【AI课程领学】第九课 · 激活函数(课时2) Tanh:零均值优势与饱和问题并存(含对比实验代码)
【AI课程领学】第九课 · 激活函数(课时2) Tanh:零均值优势与饱和问题并存(含对比实验代码)
·
【AI课程领学】第九课 · 激活函数(课时2) Tanh:零均值优势与饱和问题并存(含对比实验代码)
【AI课程领学】第九课 · 激活函数(课时2) Tanh:零均值优势与饱和问题并存(含对比实验代码)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
Tanh 是 Sigmoid 的“中心化版本”。早期神经网络、尤其 RNN 中,tanh 曾经是默认激活,因为它输出是 零均值,比 Sigmoid 更利于优化。但它仍然有饱和区,因此在深层前馈网络中依旧会遇到梯度消失。
1. tanh 的定义与性质
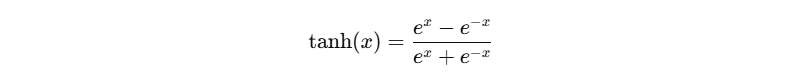
- 值域:(-1, 1),并且是奇函数(对称)。
2. tanh 的导数
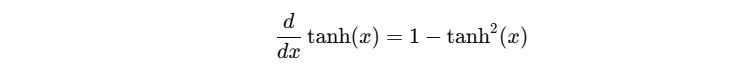
- 当 ∣ x ∣ ∣x∣ ∣x∣ 很大时,tanh(x) 接近 ±1,导数接近 0 → 饱和。
3. 相比 Sigmoid,tanh 的优势:零均值更利于梯度下降
- Sigmoid 输出在 (0,1),均值偏正,会导致梯度在更新方向上产生“偏移”,优化更慢。
- tanh 输出在 (-1,1),更接近零均值,通常收敛更快(尤其在没有 BN/LN 的时代)。
4. 现代使用场景
- RNN/LSTM 的候选状态常用 tanh
- 一些生成模型输出在 [-1,1] 时会用 tanh(例如图像生成后再反归一化)
5. Python:画 tanh 与导数
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 400)
t = np.tanh(x)
dt = 1 - t**2
plt.figure()
plt.plot(x, t)
plt.title("tanh(x)")
plt.show()
plt.figure()
plt.plot(x, dt)
plt.title("tanh'(x)")
plt.show()
6. PyTorch 对比实验:tanh vs sigmoid(收敛速度)
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(0)
X = torch.randn(512, 10)
y = (X.sum(dim=1) > 0).long()
class MLP(nn.Module):
def __init__(self, act):
super().__init__()
self.fc1 = nn.Linear(10, 64)
self.fc2 = nn.Linear(64, 2)
self.act = act
def forward(self, x):
x = self.act(self.fc1(x))
return self.fc2(x)
def train(act_fn, epochs=50):
model = MLP(act_fn)
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
for e in range(epochs):
logits = model(X)
loss = F.cross_entropy(logits, y)
opt.zero_grad()
loss.backward()
opt.step()
return loss.item()
print("sigmoid:", train(torch.sigmoid))
print("tanh:", train(torch.tanh))
print("relu:", train(F.relu))
- 一般情况下,你会看到 relu 最容易训,tanh 往往优于 sigmoid。
7. 小结
- tanh 比 sigmoid 更适合隐藏层(零均值)
- 但仍会饱和,深层网络仍可能梯度消失
- 现代前馈网络更偏向 ReLU 系列

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)