3D Gaussain splatting 的训练提速
3DGS渲染加速,适应边缘端 3D 交互,包括AR/VR 设备的实时场景渲染、移动机器人的环境感知可视化
GauRast: Enhancing GPU Triangle Rasterizers to Accelerate 3D Gaussian Splatting

研究动机和背景
3DGS 作为一项先进的 3D 场景渲染技术,备受瞩目,尤其因其高质量的输出和场景重建的自动化而备受推崇。然而,其计算需求巨大,在低功耗、资源受限的边缘设备(例如 NVIDIA Jetson Orin NX)上实时执行并不切实际。此前加速 3DGS 的工作通常依赖于构建专用硬件加速器,这增加了成本和复杂性。本文的核心思想是利用和增强现有的 GPU 光栅化器,充分利用其在三角形网格渲染方面的既有效率,而不是开发新的硬件。
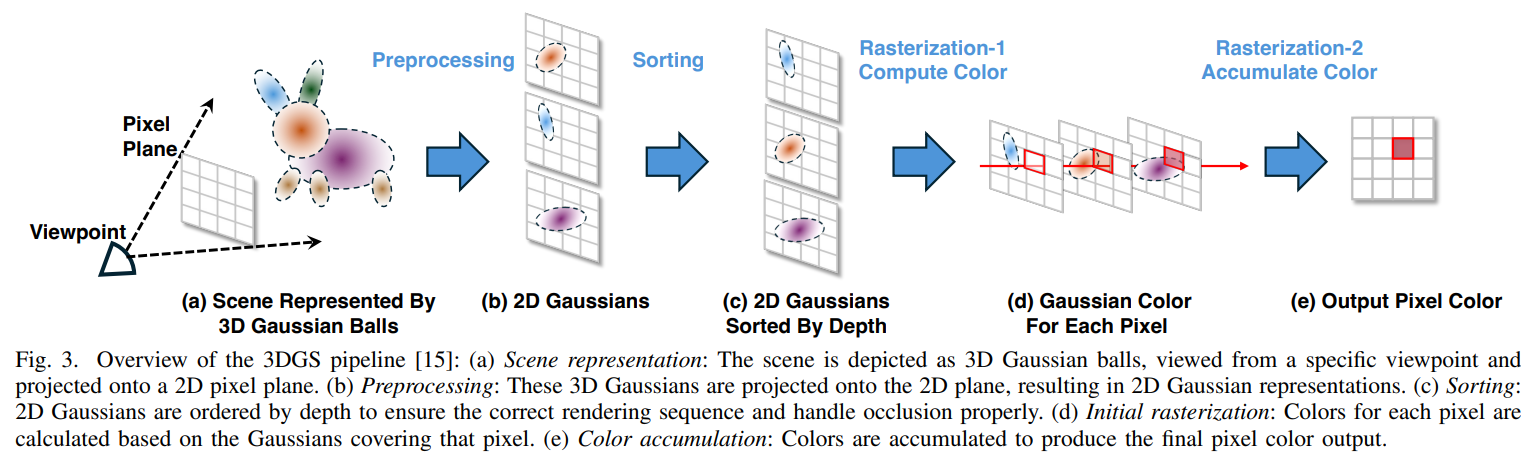
该方法首先对 3DGS 渲染管线进行广泛分析,以识别性能瓶颈。对管线的详细分析显示,仅高斯光栅化步骤就占据了基准数据集中多个场景总渲染时间的 80% 以上。鉴于三角形和高斯光栅化具有基本相似性(均涉及将图元投影到屏幕空间进行像素映射),作者建议修改现有的 GPU 三角形光栅化器以支持 3DGS。
主要贡献
GauRast 论文的核心贡献围绕 “3D 高斯溅射(3DGS)边缘实时渲染” 的硬件加速痛点展开,聚焦资源效率、兼容性、性能能效平衡三大核心,具体可归纳为以下 4 点(按创新优先级排序):
1. 核心技术创新:提出 “GPU 原生光栅化硬件增强” 范式
• 突破传统 “专用加速器” 的设计思路,发现 3DGS 的高斯光栅化与 GPU 原生三角形光栅化在数据流向、计算单元需求、输入输出格式上的高度相似性,提出 “复用现有硬件 + 最小化专用逻辑扩展” 的加速方案。
• 具体实现:仅新增 1 个指数运算单元、2 个加法器、1 个乘法器及模式切换模块,即可让 GPU 原生光栅器同时支持三角形渲染与高斯渲染,无需重新设计完整数据通路,硬件面积开销仅占 SoC 总面积的 0.2%。
• 价值:解决了专用加速器 “高成本、高复杂度、资源独占” 的核心缺陷,实现 “低成本 + 高性能” 的平衡。
2. 性能与能效突破:实现边缘设备 3DGS 实时渲染
• 针对 3DGS 渲染的核心瓶颈(高斯光栅化阶段占比超 80% 运行时间),通过硬件增强 + CUDA 协同调度(预处理 / 排序与光栅化并行流水线),实现极致加速:
◦ 端到端加速比:在边缘 GPU 平台(如 Jetson Orin NX 级),原始 3DGS 算法达 6× 加速,效率优化版 3DGS 算法达 4× 加速;
◦ 实时帧率:优化版算法渲染帧率从基线的 2-5 FPS 提升至 46 FPS,满足 AR/VR、自动驾驶等边缘场景≥30 FPS 的实时需求;
◦ 能效提升:高斯光栅化阶段能效提升 22-24×,适配边缘设备低功耗约束(≤10W)。
3. 兼容性创新:无缝适配现有 GPU 生态与工作流
• 复用 GPU 现有存储接口、通用计算单元、编程接口(如 CUDA),增强后的光栅器可在 “三角形渲染模式” 与 “高斯渲染模式” 间无缝切换,不破坏原有 GPU 对传统图形渲染(如游戏、视频)的支持。
• 泛化性:适配多厂商 GPU 架构(如 NVIDIA、Apple M 系列),只要具备三角形光栅化硬件即可部署,无需依赖特定芯片架构,降低应用落地门槛。
4. 工程落地价值:提供可规模化的边缘 3D 渲染解决方案
• 解决 3DGS 技术的核心落地瓶颈:此前 3DGS 仅能在高性能 GPU(≥200W)上实时渲染,GauRast 首次让边缘设备(低功耗、资源受限)具备 3DGS 实时渲染能力,拓展了 3DGS 的应用场景(AR/VR 设备、移动机器人、车载边缘计算)。
• 硬件实现可扩展性:基于 28nm 工艺实现 16 PE 原型,支持通过缩放 PE 数量适配不同性能需求的边缘 GPU(如从微型 IoT 芯片到中高端车载 GPU),具备规模化量产潜力。
总结核心贡献的本质
GauRast 并未发明新的渲染算法,而是通过硬件 - 算法协同优化的思路,找到 3DGS 与现有 GPU 硬件的 “适配点”,以极小的硬件代价突破边缘实时渲染的性能瓶颈,同时兼顾兼容性与能效,为 3D 神经渲染技术从 “实验室高性能平台” 走向 “边缘实际应用” 提供了关键的硬件解决方案,也为后续神经渲染算法的硬件加速提供了 “复用原生硬件 + 最小化增强” 的参考范式。
详细的技术方法
3DGS 的分析和分析:作者采用 NVIDIA Nsight Systems 对 3DGS 管道执行运行时分析,发现高斯光栅化步骤是阻碍边缘设备性能的瓶颈。
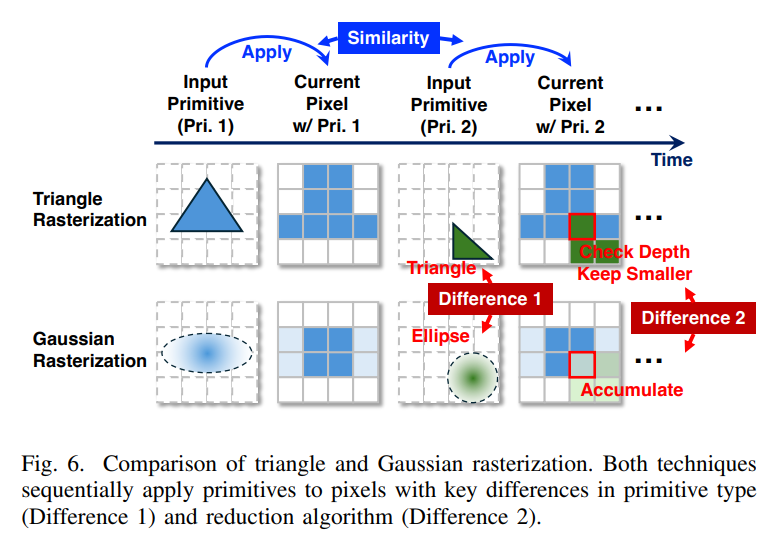
调整现有 GPU 光栅化器:高斯光栅化过程与三角形光栅化步骤相似,这一关键发现促使我们设计了增强型光栅化器——GauRast。此增强功能针对的是两个过程之间的两个关键差异:
从三角形相交测试过渡到高斯概率密度评估。
将缩减操作从基于深度的选择修改为基于重叠高斯的颜色累积。
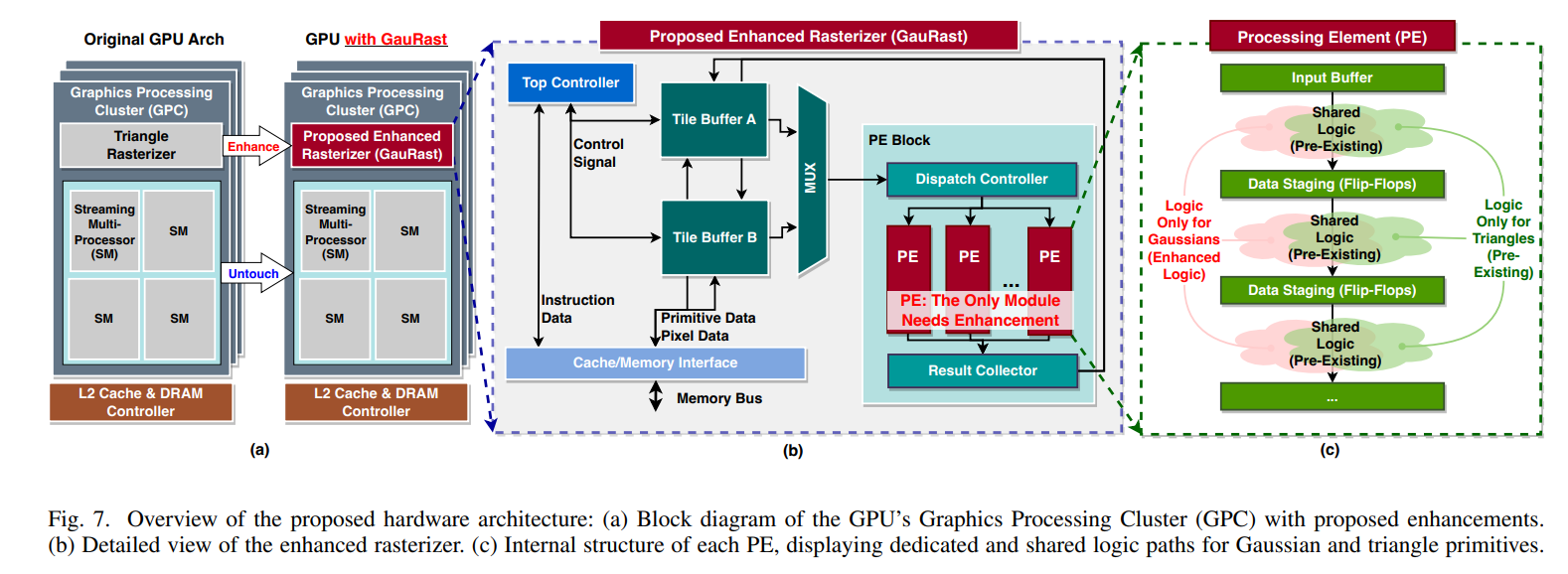
光栅化硬件的扩展:GauRast 设计的主要修改包括:
可重构数据路径:实现附加单元,例如用于计算高斯密度的幂运算,以及用于处理高斯细节的特定逻辑以及三角形光栅化逻辑。这使得相同的硬件资源可以用于双重运算。
处理单元 (PE):增强型光栅化器中的每个 PE 现在都可以处理高斯和三角形运算,并具有共享和专用逻辑路径以优化性能。新增的硬件占用空间极小,仅包含高斯处理所需的组件。
基于 CUDA 的混合调度:我们实施了一种协作式调度方法,将非主导任务(例如预处理和排序)分配给 CUDA 核心,而光栅化等繁重任务则由增强型光栅化器管理。这种并行任务分配有助于保持整体流水线效率。
作者使用 NeRF-360 数据集对 GauRast 进行了基准测试,并与 3DGS 算法的原始版本和效率优化版本进行了比较。结果显示出令人印象深刻的提升:
相对于原有的3DGS,处理速度加快了23倍,能耗降低了24倍。
端到端性能方面,原始算法加速比提升6倍,达到24FPS;
效率提升方案加速比提升4倍,达到46FPS。
GauRast的实现面积开销仅为芯片总面积的0.2% ,证明了其在边缘部署的实用性。
结论
这项研究的结果有力地表明,增强现有的 GPU 架构可以有效弥补在资源受限的平台上渲染 3DGS 等高级 3D 算法时的性能差距。该方案不仅展示了显著的性能提升,还强调了一种经济高效、硬件高效的方案,可以轻松集成到当前的 GPU 设计中。
总体而言,GauRast 代表了一种有前景的解决方案,可将高质量的 3D 渲染功能带入更广泛的应用领域,特别是在依赖于受限环境中实时处理的领域,例如 AR/VR 和自主系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)