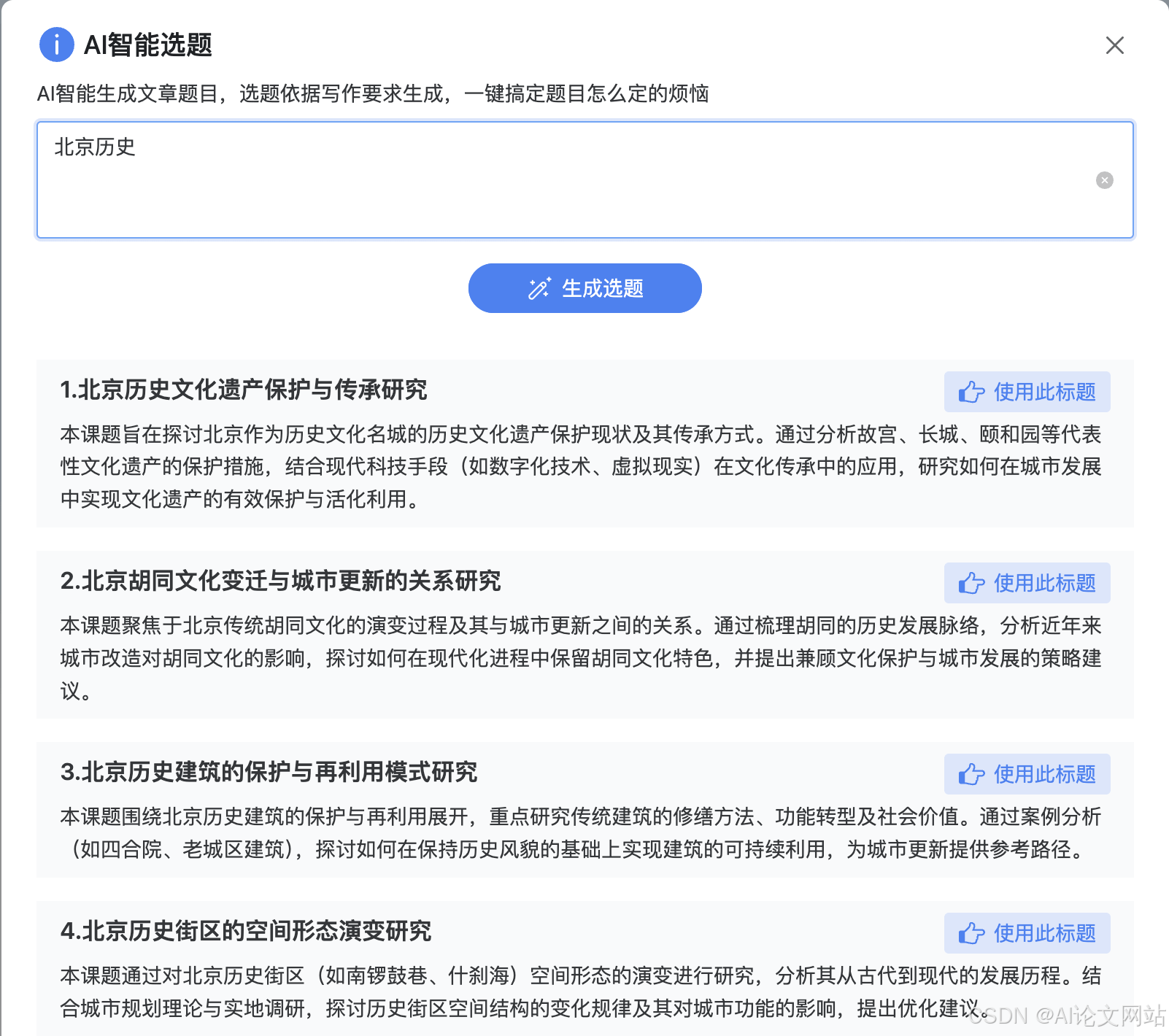
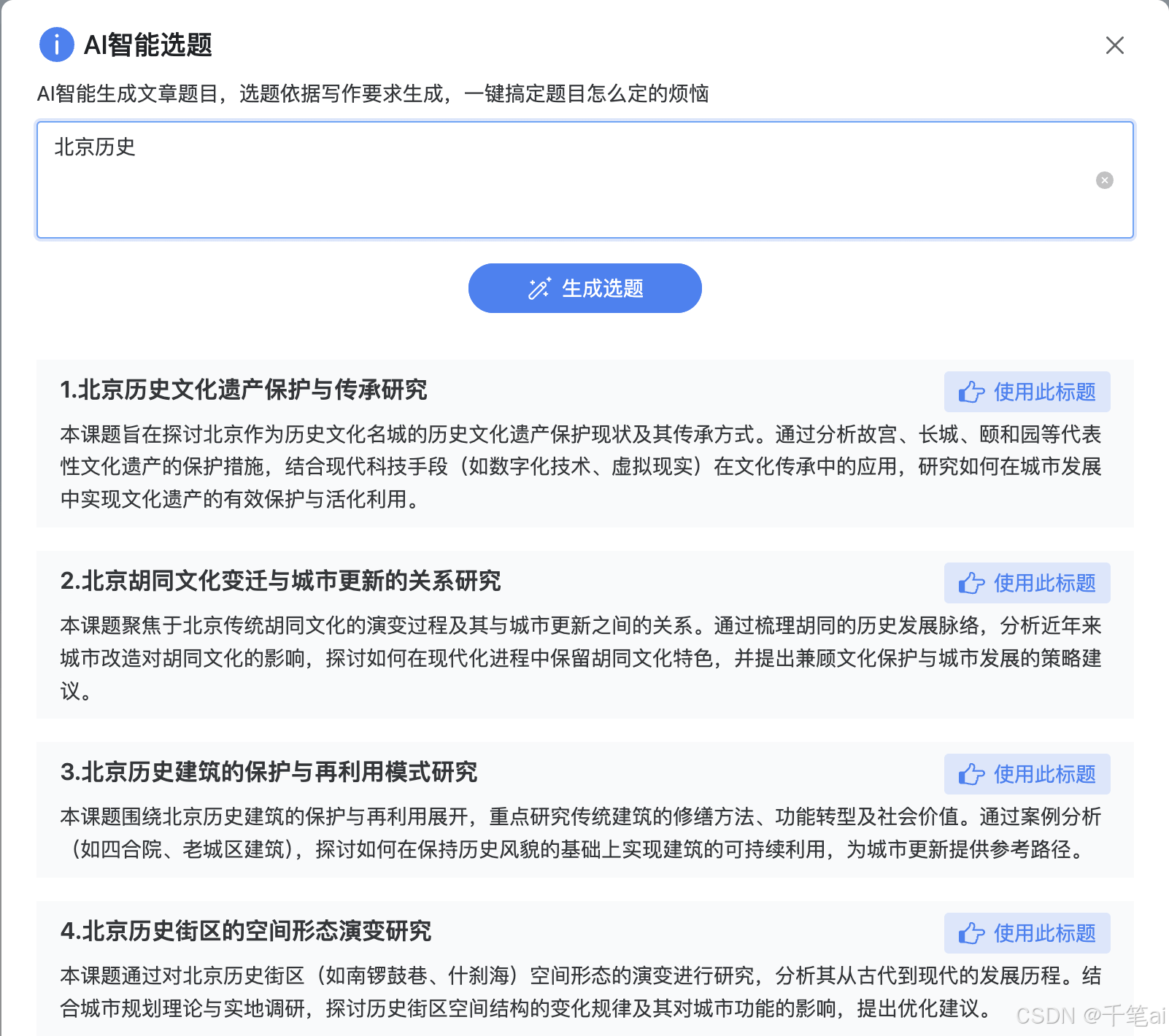
AI写作工具测评:谁是最强创作助手?
选取3-5款主流工具(如GPT-4、Claude、文心一言),对比其在技术写作、营销文案、教育辅导等场景的表现差异。:自然语言处理能力(语法纠错、风格模仿、创意生成)、多语言支持、响应速度、API稳定性。:通过标准化文本生成任务(如新闻稿、诗歌、技术报告)统计准确率、流畅度、耗时等指标。:模板丰富度、格式适配性(学术/商业/创意)、协作功能、多模态输出(图文结合)。:邀请专业作家、编辑和普通用户进
·
引言
AI写作助手的快速发展催生了对其性能、功能和应用场景的深度测评需求。测评大会旨在系统评估主流AI写作工具的技术能力、用户体验和行业适用性。
测评框架设计
技术维度:自然语言处理能力(语法纠错、风格模仿、创意生成)、多语言支持、响应速度、API稳定性。
功能维度:模板丰富度、格式适配性(学术/商业/创意)、协作功能、多模态输出(图文结合)。
伦理与安全:内容原创性检测、偏见过滤、隐私保护机制。
测评方法
定量测试:通过标准化文本生成任务(如新闻稿、诗歌、技术报告)统计准确率、流畅度、耗时等指标。
定性评估:邀请专业作家、编辑和普通用户进行盲测,评估内容的逻辑性、情感表达和实用性。
压力测试:高并发请求下的系统稳定性及长文本连贯性分析。
核心测评指标
- 语言模型性能:基于BLEU、ROUGE等算法评估文本质量。
- 用户体验:界面友好度、自定义选项、学习成本。
- 商业化能力:API接入成本、企业级功能(如品牌风格定制)。
典型案例分析
选取3-5款主流工具(如GPT-4、Claude、文心一言),对比其在技术写作、营销文案、教育辅导等场景的表现差异。
挑战与改进方向
- 技术瓶颈:长文本逻辑一致性、领域专业知识不足。
- 伦理争议:版权归属、AI内容标识的透明度。
- 未来趋势:个性化模型微调、实时协作功能的优化。
结论与建议
综合测评数据提出工具选型指南,并呼吁行业建立标准化测评体系以推动技术健康发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)