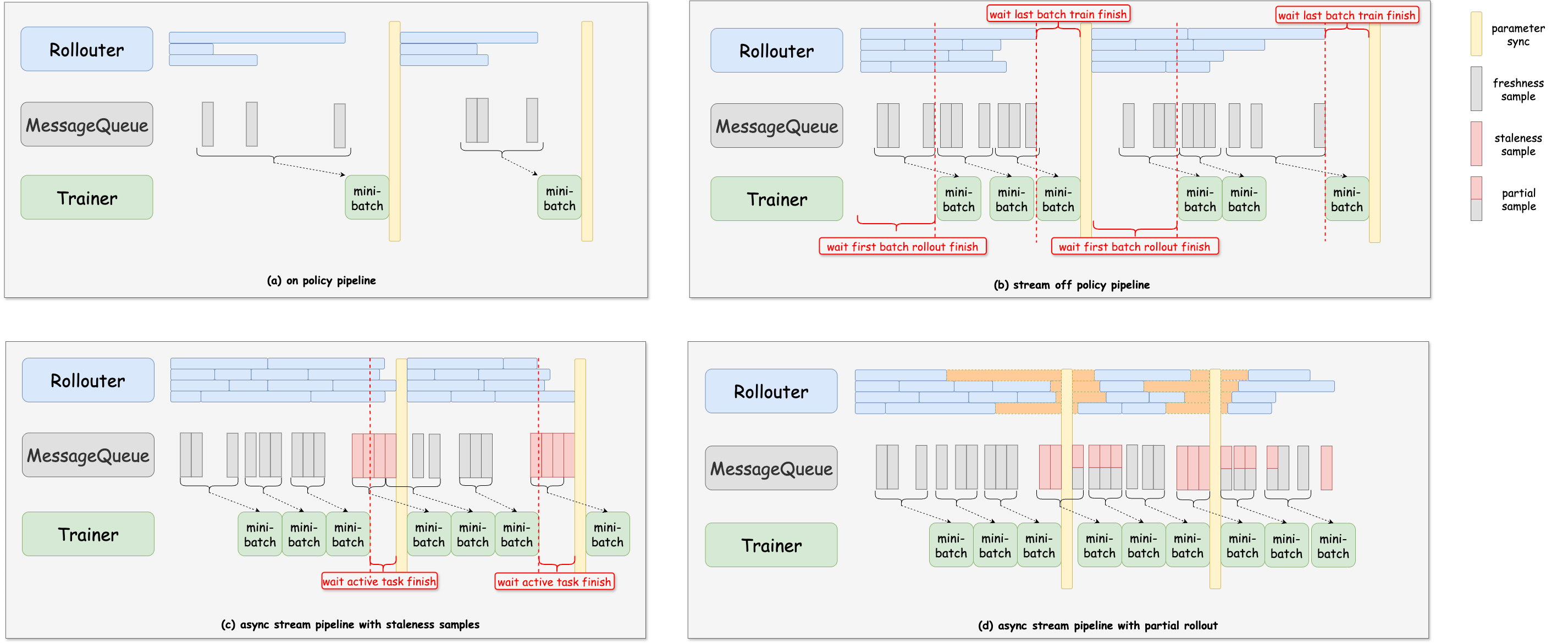
详细:
on policy pipeline:
- trigger_parameter_sync_step=1,staleness_threshold=0
- Rollouter一次生产
require_batches*ppo_mini_batch_size的samples,Trainer获取这些samples后进行训练,训练完后Trainer和Rollouter之间进行一次参数同步; - 在rollout阶段,如果存在长尾的样本,但是rollout样本数较少时,较短的样本无法填充到空闲的资源中,会造成一定的资源浪费。
- 如图a所示;
stream off policy pipeline:
- trigger_parameter_sync_step>1,staleness_threshold=0
- 将会进行同步的流式训练,Rollouter一次生产
require_batches*ppo_mini_batch_size*trigger_parameter_sync_step的samples,Trainer每获取require_batches*ppo_mini_batch_size就进行一次本地训练,训练trigger_parameter_sync_step次后,Trainer和Rollouter之间进行一次参数同步; - 相较于a,由于一次生成的样本更多,资源的空闲会更低。
- 在一次step训练中,会存在两次资源闲置的时间,分别是在第一次获取样本时,train等待
require_batches*ppo_mini_batch_size个样本生产,以及最后一次参数更新时,rollout等待训练完成。 - 如图b所示;
async stream pipeline with staleness samples:
- trigger_parameter_sync_step>=1,staleness_threshold>0,partial_rollout=Flase
- Rollouter在每次参数更新后将计划最多生产rollout_num个样本(实际根据rollout速度,生成的样本可能会少与这个值)。
- 如果rollout过程比较快,Rollouter将会在参数同步前额外生成一部分样本num_stale_samples,用于参数同步后立即给Trainer使用。 触发参数同步时,如果Rollouter有正在生产的任务,将会等待任务完成,同时不会添加新的任务;
- 相较于b,除第一次step训练外,后续的训练都不会有wait first batch rollout finish的时间,但是会有wait active task finish的时间。
- 如图c所示;
async stream pipeline with partial rollout:
- trigger_parameter_sync_step>=1,staleness_threshold>0,partial_rollout=True
- 相较于c,触发参数同步时,Rollouter如果有正在生产的sample,会打断rollout过程并进行参数同步,被中断的sample会在参数同步后继续生成。减少了wait active task finish的时间。
- 如图d所示;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)