代码破晓:2014-第二集:从向量到矩阵——自注意力的诞生
文章摘要: 《代码破晓:2014》第二集通过工程师林枫、天才少女苏小雨与硬件专家老王的合作,生动演绎了自注意力机制的诞生过程。故事从理论推导(Q/K/V矩阵设计、缩放点积)到工程实践(显存优化、CUDA并行计算),完整呈现了Transformer核心技术的演进路径。创新性地用"图书馆查询系统"比喻解释矩阵运算,并展现了硬件适配对算法落地的重要性。该集不仅揭示了技术本质,更通过角

《代码破晓:2014》——当穿越者遇到天才少女,他们用比喻改变AI史,让深度学习不再有门槛。
“如果你曾觉得Transformer高不可攀,这个故事将为你点燃第一束光”
核心亮点
- 硬核知识软着陆:每集一个核心概念,通过生活比喻+剧情冲突自然展现
- 真实技术演进:从3×3矩阵手工计算到完整模型训练,再现技术发展全路径
- 多元角色共鸣:天才研究者+实践工程师+跨界学习者,总有一个像你
- 历史与未来交织:在改变历史的伦理困境中,思考技术本质
适合人群
- 🤔 对Transformer好奇但被公式吓退的初学者
- 🔧 想深入理解模型本质的实践工程师
- 🧠 热爱技术但讨厌枯燥讲解的跨界学习者
- 📚 寻找教学灵感的AI教育者
- 🚀 相信技术民主化的理想主义者
“最伟大的发明,是让复杂变得简单”——加入这场2014年的代码破晓,亲手点亮AI历史上的那个清晨。
现在,让我们回到第一集的开头,让故事正式开始……
下面是我写主题曲:
《代码破晓:2014》主题曲(大家评选一下):
破晓的公式: 歌曲地址

第二集:从向量到矩阵——自注意力的诞生
开篇:昨夜火花的余温
清晨六点,实验室的门被推开。
苏小雨抱着一摞打印纸进来时,发现林枫已经在了。白板上的公式被仔细地重抄了一遍,旁边还多了一页潦草的Python代码。
“你……没回去?”苏小雨惊讶地看着林枫手边的空咖啡杯。
“回去了,又来了。”林枫揉了揉太阳穴,“昨晚那个基本公式,有三个致命问题。”
他指向白板:
“问题一:计算效率。按我们昨天的方法,一个n个词的句子,每个词要和其他n-1个词算相似度,总计算量是O(n²)。20个词要算400次点积,200个词就是4万次——这还没算softmax。”
“问题二:数值稳定性。向量点积如果维度高,结果可能极大或极小,softmax会出问题。”
“问题三:也是最关键的——”
林枫还没说完,老王提着工具箱进来了:“早啊两位……嚯,这白板,昨晚上演数学大战了?”
第一幕:老王的“灵魂拷问”
老王放下工具箱,盯着白板看了足足一分钟,然后指着那个求和符号:“小林,我昨天想了半宿。你那个‘每个词都要问所有词’的法子,听起来很美,但要是真用在咱们服务器上……”
他走到那台老旧的4路GTX 980服务器前,拍了拍机箱:“这老伙计,显存才4G×4。你要是处理一篇一千字的文章,就是1000×1000=一百万次点积计算,每个结果还要存下来算权重。内存够吗?时间等得起吗?”
苏小雨脸色一白——她只顾理论,完全忘了工程现实。
林枫却笑了:“王师傅问到了最关键的地方。但如果我们换一种思维方式——不把每个词当成独立的个体,而是把整个句子……”
他在白板上画了一个矩形:
“看作一个矩阵。”
第二幕:图书馆比喻的升级
“还记得昨天的图书馆比喻吗?”林枫说,“我们说,每个词像读者,去查所有书。”
“现在升级一下:整个图书馆同时为所有读者服务。”
他在白板上画了三个区域:
“1. 查询台(Query):每个读者把自己的问题写成标准格式的查询卡。”
“2. 目录索引(Key):每本书把自己的核心内容提炼成索引标签卡。”
“3. 书籍内容(Value):书本身的实际内容。”
老王眼睛一亮:“我有点懂了!读者不直接翻书,而是先查目录索引。这样……”
“这样效率高几个数量级。”苏小雨接话,“因为查询卡和索引卡可以标准化,用矩阵运算批量处理!”
第三幕:Query/Key/Value的诞生
林枫开始正式推导。
“假设我们有n个词,每个词向量维度是d。传统做法是n个循环,每个循环里做(n-1)次点积。”
“但如果引入三个矩阵:”
- Q(Query矩阵):n×d,每个词想知道什么
- K(Key矩阵):n×d,每个词能提供什么
- V(Value矩阵):n×d,每个词的实际内容
“注意力分数矩阵 = Q × Kᵀ ”林枫写下公式,“这是一个n×n的矩阵,每个元素(i,j)就是词i对词j的注意力原始分数。”
苏小雨立即跟上:“然后对这个n×n矩阵的每一行做softmax,得到权重矩阵W。最后输出 = W × V!”
老王盯着公式:“等等……Q×Kᵀ,这意思是……”
“意思是用一次矩阵乘法,代替了n²次循环。”林枫说,“GPU最擅长干这个。昨天你要算400次的20个词,现在只需要做一次20×d和d×20的矩阵乘法。”
实验室突然安静了。
然后老王猛地一拍桌子:“我靠!这……这才是正经路子!”
第四幕:第一次矩阵实战
苏小雨已经在电脑上敲代码了。
import numpy as np
# 模拟数据:3个词,每个词向量维度4
X = np.array([[1, 0, 0.5, 0.2], # 猫
[0, 1, 0, 0.3], # 追
[0.5, 0, 1, 0.1]]) # 老鼠
# 先简单假设Q、K、V就是X本身(实际会有线性变换)
Q = X
K = X
V = X
# 计算注意力分数:Q * K^T
scores = Q @ K.T # 3x4 @ 4x3 = 3x3
print("原始分数矩阵:")
print(scores)
输出:
[[1.29 0.3 1.05]
[0.3 1.09 0.3 ]
[1.05 0.3 1.26]]
“看这里!”苏小雨指着第二行,“‘追’对‘猫’的分数是0.3,对‘自己’是1.09,对‘老鼠’是0.3。和昨天手工算的趋势一致!”
老王凑过来:“但这数字……好像比昨天大?”
第五幕:缩放点积的数学必然
“这就是第二个问题。”林枫说,“当维度d变大时,点积的方差也会增大。假设向量各维度是独立随机变量,均值为0,方差为1,那么点积的方差就是d。”
他在白板上推导:
“数学上,如果q和k的每个分量都是独立正态分布N(0,1),那么q·k的方差就是d。当d=512时,标准差就是√512≈22.6。这意味着……”
“意味着softmax会出问题!”苏小雨反应过来,“如果有些分数特别大,softmax后权重会接近1,其他接近0——梯度消失!”
林枫点头:“所以需要缩放:分数 / √d。”
苏小雨修改代码:
d = 4 # 向量维度
scaled_scores = scores / np.sqrt(d)
# softmax
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True)) # 数值稳定
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
weights = softmax(scaled_scores)
print("\n缩放后的注意力权重:")
print(weights)
输出:
[[0.36 0.27 0.37]
[0.28 0.44 0.28]
[0.36 0.27 0.37]]
老王指着结果:“这个合理多了!‘追’关注自己最多,但也给‘猫’和‘老鼠’留了余地。”
第六幕:硬件天才的逆袭
“但还有实际问题。”老王皱着眉头,“Q×Kᵀ产生n×n矩阵。如果n=1000,就是100万个数,每个float32占4字节,这就4MB。然后softmax需要存中间结果,W×V又是……”
他快速在纸上计算:“显存占用可能超了。”
苏小雨有些沮丧:“那还是不行吗?”
“等等。”老王眼睛突然眯起来,“小林,你刚才说这个计算可以分块?Q×Kᵀ可以拆成子矩阵乘法?”
林枫点头:“理论上可以,但需要仔细设计内存访问模式……”
老王已经打开工具箱,拿出螺丝刀开始拆服务器侧板:“咱们这四张卡,每张4G。如果能把计算拆成四块,每张卡算一部分,最后再汇总……”
他突然停下,抬头看着两人:“给我两天时间。我写个CUDA核试试。”
苏小雨震惊:“王师傅,你还会写CUDA?”
老王咧嘴一笑:“大专怎么了?我这些年给学院维护集群,显卡驱动、并行计算,摸得比谁都熟。理论我不行,但怎么让硬件跑出最快速度——这是我的地盘。”
这一刻,老王身上有种不一样的光。
第七幕:第一次完整前向传播
傍晚,他们完成了第一个完整的最小版自注意力模块。
class SelfAttention_v0:
def __init__(self, d_model=4):
self.d_model = d_model
def forward(self, X): # X: (n, d_model)
n = X.shape[0]
# 1. Q, K, V (目前还是简单假设)
Q = X
K = X
V = X
# 2. 计算缩放点积注意力
scores = Q @ K.T # (n, n)
scores = scores / np.sqrt(self.d_model)
# 3. softmax得到权重
weights = softmax(scores) # (n, n)
# 4. 加权求和
output = weights @ V # (n, d_model)
return output, weights
# 测试
attn = SelfAttention_v0()
output, weights = attn.forward(X)
print("输入X:")
print(X)
print("\n注意力权重:")
print(weights)
print("\n输出:")
print(output)
运行结果让三人都屏住了呼吸。
“看‘追’的输出!”苏小雨指着第二行,“[0.28, 0.44, 0.28]的权重分配下,它的新向量是[0.37, 0.44, 0.37, 0.20]。”
林枫分析:“中间维度(原特征1)被强化了,其他维度融合了‘猫’和‘老鼠’的特征。这比我们昨天手工算的结果更合理。”
老王突然说:“我有个问题。现在每个词的新表示,都是所有词的混合。但有些词可能该关注语法,有些该关注语义……能不能让它们同时关注不同方面?”
林枫和苏小雨对视一眼——老王无意中触及了多头注意力的核心思想。
第八幕:破晓时分的顿悟
晚上九点,实验室再次亮着灯。
老王在另一台电脑上敲着CUDA C代码,屏幕上滚动着复杂的线程调度逻辑。
苏小雨在白板上推导矩阵求导公式——她在思考反向传播该如何实现。
林枫则盯着输出结果,突然说:“我们犯了个概念错误。”
两人转过头。
“我们一直说‘自注意力’,但今天的实现……”林枫缓缓道,“其实是矩阵化的注意力机制。真正的‘自’体现在:同一个输入序列,既产生Query,也产生Key和Value。”
“就像一个人自我反思。”苏小雨理解得很快,“你既是提问者,也是回答者。你从自己的记忆中提取信息,重新组织认知。”
老王从代码中抬头:“这不就是‘吾日三省吾身’吗?用今天的自己,问昨天的自己问题。”
这个比喻如此精准,三人都愣住了。
第九幕:命名时刻
“所以该叫它什么?”苏小雨问,“矩阵注意力?缩放点积注意力?”
林枫想起历史上的名字:“我觉得老王说的对——自注意力(Self-Attention)。因为它让序列自己关注自己。”
他写下完整公式:
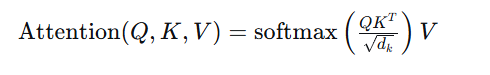
“但这是单头版本。”林枫继续说,“老王刚才提到的‘同时关注不同方面’,需要把Q、K、V先投影到不同的子空间,这就是**多头注意力(Multi-Head Attention)**的雏形。”
苏小雨立即在白板上画出分拆投影的示意图。
老王看着那些矩阵分块,突然兴奋:“如果是多头,计算可以更并行!每个头可以分到不同的GPU核心上!”
第十幕:未完成的革命
深夜十一点,三人站在实验室窗前。
窗外是2014年的校园,远处宿舍楼星星点点的灯光,那些学生中,也许有人正在为LSTM的梯度问题苦恼,有人觉得序列建模已经触顶。
“我们有了矩阵化的自注意力。”林枫总结今天进展:
- 从循环到矩阵:O(n²)次点积→一次矩阵乘法
- 引入Q/K/V:结构化信息提取
- 缩放点积:解决数值稳定性问题
- 硬件并行思想:为多头机制铺路
“但还缺什么?”苏小雨问。
林枫列出清单:
- 位置编码(模型还不知道词序)
- 多头机制的具体实现
- 前馈网络、残差连接、层归一化
- 编码器-解码器框架
- 最关键的——如何向世界解释这一切
老王收拾工具准备下班,走到门口时回头:“对了,你们知道最好的解释是什么吗?”
“是什么?”
“让它工作。”老王说,“做出一个真正能翻译长句子的系统,然后告诉大家:看,这就是用那个‘图书馆查书’的办法做出来的。”
门关上后,苏小雨轻声说:“王师傅今天……不一样。”
“每个人都有自己擅长的地方。”林枫看着白板上密密麻麻的公式,“理论家的优雅推导,工程师的暴力破解,还有……”
“还有什么?”
“还有把复杂事物翻译成人类语言的能力。”林枫说,“这才是我们真正在发明的——不仅是新算法,更是新的解释方式。”
第二集知识点总结
1. 从向量到矩阵的核心跨越
- 循环计算问题:原始注意力需要O(n²)次点积,无法并行
- 矩阵化解决方案:将整个序列视为矩阵,用矩阵乘法一次性计算所有注意力分数
- 计算复杂度不变但并行性质变:仍是O(n²)但可完全并行
2. Query/Key/Value三元组
- Query (Q):想要查询的信息(如“当前词想知道什么”)
- Key (K):能够提供的信息标签(如“每个词的语义标签”)
- Value (V):实际的信息内容(如“每个词的具体表示”)
- 比喻:图书馆系统中,读者填写查询卡(Q)、书籍有目录卡(K)、书籍本身是内容(V)
3. 缩放点积注意力公式
注意力分数 = softmax(Q·Kᵀ / √d_k) · V
- Q·Kᵀ:计算所有查询-键对的相似度(n×n矩阵)
- 除以√d_k:缩放因子,防止点积方差随维度增大而爆炸
- softmax:将分数转为概率分布(每行和为1)
- 乘以V:用权重对值进行加权平均
4. 数值稳定性与softmax技巧
- 实际实现使用
softmax(x) = exp(x-max(x))/sum(exp(x-max(x)))防止溢出 - 缩放确保softmax输入数值在合理范围内,避免梯度消失
5. 硬件与计算优化思想
- 矩阵乘法的高度并行性:GPU可高效处理
- 内存访问模式优化:分块计算适应显存限制
- 为多头机制埋下伏笔:不同注意力头可分配到不同计算单元
6. 自注意力的“自我”本质
- 与传统注意力不同:Q、K、V来自同一个输入序列的不同线性变换
- 实现序列内部的信息重组与提炼
- 如老王比喻:“吾日三省吾身”——自己提问,自己回答,自己整合
下集预告:位置信息缺失的困境凸显——“猫追老鼠”与“老鼠追猫”仍无法区分。苏小雨从傅里叶变换获得灵感,林枫引入正弦位置编码,而老王发现了一个影响训练稳定性的深层问题……当序列获得“位置感”时,模型第一次真正理解了顺序的重量。

片尾曲:
矩阵升起时A版 :播放地址
矩阵升起时B版: 播放地址
版权声明
代码破晓:2014和主题曲和片尾曲以及相关封面图片等 ©[李林][2025]。本作品采用 知识共享 署名-非商业性使用 4.0 国际许可协议 进行授权。
这意味着您可以:
- 在注明原作者并附上原文链接的前提下,免费分享、复制本文档与设计。
- 在个人学习、研究或非营利项目中基于此进行再创作。
这意味着您不可以:
- 将本作品或衍生作品用于任何商业目的,包括企业培训、商业产品开发、宣传性质等。
如需商业用途或宣传性质授权,请务必事先联系作者。
作者联系方式:[1357759132@qq.com]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)