Agentic AI探索:构建智能科研助手
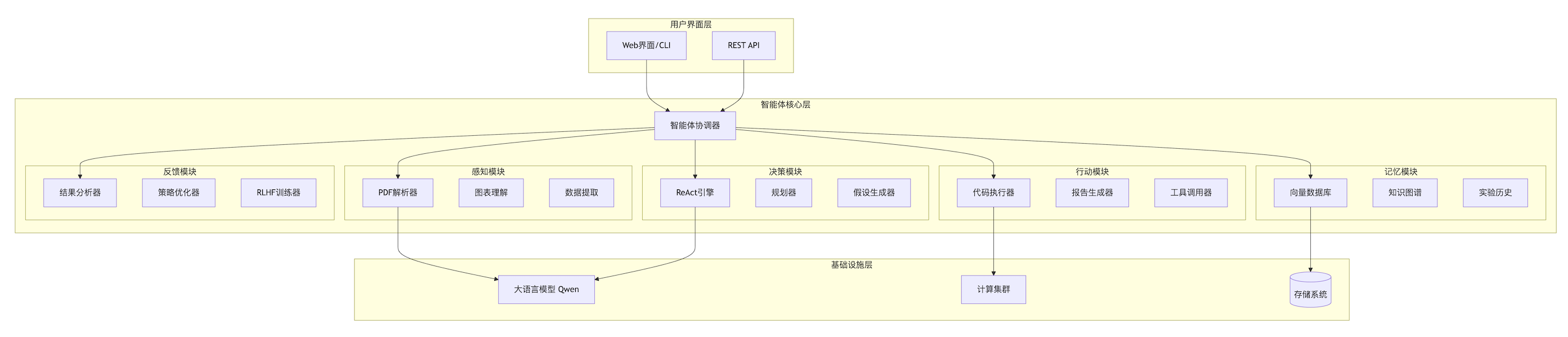
智能科研助手系统架构与功能摘要 系统架构 五大核心模块:感知、记忆、决策、行动、反馈 感知模块:支持PDF解析、图表理解、数据解析等多模态处理 记忆模块:集成向量数据库(Pinecone)和知识图谱(Neo4j) 决策模块:采用ReAct框架进行实验规划和假设生成 行动模块:包含代码执行、实验操作和报告生成功能 反馈模块:通过RLHF实现持续优化 关键技术 多模态理解:BLIP-2模型处理图表,P
项目概述与架构设计
1.1 智能科研助手核心能力
class ResearchAssistantCapabilities:
"""
智能科研助手五大核心能力
"""
PERCEPTION = {
"论文解析": "PDF文本提取 + 图表内容理解",
"数据理解": "实验数据表格、图表、代码解析",
"多模态融合": "文本、图像、代码的统一理解"
}
MEMORY = {
"文献记忆": "向量化存储 + 语义检索",
"实验历史": "知识图谱存储实验流程和结果",
"领域知识": "构建研究领域知识网络"
}
DECISION = {
"实验规划": "基于研究目标的步骤分解",
"假设生成": "基于现有知识的创新假设",
"资源分配": "计算资源和时间优化分配"
}
ACTION = {
"代码执行": "调用计算资源运行实验",
"报告生成": "自动生成实验报告和论文草稿",
"工具调用": "集成科研工具链"
}
FEEDBACK = {
"结果分析": "实验结果与假设的对比",
"策略优化": "基于反馈调整研究策略",
"主动学习": "从失败中学习并改进"
}1.2 系统整体架构
模块一:感知模块实现
2.1 PDF与图表解析系统
# perception/pdf_processor.py
import PyPDF2
import pdf2image
import torch
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import numpy as np
from typing import List, Dict, Any
import pandas as pd
import cv2
import json
class ResearchPaperPerception:
"""多模态论文感知系统"""
def __init__(self):
# 初始化BLIP-2模型用于图表理解
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.blip_processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
self.blip_model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b"
).to(self.device)
# OCR引擎(可选)
try:
import easyocr
self.reader = easyocr.Reader(['en', 'ch_sim'])
except:
self.reader = None
def extract_pdf_content(self, pdf_path: str) -> Dict[str, Any]:
"""
提取PDF论文的完整内容
"""
content = {
"metadata": {},
"text_content": [],
"figures": [],
"tables": [],
"equations": [],
"references": []
}
# 1. 提取文本内容
with open(pdf_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# 提取元数据
info = pdf_reader.metadata
content["metadata"] = {
"title": info.get('/Title', ''),
"author": info.get('/Author', ''),
"subject": info.get('/Subject', ''),
"pages": len(pdf_reader.pages)
}
# 逐页提取文本
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
# 分段处理
paragraphs = self._split_into_paragraphs(page_text)
content["text_content"].append({
"page": page_num + 1,
"paragraphs": paragraphs,
"raw_text": page_text
})
# 2. 提取图表
content["figures"] = self._extract_figures(pdf_path)
# 3. 提取表格(使用Camelot或Tabula)
content["tables"] = self._extract_tables(pdf_path)
return content
def _extract_figures(self, pdf_path: str) -> List[Dict]:
"""提取并理解图表"""
figures = []
# 将PDF转换为图片
images = pdf2image.convert_from_path(pdf_path)
for page_num, image in enumerate(images):
# 使用OpenCV检测图表区域
open_cv_image = np.array(image)
gray = cv2.cvtColor(open_cv_image, cv2.COLOR_RGB2GRAY)
# 边缘检测
edges = cv2.Canny(gray, 50, 150)
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
# 过滤小区域
area = cv2.contourArea(contour)
if area < 10000: # 面积阈值
continue
x, y, w, h = cv2.boundingRect(contour)
# 裁剪图表区域
figure_img = image.crop((x, y, x + w, y + h))
# 使用BLIP-2理解图表内容
figure_description = self._understand_figure(figure_img)
# 提取图表标题和说明文字(OCR)
caption = self._extract_caption(open_cv_image, x, y, w, h)
figures.append({
"page": page_num + 1,
"bbox": [x, y, w, h],
"description": figure_description,
"caption": caption,
"image": figure_img
})
return figures
def _understand_figure(self, image: Image.Image) -> str:
"""使用BLIP-2理解图表内容"""
# 准备输入
inputs = self.blip_processor(
images=image,
return_tensors="pt"
).to(self.device)
# 生成描述
with torch.no_grad():
generated_ids = self.blip_model.generate(
**inputs,
max_length=200,
num_beams=5,
temperature=0.8
)
description = self.blip_processor.decode(
generated_ids[0],
skip_special_tokens=True
)
# 增强描述:询问具体问题
enhanced_description = self._enhance_figure_description(image, description)
return enhanced_description
def _enhance_figure_description(self, image: Image.Image, base_desc: str) -> str:
"""增强图表描述,获取更多细节"""
questions = [
"What type of chart or graph is this?",
"What are the X and Y axes showing?",
"What are the key trends or patterns?",
"What do the different colors represent?",
"What is the main conclusion from this figure?"
]
detailed_descriptions = []
for question in questions:
prompt = f"Based on this scientific figure: {base_desc}. {question}"
inputs = self.blip_processor(
images=image,
text=prompt,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
generated_ids = self.blip_model.generate(
**inputs,
max_length=100,
num_beams=3
)
answer = self.blip_processor.decode(
generated_ids[0],
skip_special_tokens=True
)
detailed_descriptions.append(f"Q: {question}\nA: {answer}")
return base_desc + "\n\nDetailed Analysis:\n" + "\n".join(detailed_descriptions)
def _extract_tables(self, pdf_path: str) -> List[Dict]:
"""提取表格数据"""
tables = []
try:
import camelot
# 使用Camelot提取表格
camelot_tables = camelot.read_pdf(pdf_path, pages='all')
for table in camelot_tables:
# 转换为DataFrame
df = table.df
# 分析表格结构
table_analysis = {
"page": table.page,
"accuracy": table.accuracy,
"whitespace": table.whitespace,
"order": table.order,
"data": df.to_dict(),
"shape": df.shape,
"description": self._describe_table(df)
}
tables.append(table_analysis)
except:
# 备用方案:使用Tabula
pass
return tables
def _describe_table(self, df: pd.DataFrame) -> str:
"""自动描述表格内容"""
description = []
description.append(f"Table with {df.shape[0]} rows and {df.shape[1]} columns.")
# 分析列类型
for col in df.columns:
col_data = df[col].dropna()
if len(col_data) > 0:
if pd.api.types.is_numeric_dtype(df[col]):
description.append(f"Column '{col}' contains numeric data: "
f"range [{col_data.min():.2f}, {col_data.max():.2f}], "
f"mean {col_data.mean():.2f}")
else:
description.append(f"Column '{col}' contains categorical/text data")
return "\n".join(description)
# 使用示例
if __name__ == "__main__":
processor = ResearchPaperPerception()
# 处理一篇论文
paper_content = processor.extract_pdf_content("research_paper.pdf")
# 保存结构化数据
with open("paper_analysis.json", "w") as f:
json.dump(paper_content, f, indent=2, default=str)
print(f"提取了 {len(paper_content['text_content'])} 页文本内容")
print(f"发现了 {len(paper_content['figures'])} 个图表")
print(f"提取了 {len(paper_content['tables'])} 个表格")2.2 实验数据解析器
# perception/data_analyzer.py
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import json
from typing import Dict, List, Any, Tuple
class ExperimentalDataAnalyzer:
"""实验数据分析模块"""
def __init__(self):
self.analyses_cache = {}
def analyze_experiment_data(self, data_path: str, data_type: str = "csv") -> Dict:
"""
分析实验数据文件
"""
# 加载数据
if data_type == "csv":
df = pd.read_csv(data_path)
elif data_type == "excel":
df = pd.read_excel(data_path)
elif data_type == "json":
with open(data_path, 'r') as f:
data = json.load(f)
df = pd.DataFrame(data)
else:
raise ValueError(f"Unsupported data type: {data_type}")
analysis = {
"metadata": {
"file_path": data_path,
"data_type": data_type,
"shape": df.shape,
"columns": list(df.columns),
"missing_values": df.isnull().sum().to_dict()
},
"descriptive_stats": self._descriptive_statistics(df),
"correlation_analysis": self._correlation_analysis(df),
"distribution_analysis": self._distribution_analysis(df),
"outlier_detection": self._detect_outliers(df),
"time_series_analysis": self._time_series_analysis(df) if self._is_time_series(df) else None,
"visualizations": self._generate_visualizations(df, data_path)
}
# 生成自然语言总结
analysis["nl_summary"] = self._generate_nl_summary(analysis)
return analysis
def _descriptive_statistics(self, df: pd.DataFrame) -> Dict:
"""描述性统计"""
stats_dict = {}
for column in df.select_dtypes(include=[np.number]).columns:
col_data = df[column].dropna()
if len(col_data) > 0:
stats_dict[column] = {
"mean": float(col_data.mean()),
"median": float(col_data.median()),
"std": float(col_data.std()),
"min": float(col_data.min()),
"max": float(col_data.max()),
"q1": float(col_data.quantile(0.25)),
"q3": float(col_data.quantile(0.75)),
"skewness": float(stats.skew(col_data)),
"kurtosis": float(stats.kurtosis(col_data))
}
return stats_dict
def _correlation_analysis(self, df: pd.DataFrame) -> Dict:
"""相关性分析"""
numeric_df = df.select_dtypes(include=[np.number])
if len(numeric_df.columns) < 2:
return {}
# 计算相关系数
correlation_matrix = numeric_df.corr()
# 找到强相关关系
strong_correlations = []
for i in range(len(correlation_matrix.columns)):
for j in range(i+1, len(correlation_matrix.columns)):
corr = correlation_matrix.iloc[i, j]
if abs(corr) > 0.7: # 强相关阈值
strong_correlations.append({
"var1": correlation_matrix.columns[i],
"var2": correlation_matrix.columns[j],
"correlation": float(corr)
})
return {
"correlation_matrix": correlation_matrix.to_dict(),
"strong_correlations": strong_correlations,
"top_correlations": sorted(strong_correlations,
key=lambda x: abs(x["correlation"]),
reverse=True)[:10]
}
def _distribution_analysis(self, df: pd.DataFrame) -> Dict:
"""分布分析"""
distributions = {}
for column in df.select_dtypes(include=[np.number]).columns:
col_data = df[column].dropna()
if len(col_data) > 10: # 需要有足够的数据点
# 正态性检验
_, normality_p = stats.normaltest(col_data)
# 拟合最佳分布
best_fit = self._fit_best_distribution(col_data)
distributions[column] = {
"normality_test": {
"p_value": float(normality_p),
"is_normal": normality_p > 0.05
},
"best_fit_distribution": best_fit,
"histogram_data": {
"values": col_data.tolist(),
"bins": 30
}
}
return distributions
def _detect_outliers(self, df: pd.DataFrame) -> Dict:
"""异常值检测"""
outliers = {}
for column in df.select_dtypes(include=[np.number]).columns:
col_data = df[column].dropna()
if len(col_data) > 10:
# IQR方法
Q1 = col_data.quantile(0.25)
Q3 = col_data.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outlier_indices = col_data[(col_data < lower_bound) | (col_data > upper_bound)].index.tolist()
if outlier_indices:
outliers[column] = {
"method": "IQR",
"lower_bound": float(lower_bound),
"upper_bound": float(upper_bound),
"outlier_indices": outlier_indices,
"outlier_values": col_data.loc[outlier_indices].tolist(),
"outlier_count": len(outlier_indices),
"percentage": len(outlier_indices) / len(col_data) * 100
}
return outliers
def _generate_visualizations(self, df: pd.DataFrame, data_path: str) -> List[Dict]:
"""生成可视化图表"""
visualizations = []
base_name = data_path.split('/')[-1].split('.')[0]
# 1. 相关热力图
numeric_df = df.select_dtypes(include=[np.number])
if len(numeric_df.columns) > 1:
plt.figure(figsize=(10, 8))
corr_matrix = numeric_df.corr()
plt.imshow(corr_matrix, cmap='coolwarm', aspect='auto')
plt.colorbar()
plt.xticks(range(len(corr_matrix.columns)), corr_matrix.columns, rotation=45)
plt.yticks(range(len(corr_matrix.columns)), corr_matrix.columns)
plt.title('Correlation Heatmap')
heatmap_path = f"visualizations/{base_name}_heatmap.png"
plt.savefig(heatmap_path, dpi=300, bbox_inches='tight')
plt.close()
visualizations.append({
"type": "correlation_heatmap",
"path": heatmap_path,
"description": "Heatmap showing correlations between numeric variables"
})
# 2. 分布直方图
for column in numeric_df.columns:
plt.figure(figsize=(8, 6))
plt.hist(numeric_df[column].dropna(), bins=30, edgecolor='black', alpha=0.7)
plt.xlabel(column)
plt.ylabel('Frequency')
plt.title(f'Distribution of {column}')
hist_path = f"visualizations/{base_name}_{column}_histogram.png"
plt.savefig(hist_path, dpi=300, bbox_inches='tight')
plt.close()
visualizations.append({
"type": "histogram",
"variable": column,
"path": hist_path,
"description": f"Histogram showing distribution of {column}"
})
return visualizations
def _generate_nl_summary(self, analysis: Dict) -> str:
"""生成自然语言总结"""
summary_parts = []
# 基本信息
metadata = analysis["metadata"]
summary_parts.append(
f"The dataset contains {metadata['shape'][0]} rows and {metadata['shape'][1]} columns. "
f"Columns include: {', '.join(metadata['columns'][:5])}"
)
# 关键统计信息
stats = analysis["descriptive_stats"]
if stats:
key_metrics = []
for col, col_stats in list(stats.items())[:3]: # 只看前三列
key_metrics.append(
f"{col} (mean={col_stats['mean']:.2f}, std={col_stats['std']:.2f})"
)
summary_parts.append(f"Key metrics: {'; '.join(key_metrics)}")
# 相关性发现
corr = analysis["correlation_analysis"]
if corr.get("top_correlations"):
strongest = corr["top_correlations"][0]
summary_parts.append(
f"Strongest correlation: {strongest['var1']} and {strongest['var2']} "
f"(r={strongest['correlation']:.2f})"
)
# 异常值信息
outliers = analysis["outlier_detection"]
if outliers:
outlier_cols = list(outliers.keys())[:3]
summary_parts.append(
f"Outliers detected in columns: {', '.join(outlier_cols)}"
)
return " ".join(summary_parts)模块二:记忆模块实现
3.1 向量数据库与知识图谱集成
# memory/knowledge_store.py
import pinecone
from neo4j import GraphDatabase
from sentence_transformers import SentenceTransformer
import numpy as np
from typing import List, Dict, Any, Optional
import json
from datetime import datetime
class ResearchKnowledgeMemory:
"""研究知识记忆系统"""
def __init__(self,
pinecone_api_key: str,
pinecone_env: str,
neo4j_uri: str,
neo4j_user: str,
neo4j_password: str):
# 初始化向量数据库
pinecone.init(api_key=pinecone_api_key, environment=pinecone_env)
# 创建或连接索引
self.index_name = "research-knowledge"
if self.index_name not in pinecone.list_indexes():
pinecone.create_index(
name=self.index_name,
dimension=768, # 与embedding模型匹配
metric="cosine"
)
self.vector_index = pinecone.Index(self.index_name)
# 初始化知识图谱
self.neo4j_driver = GraphDatabase.driver(
neo4j_uri,
auth=(neo4j_user, neo4j_password)
)
# 初始化embedding模型
self.embedder = SentenceTransformer('all-MiniLM-L6-v2')
# 创建知识图谱schema
self._init_neo4j_schema()
def _init_neo4j_schema(self):
"""初始化Neo4j数据库schema"""
with self.neo4j_driver.session() as session:
# 创建约束确保唯一性
session.run("""
CREATE CONSTRAINT IF NOT EXISTS FOR (p:Paper) REQUIRE p.doi IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (a:Author) REQUIRE a.name IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (c:Concept) REQUIRE c.name IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (e:Experiment) REQUIRE e.id IS UNIQUE;
""")
def store_paper(self, paper_data: Dict) -> str:
"""
存储论文到记忆系统
返回:论文ID
"""
paper_id = f"paper_{paper_data.get('doi', hash(json.dumps(paper_data)))}"
# 1. 向量化存储
self._store_in_vector_db(paper_data, paper_id)
# 2. 知识图谱存储
self._store_in_knowledge_graph(paper_data, paper_id)
return paper_id
def _store_in_vector_db(self, paper_data: Dict, paper_id: str):
"""存储到Pinecone向量数据库"""
# 提取关键文本进行向量化
texts_to_embed = []
# 标题和摘要
if 'title' in paper_data:
texts_to_embed.append(f"Title: {paper_data['title']}")
if 'abstract' in paper_data:
texts_to_embed.append(f"Abstract: {paper_data['abstract']}")
# 关键段落
if 'key_paragraphs' in paper_data:
texts_to_embed.extend(paper_data['key_paragraphs'][:5])
# 方法描述
if 'methodology' in paper_data:
texts_to_embed.append(f"Methodology: {paper_data['methodology']}")
# 生成embeddings
if texts_to_embed:
embeddings = self.embedder.encode(texts_to_embed)
# 准备向量数据
vectors = []
for i, (text, embedding) in enumerate(zip(texts_to_embed, embeddings)):
vector_id = f"{paper_id}_chunk_{i}"
metadata = {
"paper_id": paper_id,
"chunk_index": i,
"text": text[:1000], # 截断长文本
"type": self._identify_chunk_type(text),
"timestamp": datetime.now().isoformat()
}
vectors.append((vector_id, embedding.tolist(), metadata))
# 批量插入
if vectors:
self.vector_index.upsert(vectors=vectors)
def _store_in_knowledge_graph(self, paper_data: Dict, paper_id: str):
"""存储到Neo4j知识图谱"""
with self.neo4j_driver.session() as session:
# 创建论文节点
session.run("""
MERGE (p:Paper {doi: $doi})
SET p.title = $title,
p.abstract = $abstract,
p.year = $year,
p.venue = $venue,
p.citations = $citations,
p.stored_at = datetime()
""", {
"doi": paper_data.get("doi", paper_id),
"title": paper_data.get("title", ""),
"abstract": paper_data.get("abstract", ""),
"year": paper_data.get("year", 2023),
"venue": paper_data.get("venue", ""),
"citations": paper_data.get("citations", 0)
})
# 创建作者节点并连接
authors = paper_data.get("authors", [])
for i, author_name in enumerate(authors):
session.run("""
MERGE (a:Author {name: $name})
MERGE (a)-[r:AUTHORED {order: $order}]->(p:Paper {doi: $doi})
""", {
"name": author_name,
"order": i + 1,
"doi": paper_data.get("doi", paper_id)
})
# 提取关键词/概念
keywords = paper_data.get("keywords", [])
for keyword in keywords:
# 清理和标准化关键词
concept_name = self._normalize_concept(keyword)
session.run("""
MERGE (c:Concept {name: $name})
MERGE (p:Paper {doi: $doi})-[r:ABOUT]->(c)
""", {
"name": concept_name,
"doi": paper_data.get("doi", paper_id)
})
# 连接参考文献
references = paper_data.get("references", [])
for ref_doi in references[:20]: # 限制数量
if ref_doi:
session.run("""
MERGE (p:Paper {doi: $doi})
MERGE (ref:Paper {doi: $ref_doi})
MERGE (p)-[r:CITES]->(ref)
""", {
"doi": paper_data.get("doi", paper_id),
"ref_doi": ref_doi
})
def store_experiment(self, experiment_data: Dict) -> str:
"""
存储实验记录
"""
experiment_id = f"exp_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
with self.neo4j_driver.session() as session:
# 创建实验节点
session.run("""
CREATE (e:Experiment {
id: $id,
name: $name,
objective: $objective,
methodology: $methodology,
parameters: $parameters,
results: $results,
conclusion: $conclusion,
success: $success,
started_at: datetime($started_at),
completed_at: datetime($completed_at)
})
""", {
"id": experiment_id,
"name": experiment_data.get("name", "Unnamed Experiment"),
"objective": experiment_data.get("objective", ""),
"methodology": json.dumps(experiment_data.get("methodology", {})),
"parameters": json.dumps(experiment_data.get("parameters", {})),
"results": json.dumps(experiment_data.get("results", {})),
"conclusion": experiment_data.get("conclusion", ""),
"success": experiment_data.get("success", True),
"started_at": experiment_data.get("started_at", datetime.now().isoformat()),
"completed_at": experiment_data.get("completed_at", datetime.now().isoformat())
})
# 连接到相关论文
related_papers = experiment_data.get("related_papers", [])
for paper_id in related_papers:
session.run("""
MATCH (p:Paper {doi: $paper_id})
MATCH (e:Experiment {id: $exp_id})
MERGE (e)-[r:BASED_ON]->(p)
""", {
"paper_id": paper_id,
"exp_id": experiment_id
})
# 连接到使用的概念
used_concepts = experiment_data.get("concepts", [])
for concept in used_concepts:
concept_name = self._normalize_concept(concept)
session.run("""
MERGE (c:Concept {name: $name})
MATCH (e:Experiment {id: $exp_id})
MERGE (e)-[r:USES]->(c)
""", {
"name": concept_name,
"exp_id": experiment_id
})
return experiment_id
def semantic_search(self, query: str, top_k: int = 10) -> List[Dict]:
"""
语义搜索相关论文和知识
"""
# 生成查询向量
query_embedding = self.embedder.encode([query])[0].tolist()
# 在向量数据库搜索
vector_results = self.vector_index.query(
vector=query_embedding,
top_k=top_k,
include_metadata=True
)
# 在知识图谱搜索
graph_results = self._graph_search(query)
# 合并结果
combined_results = []
# 处理向量结果
for match in vector_results.matches:
combined_results.append({
"type": "vector_match",
"score": match.score,
"paper_id": match.metadata.get("paper_id"),
"text": match.metadata.get("text", ""),
"source": "vector_db"
})
# 处理图谱结果
combined_results.extend(graph_results)
# 按相关性排序
combined_results.sort(key=lambda x: x.get("score", 0), reverse=True)
return combined_results[:top_k]
def _graph_search(self, query: str) -> List[Dict]:
"""在图谱中搜索"""
results = []
with self.neo4j_driver.session() as session:
# 搜索相关论文
paper_results = session.run("""
MATCH (p:Paper)
WHERE toLower(p.title) CONTAINS toLower($query)
OR toLower(p.abstract) CONTAINS toLower($query)
RETURN p,
CASE
WHEN toLower(p.title) CONTAINS toLower($query) THEN 0.8
ELSE 0.5
END as relevance
ORDER BY relevance DESC
LIMIT 5
""", {"query": query})
for record in paper_results:
paper = record["p"]
results.append({
"type": "paper",
"score": record["relevance"],
"paper_id": paper["doi"],
"title": paper["title"],
"source": "knowledge_graph"
})
# 搜索相关概念
concept_results = session.run("""
MATCH (c:Concept)-[r]-(connected)
WHERE toLower(c.name) CONTAINS toLower($query)
RETURN c,
COUNT(r) as connection_count,
COLLECT(DISTINCT labels(connected)) as connected_types
ORDER BY connection_count DESC
LIMIT 5
""", {"query": query})
for record in concept_results:
concept = record["c"]
results.append({
"type": "concept",
"score": min(record["connection_count"] / 10, 1.0),
"concept": concept["name"],
"connections": record["connection_count"],
"connected_to": record["connected_types"],
"source": "knowledge_graph"
})
return results
def get_research_context(self, topic: str) -> Dict:
"""
获取研究领域的完整上下文
"""
context = {
"topic": topic,
"key_papers": [],
"key_concepts": [],
"research_gaps": [],
"timeline": [],
"experiment_history": []
}
with self.neo4j_driver.session() as session:
# 获取关键论文
key_papers = session.run("""
MATCH (p:Paper)-[:ABOUT]->(c:Concept)
WHERE toLower(c.name) CONTAINS toLower($topic)
RETURN p,
COUNT{(p)-[:CITES]->()} as citations,
COUNT{(p)<-[:CITES]-()} as cited_by
ORDER BY citations DESC
LIMIT 10
""", {"topic": topic})
for record in key_papers:
paper = record["p"]
context["key_papers"].append({
"title": paper["title"],
"authors": paper.get("authors", []),
"year": paper.get("year"),
"citations": record["cited_by"],
"doi": paper["doi"]
})
# 获取相关概念网络
concepts = session.run("""
MATCH (c:Concept)-[r]-(other)
WHERE toLower(c.name) CONTAINS toLower($topic)
RETURN c.name as concept,
COLLECT(DISTINCT {
type: type(r),
other: labels(other)[0],
other_name: other.name
}) as connections
ORDER BY SIZE(connections) DESC
LIMIT 15
""", {"topic": topic})
for record in concepts:
context["key_concepts"].append({
"concept": record["concept"],
"connections": record["connections"]
})
# 识别研究空白(引用较少的论文)
research_gaps = session.run("""
MATCH (p:Paper)-[:ABOUT]->(c:Concept)
WHERE toLower(c.name) CONTAINS toLower($topic)
AND NOT EXISTS {(p)<-[:CITES]-()}
AND p.year > 2020
RETURN p.title as title, p.doi as doi, p.year as year
LIMIT 5
""", {"topic": topic})
for record in research_gaps:
context["research_gaps"].append({
"title": record["title"],
"doi": record["doi"],
"year": record["year"]
})
return context3.2 实验历史跟踪器
# memory/experiment_tracker.py
import sqlite3
import pandas as pd
from datetime import datetime
from typing import Dict, List, Any, Optional
import json
import hashlib
class ExperimentTracker:
"""实验历史跟踪器"""
def __init__(self, db_path: str = "experiments.db"):
self.db_path = db_path
self._init_database()
def _init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 创建实验表
cursor.execute("""
CREATE TABLE IF NOT EXISTS experiments (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
objective TEXT,
hypothesis TEXT,
methodology TEXT,
parameters TEXT,
dataset TEXT,
metrics TEXT,
results TEXT,
conclusion TEXT,
success INTEGER,
duration_seconds REAL,
cost_usd REAL,
started_at TIMESTAMP,
completed_at TIMESTAMP,
researcher TEXT,
tags TEXT
)
""")
# 创建步骤表
cursor.execute("""
CREATE TABLE IF NOT EXISTS experiment_steps (
id INTEGER PRIMARY KEY AUTOINCREMENT,
experiment_id TEXT,
step_number INTEGER,
step_type TEXT,
description TEXT,
parameters TEXT,
result TEXT,
duration_seconds REAL,
timestamp TIMESTAMP,
FOREIGN KEY (experiment_id) REFERENCES experiments (id)
)
""")
# 创建学习表(从失败中学习)
cursor.execute("""
CREATE TABLE IF NOT EXISTS lessons_learned (
id INTEGER PRIMARY KEY AUTOINCREMENT,
experiment_id TEXT,
lesson_type TEXT,
description TEXT,
impact_score REAL,
learned_at TIMESTAMP,
FOREIGN KEY (experiment_id) REFERENCES experiments (id)
)
""")
conn.commit()
conn.close()
def start_experiment(self, experiment_config: Dict) -> str:
"""开始新实验"""
experiment_id = hashlib.md5(
f"{experiment_config['name']}_{datetime.now()}".encode()
).hexdigest()[:12]
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
INSERT INTO experiments (
id, name, objective, hypothesis, methodology,
parameters, started_at, researcher, tags
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
experiment_id,
experiment_config.get("name", "Unnamed Experiment"),
experiment_config.get("objective", ""),
experiment_config.get("hypothesis", ""),
json.dumps(experiment_config.get("methodology", {})),
json.dumps(experiment_config.get("parameters", {})),
datetime.now().isoformat(),
experiment_config.get("researcher", "AI Assistant"),
json.dumps(experiment_config.get("tags", []))
))
conn.commit()
conn.close()
return experiment_id
def add_experiment_step(self, experiment_id: str, step_data: Dict):
"""记录实验步骤"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 获取当前步骤号
cursor.execute("""
SELECT COUNT(*) FROM experiment_steps
WHERE experiment_id = ?
""", (experiment_id,))
step_number = cursor.fetchone()[0] + 1
cursor.execute("""
INSERT INTO experiment_steps (
experiment_id, step_number, step_type,
description, parameters, result,
duration_seconds, timestamp
) VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
experiment_id,
step_number,
step_data.get("step_type", "execution"),
step_data.get("description", ""),
json.dumps(step_data.get("parameters", {})),
json.dumps(step_data.get("result", {})),
step_data.get("duration_seconds", 0),
datetime.now().isoformat()
))
conn.commit()
conn.close()
def complete_experiment(self, experiment_id: str, results: Dict):
"""完成实验并记录结果"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 获取开始时间
cursor.execute("""
SELECT started_at FROM experiments WHERE id = ?
""", (experiment_id,))
started_at_str = cursor.fetchone()[0]
started_at = datetime.fromisoformat(started_at_str)
duration = (datetime.now() - started_at).total_seconds()
# 计算成功率
success = results.get("success", False)
# 提取关键指标
metrics = results.get("metrics", {})
cursor.execute("""
UPDATE experiments SET
results = ?,
metrics = ?,
conclusion = ?,
success = ?,
duration_seconds = ?,
completed_at = ?
WHERE id = ?
""", (
json.dumps(results.get("raw_results", {})),
json.dumps(metrics),
results.get("conclusion", ""),
1 if success else 0,
duration,
datetime.now().isoformat(),
experiment_id
))
# 如果失败,记录教训
if not success:
self._record_lesson(experiment_id, results)
conn.commit()
conn.close()
def _record_lesson(self, experiment_id: str, results: Dict):
"""从失败中学习"""
failure_analysis = self._analyze_failure(results)
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
INSERT INTO lessons_learned (
experiment_id, lesson_type, description,
impact_score, learned_at
) VALUES (?, ?, ?, ?, ?)
""", (
experiment_id,
failure_analysis.get("type", "general"),
failure_analysis.get("description", ""),
failure_analysis.get("impact_score", 0.5),
datetime.now().isoformat()
))
conn.commit()
conn.close()
def get_experiment_history(self,
researcher: Optional[str] = None,
tags: Optional[List[str]] = None,
limit: int = 50) -> List[Dict]:
"""获取实验历史"""
conn = sqlite3.connect(self.db_path)
query = "SELECT * FROM experiments WHERE 1=1"
params = []
if researcher:
query += " AND researcher = ?"
params.append(researcher)
if tags:
for tag in tags:
query += " AND tags LIKE ?"
params.append(f'%"{tag}"%')
query += " ORDER BY started_at DESC LIMIT ?"
params.append(limit)
df = pd.read_sql_query(query, conn, params=params)
conn.close()
# 解析JSON字段
for col in ['methodology', 'parameters', 'results', 'metrics', 'tags']:
if col in df.columns:
df[col] = df[col].apply(
lambda x: json.loads(x) if x and x != 'null' else {}
)
return df.to_dict('records')
def get_similar_experiments(self, current_config: Dict, top_k: int = 5) -> List[Dict]:
"""查找相似历史实验"""
# 提取关键特征
features = self._extract_experiment_features(current_config)
conn = sqlite3.connect(self.db_path)
# 获取所有历史实验
df = pd.read_sql_query("""
SELECT id, name, objective, methodology, parameters,
results, success, duration_seconds
FROM experiments
WHERE completed_at IS NOT NULL
""", conn)
conn.close()
if df.empty:
return []
# 计算相似度
similarities = []
for _, row in df.iterrows():
try:
hist_methodology = json.loads(row['methodology']) if row['methodology'] else {}
hist_parameters = json.loads(row['parameters']) if row['parameters'] else {}
# 特征相似度计算
sim_score = self._calculate_similarity(
features,
{
'methodology': hist_methodology,
'parameters': hist_parameters,
'objective': row['objective']
}
)
similarities.append({
'experiment_id': row['id'],
'name': row['name'],
'similarity': sim_score,
'success': bool(row['success']),
'duration': row['duration_seconds'],
'result_summary': json.loads(row['results']) if row['results'] else {}
})
except:
continue
# 按相似度排序
similarities.sort(key=lambda x: x['similarity'], reverse=True)
return similarities[:top_k]
def generate_experiment_insights(self) -> Dict:
"""生成实验洞察报告"""
conn = sqlite3.connect(self.db_path)
insights = {
"overall_stats": {},
"success_patterns": [],
"failure_patterns": [],
"optimization_opportunities": [],
"researcher_performance": {}
}
# 总体统计
cursor = conn.cursor()
cursor.execute("SELECT COUNT(*) FROM experiments")
total_experiments = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM experiments WHERE success = 1")
successful_experiments = cursor.fetchone()[0]
cursor.execute("SELECT AVG(duration_seconds) FROM experiments WHERE duration_seconds > 0")
avg_duration = cursor.fetchone()[0] or 0
insights["overall_stats"] = {
"total_experiments": total_experiments,
"success_rate": successful_experiments / total_experiments if total_experiments > 0 else 0,
"avg_duration_hours": avg_duration / 3600,
"completion_rate": 1.0 # 假设所有实验都完成了
}
# 成功模式分析
cursor.execute("""
SELECT methodology, parameters, AVG(duration_seconds) as avg_time
FROM experiments
WHERE success = 1
GROUP BY methodology, parameters
HAVING COUNT(*) >= 2
ORDER BY COUNT(*) DESC
LIMIT 5
""")
for row in cursor.fetchall():
insights["success_patterns"].append({
"methodology": json.loads(row[0]) if row[0] else {},
"parameters": json.loads(row[1]) if row[1] else {},
"avg_time_hours": row[2] / 3600 if row[2] else 0,
"occurrences": 2 # 简化的计数
})
# 失败教训
cursor.execute("""
SELECT lesson_type, description, COUNT(*) as count
FROM lessons_learned
GROUP BY lesson_type, description
ORDER BY COUNT(*) DESC
LIMIT 5
""")
for row in cursor.fetchall():
insights["failure_patterns"].append({
"type": row[0],
"description": row[1],
"frequency": row[2]
})
conn.close()
return insights模块三:决策模块实现
4.1 ReAct框架与规划引擎
# decision/react_engine.py
from typing import Dict, List, Any, Optional
import re
import json
from datetime import datetime
from langchain.agents import Tool, AgentExecutor
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.schema import SystemMessage, HumanMessage, AIMessage
import asyncio
class ResearchPlanningAgent:
"""基于ReAct框架的研究规划智能体"""
def __init__(self,
llm, # 假设已初始化的Qwen模型
tools: List[Tool],
memory_store,
knowledge_store):
self.llm = llm
self.tools = {tool.name: tool for tool in tools}
self.memory = memory_store
self.knowledge = knowledge_store
# 定义ReAct提示模板
self.react_prompt = PromptTemplate(
input_variables=["objective", "context", "history", "available_tools"],
template="""
你是一个AI科研助手,负责帮助研究者规划实验。请使用ReAct框架进行思考:
思考步骤:
1. 观察:分析当前情况和目标
2. 思考:基于现有知识推理下一步
3. 行动:调用合适的工具执行操作
4. 观察:分析行动结果
5. 循环直到目标达成
研究目标:{objective}
当前上下文:
{context}
历史记录:
{history}
可用工具:
{available_tools}
请按以下格式输出:
思考: <你的推理过程>
行动: <工具名称>
行动输入: <工具输入>
观察: <工具输出>
...(重复思考-行动-观察循环)
当目标达成时,输出:
最终答案: <研究计划和步骤>
"""
)
async def plan_experiment(self,
research_question: str,
constraints: Optional[Dict] = None) -> Dict:
"""
规划完整实验流程
"""
constraints = constraints or {}
# 第一步:文献调研
literature_review = await self._conduct_literature_review(research_question)
# 第二步:生成假设
hypotheses = await self._generate_hypotheses(
research_question,
literature_review
)
# 第三步:规划实验
experiment_plan = await self._design_experiment(
research_question,
hypotheses,
constraints
)
# 第四步:优化计划
optimized_plan = await self._optimize_plan(
experiment_plan,
constraints
)
return {
"research_question": research_question,
"literature_review": literature_review,
"hypotheses": hypotheses,
"experiment_plan": optimized_plan,
"timeline": self._estimate_timeline(optimized_plan),
"resource_requirements": self._estimate_resources(optimized_plan)
}
async def _conduct_literature_review(self, research_question: str) -> Dict:
"""文献调研"""
# 搜索相关文献
search_results = await self._call_tool(
"semantic_search",
{"query": research_question, "top_k": 20}
)
# 分析文献
analysis_prompt = f"""
基于以下搜索结果,分析研究领域现状:
研究问题:{research_question}
相关文献:
{json.dumps(search_results[:10], indent=2)}
请分析:
1. 该领域的核心理论和方法
2. 主要研究空白
3. 近期重要进展
4. 关键参考文献
请用JSON格式输出分析结果。
"""
analysis = await self._call_llm(analysis_prompt)
return {
"search_results": search_results,
"analysis": json.loads(analysis),
"key_papers": search_results[:5]
}
async def _generate_hypotheses(self,
research_question: str,
literature_review: Dict) -> List[Dict]:
"""生成研究假设"""
prompt = f"""
基于以下研究问题和文献分析,生成3-5个可验证的研究假设:
研究问题:{research_question}
文献分析摘要:
{json.dumps(literature_review.get('analysis', {}), indent=2)}
请为每个假设提供:
1. 假设陈述
2. 理论基础(引用相关文献)
3. 验证方法
4. 预期结果
5. 潜在风险
请用JSON格式输出假设列表。
"""
response = await self._call_llm(prompt)
try:
hypotheses = json.loads(response)
except:
# 如果JSON解析失败,尝试提取
hypotheses = self._extract_hypotheses_from_text(response)
return hypotheses
async def _design_experiment(self,
research_question: str,
hypotheses: List[Dict],
constraints: Dict) -> Dict:
"""设计实验方案"""
# 为每个假设设计实验
experiments = []
for i, hypothesis in enumerate(hypotheses):
experiment_design = await self._design_single_experiment(
hypothesis=hypothesis,
constraints=constraints,
experiment_number=i+1
)
experiments.append(experiment_design)
# 确定实验顺序
execution_order = await self._determine_execution_order(experiments)
return {
"research_question": research_question,
"hypotheses": hypotheses,
"experiments": experiments,
"execution_order": execution_order,
"dependencies": self._identify_dependencies(experiments)
}
async def _design_single_experiment(self,
hypothesis: Dict,
constraints: Dict,
experiment_number: int) -> Dict:
"""设计单个实验"""
prompt = f"""
设计实验来验证以下假设:
假设:{hypothesis.get('statement', '')}
约束条件:
- 时间:{constraints.get('time_limit', '无限制')}
- 资源:{constraints.get('resources', '标准实验室设备')}
- 预算:{constraints.get('budget', '无限制')}
- 伦理限制:{constraints.get('ethical_constraints', '无')}
请提供详细的实验设计:
1. 实验名称
2. 实验类型(探索性/验证性/对照实验等)
3. 变量设计(自变量、因变量、控制变量)
4. 样本/数据需求
5. 实验步骤(详细)
6. 测量指标
7. 数据分析方法
8. 质量控制措施
9. 备选方案
请用JSON格式输出。
"""
design = await self._call_llm(prompt)
try:
experiment_design = json.loads(design)
except:
experiment_design = {"raw_design": design}
# 添加元数据
experiment_design.update({
"experiment_id": f"exp_{experiment_number:03d}",
"hypothesis_id": hypothesis.get("id", f"hyp_{experiment_number}"),
"designed_at": datetime.now().isoformat(),
"estimated_duration": self._estimate_experiment_duration(experiment_design),
"estimated_cost": self._estimate_experiment_cost(experiment_design, constraints)
})
return experiment_design
async def _determine_execution_order(self, experiments: List[Dict]) -> List[Dict]:
"""确定实验执行顺序"""
prompt = f"""
给定以下实验设计,请确定最优的执行顺序:
实验列表:
{json.dumps([{'id': exp.get('experiment_id'),
'name': exp.get('experiment_name', 'Unnamed'),
'type': exp.get('experiment_type', '未知'),
'duration': exp.get('estimated_duration', '未知'),
'dependencies': exp.get('dependencies', [])}
for exp in experiments], indent=2)}
考虑因素:
1. 实验间的依赖关系
2. 学习曲线(先简单后复杂)
3. 资源共享
4. 风险分散
5. 结果迭代(早期结果影响后续实验)
请输出:
1. 最优执行顺序(列表)
2. 理由说明
3. 甘特图时间估计
请用JSON格式输出。
"""
order_analysis = await self._call_llm(prompt)
try:
return json.loads(order_analysis)
except:
# 默认顺序
return {
"order": [exp["experiment_id"] for exp in experiments],
"reasoning": "按设计顺序执行",
"timeline": "需要进一步优化"
}
async def _optimize_plan(self, plan: Dict, constraints: Dict) -> Dict:
"""优化实验计划"""
# 检查资源约束
total_resources = self._calculate_total_resources(plan)
optimization_needed = False
if constraints.get("budget"):
if total_resources.get("estimated_cost", 0) > constraints["budget"]:
optimization_needed = True
if constraints.get("time_limit"):
if total_resources.get("total_duration", 0) > constraints["time_limit"]:
optimization_needed = True
if optimization_needed:
# 调用优化工具
optimized = await self._call_tool(
"optimize_experiment_plan",
{
"plan": plan,
"constraints": constraints,
"total_resources": total_resources
}
)
return optimized
else:
return plan
def _extract_hypotheses_from_text(self, text: str) -> List[Dict]:
"""从文本中提取假设"""
hypotheses = []
# 使用正则表达式提取假设
hypothesis_patterns = [
r'假设\d+[::]\s*(.+?)(?=\n|$)',
r'Hypothesis\d+[::]\s*(.+?)(?=\n|$)',
r'\d+\.\s*(.+?验证.+?)(?=\n|$)'
]
for pattern in hypothesis_patterns:
matches = re.findall(pattern, text, re.DOTALL | re.IGNORECASE)
for match in matches:
hypotheses.append({
"statement": match.strip(),
"source": "extracted_from_text"
})
return hypotheses if hypotheses else [
{"statement": "需要人工制定具体假设", "source": "placeholder"}
]
async def _call_tool(self, tool_name: str, input_data: Dict) -> Any:
"""调用工具"""
if tool_name in self.tools:
tool = self.tools[tool_name]
return await tool.arun(input_data)
else:
raise ValueError(f"工具 {tool_name} 不存在")
async def _call_llm(self, prompt: str) -> str:
"""调用大语言模型"""
messages = [
SystemMessage(content="你是一个专业的科研助手,精通实验设计和研究规划。"),
HumanMessage(content=prompt)
]
response = await self.llm.agenerate([messages])
return response.generations[0][0].text4.2 实验步骤生成器
# decision/experiment_generator.py
import json
from typing import Dict, List, Any
from dataclasses import dataclass
from enum import Enum
import networkx as nx
class ExperimentType(Enum):
EXPLORATORY = "exploratory"
VALIDATION = "validation"
REPLICATION = "replication"
AB_TESTING = "ab_testing"
LONGITUDINAL = "longitudinal"
CROSS_SECTIONAL = "cross_sectional"
@dataclass
class ExperimentalVariable:
name: str
type: str # independent, dependent, control
description: str
measurement_unit: str
expected_range: List[float]
@dataclass
class ExperimentStep:
step_number: int
name: str
description: str
duration_minutes: int
required_resources: List[str]
dependencies: List[int]
success_criteria: str
notes: str = ""
class ExperimentGenerator:
"""实验步骤生成器"""
def __init__(self, knowledge_base, llm):
self.knowledge = knowledge_base
self.llm = llm
# 实验模板库
self.experiment_templates = self._load_templates()
def generate_detailed_steps(self,
experiment_design: Dict,
available_resources: Dict) -> Dict:
"""
生成详细的实验步骤
"""
# 确定实验类型
exp_type = self._identify_experiment_type(experiment_design)
# 获取模板
template = self.experiment_templates.get(exp_type, {})
# 生成步骤
steps = self._generate_steps_from_template(
template,
experiment_design,
available_resources
)
# 添加资源准备步骤
preparation_steps = self._generate_preparation_steps(
experiment_design,
available_resources
)
# 添加质量控制步骤
qc_steps = self._generate_quality_control_steps(experiment_design)
# 组合所有步骤
all_steps = preparation_steps + steps + qc_steps
# 优化步骤顺序和并行化
optimized_steps = self._optimize_step_sequence(all_steps)
# 生成检查点
checkpoints = self._generate_checkpoints(optimized_steps)
return {
"experiment_id": experiment_design.get("experiment_id"),
"experiment_type": exp_type,
"steps": optimized_steps,
"checkpoints": checkpoints,
"total_duration": self._calculate_total_duration(optimized_steps),
"critical_path": self._identify_critical_path(optimized_steps),
"resource_schedule": self._create_resource_schedule(optimized_steps)
}
def _generate_steps_from_template(self,
template: Dict,
design: Dict,
resources: Dict) -> List[ExperimentStep]:
"""从模板生成步骤"""
if template.get("auto_generate"):
# 使用LLM生成步骤
prompt = f"""
基于以下实验设计,生成详细的实验步骤:
实验设计:
{json.dumps(design, indent=2)}
可用资源:
{json.dumps(resources, indent=2)}
模板类型:{template.get('name', '通用实验')}
请生成详细的步骤列表,每个步骤包含:
1. 步骤编号
2. 步骤名称
3. 详细描述
4. 预计耗时(分钟)
5. 所需资源
6. 依赖步骤
7. 成功标准
请用JSON格式输出步骤列表。
"""
response = self.llm.generate(prompt)
try:
steps_data = json.loads(response)
return [ExperimentStep(**step) for step in steps_data]
except:
# 使用默认步骤
return self._generate_default_steps(design)
else:
# 使用预定义模板
return self._apply_predefined_template(template, design, resources)
def _generate_preparation_steps(self,
design: Dict,
resources: Dict) -> List[ExperimentStep]:
"""生成准备步骤"""
prep_steps = []
# 1. 材料准备
materials = design.get("required_materials", [])
if materials:
prep_steps.append(ExperimentStep(
step_number=1,
name="材料准备与检查",
description=f"准备以下材料:{', '.join(materials)}",
duration_minutes=30,
required_resources=["实验室台架", "材料清单"],
dependencies=[],
success_criteria="所有材料齐全且质量合格"
))
# 2. 设备校准
equipment = design.get("required_equipment", [])
if equipment:
prep_steps.append(ExperimentStep(
step_number=2,
name="设备校准",
description=f"校准设备:{', '.join(equipment)}",
duration_minutes=45,
required_resources=equipment,
dependencies=[1] if prep_steps else [],
success_criteria="所有设备校准通过"
))
# 3. 环境准备
env_requirements = design.get("environment_requirements", {})
if env_requirements:
prep_steps.append(ExperimentStep(
step_number=3,
name="实验环境准备",
description=f"设置环境:{json.dumps(env_requirements)}",
duration_minutes=20,
required_resources=["环境监测设备"],
dependencies=[2] if len(prep_steps) >= 2 else [],
success_criteria="环境参数达到要求"
))
return prep_steps
def _generate_quality_control_steps(self, design: Dict) -> List[ExperimentStep]:
"""生成质量控制步骤"""
qc_steps = []
qc_step_num = len(design.get("steps", [])) + 1
# 中间检查点
qc_steps.append(ExperimentStep(
step_number=qc_step_num,
name="中间质量检查",
description="检查实验进度和数据质量",
duration_minutes=15,
required_resources=["检查表", "数据记录"],
dependencies=list(range(1, qc_step_num)),
success_criteria="实验按计划进行,数据质量合格"
))
# 最终验证
qc_steps.append(ExperimentStep(
step_number=qc_step_num + 1,
name="最终结果验证",
description="验证实验结果并检查异常",
duration_minutes=30,
required_resources=["分析工具", "验证标准"],
dependencies=[qc_step_num],
success_criteria="结果通过验证,无异常数据"
))
return qc_steps
def _optimize_step_sequence(self, steps: List[ExperimentStep]) -> List[ExperimentStep]:
"""优化步骤顺序,实现并行化"""
# 创建有向图表示依赖关系
G = nx.DiGraph()
for step in steps:
G.add_node(step.step_number, step=step)
for dep in step.dependencies:
G.add_edge(dep, step.step_number)
# 拓扑排序
try:
topo_order = list(nx.topological_sort(G))
except nx.NetworkXUnfeasible:
# 有循环依赖,使用简单排序
topo_order = sorted([step.step_number for step in steps])
# 识别可并行步骤
parallel_groups = []
current_group = []
max_group_size = 3 # 最大并行步骤数
for step_num in topo_order:
step = G.nodes[step_num]['step']
if len(current_group) < max_group_size:
current_group.append(step)
else:
parallel_groups.append(current_group)
current_group = [step]
if current_group:
parallel_groups.append(current_group)
# 重新编号步骤
optimized_steps = []
new_step_num = 1
for group in parallel_groups:
if len(group) == 1:
# 串行步骤
step = group[0]
step.step_number = new_step_num
# 更新依赖关系
step.dependencies = [
dep for dep in step.dependencies
if dep < new_step_num
]
optimized_steps.append(step)
new_step_num += 1
else:
# 并行步骤组
for step in group:
step.step_number = new_step_num
step.notes = f"可与步骤 {new_step_num}-{new_step_num+len(group)-1} 并行执行"
# 更新依赖关系
step.dependencies = [
dep for dep in step.dependencies
if dep < new_step_num
]
optimized_steps.append(step)
new_step_num += 1
return optimized_steps
def _generate_checkpoints(self, steps: List[ExperimentStep]) -> List[Dict]:
"""生成检查点"""
checkpoints = []
# 每3-5个步骤设置一个检查点
checkpoint_interval = 4
for i in range(0, len(steps), checkpoint_interval):
checkpoint_steps = steps[i:i+checkpoint_interval]
checkpoint = {
"checkpoint_id": f"CP_{len(checkpoints)+1:03d}",
"step_range": [s.step_number for s in checkpoint_steps],
"verification_items": self._generate_verification_items(checkpoint_steps),
"acceptance_criteria": self._generate_acceptance_criteria(checkpoint_steps),
"recovery_procedure": self._generate_recovery_procedure(checkpoint_steps)
}
checkpoints.append(checkpoint)
return checkpoints
def _identify_critical_path(self, steps: List[ExperimentStep]) -> List[int]:
"""识别关键路径"""
# 简化实现:返回依赖最多的步骤链
critical_path = []
max_dependencies = 0
for step in steps:
if len(step.dependencies) > max_dependencies:
max_dependencies = len(step.dependencies)
critical_path = step.dependencies + [step.step_number]
return critical_path if critical_path else [step.step_number for step in steps]模块四:行动模块实现
5.1 工具调用与代码执行器
# action/tool_executor.py
import subprocess
import sys
import tempfile
import os
from typing import Dict, List, Any, Optional
import json
import docker
import paramiko
from langchain.tools import BaseTool
from langchain.callbacks.manager import CallbackManagerForToolRun
class CodeExecutionTool(BaseTool):
"""代码执行工具"""
name = "execute_code"
description = "执行Python代码并返回结果"
def _run(self,
code: str,
language: str = "python",
timeout: int = 300,
run_id: Optional[str] = None) -> Dict:
"""执行代码"""
if language.lower() != "python":
return {
"success": False,
"error": f"不支持的语言: {language}",
"output": ""
}
# 创建临时文件
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
temp_file = f.name
try:
# 执行代码
result = subprocess.run(
[sys.executable, temp_file],
capture_output=True,
text=True,
timeout=timeout,
env={**os.environ, "PYTHONPATH": "."}
)
# 清理临时文件
os.unlink(temp_file)
return {
"success": result.returncode == 0,
"returncode": result.returncode,
"stdout": result.stdout,
"stderr": result.stderr,
"execution_time": "measured", # 实际需要计时
"run_id": run_id or f"run_{hash(code) % 10000}"
}
except subprocess.TimeoutExpired:
os.unlink(temp_file)
return {
"success": False,
"error": f"执行超时 ({timeout}秒)",
"output": ""
}
except Exception as e:
if os.path.exists(temp_file):
os.unlink(temp_file)
return {
"success": False,
"error": str(e),
"output": ""
}
async def _arun(self,
code: str,
language: str = "python",
timeout: int = 300,
run_id: Optional[str] = None) -> Dict:
"""异步执行代码"""
# 在单独的线程中运行
import asyncio
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as executor:
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(
executor,
lambda: self._run(code, language, timeout, run_id)
)
return result
class DockerExecutionTool(BaseTool):
"""Docker容器执行工具"""
name = "execute_in_docker"
description = "在Docker容器中执行代码"
def __init__(self):
super().__init__()
self.docker_client = docker.from_env()
def _run(self,
image: str,
command: str,
volumes: Optional[Dict] = None,
environment: Optional[Dict] = None,
gpu: bool = False) -> Dict:
"""在Docker容器中执行命令"""
try:
# 准备运行配置
run_kwargs = {
"command": command,
"detach": False,
"remove": True,
"stdout": True,
"stderr": True
}
if volumes:
run_kwargs["volumes"] = volumes
if environment:
run_kwargs["environment"] = environment
if gpu:
run_kwargs["device_requests"] = [
docker.types.DeviceRequest(count=-1, capabilities=[['gpu']])
]
# 运行容器
container = self.docker_client.containers.run(
image,
**run_kwargs
)
if isinstance(container, bytes):
output = container.decode('utf-8')
else:
output = str(container)
return {
"success": True,
"output": output,
"image": image,
"command": command
}
except docker.errors.ContainerError as e:
return {
"success": False,
"error": f"容器错误: {e}",
"output": e.stderr.decode('utf-8') if e.stderr else str(e)
}
except Exception as e:
return {
"success": False,
"error": str(e),
"output": ""
}
class SSHEnvironmentTool(BaseTool):
"""SSH远程环境工具"""
name = "execute_remote"
description = "在远程服务器上执行命令"
def __init__(self,
host: str,
username: str,
password: Optional[str] = None,
key_filename: Optional[str] = None):
super().__init__()
self.host = host
self.username = username
self.password = password
self.key_filename = key_filename
# 创建SSH客户端
self.ssh_client = paramiko.SSHClient()
self.ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def _run(self,
command: str,
workdir: Optional[str] = None) -> Dict:
"""执行远程命令"""
try:
# 连接服务器
self.ssh_client.connect(
hostname=self.host,
username=self.username,
password=self.password,
key_filename=self.key_filename
)
# 如果指定工作目录,先切换目录
if workdir:
command = f"cd {workdir} && {command}"
# 执行命令
stdin, stdout, stderr = self.ssh_client.exec_command(command)
# 读取输出
stdout_text = stdout.read().decode('utf-8')
stderr_text = stderr.read().decode('utf-8')
exit_code = stdout.channel.recv_exit_status()
return {
"success": exit_code == 0,
"exit_code": exit_code,
"stdout": stdout_text,
"stderr": stderr_text,
"command": command,
"host": self.host
}
except Exception as e:
return {
"success": False,
"error": str(e),
"output": ""
}
finally:
try:
self.ssh_client.close()
except:
pass
class ModelTrainingTool(BaseTool):
"""模型训练工具"""
name = "train_model"
description = "训练机器学习模型"
def _run(self,
config: Dict,
dataset_path: str,
output_dir: str) -> Dict:
"""训练模型"""
# 生成训练脚本
train_script = self._generate_training_script(config, dataset_path, output_dir)
# 保存脚本
script_path = os.path.join(output_dir, "train.py")
os.makedirs(output_dir, exist_ok=True)
with open(script_path, 'w') as f:
f.write(train_script)
# 执行训练
try:
result = subprocess.run(
[sys.executable, script_path],
capture_output=True,
text=True,
timeout=config.get("timeout", 3600)
)
# 解析训练结果
metrics = self._parse_training_output(result.stdout, output_dir)
return {
"success": result.returncode == 0,
"metrics": metrics,
"stdout": result.stdout,
"stderr": result.stderr,
"model_path": os.path.join(output_dir, "model.pth"),
"log_path": os.path.join(output_dir, "training.log")
}
except Exception as e:
return {
"success": False,
"error": str(e),
"output": ""
}
def _generate_training_script(self, config: Dict, dataset_path: str, output_dir: str) -> str:
"""生成训练脚本"""
model_type = config.get("model_type", "classification")
framework = config.get("framework", "pytorch")
if framework == "pytorch":
template = f"""
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import pandas as pd
import numpy as np
import json
import os
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
# 配置参数
config = {json.dumps(config, indent=2)}
# 数据加载
class CustomDataset(Dataset):
def __init__(self, data, labels):
self.data = torch.FloatTensor(data)
self.labels = torch.LongTensor(labels)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
# 加载数据
print("Loading dataset from {dataset_path}")
data = pd.read_csv('{dataset_path}')
X = data.drop(columns=['target']).values
y = data['target'].values
# 划分数据集
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 创建数据加载器
train_dataset = CustomDataset(X_train, y_train)
val_dataset = CustomDataset(X_val, y_val)
train_loader = DataLoader(train_dataset,
batch_size=config.get('batch_size', 32),
shuffle=True)
val_loader = DataLoader(val_dataset,
batch_size=config.get('batch_size', 32),
shuffle=False)
# 定义模型
class SimpleModel(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(SimpleModel, self).__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.relu(out)
out = self.layer2(out)
return out
# 初始化模型
input_size = X.shape[1]
hidden_size = config.get('hidden_size', 64)
num_classes = len(np.unique(y))
model = SimpleModel(input_size, hidden_size, num_classes)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),
lr=config.get('learning_rate', 0.001))
# 训练循环
num_epochs = config.get('epochs', 10)
train_losses = []
val_accuracies = []
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
avg_train_loss = train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 验证阶段
model.eval()
all_preds = []
all_targets = []
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1)
all_preds.extend(predicted.cpu().numpy())
all_targets.extend(target.cpu().numpy())
val_accuracy = accuracy_score(all_targets, all_preds)
val_accuracies.append(val_accuracy)
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Train Loss: {avg_train_loss:.4f}, '
f'Val Accuracy: {val_accuracy:.4f}')
# 保存模型
os.makedirs('{output_dir}', exist_ok=True)
torch.save(model.state_dict(), os.path.join('{output_dir}', 'model.pth'))
# 保存训练历史
history = {{
'train_loss': train_losses,
'val_accuracy': val_accuracies,
'config': config
}}
with open(os.path.join('{output_dir}', 'history.json'), 'w') as f:
json.dump(history, f, indent=2)
print("Training completed!")
"""
else:
template = "# 其他框架的训练脚本"
return template
def _parse_training_output(self, output: str, output_dir: str) -> Dict:
"""解析训练输出"""
metrics = {}
# 从输出中提取指标
import re
# 提取准确率
accuracy_matches = re.findall(r"Accuracy[:=]\s*([0-9.]+)", output)
if accuracy_matches:
metrics["accuracy"] = float(accuracy_matches[-1])
# 提取损失
loss_matches = re.findall(r"Loss[:=]\s*([0-9.]+)", output)
if loss_matches:
metrics["loss"] = float(loss_matches[-1])
# 从保存的历史文件中读取
history_path = os.path.join(output_dir, "history.json")
if os.path.exists(history_path):
try:
with open(history_path, 'r') as f:
history = json.load(f)
metrics.update({
"final_train_loss": history.get("train_loss", [])[-1] if history.get("train_loss") else None,
"final_val_accuracy": history.get("val_accuracy", [])[-1] if history.get("val_accuracy") else None,
"best_val_accuracy": max(history.get("val_accuracy", [])) if history.get("val_accuracy") else None
})
except:
pass
return metrics5.2 LaTeX报告生成器
# action/report_generator.py
import os
import tempfile
import subprocess
from datetime import datetime
from typing import Dict, List, Any, Optional
import json
import pandas as pd
import matplotlib.pyplot as plt
from jinja2 import Template
class LaTeXReportGenerator:
"""LaTeX实验报告生成器"""
def __init__(self, template_dir: str = "templates"):
self.template_dir = template_dir
self._load_templates()
def _load_templates(self):
"""加载LaTeX模板"""
self.templates = {
"experiment": self._get_template("experiment_report.tex"),
"methodology": self._get_template("methodology.tex"),
"results": self._get_template("results.tex"),
"discussion": self._get_template("discussion.tex")
}
def _get_template(self, filename: str) -> Template:
"""获取Jinja2模板"""
template_path = os.path.join(self.template_dir, filename)
if os.path.exists(template_path):
with open(template_path, 'r', encoding='utf-8') as f:
return Template(f.read())
else:
# 返回默认模板
return Template(self._get_default_template(filename))
def generate_experiment_report(self,
experiment_data: Dict,
results_data: Dict,
output_dir: str = "reports") -> Dict:
"""
生成完整的实验报告
"""
# 准备数据
report_data = self._prepare_report_data(experiment_data, results_data)
# 生成LaTeX内容
latex_content = self._generate_latex_content(report_data)
# 保存文件
os.makedirs(output_dir, exist_ok=True)
report_id = experiment_data.get("experiment_id", f"report_{datetime.now():%Y%m%d_%H%M%S}")
tex_filename = f"{report_id}.tex"
pdf_filename = f"{report_id}.pdf"
tex_path = os.path.join(output_dir, tex_filename)
pdf_path = os.path.join(output_dir, pdf_filename)
# 写入LaTeX文件
with open(tex_path, 'w', encoding='utf-8') as f:
f.write(latex_content)
# 编译为PDF
success = self._compile_latex(tex_path, output_dir)
# 生成图表
figures = self._generate_figures(results_data, output_dir)
return {
"report_id": report_id,
"experiment_id": experiment_data.get("experiment_id"),
"latex_path": tex_path,
"pdf_path": pdf_path if success else None,
"figures": figures,
"metadata": report_data.get("metadata", {}),
"success": success
}
def _prepare_report_data(self,
experiment_data: Dict,
results_data: Dict) -> Dict:
"""准备报告数据"""
# 提取关键信息
metadata = {
"title": experiment_data.get("name", "实验报告"),
"date": datetime.now().strftime("%Y年%m月%d日"),
"author": experiment_data.get("researcher", "AI科研助手"),
"experiment_id": experiment_data.get("experiment_id"),
"hypothesis": experiment_data.get("hypothesis", ""),
"objective": experiment_data.get("objective", "")
}
# 准备方法部分
methodology = {
"design": experiment_data.get("methodology", {}),
"variables": self._extract_variables(experiment_data),
"procedure": self._format_procedure(experiment_data.get("steps", [])),
"materials": experiment_data.get("required_materials", []),
"equipment": experiment_data.get("required_equipment", [])
}
# 准备结果部分
results = {
"raw_data": results_data.get("raw_results", {}),
"statistics": results_data.get("statistics", {}),
"metrics": results_data.get("metrics", {}),
"figures": [],
"tables": self._create_results_tables(results_data)
}
# 讨论部分
discussion = {
"interpretation": results_data.get("interpretation", ""),
"limitations": experiment_data.get("limitations", []),
"implications": results_data.get("implications", []),
"future_work": results_data.get("future_work", [])
}
return {
"metadata": metadata,
"methodology": methodology,
"results": results,
"discussion": discussion,
"conclusion": results_data.get("conclusion", "")
}
def _generate_latex_content(self, report_data: Dict) -> str:
"""生成LaTeX内容"""
# 使用模板生成完整文档
latex_template = r"""
\documentclass[12pt]{article}
\usepackage[utf8]{inputenc}
\usepackage{ctex}
\usepackage{geometry}
\usepackage{graphicx}
\usepackage{booktabs}
\usepackage{multirow}
\usepackage{amsmath}
\usepackage{hyperref}
\usepackage{float}
\geometry{a4paper, margin=1in}
\title{实验报告:{{ metadata.title }}}
\author{ {{ metadata.author }} }
\date{ {{ metadata.date }} }
\begin{document}
\maketitle
\begin{abstract}
本报告描述了关于"{{ metadata.hypothesis }}"假设的实验验证。实验旨在{{ metadata.objective }}。实验结果显示...
\end{abstract}
\section{引言}
\label{sec:introduction}
\section{方法}
\label{sec:methodology}
\subsection{实验设计}
{{ methodology.design.description }}
\subsection{变量定义}
\begin{itemize}
{% for var in methodology.variables %}
\item {{ var.name }} ({{ var.type }}): {{ var.description }}
{% endfor %}
\end{itemize}
\subsection{实验步骤}
{{ methodology.procedure }}
\section{结果}
\label{sec:results}
{% for table in results.tables %}
\subsection{ {{ table.title }} }
{{ table.content|safe }}
{% endfor %}
\section{讨论}
\label{sec:discussion}
\subsection{结果解释}
{{ discussion.interpretation }}
\subsection{实验限制}
\begin{itemize}
{% for limit in discussion.limitations %}
\item {{ limit }}
{% endfor %}
\end{itemize}
\subsection{未来工作}
\begin{itemize}
{% for work in discussion.future_work %}
\item {{ work }}
{% endfor %}
\end{itemize}
\section{结论}
\label{sec:conclusion}
{{ conclusion }}
\end{document}
"""
template = Template(latex_template)
return template.render(**report_data)
def _generate_figures(self, results_data: Dict, output_dir: str) -> List[Dict]:
"""生成图表"""
figures = []
# 创建图表目录
fig_dir = os.path.join(output_dir, "figures")
os.makedirs(fig_dir, exist_ok=True)
# 1. 性能指标图
metrics = results_data.get("metrics", {})
if metrics:
fig_path = os.path.join(fig_dir, "metrics_comparison.png")
plt.figure(figsize=(10, 6))
names = list(metrics.keys())
values = list(metrics.values())
bars = plt.bar(names, values)
plt.xlabel('指标')
plt.ylabel('值')
plt.title('实验性能指标')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig(fig_path, dpi=300)
plt.close()
figures.append({
"type": "bar_chart",
"title": "性能指标对比",
"path": fig_path,
"caption": "实验各项性能指标对比"
})
# 2. 训练历史图(如果有)
history = results_data.get("training_history", {})
if history.get("train_loss") and history.get("val_accuracy"):
fig_path = os.path.join(fig_dir, "training_history.png")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 损失曲线
ax1.plot(history["train_loss"], label='训练损失')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.set_title('训练损失曲线')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 准确率曲线
ax2.plot(history["val_accuracy"], label='验证准确率', color='orange')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
ax2.set_title('验证准确率曲线')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(fig_path, dpi=300)
plt.close()
figures.append({
"type": "training_curves",
"title": "训练历史",
"path": fig_path,
"caption": "模型训练损失和验证准确率曲线"
})
return figures
def _compile_latex(self, tex_path: str, output_dir: str) -> bool:
"""编译LaTeX为PDF"""
try:
# 使用xelatex编译(支持中文)
result = subprocess.run(
[
"xelatex",
"-interaction=nonstopmode",
"-output-directory", output_dir,
tex_path
],
capture_output=True,
text=True,
timeout=60
)
# 可能需要编译两次以获得正确的交叉引用
if result.returncode == 0:
subprocess.run(
[
"xelatex",
"-interaction=nonstopmode",
"-output-directory", output_dir,
tex_path
],
capture_output=True,
timeout=60
)
return result.returncode == 0
except Exception as e:
print(f"LaTeX编译失败: {e}")
return False模块五:反馈模块实现
6.1 RLHF优化系统
# feedback/rlhf_optimizer.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from typing import Dict, List, Any, Optional, Tuple
import json
import numpy as np
from collections import defaultdict
import random
from transformers import AutoTokenizer, AutoModelForSequenceClassification
class PreferenceDataset(Dataset):
"""偏好学习数据集"""
def __init__(self,
preference_data: List[Dict],
tokenizer,
max_length: int = 512):
self.tokenizer = tokenizer
self.max_length = max_length
self.examples = []
for item in preference_data:
chosen = item.get("chosen")
rejected = item.get("rejected")
if chosen and rejected:
self.examples.append({
"chosen": chosen,
"rejected": rejected,
"metadata": item.get("metadata", {})
})
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
example = self.examples[idx]
# 编码chosen和rejected文本
chosen_enc = self.tokenizer(
example["chosen"],
truncation=True,
padding="max_length",
max_length=self.max_length,
return_tensors="pt"
)
rejected_enc = self.tokenizer(
example["rejected"],
truncation=True,
padding="max_length",
max_length=self.max_length,
return_tensors="pt"
)
return {
"chosen_input_ids": chosen_enc["input_ids"].squeeze(),
"chosen_attention_mask": chosen_enc["attention_mask"].squeeze(),
"rejected_input_ids": rejected_enc["input_ids"].squeeze(),
"rejected_attention_mask": rejected_enc["attention_mask"].squeeze(),
"metadata": example["metadata"]
}
class RLHFOptimizer:
"""基于人类反馈的强化学习优化器"""
def __init__(self,
base_model,
reward_model_path: Optional[str] = None,
learning_rate: float = 1e-5):
self.base_model = base_model
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化奖励模型
if reward_model_path and os.path.exists(reward_model_path):
self.reward_model = AutoModelForSequenceClassification.from_pretrained(
reward_model_path
).to(self.device)
else:
# 创建新的奖励模型
self.reward_model = self._create_reward_model()
self.reward_model.train()
# 优化器
self.optimizer = optim.AdamW(
self.reward_model.parameters(),
lr=learning_rate
)
# 损失函数
self.loss_fn = nn.CrossEntropyLoss()
# 偏好数据收集
self.preference_buffer = []
self.buffer_size = 1000
def _create_reward_model(self) -> nn.Module:
"""创建奖励模型"""
# 使用基础模型作为backbone
reward_model = AutoModelForSequenceClassification.from_pretrained(
self.base_model.config._name_or_path,
num_labels=1 # 回归任务,输出奖励分数
)
return reward_model
def collect_feedback(self,
prompt: str,
responses: List[str],
preferences: List[int],
metadata: Dict = None):
"""收集人类反馈"""
# preferences: 响应偏好的排名(0表示最优)
ranked_responses = sorted(
zip(responses, preferences),
key=lambda x: x[1]
)
# 生成偏好对
for i in range(len(ranked_responses)):
for j in range(i + 1, len(ranked_responses)):
chosen = ranked_responses[i][0]
rejected = ranked_responses[j][0]
self.preference_buffer.append({
"prompt": prompt,
"chosen": chosen,
"rejected": rejected,
"metadata": metadata or {},
"timestamp": datetime.now().isoformat()
})
# 保持缓冲区大小
if len(self.preference_buffer) > self.buffer_size:
self.preference_buffer = self.preference_buffer[-self.buffer_size:]
def train_reward_model(self,
epochs: int = 3,
batch_size: int = 8,
validation_split: float = 0.1) -> Dict:
"""训练奖励模型"""
if len(self.preference_buffer) < 10:
return {"status": "insufficient_data", "loss": 0.0}
# 准备数据集
dataset = PreferenceDataset(
self.preference_buffer,
tokenizer=AutoTokenizer.from_pretrained(self.base_model.config._name_or_path)
)
# 划分训练集和验证集
val_size = int(len(dataset) * validation_split)
train_size = len(dataset) - val_size
train_dataset, val_dataset = torch.utils.data.random_split(
dataset, [train_size, val_size]
)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False
)
# 训练循环
train_losses = []
val_losses = []
for epoch in range(epochs):
# 训练阶段
self.reward_model.train()
epoch_train_loss = 0
for batch in train_loader:
# 将数据移动到设备
chosen_input_ids = batch["chosen_input_ids"].to(self.device)
chosen_attention_mask = batch["chosen_attention_mask"].to(self.device)
rejected_input_ids = batch["rejected_input_ids"].to(self.device)
rejected_attention_mask = batch["rejected_attention_mask"].to(self.device)
# 前向传播
chosen_rewards = self.reward_model(
input_ids=chosen_input_ids,
attention_mask=chosen_attention_mask
).logits.squeeze()
rejected_rewards = self.reward_model(
input_ids=rejected_input_ids,
attention_mask=rejected_attention_mask
).logits.squeeze()
# 计算损失(chosen应该比rejected有更高的奖励)
# 使用Bradley-Terry模型
rewards_diff = chosen_rewards - rejected_rewards
labels = torch.ones_like(rewards_diff) # chosen总是更好
loss = -torch.mean(torch.log(torch.sigmoid(rewards_diff)))
# 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
epoch_train_loss += loss.item()
avg_train_loss = epoch_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 验证阶段
self.reward_model.eval()
epoch_val_loss = 0
with torch.no_grad():
for batch in val_loader:
chosen_input_ids = batch["chosen_input_ids"].to(self.device)
chosen_attention_mask = batch["chosen_attention_mask"].to(self.device)
rejected_input_ids = batch["rejected_input_ids"].to(self.device)
rejected_attention_mask = batch["rejected_attention_mask"].to(self.device)
chosen_rewards = self.reward_model(
input_ids=chosen_input_ids,
attention_mask=chosen_attention_mask
).logits.squeeze()
rejected_rewards = self.reward_model(
input_ids=rejected_input_ids,
attention_mask=rejected_attention_mask
).logits.squeeze()
rewards_diff = chosen_rewards - rejected_rewards
loss = -torch.mean(torch.log(torch.sigmoid(rewards_diff)))
epoch_val_loss += loss.item()
avg_val_loss = epoch_val_loss / len(val_loader) if val_loader else 0
val_losses.append(avg_val_loss)
print(f"Epoch {epoch+1}/{epochs}, "
f"Train Loss: {avg_train_loss:.4f}, "
f"Val Loss: {avg_val_loss:.4f}")
# 保存模型
self._save_reward_model()
return {
"status": "success",
"train_losses": train_losses,
"val_losses": val_losses,
"final_train_loss": train_losses[-1] if train_losses else 0,
"final_val_loss": val_losses[-1] if val_losses else 0,
"num_samples": len(self.preference_buffer)
}
def optimize_policy(self,
prompts: List[str],
current_policy,
num_iterations: int = 10,
samples_per_prompt: int = 4) -> Dict:
"""使用PPO优化策略"""
optimization_results = {
"iterations": [],
"avg_rewards": [],
"best_responses": [],
"improvement": 0.0
}
for iteration in range(num_iterations):
iteration_rewards = []
iteration_best_response = None
iteration_max_reward = -float('inf')
for prompt in prompts:
# 采样响应
responses = []
for _ in range(samples_per_prompt):
response = current_policy.generate(prompt)
responses.append(response)
# 计算奖励
rewards = []
for response in responses:
reward = self.evaluate_response(prompt, response)
rewards.append(reward)
if reward > iteration_max_reward:
iteration_max_reward = reward
iteration_best_response = response
# 使用PPO更新策略
self._ppo_update(current_policy, prompt, responses, rewards)
iteration_rewards.extend(rewards)
avg_reward = np.mean(iteration_rewards)
optimization_results["iterations"].append(iteration + 1)
optimization_results["avg_rewards"].append(float(avg_reward))
optimization_results["best_responses"].append(iteration_best_response)
print(f"Iteration {iteration+1}/{num_iterations}, "
f"Avg Reward: {avg_reward:.4f}")
if len(optimization_results["avg_rewards"]) > 1:
improvement = (optimization_results["avg_rewards"][-1] -
optimization_results["avg_rewards"][0])
optimization_results["improvement"] = float(improvement)
return optimization_results
def evaluate_response(self, prompt: str, response: str) -> float:
"""评估响应质量"""
self.reward_model.eval()
# 编码输入
tokenizer = AutoTokenizer.from_pretrained(self.base_model.config._name_or_path)
inputs = tokenizer(
prompt + " " + response,
truncation=True,
padding="max_length",
max_length=512,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
reward = self.reward_model(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"]
).logits.item()
return reward
def _ppo_update(self, policy, prompt, responses, rewards):
"""PPO算法更新策略"""
# 简化的PPO实现
# 在实际应用中需要更完整的实现
# 计算优势函数
rewards = torch.tensor(rewards, dtype=torch.float32)
advantages = rewards - rewards.mean()
# 计算新旧策略的概率比
# 这里简化处理,实际需要存储旧策略的概率
# 计算PPO损失
# 这里省略具体实现
# 更新策略
policy.optimizer.step()
def _save_reward_model(self, path: str = "models/reward_model"):
"""保存奖励模型"""
os.makedirs(os.path.dirname(path), exist_ok=True)
self.reward_model.save_pretrained(path)
print(f"Reward model saved to {path}")6.2 实验反馈分析器
# feedback/experiment_analyzer.py
import pandas as pd
import numpy as np
from typing import Dict, List, Any, Optional, Tuple
from scipy import stats
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import json
from datetime import datetime, timedelta
class ExperimentFeedbackAnalyzer:
"""实验反馈分析器"""
def __init__(self, experiment_tracker):
self.tracker = experiment_tracker
self.analysis_cache = {}
def analyze_experiment_outcomes(self,
time_period: Optional[Tuple[str, str]] = None,
researcher: Optional[str] = None) -> Dict:
"""分析实验成果"""
# 获取实验数据
experiments = self.tracker.get_experiment_history(
researcher=researcher
)
if not experiments:
return {"error": "No experiment data found"}
# 过滤时间周期
if time_period:
start_date, end_date = time_period
experiments = [
exp for exp in experiments
if start_date <= exp.get('started_at', '') <= end_date
]
analysis = {
"summary_stats": self._calculate_summary_stats(experiments),
"success_patterns": self._identify_success_patterns(experiments),
"failure_causes": self._analyze_failure_causes(experiments),
"researcher_performance": self._analyze_researcher_performance(experiments),
"temporal_trends": self._analyze_temporal_trends(experiments),
"recommendations": self._generate_recommendations(experiments)
}
return analysis
def _calculate_summary_stats(self, experiments: List[Dict]) -> Dict:
"""计算汇总统计"""
if not experiments:
return {}
successful = [exp for exp in experiments if exp.get('success')]
failed = [exp for exp in experiments if not exp.get('success')]
# 持续时间分析
durations = []
for exp in experiments:
if exp.get('duration_seconds'):
durations.append(exp['duration_seconds'])
return {
"total_experiments": len(experiments),
"successful": len(successful),
"failed": len(failed),
"success_rate": len(successful) / len(experiments) if experiments else 0,
"avg_duration_hours": np.mean(durations) / 3600 if durations else 0,
"median_duration_hours": np.median(durations) / 3600 if durations else 0,
"duration_std_hours": np.std(durations) / 3600 if durations else 0,
"avg_cost_usd": np.mean([exp.get('cost_usd', 0) for exp in experiments]),
"total_cost_usd": sum([exp.get('cost_usd', 0) for exp in experiments])
}
def _identify_success_patterns(self, experiments: List[Dict]) -> List[Dict]:
"""识别成功模式"""
successful_exps = [exp for exp in experiments if exp.get('success')]
if len(successful_exps) < 2:
return []
patterns = []
# 分析方法学模式
methodologies = {}
for exp in successful_exps:
method_key = json.dumps(exp.get('methodology', {}), sort_keys=True)
if method_key not in methodologies:
methodologies[method_key] = []
methodologies[method_key].append(exp)
# 找到重复使用的方法
for method_key, exps in methodologies.items():
if len(exps) >= 2: # 至少重复2次
pattern = {
"pattern_type": "methodology",
"methodology": exps[0].get('methodology', {}),
"occurrences": len(exps),
"success_rate": 1.0,
"avg_duration": np.mean([e.get('duration_seconds', 0) for e in exps]),
"example_experiments": [e.get('id') for e in exps[:3]]
}
patterns.append(pattern)
# 分析参数模式
parameter_patterns = self._cluster_parameters(successful_exps)
patterns.extend(parameter_patterns)
return sorted(patterns, key=lambda x: x.get('occurrences', 0), reverse=True)[:10]
def _analyze_failure_causes(self, experiments: List[Dict]) -> List[Dict]:
"""分析失败原因"""
failed_exps = [exp for exp in experiments if not exp.get('success')]
if not failed_exps:
return []
failure_causes = []
# 从结论中提取失败原因
for exp in failed_exps:
conclusion = exp.get('conclusion', '').lower()
# 常见失败原因关键词
failure_keywords = {
'timeout': ['timeout', '超时', 'time out'],
'resource': ['资源不足', 'out of memory', '内存不足', 'resource'],
'data': ['数据问题', 'data quality', '数据质量', 'insufficient data'],
'method': ['方法错误', 'incorrect method', '方法不适合'],
'implementation': ['实现错误', 'bug', 'error', '代码错误'],
'assumption': ['假设错误', 'incorrect assumption', '前提错误']
}
detected_causes = []
for cause, keywords in failure_keywords.items():
if any(keyword in conclusion for keyword in keywords):
detected_causes.append(cause)
if not detected_causes:
detected_causes = ['unknown']
failure_causes.append({
"experiment_id": exp.get('id'),
"causes": detected_causes,
"conclusion_excerpt": conclusion[:200]
})
# 统计失败原因频率
cause_counts = {}
for fc in failure_causes:
for cause in fc['causes']:
cause_counts[cause] = cause_counts.get(cause, 0) + 1
# 返回排序后的失败原因
sorted_causes = sorted(
cause_counts.items(),
key=lambda x: x[1],
reverse=True
)
return [
{"cause": cause, "count": count, "percentage": count/len(failed_exps)*100}
for cause, count in sorted_causes
]
def _analyze_researcher_performance(self, experiments: List[Dict]) -> Dict:
"""分析研究员表现"""
researcher_stats = {}
for exp in experiments:
researcher = exp.get('researcher', 'unknown')
if researcher not in researcher_stats:
researcher_stats[researcher] = {
"total": 0,
"successful": 0,
"durations": [],
"costs": []
}
stats = researcher_stats[researcher]
stats["total"] += 1
if exp.get('success'):
stats["successful"] += 1
if exp.get('duration_seconds'):
stats["durations"].append(exp['duration_seconds'])
if exp.get('cost_usd'):
stats["costs"].append(exp['cost_usd'])
# 计算详细指标
detailed_stats = {}
for researcher, stats in researcher_stats.items():
detailed_stats[researcher] = {
"total_experiments": stats["total"],
"success_rate": stats["successful"] / stats["total"] if stats["total"] > 0 else 0,
"avg_duration_hours": np.mean(stats["durations"]) / 3600 if stats["durations"] else 0,
"avg_cost_usd": np.mean(stats["costs"]) if stats["costs"] else 0,
"efficiency_score": self._calculate_efficiency_score(stats)
}
return detailed_stats
def _calculate_efficiency_score(self, stats: Dict) -> float:
"""计算效率分数"""
if stats["total"] == 0:
return 0.0
success_rate = stats["successful"] / stats["total"]
# 考虑平均持续时间(越短越好)
if stats["durations"]:
avg_duration = np.mean(stats["durations"])
# 归一化到0-1,假设最长实验时间为1周(604800秒)
duration_score = 1 - min(avg_duration / 604800, 1)
else:
duration_score = 0.5
# 考虑成本(越低越好)
if stats["costs"]:
avg_cost = np.mean(stats["costs"])
# 归一化到0-1,假设最高成本为10000美元
cost_score = 1 - min(avg_cost / 10000, 1)
else:
cost_score = 0.5
# 综合分数(成功率权重最高)
efficiency = 0.5 * success_rate + 0.3 * duration_score + 0.2 * cost_score
return efficiency
def _analyze_temporal_trends(self, experiments: List[Dict]) -> Dict:
"""分析时间趋势"""
if len(experiments) < 5:
return {}
# 按时间排序
sorted_exps = sorted(
experiments,
key=lambda x: x.get('started_at', '')
)
# 按周或月分组
weekly_groups = {}
for exp in sorted_exps:
start_date = exp.get('started_at', '').split('T')[0]
if start_date:
# 简化:按周分组
year_week = datetime.fromisoformat(start_date).strftime('%Y-%W')
if year_week not in weekly_groups:
weekly_groups[year_week] = []
weekly_groups[year_week].append(exp)
# 计算每周指标
weekly_metrics = []
for week, week_exps in sorted(weekly_groups.items()):
successful = len([e for e in week_exps if e.get('success')])
weekly_metrics.append({
"week": week,
"total": len(week_exps),
"successful": successful,
"success_rate": successful / len(week_exps) if week_exps else 0,
"avg_duration": np.mean([e.get('duration_seconds', 0) for e in week_exps])
})
# 趋势分析
if len(weekly_metrics) >= 3:
success_rates = [m["success_rate"] for m in weekly_metrics]
# 线性回归看趋势
x = np.arange(len(success_rates))
slope, intercept, r_value, p_value, std_err = stats.linregress(x, success_rates)
trends = {
"weekly_metrics": weekly_metrics,
"success_rate_trend": {
"slope": slope,
"trend": "improving" if slope > 0.01 else "declining" if slope < -0.01 else "stable",
"r_squared": r_value**2,
"last_4_weeks_avg": np.mean(success_rates[-4:]) if len(success_rates) >= 4 else 0
}
}
else:
trends = {"weekly_metrics": weekly_metrics}
return trends
def _generate_recommendations(self, experiments: List[Dict]) -> List[Dict]:
"""生成改进建议"""
recommendations = []
# 分析最近的失败
recent_failed = [
exp for exp in experiments[-20:] # 最近20个实验
if not exp.get('success')
]
if recent_failed:
# 建议1:审查方法学
recommendations.append({
"type": "methodology_review",
"priority": "high" if len(recent_failed) >= 3 else "medium",
"description": f"最近有 {len(recent_failed)} 个实验失败,建议审查实验方法学",
"suggested_actions": [
"组织方法学审查会议",
"与成功实验对比方法差异",
"考虑先进行小规模试点实验"
]
})
# 分析持续时间
durations = [exp.get('duration_seconds', 0) for exp in experiments[-10:]]
if durations and np.mean(durations) > 86400: # 超过24小时
recommendations.append({
"type": "duration_optimization",
"priority": "medium",
"description": "实验平均持续时间较长,考虑优化",
"suggested_actions": [
"分析实验瓶颈步骤",
"考虑并行化处理",
"优化资源分配"
]
})
# 分析研究员表现差异
researcher_stats = self._analyze_researcher_performance(experiments)
if len(researcher_stats) > 1:
success_rates = [s["success_rate"] for s in researcher_stats.values()]
if max(success_rates) - min(success_rates) > 0.3: # 成功率差异大
recommendations.append({
"type": "knowledge_sharing",
"priority": "medium",
"description": "研究员间表现差异较大,建议知识共享",
"suggested_actions": [
"组织经验分享会",
"建立最佳实践文档",
"实施结对编程/实验"
]
})
return recommendations系统集成与部署
7.1 主控制器与工作流编排
# main/research_assistant.py
import asyncio
from typing import Dict, List, Any, Optional
import json
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
class IntelligentResearchAssistant:
"""智能科研助手主控制器"""
def __init__(self, config_path: str = "config.yaml"):
# 加载配置
self.config = self._load_config(config_path)
# 初始化各个模块
self.perception = ResearchPaperPerception()
self.memory = ResearchKnowledgeMemory(
pinecone_api_key=self.config["pinecone"]["api_key"],
pinecone_env=self.config["pinecone"]["environment"],
neo4j_uri=self.config["neo4j"]["uri"],
neo4j_user=self.config["neo4j"]["user"],
neo4j_password=self.config["neo4j"]["password"]
)
# 初始化工具
self.tools = self._initialize_tools()
# 初始化决策引擎
self.decision_engine = ResearchPlanningAgent(
llm=self._initialize_llm(),
tools=self.tools,
memory_store=self.memory,
knowledge_store=self.memory
)
# 初始化行动模块
self.action_executor = ActionOrchestrator(
tools=self.tools,
report_generator=LaTeXReportGenerator()
)
# 初始化反馈模块
self.feedback_analyzer = ExperimentFeedbackAnalyzer(
experiment_tracker=ExperimentTracker()
)
# 工作流状态
self.current_workflow = None
self.workflow_history = []
async def start_research_workflow(self,
research_topic: str,
constraints: Optional[Dict] = None) -> Dict:
"""启动研究工作流"""
workflow_id = f"workflow_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
self.current_workflow = {
"id": workflow_id,
"topic": research_topic,
"status": "started",
"started_at": datetime.now().isoformat(),
"steps": [],
"results": {}
}
try:
# 步骤1:文献调研
literature_result = await self._conduct_literature_review(
research_topic, constraints
)
# 步骤2:研究规划
research_plan = await self.decision_engine.plan_experiment(
research_topic, constraints
)
# 步骤3:实验执行
experiment_results = await self._execute_experiments(
research_plan, constraints
)
# 步骤4:结果分析
analysis_results = await self._analyze_results(
experiment_results, research_plan
)
# 步骤5:报告生成
report = await self._generate_final_report(
research_topic, research_plan, experiment_results, analysis_results
)
# 步骤6:反馈学习
learning_outcomes = await self._learn_from_feedback(
research_plan, experiment_results, analysis_results
)
# 完成工作流
self.current_workflow.update({
"status": "completed",
"completed_at": datetime.now().isoformat(),
"literature_review": literature_result,
"research_plan": research_plan,
"experiment_results": experiment_results,
"analysis_results": analysis_results,
"report": report,
"learning_outcomes": learning_outcomes
})
# 保存到历史
self.workflow_history.append(self.current_workflow.copy())
return self.current_workflow
except Exception as e:
self.current_workflow.update({
"status": "failed",
"error": str(e),
"completed_at": datetime.now().isoformat()
})
raise
async def _conduct_literature_review(self,
topic: str,
constraints: Dict) -> Dict:
"""执行文献调研"""
# 搜索相关论文
search_results = self.memory.semantic_search(topic, top_k=50)
# 分析研究领域
domain_analysis = self.memory.get_research_context(topic)
# 提取关键论文
key_papers = []
for paper in search_results[:10]:
if paper.get("paper_id"):
key_papers.append({
"id": paper["paper_id"],
"title": paper.get("title", ""),
"relevance": paper.get("score", 0),
"key_findings": self._extract_key_findings(paper)
})
# 识别研究空白
research_gaps = self._identify_research_gaps(domain_analysis, key_papers)
return {
"topic": topic,
"search_results": search_results[:20],
"key_papers": key_papers,
"domain_analysis": domain_analysis,
"research_gaps": research_gaps,
"summary": self._generate_literature_summary(domain_analysis, research_gaps)
}
async def _execute_experiments(self,
research_plan: Dict,
constraints: Dict) -> Dict:
"""执行实验计划"""
experiment_results = {}
for experiment in research_plan.get("experiments", []):
exp_id = experiment.get("experiment_id")
# 生成详细步骤
detailed_steps = self.action_executor.generate_experiment_steps(
experiment, constraints
)
# 执行实验
exp_result = await self.action_executor.execute_experiment(
detailed_steps, constraints
)
# 记录结果
self.memory.store_experiment({
"experiment_id": exp_id,
"plan": experiment,
"steps": detailed_steps,
"results": exp_result,
"success": exp_result.get("success", False)
})
experiment_results[exp_id] = exp_result
return experiment_results
async def _analyze_results(self,
experiment_results: Dict,
research_plan: Dict) -> Dict:
"""分析实验结果"""
# 分析每个实验的结果
analyses = {}
for exp_id, result in experiment_results.items():
analysis = self.feedback_analyzer.analyze_experiment_result(
result, research_plan
)
analyses[exp_id] = analysis
# 综合所有实验结果
overall_analysis = self._synthesize_results(analyses, research_plan)
# 验证研究假设
hypothesis_validation = self._validate_hypotheses(
analyses, research_plan.get("hypotheses", [])
)
return {
"experiment_analyses": analyses,
"overall_analysis": overall_analysis,
"hypothesis_validation": hypothesis_validation,
"conclusions": self._draw_conclusions(overall_analysis, hypothesis_validation)
}
async def _generate_final_report(self,
topic: str,
research_plan: Dict,
experiment_results: Dict,
analysis_results: Dict) -> Dict:
"""生成最终报告"""
# 准备报告数据
report_data = {
"research_topic": topic,
"research_plan": research_plan,
"experiment_results": experiment_results,
"analysis_results": analysis_results,
"timestamp": datetime.now().isoformat()
}
# 生成报告
report = self.action_executor.generate_comprehensive_report(report_data)
# 保存报告
report_path = self._save_report(report, topic)
return {
"report_path": report_path,
"report_data": report,
"summary": self._generate_report_summary(report_data)
}
async def _learn_from_feedback(self,
research_plan: Dict,
experiment_results: Dict,
analysis_results: Dict) -> Dict:
"""从反馈中学习"""
# 收集反馈数据
feedback_data = self._collect_feedback_data(
research_plan, experiment_results, analysis_results
)
# 更新奖励模型
if self.config.get("enable_rlhf", False):
learning_result = self.feedback_analyzer.update_from_feedback(feedback_data)
else:
learning_result = {"status": "rlhf_disabled"}
# 更新知识库
knowledge_updates = self._update_knowledge_base(
research_plan, experiment_results, analysis_results
)
return {
"feedback_data": feedback_data,
"rlhf_update": learning_result,
"knowledge_updates": knowledge_updates,
"insights": self._extract_insights(analysis_results)
}
def _extract_key_findings(self, paper: Dict) -> List[str]:
"""提取论文关键发现"""
# 简化的实现,实际应该使用NLP技术
findings = []
if "abstract" in paper:
# 从摘要中提取关键句子
sentences = paper["abstract"].split('.')
findings.extend(sentences[:3]) # 取前三句
return findings
def _identify_research_gaps(self, domain_analysis: Dict, key_papers: List[Dict]) -> List[Dict]:
"""识别研究空白"""
gaps = []
# 基于引用分析找到未被充分研究的方向
for paper in key_papers:
# 检查相关研究数量
related_count = len(paper.get("citations", []))
if related_count < 10: # 引用较少的研究方向
gaps.append({
"area": paper.get("title", "未知领域"),
"paper_id": paper.get("id"),
"citation_count": related_count,
"reason": "该方向研究较少,有探索空间"
})
return gaps[:5] # 返回前5个研究空白部署与使用指南
8.1 环境配置
# config.yaml
# 基础配置
app:
name: "智能科研助手"
version: "1.0.0"
environment: "production" # development, staging, production
log_level: "INFO"
# 模型配置
models:
blip2:
model_name: "Salesforce/blip2-opt-2.7b"
device: "cuda" # or "cpu"
sentence_transformer:
model_name: "all-MiniLM-L6-v2"
llm:
provider: "qwen"
model_name: "Qwen-72B-Chat"
api_key: ${QWEN_API_KEY}
endpoint: "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 数据库配置
pinecone:
api_key: ${PINECONE_API_KEY}
environment: "us-west1-gcp"
index_name: "research-knowledge"
neo4j:
uri: "bolt://localhost:7687"
user: "neo4j"
password: ${NEO4J_PASSWORD}
database: "research"
# 工具配置
tools:
code_execution:
timeout: 300
memory_limit: "4G"
docker:
enabled: true
gpu_support: true
ssh:
enabled: false
hosts: []
# 监控配置
monitoring:
prometheus:
enabled: true
port: 9090
grafana:
enabled: true
port: 3000
# 存储配置
storage:
data_dir: "./data"
reports_dir: "./reports"
experiments_dir: "./experiments"
cache_dir: "./cache"8.2 Docker部署
# Dockerfile
FROM pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime
# 设置工作目录
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y \
git \
wget \
curl \
xz-utils \
file \
libgl1-mesa-glx \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
texlive-xetex \
texlive-latex-recommended \
texlive-fonts-recommended \
texlive-latex-extra \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件
COPY requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 创建必要的目录
RUN mkdir -p data reports experiments cache
# 暴露端口
EXPOSE 8000 9090
# 启动命令
CMD ["python", "-m", "main.api_server"]8.3 API服务
# main/api_server.py
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional, Dict, List
import uvicorn
from research_assistant import IntelligentResearchAssistant
app = FastAPI(
title="智能科研助手API",
description="AI驱动的自动化科研平台",
version="1.0.0"
)
# 初始化助手
assistant = None
@app.on_event("startup")
async def startup_event():
"""启动时初始化"""
global assistant
assistant = IntelligentResearchAssistant("config.yaml")
# 预热模型
await assistant.initialize()
class ResearchRequest(BaseModel):
topic: str
constraints: Optional[Dict] = None
researcher_id: Optional[str] = None
class ResearchResponse(BaseModel):
workflow_id: str
status: str
message: str
estimated_time: Optional[int] = None
@app.post("/research/start", response_model=ResearchResponse)
async def start_research(request: ResearchRequest, background_tasks: BackgroundTasks):
"""启动研究项目"""
try:
workflow_id = f"workflow_{uuid.uuid4().hex[:8]}"
# 在后台执行研究任务
background_tasks.add_task(
run_research_workflow,
workflow_id,
request.topic,
request.constraints or {},
request.researcher_id
)
return ResearchResponse(
workflow_id=workflow_id,
status="started",
message="研究任务已启动,正在后台执行",
estimated_time=3600 # 估计1小时
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/research/status/{workflow_id}")
async def get_research_status(workflow_id: str):
"""获取研究状态"""
if assistant is None:
raise HTTPException(status_code=503, detail="Assistant not initialized")
workflow = assistant.get_workflow(workflow_id)
if not workflow:
raise HTTPException(status_code=404, detail="Workflow not found")
return workflow
@app.get("/research/results/{workflow_id}")
async def get_research_results(workflow_id: str):
"""获取研究结果"""
if assistant is None:
raise HTTPException(status_code=503, detail="Assistant not initialized")
results = assistant.get_results(workflow_id)
if not results:
raise HTTPException(status_code=404, detail="Results not found")
return results
@app.post("/feedback/provide")
async def provide_feedback(feedback_data: Dict):
"""提供反馈"""
if assistant is None:
raise HTTPException(status_code=503, detail="Assistant not initialized")
try:
assistant.collect_feedback(feedback_data)
return {"status": "success", "message": "Feedback collected"}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
async def run_research_workflow(workflow_id: str, topic: str, constraints: Dict, researcher_id: Optional[str]):
"""运行研究工作流(后台任务)"""
try:
result = await assistant.start_research_workflow(
topic,
constraints,
researcher_id
)
# 保存结果
assistant.save_workflow_result(workflow_id, result)
except Exception as e:
# 记录错误
assistant.log_error(workflow_id, str(e))
if __name__ == "__main__":
uvicorn.run(
app,
host="0.0.0.0",
port=8000,
log_level="info"
)性能优化与扩展
9.1 缓存优化
# utils/cache_manager.py
import redis
import pickle
from functools import wraps
from typing import Any, Callable, Optional
import hashlib
import json
class ResearchCacheManager:
"""研究缓存管理器"""
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis_client = redis.from_url(redis_url)
self.default_ttl = 3600 # 1小时
def cache_result(self,
func: Callable,
ttl: Optional[int] = None) -> Callable:
"""缓存装饰器"""
@wraps(func)
async def wrapper(*args, **kwargs):
# 生成缓存键
cache_key = self._generate_cache_key(func, args, kwargs)
# 尝试从缓存获取
cached = self.redis_client.get(cache_key)
if cached:
return pickle.loads(cached)
# 执行函数
result = await func(*args, **kwargs)
# 缓存结果
self.redis_client.setex(
cache_key,
ttl or self.default_ttl,
pickle.dumps(result)
)
return result
return wrapper
def _generate_cache_key(self,
func: Callable,
args: tuple,
kwargs: dict) -> str:
"""生成缓存键"""
key_parts = [
func.__module__,
func.__name__,
str(args),
json.dumps(kwargs, sort_keys=True)
]
key_string = ":".join(key_parts)
return f"research:{hashlib.md5(key_string.encode()).hexdigest()}"
def invalidate_pattern(self, pattern: str):
"""使匹配模式的缓存失效"""
keys = self.redis_client.keys(pattern)
if keys:
self.redis_client.delete(*keys)9.2 异步处理优化
# utils/async_executor.py
import asyncio
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from typing import List, Any, Callable, Optional
import functools
class AsyncResearchExecutor:
"""异步研究执行器"""
def __init__(self,
max_workers: int = 4,
use_processes: bool = False):
self.max_workers = max_workers
self.use_processes = use_processes
if use_processes:
self.executor = ProcessPoolExecutor(max_workers=max_workers)
else:
self.executor = ThreadPoolExecutor(max_workers=max_workers)
async def parallel_execute(self,
tasks: List[Callable],
task_args: List[tuple]) -> List[Any]:
"""并行执行任务"""
loop = asyncio.get_event_loop()
# 准备异步任务
async_tasks = []
for task, args in zip(tasks, task_args):
if asyncio.iscoroutinefunction(task):
# 已经是异步函数
async_tasks.append(task(*args))
else:
# 同步函数,在线程池中执行
async_tasks.append(
loop.run_in_executor(
self.executor,
functools.partial(task, *args)
)
)
# 并行执行
results = await asyncio.gather(*async_tasks, return_exceptions=True)
# 处理异常
processed_results = []
for result in results:
if isinstance(result, Exception):
# 记录异常并返回None
print(f"Task failed: {result}")
processed_results.append(None)
else:
processed_results.append(result)
return processed_results
async def pipeline_execute(self,
pipeline: List[Callable],
initial_input: Any) -> Any:
"""流水线执行任务"""
current_result = initial_input
for task in pipeline:
if asyncio.iscoroutinefunction(task):
current_result = await task(current_result)
else:
loop = asyncio.get_event_loop()
current_result = await loop.run_in_executor(
self.executor,
functools.partial(task, current_result)
)
if current_result is None:
break
return current_result总结与展望
10.1 系统优势
核心技术优势:
-
多模态理解能力:结合文本、图表、代码的综合分析
-
自主研究规划:从文献调研到实验设计的完整自动化
-
持续学习进化:基于反馈的RLHF优化机制
-
知识积累传承:构建领域知识图谱和实验记忆库
应用价值:
-
研究效率提升:自动化重复性工作,加速研究进程
-
发现新知识:通过模式识别发现人类忽略的关联
-
降低门槛:使非专业人士也能进行高质量研究
-
促进协作:标准化研究流程,便于团队协作
10.2 未来扩展方向
短期扩展(3-6个月):
-
更多领域适配:扩展到材料科学、社会科学等领域
-
云原生部署:Kubernetes集群部署,弹性伸缩
-
移动端支持:开发移动应用,随时随地进行研究
中期规划(6-12个月):
-
多智能体协作:多个研究助手分工协作
-
跨语言支持:支持多语言文献和报告
长期愿景(1-3年):
-
通用科研AI:实现跨学科的通用研究能力
-
科学发现自动化:完全自主的科学发现系统
-
人机共生研究:形成人类与AI协同研究的全新范式
10.3 部署建议
硬件要求:
-
GPU服务器:至少2块NVIDIA A100(80GB)
-
内存:512GB RAM
-
存储:10TB NVMe SSD
-
网络:10GbE网络连接
软件要求:
-
操作系统:Ubuntu 20.04 LTS+
-
容器:Docker 20.10+, Kubernetes 1.24+
-
数据库:Redis 7.0+, Neo4j 5.0+
团队配置:
-
AI研究员:2-3人,负责模型优化
-
后端工程师:2-3人,负责系统开发
-
领域专家:1-2人,负责领域知识注入
-
运维工程师:1-2人,负责部署和维护
这个智能科研助手系统代表了AI在科学研究领域的前沿应用,通过将感知、记忆、决策、行动、反馈五大能力有机结合,为研究者提供了一个强大的AI协作者。随着技术的不断发展和完善,它有望成为推动科学进步的重要力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)