GeoShapley论文详细解析:一种度量机器学习模型空间效应的博弈论方法
原文:GeoShapley: A Game Theory Approach to Measuring Spatial Effects in Machine Learning Models随着机器学习(ML)和人工智能(AI)在地理空间现象建模中的广泛应用,其在处理海量异质数据、捕捉复杂结构方面的优势日益凸显。然而,机器学习模型的“黑箱”特性严重阻碍了其在科学发现中的应用——地理学家更关注模型的可解
GeoShapley论文详细解析:一种度量机器学习模型空间效应的博弈论方法
原文:GeoShapley: A Game Theory Approach to Measuring Spatial Effects in Machine Learning Models
引言
随着机器学习(ML)和人工智能(AI)在地理空间现象建模中的广泛应用,其在处理海量异质数据、捕捉复杂结构方面的优势日益凸显。然而,机器学习模型的“黑箱”特性严重阻碍了其在科学发现中的应用——地理学家更关注模型的可解释性,以理解地理空间现象背后的关系和过程。
可解释人工智能(XAI)的发展为解决这一问题提供了思路,其中SHAP(Shapley Additive Explanations)方法因其理论严谨性被广泛应用。但现有XAI方法在地理空间数据建模中存在两大痛点:
- 仅支持树模型的交互效应计算,无法适配神经网络等新兴地理空间建模架构;
- 未将地理位置特征(如经纬度、位置嵌入)视为一个联合变量,破坏了Shapley值的理论特性。
为此,本文提出GeoShapley方法,通过扩展博弈论中的Shapley值框架,实现对任意机器学习模型空间效应的度量。本文将从论文各核心部分展开详细解析,重点聚焦方法论设计与实验验证。
1. 研究背景与相关工作
1.1 地理空间建模的现状与挑战
机器学习在地理空间领域的应用场景包括:
- 土地覆盖分类(Camps-Valls et al. 2014)
- 天气预报(Espeholt et al. 2022)
- 交通预测(Derrow-Pinion et al. 2021)
- 目标检测(W. Li and Hsu 2020)
这些应用的核心优势是预测精度,但地理学家更关注“解释性”——即空间效应(如空间自相关、空间异质性)的量化与解读。传统空间统计模型(如GWR、MGWR)虽可解释,但存在线性假设、模型设定复杂、计算开销大等问题。
1.2 可解释人工智能(XAI)相关方法
1.2.1 全局解释方法
- 置换特征重要性(Permutation Feature Importance):通过移除/扰动特征评估其对模型精度的影响(Breiman 2001),但仅能提供全局平均重要性,无法反映局部差异。
- 部分依赖图(Partial Dependence Plots):展示特征与预测结果的边际关系(Friedman 2001),但无法捕捉特征交互。
1.2.2 局部解释方法
- LIME(Locally Interpretable Model-agnostic Explanations):将复杂模型在局部近似为线性模型(Ribeiro et al. 2016),但存在局部邻域定义模糊的问题。
- SHAP:基于博弈论Shapley值,将预测结果分解为各特征的边际贡献(Lundberg and Lee 2017),统一了LIME等多种方法。其优势在于:
- 满足有效性、对称性、零玩家、可加性四大公理;
- 支持局部和全局解释;
- 已集成到Google Vertex、Amazon SageMaker等平台。
1.2.3 SHAP在地理空间中的局限性
- 模型依赖性:仅树模型(如XGBoost、随机森林)支持交互效应计算,无法适配神经网络、SVM等模型;
- 位置特征处理不当:将经纬度等位置特征拆分为独立变量,违反Shapley值“玩家独立性”假设(Harris et al. 2021);
- 空间效应解释不明确:未区分“内在位置效应”和“位置-特征交互效应”。
2. 方法论:GeoShapley的设计与实现
2.1 核心思想
GeoShapley的核心创新是将位置特征视为一个联合玩家,扩展Shapley值框架以支持:
- 内在位置效应(Intrinsic Location Effect):位置本身对预测结果的贡献;
- 非空间效应(Non-spatial Effect):位置不变的特征边际贡献;
- 位置-特征交互效应(Location-Feature Interaction Effect):空间异质性(如GWR中的空间变系数)。
2.2 理论基础:Shapley值回顾
Shapley值源于合作博弈论,用于公平分配联盟游戏中各玩家的贡献。对于包含ppp个玩家(特征)的模型,玩家jjj的Shapley值为:
φj=∑S⊆M\{j}s!(p−s−1)!p!(f(S∪{j})−f(S))\varphi_{j}=\sum_{S \subseteq M \backslash\{j\}} \frac{s !(p-s-1) !}{p !}(f(S \cup\{j\})-f(S))φj=S⊆M\{j}∑p!s!(p−s−1)!(f(S∪{j})−f(S))
其中:
- MMM:所有玩家集合;
- SSS:不含玩家jjj的子集(大小为sss);
- f(S)f(S)f(S):子集SSS的游戏结果(模型预测值)。
Shapley值的关键特性:
- 有效性:所有玩家贡献之和等于总结果;
- 对称性:边际贡献相同的玩家具有相同Shapley值;
- 零玩家:对所有子集无边际贡献的玩家Shapley值为0;
- 可加性:复合游戏的Shapley值等于各子游戏Shapley值之和。
示例:三玩家Shapley值计算
假设玩家A、B、C的联盟结果如下表:
| Game | Player set S | Outcome f(S) |
|---|---|---|
| 1 | None | 0 |
| 2 | A | 5 |
| 3 | B | 10 |
| 4 | C | 100 |
| 5 | A,B | 5 |
| 6 | A,C | 120 |
| 7 | B,C | 140 |
| 8 | A,B,C | 150 |
根据公式计算A的Shapley值:
φA=f(A)−f(None)3+f(A,B)−f(B)6+f(A,C)−f(C)6+f(A,B,C)−f(B,C)3=53+−56+206+103=7.5\begin{aligned} \varphi_{A}= & \frac{f(A)-f(None)}{3}+\frac{f(A,B)-f(B)}{6}+\frac{f(A,C)-f(C)}{6}+\frac{f(A,B,C)-f(B,C)}{3} \\ = & \frac{5}{3}+\frac{-5}{6}+\frac{20}{6}+\frac{10}{3}=7.5 \end{aligned}φA==3f(A)−f(None)+6f(A,B)−f(B)+6f(A,C)−f(C)+3f(A,B,C)−f(B,C)35+6−5+620+310=7.5
同理可得φB=20\varphi_B=20φB=20,φC=122.5\varphi_C=122.5φC=122.5,验证了有效性(7.5+20+122.5=1507.5+20+122.5=1507.5+20+122.5=150)。
2.3 GeoShapley的数学定义
GeoShapley扩展了联合Shapley值(Joint Shapley Value)和Shapley交互值(Shapley Interaction Value),定义了三个核心组件:
2.3.1 1. 内在位置效应(ϕGEO\phi_{GEO}ϕGEO)
将位置特征(如经纬度、位置嵌入)视为一个联合玩家GEOGEOGEO(大小为ggg),其边际贡献为:
ϕGEO=∑S⊆M\{GEO}s!(p−s−g)!(p−g+1)!(f(S∪{GEO})−f(S))\phi_{GEO}=\sum_{S \subseteq M \backslash\{GEO\}} \frac{s !(p-s-g) !}{(p-g+1) !}(f(S \cup\{GEO\})-f(S))ϕGEO=S⊆M\{GEO}∑(p−g+1)!s!(p−s−g)!(f(S∪{GEO})−f(S))
- 当g=1g=1g=1时,退化为普通Shapley值;
- 当g=2g=2g=2时(经纬度),联合处理位置特征,避免拆分导致的理论冲突;
- 物理意义:类似GWR中的局部截距,量化位置本身的固有价值。
2.3.2 2. 非空间效应(ϕj\phi_jϕj)
非位置特征xjx_jxj的位置不变边际贡献,与传统Shapley值定义一致:
ϕj=∑S⊆M\{j}s!(p−s−g)!(p−g+1)!(f(S∪{j})−f(S))\phi_{j}=\sum_{S \subseteq M \backslash\{j\}} \frac{s !(p-s-g) !}{(p-g+1) !}(f(S \cup\{j\})-f(S))ϕj=S⊆M\{j}∑(p−g+1)!s!(p−s−g)!(f(S∪{j})−f(S))
- 物理意义:类似线性回归系数,量化特征的全局平均效应。
2.3.3 3. 位置-特征交互效应(ϕ(GEO,j)\phi_{(GEO,j)}ϕ(GEO,j))
基于Shapley交互值,量化位置与特征xjx_jxj的协同效应:
ϕ(GEO,j)=∑S⊆M\{GEO,j}s!(p−s−g−1)!(p−g+1)!Δ{GEO,j}Δ{GEO,j}=f(S∪{GEO,j})−f(S∪{GEO})−f(S∪{j})+f(S)\begin{gathered} \phi_{(GEO, j)}=\sum_{S \subseteq M \backslash\{GEO, j\}} \frac{s !(p-s-g-1) !}{(p-g+1) !} \Delta_{\{GEO, j\}} \\ \Delta_{\{GEO, j\}}=f(S \cup\{GEO, j\})-f(S \cup\{GEO\})-f(S \cup\{j\})+f(S) \end{gathered}ϕ(GEO,j)=S⊆M\{GEO,j}∑(p−g+1)!s!(p−s−g−1)!Δ{GEO,j}Δ{GEO,j}=f(S∪{GEO,j})−f(S∪{GEO})−f(S∪{j})+f(S)
- 物理意义:类似GWR中的空间变系数,量化特征效应的空间异质性。
2.3.4 4. 预测结果分解
GeoShapley满足有效性,预测结果可分解为:
y^=ϕ0+ϕGEO+∑j=1p−gϕj+∑j=1p−gϕ(GEO,j)\hat{y}=\phi_{0}+\phi_{GEO}+\sum_{j=1}^{p-g} \phi_{j}+\sum_{j=1}^{p-g} \phi_{(GEO, j)}y^=ϕ0+ϕGEO+j=1∑p−gϕj+j=1∑p−gϕ(GEO,j)
其中:
- ϕ0\phi_0ϕ0:基准值(背景数据的平均预测值);
- 若模型无空间效应,则ϕGEO=ϕ(GEO,j)=0\phi_{GEO}=\phi_{(GEO,j)}=0ϕGEO=ϕ(GEO,j)=0,退化为传统SHAP。
2.4 高效估计方法
传统Shapley值计算复杂度为O(2p)O(2^p)O(2p),无法处理高维数据。GeoShapley基于Kernel SHAP进行扩展,通过加权最小二乘求解:
ϕi=(ZTWZ)−1ZTWv\phi_{i}=\left(Z^{T} W Z\right)^{-1} Z^{T} W vϕi=(ZTWZ)−1ZTWv
关键改进:二进制矩阵ZZZ的重构
- 原始Kernel SHAP的ZZZ维度为2p×(p+1)2^p \times (p+1)2p×(p+1);
- GeoShapley中,位置特征联合处理,ZZZ维度变为2p−g+1×(2(p−g)+1)2^{p-g+1} \times (2(p-g)+1)2p−g+1×(2(p−g)+1),大幅降低计算量。
示例:p=4p=4p=4(2个位置特征GEOGEOGEO,2个非位置特征X1,X2X1,X2X1,X2),ZZZ矩阵结构如下:
| Feature set | X1 | X2 | X1,GEO | X2,GEO | GEO | Intercept |
|---|---|---|---|---|---|---|
| None | 0 | 0 | 0 | 0 | 0 | 1 |
| X1 | 1 | 0 | 0 | 0 | 0 | 1 |
| X2 | 0 | 1 | 0 | 0 | 0 | 1 |
| GEO | 0 | 0 | 0 | 0 | 1 | 1 |
| X1,GEO | 1 | 0 | 1 | 0 | 1 | 1 |
| X2,GEO | 0 | 1 | 0 | 1 | 1 | 1 |
| X1,X2 | 1 | 1 | 0 | 0 | 0 | 1 |
| X1,X2,GEO | 1 | 1 | 1 | 1 | 1 | 1 |
背景数据集选择
- 小数据集:使用全量数据;
- 大数据集:使用K-means聚类的代表性样本(如50个),平衡方差与计算效率(附录B验证了50个样本即可使方差趋于稳定)。
2.5 Python工具包实现
GeoShapley已开源为Python包geoshapley,特性如下:
- 安装:
pip install geoshapley; - 兼容主流ML库:scikit-learn、XGBoost、TabNet;
- 可视化工具:支持空间效应(热力图)、非空间效应(部分依赖图)、交互效应(空间变系数图);
- 代码仓库:https://github.com/Ziqi-Li/geoshapley(含复现论文结果的数据集和代码)。
3. 实验验证:模拟数据实验
3.1 实验设计
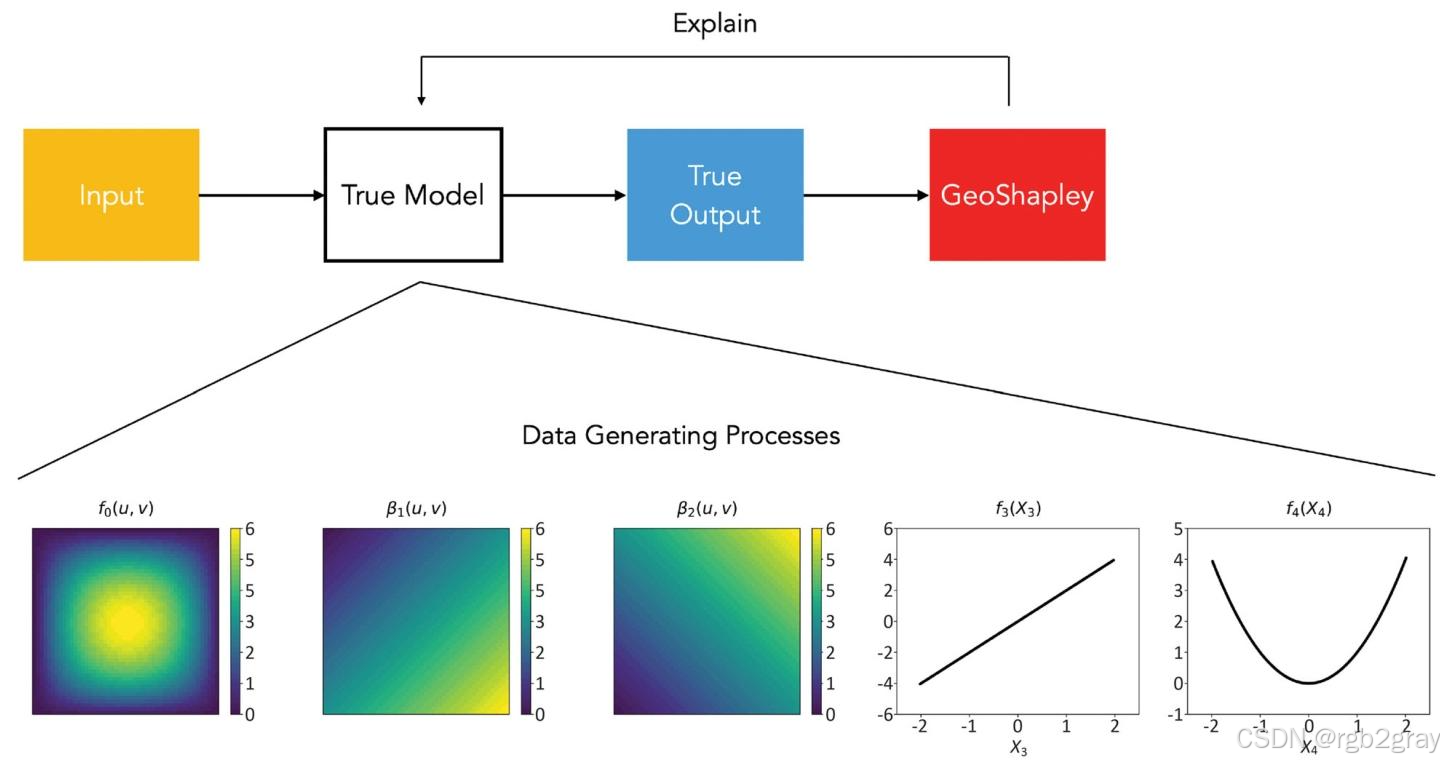
为验证GeoShapley的解释准确性,设计含已知空间/非空间效应的数据生成过程(DGP):
空间效应
- 内在位置效应:f0(u,v)=6124[12.52−(12.5−u2)2][12.52−(12.5−v2)2]f_0(u,v)=\frac{6}{12^4}[12.5^2-(12.5-\frac{u}{2})^2][12.5^2-(12.5-\frac{v}{2})^2]f0(u,v)=1246[12.52−(12.5−2u)2][12.52−(12.5−2v)2](u,v∈[0,49]u,v \in [0,49]u,v∈[0,49],50×50网格,2500个样本);
- 位置-特征交互效应:
- f1(X1,u,v)=β1(u,v)⋅X1f_1(X_1,u,v)=\beta_1(u,v) \cdot X_1f1(X1,u,v)=β1(u,v)⋅X1,β1(u,v)=349(u+v)\beta_1(u,v)=\frac{3}{49(u+v)}β1(u,v)=49(u+v)3;
- f2(X2,u,v)=β2(u,v)⋅X2f_2(X_2,u,v)=\beta_2(u,v) \cdot X_2f2(X2,u,v)=β2(u,v)⋅X2,β2(u,v)=349((49−u)+v)\beta_2(u,v)=\frac{3}{49((49-u)+v)}β2(u,v)=49((49−u)+v)3。
非空间效应
- 线性效应:f3(X3)=2X3f_3(X_3)=2X_3f3(X3)=2X3;
- 非线性效应:f4(X4)=X42f_4(X_4)=X_4^2f4(X4)=X42。
最终标签:y=f0+f1+f2+f3+f4+ϵy=f_0+f_1+f_2+f_3+f_4+\epsilony=f0+f1+f2+f3+f4+ϵ(ϵ∼N(0,1)\epsilon \sim N(0,1)ϵ∼N(0,1))。
3.2 验证指标
- 解释准确性:GeoShapley分解结果与真实DGP的匹配程度;
- 模型兼容性:验证7种不同结构模型的解释效果:
- 统计模型:线性回归(LR)、多尺度地理加权回归(MGWR);
- 机器学习模型:随机森林(RF)、XGBoost、支持向量机(SVM)、高斯过程(GP)、神经网络(NN)。
3.3 实验结果
3.3.1 模型预测精度
| 模型 | 样本外R2R^2R2 |
|---|---|
| LR | 0.757 |
| RF | 0.906 |
| MGWR | 0.943 |
| XGBoost | 0.964 |
| SVM | 0.969 |
| GP | 0.971 |
| NN | 0.971 |
| 真实R2R^2R2 | 0.975 |
- LR因无法捕捉空间/非线性效应表现最差;
- 机器学习模型(尤其是SVM、GP、NN)接近真实R2R^2R2,验证了其捕捉复杂效应的能力。
3.3.2 GeoShapley解释准确性
-
真实模型验证:直接对DGP计算GeoShapley,分解结果与真实效应完全匹配(图4):
- ϕGEO+ϕ0\phi_{GEO}+\phi_0ϕGEO+ϕ0 完美复现 f0(u,v)f_0(u,v)f0(u,v);
- β^j=ϕj+ϕ(GEO,j)Xj−E(Xj)\hat{\beta}_j=\frac{\phi_j+\phi_{(GEO,j)}}{X_j-E(X_j)}β^j=Xj−E(Xj)ϕj+ϕ(GEO,j) 完美复现 β1(u,v)\beta_1(u,v)β1(u,v) 和 β2(u,v)\beta_2(u,v)β2(u,v);
- ϕ3\phi_3ϕ3 对应 2X32X_32X3,ϕ4\phi_4ϕ4 对应 X42X_4^2X42。
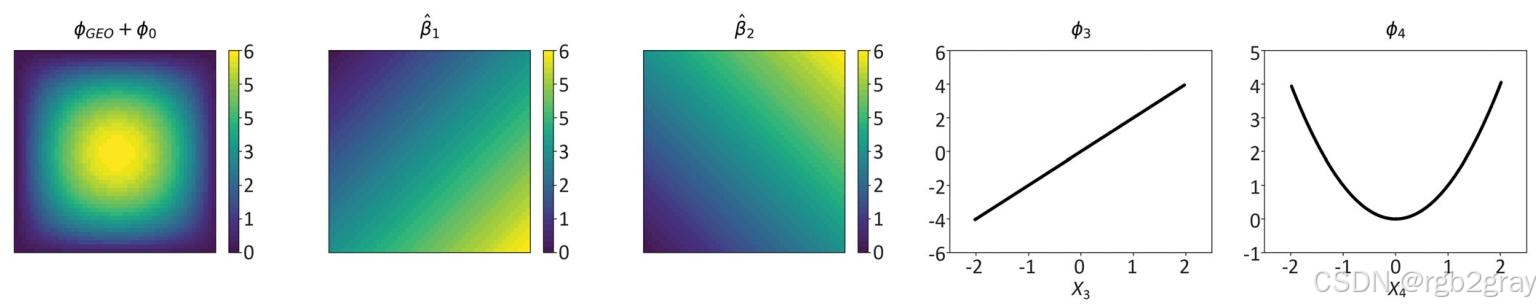
图4 真实模型中GeoShapley度量的空间和非空间过程:第一行为真实DGP,其余行为GeoShapley分解结果,完美匹配真实效应。
-
不同模型的解释对比(图6):
- LR:仅能捕捉线性效应(f3f_3f3),无法捕捉空间/非线性效应;
- RF:存在较多噪声,但能捕捉部分结构;
- XGBoost/SVM/GP/NN:几乎完美复现所有效应,验证了GeoShapley的模型无关性;
- MGWR:能捕捉空间效应,但无法捕捉非线性效应(f4f_4f4),且因模型假设限制,空间效应估计存在偏差。
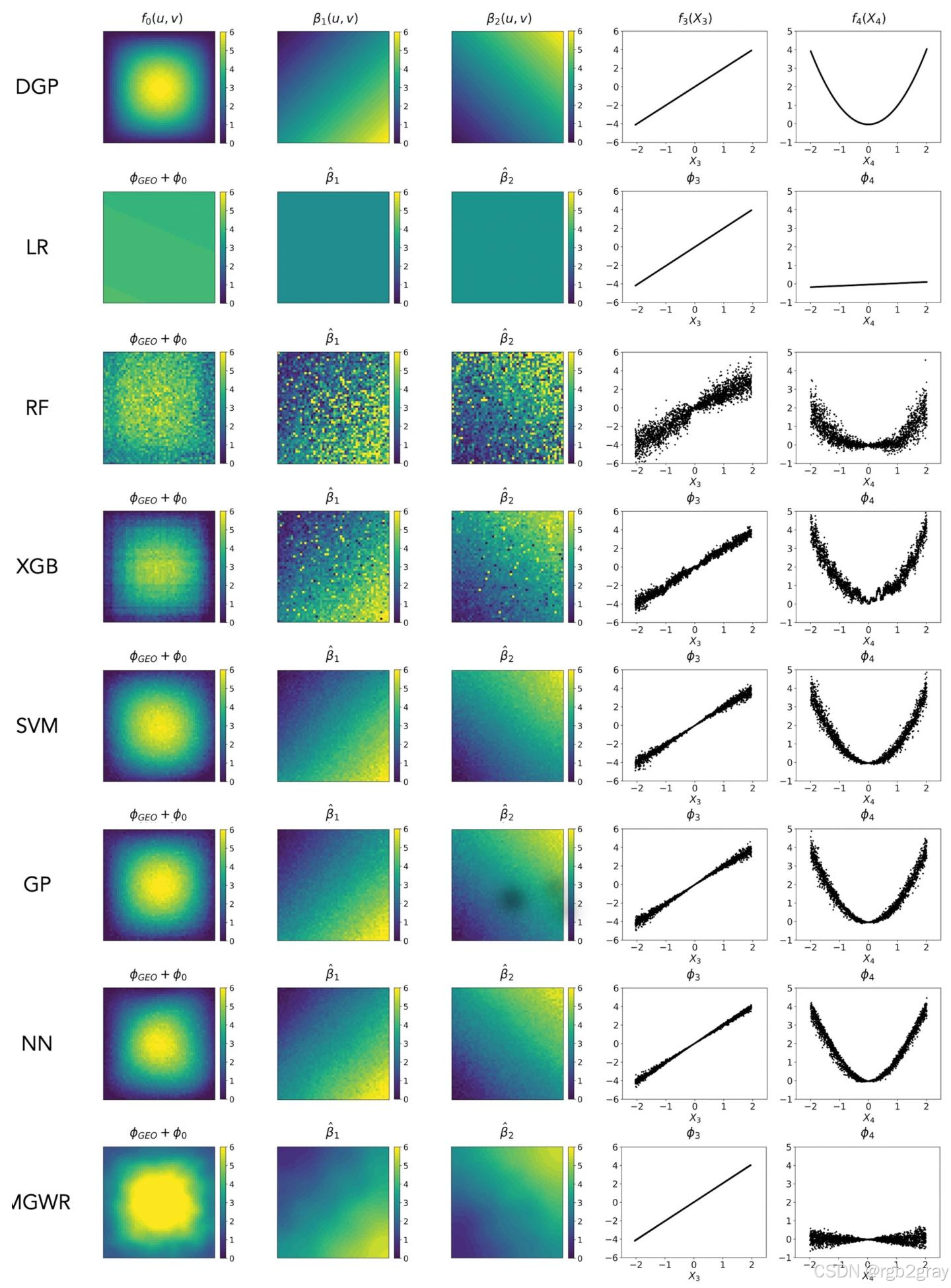
图6 不同模型的GeoShapley解释对比:第一行为真实DGP,其余行为各模型的GeoShapley分解结果。机器学习模型(XGBoost/SVM/GP/NN)解释效果最优。
4. 实证案例:西雅图房价建模
4.1 数据说明
-
数据集:King County 2014-2015年房屋销售数据,含16581条记录;
-
因变量:房屋售价的对数(log10(price)\log_{10}(price)log10(price));
-
特征:8个非位置特征(浴室数量、居住面积、地块面积、建筑等级等)+ 2个位置特征(UTM坐标);
-
特征相关性:居住面积与建筑等级相关性较强(0.73),其余特征相关性较低(图7)。
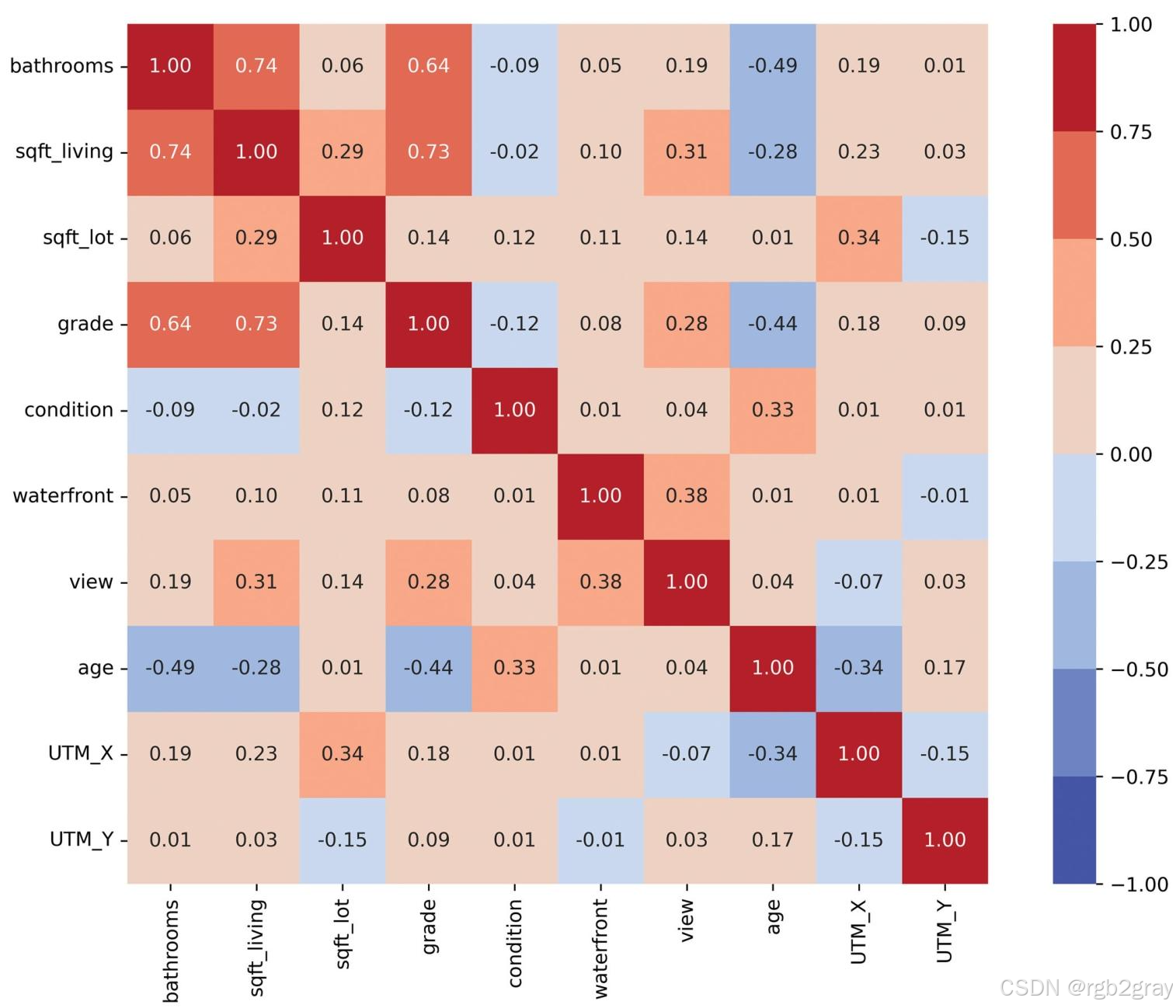
图7 特征相关性矩阵:颜色越深表示相关性越强,居住面积与建筑等级、浴室数量存在较强正相关。
4.2 模型选择
训练7种模型并对比样本外R2R^2R2:
| 模型 | 样本外R2R^2R2 |
|---|---|
| LR | 0.763 |
| NN | 0.858 |
| GP | 0.869 |
| SVM | 0.878 |
| RF | 0.892 |
| XGBoost | 0.908 |
XGBoost表现最优(R2=0.908R^2=0.908R2=0.908),且残差无明显空间自相关(Moran’s I=0.037),选择其作为最终模型进行GeoShapley解释。
4.3 解释结果
4.3.1 特征重要性排序(图8)
-
位置(GEO)是最重要特征:贡献范围为-43%~+123%(相对于基准房价105.63≈43万美元10^{5.63}\approx43万美元105.63≈43万美元);
-
非位置特征重要性:居住面积 > 建筑等级 > 地块面积 > 房龄 > 景观 > 房屋状况 > 浴室数量 > 临水属性;
-
交互效应:位置-房龄(age×GEO)是最强交互项,但整体弱于主效应。
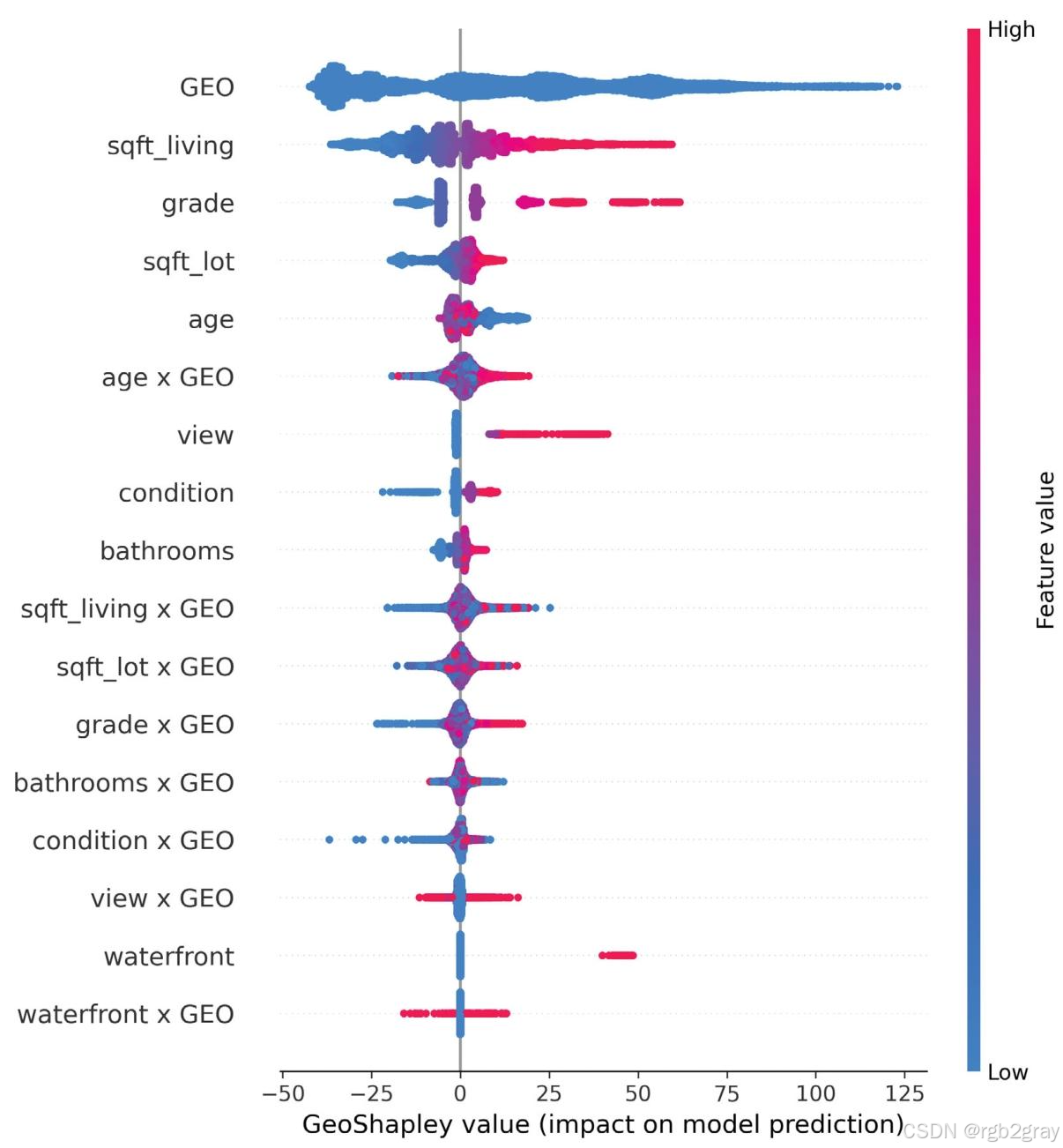
图8 房价模型的GeoShapley特征重要性排序:x轴为GeoShapley值(对房价的百分比影响),颜色表示特征取值大小。
4.3.2 非空间效应(图9)
通过部分依赖图展示特征的全局边际效应(控制其他特征不变):
-
居住面积:非线性正相关,面积越大,房价增长幅度越大;
-
建筑等级:等级13(最高)比等级1(最低)高60%;
-
临水属性:有临水的房屋比无临水的高30%~40%;
-
房龄:50年以内的房屋,房龄越小房价越高;50年以上房龄对房价影响不显著。
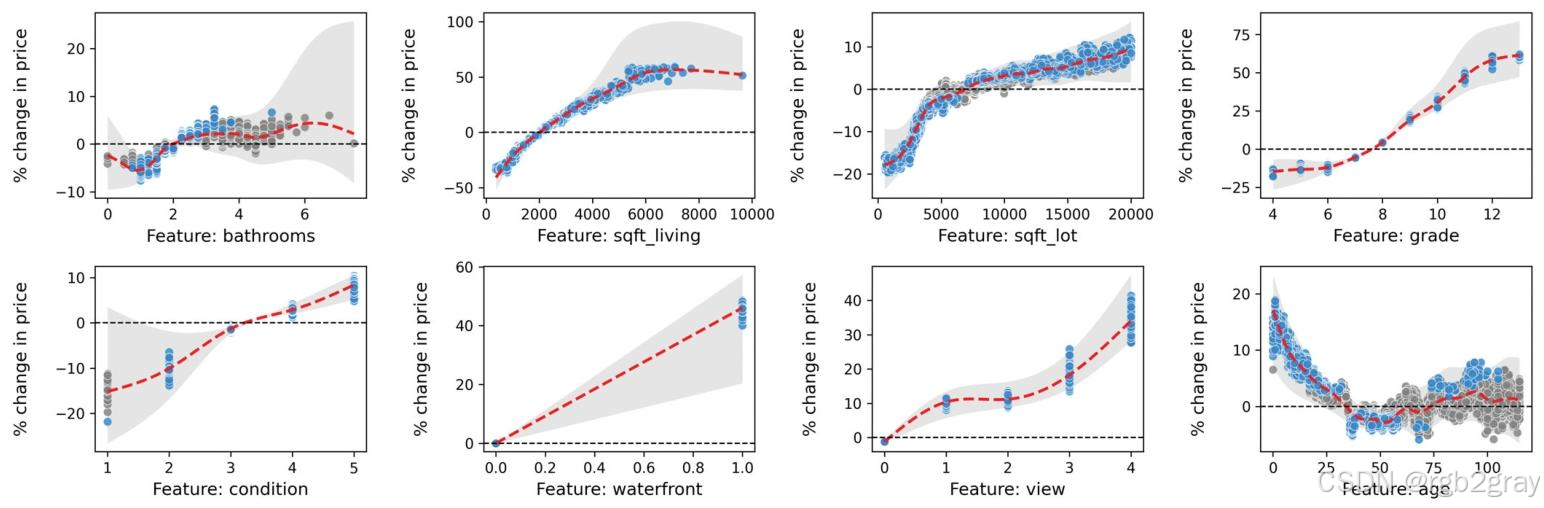
图9 特征与房价百分比变化的边际关系:灰色阴影为95%置信区间,灰色点表示效应不显著。
4.3.3 空间效应
-
内在位置效应(图10A):
- 正效应区域:西雅图市中心、北部区域、贝尔维尤(Bellevue)湖边区域(靠近亚马逊总部、优质学校、交通枢纽);
- 负效应区域:西雅图南部郊区(远离核心设施、 zoning 限制少);
- 相同房屋属性下,贝尔维尤的房价是南部郊区的3~4倍。
-
位置-房龄交互效应(图10B):
- Queen Anne、Capitol Hill等区域:房龄越大,房价越高(老房子经翻新,且位于核心地段);
- 其他区域:房龄对房价的交互效应不显著。
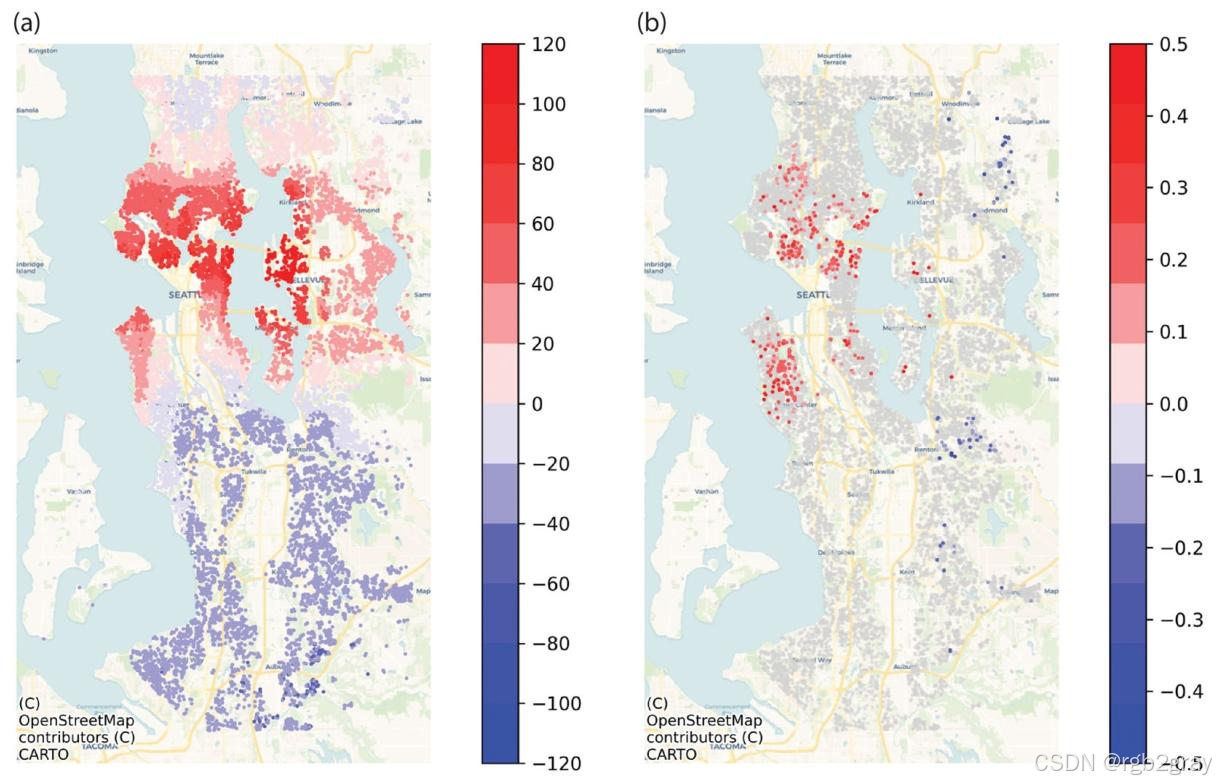
图10 空间效应可视化:(A) 内在位置效应(房价百分比变化);(B) 位置-房龄交互效应(每增加1年房龄的房价变化百分比)。灰色表示效应不显著。
5. 讨论与展望
5.1 核心贡献
- 模型无关性:首次实现对任意统计/ML模型的空间效应解释,支持跨模型对比;
- 理论一致性:将位置特征视为联合玩家,符合Shapley值理论假设;
- 解释直观性:分解结果与空间统计模型(GWR、MGWR)直接对应,降低地理学家使用门槛;
- 工程化实现:开源Python包,支持大规模地理空间数据应用。
5.2 局限性与未来方向
- 统计推断能力:当前依赖bootstrap构建置信区间,计算开销大,未来可结合参数化推断框架(如Shapley-Taylor分解);
- 空间因果推断:GeoShapley目前关注关联效应,未来可扩展至因果Shapley值,量化位置的因果效应;
- 高维位置嵌入:支持更复杂的位置编码(如space2vec)的联合处理;
- 动态空间效应:扩展至时空数据,捕捉时间依赖的空间效应。
6. 结论
GeoShapley通过扩展博弈论Shapley值框架,解决了现有XAI方法在地理空间建模中的核心痛点。其核心优势在于:
- 模型无关,支持任意统计/ML模型;
- 理论严谨,联合处理位置特征;
- 解释直观,与空间统计模型无缝衔接;
- 工程化成熟,开源工具包易于使用。
通过模拟数据验证和西雅图房价实证案例,GeoShapley展现了在量化空间效应、揭示地理空间现象背后机制的强大能力,为地理学家和数据科学家提供了一种兼具预测精度和可解释性的地理空间建模工具。
7. 参考代码:
from geoshapley import GeoShapleyExplainer
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_geo, y, random_state=1)
#Fit a NN model based on training data
mlp_model = MLPRegressor().fit(X_train, y_train)
#Specify a small background data
background = X_train.sample(100).values
#Initilize a GeoShapleyExplainer
mlp_explainer = GeoShapleyExplainer(mlp_model.predict, background)
#Explain the data
mlp_rslt = mlp_explainer.explain(X_geo)
#Make a shap-style summary plot
mlp_rslt.summary_plot()
#Make partial dependence plots of the primary (non-spatial) effects
mlp_rslt.partial_dependence_plots()
#Generate a ranked global feature contribution bar plot of the GeoShapley values.
mlp_rslt.contribution_bar_plot()
#Calculate spatially varying explanations
mlp_svc = mlp_rslt.get_svc()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)