UMM01:统一多模态理解与生成模型:进展、挑战与机遇
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and OpportunitiesXinjie Zhang*, JintaoGuo*, Shanshan Zhao*, Minghao Fu, Lunhao Duan, Jiakui Hu, Yong Xien Chng, Guo-Hua Wa
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
统一多模态理解与生成模型:进展、挑战与机遇
Xinjie Zhang*, JintaoGuo*, Shanshan Zhao*, Minghao Fu, Lunhao Duan, Jiakui Hu, Yong Xien Chng, Guo-Hua Wang, Qing-Guo Chen†, Zhao Xu, Weihua Luo, Kaifu Zhang
摘要——近年来,多模态理解模型和图像生成模型都取得了显著进展。尽管各自成就斐然,这两个领域却独立演化,形成了不同的架构范式:自回归架构主导了多模态理解,而基于扩散的模型则成为图像生成的基石。近来,旨在整合这些任务的统一框架引起了越来越多的关注,GPT-4o的新能力的出现就例证了这一趋势,凸显了统一的潜力。然而,两个领域之间的架构差异也带来了重大挑战。为清晰概述当前面向统一的研究工作,我们呈现了一篇全面的综述,以指导未来研究。首先,我们介绍多模态理解与文本到图像生成模型的基础概念和最新进展。接着,我们回顾现有的统一模型,并将其分为三大架构范式:基于扩散的、基于自回归的,以及融合自回归与扩散机制的混合方法。对于每一类,我们分析了相关工作的结构设计与创新。此外,我们汇编了面向统一模型的数据集与基准测试,为未来探索提供资源。最后,我们讨论了该新兴领域面临的关键挑战,包括分词策略、跨模态注意力与数据问题。由于该领域仍处于早期阶段,我们预计会有快速发展,并将定期更新此综述。与本综述相关的参考资料可在https://github.com/AIDC-AI/Awesome-Unified-Multimodal-Models获得。
Index Terms—统一多模态模型、Multimodal understanding、图像生成、自回归模型、扩散模型
1引言
近年来,大型语言模型(LLMs)如LLaMa [1], [2], PanGu [3], [4], Qwen [5], [6], 和GPT [7], 的快速发展革新了人工智能。这些模型在规模和能力上不断扩展,推动了各类应用的突破。与此同时,LLMs已被扩展到多模态领域,催生了诸如LLaVa [8], Qwen-VL [9], [10], InternVL [11], Ovis [12], 和GPT4 [13]等强大的多模态理解模型。这些模型的能力已从简单的图像字幕生成扩展到根据用户指令执行复杂推理任务。另一方面,图像生成技术也迅速发展,出现了像
SDseries [14], [15] 和 FLUX [16] 现在能够生成与用户提示高度一致的高质量图像。
用于LLMs和多模态理解模型的主流架构范式是自回归生成[17],它依赖仅解码器结构和基于下一个代币预测的顺序文本生成。相比之下,文本到图像生成领域沿着不同的轨迹演进。最初由生成对抗网络(GANs)主导[18],图像生成随后转向了基于扩散的模型[19],这些模型利用诸如UNet [14]和DiT [20],[21]之类的架构,同时配合像CLIP [22]和T5 [23]这样的先进文本编码器。尽管在使用受LLM启发的架构进行图像生成方面有一些探索
[24], [25], [26],,但基于扩散的方法目前在性能上仍然是最先进的。
尽管在图像生成质量方面,自回归模型落后于基于扩散的方法,但它们与大语言模型在结构上的一致性使其在开发统一多模态系统时特别具有吸引力。能够同时理解和生成多模态内容的统一模型具有巨大的潜力:它可以根据复杂指令生成图像、对视觉数据进行推理,并通过生成的输出可视化多模态分析。GPT-4o在2025年3月[27]所展现的增强能力进一步凸显了这一潜力,并在统一化方向上引发了广泛关注。
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
Xinjie Zhang*, Jintao Guo*, Shanshan Zhao*, Minghao Fu, Lunhao Duan, Jiakui Hu, Yong Xien Chng, Guo-Hua Wang, Qing-Guo Chen†, Zhao Xu, Weihua Luo, Kaifu Zhang
Abstract—Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o’s new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey are available on https://github.com/AIDC-AI/Awesome-Unified-Multimodal-Models
Index Terms—Unified multimodal models, Multimodal understanding, Image generation, Autoregressive model, Diffusion model
1 INTRODUCTION
In recent years, the rapid advancement of large language models (LLMs), such as LLaMa [1], [2], PanGu [3], [4], Qwen [5], [6], and GPT [7], has revolutionized artificial intelligence. These models have scaled up in both size and capability, enabling breakthroughs across diverse applications. Alongside this progress, LLMs have been extended into multimodal domains, giving rise to powerful multimodal understanding models like LLaVa [8], Qwen-VL [9], [10], InternVL [11], Ovis [12], and GPT4 [13]. These models have expanded their capabilities beyond simple image captioning to performing complex reasoning tasks based on user instructions. On the other hand, image generation technology has also experienced rapid development, with models like
SD series [14], [15] and FLUX [16] now capable of producing high-quality images that adhere closely to user prompts.
The predominant architectural paradigm for LLMs and multimodal understanding models is autoregressive generation [17], which relies on decoder-only structures and next-token prediction for sequential text generation. In contrast, the field of text-to-image generation has evolved along a different trajectory. Initially dominated by Generative Adversarial Networks (GANs) [18], image generation has since transitioned to diffusion-based models [19], which leverage architectures like UNet [14] and DiT [20], [21] alongside advanced text encoders such as CLIP [22] and T5 [23]. Despite some explorations into using LLM-inspired architectures for image generation [24], [25], [26], diffusion-based approaches remain the state-of-the-art in terms of performance currently.
While autoregressive models lag behind diffusion-based methods in image generation quality, their structural consistency with LLMs makes them particularly appealing for developing unified multimodal systems. A unified model capable of both understanding and generating multimodal content holds immense potential: it could generate images based on complex instructions, reason about visual data, and visualize multimodal analyses through generated outputs. The unveiling of GPT-4o’s enhanced capabilities [27] in March 2025 has further highlighted this potential, sparking widespread interest in unification.
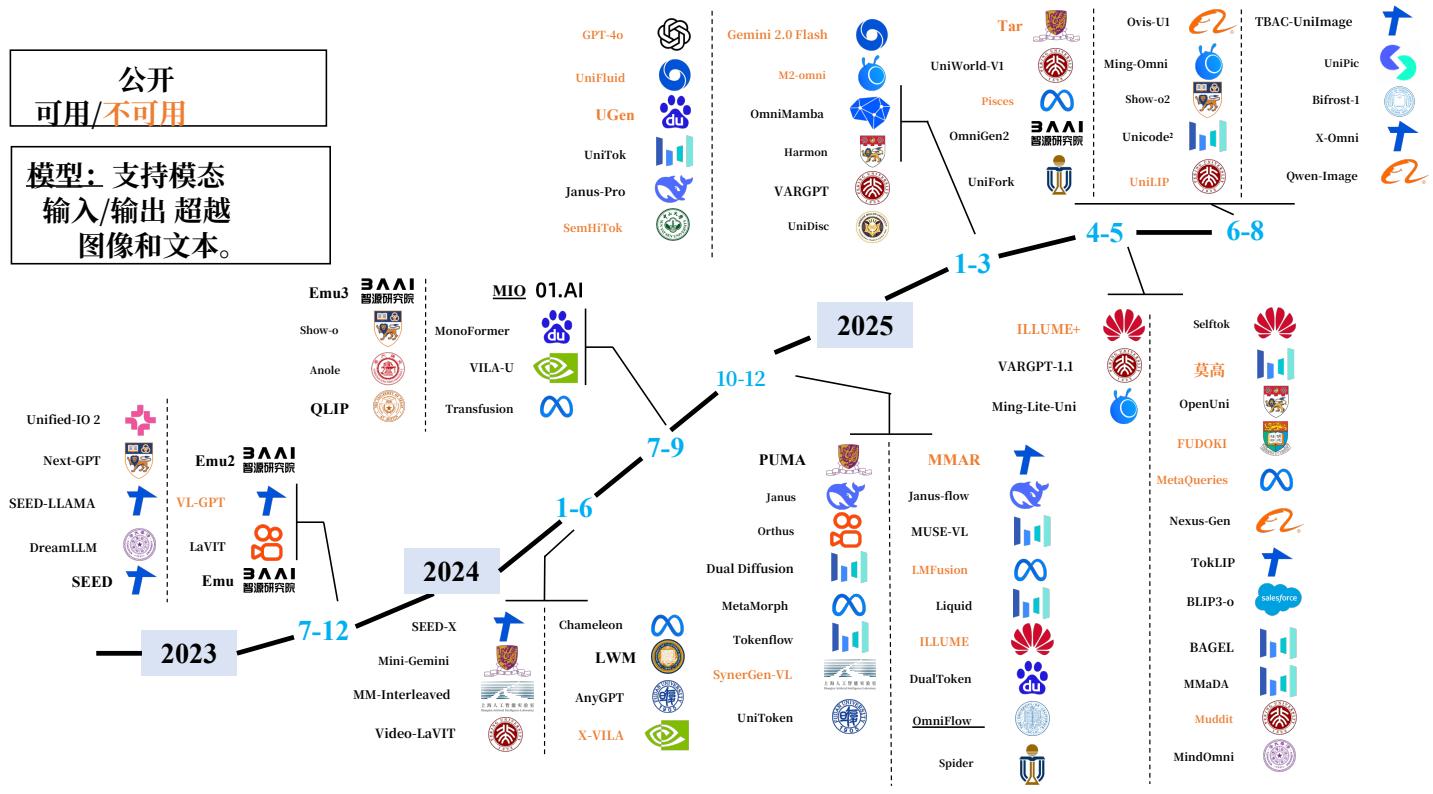
图1.公开可用和不可用的统一多模态模型时间线。图中模型按发布年份分类,涵盖2023年至2025年。图中带下划线的模型代表任意到任意多模态模型,能够处理超出文本和图像的输入或输出,如音频、视频和语音。该时间线突出了该领域的快速增长。
然而,设计这样一个统一的框架面临重大挑战。它需要将自回归模型在推理和文本生成方面的优势与基于扩散的模型在高质量图像合成方面的鲁棒性相结合。仍有一些关键问题尚未解决,包括如何有效地对图像进行分词以用于自回归生成。一些方法 [28], [29], [30] 采用在扩散管道中常用的 VAE [31] 或 VQ-GAN [32] 或其相关变体,而其他方法 [33], [34], [35] 则使用诸如 EVA-CLIP [36] 和 OpenAI-CLIP [22] 之类的语义编码器。此外,尽管离散令牌是自回归模型中文本的标准表示,emerging research [25] 表明连续表示可能更适合图像令牌。除了分词之外,将并行扩散策略与序列化自回归生成相结合的混合架构 [37], [38], [39],相较于简单双纯的自回归架构,提供了另一条有前景的途径。因此,对于统一多模态模型而言,图像分词技术和架构设计仍处于初期阶段。
为了全面概述统一多模态模型的现状(如图1所示),并为未来的研究工作提供参考,我们撰写了这篇综述。首先介绍多模态理解和图像生成的基础概念与最新进展,涵盖基于自回归和基于扩散的范式。接着回顾现有的统一模型,并将它们归类为三种主要的架构范式:基于扩散的、基于自回归的,以及融合自回归与扩散机制的混合方法,
在自回归和混合类别中,我们进一步根据模型的图像标记化策略对其进行分类,以反映该领域中方法的多样性。
除了架构之外,我们还汇编了为训练和评估统一多模态模型量身定制的数据集和基准。这些资源涵盖多模态理解、文本到图像生成、图像编辑及其他相关任务,为未来的探索提供了基础。最后,我们讨论了这一新兴领域面临的关键挑战,包括高效的分词策略、数据构建、模型评估等。应对这些挑战对提升统一多模态模型的能力和可扩展性至关重要。
在社区中,已有关于大型语言模型[40],[41],多模态理解[42],[43],[44],和图像生成[45],[46],的优秀综述,而我们的工作专注于理解与生成任务的整合。建议读者参考这些互补的综述以获得相关主题的更广阔视角。我们旨在激发该快速发展领域的更多研究,并为社区提供有价值的参考。包括相关参考文献、数据集和与本综述相关的基准测试在内的资料已在GitHub上提供,并将定期更新以反映持续的进展。
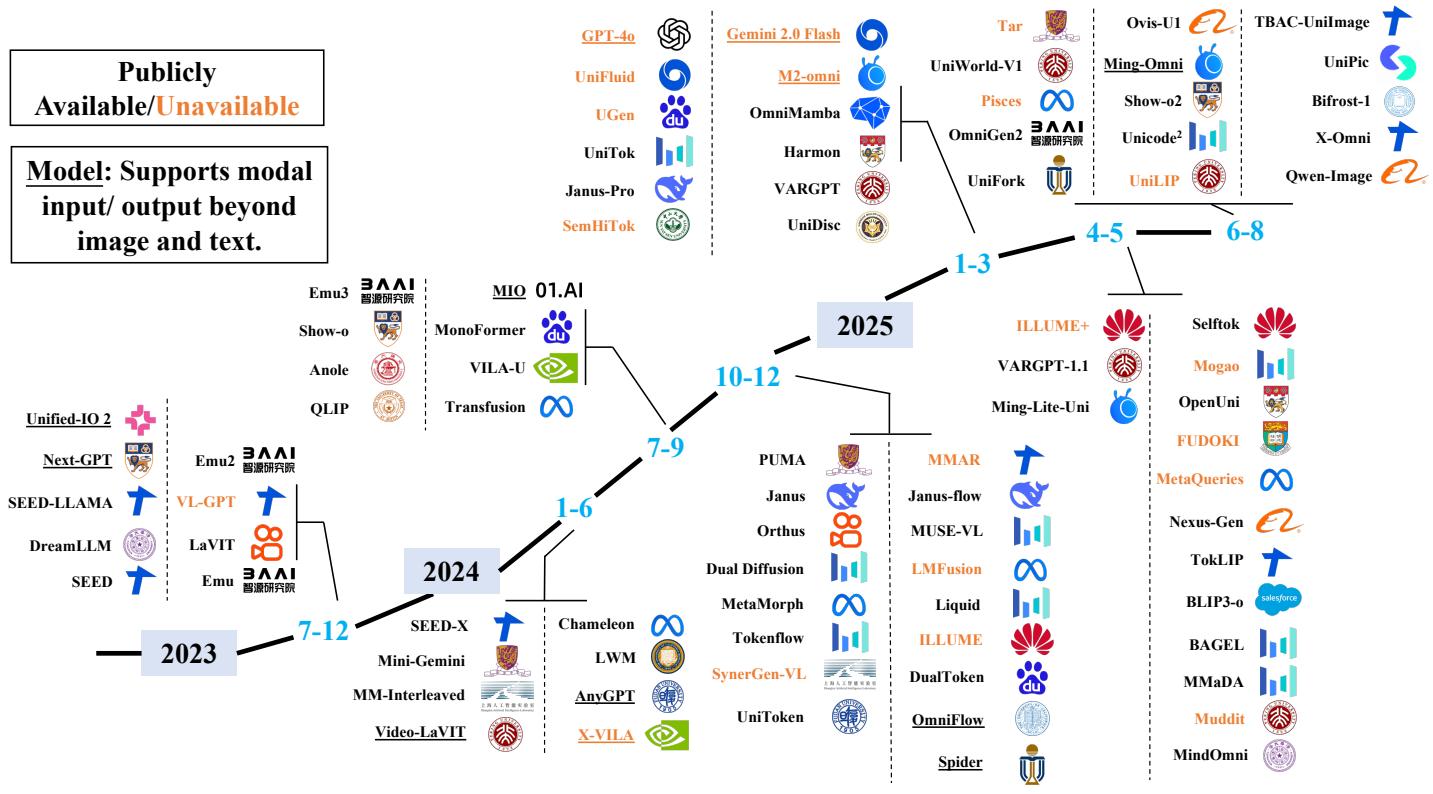
Fig. 1. Timeline of Publicly Available and Unavailable Unified Multimodal Models. The models are categorized by their release years, from 2023 to 2025. Models underlined in the diagram represent any-to-any multimodal models, capable of handling inputs or outputs beyond text and image, such as audio, video, and speech. The timeline highlights the rapid growth in this field.
However, designing such a unified framework presents significant challenges. It requires integrating the strengths of autoregressive models for reasoning and text generation with the robustness of diffusion-based models for high-quality image synthesis. Key questions remain unresolved, including how to tokenize images effectively for autoregressive generation. Some approaches [28], [29], [30] employ VAE [31] or VQ-GAN [32] commonly used in diffusion-based pipelines, or relevant variants, while others [33], [34], [35] utilize semantic encoders like EVA-CLIP [36] and OpenAI-CLIP [22]. Additionally, while discrete tokens are standard for text in autoregressive models, continuous representations may be more suitable for image tokens, as suggested by emerging research [25]. Beyond tokenization, hybrid architectures [37], [38], [39] that combine parallel diffusion strategies with sequential autoregressive generation offer another promising approach aside from naive autoregressive architecture. Thus, both image tokenization techniques and architectural designs remain in their nascent stages for unified multimodal models.
To provide a comprehensive overview of the current state of unified multimodal models (as illustrated in Fig. 1), thereby benefiting future research endeavors, we present this survey. We begin by introducing the foundational concepts and recent advancements in both multimodal understanding and image generation, covering both autoregressive and diffusion-based paradigms. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffu
sion mechanisms. Within the autoregressive and hybrid categories, we further classify models based on their image tokenization strategies, reflecting the diversity of approaches in this area.
Beyond architecture, we assemble datasets and benchmarks tailored for training and evaluating unified multimodal models. These resources span multimodal understanding, text-to-image generation, image editing, and other relevant tasks, providing a foundation for future exploration. Finally, we discuss the key challenges facing this nascent field, including efficient tokenization strategy, data construction, model evaluation, etc. Tackling these challenges will be crucial for advancing the capabilities and scalability of unified multimodal models.
In the community, there exist excellent surveys on large language models [40], [41], multimodal understanding [42], [43], [44], and image generation [45], [46], while our work focuses specifically on the integration of understanding and generation tasks. Readers are encouraged to consult these complementary surveys for a broader perspective on related topics. We aim to inspire further research in this rapidly evolving field and provide a valuable reference for the community. Materials including relevant references, datasets, and benchmarks associated with this survey are available on GitHub and will be regularly updated to reflect ongoing advancements.
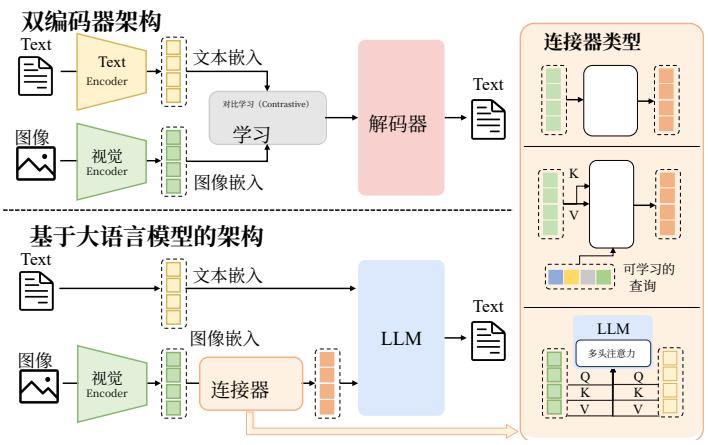
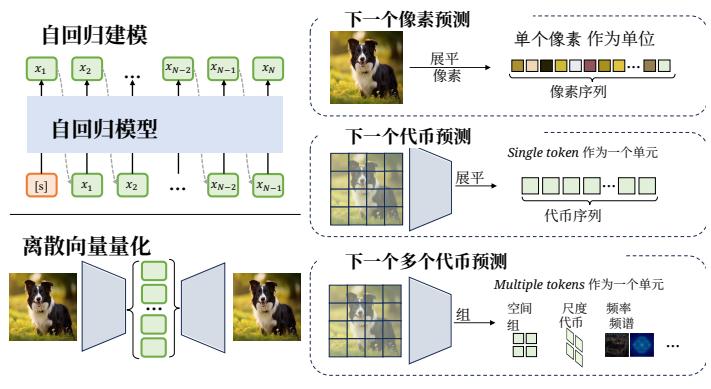
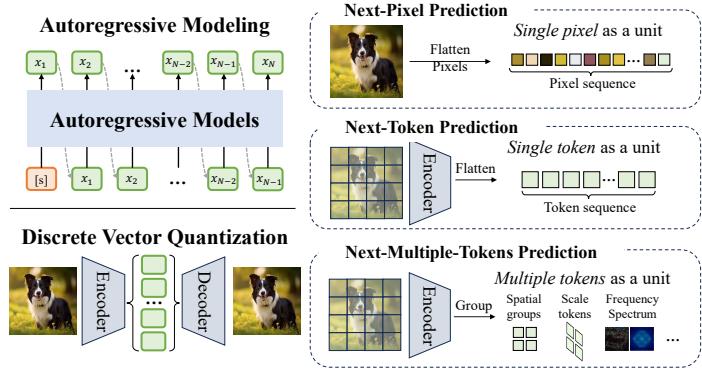
图4.自回归模型核心组件示意图,包括自回归序列建模和离散向量量化。现有自回归模型大致可分为三类:下一个像素预测将图像展平为像素序列;下一个代币预测通过视觉分词器将图像转换为代币序列;下一个多个代币预测在自回归步骤中输出多个代币。
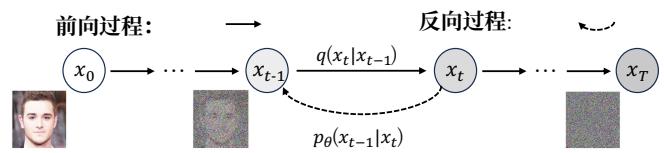
图2. 多模态理解模型的架构,包含多模态编码器、一个连接器和一个大语言模型。多模态编码器将图像、音频或视频转换为特征,这些特征由连接器处理作为大语言模型的输入。连接器的架构大致可分为三类:基于投影的、基于查询的和基于融合的连接器。
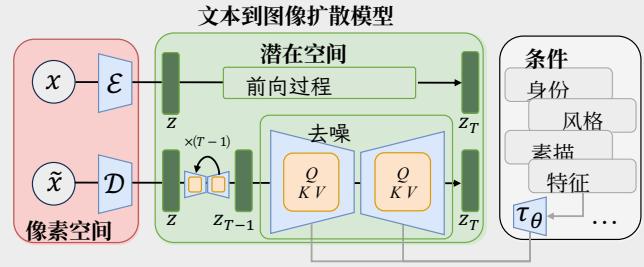
图3.基于扩散的文本到图像生成模型示意图,展示了除了文本之外的多种条件如何被引入以引导生成结果。图像生成被表述为一对马尔可夫链:正向过程通过加入高斯噪声逐步破坏输入数据,反向过程则学习一个参数化分布以迭代去噪,恢复到输入数据。
2 预备知识
2.1多模态理解模型
多模态理解模型是指能够接收、多模态输入上进行推理并生成输出的基于LLM的架构[47]。这些模型将LLM的生成和推理能力扩展到文本数据之外,使得在多样信息模态间实现丰富的语义理解成为可能[42],[48]。现有方法的大部分工作集中于视觉-语言理解(VLU),它将视觉(例如,图像和视频)与文本输入整合,以支持对空间关系、对象、场景和抽象概念的更全面理解[49],[50],[51]。多模态理解模型的典型架构示于图2。这些模型在混合输入空间内运行,其中文本数据以离散形式表示,而视觉信号被编码为连续表示[52]。类似
与传统大语言模型类似,它们的输出作为从内部表示派生的离散代币生成,使用基于分类的语言建模和任务特定的解码策略 [8], [53]。
早期的视觉-语言理解模型主要集中在使用双编码器架构对视觉和文本模态进行对齐,其中图像和文本首先分别编码,然后通过对齐的潜在表示联合推理,包括CLIP [22]、ViLBERT [54]、VisualBERT [55],和UNITER [56]。尽管这些开创性模型为多模态推理奠定了关键原则,但它们高度依赖基于区域的视觉预处理和独立编码器,限制了模型的可扩展性和通用性。随着强大大语言模型的出现,视觉-语言理解模型已逐步转向仅解码器架构,结合被冻结或仅微调的LLM主干。这些方法主要通过具有不同结构的连接器转换图像嵌入,如图2所示。具体来说,MiniGPT-4 [57]使用单层可学习层将来自CLIP的图像嵌入投射到Vicuna[58]的代币空间;BLIP-2 [53]引入了一个查询变换器,将冻结的视觉编码器与冻结的LLM(例如Flan-T5[59]或Vicuna[58])连接起来,从而以显著更少的可训练参数实现高效的视觉-语言对齐;Flamingo[60]则采用门控交叉注意力层,将预训练的视觉编码器与冻结的Chinchilla[61]解码器连接。
近年来在视觉语言理解(VLU)方面的进展凸显了向通用多模态理解的转变。GPT-4V [62] 将GPT-4框架 [13] 扩展到分析用户提供的图像输入,尽管为专有模型,但在视觉推理、图像描述和多模态对话方面表现出强大能力。
Gemini [63], 基于仅解码器架构,支持图像、视频和音频模态,其Ultra版本在多模态推理任务上树立了新的基准。
Qwen系列体现了可扩展的多模态设计:Qwen-VL [5]引入了视觉感受器和对齐模块,而Qwen2-VL [9]增加了动态分辨率处理和M-RoPE,以稳健地处理多样化输入。
LLaVA-1.5 [64]和LLaVA-
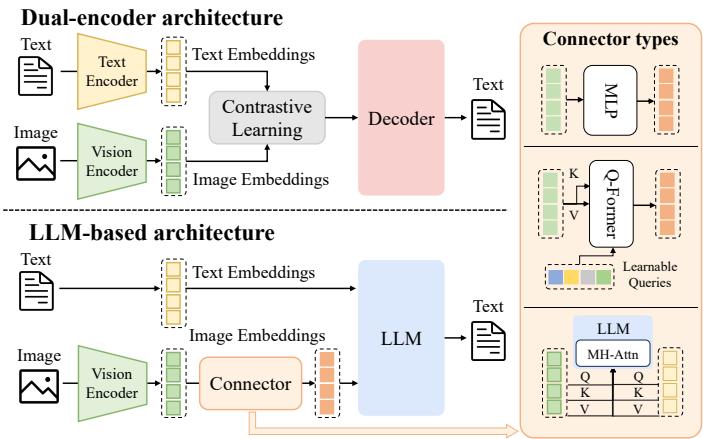
Fig. 4. Illustration of core components in autoregressive models, including the autoregression sequence modeling and discrete vector quantization. Exiting autoregressive models can be roughly divided into three types: Next-Pixel Prediction flattens the image into a pixel sequence, Next-Token Prediction converts the image into a token sequence via a visual tokenizer, and Next-Multiple-Token Prediction outputs multiple tokens in an autoregressive step.
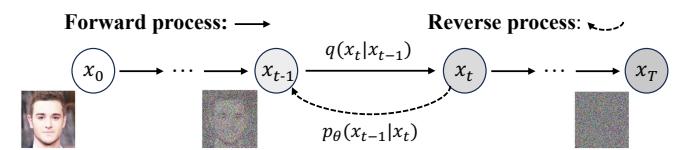
Fig. 2. Architecture of multimodal understanding models, containing multimodal encoders, a connector, and a LLM. The multimodal encoders transform images, audio, or videos into features, which are processed by the connector as the input of LLM. The architectures of theconnector can be broadly categorized by three types: projection-based, query-based, and fusion-based connectors.
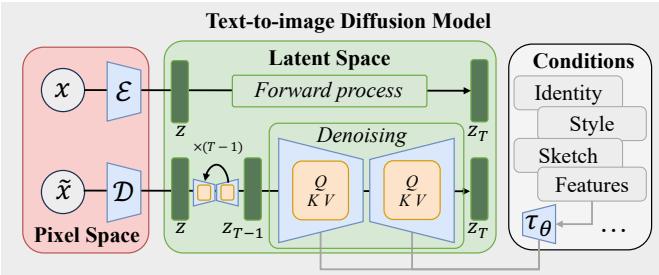
Fig. 3. Illustration of diffusion-based text-to-image generation models, where various conditions beyond text are introduced to steer the outcomes. The image generation is formulated as a pair of Markov chains: a forward process that gradually corrupts input data by adding Gaussian noise, and a reverse process that learns a parameterized distribution to iteratively denoise back to the input data.
2 PRELIMINARY
2.1 Multimodal Understanding Model
Multimodal understanding models refer to LLM-based architectures capable of receiving, reasoning over, and generating outputs from multimodal inputs [47]. These models extend the generative and reasoning capabilities of LLMs beyond textual data, enabling rich semantic understanding across diverse information modalities [42], [48]. Most efforts of existing methods focus on vision-language understanding (VLU), which integrates both visual (e.g., images and videos) and textual inputs to support a more comprehensive understanding of spatial relationships, objects, scenes, and abstract concepts [49], [50], [51]. A typical architecture of multimodal understanding models is illustrated in Fig. 2. These models operate within a hybrid input space, where textual data are represented discretely, while visual signals are encoded as continuous representations [52]. Similar
to traditional LLMs, their outputs are generated as discrete tokens derived from internal representations, using classification-based language modeling and task-specific decoding strategies [8], [53].
Early VLU models primarily focused on aligning visual and textual modalities using dual-encoder architectures, wherein images and text are first encoded separately and then jointly reasoned over via aligned latent representations, including CLIP [22], ViLBERT [54], VisualBERT [55], and UNITER [56]. Although these pioneering models established key principles for multimodal reasoning, they depended heavily on region-based visual preprocessing and separate encoders, limiting the scalability and generality of the mode. With the emergence of powerful LLMs, VLU models have progressively shifted toward decoder-only architectures that incorporate frozen or minimally fine-tuned LLM backbones. These methods primarily transform image embeddings through a connector with different structures, as illustrated in Fig. 2. Specifically, MiniGPT-4 [57] utilized a single learnable layer to project CLIP-derived image embeddings into the token space of Vicuna [58]. BLIP-2 [53] introduced a querying transformer, to bridge a frozen visual encoder with a frozen LLM (e.g., Flan-T5 [59] or Vicuna [58]), enabling efficient vision-language alignment with significantly fewer trainable parameters. Flamingo [60] employed gated cross-attention layers to connect a pretrained vision encoder with a frozen Chinchilla [61] decoder.
Recent advances in VLU highlight a shift toward general multimodal understanding. GPT-4V [62] extends the GPT-4 framework [13] to analyze image inputs provided by the user, demonstrating strong capabilities in visual reasoning, captioning, and multimodal dialogue, despite its proprietary nature. Gemini [63], built upon a decoder-only architecture, supports image, video, and audio modalities, with its Ultra variant setting new benchmarks in multimodal reasoning tasks. The Qwen series exemplifies scalable multimodal design: Qwen-VL [5] incorporates visual receptors and grounding modules, while Qwen2-VL [9] adds dynamic resolution handling and M-RoPE for robust processing of varied inputs. LLaVA-1.5 [64] and LLaVA
Next [65] 使用基于CLIP的视觉编码器和Vicuna风格的LLMs,在VQA和遵循指令任务中具有竞争力。InternVL系列 [11], [66], [67] 探索了统一的多模态预训练策略,能够同时从文本和视觉数据中学习,以提升各类视觉-语言任务的性能。Ovis [12]通过一个可学习的视觉嵌入查找表引入了结构嵌入对齐机制,从而生成在结构上与文本代币相映射的视觉嵌入。最近,一些模型开始探索用于多模态处理的可扩展且统一的架构。DeepSeek-VL2 [68] 采用专家混合架构(MoE)来增强跨模态推理。总体而言,这些模型清晰地推动了面向指令微调和以代币为中心的框架发展,使其能够以统一且可扩展的方式应对多样的多模态任务。
2.2 文本到图像模型
扩散模型。扩散模型(DM)将生成表述为一对马尔可夫链:前向过程通过在时间步上逐步加入高斯噪声来逐渐破坏数据 x 0 x_0 x0 T T T 以生成 x T x_{T} xT ,以及反向过程学习一个参数化分布以迭代去噪回到数据流形[19],[69],[70]。形式上,如图3所示,在前向过程中,给定数据分布 x 0 ∼ q ( x 0 ) x_0\sim q(x_0) x0∼q(x0) ,在每个步骤 t t t 数据 x t x_{t} xt 被噪声化:
q ( x 1 : T ∣ x 0 ) : = ∏ T q ( x t ∣ x t − 1 ) , (1) q \left(x _ {1: T} \mid x _ {0}\right) := \prod^ {T} q \left(x _ {t} \mid x _ {t - 1}\right), \tag {1} q(x1:T∣x0):=∏Tq(xt∣xt−1),(1)
q ( t x ∣ x − t − 1 ) = N x ( t 1 − ; β t − t − 1 1 , β t ) 1 t = 1 , ( x − ) 2 q \left(\underset {x} {t} \mid x _ {-} ^ {t - 1}\right) = \underset {x} {\mathcal {N}} (\underset {1 -} {t}; \sqrt [ t = 1 ]{\frac {\beta_ {t - t - 1} ^ {1} , \beta_ {t})}{1}}, \underset {x _ {-}} () \quad 2 q(xt∣x−t−1)=xN(1−t;t=11βt−t−11,βt),x−()2
其中 β t \beta_{t} βt 是噪声的方差超参数。在反向过程中,模型逐步去噪以逼近马尔可夫链的反向。逆转移 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t - 1}|x_t) pθ(xt−1∣xt) 被参数化为:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) , (3) p _ {\theta} \left(x _ {t - 1} \mid x _ {t}\right) = \mathcal {N} \left(x _ {t - 1}; \mu_ {\theta} \left(x _ {t}, t\right), \Sigma_ {\theta} \left(x _ {t}, t\right)\right), \tag {3} pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)),(3)
网络对均值 μ θ ( x t , t ) \mu_{\theta}(x_t,t) μθ(xt,t) 和方差 Σ θ ( x t , t ) \Sigma_{\theta}(x_t,t) Σθ(xt,t) 进行参数化。网络以被加噪的数据 x t x_{t} xt 和时间步 t t t 作为输入,输出用于噪声预测的正态分布参数。噪声向量由采样 x T ∼ p ( x T ) x_{T} \sim p(x_{T}) xT∼p(xT) 初始化,然后从学习到的转移核 x t − 1 ∼ p θ ( x t − 1 ∣ x t ) x_{t - 1} \sim p_{\theta}(x_{t - 1}|x_{t}) xt−1∼pθ(xt−1∣xt) 逐步采样,直到 t = 1 t = 1 t=1 。训练目标是最小化负对数似然的变分下界:
L = E q ( x 0 , x 1 : T ) [ ∥ ϵ θ ( x t , t ) − ϵ ∗ ( x t , t ) ∥ 2 ] \mathcal{L} = \mathbb{E}_{q(x_0,x_{1:T})}\left[\| \epsilon_\theta (x_t,t) - \epsilon^* (x_t,t)\| ^2\right] L=Eq(x0,x1:T)[∥ϵθ(xt,t)−ϵ∗(xt,t)∥2] , 其中 ϵ θ ( x t , t ) \epsilon_{\theta}(x_{t},t) ϵθ(xt,t) 是模型对时间步 t t t 时噪声的预测, ϵ ∗ ( x t , t ) \epsilon^{*}(x_{t},t) ϵ∗(xt,t) 是在该时间步加入的真实噪声。
早期的扩散模型使用基于U-Net的架构来近似得分函数[19]。基于Wide ResNet的U-Net设计集成了残差连接和自注意力块,以保持梯度流并恢复精细的图像细节。这些方法大致可分为像素级方法和潜在特征级方法。像素级方法直接在像素空间中运行扩散过程,包括引入“无分类器引导”的GLIDE[71]和采用预训练大型语言模型作为文本编码器的Imagen[72],即T5-XXL。然而,这些方法在训练和推理上计算成本昂贵,导致
催生了在预训练变分自编码器潜在空间中运行的潜在扩散模型(LDMs)[14]的发展。LDMs在保持高生成质量的同时实现了计算效率,从而激发了各种基于扩散的生成模型的发展,包括VQ-Diffusion[73],、SD2.0[74],、SDXL[75],和UPainting[76]。
在Transformer架构的进步推动下,基于Transformer的模型已被引入到扩散过程中。开创性的Diffusion Transformers (DiT) [20]将输入图像转换为一系列图像补丁序列,并通过一系列Transformer模块处理这些序列。DiT还将扩散时间步 t t t 和条件信号 c c c 等额外的条件信息作为输入。DiT的成功激发了许多先进的生成方法的出现,包括在扩散训练中注入自监督视觉表征以增强大规模性能的REPA [77],SD3.0 [15]使用两个独立的权重集合来建模文本和图像模态,以及其他方法[78],[79],[80]。在文本编码器方面,这些方法主要利用对比学习将图像和文本模态对齐到共享的潜在空间,联合在大规模图像-字幕对上训练独立的图像和文本编码器[22],[53],[81]。具体而言,GLIDE [71]同时探索了CLIP引导和无分类器引导,证明了基于CLIP的扩散优于早期的GAN基线并支持强大的文本驱动编辑。SD[14]采用了冻结的CLIP-ViT-L/14编码器来为其潜在扩散去噪器提供条件,从而以高效计算实现高质量样本。SD3.0 [15]使用CLIP ViT-L/14、OpenCLIPbigG/14和T5-v1.1 XXL将文本转换为用于生成引导的嵌入表示。
最近在扩散模型方面的进展已将LLMs引入以增强文本到图像的扩散生成[82],[83],这显著提升了文本-图像对齐性以及生成图像的质量。RPG[83]利用多模态LLMs的视觉语言先验,从文本提示中推理出互补的空间布局,并在文本引导的图像生成和编辑过程中操控扩散模型的对象组成。然而,这些方法针对特定任务需要不同的模型架构、训练策略和参数配置,给模型管理带来了挑战。一种更具可扩展性的解决方案是采用一个unified generation model,能够处理多种数据生成任务[84],[85],[86],[87]。OmniGen[84]实现了文本到图像的生成功能,并支持各种下游任务,如图像编辑、主体驱动生成和视觉条件生成。UniReal[85]将图像级任务视为不连续的视频生成,将不同数量的输入和输出图像视为帧,从而无缝支持图像生成、编辑、定制和合成等任务。GenArtist[86]提供了一个由多模态大型语言模型(MLLM)代理协调的统一图像生成与编辑系统。UniVG[87]将多模态输入视为统一条件,并通过一组权重来支持各种下游应用。随着该领域研究的推进,预计会出现越来越多的统一模型,能够处理更广泛的图像生成与编辑任务。
Next [65] use CLIP-based vision encoders and Vicuna-style LLMs for competitive performance in VQA and instruction-following tasks. The InternVL series [11], [66], [67] explore a unified multimodal pre-training strategy, which simultaneously learns from both text and visual data to enhance performance across various visual-linguistic tasks. Ovis [12] introduces a structural embedding alignment mechanism through a learnable visual embedding lookup table, thus producing visual embeddings that structurally mirror textual tokens. Recently, some models have explored scalable and unified architectures for multimodal processing. DeepSeek-VL2 [68] employs a Mixture-of-Experts (MoE) architecture to enhance cross-modal reasoning. Overall, these models mark a clear progression toward instruction-tuned and token-centric frameworks capable of addressing diverse multimodal tasks in a unified and scalable manner.
2.2 Text-to-Image Model
Diffusion models. Diffusion models (DM) formulate generation as a pair of Markov chains: a forward process that gradually corrupts data x 0 x_0 x0 by adding Gaussian noise over T T T timesteps to produce x T x_{T} xT , and a reverse process that learns a parameterized distribution to iteratively denoise back to the data manifold [19], [69], [70]. Formally, as shown in Fig. 3 in the forward process, given the date distribution x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x0∼q(x0) , at each step t t t , the data x t x_{t} xt is noised:
q ( x 1 : T ∣ x 0 ) : = ∏ t = 1 T q ( x t ∣ x t − 1 ) , (1) q \left(x _ {1: T} \mid x _ {0}\right) := \prod_ {t = 1} ^ {T} q \left(x _ {t} \mid x _ {t - 1}\right), \tag {1} q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),(1)
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) , (2) q \left(x _ {t} \mid x _ {t - 1}\right) = \mathcal {N} \left(x _ {t}; \sqrt {1 - \beta_ {t}} x _ {t - 1}, \beta_ {t} \mathbf {I}\right), \tag {2} q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),(2)
where β t \beta_{t} βt is the variance hyperparameters of the noise. During the reverse process, the model progressively denoises the data to approximate the reverse of the Markov chain. The reverse transition p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t - 1}|x_t) pθ(xt−1∣xt) is parameterized as:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) , (3) p _ {\theta} \left(x _ {t - 1} \mid x _ {t}\right) = \mathcal {N} \left(x _ {t - 1}; \mu_ {\theta} \left(x _ {t}, t\right), \Sigma_ {\theta} \left(x _ {t}, t\right)\right), \tag {3} pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)),(3)
where the network parameterizes the mean μ θ ( x t , t ) \mu_{\theta}(x_t,t) μθ(xt,t) and variance Σ θ ( x t , t ) \Sigma_{\theta}(x_t,t) Σθ(xt,t) . The network takes the noised data x t x_{t} xt and time step t t t as inputs, and outputs the parameters of the normal distribution for noise prediction. The noise vector is initiated by sampling x T ∼ p ( x T ) x_{T} \sim p(x_{T}) xT∼p(xT) , and then successively sample from the learned transition kernels x t − 1 ∼ p θ ( x t − 1 ∣ x t ) x_{t-1} \sim p_{\theta}(x_{t-1}|x_{t}) xt−1∼pθ(xt−1∣xt) until t = 1 t = 1 t=1 . The training objective is to minimize a Variational Lower-Bound of the Negative Log-Likelihood: L = E q ( x 0 , x 1 : T ) [ ∥ ϵ θ ( x t , t ) − ϵ ∗ ( x t , t ) ∥ 2 ] \mathcal{L} = \mathbb{E}_{q(x_0,x_1:T)}\left[\| \epsilon_{\theta}(x_t,t) - \epsilon^* (x_t,t)\| ^2\right] L=Eq(x0,x1:T)[∥ϵθ(xt,t)−ϵ∗(xt,t)∥2] , where ϵ θ ( x t , t ) \epsilon_{\theta}(x_t,t) ϵθ(xt,t) is the model’s prediction of the noise at timestep t t t , and ϵ ∗ ( x t , t ) \epsilon^{*}(x_{t},t) ϵ∗(xt,t) is the true noise added at that timestep.
Early diffusion models utilized a U-Net architecture to approximate the score function [19]. The U-Net design, based on a Wide ResNet, integrates residual connections and self-attention blocks to preserve gradient flow and recover fine-grained image details. These methods could be roughly divided into pixel-level methods and latent-feature-level methods. The pixel-level methods directly operate the diffusion process in the pixel space, including GLIDE [71] that introduced “classifier-free guidance” and Imagen [72] that employ the pretrained large language model, i.e., T5-XXL [23], as text encoder. However, these methods suffer expensive raining and inference computation costs, leading
to the development of Latent Diffusion Models (LDMs) [14] that operate in the latent space of a pre-trained variational autoencoder. LDMs achieve computational efficiency while preserving high-generation quality, thus inspiring various diffusion-based generative models, including VQ-Diffusion [73], SD 2.0 [74], SD XL [75], and UPainting [76].
Advancements in transformer architectures have led to the adoption of transformer-based models in diffusion processes. The pioneering Diffusion Transformers (DiT) [20] transforms input images into a sequence of patches and feeds them through a series of transformer blocks. DiT takes additional conditional information such as the diffusion timestep t t t and a conditioning signal c c c as inputs. The success of DiT inspired many advanced generative methods, including REPA [77] that injects self-supervised visual representations into diffusion training to strengthen large-scale performance, SD 3.0 [15] use two separate sets of weights to model text and image modality, and others [78], [79], [80]. For text encoders, these methods primarily use utilized contrastive learning to align image and text modalities in a shared latent space, which jointly trained separate image and text encoders on large-scale image-caption pairs [22], [53], [81]. Specifically, GLIDE [71] explores both CLIP guidance and classifier-free guidance, demonstrating that CLIP-conditioned diffusion outperforms earlier GAN baselines and supports powerful text-driven editing. SD [14] employs a frozen CLIP-ViT-L/14 encoder to condition its latent diffusion denoiser, achieving high-quality samples with efficient computation. SD 3.0 [15] utilizes CLIP ViT-L/14, OpenCLIP bigG/14, and T5-v1.1 XXL to transform text into embeddings for generation guidance.
Recent advancements in diffusion models have incorporated LLMs to enhance text-to-image diffusion generation [82], [83], which significantly improves the text-image alignment as well as the quality of generated images. RPG [83] leverages the vision-language prior of multimodal LLMs to reason out complementary spatial layouts from text prompts, and manipulates the object compositions for diffusion models in both text-guided image generation and editing process. However, these methods require different model architectures, training strategies, and parameter configurations for specific tasks, which presents challenges in managing these models. A more scalable solution is to adopt a unified generation model capable of handling a variety of data generation tasks [84], [85], [86], [87]. OmniGen [84] achieves text-to-image generation capabilities and supports various downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. UniReal [85] treats image-level tasks as discontinuous video generation, treating varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, customization, and composition. GenArtist [86] provides a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. UniVG [87] treats multi-modal inputs as unified conditions with a single set of weights to enable various downstream applications. As research in this domain advances, it is expected that increasingly unified models will emerge, capable of addressing a broader spectrum of image generation and editing tasks.
Autoregressive models. Autoregressive (AR) models de
将序列的联合分布分解为条件概率的乘积,从而依次根据所有先前生成的元素来预测每个元素。该范式最初为语言建模而设计,已成功通过将图像映射为一维离散代币序列(像素、图像补丁或潜在代码)而被应用于视觉领域。形式上,给定序列 x = ( x 1 , x 2 , … , x N ) x = (x_{1}, x_{2}, \dots, x_{N}) x=(x1,x2,…,xN) ,模型被训练为在条件化于所有前序元素的情况下生成每个元素:
p ( x ) = ∏ i = 1 N p ( x i ∣ x 1 , x 2 , … , x i − 1 ; θ ) . (4) p (x) = \prod_ {i = 1} ^ {N} p \left(x _ {i} \mid x _ {1}, x _ {2}, \dots , x _ {i - 1}; \theta\right). \tag {4} p(x)=i=1∏Np(xi∣x1,x2,…,xi−1;θ).(4)
其中 θ \theta θ 是模型参数。训练目标是最小化负对数似然(NLL)损失:
L ( θ ) = − ∑ i = 1 N log p ( x i ∣ x 1 , x 2 , … , x i − 1 ; θ ) . (5) \mathcal {L} (\theta) = - \sum_ {i = 1} ^ {N} \log p \left(x _ {i} \mid x _ {1}, x _ {2}, \dots , x _ {i - 1}; \theta\right). \tag {5} L(θ)=−i=1∑Nlogp(xi∣x1,x2,…,xi−1;θ).(5)
如图4所示,现有方法基于序列表示策略分为三类:基于像素、基于代币和多代币模型。
- 基于像素的模型。PixelRNN [88] 是下一个像素预测的开创性方法。它将二维图像转换为一维像素序列,并使用 LSTM 层基于先前生成的值按序生成每个像素。虽然在建模空间依赖方面有效,但它存在计算成本高的问题。
PixelCNN[89] 引入了扩张卷积,以更高效地捕捉长程像素依赖,而 PixelCNN++ [90] 利用离散化对数混合似然和架构改进来提高图像质量和效率。一些先进工作 [91] 还提出了并行化方法,以降低计算开销并实现更快的生成,尤其适用于高分辨率图像。
2)基于代币的模型。受自然语言处理范式启发,基于代币的自回归模型将图像转换为紧凑的离散代币序列,大幅缩短序列长度并支持高分辨率的合成。该过程从向量量化(VQ)开始:
一个通过重建和约束损失训练的编码器-解码器学习出紧凑的潜在索引码本,然后仅解码器Transformer对这些代币的条件分布进行建模[92]。典型的VQ模型包括VQ-VAE-2[93], VQGAN[32], ViT-VQGAN[94], 等[95], [96], [97]。许多工作致力于增强仅解码器
Transformer 模型。LlamaGen [24] 将 VQGAN 分词器应用于 LLaMA 骨干网络 [1], [2], 在与 DiTs 可比的性能下表明随着参数量增加,生成质量有所提升。与此同时,像 DeLVM [98] 这样的数据高效变体在显著减少数据量的情况下达到相当的逼真度,而诸如 AiM [26],、ZigMa [99], 和 DiM [100] 的模型则集成了线性或门控注意力层
从Mamba[101]提供更快的推理和更出色的性能。为丰富上下文建模,提出了随机和混合解码策略。像SAIM[102], RandAR[103], 和RAR[104]这样的方法通过随机重排补丁预测来克服僵化的光栅偏差,
while SAR [105] 将因果学习推广到任意顺序和跳跃间隔。混合框架进一步融合范式:RAL [106]使用对抗策略梯度来
缓解暴露偏差,ImageBART[107]将分层扩散更新与自回归解码交错进行,DisCo-Diff[108]则通过离散潜变量增强扩散解码器以获得同类最佳的FID。
- 多个代币的方法。为提高生成效率,近期的自回归模型已从生成单个代币转向将多个代币作为一组进行预测,在不损失质量的情况下实现了显著提速。下一补丁预测(NPP)[109] 将图像令牌聚合为具有高信息密度的补丁级标记,从而显著减少序列长度。类似地,下一块预测(NBP)[110] 将分组扩展到较大的空间块,例如行或整个帧。相邻自回归(NAR) [111] 提出使用局部的“下一邻居”机制向外预测,而并行自回归(PAR) [112] 则将代币划分为不相交的子集以实现并发解码。MAR [25] 放弃了分-
放弃了固定的标记化和固定顺序,转而采用使用扩散损失训练的连续表示。除了空间分组之外,VAR [113] 引入了粗到细的下一级尺度范式,这启发了各种高级方法,
包括FlowAR[114]、M-VAR[115]、FastVAR[116]和FlexVAR[117]。一些基于频率的方法在频谱上将生成过程分解:FAR[118]和NFIG[119]合成
低频结构,然后再细化高频细节。
xAR [120] 抽象地统一了自回归单元,包括补丁、单元、尺度或整个图像,在单一框架下。这些多标记方法展示了为在现代图像生成中平衡保真度、效率和可扩展性而定义适当自回归单元的重要性,
图像生成。
控制机制也已被集成到自回归解码器中以实现更精确的编辑。ControlAR [121] 在解码过程中引入了诸如边缘图和深度线索等空间约束,从而允许对标记级编辑进行细粒度控制。ControlVAR [122] 通过在图像级特征上实现尺度感知条件化进一步推进了这一概念,增强了一致性和可编辑性。CAR [123] 在类似概念上进行了阐述,聚焦于自回归模型中的高级控制机制,以增强视觉输出的细节和适应性。对于涉及多个对象或时间上一致序列的复杂场景,
Many-to-Many Diffusion (M2M) [124] 将自回归框架适配用于多帧生成,
eration,确保图像之间的语义和时序一致性。MSGNet[125]将VQ-VAE与自回归建模相结合,以在场景中的多个实体之间保留空间-语义对齐。在医疗领域,MVG[126]将自回归图像到图像生成扩展到分割、合成和去噪等任务,通过以成对的提示-图像输入作为条件来实现这些任务。这些文本-
到图像生成的自回归方法提供了模型架构和视觉建模方法的基础,有效推进了用于理解和生成的统一多模态模型的研究。
3 统一多模态模型:用于理解和生成
统一多模态模型旨在构建一个能够同时理解和生成数据的单一架构
fine the joint distribution of a sequence by factorizing it into a product of conditional probabilities, whereby each element is predicted in turn based on all previously generated elements. This paradigm, originally devised for language modeling, has been successfully adapted to vision by mapping an image to a 1D sequence of discrete tokens (pixels, patches, or latent codes). Formally, given a sequence x = ( x 1 , x 2 , … , x N ) x = (x_{1},x_{2},\dots,x_{N}) x=(x1,x2,…,xN) , the model is trained to generate each element by conditioning all preceding elements:
p ( x ) = ∏ i = 1 N p ( x i ∣ x 1 , x 2 , … , x i − 1 ; θ ) . (4) p (x) = \prod_ {i = 1} ^ {N} p \left(x _ {i} \mid x _ {1}, x _ {2}, \dots , x _ {i - 1}; \theta\right). \tag {4} p(x)=i=1∏Np(xi∣x1,x2,…,xi−1;θ).(4)
where θ \theta θ is the model parameters. The training objective is to minimize the negative log-likelihood(NLL) loss:
L ( θ ) = − ∑ i = 1 N log p ( x i ∣ x 1 , x 2 , … , x i − 1 ; θ ) . (5) \mathcal {L} (\theta) = - \sum_ {i = 1} ^ {N} \log p \left(x _ {i} \mid x _ {1}, x _ {2}, \dots , x _ {i - 1}; \theta\right). \tag {5} L(θ)=−i=1∑Nlogp(xi∣x1,x2,…,xi−1;θ).(5)
As shown in Fig. 4, existing methods are divided into three types based on sequence representation strategies: pixel-based, token-based, and multiple-token-based models.
-
Pixel-based models. PixelRNN [88] was the pioneering method for next-pixel prediction. It transforms a 2D image into a 1D sequence of pixels and employs LSTM layers to sequentially generate each pixel based on previously generated values. While effective in modeling spatial dependencies, it suffers from high computational costs. PixelCNN [89] introduces dilated convolutions to more efficiently capture long-range pixel dependencies, while PixelCNN++ [90] leverages a discretized logistic mixture likelihood and architectural refinements to enhance image quality and efficiency. Some advanced works [91] have also proposed parallelization methods to reduce computational overhead and enable faster generation, particularly for high-resolution images.
-
Token-based models. Inspired by natural language processing paradigms, token-based AR models convert images into compact sequences of discrete tokens, greatly reducing sequence length and enabling high-resolution synthesis. This process begins with vector quantization (VQ): an encoder-decoder trained with reconstruction and commitment losses learns a compact codebook of latent indices, after which a decoder-only transformer models the conditional distribution over those tokens [92]. Typical VQ models include VQ-VAE-2 [93], VQGAN [32], ViT-VQGAN [94], and others [95], [96], [97] Many works have been investigated to enhance the decoder-only transformer models. LlamaGen [24] applies the VQGAN tokenizer to LLaMA backbones [1], [2], achieving comparable performance with DiTs and showing that generation quality improves with the increase of parameters. In parallel, data-efficient variants like DeLVM [98] achieve comparable fidelity with substantially less data, and models such as AiM [26], ZigMa [99], and DiM [100] integrate linear or gated attention layers from Mamba [101] to deliver faster inference and superior performance. To enrich contextual modeling, stochastic and hybrid decoding strategies have been proposed. Methods like SAIM [102], RandAR [103], and RAR [104] randomly permute patch predictions to overcome rigid raster biases, while SAR [105] generalizes causal learning to arbitrary orders and skip intervals. Hybrid frameworks further blend paradigms: RAL [106] uses adversarial policy gradients to
mitigate exposure bias, ImageBART [107] interleaves hierarchical diffusion updates with AR decoding, and DisCo-Diff [108] augments diffusion decoders with discrete latent for best-in-class FID.
- Multiple-tokens-based methods. To improve generation efficiency, recent AR models have shifted from generating individual tokens to predicting multiple tokens as a group, achieving significant speedups without quality loss. Next Patch Prediction (NPP) [109] aggregates image tokens into patch-level tokens with high information density, thus significantly reducing sequence length. Similarly, Next Block Prediction (NBP) [110] extends grouping to large spatial blocks, such as rows or entire frames. Neighboring AR (NAR) [111] proposes to predict outward using a localized “next-neighbor” mechanism, and Parallel Autoregression (PAR) [112] partitions tokens into disjoint subsets for concurrent decoding. MAR [25] abandons discrete tokenization and fixed ordering in favor of continuous representations trained with a diffusion loss. Beyond spatial grouping, VAR [113] introduced a coarse-to-fine next-scale paradigm, which inspired various advanced methods, including FlowAR [114], M-VAR [115], FastVAR [116], and FlexVAR [117]. Some frequency-based methods decompose generation spectrally: FAR [118] and NFIG [119] synthesize low-frequency structures before refining high-frequency details. xAR [120] abstractly unifies autoregressive units, including patches, cells, scales, or entire images, under a single framework. These multiple-token methods demonstrate the importance of defining appropriate autoregressive units for balancing fidelity, efficiency, and scalability in modern image generation.
Control mechanisms have also been integrated into autoregressive decoders for more precise editing. ControlAR [121] introduces spatial constraints such as edge maps and depth cues during decoding, allowing fine-grained control over token-level edits. ControlVAR [122] further advances this concept by implementing scale-aware conditioning on image-level features, enhancing coherence and editability. CAR [123] elaborates on a similar concept, focusing on advanced control mechanisms in autoregressive models to enhance the detail and adaptability of visual outputs. For complex scenarios involving multiple objects or temporally coherent sequences, Many-to-Many Diffusion (M2M) [124] adapts the autoregressive framework for multi-frame generation, ensuring semantic and temporal consistency across images. MSGNet [125] combines VQ-VAE with autoregressive modeling to preserve spatial-semantic alignment across multiple entities in a scene. In the medical domain, MVG [126] extends autoregressive image-to-image generation to tasks such as segmentation, synthesis, and denoising by conditioning on paired prompt-image inputs. These text-to-image generation AR methods provide the basics of the model architecture and visual modeling methods, effectively advancing research on unified multimodal models for understanding and generation.
3 UNIFIED MULTIMODAL MODELS FOR UNDERSTANDING AND GENERATION
Unified multimodal models aim to build a single architecture capable of both understanding and generating data
统一多模态理解与生成模型概览。该表根据骨干网络、编码器-解码器架构以及所使用的具体扩散或自回归模型对模型进行分类。表中包含有关模型、编码器、解码器以及图像生成中使用的掩码的信息,并提供了这些模型的发布日期,突出了多模态架构随时间的发展。
表1
| 模型 | Type | 架构 | Date | |||
| 骨干网络 | 理解编码器 | 生成编码器 | 生成解码器 | |||
| 扩散模型 | ||||||
| Dual Diffusion [127] | a | D-DiT | SD-VAE | SD-VAE | Bidirect. | |
| UniDisc [128] | a | DiT | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | |
| MMaDA [129] | a | LLaDA | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | |
| FUDOKI [130] | a | DeepSeek-LLM | SigLIP | VQGAN | VQGAN | Bidirect. |
| Muddit [131] | a | Meissonic (MM-DiT) | VQGAN | VQGAN | Bidirect. | |
| 自回归模型 | ||||||
| LWM [29] | b-1 | LLaMa-2 | VQGAN | VQGAN | 因果 | |
| Chameleon [30] | b-1 | LLaMa-2 | VQ-IMG | VQ-IMG | 因果 | |
| ANOLE [132] | b-1 | LLaMa-2 | VQ-IMG | VQ-IMG | 因果 | |
| Emu3 [133] | b-1 | LLaMa-2 | SBER-MoVQGAN | SBER-MoVQGAN | 因果 | |
| MMAR [134] | b-1 | Qwen2 | SD-VAE + EmbeddingViT | 扩散MLP | Bidirect. | |
| Orthus [135] | b-1 | Chameleon | VQ-IMG+视觉嵌入。 | 扩散MLP | 因果 | |
| SynerGen-VL [136] | b-1 | InterLM2 | SBER-MoVQGAN | SBER-MoVQGAN | 因果 | |
| Liquid [137] | b-1 | GEMMA | VQGAN | VQGAN | 因果 | |
| UGen [138] | b-1 | TinyLlama | SBER-MoVQGAN | SBER-MoVQGAN | 因果 | |
| Harmon [139] | b-1 | Qwen2.5 | MAR | MAR | Bidirect. | |
| TokLIP [140] | b-1 | Qwen2.5 | VQGAN+SigLIP | VQGAN | 因果 | |
| Selftok [141] | b-1 | LLaMA3.1 | SD3-VAE+MMDiT | SD3 | 因果 | |
| Emu [142] | b-2 | LLaMA | EVA-CLIP | SD | 因果 | |
| LaVIT [143] | b-2 | LLaMA | EVA-CLIP | SD-1.5 | 因果 | |
| DreamLLM [34] | b-2 | LLaMA | OpenAI-CLIP | SD-2.1 | 因果 | |
| Emu2 [33] | b-2 | LLaMA | EVA-CLIP | SDXL | 因果 | |
| VL-GPT [35] | b-2 | LLaMA | OpenAI-CLIP | IP-Adapter | 因果 | |
| MM-Interleaved [144] | b-2 | Vicuna | OpenAI-CLIP | SD-v2.1 | 因果 | |
| Mini-Gemini [145] | b-2 | Gemma&Vicuna | OpenAI-CLIP+ConvNext | SDXL | 因果 | |
| VILA-U [146] | b-2 | LLaMA-2 | Siglip+RQ | RQ-VAE | 因果 | |
| PUMA [147] | b-2 | LLaMA-3 | OpenAI-CLIP | SDXL | Bidirect. | |
| MetaMorph [148] | b-2 | LLaMA | Siglip | SD-1.5 | 因果 | |
| ILLUME [149] | b-2 | Vicuna | UNIT | SDXL | 因果 | |
| UniTok [150] | b-2 | LLaMA-2 | ViTamin | ViTamin | 因果 | |
| QLIP [151] | b-2 | LLaMA-3 | QLIP-ViT+BSQ | BSQ-AE | 因果 | |
| DualToken [152] | b-2 | Qwen2.5 | Siglip | RQVAE | 因果 | |
| UniFork [153] | b-2 | Qwen2.5 | Siglip+RQ | RQ-VAE | 因果 | |
| UniCode2 [154] | b-2 | Qwen2.5 | Siglip+RQ | FLUX.1-dev/SD-1.5 | 因果 | |
| UniWorld [155] | b-2 | Qwen2.5-VL | Siglip2 | DiT | Bidirect. | |
| Pisces [156] | b-2 | LLaMA-3.1 | Siglip | EVA-CLIP | 扩散 | 因果 |
| Tar [157] | b-2 | Qwen2.5 | Siglip2+VQ | VQGAN/SANA | 因果 | |
| OmniGen2 [158] | b-2 | Qwen2.5-VL | Siglip | OmniGen | 因果 | |
| Ovis-U1 [159] | b-2 | Ovis | AimV2 | MMDiT | 因果 | |
| X-Omni [160] | b-2 | Qwen2.5-VL | QwenViT | Siglip | FLUX | 因果 |
| Qwen-Image [161] | b-2 | Qwen2.5-VL | QwenViT | MMDiT | 因果 | |
| Bifrost-1 [162] | b-2 | Qwen2.5-VL | QwenViT | ViT | FLUX | 因果 |
| SEED [163] | b-3 | OPT | SEED 分词器 | 可学习查询 | SD | 因果 |
| SEED-LLaMA [164] | b-3 | LLaMa-2 & Vicuna | SEED 分词器 | 可学习查询 | unCLIP-SD | 因果 |
| SEED-X [165] | b-3 | LLaMa-2 | SEED 分词器 | 可学习查询 | SDXL | 因果 |
| MetaQueriesies [166] | b-3 | LLaVA&Qwen2.5-VL | Siglip | 可学习查询 | Sana | 因果 |
| Nexus-Gen [167] | b-3 | Qwen2.5-VL | QwenViT | 可学习查询 | FLUX | 因果 |
| Ming-Lite-Uni [168] | b-3 | M2-omni | NavIT | 可学习查询 | Sana | 因果 |
| BLIP3-o [169] | b-3 | Qwen2.5-VL | OpenAI-CLIP | 可学习查询 | Lumina-Next | 因果 |
| OpenUni [170] | b-3 | InternVL3 | OpenAI-CLIP | 可学习查询 | Sana | 因果 |
| Ming-Omni [171] | b-3 | Ling | OpenAI-ViT | 可学习查询 | 多尺度 DiT | 因果 |
| UniLIP [172] | b-3 | InternVL3 | OpenAI-ViT | 可学习查询 | Sana | 因果 |
| TBAC-UniImage [173] | b-3 | Qwen2.5-VL | QwenViT | 可学习查询 | Sana | 因果 |
| Janus [174] | b-4 | DeepSeek-LLM | Siglip | VQGAN | VQGAN | Casual |
| Janus-Pro [175] | b-4 | DeepSeek-LLM | Siglip | VQGAN | VQGAN | Casual |
| OmniMamba [176] | b-4 | Mamba-2 | DINO-v2+Siglip | VQGAN | VQGAN | 因果 |
| UniFluid [177] | b-4 | Gemma-2 | Siglip | SD-VAE | 扩散MLP | 因果 |
| MindOmni [178] | b-4 | Qwen2.5-VL | QwenViT | VAE | OmniGen | 因果 |
| Skywork UniPic [179] | b-4 | Qwen2.5 | SigLIP2 | SDXL-VAE | SDXL-VAE | 因果 |
| MUSE-VL [180] | b-5 | Qwen-2.5&Yi-1.5 | SigLIP | VQGAN | VQGAN | 因果 |
| Tokenflow [181] | b-5 | Vicuna&Qwen-2.5 | OpenAI-CLIP | MSVQ | MSVQ | 因果 |
| VARGPT [182] | b-5 | Vicuna-1.5 | OpenAI-CLIP | MSVQ | VAR-D30 | 因果 |
| SemHiTok [183] | b-5 | Qwen2.5 | Siglip | ViT | ViT | 因果 |
| VARGPT-1.1 [184] | b-5 | Qwen2 | SigLIP | MSVQ | Infinity | 因果 |
| ILLUME+ [185] | b-5 | Qwen2.5 | QwenViT | MoVQGAN | SDXL | 因果 |
| UniToken [186] | b-5 | Chameleon | SigLIP | VQ-IMG | VQGAN | 因果 |
| Show-o2 [187] | b-5 | Qwen2.5 | Wan-3DVAE + Siglip | Wan-3DVAE | Wan-3DVAE | 因果 |
融合自回归与扩散模型
| Transfusion [38] | c-1 | LLaMA-2 | SD-VAE | SD-VAE | Bidirect. | 2024-08 |
| Show-o [39] | c-1 | LLaVA-v1.5-Phi | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | 2024-08 |
| MonoFormer [37] | c-1 | TinyLlama | SD-VAE | SD-VAE | Bidirect. | 2024-09 |
| LMFusion [188] | c-1 | LLaMA | SD-VAE+UNet下采样。 | SD-VAE+UNet上采样。 | Bidirect. | 2024-12 |
| Janus-flow [189] | c-2 | DeepSeek-LLM | Siglip | SDXL-VAE | 因果 | 2024-11 |
| 莫高 [190] | c-2 | Qwen2.5 | Siglip+SDXL-VAE | SDXL-VAE | Bidirect. | 2025-05 |
| BAGEL [191] | c-2 | Qwen2.5 | SigLIP | FLUX-VAE | FLUX-VAE | 2025-05 |
Overview of Unified Multimodal Understanding and Generation Models. This table categorizes models based on their backbone, encoder-decoder architecture, and the specific diffusion or autoregressive models used. It includes information on model, encoder, decoder and the mask used in image generation. The release dates of these models are also provided, highlighting the evolution of multimodal architectures over time.
TABLE 1
| Model | Type | Architecture | Date | ||||
| Backbone | Und. Enc. | Gen. Enc. | Gen. Dec. | Mask | |||
| Diffusion Model | |||||||
| Dual Diffusion [127] | a | D-DiT | SD-VAE | SD-VAE | Bidirect. | 2024-12 | |
| UniDisc [128] | a | DiT | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | 2025-03 | |
| MMDA [129] | a | LLaDA | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | 2025-05 | |
| FUDOKI [130] | a | DeepSeek-LLM | SigLIP | VQGAN | VQGAN | Bidirect. | 2025-05 |
| Muddit [131] | a | Meissonic (MM-DiT) | VQGAN | VQGAN | Bidirect. | 2025-05 | |
| Autoregressive Model | |||||||
| LWM [29] | b-1 | LLaMa-2 | VQGAN | VQGAN | Causal | 2024-02 | |
| Chameleon [30] | b-1 | LLaMa-2 | VQ-IMG | VQ-IMG | Causal | 2024-05 | |
| ANOLE [132] | b-1 | LLaMa-2 | VQ-IMG | VQ-IMG | Causal | 2024-07 | |
| Emu3 [133] | b-1 | LLaMA-2 | SBER-MoVQGAN | SBER-MoVQGAN | Causal | 2024-09 | |
| MMAR [134] | b-1 | Qwen2 | SD-VAE + EmbeddingViT | Diffusion MLP | Bidirect. | 2024-10 | |
| Orthus [135] | b-1 | Chameleon | VQ-IMG+Vision embed. | Diffusion MLP | Causal | 2024-11 | |
| SynerGen-VL [136] | b-1 | InterLM2 | SBER-MoVQGAN | SBER-MoVQGAN | Causal | 2024-12 | |
| Liquid [137] | b-1 | GEMMA | VQGAN | VQGAN | Causal | 2024-12 | |
| UGen [138] | b-1 | TinyLlama | SBER-MoVQGAN | SBER-MoVQGAN | Causal | 2025-03 | |
| Harmon [139] | b-1 | Qwen2.5 | MAR | MAR | Bidirect. | 2025-03 | |
| TokLIP [140] | b-1 | Qwen2.5 | VQGAN+SigLIP | VQGAN | Causal | 2025-05 | |
| Selftok [141] | b-1 | LLaMA3.1 | SD3-VAE+MMDiT | SD3 | Causal | 2025-05 | |
| Emu [142] | b-2 | LLaMA | EVA-CLIP | SD | Causal | 2023-07 | |
| LaVIT [143] | b-2 | LLaMA | EVA-CLIP | SD-1.5 | Causal | 2023-09 | |
| DreamLLM [34] | b-2 | LLaMA | OpenAI-CLIP | SD-2.1 | Causal | 2023-09 | |
| Emu2 [33] | b-2 | LLaMA | EVA-CLIP | SDXL | Causal | 2023-12 | |
| VL-GPT [35] | b-2 | LLaMA | OpenAI-CLIP | IP-Adapter | Causal | 2023-12 | |
| MM-Interleaved [144] | b-2 | Vicuna | OpenAI-CLIP | SD-v2.1 | Causal | 2024-01 | |
| Mini-Gemini [145] | b-2 | Gemma&Vicuna | OpenAI-CLIP+ConvNext | SDXL | Causal | 2024-03 | |
| VILA-U [146] | b-2 | LLaMA-2 | SigLIP+RQ | RQ-VAE | Causal | 2024-09 | |
| PUMA [147] | b-2 | LLaMA-3 | OpenAI-CLIP | SDXL | Bidirect. | 2024-10 | |
| MetaMorph [148] | b-2 | LLaMA | SigLIP | SD-1.5 | Causal | 2024-12 | |
| ILLUME [149] | b-2 | Vicuna | UNIT | SDXL | Causal | 2024-12 | |
| UniTok [150] | b-2 | LLaMA-2 | ViTamin | ViTamin | Causal | 2025-02 | |
| QLIP [151] | b-2 | LLaMA-3 | QLIP-ViT+BSQ | BSQ-AE | Causal | 2025-02 | |
| DualToken [152] | b-2 | Qwen2.5 | SigLIP | RQVAE | Causal | 2025-03 | |
| UniFork [153] | b-2 | Qwen2.5 | SigLIP+RQ | RQ-VAE | Causal | 2025-06 | |
| UniCode2 [154] | b-2 | Qwen2.5 | SigLIP+RQ | FLUX.1-dev / SD-1.5 | Causal | 2025-06 | |
| UniWorld [155] | b-2 | Qwen2.5-VL | SigLIP2 | DIt | Bidirect. | 2025-06 | |
| Pisces [156] | b-2 | LLaMA-3.1 | SigLIP | EVA-CLIP | Diffusion | Causal | 2025-06 |
| Tar [157] | b-2 | Qwen2.5 | SigLIP2+VQ | VQGAN / SANA | Causal | 2025-06 | |
| OmniGen2 [158] | b-2 | Qwen2.5-VL | SigLIP | OmniGen | Causal | 2025-06 | |
| Ovis-U1 [159] | b-2 | Ovis | AimV2 | MMDIT | Causal | 2025-06 | |
| X-Omni [160] | b-2 | Qwen2.5-VL | QwenViT | Siglip | FLUX | Causal | 2025-07 |
| Qwen-Image [161] | b-2 | Qwen2.5-VL | QwenViT | MMDIT | Causal | 2025-08 | |
| Bifrost-1 [162] | b-2 | Qwen2.5-VL | QwenViT | ViT | FLUX | Causal | 2025-08 |
| SEED [163] | b-3 | OPT | SEED Tokenizer | Learnable Query | SD | Causal | 2023-07 |
| SEED-LLaMA [164] | b-3 | LLaMa-2 & Vicuna | SEED Tokenizer | Learnable Query | unCLIP-SD | Causal | 2023-10 |
| SEED-X [165] | b-3 | LLaMa-2 | SEED Tokenizer | Learnable Query | SDXL | Causal | 2024-04 |
| MetaQueries [166] | b-3 | LLaVA&Qwen2.5-VL | SigLIP | Learnable Query | Sana | Causal | 2025-04 |
| Nexus-Gen [167] | b-3 | Qwen2.5-VL | QwenViT | Learnable Query | FLUX | Causal | 2025-04 |
| Ming-Lite-Uni [168] | b-3 | M2-omni | NaViT | Learnable Query | Sana | Causal | 2025-05 |
| BLIP3-o [169] | b-3 | Qwen2.5-VL | OpenAI-CLIP | Learnable Query | Lumina-Next | Causal | 2025-05 |
| OpenUni [170] | b-3 | InternVL3 | InternViT | Learnable Query | Sana | Causal | 2025-05 |
| Ming-Omni [171] | b-3 | Ling | QwenViT | Learnable Query | Multi-scale DiT | Causal | 2025-06 |
| UniLIP [172] | b-3 | InternVL3 | InternViT | Learnable Query | Sana | Causal | 2025-07 |
| TBAC-Unilmage [173] | b-3 | Qwen2.5-VL | QwenViT | Learnable Query | Sana | Causal | 2025-08 |
| Janus [174] | b-4 | DeepSeek-LLM | SigLIP | VQGAN | VQGAN | Causal | 2024-10 |
| Janus-Pro [175] | b-4 | DeepSeek-LLM | SigLIP | VQGAN | VQGAN | Causal | 2025-01 |
| OmniMamba [176] | b-4 | Mamba-2 | DINO-v2+SigLIP | VQGAN | VQGAN | Causal | 2025-03 |
| Unifluid [177] | b-4 | Gemma-2 | SigLIP | SD-VAE | Diffusion MLP | Causal | 2025-03 |
| MindOmni [178] | b-4 | Qwen2.5-VL | QwenViT | VAE | OmniGen | Causal | 2025-06 |
| Skywork UniPic [179] | b-4 | Qwen2.5 | SigLIP2 | SDXL-VAE | SDXL-VAE | Causal | 2025-08 |
| MUSE-VL [180] | b-5 | Qwen-2.5&Yi-1.5 | SigLIP | VQGAN | VQGAN | Causal | 2024-11 |
| Tokenflow [181] | b-5 | Vicuna&Qwen-2.5 | OpenAI-CLIP | MSVQ | MSVQ | Causal | 2024-12 |
| VARGPT [182] | b-5 | Vicuna-1.5 | OpenAI-CLIP | MSVQ | VAR-d30 | Causal | 2025-01 |
| SemHiTok [183] | b-5 | Qwen2.5 | SigLIP | ViT | ViT | Causal | 2025-03 |
| VARGPT-1.1 [184] | b-5 | Qwen2.5 | SigLIP | MSVQ | Infinity | Causal | 2025-04 |
| ILLUME+ [185] | b-5 | Qwen2.5 | QwenViT | MoVQGAN | SDXL | Causal | 2025-04 |
| UniToken [186] | b-5 | Chameleon | SigLIP | VQ-IMG | VQGAN | Causal | 2025-04 |
| Show-o2 [187] | b-5 | Qwen2.5 | Wan-3DVAE + SigLIP | Wan-3DVAE | Wan-3DVAE | Causal | 2025-06 |
| Fused Autoregressive and Diffusion Model | |||||||
| Transfusion [38] | c-1 | LLaMA-2 | SD-VAE | SD-VAE | Bidirect. | 2024-08 | |
| Show-o [39] | c-1 | LLaVA-v1.5-Phi | MAGVIT-v2 | MAGVIT-v2 | Bidirect. | 2024-08 | |
| MonoFormer [37] | c-1 | TinyLLaMA | SD-VAE | SD-VAE+UNet down. | Bidirect. | 2024-09 | |
| LFusion [188] | c-1 | LLaMA | SD-VAE+UNet down. | 2024-12 | |||
| Janus-flow [189] | c-2 | DeepSeek-LLM | SigLIP | SDXL-VAE | SDXL-VAE | Causal | 2024-11 |
| Mogao [190] | c-2 | Qwen2.5 | SigLIP+SDXL-VAE | SDXL-VAE | Bidirect. | 2025-05 | |
| BAGEL [191] | c-2 | Qwen2.5 | SigLIP | FLUX-VAE | Bidirect. | 2025-05 | |
图5.统一多模态理解与生成模型的分类。根据骨干架构,这些模型分为三大类:扩散、MLLM(AR)和MLLM(AR + Diffusion)。每一类又根据所采用的编码策略细分,包括像素编码、语义编码、可学习查询编码和混合编码。我们展示了这些类别内的架构变体及其对应的编码器-解码器配置。
表2
支持除图像和文本之外的模态输入/输出的任意到任意多模态模型概览。本表对支持
varie模砸码器和砸,用d阅凿出的韵意动韵类,以模布的这些模型远近年来向更广运多模交匝的转变arc hitecture mo mat
| 模型 | 架构 | Date | |||
| 骨干网络 | 模态编码器 | 模态解码器 | Mask | ||
| Next-GPT [192] | Vicuna | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 | 因果 | 2023-09 |
| Unified-IO 2 [193] | T5 | 音频频谱变换器+视觉 ViT | 音频 ViT-VQGAN + 视觉 VQGAN | 因果 | 2023-12 |
| Video-LaVIT [194] | LLaVA-1.5 | LaVIT+运动 VQ-VAE | SVD img2vid-xt | 因果 | 2024-02 |
| AnyGPT [195] | LLaMa-2 | EnCodec+SEED 分词器+SpeechTokenizer | EnCodec+SD+SoundStorm | 因果 | 2024-02 |
| X-VILA [196] | Vicuna | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 | 因果 | 2024-05 |
| MIO [197] | Yi-Base | SpeechTokenizer+SEED-Tokenizer | SpeechTokenizer+SEED 分词器 | 因果 | 2024-09 |
| Spider [198] | LLaMA-2 | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 | 因果 | 2024-11 |
| OmniFlow [199] | MMDiT | HiFiGen+SD-VAE+Flan-T5 | +Grounding DINO+SAM | Bidirect. | 2024-12 |
| M2-omni [200] | LLaMA-3 | paraformer-zh+NaViT | HiFiGen+SD-VAE+TinyLlama | Casual | 2025-02 |
跨越多种模态。这些模型旨在以统一的方式处理不同形式的输入(例如文本、图像、视频、音频)并在一种或多种模态中生成输出。一个典型的统一多模态框架可以抽象为三个核心组件:将不同输入模态投射到表示空间的模态特定编码器;整合多模态信息并实现跨模态推理的模态融合骨干;以及在目标模态中生成输出(例如文本生成或图像合成)的模态特定解码器。
在本节中,我们主要关注支持视觉-语言理解与生成的统一多模态模型,即以图像和文本作为输入并生成文本或图像作为输出的模型。如图5所示,现有的统一模型大体可以
划分为三种主要类型:扩散模型、自回归模型,以及融合的自回归 + 扩散模型。对于自回归模型,我们进一步根据其模态编码方法将其分为四个子类别:基于像素的编码、基于语义的编码、可学习查询编码和混合编码。这些编码策略分别代表了处理视觉和文本数据的不同方式,从而在多模态表示的集成度和灵活性上产生差异。融合的自回归 + 扩散模型根据模态编码分为两类:基于像素的编码和混合编码。这些模型结合了自回归和扩散技术的特性,为更统一且高效的多模态生成提供了有前景的方法。
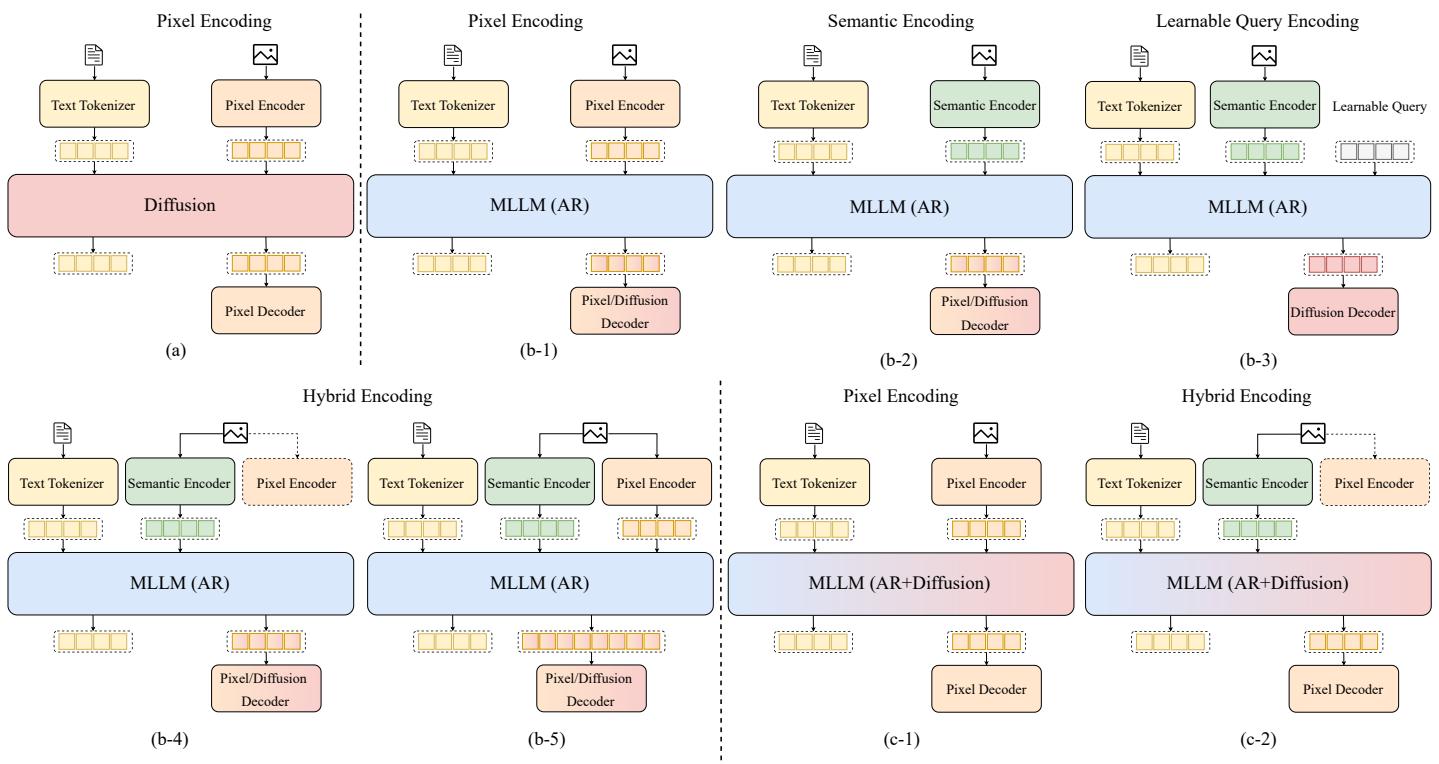
Fig. 5. Classification of Unified Multimodal Understanding and Generation Models. The models are divided into three main categories based on their backbone architecture: Diffusion, MLLM (AR), and MLLM (AR + Diffusion). Each category is further subdivided according to the encoding strategy employed, including Pixel Encoding, Semantic Encoding, Learnable Query Encoding, and Hybrid Encoding. We illustrate the architectural variations within these categories and their corresponding encoder-decoder configurations.
TABLE 2
Overview of Any-to-Any Multimodal Models Supporting Modal Input/Output Beyond Image and Text. This table categorizes models that support a variety of input and output modalities, including audio, music, image, video, and text. It includes information on the model’s backbone architecture, modality encoders and decoders, the type of attention mask used in vision generation, and the model release dates. These models exemplify the shift toward broader multimodal interactions in recent years.
| Model | Architecture | Date | |||
| Backbone | Modality Enc. | Modality Dec. | Mask | ||
| Next-GPT [192] | Vicuna | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 | Causal | 2023-09 |
| Unified-IO 2 [193] | T5 | Audio Spectrogram Transformer+Vision ViT | Audio ViT-VQGAN + Vision VQGAN | Causal | 2023-12 |
| Video-LaVIT [194] | LLaVA-1.5 | LaViT+Motion VQ-VAE | SVD img2vid-xt | Causal | 2024-02 |
| AnyGPT [195] | LLaMA-2 | Encodec+SEED Tokenizer+SpeechTokenizer | Encodec+SD+SoundStorm | Causal | 2024-02 |
| X-VILA [196] | Vicuna | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 | Causal | 2024-05 |
| MIO [197] | Yi-Base | SpeechTokenizer+SEED-Tokenizer | SpeechTokenizer+SEED Tokenizer | Causal | 2024-09 |
| Spider [198] | LLaMA-2 | ImageBind | AudioLDM+SD-1.5+Zeroscope-v2 +Grounding DINO+SAM | Causal | 2024-11 |
| OmniFlow [199] | MMDiT | HiFiGen+SD-VAE+Flan-T5 | HiFiGen+SD-VAE+TinyLlama | Bidirect. | 2024-12 |
| M2-omni [200] | LLaMA-3 | paraformer-zh+NaViT | CosyVoice-vocoder+SD-3 | Casual | 2025-02 |
across multiple modalities. These models are designed to process diverse forms of input (e.g., text, image, video, audio) and produce outputs in one or more modalities in a unified manner. A typical unified multimodal framework can be abstracted into three core components: modality-specific encoders that project different input modalities into a representation space; a modality-fusion backbone that integrates information from multiple modalities and enables cross-modal reasoning; and modality-specific decoders that generate output in the desired modality (e.g., text generation or image synthesis).
In this section, we primarily focus on unified multimodal models that support vision-language understanding and generation, i.e., models that take both image and text as input and produce either text or image as output. As shown in Fig. 5, existing unified models can be broadly
categorized into three main types: diffusion models, autoregressive models, and fused AR + diffusion models. For autoregressive models, we further classify them based on their modality encoding methods into four subcategories: pixel-based encoding, semantic-based encoding, learnable query-based encoding, and hybrid encoding. Each of these encoding strategies represents different ways of handling visual and textual data, leading to varying levels of integration and flexibility in the multimodal representations. Fused AR + diffusion models are divided into two subcategories based on modality encoding: pixel-based encoding and hybrid encoding. These models combine aspects of both autoregressive and diffusion techniques, offering a promising approach to more unified and efficient multimodal generation.
In the following sections, we will delve deeper into
每一类:第3.1节探讨基于扩散的模型,讨论它们在从噪声表示生成高质量图像和文本方面的独特优势。第3.2节聚焦于基于自回归的模型,详细说明不同编码方法如何影响它们在视觉-语言任务中的性能。第3.3节涵盖融合的AR + diffusion模型,审视这两种范式的结合如何增强多模态生成能力。最后,我们将讨论任意到任意的多模态模型,这类模型将该框架推广到超越视觉和语言的更广泛模态,如音频、视频和语音,旨在构建通用的、多用途的生成模型。
3.1扩散模型
扩散模型在图像生成领域取得了显著成功,这得益于若干关键优势。首先,与生成对抗网络(GANs)相比,它们提供了更高的样本质量,具有更好的模式覆盖能力,并缓解了诸如模式崩溃和训练不稳定性等常见问题 [201]。其次,训练目标——从略微扰动的数据中预测所添加的噪声——是一个简单的监督学习任务,避免了对抗性动态。第三,扩散模型高度灵活,允许在采样过程中融入各种条件信号,例如分类器引导[201]和无分类器引导[202],这提升了可控性和生成保真度。此外,噪声调度[203]和加速采样技术[204],[205]的改进显著降低了计算负担,使扩散模型越来越高效且具备可扩展性。
利用这些优势,研究人员已将扩散模型从单模态任务扩展到多模态生成,旨在在统一框架内支持文本与图像等输出。如图5(a)所示,在多模态扩散模型中,去噪过程不仅以时间步和噪声为条件,还以多模态上下文为条件,例如文本描述、图像或联合嵌入表示。这一扩展使不同模态之间能够同步生成,并允许在生成输出之间实现丰富的语义对齐。
一个具有代表性的例子是 Dual Diffusion [127], 它为联合文本和图像生成引入了双分支扩散过程。具体来说, 给定一对文本-图像, Dual Diffusion 首先使用预训练的 T5 encoder [23] 通过 softmax 概率建模对文本进行编码以获得离散文本表征, 然后使用来自 Stable Diffusion 的 VAE encoder [14] 对图像进行编码以获得连续的图像潜变量。文本和图像潜变量分别通过各自的前向扩散过程被加入噪声, 从而在每个时间步得到带噪的潜变量。在反向过程期间, 模型使用两个模态特定的去噪器联合去噪文本和图像潜变量: 一个基于 Transformer 的文本去噪器和一个基于 UNet 的图像去噪器。关键是, 在每个时间步, 去噪器引入跨模态条件化, 即文本潜变量对图像潜变量进行注意, 反之亦然, 使得在整个去噪轨迹中实现模态之间的语义对齐。去噪之后, 文本潜变量被解码为
通过T5解码器的自然语言,而图像潜变量通过VAE解码器被解码为高保真图像。训练由两项不同的损失项监督:图像分支最小化标准的噪声预测损失,而文本分支最小化对比对数损失。通过耦合这两条扩散链并引入显式的跨模态交互,Dual Diffusion能够从纯噪声生成连贯且可控的多模态内容。
不同于将离散文本扩散与基于 Stable Diffusion 的连续图像扩散相结合的 Dual Diffusion [127], [14], UniDisc [128] 采用了一个完全离散的扩散框架, 从头训练一个 Diffusion Transformer [206] 。它使用 LLaMA2 分词器 [2]对文本进行分词, 并通过 MAGVIT-v2 编码器 [207], 将图像转换为离散令牌, 从而实现两种模态在离散令牌空间中的统一。这些令牌经历离散的正向扩散过程, 在此过程中跨模态同时加入结构化噪声。在反向过程中, UniDisc 逐步对令牌进行去噪以生成连贯的序列。随后, LLaMA2 和 MAGVIT-v2 解码器将这些序列转换为高质量的文本和图像。通过采用完全离散的方法, UniDisc 能够同时细化文本和图像令牌, 提高推理效率并支持多样的跨模态条件控制。
与早期基于离散扩散的方法相比,FUDOKI [130] 引入了一种基于离散流匹配 [208] 的新型生成方法。在该框架下,FUDOKI 通过采用动力学最优、度量诱导的概率轨迹来建模噪声与数据分布之间的直接路径。该设计实现了一个连续的自我纠正机制,相较于早期模型中使用的简单掩码策略具有明显优势。FUDOKI 的模型架构基于 Janus-1.5B [174],但为支持统一的视觉-语言离散流建模做出了重要修改。其中一项关键改动是将标准的因果掩码替换为全注意力掩码,使每个令牌都能关注所有其他令牌,从而增强全局上下文理解。尽管该修改移除了显式的因果结构,模型仍通过将输出 logits 向后平移一位来支持下一个代币预测。另一个重要区别在于 FUDOKI 处理时间或损坏等级的方式。与扩散模型中所需的显式时间步嵌入不同,FUDOKI 直接从输入数据推断损坏状态。沿用 Janus-1.5B 的设计,FUDOKI 将理解与生成的处理路径解耦。为了图像理解,采用了 SigLIP 编码器[209] 来捕捉高层语义特征;而用于图像生成的则是来自 LlamaGen 的基于 VQGAN 的分词器 [24],它将图像编码为低层离散令牌序列。在输出阶段,Janus-1.5B 骨干网络生成的特征嵌入会传入模态特定的输出头,以生成最终的文本和图像输出。
类似地,Muddit [131] 引入了一个用于双向生成的统一模型,使用纯离散扩散框架来处理文本和图像。其架构特点是采用单一的 Multimodal DiffusionTransformer (MM-DiT),其架构设计与 FLUX [210] 相似。为了利用强大的图像先验,MM-DiT
each category: Section 3.1 explores diffusion-based models, discussing their unique advantages in terms of generating high-quality images and text from noisy representations. Section 3.2 focuses on autoregressive-based models, detailing how different encoding methods impact their performance in vision-language tasks. Section 3.3 covers fused AR + diffusion models, examining how the combination of these two paradigms can enhance multimodal generation capabilities. Finally, we extend our discussion to any-to-any multimodal models, which generalize this framework beyond vision and language to support a broader range of modalities such as audio, video, and speech, with the aim of building universal, general-purpose generative models.
3.1 Diffusion Models
Diffusion models have achieved remarkable success in the field of image generation owing to several key advantages. First, they provide superior sample quality compared to generative adversarial networks (GANs), offering better mode coverage and mitigating common issues such as mode collapse and training instability [201]. Second, the training objective—predicting the added noise from slightly perturbed data—is a simple supervised learning task that avoids adversarial dynamics. Third, diffusion models are highly flexible, allowing the incorporation of various conditioning signals during sampling, such as classifier guidance [201] and classifier-free guidance [202], which enhances controllability and generation fidelity. Furthermore, improvements in noise schedules [203] and accelerated sampling techniques [204], [205] have significantly reduced the computational burden, making diffusion models increasingly efficient and scalable.
Leveraging these strengths, researchers have extended diffusion models beyond unimodal tasks toward multimodal generation, aiming to support both text and image outputs within a unified framework. As shown in Fig. 5 (a), in multimodal diffusion models, the denoising process is conditioned not only on timestep and noise but also on multimodal contexts, such as textual descriptions, images, or joint embeddings. This extension enables synchronized generation across different modalities and allows for rich semantic alignment between generated outputs.
A representative example is Dual Diffusion [127], which introduces a dual-branch diffusion process for joint text and image generation. Specifically, given a text-image pair, Dual Diffusion first encodes the text using a pretrained T5 encoder [23] with softmax probability modeling to obtain discrete text representations, and encodes the image using the VAE encoder from Stable Diffusion [14] to obtain continuous image latents. Both text and image latents are independently noised through separate forward diffusion processes, resulting in noisy latent variables at each timestep. During the reverse process, the model jointly denoises the text and image latents using two modality-specific denoisers: a Transformer-based text denoiser and a UNet-based image denoiser. Crucially, at each timestep, the denoisers incorporate cross-modal conditioning, where the text latent attends to the image latent and vice versa, enabling semantic alignment between the modalities throughout the denoising trajectory. After denoising, the text latent is decoded into
natural language via a T5 decoder, and the image latent is decoded into a high-fidelity image via the VAE decoder. Training is supervised by two distinct loss terms: the image branch minimizes a standard noise prediction loss, while the text branch minimizes a contrastive log-loss. By coupling the two diffusion chains and introducing explicit cross-modal interactions, Dual Diffusion enables coherent and controllable multimodal generation from pure noise.
Unlike Dual Diffusion [127], which combines discrete text diffusion with continuous image diffusion via Stable Diffusion [14], UniDisc [128] employs a fully discrete diffusion framework to train a Diffusion Transformer [206] from scratch. It tokenizes text using the LLaMA2 tokenizer [2] and converts images into discrete tokens with the MAGVIT-v2 encoder [207], allowing unification of both modalities in a discrete token space. These tokens undergo a discrete forward diffusion process, where structured noise is added simultaneously across modalities. In the reverse process, UniDisc progressively denoises the tokens to generate coherent sequences. The LLaMA2 and MAGVIT-v2 decoders then transform these sequences into high-quality text and images. By adopting a fully discrete approach, UniDisc enables simultaneous refinement of text and image tokens, enhancing inference efficiency and supporting versatile cross-modal conditioning.
In contrast to earlier discrete diffusion-based methods, FUDOKI [130] introduces a novel generative approach based on a discrete flow matching [208]. Under this framework, FUDOKI models a direct path between noise and data distributions by employing a kinetic-optimal, metric-induced probability trajectory. This design enables a continuous self-correction mechanism, which provides a clear advantage over the simple masking strategies used in earlier models. FUDOKI’s model architecture is based on Janus-1.5B [174]. However, it introduces essential modifications to support unified vision-language discrete flow modeling. One key change is the replacement of the standard causal mask with a full attention mask. This allows every token to attend to all others, thereby enhancing global contextual understanding. Although this modification removes the explicit causal structure, the model still supports next-token prediction by shifting its output logits by one position. Another important distinction is in the way FUDOKI handles time or corruption levels. Instead of relying on explicit timestep embeddings, as required in diffusion models, FUDOKI infers the corruption state directly from the input data. Following Janus-1.5B, FUDOKI decouples the processing paths for understanding and generation. A SigLIP encoder [209] is employed to capture high-level semantic features for image understanding, while a VQGAN-based tokenizer from LlamaGen [24] encodes the image into a sequence of low-level discrete tokens for image generation. At the output stage, the feature embeddings generated by the Janus-1.5B backbone are passed through modality-specific output heads to produce the final text and image outputs.
In a similar vein, Muddit [131] introduces a unified model for bidirectional generation using a purely discrete diffusion framework to handle text and images. Its architecture features a single Multimodal Diffusion Transformer (MM-DiT) with an architectural design similar to that of FLUX [210]. To leverage a strong image prior, the MM-DiT
生成器从Meissonic [211],初始化,该模型经过大量训练以用于高分辨率合成。两种模态都被量化到共享的离散空间,其中预训练的VQ-VAE [32]将图像编码为码书索引,CLIP模型[22]提供文本标记的嵌入。在统一训练期间,Muddit使用余弦调度策略对令牌进行掩码,单一的MM-DiT生成器被训练去预测基于另一模态条件的干净令牌。输出方面,轻量线性头解码文本标记,而VQ-VAE解码器重构图像,从而使一组参数即可处理文本和图像的生成。
在此基础上,MMaDA [129] 将扩散范式扩展为统一的多模态基础模型。它采用LLaDA-8B-Instruct [212] 作为语言骨干网络,并使用MAGVIT-v2 [213] 图像令牌器将图像转换为离散语义令牌。这个统一的令牌空间使得生成过程中多模态条件化无缝衔接。为提升跨模态的对齐,MMaDA引入了一种混合链式思维(CoT)微调策略,将文本与视觉任务之间的推理格式统一化。该对齐促成了冷启动强化学习,使得从一开始就能进行有效的后训练。此外,MMaDA融入了一种新颖的UniGRPO方法,这是一种为扩散模型设计的统一基于策略梯度的强化学习算法。UniGRPO通过利用多样化的奖励信号(如事实正确性、视觉-文本对齐和用户偏好)来实现对推理与生成任务的后训练优化。该设计确保模型在广泛能力上持续改进,而不是过拟合于狭窄的特定任务奖励。
尽管这些创新方法不断涌现,统一离散扩散模型领域仍存在显著挑战和局限。首要问题是推理效率。尽管像 Mercury [214] 和 Gemini Diffusion [215] 这样的模型在并行生成代币方面展示了高速度潜力,但大多数开源离散扩散模型在实际推理速度上仍落后于其自回归模型对应物。这种差距主要源于对键值缓存的支持不足以及在并行解码多个令牌时输出质量的下降。扩散模型的有效性也受到训练困难的制约。与每个代币都能提供学习信号的自回归训练不同,离散扩散训练只提供稀疏监督,因为损失是在随机选择的被掩盖令牌子集上计算的,这导致对训练语料的利用效率低下且方差高。此外,这些模型表现出长度偏差,并且由于缺乏像自回归模型中序列结束令牌那样的内建停止机制,难以在不同输出长度间泛化。架构和支撑基础设施方面也需要进一步开发。在架构上,许多现有模型沿用了最初为自回归系统设计的结构,这种出于工程简化而采用的方法并不总是适合扩散过程——扩散过程旨在以根本不同于自回归模型序列性质的方式捕捉联合数据分布。在基础设施方面,对离散扩散模型的支持仍然有限。与成熟的
可用于自回归模型的框架相比,它们缺乏成熟的流水线和稳健的开源选项。这一差距阻碍了公平比较,减缓了研究进展,并使实际部署变得复杂。要推进统一离散扩散模型的能力和实际应用,必须解决这些在推理、训练、架构和基础设施方面相互关联的挑战。
3.2 自回归模型
统一多模态理解与生成模型的一个主要方向采用自回归(AR)架构,其中视觉和语言代币通常被串行化并按顺序建模。在这些模型中,主干Transformer通常改造自大型语言模型(LLMs),例如LLaMA系列[1],[2],[216],Vicuna[58],Gemma系列[217],[218],[219],和Qwen系列[5],[6],[9],[10],作为统一的模态融合模块,自回归地预测多模态输出。
如图5所示,为了将视觉信息整合到AR框架中,现有方法在模态编码期间提出了不同的图像标记化策略。这些方法大致可分为四类:基于像素、基于语义、基于可学习查询和混合编码方法。
- 基于像素的编码。如图 5(b-1) 所示,基于像素的编码通常指将图像表示为由预训练自编码器获得的连续或离散代币,这些自编码器仅通过图像重构进行监督。
构建,例如类VQGAN的模型[32],[220],[221],[222]。这些Encoder将高维像素空间压缩到紧凑的潜在空间,其中每个空间补丁对应一个图像令牌。在统一的多模态自回归模型中,从此类编码器序列化的图像令牌被以类似于文本标记的方式处理,允许
两种模态在单一序列内被建模。
最近的工作采用并通过各种编码器设计增强了基于像素的分词方法。LWM [29] 使用 VQGAN 分词器 [32] 将图像编码为离散潜在代码,而无需语义监督。它提出了一个多模态世界建模框架,其中视觉和文本代币被串行化在一起,以进行统一的自回归建模。通过仅通过基于重建的视觉代币和文本描述来学习世界动力学,LWM 表明大规模多模态生成在没有专门语义分词的情况下也是可行的。Chameleon [30] 和 ANOLE [132] 都采用了 VQ-IMG [222], ——一种为内容丰富的图像生成设计的改进型 VQ-VAE 变体。与标准 VQGAN 分词器相比,VQ-IMG 具有更深的编码器、更大的感受野,并包含残差预测以更好地保留复杂的视觉细节。该增强使 Chameleon 和 ANOLE 能更忠实地串行化图像内容,从而支持高质量的多模态生成。此外,这些模型促进了交错生成,允许在统一的自回归框架内交替生成文本和图像代币。Emu3 [133], 、SynerGen-VL [136] 和 UGen [138] 使用了 SBER-MoVQGAN [220], [221], ——一种多尺度 VQGAN 变体,将图像编码为既能捕捉全局结构又能捕捉细粒度
generator is initialized from Meissonic [211], a model extensively trained for high-resolution synthesis. Both modalities are quantized into a shared discrete space, where a pre-trained VQ-VAE [32] encodes images into codebook indices and a CLIP model [22] provides text token embeddings. During its unified training, Muddit employs a cosine scheduling strategy to mask tokens, and the single MM-DiT generator is trained to predict the clean tokens conditioned on the other modality. For output, a lightweight linear head decodes text tokens, while the VQ-VAE decoder reconstructs the image, allowing a single set of parameters to handle both text and image generation.
Building upon this foundation, MMaDA [129] scales up the diffusion paradigm toward a unified multimodal foundation model. It adopts LLaDA-8B-Instruct [212] as the language backbone and uses a MAGVIT-v2 [213] image tokenizer to convert images into discrete semantic tokens. This unified token space enables seamless multimodal conditioning during generation. To improve alignment across modalities, MMaDA introduces a mixed chain-of-thought (CoT) fine-tuning strategy, which unifies reasoning formats between text and vision tasks. This alignment facilitates cold-start reinforcement learning, allowing effective post-training from the outset. Furthermore, MMaDA incorporates a novel UniGRPO method, a unified policy-gradient-based RL algorithm designed for diffusion models. UniGRPO enables post-training optimization across both reasoning and generation tasks by leveraging diversified reward signals, such as factual correctness, visual-textual alignment, and user preferences. This design ensures the model consistently improves across a broad range of capabilities, rather than overfitting to a narrow task-specific reward.
Despite these innovative approaches, significant challenges and limitations persist in the landscape of unified discrete diffusion models. A primary concern is inference efficiency. Although models like Mercury [214] and Gemini Diffusion [215] demonstrate potential for high-speed parallel token generation, most open-source discrete diffusion models still lag behind the practical inference speeds of their autoregressive counterparts. This discrepancy is primarily due to a lack of support for key-value cache and the degradation in output quality that occurs when decoding multiple tokens in parallel. The effectiveness of diffusion models is also hindered by training difficulties. Unlike autoregressive training, where every token provides a learning signal, discrete diffusion training offers only sparse supervision, as the loss is computed on a randomly selected subset of masked tokens, leading to inefficient use of the training corpus and high variance. Moreover, these models exhibit a length bias and struggle to generalize across different output lengths because they lack a built-in stopping mechanism like the end-of-sequence token found in autoregressive models. Additional development is also needed in architecture and supporting infrastructure. Architecturally, many existing models reuse designs originally created for autoregressive systems, an approach chosen for engineering simplicity that is not always suited to the diffusion process, which aims to capture joint data distributions in a way that is fundamentally different from the sequential nature of autoregressive models. On the infrastructure side, support for discrete diffusion models remains limited. Compared to the mature
frameworks available for autoregressive models, they lack well-developed pipelines and robust open-source options. This gap hinders fair comparisons, slows research, and complicates real-world deployment. Addressing these interconnected challenges in inference, training, architecture, and infrastructure is essential to advance the capabilities and practical use of unified discrete diffusion models.
3.2 Auto-Regressive Models
One major direction in unified multimodal understanding and generation models adopts autoregressive (AR) architectures, where both vision and language tokens are typically serialized and modeled sequentially. In these models, a backbone Transformer, typically adapted from large language models (LLMs) such as LLaMA family [1], [2], [216], Vicuna [58], Gemma series [217], [218], [219], and Qwen series [5], [6], [9], [10], serves as the unified modality-fusion module to autoregressively predict multimodal outputs.
To integrate visual information into the AR framework, as shown in Fig. 5, existing methods propose different strategies for image tokenization during modality encoding. These approaches can be broadly categorized into four types: pixel-based, semantic-based, learnable query-based, hybrid-based encoding methods.
- Pixel-based Encoding. As shown in Fig. 5 (b-1), pixel-based encoding typically refers to the representation of images as continuous or discrete tokens obtained from pretrained autoencoders supervised purely by image reconstruction, such as VQGAN-like models [32], [220], [221], [222]. These encoders compress the high-dimensional pixel space into a compact latent space, where each spatial patch corresponds to an image token. In unified multimodal autoregressive models, image tokens serialized from such encoders are processed analogously to text tokens, allowing both modalities to be modeled within a single sequence.
Recent works have adopted and enhanced pixel-based tokenization with various encoder designs. LWM [29] employs a VQGAN tokenizer [32] to encode images into discrete latent codes without requiring semantic supervision. It proposes a multimodal world modeling framework, wherein visual and textual tokens are serialized together for unified autoregressive modeling. By learning world dynamics purely through reconstruction-based visual tokens and textual descriptions, LWM demonstrates that large-scale multimodal generation is feasible without specialized semantic tokenization. Both Chameleon [30] and ANOLE [132] adopt VQ-IMG [222], an improved VQ-VAE variant designed for content-rich image generation. Compared to standard VQGAN tokenizers, VQ-IMG features a deeper encoder with larger receptive fields and incorporates residual prediction to better preserve complex visual details. This enhancement enables Chameleon and ANOLE to serialize image content more faithfully, thereby supporting high-quality multimodal generation. Moreover, these models facilitate interleaved generation, allowing text and image tokens to be generated alternately within a unified autoregressive framework. Emu3 [133], SynerGen-VL [136] and UGen [138] employs SBER-MoVQGAN [220], [221], a multiscale VQGAN variant that encodes images into latent representations capturing both global structure and fine-grained
细节。通过利用多尺度分词,这些模型在保持高效训练吞吐量的同时,提高了用于自回归建模的视觉表示的表达力。与LWM [29],相似,Liquid [137]使用一种VQGAN风格的分词器,并发现了一个新见解:当在单一自回归目标和共享视觉代币表示下统一时,视觉理解与生成可以互相促进。此外,MMAR [134]、Orthus [135]、Harmon [139]引入了使用其对应编码器提取的连续值图像代币的框架,避免了与离散化相关的信息丢失。他们还通过在每个自回归图像补丁嵌入之上采用轻量级扩散头,将扩散过程与自回归骨干网络分离开来。该设计确保了骨干网络的隐藏表示不局限于最终的去噪步骤,从而促进了更好的图像理解。TokLIP[140]将低级离散VQGAN分词器与基于ViT的代币编码器SigLIP [209]集成,以捕捉高级连续语义,这不仅赋予视觉代币高级语义理解,还增强了低级生成能力。Selftok[141]提出了一种新颖的离散视觉自治分词器,在高质量重建与压缩率之间实现了良好折衷,同时为有效的视觉强化学习实现了最优策略改进。
除了MMAR[134]和Harmon[139],之外,这些模型在预训练和生成阶段都应用了因果注意力掩码,确保每个代币仅关注序列中之前的代币。它们采用下一个代币预测损失进行训练,其中图像和文本代币都以自回归方式被预测,从而统一了跨模态的训练目标。值得注意的是,在基于像素的编码方法中,用于从潜在代币重建图像的解码器通常遵循最初在类VQGAN模型中提出的配对解码器结构。这些解码器是经过专门优化的轻量级卷积架构,旨在将离散潜在网格映射回像素空间,主要关注精确的低层重建而非高级语义推理。此外,由于一些方法(例如MMAR[134],Orthus[135]和Harmon[139],)将图像标记为连续潜变量,它们采用轻量级扩散多层感知机作为解码器,将连续潜变量映射回像素空间。
尽管像素级编码方法有效,但它们存在若干固有局限:首先,由于视觉代币仅为像素级重建而优化,往往缺乏高层语义抽象,使得文本与图像表示之间的跨模态对齐更加困难。其次,基于像素的分词倾向于产生密集的代币网格,与仅文本模型相比,在高分辨率图像下会显著增加序列长度。这导致在自回归训练和推理过程中产生巨大的计算和内存开销,限制了可扩展性。第三,由于底层视觉编码器是以重建为中心的目标进行训练,所得视觉代币可能保留模态特定偏差,例如对纹理和低级模式的过度敏感,而这些并不一定有利于语义理解或精细颗粒度的跨模态推理。
- 语义编码。为克服基于像素的编码器固有的语义限制,越来越多的工作采用语义编码,即使用预训练的文本对齐视觉编码器处理图像输入,例如 OpenAI-CLIP [22]、SigLIP [209]、EVA-CLIP [36],或如 UNIT [223],这样更近的统一分词器,如图 5(b-2) 所示。其中一些模型将多模态自回归模型编码的多模态特征作为扩散模型的条件,从而在保留多模态理解能力的同时实现图像生成,例如使用 Qwen2.5-VL [10] 作为多模态模型并以增强的 OmniGen [224] 作为图像扩散模型的 OmniGen 2 [158];Ovis-U 1 [159] 通过引入定制设计的扩散 Transformer 将多模态模型 Ovis [12] 扩展为统一模型;Qwen-Image [161] 也类似地在 Qwen2.5-VL [10] 基础上集成了扩散 Transformer。然而,大多数此类模型在大规模图文对上以对比学习或回归为目标进行训练,生成的视觉嵌入在共享的语义空间中与语言特征高度对齐。这类表示能够实现更有效的跨模态对齐,对多模态理解与生成尤为有利。
若干具有代表性的模型采用不同的语义编码器和架构设计以支持统一的多模态任务。Emu [142], Emu2 [33], 和 LaViT [143]均采用 EVA-CLIP [36] 作为视觉编码器。值得注意的是,Emu [142]首次提出了将冻结的 EVA-CLIP 编码器、大型语言模型和扩散解码器结合的架构,以统一 VQA、图像描述和图像生成任务。Emu2 [33] 在 Emu [142] 的基础上提出了一个简化且可扩展的统一多模态预训练建模框架。它将 MLLM 模型规模扩展到 370 亿参数,从而显著增强了理解和生成能力。Bifrost-1 [162] 采用两个语义编码器:用于生成的 ViT 和用于理解的(在所用 MLLM(QWen2.5-VL)中使用的)编码器。预测的 CLIP 潜在表示用于连接 MLLM 与扩散模型。LaViT [143]引入了构建在 EVA-CLIP 之上的动态视觉分词机制。它使用选择器和合并器模块,基于内容复杂度自适应地从图像嵌入中选择视觉标记。该过程动态决定每张图像的视觉标记序列长度。动态分词在保留重要视觉线索的同时显著减少冗余信息,提高了训练效率和在图像描述、视觉问答及图像生成等任务中的生成质量。Dream-LLM [34], VL-GPT [35], MM-Interleaved [144], 和 PUMA [147] 均使用 OpenAI-CLIP 编码器 [22]。DreamLLM[34] 引入了一个轻量的线性投影,将 CLIP 嵌入与语言标记对齐,而 VL-GPT [35] 在 OpenAI-CLIP 视觉编码器之后采用了强大的 Casual Transformer,有效保留原始图像的语义信息和像素细节。MM-Interleaved[144] 和 PUMA [147] 都通过 CLIP 分词器结合简单的 ViT-Adapter 或池化操作提取多粒度图像特征,以提供精细的特征融合,从而支持丰富的多模态生成。Mini-Gemini [145]引入了一种需要双语义编码器的视觉标记增强机制,具体地,它利用
details. By leveraging multi-scale tokenization, these models improve the expressiveness of visual representations for autoregressive modeling while maintaining efficient training throughput. Similar with LWM [29], Liquid [137] utilizes a VQGAN-style tokenizer and uncovers a novel insight that visual understanding and generation can mutually benefit when unified under a single autoregressive objective and shared visual token representation. Moreover, MMAR [134], Orthus [135], Harmon [139] introduce the frameworks that utilize continuous-valued image tokens extracted by their corresponding encoders, avoiding the information loss associated with discretization. They also decouple the diffusion process from the AR backbone by employing lightweight diffusion heads atop each auto-regressed image patch embedding. This design ensures that the backbone’s hidden representations are not confined to the final denoising step, facilitating better image understanding. TokLIP [140] integrates a low-level discrete VQGAN tokenizer with a ViT-based token encoder SigLIP [209] to capture high-level continuous semantics, which not only empowers visual tokens with high-level semantic understanding but also enhances low-level generative capacity. Selftok [141] introduces a novel discrete visual self-consistency tokenizer, achieving a favorable trade-off between high-quality reconstruction and compression rate while enabling optimal policy improvement for effective visual reinforcement learning.
Across these models except for MMAR [134] and Harmon [139], causal attention masks are applied during both pretraining and generation phases, ensuring that each token only attends to preceding tokens in the sequence. They are trained using a next-token prediction loss, where both image and text tokens are predicted autoregressively, thus unifying the training objective across modalities. Notably, in pixel-based encoding approaches, the decoder used to reconstruct images from latent tokens typically follows the paired decoder structure originally proposed in VQGAN-like models. These decoders are lightweight convolutional architectures specifically optimized to map discrete latent grids back to the pixel space, focusing primarily on accurate low-level reconstruction rather than high-level semantic reasoning. Moreover, since some methods, like MMAR [134], Orthus [135] and Harmon [139], tokenize the image into continuous latents, they adopt the lightweight diffusion MLP as their decoder to map continuous latents back to the pixel space.
Despite their effectiveness, pixel-based encoding methods face several inherent limitations: First, since the visual tokens are optimized purely for pixel-level reconstruction, they often lack high-level semantic abstraction, making cross-modal alignment between text and image representations more challenging. Second, pixel-based tokenization tends to produce dense token grids, significantly increasing sequence lengths compared to text-only models, especially for high-resolution images. This leads to substantial computational and memory overhead during autoregressive training and inference, limiting scalability. Third, because the underlying visual encoders are trained with reconstruction-centric objectives, the resulting visual tokens may retain modality-specific biases, such as excessive sensitivity to textures and low-level patterns, which are not necessarily optimal for semantic understanding or fine-grained cross-modal reasoning.
- Semantic Encoding. To overcome the semantic limitations inherent in pixel-based encoders, a growing body of work adopts semantic encoding, where image inputs are processed using pretrained text-aligned vision encoders such as OpenAI-CLIP [22], SigLIP [209], EVA-CLIP [36], or more recent unified tokenizers like UNIT [223], as shown in Fig. 5 (b-2). Some of these models leverage the multimodal features encoded by the multimodal autoregressive model as conditions for a diffusion model, enabling image generation with retained multimodal understanding capabilities, like OmniGen2 [158] that utilizes Qwen2.5-VL [10] as the multimodal model and enhanced OmniGen [224] as the image diffusion model, Ovis-U1 [159] extending the multimodal model Ovis [12] into a unified model by incorporating a custom-designed diffusion transformer while Qwen-Image [161] similarly building upon Qwen2.5-VL [10] by integrating a diffusion transformer. However, most of these models are trained on large-scale image-text pairs with contrastive or regression-based objectives, producing visual embeddings that align closely with language features in a shared semantic space. Such representations enable more effective cross-modal alignment and are particularly beneficial for multimodal understanding and generation.
Several representative models leverage different semantic encoders and architectural designs to support unified multimodal tasks. Emu [142], Emu2 [33], and LaViT [143] all employ EVA-CLIP [36] as their vision encoder. Notably, Emu [142] introduces the initial architecture combining a frozen EVA-CLIP encoder, a large language model, and a diffusion decoder to unify VQA, image captioning, and image generation. Emu2 [33] builds upon Emu [142] by proposing a simplified and scalable modeling framework for unified multimodal pretraining. It scales the MLLM model up to 37B parameters, significantly enhancing both understanding and generation capabilities. Bifrost-1 [162] employs two semantic encoders, ViT for generation and the one employed in the used MLLM (QWen2.5-VL) for understanding. The predicted CLIP latents are used to bridge the MLLM and diffusion model. LaViT [143] introduces a dynamic visual tokenization mechanism built on top of EVA-CLIP. It employs a selector and merger module to adaptively select visual tokens from image embeddings based on content complexity. This process dynamically determines the length of the visual token sequence per image. The dynamic tokenization significantly reduces redundant information while preserving important visual cues, improving training efficiency and generation quality in tasks such as captioning, visual question answering, and image generation. DreamLLM [34], VL-GPT [35], and MM-Interleaved [144], and PUMA [147] utilize OpenAI-CLIP encoder [22]. DreamLLM [34] introduces a lightweight linear projection to align CLIP embeddings with language tokens, while VL-GPT [35] employs a powerful casual transformer after OpenAI-CLIP vision encoder to effectively retain both semantic information and pixel details of the original image. Both MM-Interleaved [144] and PUMA [147] extract multi-granular image features via a CLIP tokenizer with simple ViT-Adapter or pooling operation to provide fine-grained feature fusion, thus supporting rich multimodal generation. Mini-Gemini [145] introduces a visual token enhancement mechanism that requires dual semantic encoders. Specifically, it leverages
一个经过CLIP预训练的ViT编码器[22]来获取全局视觉标记,同时一个在LAION上预训练的ConvNeXt编码器提供密集的局部视觉信息。随后采用交叉注意力模块,通过引入来自密集编码器的细节视觉线索来细化全局视觉标记。经增强的全局标记随后与文本标记结合并由LLM处理,以实现联合的视觉-语言理解与生成。该设计有效弥合了CLIP特征的语义抽象与密集编码器的像素级精确度之间的差距。
MetaMorph [148] 采用 SigLIP [209] 提取视觉嵌入,并在预训练语言模型中引入模态特定适配器。这些适配器插入在多个 Transformer 层中,相较于浅层投影方法,允许更深层次的视觉-语言交互。ILLUME [149] 采用 UNIT [223] 作为其视觉编码器,以提供在语义对齐与像素级保真度之间平衡的统一表示。不同于仅专注于对比目标的 CLIP 类编码器,UNIT[223] 通过同时进行图像重建和对比对齐损失的联合训练,生成既适用于视觉-语言理解又适用于图像合成的标记。基于强大的 UNIT 分词器,ILLUME 有效生成既保留语义又保留像素级信息的图像标记,在包括图像描述、VQA、文本到图像以及交错生成在内的多项理解与生成任务中取得更佳表现。类似地,VILA-U [146] 和 UniTok [150] 模仿 UNIT [223] 引入图文对比学习,以获得一种在语义对齐与像素级保真度之间平衡的新型文本对齐视觉分词器。QLIP
[151] 通过实施二元球面量化来解决重建任务与文本-图像对齐任务之间的潜在冲突。Tar [157]通过利用LLMs的词汇表发起视觉码本,并结合尺度自适应池化与解码方法论。该方法使模型能够根据需要调整分词器的长度:在高效生成时采用粗粒度分词器,而在全面理解时采用细粒度分词器。在生成任务中,Tar利用扩散技术来增强自回归模型的视觉生成效果。UniFork [153]利用VILA-U的文本对齐视觉特征。然而,与在理解与生成中完全共享参数的MLLM不同,UniFork仅在浅层与这些任务共享参数,而在更深层由不同网络分别管理这些任务。该架构成功调和了共享学习与任务特化之间的平衡。UniCode[154]采用了级联码本。按照[225],中描述的方法,它使用来自聚类SigLIP特征的巨大码本作为冻结的基础码本,同时引入补充的可学习码本以细化特定任务的语义。这种分离增强了利用率并促进了稳健学习。近期的工作DualToken [152]使用SigLIP的浅层特征用于重建、深层特征用于语义学习,从而同时获得纹理和语义视觉特征。因此,DualToken [152]在重建和语义任务上都取得了优越的性能,同时展示出
在下游MLLM理解与生成任务中表现出显著效果。
X-Omni [160] 使用 SigLIP-VQ 作为视觉编码器,并采用强化学习来缓解与自回归推理相关的累积误差,同时减少离散编码固有的信息丢失。这一方法显著提升了离散自回归模型的生成质量,促进了图像与语言生成的无缝整合。
在大多数此类模型中,MLLM训练期间会应用因果注意力掩码,并使用下一个代币预测损失来优化文本与视觉代币的生成。对于图像生成,这些模型大多采用基于扩散的解码器,例如SD系列[14], [226], 、IP-adapter [227], FLUX [16],和Lumina-Next[228],它们与MLLM独立训练。推理时,MLLM先输出语义级视觉代币,然后将其传递给扩散解码器以生成最终图像。之所以选择将语义编码器与扩散解码器配对,是因为语义嵌入虽能编码高层概念信息,但缺乏直接像素重建所需的空间密度和低级粒度。扩散模型凭借其迭代去噪机制,特别适合将语义表示逐步细化为高分辨率、照片级真实感的图像,即使输入代币稀疏或抽象也能胜任。相比之下,尽管少数方法(如VILA-U [146]和UniTok [150])采用基于像素的解码器,但其生成的图像质量不及扩散解码器。因此,扩散解码器为语义压缩的视觉代币提供了更强健、更具表现力的解码路径,显著改善了文本-图像对齐、全局一致性和视觉保真度。UniWorld [155]与Pisces [156]致力于开发和扩展此类解决方案。
UniWorld 直接利用预训练 MLLM 的输出特征作为视觉理解的高层条件信号,同时使用 SigLIP 作为低层条件信号,为 DiT 提供全面的语义视觉控制。Pisces 在视觉生成任务中采用 EVA-CLIP 作为条件,并利用扩散进一步提升模型的视觉生成输出。针对不同任务,Pisces 引入了定制的视觉向量长度,并采用不同的 MLP 来编码条件。这种方法提升了模型设计的灵活性,同时相比单一编码器配置降低了推理成本。
尽管具有这些优势,语义编码也存在若干局限。首先,由于对低层线索的抽象,生成的视觉代币在像素级别上较难控制,从而难以执行细粒度图像编辑、局部修补或保持结构的变换。其次,语义编码器通常只提供全局或中层的表示,对于需要空间对应的任务(例如指称表达分割或姿势精确合成)可能不够用。最后,由于语义编码器和扩散解码器通常是分开训练的,缺乏端到端优化可能导致多模态大语言模型输出与解码器预期之间的不匹配,偶尔引发语义漂移或生成伪影。
a CLIP-pretrained ViT encoder [22] to obtain global visual tokens, while a LAION-pretrained ConvNeXt encoder provides dense local visual information. A cross-attention module is then employed to refine the global visual tokens by incorporating detailed visual cues from the dense encoder. These enhanced global tokens are subsequently combined with text tokens and processed by an LLM for joint vision-language understanding and generation. This design effectively bridges the semantic abstraction of CLIP features with the pixel-level precision of dense encoders. MetaMorph [148] employs SigLIP [209] to extract visual embeddings and introduces modality-specific adapters within a pretrained language model. These adapters are inserted throughout multiple transformer layers, allowing for deeper vision-language interaction compared to shallow projection approaches. ILLUME [149] adopt UNIT [223] as its vision encoder to provide a unified representation that balances semantic alignment and pixel-level fidelity. Unlike CLIP-like encoders that focus purely on contrastive objectives, UNIT [223] is jointly trained with both image reconstruction and contrastive alignment losses, producing tokens suitable for both vision-language understanding and image synthesis. Built on the powerful UNIT tokenizer, ILLUME effectively generates image tokens that retain both semantic and pixel-level information, which achieves better performance in multiple understanding and generation tasks, including captioning, VQA, text-to-image, and interleaved generation. Similarly, VILA-U [146] and UniTok [150] mimic UNIT [223] to introduce image-text contrastive learning to obtain a novel text-aligned vision tokenizer that balances semantic alignment and pixel-level fidelity. QLIP [151] addresses the potential conflict between reconstruction and text-image alignment tasks by implementing binary-spherical quantization. Tar [157] initiates the visual codebook by leveraging the vocabulary of LLMs and incorporates scale-adaptive pooling and decoding methodologies. This approach enables the model to adjust the length of the tokenizer according to the requirement: employing coarse-grained tokenizers for efficient generation and fine-grained tokenizers for comprehensive understanding. In generation tasks, Tar utilizes diffusion techniques to enhance the visual generation outcomes of AR models. UniFork [153] capitalizes on the text-aligned vision features of VILA-U. However, differentiating itself from the fully-shared parameters of understanding and generation MLLM, UniFork shares the parameters solely with these tasks at the shallow layer. At the deeper layer, these tasks are managed by distinct networks. This architecture successfully mediates the equilibrium between shared learning and task-specific specialization. UniCode[2] [154] employs a cascaded codebook. In line with the method outlined in [225], it utilizes a substantial codebook derived from clustered SigLIP feature as the frozen foundational codebook, while introducing supplementary learnable codebooks to refine semantics specific to particular tasks. This separation enhances utilization and fosters robust learning. Recent work DualToken [152] uses shallow-layer features of SigLIP for reconstruction and deep-layer features of SigLIP for semantic learning, thereby obtaining the texture and semantic visual features simultaneously. As a result, DualToken [152] achieves superior performance in both reconstruction and semantic tasks while demonstrating re
markable effectiveness in downstream MLLM understanding and generation tasks. X-Omni [160] utilizes SigLIP-VQ as a visual encoder and employs reinforcement learning to mitigate the cumulative error associated with autoregressive inference and to reduce the information loss inherent in discrete encoding. This methodology substantially enhances the generation quality of discrete autoregressive models, facilitating a seamless integration of image and language generation.
Across most of these models, causal attention masks are applied during MLLM training, and next-token prediction loss is used to optimize both text and vision token generation. For image generation, most of these models typically employ diffusion-based decoders, such as SD family [14], [226], IP-adapter [227], FLUX [16], and Lumina-Next [228], which are trained independently from the MLLM. During inference, the MLLM produces semantic-level visual tokens, which are then passed to the diffusion decoder for final image synthesis. This design choice—pairing semantic encoders with diffusion decoders—is motivated by the fact that semantic embeddings encode high-level conceptual information but lack the spatial density and low-level granularity required for direct pixel reconstruction. Diffusion models, with their iterative denoising mechanisms, are particularly well-suited for this setting: they are capable of progressively refining semantic representations into high-resolution, photorealistic images, even when the input tokens are sparse or abstract. In contrast, although few approaches (i.e., VILA-U [146] and UniTok [150]) adopt pixel-based decoders, their generated image quality is less competitive than the diffusion decoders. Thus, diffusion decoders provide a more robust and expressive decoding pathway for semantically compressed visual tokens, significantly improving text-image alignment, global coherence, and visual fidelity. UniWorld [155] and Pisces [156] have endeavored to develop and expand such a solution. UniWorld directly utilizes the output features of pre-trained MLLM for visual comprehension as a high-level conditional signal, while employing SigLIP as low-level conditional signal to deliver comprehensive semantic visual control for DiT. Pisces employs EVA-CLIP as a condition for visual generation tasks and leverages diffusion to further enhance the model’s visual generation output. For various tasks, Pisces introduces tailored visual vector lengths and employs distinct MLPs to encode conditions. This approach increases the flexibility of model design while mitigating the inference cost compared to a single encoder configuration.
Despite these advantages, semantic encoding also comes with several limitations. First, due to the abstraction of low-level cues, the resulting visual tokens are less controllable at the pixel level, making it difficult to perform fine-grained image editing, local inpainting, or structure-preserving transformation. Second, semantic encoders often provide only global or mid-level representations, which can be insufficient for tasks requiring spatial correspondence (e.g., referring expression segmentation or pose-accurate synthesis). Lastly, since the semantic encoder and diffusion decoder are typically trained separately, the lack of end-to-end optimization can lead to mismatch between MLLM outputs and decoder expectations, occasionally causing semantic drift or generation artifacts.
3)可学习查询编码。可学习查询编码已成为生成自适应且与任务相关的图像表示的有效策略。如图5(b-3)所示,与纯粹依赖固定的视觉标记器或密集图像补丁不同,该方法引入了一组可学习的查询令牌,用于动态地从图像特征中提取信息性内容。这些查询令牌充当内容感知的探针,与视觉编码器交互以生成紧凑且在语义上对齐的嵌入表示,非常适合多模态理解和生成。
当前可学习查询编码的实现大致可分为两类具有代表性的范式。第一类以SEED[163],为代表,提出了一种学习因果视觉嵌入的seedtokenizer。具体来说,输入图像首先通过BLIP-2ViT编码器[53]被编码为密集的特征token,这些特征随后与一组可学习的查询令牌拼接,并由一个因果Q-Former处理以产生因果视觉嵌入。该设计通过图文对比学习和图像重建监督共同训练,使得学习到的嵌入既保留了低级视觉细节,又能捕捉与文本的高级语义对齐。在此基础上,SEED-LLAMA[164]和SEED-X[165]通过将OPT骨干网络[229]替换为更强的LLaMA2模型[2]并将解码器升级为UnCLIP-SD[14]或SDXL[226],提升了模型在理解和生成任务上的性能。第二类方法由MetaQuerieses[166],提出,提供了可学习查询编码的简化版本。在这里,图像特征由被冻结的SigLIP编码器[209],提取,然后与可学习查询令牌拼接并直接传入如LLaVA[216]或Qwen2.5-VL[10]等冻结的视觉-语言骨干网络。输出的因果嵌入被用作扩散式图像解码器的条件输入,从而实现高质量图像生成。由于骨干网络保持冻结,视觉-语言理解能力与底层预训练模型一致,为多模态生成提供了一种轻量且有效的解决方案。Open-Uni[170]对MetaQuerieses的架构进行了改进,仅使用可学习查询并在MLLM与扩散模型之间引入一个轻量连接器,以便实现统一的多模态理解与生成。Open-Uni表明,连接MLLM的视觉理解部分与基于扩散的视觉生成部分的连接器可以非常简单,例如仅由六层Transformer组成。Nexus-Gen[167]和Ming-Lite-Uni[168]遵循MetaQuerieses的范式,但在此基础上做出显著改进以进一步增强多模态生成能力。Nexus-Gen[167]引入了更强大的扩散解码器FLUX-1.dev,显著提升了生成质量,使模型更好地捕捉复杂图像生成任务所需的精细细节与高保真特征。另一方面,Ming-Lite-Uni[168]采取不同路径,通过引入高性能的MLLM模型M2-omini[200],来增强视觉-语言交互。该模型执行高级的视觉-语言条件化以生成条件化图像嵌入,确保更语义对齐的表示。
表示。此外,Ming-Lite-Uni 通过在其扩散模型中引入多尺度可学习令牌进行微调,从而促进各视觉尺度之间更好的语义对齐。该多尺度表示对齐机制增强了模型从文本提示生成细节丰富且具上下文关联图像的能力,解决了分辨率不匹配和语义不一致等挑战。这一创新方法使 Ming-Lite-Uni 在多模态理解与生成方面成为一款强大的工具,推动了当前方法在灵活性和性能上的边界。Ming-Omni [171] 遵循集成的专家混合(MoE)架构,通过为每个令牌定制的机制实现模态特定的路由,从而启用定制化的路由分配。为应对视觉生成中固有的多尺度现象 [113],Ming-Omni 采用由对齐策略引导的多尺度可学习查询,迭代地从粗到细生成图像细节。此外,Ming-Omni 集成了音频模态,并实施了双阶段训练策略以缓解音频理解与生成任务之间的相互影响。初始阶段强调理解能力,而后续阶段则侧重于提升生成质量。
BLIP3-o [169] 同样使用可学习查询来搭建多模态理解与生成之间的桥梁,但它采用了两个扩散模型:一个用于学习CLIP嵌入,另一个以CLIP作为条件来生成图像。研究表明,流匹配损失比均方误差损失更有效,能实现更丰富的图像采样并提高图像质量。UniLIP [172] 通过自蒸馏逐步将重建能力引入CLIP,然后将可学习查询与MLLM最后一层的隐藏状态组合作为联合条件。该框架被证明能优化用于视觉编辑的丰富信息。为了利用MLLM中间层的层级表示,
TBAC-UniImage [173] 在多个层而非仅最后一层应用可学习查询。总而言之,这些基于可学习查询的设计具有共同的优势:它们提供了自适应、紧凑且语义丰富的表示,既支持高效的图像理解又支持高质量的生成。通过聚焦于任务驱动的 token 提取,此类模型为统一多模态框架中传统视觉标记器提供了灵活且可扩展的替代方案。
尽管可学习查询编码具有灵活性并展现出有希望的结果,但它也存在若干可能限制其更广泛适用性的局限性。首先,一个关键挑战是可学习查询令牌带来的计算开销增加。随着查询令牌数量的增长,模型的内存消耗和计算复杂度可能显著上升,尤其是在扩展到大型数据集或更复杂的多模态任务时。此外,使用固定编码器(如MetaQueries中所见)在面对偏离预训练数据分布的新颖或复杂视觉输入时,可能会阻碍模型的灵活性。其次,在像SEED[163]和MetaQueries[166],这样的方法中,依赖冻结或预训练的骨干网络会限制视觉特征对下游任务的适应性。尽管
- Learnable Query Encoding. Learnable query encoding has emerged as an effective strategy for producing adaptive and task-relevant image representations. As shown in Fig. 5 (b-3), instead of relying purely on fixed visual tokenizers or dense image patches, this approach introduces a set of learnable query tokens that dynamically extract informative content from image features. These query tokens act as content-aware probes that interact with visual encoders to generate compact and semantically aligned embeddings, well-suited for multimodal understanding and generation.
Current implementations of learnable query encoding can be broadly divided into two representative paradigms. The first is represented by SEED [163], which proposes a seed tokenizer that learns causal visual embeddings. Specifically, an input image is first encoded into dense token features via a BLIP-2 ViT encoder [53]. These features are then concatenated with a set of learnable query tokens and processed by a causal Q-Former to produce causal visual embeddings. This design is trained using both image-text contrastive learning and image reconstruction supervision, allowing the learned embeddings to simultaneously retain low-level visual detail and capture high-level semantic alignment with text. Building on this foundation, SEED-LLAMA [164] and SEED-X [165] enhance the model’s capacity by replacing the OPT backbone [229] with a stronger LLaMA2 model [2] and upgrading the decoder to UnCLIPSD [14] or SDXL [226], leading to improved performance in both understanding and generation tasks. The second approach, introduced by MetaQueries [166], provides a simplified version of learnable query encoding. Here, image features are extracted via a frozen SigLIP encoder [209], which are then concatenated with learnable query tokens and directly passed through a frozen vision-language backbone such as LLaVA [216] or Qwen2.5-VL [10]. The output causal embeddings are used as conditioning inputs for a diffusion-based image decoder, enabling high-quality image generation. Because the backbone is kept frozen, the vision-language understanding capabilities remain consistent with the underlying pretrained models, offering a lightweight yet effective solution for multimodal generation. OpenUni [170] refines the architecture of MetaQueries by utilizing solely learnable queries and a lightweight connector between a MLLM and a diffusion model, facilitating cohesive multimodal understanding and generation. OpenUni demonstrates that the conneter between the MLLM visual understanding component and the diffusion-based visual generation component can be minimal in complexity, exemplified by a configuration comprising merely six Transformer layers. Nexus-Gen [167] and Ming-Lite-Uni [168] follow the MetaQueries paradigm, but with notable advancements to further enhance multimodal generation. NexusGen [167] introduces a more powerful diffusion decoder, FLUX-1.dev, which significantly improves the generation quality. This approach allows the model to better capture the intricate details and high-fidelity features necessary for complex image generation tasks. On the other hand, MingLite-Uni [168] takes a different route by introducing a highly capable MLLM model, M2-omini [200], for enhanced vision-language interaction. This model performs advanced vision-language conditioning to generate the conditioned image embeddings, ensuring a more semantically aligned representation.
sentation. In addition, Ming-Lite-Uni fine-tunes its diffusion model by incorporating multi-scale learnable tokens, which facilitate improved semantic alignment across various visual scales. The multi-scale representation alignment mechanism enhances the model’s ability to generate detailed and contextually rich images from textual prompts, addressing challenges such as resolution mismatches and semantic inconsistencies. This innovative approach makes Ming-Lite-Uni a powerful tool for multimodal understanding and generation, pushing the boundaries of current methods in both flexibility and performance. Ming-Omni [171] adheres to the integrated MoE architecture, wherein modality-specific routing is facilitated through dedicated mechanisms tailored for each token, thereby enabling customized routing distributions. To address the multi-scale phenomenon inherent in visual generation [113], Ming-Omni employs multi-scale learnable queries, directed by an alignment strategy, to iteratively generate images progressing from coarse to fine detail. Furthermore, Ming-Omni integrates the audio modality and implements a dual-stage training strategy to mitigate the mutual influence between audio comprehension and generation tasks. The initial stage emphasizes comprehension capabilities, while the subsequent stage concentrates on enhancing generation quality. BLIP3o [169] also employs learnable queries to bridge multimodal understanding and generation. However, it utilizes two diffusion models: one for learning CLIP embeddings and the other for using CLIP as a condition to generate images. It reveals that flow matching loss is more effective than MSE loss, enabling more diverse image sampling and yielding better image quality. UniLIP [172] incrementally incorporates reconstruction ability into CLIP through the self-distillation, then employs a learnable query along with the hidden state of the last layer of the MLLM as combined conditions. This framework is demonstrated to optimize the abundant information for visual editing. To exploit the hierarchical representations within the MLLM’s intermediate layers, TBAC-UniImage [173] applies learnable queries at multiple layers instead of the last layer. To sum up, these learnable query-based designs share a common strength: they provide adaptive, compact, and semantically enriched representations that support both efficient image understanding and high-quality generation. By focusing on task-driven token extraction, such models offer a flexible and extensible alternative to traditional visual tokenizers, especially in unified multimodal frameworks.
Despite its flexibility and promising results, learnable query encoding also comes with several limitations that may restrict its broader applicability. First, one key challenge is the increased computational overhead introduced by the learnable query tokens. As the number of query tokens grows, the model’s memory consumption and computational complexity can significantly rise, especially when scaling up to large datasets or more intricate multimodal tasks. Furthermore, the use of a fixed encoder (as seen in approaches like MetaQueries) can hinder the model’s flexibility when confronted with novel or complex visual inputs that diverge from the pretrained data distributions. Second, in methods like SEED [163] and MetaQueries [166], the reliance on frozen or pretrained backbones can limit the adaptability of visual features to downstream tasks. While
冻结可以降低训练成本并保留预学习的知识,但它也限制了模型在不断演变的查询语义下动态对齐图像特征的能力,特别是在更具多样性或可组合性的设置中。最后,尽管可学习查询能够有效捕捉与任务相关的内容,但它们并不总是能均匀地处理多样的视觉内容。例如,包含多个对象、精细颗粒度细节或视觉线索模糊的复杂场景,可能无法被相对较少的可学习查询充分表示。当模型必须生成高度细致的输出时,这一局限性尤为明显,因为固定或较小的查询集可能无法在某些情境下捕捉视觉输入的丰富性和多样性。
4)混合编码。为了解决单一视觉表示模态的固有局限性,统一多模态模型中引入了混合编码策略。基于像素的编码方法(例如VQ-VAE或VQGAN)在保留精细视觉细节方面表现出色,但往往缺乏与文本的语义对齐。相反,基于语义的编码器(例如SigLIP或CLIP变体)会生成语义丰富的抽象表示,但在保持低级图像保真度方面效果较差。混合编码旨在通过将像素级和语义级特征合并到统一表示中,结合两种方法的优势。根据像素令牌和语义令牌的集成方式,混合编码方法大致可分为两类:伪混合编码和联合混合编码。
伪混合编码。该类别的代表性工作包括Janus[174]、Janus-Pro[175]、OmniMamba[176]、UniFluid[177]和MindOmni[178]。如图5(b-4)所示,这些模型采用双编码器——通常是语义编码器(例如SigLIP)和像素编码器(例如VQGAN或VAE)——但以任务特定的方式使用它们。在训练期间,语义编码器分支在视觉-语言理解任务中启用,而像素编码器分支在图像生成任务中激活。尽管双编码器在混合理解与生成数据集上同时训练,但在理解任务的推理阶段不会使用像素编码器,而在文本到图像生成时语义编码器被禁用。然而,对于图像编辑,UniFluid[177]使用语义编码器对源图像进行编码,而MindOmni[178]则同时使用VAE和语义编码器对源图像进行编码。这一设计选择的理由是,混合训练包含两类数据可以提升理解与生成任务的性能。Skywork UniPic[179]在理解任务中采用SigLIP2作为编码器,在生成任务中采用MAR[25]作为编码器。但由于在任一时刻仅有一个编码器处于激活状态,这些模型并未充分利用混合编码的优势。具体而言,它们错失了在生成任务中应用语义落地的机会,也未能在理解任务中利用高保真视觉细节。因此,这些模型通常使用像素解码器从潜在代码重建图像。
联合混合编码。如图5(b-5)所示,联合混合编码方法将语义代币和像素代币整合为供语言模型或解码器使用的统一输入,从而能够同时利用两种表示。
这些模型在融合策略上有所不同。MUSE-VL [180] 和 UniToken [186] 在将特征传入大语言模型之前,沿通道维度将 SigLIP 和 VQGAN 的特征拼接起来。Tokenflow [181] 采用双编码器和带共享映射的码本,能够联合优化高层语义和低层像素细节。VARGPT [182], 、VARGPT-1.1[184], 和 ILLUME+ [185] 则在序列维度上拼接语义代币与像素代币,在大语言模型的输入中同时保留两类代币。
SemHiTok [183]引入了语义引导分层码本(SGHC),它在继承语义码本语义信息的同时融入纹理信息以实现像素重建。值得注意的是,与其他直接为图像处理采用不同网络分支的方法相反,Show-o2 [187]对由 3DVAE [230],生成的潜在特征使用独立的网络分支处理,并通过时空融合模块聚合不同分支的输出。这种方法使 Show-o2 能够捕捉低层和高层视觉信息。然而,由于 Show-o2 使用 3DVAE 对图像或视频进行有损压缩,可能导致细微语义元素的损失,从而在视觉语义细节的处理上表现欠佳。通过整合语义与详细的视觉信息,联合混合编码为多模态理解与生成提供了更稳健且表现力更强的建模能力。这些模型既支持像素解码器(例如 VQGAN、Infinity[231]、VAR-D30 [113]),也支持基于扩散的解码器(例如 SDXL [226]),使其能够生成在语义对齐和视觉真实感方面都有改进的图像。
虽然混合编码通过整合像素级和语义级表示的互补优势提供了有前景的方向,但它仍然面临若干局限。许多伪混合方法在推理时并未同时利用两种编码器,从而未能充分发挥精细视觉细节与高级语义之间的潜在协同作用。即使在联合混合方法中,异构代币类型的融合也可能引入模态不平衡或冗余,如果不加以谨慎处理,可能会阻碍下游性能。此外,双编码器架构大幅增加了计算和内存开销,在分辨率高或序列较长的场景中尤其对可扩展性构成挑战。对齐像素代币和语义代币仍然不是一个简单的问题,因为隐式不匹配可能导致不连贯的表示或相互冲突的学习信号。最后,当前的混合编码技术往往假定像素与语义代币之间存在隐式对齐,然而在实际中,这种对齐并不容易实现。视觉细节与语义抽象之间的错位可能导致冲突的监督信号或不连贯的表示,尤其是在数据稀缺或有噪声的训练环境中。
3.3 融合自回归和扩散模型
融合自回归(AR)和扩散建模最近作为一个强大的统一视觉-文本生成框架出现。在这一范式中,文本代币是
freezing reduces training cost and preserves pre-learned knowledge, it also restricts the capacity of the model to dynamically align image features with the evolving query semantics, especially in more diverse or compositional settings. Finally, while learnable queries effectively capture task-relevant content, they may not always handle diverse visual content uniformly. For instance, complex scenes with multiple objects, fine-grained details, or ambiguous visual cues might not be as well-represented by a relatively small number of learnable queries. This limitation is particularly evident when the model must generate highly detailed outputs, as the fixed or small query set may fail to capture the richness and variability of the visual input in certain contexts.
- Hybrid Encoding. To address the inherent limitations of using a single modality of visual representation, hybrid encoding strategies have been introduced in unified multimodal models. Pixel-based encoding methods (e.g., VQVAE or VQGAN) excel at preserving fine-grained visual details but often lack semantic alignment with text. In contrast, semantic-based encoders (e.g., SigLIP or CLIP variants) produce abstract representations that are semantically rich yet less effective at retaining low-level image fidelity. Hybrid encoding aims to combine the strengths of both approaches by incorporating both pixel-level and semantic-level features into a unified representation. Depending on how pixel and semantic tokens are integrated, hybrid encoding methods can be broadly categorized into two types: pseudo hybrid encoding and joint hybrid encoding.
Pseudo Hybrid Encoding. Representative works in this category include Janus [174], Janus-Pro [175], OmniMamba [176], Unifluid [177], and MindOmni [178]. As shown in Fig. 5 (b-4), these models adopt dual encoders—typically a semantic encoder (e.g., SigLIP) and a pixel encoder (e.g., VQGAN or VAE)—but use them in a task-specific manner. During training, the semantic encoder branch is enabled for vision-language understanding tasks, while the pixel encoder branch is activated for image generation tasks. Although the dual encoders are trained concurrently with combined understanding and generation datasets, the pixel encoder is not utilized during inference in understanding tasks and the semantic encoder is disabled for text-to-image generation. However, for image editing, Unifluid [177] uses the semantic encoder to encode the source image while MindOmni [178] utilizes both VAE and semantic encoder to encode the source image. The rationale behind this design choice is that mixed training with both types of data can enhance performance across understanding and generation tasks. Skywork UniPic [179] employs SigLIP2 as the encoder for understanding tasks and MAR [25] as the encoder for generative tasks. However, since only one encoder is active at any given time, these models do not fully harness the advantages of hybrid encoding. Specifically, they miss the opportunity to employ semantic grounding in generation tasks and fail to utilize high-fidelity visual details in comprehension tasks. Consequently, these models typically engage pixel decoders to reconstruct images from latent codes.
Joint Hybrid Encoding. As shown in Fig. 5 (b-5), joint hybrid encoding methods integrate both semantic and pixel tokens into a single unified input for the language model or decoder, enabling simultaneous utilization of both rep
resentations. These models differ in their fusion strategies. MUSE-VL [180] and UniToken [186] concatenates the features from SigLIP and VQGAN along the channel dimension before passing them into the LLM. Tokenflow [181] incorporate dual encoders and codebooks with a shared mapping, enabling the joint optimization of high-level semantics and low-level pixel details. VARGPT [182], VARGPT-1.1 [184], and ILLUME+ [185] concatenate the semantic and pixel tokens along the sequence dimension, maintaining both token types in the LLM’s input. SemHiTok [183] introduces the Semantic Guided Hierarchical Codebook (SGHC), which perfectly inherits the semantic information of the semantic codebook while incorporating texture information to achieve pixel reconstruction. It is significant to observe that, contrary to other methods that directly employ distinct network branches for image processing, Show-o2 [187] utilizes separate network branches for the processing of latent features generated by 3DVAE [230], and uses the spatial-temporal fusion module to aggregate the outputs of different branches. This approach enables Show-o2 to capture both low-level and high-level visual information. However, such an operation might result in the loss of subtle semantic elements, owing to Show-o2’s use of 3D VAE for lossy compression of images or videos, potentially causing suboptimal handling of visual semantic details. By integrating both semantic and detailed visual information, joint hybrid encoding enables more robust and expressive modeling capabilities for multimodal understanding and generation. These models support pixel decoders (e.g., VQGAN, Infinity [231], VAR-D30 [113]) as well as diffusion-based decoders (e.g., SDXL [226]), allowing them to generate images with improved semantic alignment and visual realism.
While hybrid encoding offers a promising direction by integrating the complementary strengths of pixel-level and semantic-level representations, it still faces several limitations. Many pseudo hybrid methods do not leverage both encoders simultaneously at inference time, thereby underutilizing the potential synergy between fine-grained visual details and high-level semantics. Even in joint hybrid approaches, the fusion of heterogeneous token types can introduce modality imbalance or redundancy, which may hinder downstream performance if not carefully managed. Additionally, the dual-encoder architecture substantially increases computational and memory overhead, posing challenges for scalability, especially in high-resolution or long-sequence scenarios. Aligning pixel and semantic tokens also remains a non-trivial problem, as implicit mismatches can lead to incoherent representations or conflicting learning signals. Finally, current hybrid encoding techniques often assumes implicit alignment between the pixel and semantic tokens. However, in practice, such alignment is non-trivial. Misalignment between visual details and semantic abstraction can lead to conflicting supervision signals or incoherent representations, especially in data-scarce or noisy training settings.
3.3 Fused Autoregressive and Diffusion Models
Fused autoregressive (AR) and diffusion modeling has recently emerged as a powerful framework for unified vision-language generation. In this paradigm, text tokens are
自回归地生成的,保留了大型语言模型的组合推理优势,而图像代币则通过多步去噪过程生成,遵循扩散建模原理。这种混合策略允许图像生成以非顺序的方式进行,从而提升了视觉质量和全局一致性。
代表性模型如 Transfusion [38], Show-o [39], MonoFormer [37], 和 LMFusion [188], 遵循这种方法。在生成过程中,会向潜在视觉表示添加噪声并逐步去除,该过程以先前生成的文本或完整的跨模态上下文为条件。尽管由于多次采样步骤这一设计增加了推理成本,但它在符号控制与视觉保真度之间实现了有效的权衡,使其非常适合高质量的视觉-语言生成任务。现有的融合自回归 + 扩散模型通常采用两种图像标记化策略之一:基于像素的编码和混合编码。
- 基于像素的编码:如图 5 (c-1) 所示,基于像素的编码将图像转换为离散令牌或连续潜向量,然后将其作为基于扩散的去噪过程中的目标,该过程以自回归生成的文本令牌为条件。在近期工作中,Transfusion [38]、MonoFormer [37] 和 LMFusion [188] 都采用了通过 SD-VAE 提取的连续潜表示。这些模型共享一个结合了用于语言建模的自回归损失和用于图像重建的扩散损失的训练目标,并利用双向注意力以实现空间一致性。尽管具有共同框架,每个模型都引入了不同的架构创新:Transfusion [38] 提出了一个统一的 Transformer 主干,配以模态特定层以联合处理离散和连续输入;MonoFormer [37] 引入了一个紧凑架构,采用共享块和任务相关注意力掩码以平衡自回归和扩散任务;LMFusion [188] 通过一个轻量级的视觉注入模块使冻结的大语言模型能够执行高质量的图像生成,在仅训练视觉分支的同时保留语言能力。相比之下,Show-o [39] 采用了基于 MAGVIT-v2 [213],的离散像素分词器来生成符号化图像
与Transformer风格解码兼容的代币。它既支持基于自回归的文本代币生成,也支持基于扩散的图像合成,通过自回归和扩散损失的组合进行监督训练。总体而言,这些模型展示了基于像素的编码在平衡来自语言模型的语义可控性与来自扩散过程的高分辨率视觉保真度方面的有效性。
尽管在融合自回归和扩散框架中基于像素的编码方法效果显著,但它们也面临若干限制。首先,依赖连续潜在空间的模型(例如通过SD-VAE)在训练和推理期间会引入显著的计算开销,这是由于扩散采样的迭代性质以及高维特征处理的需求。当扩展到高分辨率图像生成或多轮视觉-文本交互时,这种负担尤为沉重。其次,文本与视觉模态之间的对齐仍然具有挑战性。虽然双向注意力机制能够实现跨模态融合,但潜在空间表征——
尤其是那些通过 SD-VAE 中的无监督重建目标学到的表征——可能并不总是与语义上有意义的语言代币最佳对齐,可能导致较弱的细粒度可控性或生成结果的可解释性下降。最后,像 Show-o 中使用的离散分词方案继承了基于 VQ 的模型的问题,例如码本崩溃以及在表示细微视觉差异方面的容量限制。这些符号代币虽然与 Transformer 风格建模兼容,但可能限制视觉多样性并相比连续潜变量方法降低重建保真度。
- 混合编码:如图 5 (c-2) 所示,混合编码融合了语义特征(例如来自 CLIP 或 ViT 编码器)和像素级潜变量(例如来自 SD-VAE),提供了更具表现力的图像表示。这种方法允许模型在保持细节视觉信息的同时利用高层语义抽象。具体而言,Janus-flow [189], Mogao [190] 和 BAGEL [191] 采用双编码器架构,并提出了一种将自回归语言模型与
修正流相协调的设计。它们将理解编码器和生成编码器解耦,使用 Siglip 或 Siglip 与 SDXL-VAE 的拼接作为用于多模态理解的视觉编码器, 使用 SDXL-VAE 或 FLUX-VAE 进行图像生成。然而, 这种伪混合编码的设计
限制了模型在生成过程中同时利用语义和像素级特征的能力,因为仅像素编码器在图像合成过程中处于激活状态。这种解耦虽然有利于模块化和训练效率, 但会阻止模型在图像解码时充分利用语义线索, 可能削弱生成任务中精细对齐和多模态可组合性。
尽管取得了进展,混合编码方法仍面临若干挑战。双编码器架构的集成以及自回归与扩散过程的结合增加了模型的整体复杂性。这可能导致更高的计算成本和更长的训练时间,使其在效率上不及更简单的模一
型。此外,确保语义与像素级特征之间的有效对齐需要谨慎的架构设计和优化。这种对齐过程可能难以实现和微调,限制了模型以平衡的方式充分利用两种模态的能力。此外,在统一模型中平衡视觉-语言理解与图像生成的目标常常导致权衡,其中一项任务的改进可能以牺牲另一项为代价。这些限制强调了需要更高效的混合设计,以在降低计算开销的同时更好地利用视觉和语义特征的优势,并在各项任务上保持高性能。
3.4 任意到任意多模态模型
尽管早期的统一多模态模型主要集中于文本-图像对,近期研究已扩展到任意到任意的多模态建模。这一雄心勃勃的方法旨在创建能够处理并生成多种模态(包括音频、视频、语音、音乐等)的模型。这些模型的目标是在单一架构内统一模态特定的编码器和解码器,
generated autoregressively, preserving the compositional reasoning strengths of large language models, while image tokens are generated through a multi-step denoising process, following the diffusion modeling principle. This hybrid strategy allows image generation to proceed in a non-sequential manner, resulting in improved visual quality and global consistency.
Representative models such as Transfusion [38], Showo [39], MonoFormer [37], and LMFusion [188], follow this approach. During generation, noise is added to latent visual representations and removed iteratively, with the process conditioned on previously generated text or full cross-modal context. Although this design increases inference cost due to multiple sampling steps, it achieves an effective trade-off between symbolic control and visual fidelity, making it well-suited for high-quality vision-language generation tasks. Existing fused AR + diffusion models typically adopt one of two image tokenization strategies: pixel-based encoding and hybrid encoding.
- Pixel-based Encoding: As shown in Fig. 5 (c-1), pixel-based encoding transforms images into either discrete tokens or continuous latent vectors, which are then used as targets in a diffusion-based denoising process conditioned on autoregressively generated text tokens. Among recent works, Transfusion [38], MonoFormer [37], and LM-Fusion [188] all adopt continuous latent representations extracted via SD-VAE. These models share a common training objective that combines autoregressive loss for language modeling and diffusion loss for image reconstruction, and utilize bidirectional attention to enable spatial coherence. Despite this shared framework, each model introduces distinct architectural innovations: Transfusion [38] proposes a unified transformer backbone with modality-specific layers to jointly handle discrete and continuous inputs; MonoFormer [37] introduces a compact architecture with shared blocks and task-dependent attention masking to balance AR and diffusion tasks; and LMFusion [188] enables frozen LLMs to perform high-quality image generation through a lightweight visual injection module, preserving language capabilities while training only the vision branch. In contrast, Show-o [39] employs a discrete pixel-based tokenizer based on MAGVIT-v2 [213], generating symbolic image tokens compatible with transformer-style decoding. It supports both AR-based text token generation and diffusion-based image synthesis, supervised through a combination of autoregressive and diffusion losses. Collectively, these models demonstrate the effectiveness of pixel-based encoding in balancing semantic controllability from language models and high-resolution visual fidelity from diffusion processes.
Despite their effectiveness, pixel-based encoding approaches in fused AR and diffusion frameworks also face several limitations. First, models that rely on continuous latent spaces (e.g., via SD-VAE) introduce significant computational overhead during training and inference, due to the iterative nature of diffusion sampling and the need for high-dimensional feature processing. This can become especially burdensome when scaling to high-resolution image generation or multi-turn vision-language interactions. Second, alignment between textual and visual modalities remains challenging. While bidirectional attention mechanisms enable cross-modal fusion, the latent space represen
tations—particularly those learned through unsupervised reconstruction objectives in SD-VAE—may not always be optimally aligned with semantically meaningful language tokens, potentially leading to weaker fine-grained controllability or less interpretable generation. Finally, discrete tokenization schemes, as used in Show-o, inherit issues from VQ-based models such as codebook collapse and limited capacity to represent subtle visual nuances. These symbolic tokens, while compatible with transformer-style modeling, may constrain visual diversity and reduce reconstruction fidelity compared to continuous latent methods.
- Hybrid Encoding: As shown in Fig. 5 (c-2), hybrid encoding fuses both semantic features (e.g., from CLIP or ViT encoders) and pixel-level latents (e.g., from SD-VAE), providing a more expressive image representation. This approach allows models to leverage high-level semantic abstraction while maintaining detailed visual information. Specifically, Janus-flow [189], Mogao [190] and BAGEL [191] adopt a dual-encoder architecture and presents a minimalist architecture that harmonizes AR language models with rectified flow. They decouples the understanding and generation encoders, using SigLIP or the concatenation of SigLIP and SDXL-VAE as the vision encoder for multimodal understanding and SDXL-VAE or FLUX-VAE for image generation. However, the pseudo hybrid encoding design limits the model’s ability to simultaneously leverage both semantic and pixel-level features during generation, as only the pixel encoder is active in the image synthesis process. This decoupling, while beneficial for modularity and training efficiency, prevents the model from fully exploiting semantic cues during image decoding, potentially weakening fine-grained alignment and multimodal compositionality in generative tasks.
Despite their advancements, hybrid encoding methods face several challenges. The integration of dual-encoder architectures and the combination of autoregressive and diffusion processes increase the model’s overall complexity. This can result in higher computational costs and longer training times, making them less efficient compared to simpler models. Furthermore, ensuring effective alignment between semantic and pixel-level features requires careful architectural design and optimization. This alignment process can be difficult to achieve and fine-tune, limiting the model’s ability to fully utilize both modalities in a balanced way. Additionally, balancing the objectives of vision-language understanding and image generation within a unified model often leads to trade-offs, where improvements in one task may come at the expense of the other. These limitations underscore the need for more efficient hybrid designs that can better leverage the strengths of both visual and semantic features while reducing computational overhead and maintaining high performance across tasks.
3.4 Any-to-Any Multimodal Models
While early unified multimodal models primarily focused on text-image pairs, recent research has expanded toward any-to-any multimodal modeling. This ambitious approach seeks to create models that can process and generate across a diverse set of modalities, including audio, video, speech, music, and beyond. These models aim to unify modality-specific encoders and decoders within a single architecture,
从而实现诸如文本到音频、视频到文本、语音到音乐,甚至图像到视频的任务。本节回顾了该新兴领域中的代表性工作,重点介绍它们的设计原则、模块化以及当前的局限性。
大多数任意到任意模型遵循模块化设计,每种模态配备专门的编码器和解码器,同时共享主干以促进跨模态表示学习和序列建模。例如,OmniFlow [199] 整合了用于音频和音乐生成的HiFiGen [232]、用于图像处理的SD-VAE [14],并使用类DiT的扩散模型(MMDiT)[15]作为主干。该模块化设计使模型能够高效地将不同模态结合用于复杂的生成任务。
一些模型依赖共享嵌入空间在特征层面统一不同模态。例如,Spider[198]、X-VILA [196]、和Next-GPT [192]利用ImageBind——一种对比学习(Contrastive)训练的模型,将六种模态(文本、图像、视频、音频、深度和热成像)映射到单一嵌入空间。这个统一表示使得通过模态特定解码器(如Stable Diffusion [14]、Zeroscope或基于LLM的文本解码器[1])进行灵活的条件化和生成成为可能。虽然这一方法在理论上很优雅,但其生成能力通常受限于解码器的质量和共享嵌入的粒度。
其他模型,例如AnyGPT[195]和Unified-IO2[193],将序列到序列范式扩展以处理多种模态。AnyGPT[195]使用EnCodec[233]进行音频标记化,使用SpeechTokenizer[234]处理语音,并训练一个带有模态特定前缀的统一Transformer。另一方面,Unified-IO2[193],采用更为结构化的编码器-解码器设计,包含视觉、音频和语言模态,支持在单一模型中处理诸如AST到文本、语音到图像或视频字幕生成等任务。
最近一个值得注意的任意到任意统一多模态模型是M2-omni[200],它引入了一个高度通用的架构,能够处理和生成包括文本、图像、视频和音频在内的多种模态。M2-omini在此基础上进一步发展,融合了多个模态特定的分词器和解码器,每个组件都经过精心设计以处理不同数据类型的独特特性。具体来说,它利用NaViT[235]对任意分辨率的视频和图像进行编码,并结合一个预训练的SD-3[226]作为图像解码器。对于音频,M2-omini引入了paraformer-zh[236]来提取音频令牌,并将预测的离散音频令牌输入到预训练的CosyVoice[237]流匹配与声码器模型中以生成音频流。该集成确保M2-omini能够从各种输入中有效生成高质量的图像和音频流,使其真正成为一个多模态强大模型。
尽管取得了可喜进展,当前的任意到任意模型仍面临若干挑战。一个关键问题是模态不平衡,文本和图像模态往往占据主导地位,而音频、视频和音乐等模态则被低估或代表性不足,这限制了这些模型可处理任务的多样性。另一个挑战是可扩展性:支持广泛的模态会增加模型的复杂性,从而导致更高的推理延迟和更大的资源
需求。此外,确保跨模态的语义一致性仍然不是一项简单的任务,模型常常难以保持稳健且对齐的输出。这些挑战是任意到任意多模态模型发展中持续研究的方向。
尽管如此,这些模型代表了朝着开发能够理解并在整个人类感官输入与交流频谱上进行生成的通用基础模型迈出的关键一步。随着数据、架构和训练范式的演进,未来的任意到任意模型有望变得更具可组合性、更高效,并且真正能够实现跨模态的通用生成能力。
4面向统一模型的数据集
大规模、高质量且多样化的训练数据是构建强大统一多模态理解与生成模型的基石。这些模型通常需要在海量图文对上进行预训练,以学习跨模态的相关性与表示。需要注意的是,在大规模多模态数据上训练之前,这些模型通常会以源自在大规模自然语言语料(例如CommonCrawl 1 ^{1} 1 、RedPajama[291]、WebText[292],等)上训练所得的参数进行初始化。鉴于本综述主要聚焦于多模态模型,本节的讨论将排除仅有文本的数据。根据主要用途与模态特征,常见的多模态预训练数据集大致可分为:多模态理解数据集、文本到图像生成数据集、图像编辑数据集、交错图文数据集,以及其它在文本与图像输入条件下用于图像生成的数据集。本节将围绕表3中列出的各类别代表性数据集展开,重点介绍自2020年起发布的数据集。
4.1多模态理解数据集
这些数据集主要用于训练模型的跨模态理解能力,使其能够执行图像字幕生成、视觉问答(VQA)、图像-文本检索和视觉定位等任务。它们通常由大量图像及其对应的文本描述组成。
- RedCaps [238]: 该数据集包含来自 Reddit的1200万图文对。它特别擅长捕捉用户在社交媒体平台上经常分享的日常物品和瞬间(如宠物、爱好、食物、休闲等)。
- Wukong [239]: 悟空数据集是一个大规模中文多模态预训练数据集,包含从网络过滤得到的1亿中文图文对。其创建解决了大规模高质量中文多模态预训练数据的缺乏问题,为面向中文场景的多模态模型发展做出了重要贡献。
- LAION [240]: LAION (Large-scale Artificial Intelligence Open Network) 项目提供了最大全球公开可用的图文对数据集之一。例如, LAION-5B 包含近 60 亿的图文对
enabling tasks such as text-to-audio, video-to-text, speech-to-music, or even image-to-video generation. This section reviews representative works in this emerging field, highlighting their design principles, modularity, and current limitations.
Most any-to-any models follow a modular design, where each modality is paired with a specialized encoder and decoder, while a shared backbone facilitates cross-modal representation learning and sequence modeling. For example, OmniFlow [199] integrates HiFiGen [232] for audio and music generation, SD-VAE [14] for image processing, and uses a DiT-like diffusion model (MMDiT) [15] as the backbone. This modular design allows the model to efficiently combine different modalities for complex generation tasks.
Some models rely on shared embedding spaces to unify different modalities at the feature level. For instance, Spider [198], X-VILA [196], and Next-GPT [192] leverage Image-Bind—a contrastively trained model that maps six modalities (text, image, video, audio, depth, and thermal) into a single embedding space. This unified representation enables flexible conditioning and generation via modality-specific decoders, such as Stable Diffusion [14], Zeroscope, or LLM-based text decoders [1]. While this approach is elegant in theory, its generative capacity is often constrained by the quality of the decoder and the granularity of the shared embedding.
Other models, such as AnyGPT [195] and Unified-IO 2 [193], extend the sequence-to-sequence paradigm to handle multiple modalities. AnyGPT [195] utilizes EnCodec [233] for audio tokenization, SpeechTokenizer [234] for speech, and trains a unified Transformer with modality-specific prefixes. Unified-IO 2 [193], on the other hand, adopts a more structured encoder-decoder design that includes visual, audio, and language modalities, supporting tasks like AST-to-text, speech-to-image, or video captioning within a single model.
A recent and notable addition to the any-to-any unified multimodal models is M2-omni [200], which introduces a highly versatile architecture capable of processing and generating a wide variety of modalities, including text, image, video, and audio. M2-omini takes a step forward by incorporating multiple modality-specific tokenizers and decoders, each carefully designed to handle the unique characteristics of different data types. Specifically, it utilizes NaViT [235] to encode videos and images of arbitrary resolution, and combines a pre-trained SD-3 [226] as the image decoder. For audio, M2-omini introduces paraformerzh [236] to extract audio tokens, and feeds the predicted discrete audio tokens into the pretrained CosyVoice [237] flow matching and vocoder model to generate audio streams. This integration ensures that M2-omini can effectively generate high-quality images, and audio streams from various inputs, making it a truly multi-modal powerhouse.
Despite promising progress, current any-to-any models still face several challenges. One key issue is modality imbalance, where text and image modalities are often dominant, while others like audio, video, and music are underrepresented. This limits the diversity of tasks these models can handle. Another challenge is scalability, as supporting a wide range of modalities increases model complexity, leading to higher inference latency and greater resource
requirements. Additionally, ensuring semantic consistency across modalities remains a non-trivial task, with models often struggling to maintain grounded and aligned outputs. These challenges represent ongoing areas of research in the development of any-to-any multimodal models.
Nevertheless, these models represent a crucial step toward developing universal foundation models that can understand and generate across the full spectrum of human sensory input and communication. As data, architectures, and training paradigms evolve, future any-to-any models are expected to become more compositional, efficient, and capable of truly universal cross-modal generation.
4 DATASETS ON UNIFIED MODELS
Large-scale, high-quality, and diverse training data form the bedrock for building powerful unified multimodal understanding and generation models. These models typically require pre-training on vast amounts of image-text pairs to learn cross-modal correlations and representations. It is important to note that before being trained on large-scale multi-modal data, these models are often initialized with parameters derived from training on a large-scale natural language corpus, such as Common Crawl1, RedPajama [291], WebText [292], etc. Since this survey primarily focuses on multimodal models, the discussion in this section will exclude text-only data. Based on the primary use and modality characteristics, common pre-training multimodal datasets can be broadly categorized as follows: Multimodal Understanding datasets, Text-to-Image Generation datasets, Image Editing datasets, Interleaved Image-Text datasets, and other datasets for image generation conditioned on both text and image inputs. This section will elaborate on representative datasets listed in Tab. 3 within each category, focusing on those released from 2020 onwards.
4.1 Multimodal Understanding Datasets
These datasets are primarily used to train the cross-modal understanding capabilities of models, enabling tasks such as image captioning, visual question answering (VQA), imagedtext retrieval, and visual grounding. They typically consist of large collections of images paired with corresponding textual descriptions.
- RedCaps [238]: This dataset comprises 12 million image-text pairs sourced from Reddit. It is particularly specialized in capturing everyday items and moments (like pets, hobbies, food, leisure, etc.) frequently shared by users on social media platforms.
- Wukong [239]: The Wukong dataset is a large-scale Chinese multimodal pre-training dataset containing 100 million Chinese image-text pairs filtered from the web. Its creation addressed the lack of large-scale, high-quality Chinese multimodal pre-training data, significantly contributing to the development of multimodal models targeting Chinese scenarios.
- LAION [240]: The LAION (Large-scale Artificial Intelligence Open Network) project provides one of the largest publicly available image-text pair datasets. For instance, LAION-5B contains nearly 6 billion image-text
常用于预训练统一多模态理解与生成模型的数据集概览。本表按主要应用(多模态理解、文本到图像生成、图像编辑、交错图文和其他条件生成任务)对数据集进行分类,并列出每个数据集的大致样本规模和发布日期。
表3
| 数据集 | 样本数 | Date |
| 多模态理解 | ||
| RedCaps [238] | 12M | 2021-11 |
| 悟空 [239] | 100M | 2022-02 |
| LAION [240] | 5.9B | 2022-03 |
| COYO [241] | 747M | 2022-08 |
| Laion-COCO [242] | 600M | 2022-09 |
| DataComp [243] | 1.4B | 2023-04 |
| GRIT [244] | 20M | 2023-06 |
| CapsFusion-120M [245] | 120M | 2023-10 |
| ShareGPT4V [246] | 100K | 2023-11 |
| ALLaVA-4V [216] | 1.4M | 2024-02 |
| Cambrian-10M(7M) [247] | 10M | 2024-06 |
| LLaVA-OneVision [248] | 4.8M | 2024-08 |
| Infinity-MM [249] | 40M | 2024-10 |
| Text-to-Image | ||
| CC-12M [250] | 12M | 2021-02 |
| LAION-Aesthetics [240] | 120M | 2022-08 |
| SAM [251] | 11M | 2023-04 |
| Mario-10M [252] | 10M | 2023-05 |
| RenderedText [253] | 12M | 2023-06 |
| JourneyDB [254] | 4M | 2023-07 |
| AnyWord-3M [255] | 3M | 2023-11 |
| CosmicMan-HQ 1.0 [256] | 6M | 2024-04 |
| DOCCI [257] | 15K | 2024-04 |
| PixelProse [258] | 16M | 2024-06 |
| DenseFusion [259] | 1M | 2024-07 |
| Megalith [260] | 10M | 2024-07 |
| text-to-image-2M [261] | 2M | 2024-09 |
| PD12M [262] | 12M | 2024-10 |
| SFHQ-T2I [263] | 122K | 2024-10 |
| EliGen 训练集 [264] | 500k | 2025-01 |
| TextAtlas5M [265] | 5M | 2025-02 |
| BLIP-3o 6万 [169] | 60K | 2025-05 |
| ShareGPT-4o-Image [266] | 45K | 2025-06 |
| Echo-4o-Image [267] | 106K | 2025-08 |
| 图像编辑 ing | ||
| InstructP2P [268] | 313K | 2022-11 |
| Magicbrush [269] | 10K | 2023-06 |
| HIVE [270] | 1.1M | 2023-07 |
| HQ-Edit [271] | 197K | 2024-04 |
| SEED-Data-Edit [165] | 3.7M | 2024-05 |
| EditWorld [272] | 8.6K | 2024-06 |
| UltraEdit [273] | 4M | 2024-07 |
| PromptFix [274] | 1M | 2024-09 |
| OmniEdit [275] | 1.2M | 2024-11 |
| AnyEdit [276] | 2.5M | 2024-11 |
| RefEdit [277] | 18K | 2025-04 |
| Imgedit [278] | 1.2M | 2025-05 |
| ByteMorph-6M [279] | 6.4M | 2025-05 |
| ShareGPT-4o-Image [266] | 46K | 2025-06 |
| GPT-Image-Edit-150万 [280] | 1.5M | 2025-07 |
| X2Edit [281] | 3.7M | 2025-08 |
| 交错图文 | ||
| 多模态 C4 [282] | 1012万 | 2023-04 |
| OBELICS [283] | 141M | 2023-06 |
| CoMM [284] | 227K | 2024-06 |
| OmniCorpus [285] | 8B | 2024-10 |
| Other Text+图像到图像 | ||
| LAION-Face [286] | 50M | 2021-12 |
| MultiGen-20M [287] | 20M | 2023-05 |
| Subjects200K [288] | 200K | 2024-11 |
| X2I-subject-driven [84] | 2.5M | 2024-12 |
| SynCD [289] | 95K | 2025-02 |
| Graph200K [290] | 200K | 2025-03 |
| Echo-4o-Image [267] | 73K | 2025-08 |
从网络抓取的图文对。该数据使用CLIP模型进行过滤,以确保图像与文本之间具有一定的相关性。由于其庞大的规模和多样性,LAION数据集已成为许多大型多模态模型预训练的基础。其子集Laion-COCO[242],包含6亿个具有高质量图注的样本,旨在提供在风格上更接近MS COCO[293]的大规模数据集。
-
COYO [241]: COYO 是另一个大规模图文对数据集, 约包含 7.47 亿个样本。与 LAION 类似, 它来源于网络抓取并经过过滤处理, 为社区提供了一个替代性的、大规模的预训练资源来补充 LAION。
-
DataComp [243]: DataComp 包含 14 亿个样本,来源于 Common Crawl,采用精心设计的过滤策略(CLIP 评分和基于图像的过滤),旨在提供比原始抓取数据更高质量的图文对。
-
ShareGPT4V [246]: 该数据集提供约10万条高质量的图像-文本对话数据点。它专门用于增强大型多模态模型的指令遵循和对话能力,使它们成为更好的会话代理。
• ALLa[216]: 该数据集包含 140 万个样本, 采用合成方式生成, 旨在促进资源友好型轻量视觉-语言模型 (LVLMs) 的训练。生成流水线在多阶段过程中利用强大的专有模型(如 GPT-4V):首先从 LAION 和 Vision-FLAN 等来源挑选图像; 然后为这些图像生成精细、详细的图注; 最后创建复杂推理的视觉问答对, 强调包含证据和思维链的详细答案, 以支持稳健的视觉指令微调。
- CapsFusion-120M [245]: 它是一个大规模集合,包含从Laion-COCO [242]中筛选出的1.2亿图文对。图注通过将Laion-COCO中的图注与CapsFusion-LLaMA [245]集成获得。
- Cambrian-10M(7M) [247]: Cambrian-10M是一个为多模态指令微调设计的大规模数据集,来源于多样化的数据,但在各类别之间存在不均衡分布。为提升数据集质量,基于优化的数据比例进行了数据过滤,从而生成了Cambrian-7M。
- LLaVA-OneVision [248]: 该视觉指令微调集合包含两部分:单图像数据集,包含320万条多样化、已分类的样本(问答、光学字符识别、数学等),以及包含160万条混合模态样本的OneVision数据集(包括视频、多图像及精选的单图像数据)。
- Infinity-MM [248]: Infinity-MM 是一个全面的多模态训练数据集,包含超过 4000 万条样本,通过广泛收集并对现有开源数据集进行分类以及新增生成的数据而创建。该集合包括图像标题、通用视觉指令以及更高质量的精选
TABLE 3
Overview of common datasets used for pre-training unified multimodal understanding and generation models. This table categorizes datasets by primary application (Multimodal Understanding, Text-to-Image Generation, Image Editing, Interleaved Image-Text, and Other conditional generation tasks), detailing the approximate sample size and release date for each dataset.
| Dataset | Samples | Date |
| Multimodal Understanding | ||
| RedCaps [238] | 12M | 2021-11 |
| Wukong [239] | 100M | 2022-02 |
| LAION [240] | 5.9B | 2022-03 |
| COYO [241] | 747M | 2022-08 |
| Laion-COCO [242] | 600M | 2022-09 |
| DataComp [243] | 1.4B | 2023-04 |
| GRIT [244] | 20M | 2023-06 |
| CapsFusion-120M [245] | 120M | 2023-10 |
| ShareGPT4V [246] | 100K | 2023-11 |
| ALLaVA-4V [216] | 1.4M | 2024-02 |
| Cambrian-10M(7M) [247] | 10M | 2024-06 |
| LLaVA-OneVision [248] | 4.8M | 2024-08 |
| Infinity-MM [249] | 40M | 2024-10 |
| Text-to-Image | ||
| CC-12M [250] | 12M | 2021-02 |
| LAION-Aesthetics [240] | 120M | 2022-08 |
| SAM [251] | 11M | 2023-04 |
| Mario-10M [252] | 10M | 2023-05 |
| RenderedText [253] | 12M | 2023-06 |
| JourneyDB [254] | 4M | 2023-07 |
| AnyWord-3M [255] | 3M | 2023-11 |
| CosmicMan-HQ 1.0 [256] | 6M | 2024-04 |
| DOCCI [257] | 15K | 2024-04 |
| PixelProse [258] | 16M | 2024-06 |
| DenseFusion [259] | 1M | 2024-07 |
| Megalith [260] | 10M | 2024-07 |
| text-to-image-2M [261] | 2M | 2024-09 |
| PD12M [262] | 12M | 2024-10 |
| SFHQ-T2I [263] | 122K | 2024-10 |
| EliGen TrainSet [264] | 500k | 2025-01 |
| TextAtlas5M [265] | 5M | 2025-02 |
| BLIP-3o 60k [169] | 60K | 2025-05 |
| ShareGPT-4o-Image [266] | 45K | 2025-06 |
| Echo-4o-Image [267] | 106K | 2025-08 |
| Image Editing | ||
| InstructP2P [268] | 313K | 2022-11 |
| Magicbrush [269] | 10K | 2023-06 |
| HIVE [270] | 1.1M | 2023-07 |
| HQ-Edit [271] | 197K | 2024-04 |
| SEED-Data-Edit [165] | 3.7M | 2024-05 |
| EditWorld [272] | 8.6K | 2024-06 |
| UltraEdit [273] | 4M | 2024-07 |
| PromptFix [274] | 1M | 2024-09 |
| OmniEdit [275] | 1.2M | 2024-11 |
| AnyEdit [276] | 2.5M | 2024-11 |
| RefEdit [277] | 18K | 2025-04 |
| Imgedit [278] | 1.2M | 2025-05 |
| ByteMorph-6M [279] | 6.4M | 2025-05 |
| ShareGPT-4o-Image [266] | 46K | 2025-06 |
| GPT-Image-Edit-1.5M [280] | 1.5M | 2025-07 |
| X2Edit [281] | 3.7M | 2025-08 |
| Interleaved Image-Text | ||
| Multimodal C4 [282] | 101.2M | 2023-04 |
| OBELICS [283] | 141M | 2023-06 |
| CoMM [284] | 227K | 2024-06 |
| OmniCorpus [285] | 8B | 2024-10 |
| Other Text+Image-to-Image | ||
| LAION-Face [286] | 50M | 2021-12 |
| MultiGen-20M [287] | 20M | 2023-05 |
| Subjects200K [288] | 200K | 2024-11 |
| X2I-subject-driven [84] | 2.5M | 2024-12 |
| SynCD [289] | 95K | 2025-02 |
| Graph200K [290] | 200K | 2025-03 |
| Echo-4o-Image [267] | 73K | 2025-08 |
pairs crawled from the web. This data is filtered using CLIP models to ensure a degree of relevance between images and texts. Due to its immense scale and diversity, the LAION dataset has become fundamental for pre-training many large multimodal models. Its subset, Laion-COCO [242], contains 600 million samples with high-quality captions and aims to provide a large-scale dataset stylistically closer to MS COCO [293].
- COYO [241]: COYO is another large-scale image-text pair dataset, comprising approximately 747 million samples. Similar to LAION, it is sourced from web crawls and undergoes filtering processes. It offers the community an alternative large-scale pre-training resource to LAIONl.
- DataComp [243]: DataComp, contains 1.4 billion samples derived from Common Crawl using carefully designed filtering strategies (CLIP score and Image-based filtering), intended to provide higher quality image-text pairs than raw crawled data.
- ShareGPT4V [246]: This dataset provides approximately 100K high-quality image-text conversational data points. It is specifically designed and used to enhance the instruction-following and dialogue capabilities of large multimodal models, making them better conversational agents.
- ALLaVA [216]: This dataset, comprising 1.4 million samples, is synthetically generated to facilitate the training of resource-friendly Lite Vision-Language Models (LVLMs). The generation pipeline leverages strong proprietary models (like GPT-4V) in a multistage process: first, images are selected from sources like LAION and Vision-FLAN; then, fine-grained, detailed captions are generated for these images; finally, complex reasoning visual question-answering pairs are created, emphasizing detailed answers that include evidence and chain-of-thought, to support robust visual instruction fine-tuning.
- CapsFusion-120M [245]: It is a large-scale collection of 120M image-text pairs selected from Laion-COCO [242]. The caption is acquired by integrating the captions in Laion-COCO with CapsFusion-LLaMA [245].
- Cambrian-10M(7M) [247]: Cambrian-10M is a large-scale dataset designed for multimodal instruction tuning, sourced from a diverse array of data with an unbalanced distribution across categories. To enhance the quality of the dataset, data filtering based on a refined data ratio is applied, which results in the creation of Cambrian-7M.
- LLaVA-OneVision [248]: This visual instruction tuning collection features two main parts: a Single-Image dataset of 3.2 million diverse, categorized samples (QA, OCR, math, etc.), and the OneVision dataset with 1.6 million mixed-modal samples (including video, multi-image, and selected single-image data).
- Infinity-MM [248]: Infinity-MM is a comprehensive multimodal training dataset with over 40 million samples, created by extensively collecting and categorizing existing open-source datasets alongside newly generated data. This collection includes image captions, general visual instructions, higher-quality selective in
structions, and a significant portion of datagenerated by GPT-4 or synthesized using a custom视觉语言模型-based流水线 to ensure对齐和diversity. All data undergoes rigorous processing and filtering for quality and consistency.
- 其他数据集:最近开发的额外理解类数据集包括 GRIT (Grid-based Representation for Image-Text) [244] (20M 样本,强调细粒度图像区域与文本短语对齐)。此外,虽然 SAM 数据集 [251]最初并不包含图文对,但由 1100 万张高分辨率图像及详细分割掩码组成的集合提供了有价值的空间和语义信息。它可以增强多模态模型的细粒度理解能力,例如理解对象的位置、边界或执行特定区域的操作。此外,用于文本到图像的模型的数据也可以用于多模态理解任务。
4.2 Text-to-Image Datasets
这些数据集主要用于训练能够生成与文本描述相对应图像的模型。它们通常由图像-文本对组成,往往更强调图像的美学质量、内容的丰富性或特定的风格属性。
-
CC-12M(概念字幕12M)[250]: CC-12M包含大约1200万个从网络替代文本中提取并过滤的图文对。与原始网络抓取数据相比,其文本描述通常更简洁且更具描述性,因此被广泛用于训练文本到图像模型。
-
LAION-Aesthetics [240]: 这是 LAION 数据集的一个子集,使用美学评分模型进行筛选,以便为选出约 1.2 亿张被认为具有更高“美学价值”的图像(及其文本)。
-
文本渲染数据集:为专门解决在生成图像中准确且清晰地渲染文本的挑战,已开发了多个数据集。Mario-10M[252],(含1000万样本)用于训练TextDiffuser模型[252],提供了旨在改善文本布局和易读性的数据。RenderedText数据集[253]提供了1200万张高分辨率合成手写文本图像,具有多样的视觉属性,是手写文本理解与生成的丰富资源。AnyWord-3M[255],(含300万样本)对于训练像AnyText[255]这样的模型至关重要,同样侧重于提升生成文本的质量。最后,TextAtlas5M[265]针对密集文本生成,结合了交错的文档、合成数据和带有更长说明及人工注释的真实世界图像,以应对复杂的富文本图像场景。
-
JourneyDB [254]: JourneyDB 包含由 Midjourney 平台生成的 400 万对高质量图像-提示对。由于 Midjourney 以生成具有创造性和艺术性的图像而闻名,该数据集为训练模型学习复杂、细致且富有艺术风格的文本到图像映射提供了宝贵资源。
-
CosmicMan-HQ 1.0 [256]: 它由 600 万张高质量真实人像图像组成,平均分辨率为 1488 × 1255 1488 \times 1255 1488×1255 像素。该数据集的特点是其精确的文本注释,来源于 1.15 亿个不同粒度的属性。它可用于提升生成真人图像的能力。
-
DOCCI [257]: DOCCI 提供 1.5 万张精心策划的独特图像,每张图像都配有冗长的人工注释英文描述(平均 136 字),旨在提供高度详细的信息并区分相似图像。该数据集对细粒度描述和对比图像集的关注,使其成为训练和评估图像到文本与文本到图像模型的宝贵资源,尤其是评估它们处理细微细节和复杂构图能力时。
-
PixelProse [258]: PixelProse 从 Data- Comp [243], CC-12M [250], 和 RedCaps [238], 中提取, 包含带有相应文本描述的丰富注释图像。该数据集提供了有价值的元数据,例如水印存在和美学评分, 可用于过滤以获得期望的图像。
-
Megalith [260]: Megalith 是一个数据集,包含约 1000 万个指向 Flickr 上被归类为“照片”的图像链接,这些图像的许可证确保不存在版权限制。社区使用像 ShareCaptioner [246], Florence2 [294] 和 InternVL2 [11], [66] 这样的模型所制作的图注可公开获取。
-
PD12M [262]: PD12M由1240万张高质量公有领域和CCO许可图像组成,配有使用Florence-2-large [294]生成的合成字幕。它旨在用于训练文本到图像的模型,提供大量数据同时将版权问题降到最低。
-
合成数据集:用于文本到图像合成的专用数据集越来越多地使用现有生成模型创建。text-to-image-2M数据集[261]提供用于微调的200万条增强文本-图像对,这些样本由先进的T2I和图像描述模型精心筛选。SFHQ-T2I[263]提供12.2万张多样且高分辨率的合成人脸图像,由多个T2I模型生成,确保多样性和隐私保护。针对实体控制,EliGen训练集[264]使用来自基线模型(FLUX.1-dev)的图像和由MLLM生成的提示,以实现风格一致性和详细标注。类似地,BLIP-3o6万[169]提供6万条从GPT-4o蒸馏而来的指令微调样本,涵盖各种类别以支持多样化训练。ShareGPT-4o-Image[266]贡献了45K文本-图像对,其中提示通过属性优先方法和图像优先方法生成,相应图像由GPT-4o的图像生成能力合成,以蒸馏其高级技能。为专门解决真实数据中的薄弱点,Echo-4o-Image[267]提供了超过10万条样本,针对超现实幻想场景以及复杂的长尾指令,以增强模型的想象力和对齐性。
-
其他数据集:SAMdataset [251] (约1100万高分辨率图像)和DenseFusion [259] (100万样本)是文本到图像的其他潜在数据来源
structures, and a significant portion of data generated by GPT-4 or synthesized using a custom VLM-based pipeline to ensure alignment and diversity. All data undergoes rigorous processing and filtering for quality and consistency.
- Other Datasets: Additional understanding datasets developed recently include GRIT (Grid-based Representation for Image-Text) [244] (20M samples emphasizing fine-grained image region-text phrase alignment). Furthermore, while SAM Dataset [251] does not initially consist of image-text pairs, the collection of 11 million high-resolution images with detailed segmentation masks offers valuable spatial and semantic information. It can enhance the fine-grained understanding capabilities of multimodal models, like comprehending object locations, boundaries, or performing region-specific operations. In addition, data for text-to-image models can also be used for multimodal understanding task.
4.2 Text-to-Image Datasets
These datasets are mainly used for training models that generate images corresponding to textual descriptions. They typically consist of image-text pairs, often with a higher emphasis on the aesthetic quality of the images, the richness of the content, or specific stylistic attributes.
-
CC-12M (Conceptual Captions 12M) [250]: CC-12M contains about 12 million image-text pairs extracted and filtered from web Alt-text. Compared to raw web-crawled data, its textual descriptions are generally more concise and descriptive, making it widely used for training text-to-image models.
-
LAION-Aesthetics [240]: This is a subset of the LAION dataset, filtered using an aesthetic scoring model to select approximately 120 million images (and their texts) deemed to have higher “aesthetic value”.
-
Text Rendering Datasets: Several datasets have been developed to specifically address the challenges of accurately and legibly rendering text within generated images. Mario-10M [252], with 10 million samples, was used to train the TextDiffuser model [252], providing data designed to improve text placement and legibility. The RenderedText dataset [253] offers 12 million high-resolution synthetic images of handwritten text, generated with diverse visual attributes, serving as a rich resource for handwritten text understanding and generation. AnyWord-3M [255], containing 3 million samples, is crucial for training models like AnyText [255] and also focuses on enhancing the quality of generated text. Lastly, TextAtlas5M [265] targets dense text generation, incorporating a diverse mix of interleaved documents, synthetic data, and real-world images with longer captions and human annotations to tackle complex text-rich image scenarios.
-
JourneyDB [254]: JourneyDB consists of 4 million high-quality image-prompt pairs generated by the Midjourney platform. As Midjourney is known for generating creative and artistic images, this dataset provides valuable resources for training models to learn complex, detailed, and artistically styled text-to-image mappings.
-
CosmicMan-HQ 1.0 [256]: It comprises 6 million high-quality real-world human images with an average resolution of 1488 × 1255 1488 \times 1255 1488×1255 pixels. This dataset is distinguished by its precise text annotations, derived from 115 million attributes varying in granularity. It can be used to improve the capability of generating human images.
-
DOCCI [257]: DOCCI provides 15k uniquely curated images, each with long, human-annotated English descriptions (average 136 words) designed to be highly detailed and to differentiate between similar images. The dataset’s focus on fine-grained descriptions and contrastive image sets makes it a valuable resource for training and evaluating both image-to-text and text-to-image models, particularly for their ability to handle nuanced details and complex compositions.
-
PixelProse [258]: PixelProse extracted from DataComp [243], CC-12M [250], and RedCaps [238], contains richly annotated images with corresponding textual descriptions. This dataset provides valuable metadata such as watermark presence and aesthetic scores which can be used for filtering to get expected images.
-
Megalith [260]: Megalith is a dataset consisting of approximately 10 million links to Flickr images categorized as “photo” with licenses ensuring no copyright restrictions. The captions made by the community using models like ShareCaptioner [246], Florence2 [294], and InternVL2 [11], [66] are available publicly.
-
PD12M [262]: PD12M consists of 12.4 million high-quality public domain and CC0-licensed images paired with synthetic captions generated using Florence-2-large [294]. It is designed for training text-to-image models, offering a substantial collection while minimizing copyright concerns.
-
Synthesized Datasets: Specialized datasets for text-to-image synthesis are increasingly created using existing generative models. The text-to-image-2M dataset [261] provides 2 million enhanced text-image pairs for fine-tuning, curated using advanced T2I and captioning models. SFHQ-T2I [263] offers 122K diverse, high-resolution synthetic face images generated by multiple T2I models, ensuring variance and privacy. For entity control, the EliGen TrainSet [264] uses images from a baseline model (FLUX.1-dev) and MLLM-generated prompts for stylistic consistency and detailed annotation. Similarly, BLIP-3o 60k [169] provides 60,000 instruction tuning samples distilled from GPT-4o, covering various categories for diverse training. ShareGPT-4o-Image [266] contributes 45K text-to-image pairs, where prompts are generated through both a structured attribute-first approach and an image-first approach, with corresponding images synthesized by GPT-4o’s image generation capabilities to distill its advanced skills. To specifically address blind spots in real-world data, Echo-4o-Image [267] provides over 100K samples targeting surreal fantasy scenarios and complex, long-tail instructions to enhance model imagination and alignment.
-
Other Datasets: SAM dataset [251] (approx. 11 M high-resolution images) and DenseFusion [259] (1M samples) are other potential data sources for text-to-image
生成模型训练。请注意,多模态理解数据集可用于通过美学评分过滤、不适宜工作过滤、分辨率过滤、水印过滤、重新配注释等方法来合成文本到图像生成的数据,但此处不再赘述。
4.3图像编辑数据集
随着模型能力的提升,基于指令的图像编辑已成为一个重要的研究方向。本类别的数据集通常包含(三元组:源图像、编辑指令、目标图像)。这些数据集用于训练模型根据
文本命令,从而增强两方面的理解——
生成能力d能力 bilities o f unified models.
- InstructPix2Pix [268]: 该数据集使用一种创新的合成方法生成:首先,大语言模型(如GPT-3)生成针对目标图像的编辑指令和图注;然后,基于原始和目标图注,文本到图像模型(如Stable Diffusion)生成“前”后图像。该方法自动创建了约313K(指令、输入图像、输出图像)训练样本。
- MagicBrush [269]: MagicBrush 是一个高质量的人工注释的基于指令的图像编辑数据集。它包含约 1 万个样本,涵盖各种真实且精细颗粒度的编辑操作(如添加/移除/替换对象、属性修改、风格迁移),并为被编辑区域提供掩码。其人工注释使得指令更加自然且多样。
- HIVE [270]: HIVE 框架将人工反馈引入指令式视觉编辑,提供了一个 110 万的训练数据集(使用与 InstructPix2Pix 类似的方法,通过 GPT-3 和 Prompt-to-Prompt 生成,并辅以循环一致性增强)以及一个 3.6K 的奖励数据集,在该数据集中人类对模型输出进行排序。
- EditWorld [272]: EditWorld 提出了“基于世界指令的图像编辑”任务,侧重于逼真的世界动态。其数据集通过两条路径策划:一方面使用 GPT-3.5 生成世界指令并用文本到图像模型(T2I models)生成复杂的输入-输出图像;另一方面则从视频中提取配对帧,并由视觉-语言模型为动态变换生成相应指令。
- PromptFix [274]: PromptFix 构建了一个大规模的遵循指令的数据集(1.01M 三元组),覆盖广泛的图像处理任务,特别是低级任务(例如图像修补、去雾、超分辨率、上色)。
- HQ-Edit [271],SEED-Data-Edit [165], UltraEdit [273], OmniEdit [275], AnyEdit [276]: 这些代表了较新的、大规模的图像编辑数据集。例如,SEED-Data-Edit 包含 370 万样本,UltraEdit 包含 400 万样本,AnyEdit 提供 250 万样本,OmniEdit 包括 1.2M 样本,而 HQ-Edit 包含 19.7 万样本。它们常将自动化生成与人工过滤/注释相结合,旨在提供更大规模、更高质量和更多样化的编辑-
使用指令和图像对来训练更健壮的跟随指令的编辑模型。
- RefEdit [277]: 该合成数据集专门针对基于指令的编辑涉及指代的挑战文本部分(提示词、指令、指称表达)使用GPT-4o生成,初始图像由FLUX提供,Grounded SAM用于根据表达生成精确掩码,且为受控编辑(如对象)使用专门模型。
移除或修改。 - ImgEdit [278]: ImgEdit 是一个大规模(1.2M 编辑对)数据集,旨在支持高质量的单轮和多轮图像编辑。其多阶段生成流水线对 LAION-Aesthetics 进行过滤,使用视觉-语言模型和检测/分割模型进行定位和指令生成(包括空间提示和多轮对话),采用最先进的生成模型(FLUX、带插件的 SDXL)进行任务特定的图像修补,并使用 GPT-4o 进行最终质量过滤。
- ByteMorph-6M [279]: ByteMorph-6M 是一个大规模数据集,包含超过 600 万张图像编辑对,专为涉及非刚性运动(例如相机视角变化、对象变形、人体关节动作)的指令引导编辑而设计。其构建过程首先使用视觉-语言模型从初始帧的指令模板生成“运动描述字幕”;随后,基于该运动描述字幕的图像到视频模型生成动态视频;最后从这些视频中采样帧,并由大语言模型生成精确的编辑指令,描述相邻帧对之间的变换,从而形成源-目标编辑数据。
- ShareGPT-4o-Image (Editing) [266]: 在其文本到图像的数据之外, ShareGPT-4o-Image 还包含 46K 指令引导的图像编辑三元组。这些样本的生成流程是先选择源图像(来源于其文本到图像集合或真实照片),然后从预定义的分类法中抽取一个编辑任务(例如,对象操作、风格迁移),接着由大语言模型为该任务和图像合成一条自然语言指令,最后使用 GPT-4o 的图像生成能力来生成编辑后的图像。
- GPT-Image-Edit-1.5M [280]: GPT-IMAGE-EDIT-1.5M 是一个大规模图像编辑数据集,包含超过 150 万条高质量的指令引导图像编辑三元组。它通过利用 GPT-4o 的强大能力,系统性地统一并精炼了三个现有数据集:OmniEdit、HQ-Edit 和 UltraEdit。核心方法包括重新生成输出图像以提升视觉质量和指令对齐性,以及有选择地重写提示词以改善语义清晰度。该过程产出了一份高保真语料,旨在弥合专有与开源指令引导图像编辑模型之间的差距。
- X2Edit [281]: X2Edit 是一个大规模且全面的图像编辑数据集,包含 370 万样本,旨在在 14 种多样化的编辑任务之间实现平衡。它通过一个自动化流程构建,首先使用 VLM 生成任务感知指令,
generation model training. Note that, the multimodal understanding datasets can be utilized for synthesizing text-to-image generation data via aesthetics score filtering, NSFW filtering, resolution filtering, watermark filtering, recaption, etc., which is not introduced here.
4.3 Image Editing Datasets
With advancing model capabilities, instruction-based image editing has become an important research direction. Datasets in this category typically contain triplets of (source image, editing instruction, target image). These datasets are utilized to train models to alter input images according to textual commands, thereby enhancing both the comprehension and generation capabilities of unified models.
- InstructPix2Pix [268]: This dataset was generated using an innovative synthetic approach: first, a large language model (like GPT-3) generates an editing instruction and a caption for the target image; then, a text-to-image model (like Stable Diffusion) generates the “before” and “after” images based on the original and target captions. This method automatically created about 313K (instruction, input image, output image) training samples.
- MagicBrush [269]: MagicBrush is a high-quality, manually annotated dataset for instruction-based image editing. It contains approximately 10K samples covering various realistic and fine-grained editing operations (like object addition/removal/replacement, attribute modification, style transfer) and provides masks for the edited regions. Its manual annotation leads to more natural and diverse instructions.
- HIVE [270]: The HIVE framework introduces human feedback into instructional visual editing, providing a 1.1M training dataset (generated similarly to InstructPix2Pix using GPT-3 and Prompt-to-Prompt, plus cycle consistency augmentation) and a 3.6K reward dataset where humans rank model outputs.
- EditWorld [272]: EditWorld introduces the task of “world-instructed image editing,” focusing on realistic world dynamics. Its dataset is curated through two branches: one uses GPT-3.5 for world instructions and T2I models for complex input-output image generation, and the other extracts paired frames from videos with vision-language models generating corresponding instructions for dynamic transformations.
- PromptFix [274]: PromptFix constructs a large-scale instruction-following dataset (1.01M triplets) focusing on a comprehensive range of image processing tasks, particularly low-level tasks (e.g., inpainting, dehazing, super-resolution, colorization).
- HQ-Edit [271], SEED-Data-Edit [165], UltraEdit [273], OmniEdit [275], AnyEdit [276]: These represent more recent, larger-scale image editing datasets. For instance, SEED-Data-Edit contains 3.7M samples, UltraEdit has 4M samples, AnyEdit provides 2.5M samples, OmniEdit includes 1.2M samples, and HQ-Edit contains 197K samples. They often combine automated generation with human filtering/annotation, aiming to provide larger-scale, higher-quality, and more diverse edit
ing instructions and image pairs to train more robust instruction-following editing models.
- RefEdit [277]: This synthetic dataset specifically targets instruction-based editing challenges involving referring expressions in complex scenes. It’s generated using GPT-4o for text components (prompts, instructions, referring expressions), FLUX for initial images, Grounded SAM for precise mask generation from expressions, and specialized models for controlled edits like object removal or modification.
- ImgEdit [278]: ImgEdit is a large-scale (1.2M edit pairs) dataset designed for high-quality single-turn and multi-turn image editing. Its multi-stage generation pipeline filters LAION-Aesthetics, uses vision-language models and detection/segmentation models for grounding and instruction generation (including spatial cues and multi-turn dialogues), employs state-of-the-art generative models (FLUX, SDXL with plugins) for task-specific inpainting, and uses GPT-4o for final quality filtering.
- ByteMorph-6M [279]: ByteMorph-6M is a large-scale dataset with over 6 million image editing pairs specifically designed for instruction-guided editing involving non-rigid motions (e.g., camera viewpoint shifts, object deformations, human articulations). It is constructed by first using a Vision-Language Model to generate “Motion Captions” from instruction templates for an initial frame; then, an image-to-video model generates a dynamic video based on this motion caption; finally, frames are sampled from these videos, and an LLM generates precise editing instructions describing the transformation between neighboring frame pairs, which form the source-target editing data.
- ShareGPT-4o-Image (Editing) [266]: Complementing its text-to-image data, ShareGPT-4o-Image also includes 46K instruction-guided image editing triplets. These samples are generated by first selecting a source image (either from its text-to-image collection or real photos), then sampling an editing task from a predefined taxonomy (e.g., object manipulation, style transfer), having an LLM synthesize a natural language instruction for that task and image, and finally using GPT-4o’s image generation capabilities to produce the edited image.
- GPT-Image-Edit-1.5M [280]: GPT-IMAGE-EDIT-1.5M is a large-scale image editing dataset containing over 1.5 million high-quality instruction-guided image editing triplets. It is constructed by leveraging the powerful capabilities of GPT-4o to systematically unify and refine three existing datasets: OmniEdit, HQ-Edit, and UltraEdit. The core methodology involves regenerating output images to enhance visual quality and instruction alignment, as well as selectively rewriting prompts to improve semantic clarity. This process results in a high-fidelity corpus designed to bridge the gap between proprietary and open-source instruction-guided image editing models.
- X2Edit [281]: X2Edit is a large-scale and comprehensive image editing dataset with 3.7 million samples, designed to be balanced across 14 diverse editing tasks. It is constructed through an automated pipeline that first uses a VLM to generate task-aware instructions,
随后由业界领先且经验丰富的生成模型执行这些操作以产生编辑图像。为了解决现有开源资源在质量和均衡性方面的问题,所有生成的配对都经过基于多种评分机制的最终严格过滤阶段,以确保高保真度和准确性。
4.4 交错图文数据集
除了由图像与图注配对组成的数据集外,
另一个重要类别包括交错的图像
te与文本数据。这些数据集包含文档或序列,w其中文本和图像自然地相互跟随,反映出
in在网页或文档中发现的内容。训练
m模型在这些交错数据上的训练增强了它们
理解和生成多模态内容的能力,这是一个必要的g统一模型的目标。
- Multimodal C4 (MMC4) [282]: MMC4 通过将图像按算法方式交错插入来自 Common Crawl 的文本文档,扩展了大规模纯文本 C4 [23] 语料库。这个公开数据集包含超过 1.01 亿个文档和 5.71 亿幅图像,旨在为设计用于处理图像与文本混合序列的模型提供必要的交错预训练数据。
- OBELICS [283]: OBELICS 是一个开放的、网络级规模的数据集, 包含从 Common Crawl 提取的 1.41 亿个多模态网页文档, 具有与 1150 亿文本标记交错的 3.53 亿幅图像。该数据集侧重于捕捉完整的文档结构, 而非孤立的图文对, 旨在提升模型在各类基准测试上的表现。
- CoMM [284]: CoMM 是一个高质量的、经过策划的数据集,专注于连贯性和一致性方面的交错图像-文本序列,包含约 227K 样本。它通过主要从教学类和视觉叙事网站(如 WikiHow)获取内容,并采用多视角过滤策略,解决了在更大数据集中观察到的叙事流畅性和视觉一致性方面的局限。CoMM 旨在提升 MLLMs 生成逻辑结构良好且视觉一致的多模态内容的能力,并引入了专门用于评估这些能力的新基准任务。
- OmniCorpus [285]: OmniCorpus 是一个非常大规模(数十亿级)的图像-文本交错数据集,包含 86 亿张图像和 1,6960 亿(应保持原文为 1,696 billion)文本标记,来自 22 亿份文档。它使用一个高效的数据引擎创建,从多样化来源提取并过滤内容,包括英语和非英语网站以及视频平台(提取关键帧并转录音频)。该数据集融入了人工反馈过滤以提升数据质量,旨在为 MLLM 研究提供坚实的基础。
4.5其他文本+图像到图像数据集
B除了前面提到的类别之外,为了进一步
增强统一模型的能力——例如生成
基于提供的主体图像的图像,或利用控制信号(例如深度图、Canny边缘图)——我们在本节介绍相关数据集。
LAION-Face[286]:上述讨论的数据集强调通用的主体驱动生成,而保留身份的图像生成则是该类别的一个特殊子集。
利用包含50M图文对的LAION-Face,最近的进展如InstantID [295] 已成功生成
在保持角色身份的同时处理图像。
-
MultiGen-20M [287]: 该数据集包含 20M 样本,旨在训练能够在多种控制信号(例如文本描述、深度图、边缘图、分割掩码、草图)条件下进行统一图像生成的模型,如 UniControl [287]。它整合来自各个来源的数据并将其转换为统一格式,使模型能够学习多任务、多条件的图像生成。数据集可以组织为三元组,例如“深度图、带提示的指令、目标图像”(“带提示的指令”可以表述为:“根据深度图生成一幅令人印象深刻的场景。”),以有效地训练统一模型。
-
Subjects200K [288]: 包含20万个样本,Subjects200K侧重于以主体为驱动的 -图像生成,这对于个性化内容创作至关重要。该数据集通过一个多阶段流水线合成生成:首先,一个大语言模型(ChatGPT-4o)创建涉及对象类别和场景的结构化描述;随后,一个图像合成模型(FLUX [16])基于这些描述生成多样但一致的配对图像;最后,大语言模型对生成的图像对进行质量评估,以确保主体一致性、合适的构图,和
高分辨率。
- SynCD [289]: SynCD (
SyntheticCustomizationDataset)提供大约9.5万组图像,专为文本到图像的图像定制任务设计,解决了缺乏公开数据集包含同一对象在多种Conditions下多张图像的问题。它通过利用现有的文本到图像模型和3D素材数据集(如Objaverse [296])合成,生成同一对象在不同光照、背景和姿势下的多视角一致图像,包含
诸如共享注意力和深度引导等技术。
- X2I-subject-driven [84]: X2I-subject-driven 数据集通过两个组成部分促进主体驱动的图像生成。
GRIT-Entity 数据集源自 GRIT [244] dataset,通过自动检测并分割图像中的对象,随后可选择性地使用 MS-Diffusion [297] 重绘步骤以提高质量和多样性。为了鼓励超越简单复制粘贴模式的更稳健的生成能力,更高质量的 Web-Images 数据集是通过自动文本分析和大型语言模型过滤识别出知名个体、抓取其网页图像、进行自动视觉验证以确保主体准确性,然后对所选图像进行图注而构建的。
- Graph200K [290]: Graph200K 是一个图结构的
which are then executed by industry-leading and expert generative models to produce the edited images. To overcome the quality and balance issues in existing open-source resources, all generated pairs undergo a final, rigorous filtering stage based on multiple scoring mechanisms to ensure high fidelity and accuracy.
4.4 Interleaved Image-Text Datasets
Beyond datasets consisting of paired images and captions, another important category comprises interleaved image-text data. These datasets contain documents or sequences where text and images naturally follow one another, mirroring content found on webpages or in documents. Training models on this interleaved data enhances their capability to comprehend and generate multimodal content, an essential goal for unified models.
- Multimodal C4 (MMC4) [282]: MMC4 augments the large-scale text-only C4 [23] corpus by algorithmically interleaving images into the text documents sourced from Common CWEl. This public dataset, containing over 101 million documents and 571 million images, was created to provide the necessary interleaved pretraining data for models designed to process mixed sequences of images and text.
- OBELICS [283]: OBELICS is an open, web-scale dataset comprising 141 million multimodal web documents extracted from Common Crawl, featuring 353 million images interleaved with 115 billion text tokens. The dataset focuses on capturing the full document structure rather than isolated image-text pairs, aiming to improve model performance on various benchmarks.
- CoMM [284]: CoMM is a high-quality, curated dataset focused specifically on the coherence and consistency of interleaved image-text sequences, containing approximately 227K samples. It addresses limitations in narrative flow and visual consistency observed in larger datasets by sourcing content primarily from instructional and visual storytelling websites (like WikiHow) and applying a multi-perspective filtering strategy. CoMM aims to enhance MLLMs’ ability to generate logically structured and visually consistent multimodal content and introduces new benchmark tasks specifically designed to evaluate these capabilities.
- OmniCorpus [285]: OmniCorpus is a very large-scale (10 billion-level) image-text interleaved dataset, containing 8.6 billion images and 1,696 billion text tokens from 2.2 billion documents. It was created using an efficient data engine that extracts and filters content from diverse sources, including English and non-English websites as well as video platforms (extracting keyframes and transcribing audio). The dataset incorporates human-feedback filtering to enhance data quality, aiming to provide a solid foundation for MLLM research.
4.5 Other Text+Image-to-Image Datasets
Beyond the previously mentioned categories, to further enhance a unified model’s capabilities—such as generating
images based on provided subject images, or utilizing control signals (e.g., depth maps, canny maps) —we introduce relevant datasets in this section.
- LAION-Face [286]: The datasets discussed above emphasize general subject-driven generation, whereas ID-preserving image generation represents a specialized subset of this category. Utilizing LAION-Face, which includes 50 million image-text pairs, recent advancements such as InstantID [295] have succeeded in generating images while maintaining character identity.
- MultiGen-20M [287]: This dataset comprises 20 million samples designed to train models capable of unified image generation conditioned on multiple control signals (e.g., text descriptions, edge maps, depth maps, segmentation masks, sketches), such as UniControl [287]. It integrates data from various sources and converts them into a unified format, enabling models to learn multitask, multi-conditional image generation. The dataset can be structured as triples, such as “depth map, instruction with prompt, target image” (The “instruction with prompt” might be phrased as: “Generate an impressive scene following the depth map.”, to effectively train unified models.
- Subjects200K [288]: Containing 200K samples, Subjects200K focuses on subject-driven image generation, crucial for personalized content creation. This dataset was generated synthetically through a multi-stage pipeline: initially, an LLM (ChatGPT-4o) creates structured descriptions involving object categories and scenes; subsequently, an image synthesis model (FLUX [16]) generates diverse yet consistent paired images based on these descriptions; finally, the LLM performs quality assessment on the generated pairs to ensure subject consistency, proper composition, and high resolution.
- SynCD [289]: SynCD (Synthetic Customization Dataset) provides approximately 95K sets of images specifically designed for text+image-to-image customization tasks, addressing the lack of public datasets containing multiple images of the same object under diverse conditions. It is synthesized by leveraging existing text-to-image models and 3D asset datasets (like Objaverse [296]) to generate multiple consistent views of an object with varied lighting, backgrounds, and poses, incorporating techniques like shared attention and depth guidance.
- X2I-subject-driven [84]: The X2I-subject-driven dataset facilitates subject-driven image generation through two components. The GRIT-Entity dataset is derived from the GRIT [244] dataset by automatically detecting and segmenting objects from images, followed by an optional MS-Diffusion [297] repainting step to improve quality and diversity. To encourage more robust generative capabilities beyond simple copy-paste patterns, the higher-quality Web-Images dataset was constructed by identifying notable individuals through automated text analysis and large language model filtering, scraping their web images, performing automated visual verification to ensure subject accuracy, and then captioning the selected images.
- Graph200K [290]: Graph200K is a graph-structured
基于Subjects200K构建的数据集,每张图像都附带49种注释,涵盖五类元任务:条件生成(例如Canny边缘、深度图、分割)、IPpreservation、风格转换(语义可变与语义不变)、图像编辑(使用VLMs和修复模型的背景可变与背景不变)以及修复(通过在线降质)。该结构旨在提高任务密度和任务间关联,使模型通过将任务表述为图中路径来学习共享且可迁移的知识,以实现通用图像生成。
- Echo-4o-Image (Multi-Reference) [267]: 该数据集组件解决了自然图像集合中结构化、多输入生成任务稀缺的问题。它为“多对一”生成提供了73K合成样本,专门设计了多样化的指令和丰富的参考信息。与从视频帧采样等替代方法相比,这种受控合成为多参考图像构图提供了更有针对性且更为多样的训练来源。
主体驱动生成(包含单主体与多主体)是一项关键的图像生成能力,正日益受到社区关注。它也被预期将成为统一模型的一个重要特性。然而,从公开数据集中获取此类专用数据具有挑战性,因此常常采用数据合成方法,诸如Subjects200K和SynCD这样的数据集即为例证。这些数据集说明了为满足主体驱动生成和定制等任务所需的公开可用训练样本不足时,对合成数据的日益依赖。
为了创建大规模数据集,各种流水线 [85], [297], [298], [299] 已被开发出来,用于以程序化方式生成合适的训练数据,通常利用易于获取的图像或视频源。下面我们简要概述这些流水线以供参考。
- 从图像进行数据合成:这些流水线通常从单张图像开始,使用诸如 BLIP-2 [53] 或 Kosmos2 [244] 等模型进行初始图像描述(包括带有边界框的定位图注),随后进行目标检测(例如 Grounding DINO [300])和分割(例如 SAM [251])以提取主体掩码和区域图注。这些流水线可以生成用于单一主体定制和多个主体定制的数据。
- 从视频进行数据合成:由图像构建的数据常常在模型学习中导致复制粘贴问题。通过使用视频分割模型(例如SAM2 [301])从不同帧中提取主体来合成数据的流水线可以缓解此问题。此外,该流水线还可以生成用于图像编辑任务的训练数据。[85]。
健壮的统一多模态模型在很大程度上依赖于近年来开发的大规模、高质量且多样化的训练数据集,这些数据集包括图文对、交错的图文文档和特定任务格式。虽然大规模的网络级配对数据(如 LAION、COYO)和交错文档语料(如 MMC4、OBELICS)
为预训练提供了广泛的语义覆盖和上下文理解,许多工作则着重于提高数据质量并为特定属性或高级能力定制资源。专用数据集对改进基于指令的图像编辑、准确的文本渲染、连贯的多模态生成以及复杂的条件控制愈发重要。此外,鉴于用于基于指令的图像编辑和主体定制等任务的高质量公开数据稀缺,数据合成流水线的开发与利用已成为必要手段,从而能够创建训练这些高度特定模型功能所需的定向数据集。归根结底,这些多样化数据资源的持续演进、规模扩展、目标化专业化与创新合成,是推动统一多模态模型日益复杂的理解与生成能力的根本动力。
5基准测试
现代大规模统一多模态模型不仅应在像素级别对视觉与语言信息进行对齐,还应执行复杂推理、支持连贯的多轮对话并整合外部知识。同时,这些模型还应生成高保真度的视觉输出,忠实遵循文本提示,并为用户提供对风格和构图要素的细粒度控制。本节系统性地总结了相关评估基准。统计摘要见表4。
5.1 理解方面的评估
感知。现代视觉-语言大模型必须通过定位、识别和检索,准确地将视觉输入与语言描述连接起来。早期的图像-文本检索和图注基准,如Flickr30k[365],MS COCO 图注[366],用于评估模型是否能够检索相关图注并将文本短语定位到图像区域。视觉问答基准
像VQA[302],VQA v2 [303],VisDial [308]和TextVQA[310]进一步要求模型解释复杂场景并对关于对象的自由形式查询给出答案,
attributes and relations hips。领域特定 fic challenges such as ChartQA [309] 评估对结构化图表和图形的理解,而 VSR [8] 探究真实世界图像中的空间关系推理。
为了统一评估,大规模元基准套件同时测试低级感知和专家推理。MMBench [316] 提供了 3K 双语多项选择题,涵盖定位、识别和检索,从而实现跨语言比较。MMMU [317] 增加了约 11.5K 遍及六个学科的大学水平多模态问题,用以探查领域知识和逻辑推理。HaluEval [312] 在多样的模型生成和带注释语句上诊断幻觉识别。MM-Vet [318] 覆盖识别、光学字符识别、空间推理、数学和开放式问答,其 v2 [319] 进一步评估图文交错序列。SEED-Bench [321] 设计了一个生成多项选择题的流水线,以针对特定评估维度
dataset built upon Subjects200K, where each image is augmented with 49 types of annotations spanning five meta-tasks: conditional generation (e.g., canny edges, depth maps, segmentation), IP preservation, style transfer (semantic-variant and -invariant), image editing (background-variant and -invariant using VLMs and inpainting models), and restoration (via online degradations). This structure aims to increase task density and inter-relation, enabling models to learn shared and transferable knowledge for universal image generation by formulating tasks as paths within this graph.
- Echo-4o-Image (Multi-Reference) [267]: This component of the dataset addresses the scarcity of structured, multi-input generation tasks in natural image collections. It provides 73K synthetic samples for “Multi-to-one” generation, which are explicitly designed with diverse instructions and rich reference information. This controlled synthesis offers a more targeted and varied training source for multi-reference image composition compared to alternatives like sampling from video frames.
Subject-driven generation, involving both single and multiple subjects, is a crucial image generation capability that is increasingly attracting attention within the community. It is also anticipated to be a significant feature inherent in unified models. However, obtaining such specialized data from public datasets is challenging, leading to the frequent use of data synthesis methods, exemplified by datasets like Subjects200K and SynCD. These datasets illustrate the growing reliance on synthetic data to address the shortage of publicly available training examples needed for tasks like subject-driven generation and customization.
To create large-scale datasets, various pipelines [85], [297], [298], [299] have been developed to programmatically generate suitable training data, typically utilizing readily accessible image or video sources. Below, we provide a brief overview of these pipelines for reference.
- Data synthesis from images: These pipelines often start with single images, using models like BLIP-2 [53] or Kosmos2 [244] for initial captioning (including grounding captions with bounding boxes), followed by object detection (e.g., Grounding DINO [300]) and segmentation (e.g., SAM [251]) to extract subject masks and region captions. These pipelines can generate data for single subject customization and multiple subjects customization.
- Data synthesis from videos: Data constructed from images often cause the copy-paste issue in model learning. The pipeline of synthesizing data from videos can alleviate this issue by extracting subjects from different frames with video segmentation models (e.g., SAM2 [301]). In addition, this pipeline can also enable the generation of training data for image editing task. [85].
Robust unified multimodal models rely critically on large-scale, high-quality, and diverse training datasets developed recently, encompassing image-text pairs, interleaved image-text documents, and task-specific formats. While massive web-scale paired data (like LAION, COYO) and interleaved document corpora (like MMC4, OBELICS)
provide broad semantic coverage and contextual understanding for pre-training, significant efforts focus on enhancing data quality and tailoring resources for specific attributes or advanced capabilities. Specialized datasets are increasingly crucial for improving instruction-based editing, accurate text rendering, coherent multimodal generation, and complex conditional control. Furthermore, recognizing the scarcity of high-quality public data for tasks like instruction-based image editing and subject customization, the development and utilization of data synthesis pipelines have become essential, enabling the creation of targeted datasets needed to train these highly specific model functionalities. Ultimately, the continuous evolution, growing scale, targeted specialization, and innovative synthesis of these varied data resources are the fundamental drivers enabling the increasingly sophisticated understanding and generation capabilities of unified multimodal models.
5 BENCHMARKS
Modern large-scale unified multimodal models should not only align visual and linguistic information at the pixel level but also perform complex reasoning, support coherent multi-turn dialogue and integrate external knowledge. Simultaneously, these models are expected to produce high-fidelity visual outputs that faithfully adhere to textual prompts while providing users with fine-grained control over stylistic and compositional elements. In this section we systematically summarize the related evaluation benchmarks. Please refer to Tab. 4 for statistical summary.
5.1 Evaluation on Understanding
Perception. Modern vision-language large models must accurately connect visual inputs with linguistic descriptions through grounding, recognition and retrieval. Early image-text retrieval and captioning benchmarks such as Flickr30k [365], MS COCO Captions [366] evaluate whether models can retrieve relevant captions and localize textual phrases to image regions. Visual question answering benchmarks like VQA [302], VQA v2 [303], VisDial [308] and TextVQA [310] further require models to interpret complex scenes and answer free-form queries about objects, attributes and relationships. Domain-specific challenges such as ChartQA [309] assess understanding of structured charts and graphs, while VSR [8] probes spatial relation reasoning in real-world images.
To unify the evaluation, large-scale meta-benchmark suites test both low-level perception and expert reasoning. MMBench [316] supplies 3K bilingual multiple-choice questions spanning grounding, recognition and retrieval, enabling cross-lingual comparison. MMMU [317] adds about 11.5K college-level multimodal problems across six disciplines to probe domain knowledge and logical deduction. HaluEval [312] diagnoses hallucination recognition on a diverse set of model-generated and annotated statements. MM-Vet [318] covers recognition, OCR, spatial reasoning, maths and open question answering, and its v2 [319] further evaluates interleaved image-text sequences. SEED-Bench [321] designs a pipeline for generating multiple-choice questions that target specific evaluation dimensions
当前对统一大规模生成模型的评估和基准测试的统计摘要。该表将基准测试分为理解、图像生成和交错生成,详细列出了每一类的规模、描述、输入/输出类型和发表会议。
表4
| 基准 | Size | 描述 | 输入/输出类型 | 发表会议 |
| 理解 | ||||
| VQA [302] | 1000万问答对 | 开放域视觉问答 | 图像+问题→答案 | ICCV2015 |
| VQAv2 [303] | 100万问答对 | 开放域视觉问答 | 图像+问题→答案 | CVPR2017 |
| CLEVR [304] | 85.3万问答对 | 组合式视觉问答 | 图像+问题→答案 | CVPR2017 |
| GQA [305] | 2200万问答对 | 组合式视觉问答 | 图像+问题→答案 | CVPR2019 |
| OK-VQA [306] | 14K问答对 | 基于知识的视觉问答 | 图像+问题→答案 | CVPR2019 |
| VCR [307] | 29万问答对 | 常识视觉问答 | 图.+问.→答案+推理依据 | CVPR2019 |
| VisDial [308] | 120万对话 | 多轮视觉对话 | 图像+对话→答案 | CVPR2019 |
| ChartQA [309] | 3.27万问答 | 数据可视化问答 | 图像+问题→答案 | ACL2020 |
| TextVQA [310] | 4.5万问答 | 场景文本视觉问答 | 图像+问题→答案 | CVPR2020 |
| A-OKVQA [311] | 25K问答对 | 扩展常识视觉问答 | 图像+问题→答案 | ECCV2022 |
| HaluEval [312] | 35K样本 | 幻觉检测 | 模型输出→是/否 | EMNLP2023 |
| VSR [8] | 3K问答对 | 空间推理 | 图像+问题→真/假 | TACL2023 |
| LAMM [313] | 62K问答 | 指令基准测试 | 特征+Instruction→输出 | NeurIPS2023 |
| LLaVa-Bench [314] | 150问答 | 指令基准测试 | 图像+问题→答案 | NeurIPS2023 |
| OwlEval [315] | 82问题 | 视觉相关评估 | 图像+指令→答案 | Arxiv2023 |
| MMBench [316] | 3K问答对 | 细粒度多模态评估 | 图像+问题→答案 | ECCV2024 |
| MMMU [317] | 1.15万问答 | 专家级理解 | 图像+问题→答案 | CVPR2024 |
| MM-Vet [318] | 218样本 | 视觉-语言能力评估 | 图像+问题→答案 | ICML2024 |
| MM-Vet v2 [319] | 218+样本数 | 视觉-语言序列理解 | 图像+序列→答案 | arXiv2024 |
| MMStar [320] | 1.5K问答对 | Vision Indispensable Eval | 图像+问题→答案 | NeurIPS2024 |
| SEED-Bench [321] | 19K问答对 | 综合评估 | 图像/视频+MCQ→答案 | CVPR2024 |
| Open-VQA [322] | 多样化 | VQA评估 | 图像+问/答→问答链 | ICLR2024 |
| MathVista [323] | 6K问答 | 数学推理 | 图像+文本→数学输出 | ICLR2024 |
| General-Bench [324] | >700任务 | 超大规模评估 | 按任务多样化 | Arxiv2025 |
| 图像生成 | ||||
| DrawBench [72] | 200提示 | 综合评估 | 文本提示→图像 | NeurIPS 2022 |
| PartiPrompts [325] | 1600提示 | 综合评估 | 文本提示→图像 | TMLR 2022 |
| PaintSkills [326] | ~7K场景 | 组合性评估 | 文本提示→图像 | ICCV2023 |
| HRS-Bench [327] | 960提示词 | 多技能评估 | 文本提示→图像 | ICCV2023 |
| TIFA [328] | 4081提示词 | 基于问答的评估 | 文本提示→图像 | ICCV2023 |
| GenEval [329] | 1000提示词 | 面向对象的评估 | 文本提示→图像 | NeurIPS2023 |
| T2I-CompBench [330] | 6000条提示 | 组合性评估 | 文本提示→图像 | NeurIPS2023 |
| HEIM [331] | ~1620提示词 | 综合评估 | 文本提示→图像 | NeurIPS2023 |
| Commonsense-T2I [332] | 500提示 | 常识驱动评估 | 文本提示→图像 | COLM2024 |
| DSG-Ik [333] | 1060提示 | 组合性评估 | 文本提示→图像 | ICLR2024 |
| GenAI-Bench [334] | 1600提示 | 组合性评估 | 文本提示→图像 | CVPR2024 |
| ConceptMix [335] | 2100条提示 | 组合性评估 | 文本提示→图像 | NeurIPS2024 |
| DPG-Bench [336] | 1065条提示 | 属性评估 | 文本提示→图像 | arXiv2024 |
| T2I-CompBench++ [337] | 6000+提示词 | 组合性评估 | 文本提示→图像 | TPAMI2025 |
| MMIG-Bench [338] | 4850提示 | 综合评估 | 文本提示→图像 | Arxiv2025 |
| OneIG-Bench [339] | ~2k提示 | 综合评估 | 文本提示→图像 | Arxiv2025 |
| WISE [340] | 1k提示 | 世界知识评估 | 文本提示→图像 | Arxiv2025 |
| CVTG-2K [341] | 2k提示 | 多区域视觉文本评估 | 文本提示→图像 | Arxiv2025 |
| WorldGenBench [342] | 1072提示 | 世界知识评估 | 文本提示→图像 | Arxiv2025 |
| EditBench [343] | 240次编辑 | 掩码引导编辑 | 图像+插入+[掩码]→图像 | CVPR2023 |
| Magicbrush [344] | 1053次编辑 | 真实图像编辑 | 图像+指令→图像 | NeurIPS2023 |
| EditVal [344] | 648编辑 | 面向属性的评估 | 图像+指令→图像 | Arxiv2023 |
| Emu-Edit [345] | 3055编辑 | 多任务编辑 | 图像+指令→图像 | CVPR2024 |
| Reason-Edit [346] | 219编辑 | 复杂指令编辑 | 图像+指令→图像 | CVPR2024 |
| I2EBench [347] | 2240次编辑 | 多维评估 | 图像+指令→图像 | NeurIPS2024 |
| HumanEdit [348] | 5.7K次编辑 | 人工奖励编辑 | 图像+插入+[掩码]→图像 | arXiv2024 |
| HQ-Edit [271] | ~200K编辑 | 高分辨率编辑 | 图像+指令→图像 | ICLR2025 |
| AnyEdit [276] | 1250编辑 | 综合评估 | 图像+指令→图像 | CVPR2025 |
| IE-Bench [349] | 301编辑 | 人类对齐感知评估 | 图像+指令→图像 | Arxiv2025 |
| GEdit-Bench [350] | 606次编辑 | 基于真实场景的编辑 | 图像+指令→图像 | Arxiv2025 |
| CompBench [351] | 3000次编辑 | 复杂指令编辑 | 图像+指令→图像 | Arxiv2025 |
| GIE-Bench [352] | 1080次编辑 | 保持内容评估 | 图像+指令→图像 | Arxiv2025 |
| EditInspector [353] | 783次编辑 | 综合评估 | 图像+指令→图像 | Arxiv2025 |
| ComplexBench-Edit [354] | <1K编辑列表 | 链依赖编辑评估 | 图像+指令→图像 | Arxiv2025 |
| ByteMorph-Bench [279] | 613编辑 | 非刚性编辑评估 | 图像+指令→图像 | Arxiv2025 |
| RefEdit-Bench [277] | 200编辑 | 表达驱动编辑评估 | 图像+指令→图像 | Arxiv2025 |
| ImgEdit-Bench [278] | 200编辑 | 表达驱动编辑评估 | 图像+指令→图像 | Arxiv2025 |
| KRIS-Bench [355] | 1267次编辑 | Cognitive Reasoning评估 | 图像+指令→图像 | Arxiv2025 |
| 交错/组合生成 | ||||
| InterleavedBench [356] | 815个样本 | 人工策划的交错 | 文本+图像→文本+图像 | EMNLP2024 |
| OpenLEAF [357] | 30查询 | 开放域交错 | 查询→文本+图像 | MM2024 |
| ISG [358] | 1150样本数 | 场景驱动交错 | 图形+文本→文本+图像 | ICLR2025 |
| MMIE [359] | 2万查询 | 知识密集型交换 | 历史+查询→响应 | ICLR2025 |
| OpenING [360] | 5.4K样本 | 开放域交错 | 查询→文本+图像 | CVPR2025 |
| UniBench [361] | 81个细粒度标签 | 统一组合评估 | 提示→图像+答案 | Arxiv2025 |
| 其他类型 | ||||
| MultiGen-20M [287] | 多样化 | 可控生成 | 特征+指令→图像 | NeurIPS2023 |
| Dreambench [362] | 30个对象 | 主体驱动生成 | 参考图像+指令→图像 | CVPR2023 |
| Dreambench++ [363] | 150张图像 | 个性化生成 | RefImg. + Instruction → 图像 | ICLR2025 |
| VTBench [364] | 多样性 | 视觉标记器评估 | 图像→重建图像 | Arxiv2025 |
Statistical summary of current evaluations and benchmarks for unified large-scale generative models. This table categorizes benchmarks into Understanding, Image Generation, and Interleaved Generation, detailing the size, description, input/output types, and publication venues for each.
TABLE 4
| Benchmark | Size | Description | In/out Type | Venue |
| Understanding | ||||
| VQA [302] | 10M QAs | Open-domain Visual QA | Image + Question → Answer | ICCV2015 |
| VQAv2 [303] | 1M QAs | Open-domain Visual QA | Image + Question → Answer | CVPR2017 |
| CLEVR [304] | 853K QAs | Compositional Visual QA | Image + Question → Answer | CVPR2017 |
| GQA [305] | 22M QAs | Compositional Visual QA | Image + Question → Answer | CVPR2019 |
| OK-VQA [306] | 14K QAs | Knowledge-based VQA | Image + Question → Answer | CVPR2019 |
| VCR [307] | 290K QAs | Commonsense Visual QA | Img. + Q. → Answer → Rationale | CVPR2019 |
| VisDial [308] | 1.2M Dialogs | Multi-turn Visual Dialog | Image + Dialog → Answer | CVPR2019 |
| ChartQA [309] | 32.7K QAs | Data Visualization QA | Image + Question → Answer | ACL2020 |
| TextVQA [310] | 45K QAs | Scene Text Visual QA | Image + Question → Answer | CVPR2020 |
| A-OKVQA [311] | 25K QAs | Expanded Commonsense VQA | Image + Question → Answer | ECCV2022 |
| HaluEval [312] | 35K Samples | Hallucination Detection | Model output → Yes / No | EMNLP2023 |
| VSR [8] | 3K QAs | Spatial Reasoning | Image + Question → True / False | TACL2023 |
| LAMM [313] | 62K QAs | Instruction Benchmarking | Features + Instruction → Output | NeurIPS2023 |
| LLaVa-Bench [314] | 150 QAs | Instruction Benchmarking | Image + Question → Answer | NeurIPS2023 |
| OwlEval [315] | 82 Qs | Visual-related Eval | Image + Instruction → Answer | Arxiv2023 |
| MMBench [316] | 3K QAs | Fine-grained Multi-modal Eval | Image + Question → Answer | ECCV2024 |
| MMMU [317] | 11.5K QAs | Expert-level Understanding | Image + Question → Answer | CVPR2024 |
| MM-Vet [318] | 218 Samples | VL Capability Eval | Image + Question → Answer | ICML2024 |
| MM-Vet v2 [319] | 218+ Samples | Vision Indispensable Eval | Image + Sequences → Answer | Arxiv2024 |
| MMStar [320] | 1.5K QAs | Comprehensive Evaluation | Image + Question → Answer | NeurIPS2024 |
| SEED-Bench [321] | 19K QAs | VQA Evaluation | Image/Video + MCQ → Answer | CVPR2024 |
| Open-VQA [322] | Varied | Math Reasoning | Image + Q/A → QA Chain | ICLR2024 |
| MathVista [323] | 6K QAs | Ultra Large-scale Eval | Image + Text → Math Output | ICLR2024 |
| General-Bench [324] | >700 tasks | Varied by Task | Arxiv2025 | |
| Image Generation | ||||
| DrawBench [72] | 200 Prompts | Comprehensive Eval | Text Prompt → Image | NeurIPS2022 |
| PartiPrompts [325] | 1600 Prompts | Comprehensive Eval | Text Prompt → Image | TMLR2022 |
| PaintSkills [326] | ~7K Scenes | Compositional Eval | Text Prompt → Image | ICCV2023 |
| HRS-Bench [327] | 960 Prompts | Multi-skill Eval | Text Prompt → Image | ICCV2023 |
| TIFA [328] | 4081 Prompts | QA-based Eval | Text Prompt → Image | ICCV2023 |
| GenEval [329] | 1000 Prompts | Object-focused Eval | Text Prompt → Image | NeurIPS2023 |
| T2I-CompBench [330] | 6000 Prompts | Compositional Eval | Text Prompt → Image | NeurIPS2023 |
| HEIM [331] | ~1620 Prompts | Comprehensive Eval | Text Prompt → Image | NeurIPS2023 |
| Commonsense-T2I [332] | 500 Prompts | Commonsense-driven Eval | Text Prompt → Image | COLM2024 |
| DSG-1k [333] | 1600 Prompts | Compositional Eval | Text Prompt → Image | ICLR2024 |
| GenAI-Bench [334] | 1600 Prompts | Compositional Eval | Text Prompt → Image | CVPR2024 |
| ConceptMix [335] | 2100 Prompts | Compositional Eval | Text Prompt → Image | NeurIPS2024 |
| DPG-Bench [336] | 1065 prompts | Attribute Eval | Text Prompt → Image | Arxiv2024 |
| T2I-CompBench++ [337] | 6000+ Prompts | Comprehensive Eval | Text Prompt → Image | TPAMI2025 |
| MMIG-Bench [338] | 4850 Prompts | Comprehensive Eval | Text Prompt → Image | Arxiv2025 |
| OneIG-Bench [339] | ~2k Prompts | Comprehensive Eval | Text Prompt → Image | Arxiv2025 |
| WISE [340] | 1k Prompts | World Knowledge Eval | Text Prompt → Image | Arxiv2025 |
| CVTG-2K [341] | 2k Prompts | Multi-region Visual Text Eval | Text Prompt → Image | Arxiv2025 |
| WorldGenBench [342] | 1072 Prompts | World Knowledge Eval | Text Prompt → Image | Arxiv2025 |
| EditBench [343] | 240 Edits | Mask-guided Editing | Img. + Ins. + [Mask] → Image | CVPR2023 |
| MagicBrush [269] | 1053 Edits | Real-image Editing | Image + Instruction → Image | NeurIPS2023 |
| EditVal [344] | 648 Edits | Attribute-focused Eval | Image + Instruction → Image | Arxiv2023 |
| Emu-Edit [345] | 3055 Edits | Multi-task Editing | Image + Instruction → Image | CVPR2024 |
| Reason-Edit [346] | 219 Edits | Complex Instruction Editing | Image + Instruction → Image | CVPR2024 |
| I2EBench [347] | 2240 Edits | Multi-dimensional Eval | Image + Instruction → Image | NeurIPS2024 |
| HumanEdit [348] | 5.7K Edits | Human-rewarded Editing | Img. + Ins. + [Mask] → Image | Arxiv2024 |
| HQ-Edit [271] | ~200K Edits | High-resolution Editing | Image + Instruction → Image | ICLR2025 |
| AnyEdit [276] | 1250 Edits | Comprehensive Eval | Image + Instruction → Image | CVPR2025 |
| IE-Bench [349] | 301 Edits | Human-aligned Perceptual Eval | Image + Instruction → Image | Arxiv2025 |
| GEdit-Bench [350] | 606 Edits | Real-world-grounded Editing | Image + Instruction → Image | Arxiv2025 |
| CompBench [351] | 3K Edits | Complex Instruction Editing | Image + Instruction → Image | Arxiv2025 |
| GIE-Bench [352] | 1080 Edits | Content-preserving Eval | Image + Instruction → Image | Arxiv2025 |
| EditInspector [353] | 783 Edits | Comprehensive Eval | Image + Instruction → Image | Arxiv2025 |
| ComplexBench-Edit [354] | <1K List of Edits | Chain-dependent Editing Eval | Image + Instruction → Image | Arxiv2025 |
| ByteMorph-Bench [279] | 613 Edits | Non-rigid Editing Eval | Image + Instruction → Image | Arxiv2025 |
| RefEdit-Bench [277] | 200 Edits | Expression-driven Editing Eval | Image + Instruction → Image | Arxiv2025 |
| ImgEdit-Bench [278] | 200 Edits | Expression-driven Editing Eval | Image + Instruction → Image | Arxiv2025 |
| KRIS-Bench [355] | 1267 Edits | Cognitive Reasoning Eval | Image + Instruction → Image | Arxiv2025 |
| Interleaved / Compositional Generation | ||||
| InterleavedBench [356] | 815 Samples | Human-curated Interleaving | Text + Images → Text + Images | EMNLP2024 |
| OpenLEAF [357] | 30 Queries | Open-domain Interleaving | Query → Text + Images | MM2024 |
| ISG [358] | 1150 Samples | Scene-driven Interleaving | Graph + Text → Text + Images | ICLR2025 |
| MMIE [359] | 20K Queries | Knowledge-intensive Interleaving | History + Query → Response | ICLR2025 |
| OpenING [360] | 5.4K Samples | Open-domain Interleaving | Query → Text + Images | CVPR2025 |
| UniBench [361] | 81 fine-grained tags | Unified Compositional Eval | Prompt → Images + Answer | Arxiv2025 |
| Other Types | ||||
| MultiGen-20M [287] | Varied | Controllable Generation | Features + Instruction → Image | NeurIPS2023 |
| Dreambench [362] | 30 objects | Subject-Driven Generation | Ref Img. + Instruction → Image | CVPR2023 |
| Dreambench++ [363] | 150 imgs | Personalized Generation | Ref Img. + Instruction → Image | ICLR2025 |
| VTBench [364] | Varied | Visual Tokenizer Eval | Image → Reconstructed Image | Arxiv2025 |
并最终在12个维度上提供19K多项选择题项。
LLaVa-Bench [314] 提供带有用于泛化检测的密集查询的 COCO [293] 和真实场景图像集。LAMM [313] 提供涵盖 2D 和 3D 模态的指令微调示例以支持代理开发。
Open-VQA [322] 构建分层的后续问题以细化粗略的VQA答案。OwlEval [315]提供人工评分的开放式视觉问题以评估相关性和信息量。MMStar [320] 精心策划了跨越六项核心技能和18个轴的平衡挑战样本,以实现高精度评估。
推理。在感知层面评估的基础上,推理基准测试探查逐步更丰富的认知能力。CLEVR [304] 系统性地变换物体属性和空间关系,迫使模型执行测试计数、比较和关系逻辑的多跳程序。转向自然图像时,GQA [305] 利用密集场景图生成可组合的问题,其函数式程序用于测试一致性、定位和可行性。
常识扩展例如 OK-VQA [306] 及其更大规模的后续数据集 A-OKVQA [311] 会挑选出答案不在图像内的问题,要求在世界知识库上进行检索或推理。VCR [307] 更进一步,不仅要求模型选择正确答案,还要求通过选择一致的推理依据来证明答案,从而把识别与解释结合起来,考验多步骤的常识链。
领域特定的推理数据集将这一发展推进到日常场景之外。ChartQA [309] 提出将视觉感知与对条形图、折线图和饼图的定量推理交织在一起的问题,融合了数据提取、逻辑比较和算术计算。MathVista [323] 将范围扩展到在具有视觉支撑的语境中解决数学问题,把精细颗粒度的视觉理解与符号操作结合在各种示例中。这些基准测试形成了一个分层的频谱,涵盖结构化逻辑推理、开放域常识、视觉解释和数值密集型任务,为多模态推理系统提供了全面的压力测试。
此外,General-Bench [324]是一个超大规模基准测试,涵盖超过700个任务和325,800个实例,跨越多样模态与能力,为多模态通用模型提供了协同驱动的评估套件。
5.2图像生成评估
Text-to-Image Generation。早期的自动化指标如FID[367]和CLIPScore[22]为评估图像质量奠定了基础。近期的基准测试则更强调组合推理、提示词对齐和现实适用性。
PaintSkills [326], DrawBench [72], 和
PartiPrompts [325] 评估核心的构图能力。GenEval
[329] 评估六项细粒度任务,包括单对象生成、对象共现、计数、颜色控制、相对定位和属性绑定,通过将预训练检测器的输出与真实标注进行比较来完成评估。
Expanding on this, GenAI-Bench [334] 提供了1.6K精心设计的人工提示词,涵盖了关系性、
逻辑性和基于属性的类别。其评估框架将人工偏好判断与自动对齐分数相结合,以提供全面的评估。此外,
HRS-Bench [327] 评估了13项不同的技能,这些技能被分为五大类:准确性、鲁棒性、泛化、公平性和偏差,从而确保了可扩展且可靠的性能测量。此外,DPG-Bench [336]侧重于描述多个对象的密集提示,每个对象由多种属性和关系来表征。
T2I-CompBench [330] 及其后续版本
T2I-CompBench++ [337] 专门针对可组合性泛化,使用基于检测器的评分测试生成新颖属性和关系组合的能力。
VISOR [368] 提出了一种用于评估生成模型空间理解能力的自动方法。与此互补,Commonsense-T2I [332] 挑战模型描绘那些需要常识定位的日常概念。
为支持大规模概念多样性,EvalMuse-40K [369] 提供了40K众包提示,侧重于细腻的概念表征;HEIM [331] 确定了12个方面,包括文本-图像对齐、图像质量、美学、原创性、推理、知识、偏差、有害性、公平性、鲁棒性、多语言性和效率。考虑到实际需求,FlashEval [370] 通过迭代搜索将大规模评估集缩减为多个多样化的小集以加速基准测试。MEMO-Bench [371] 引入了一个用于评估T2I模型和MLLMs情感理解与表达能力的综合基准。
ConceptMix [335] 通过抽样 k 元视觉概念构建提示,评估文本到图像模型的可组合生成能力,并使用强大的视觉语言模型自动验证生成图像中概念的存在。TIFA [328] 提供了一个通过从提示生成的视觉问答来评估文本到图像忠实度的细粒度基准。
为在基于VQA的图像-提示对齐评估中丰富问题生成的依赖关系,DSG-1k [333]使用多层语义图对其问题进行了优化。MMIG-Bench [338]提出了一个多维评估框架,严格审视文本到图像生成模型。OneIG-Bench [339]引入了一个跨更多维度的文本到图像模型的综合细粒度评估框架。
[340], [342] 评估文本到图像模型的世界知识理解,强调语义一致性、真实感和美学。CVTG-2K [341] 在复杂的多区域布局、多样的文本属性和细粒度定位上评估视觉-文本生成。
图像编辑。用于指令引导图像编辑的基准测试在规模和范围上不断扩大。MagicBrush [269]是一个大规模、人工标注的指令引导真实图像编辑数据集,涵盖多种场景:单轮、多轮、提供掩码和无掩码的编辑。HQ-Edit [271] 包含大约20万条高分辨率编辑,并带有计算得到的对齐和一致性分数,可使用GPT-4V对图像编辑对的质量进行量化评估。
and finally offers 19K multi-choice items over 12 dimensions. LLaVa-Bench [314] provides COCO [293] and inthe-wild image sets with dense queries for generalization checks. LAMM [313] supplies instruction-tuning examples covering 2D and 3D modalities for agent development. Open-VQA [322] formulates hierarchical follow-up questions to refine coarse VQA answers. OwlEval [315] offers human-rated open-ended visual questions assessing relevance and informativeness. MMStar [320] curates carefully balanced challenge samples spanning six core skills and 18 axes for high-precision evaluation.
Reasoning. Building on perception-level evaluation, reasoning benchmarks probe progressively richer cognitive skills. CLEVR [304] systematically varies object attributes and spatial relations, forcing models to execute multi-hop programs that test counting, comparison and relational logic. Moving to natural images, GQA [305] leverages dense scene graphs to generate compositional questions whose functional programs are used to test consistency, grounding and plausibility.
Commonsense extensions such as OK-VQA [306] and its larger successor A-OKVQA [311] select questions whose answers lie outside the image, requiring retrieval or inference over world knowledge bases. VCR [307] further demands that a model not only choose the correct answer but also justify it by selecting a coherent rationale, thereby coupling recognition with explanation and testing multi-step commonsense chains.
Domain-specific reasoning datasets extend this progression beyond everyday scenes. ChartQA [309] introduces questions that intertwine visual perception with quantitative reasoning over bar, line and pie charts, integrating data extraction, logical comparison and arithmetic calculation. MathVista [323] broadens the scope to mathematical problem solving in visually grounded contexts and combines fine-grained visual understanding with symbolic manipulation across diversified examples. These benchmarks form a layered spectrum that spans structured logical inference, open-domain commonsense, visual explanation and numerically intensive tasks, offering a comprehensive stress-test for multimodal reasoning systems.
Moreover, General-Bench [324], an ultra-large benchmark comprising over 700 tasks and 325,800 instances across varied modalities and capabilities, provides a synergy-driven evaluation suite for multimodal generalist models.
5.2 Evaluation on Image Generation
Text-to-Image Generation. Early automated metrics such as FID [367] and CLIPScore [22] established the foundation for evaluating image quality. More recent benchmarks, however, emphasize compositional reasoning, prompt alignment, and real-world applicability. PaintSkills [326], Draw-Bench [72], and PartiPrompts [325] evaluate core compositional capabilities. GenEval [329] evaluates six fine-grained tasks, including single-object generation, object co-occurrence, counting, color control, relative positioning, and attribute binding by comparing outputs from pretrained detectors against ground-truth annotations.
Expanding on this, GenAI-Bench [334] presents 1.6K meticulously crafted human prompts that cover relational,
logical, and attribute-based categories. Its evaluation framework combines human preference judgments with automated alignment scores to provide a comprehensive assessment. In addition, HRS-Bench [327] evaluates 13 distinct skills that are grouped into five major categories: accuracy, robustness, generalization, fairness, and bias, thereby ensuring scalable and reliable performance measurement. Moreover, DPG-Bench [336] focuses on dense prompts that describe multiple objects, with each object characterized by a variety of attributes and relationships.
The T2I-CompBench [330] and its successor T2I-CompBench++ [337] specifically target compositional generalization, testing the generation of novel attribute and relation combinations using detector-based scoring. VISOR [368] proposes an automatic method for evaluating the spatial understanding capabilities of generative models. Complementing these, Commonsense-T2I [332] challenges models to depict everyday concepts that require commonsense grounding.
To support large-scale concept diversity, EvalMuse40K [369] provides 40K crowdsourced prompts focusing on nuanced concept representation, and HEIM [331] identifies 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality and efficiency. Considering practical needs, FlashEval [370] shrinks the large-scale evaluation set into diverse smaller ones through iterative search to accelerate the benchmark testing. MEMO-Bench [371] introduces a comprehensive benchmark for evaluating the emotional understanding and expression capabilities of T2I models and MLLMs. ConceptMix [335] evaluates text-to-image models’ compositional generation ability by sampling k-tuples of visual concepts to construct prompts and automatically verifying concept presence in the resulting images using a strong visual language model. TIFA [328] offers a fine-grained benchmark for evaluating text-to-image faithfulness via visual question answering generated from prompts.
To enrich dependencies in question generation for VQA-based evaluation of image-prompt alignment, DSG-1k [333] refines its questions using a multi-level semantic graph. MMIG-Bench [338] introduced a multi-dimensional assessment framework that rigorously examines text-to-image generation models. OneIG-Bench [339] introduces a comprehensive fine-grained evaluation framework for text-to-image models across more dimensions. [340], [342] evaluate text-to-image models’ world knowledge understanding, which emphasizes semantic consistency, realism, and aesthetics. CVTG-2K [341] evaluates visual-text generation on complex multi-region layouts, diverse text attributes, and fine-grained positioning.
Image Editing. Benchmarks for instruction-guided image editing have grown in scale and scope. MagicBrush [269] is a large-scale, manually annotated dataset for instruction-guided real image editing that covers diverse scenarios: single-turn, multi-turn, mask-provided, and mask-free editing. HQ-Edit [271] contains approximately 200K high-resolution edits with computed alignment and coherence scores, allowing quantitatively assessing the quality of image edit pairs using GPT-4V.
Building on this, I2EBench [347] consolidates over 2K
图像和4K步骤化指令,涵盖16个编辑维度。EditVal [344] 提供了一个标准化基准,具有细粒度编辑注释和与人工判断一致的自动化评估流程。Emu-Edit [345] 涵盖七项编辑任务,包括背景更改、对象级编辑和风格修改,并提供成对的指令与输入/输出描述。Reason-Edit [346]是一个诊断基准,针对因果和反事实推理,强调对象关系、属性依赖和多步推理。
提供跨多样化对象、属性和场景的掩码输入-参考对,EditBench [343]为基于文本的图像修复提供了一个诊断性基准,能够对编辑质量进行精确评估。HumanEdit [348]包含5,751张高分辨率图像和涵盖六种编辑类型的开放式指令,并配有注释掩码和多阶段人工反馈。IE-Bench [349]提供了一个与人类对齐的基准,用于评估文本驱动的图像编辑质量,包含多样化的编辑和感知得分。
更近期的基准包括 GEdit-Bench [350], 该基准包含 606 条真实世界的指令-图像对; CompBench [351] 通过大规模 MLLM 与人工协作, 将编辑分解为位置、外观、动态和对象尺寸; GIE-Bench [352] 在 1,000 多个示例上使用多项选择 VQA 和面向对象的掩码来评估编辑准确性和内容保留。沿着这一趋势, 诸如 [276], [278], [353], [354] 等基准也开展了对基于文本的图像编辑的综合评估, 评估视觉一致性、伪影检测、指令遵从性、视觉质量和细节保留。
其他基准测试还包括 ByteMorph-Bench [279], 其应对非刚性图像操作; RefEdit-Bench [277], 用于评估在复杂多实体场景中基于指称表达的编辑; 以及 KRIS-Bench [355], 它提供了一个认知基础套件, 用于评估事实性、概念性和过程性推理。
Other Types of Image Generation。除文本到图像生成和编辑外,其他基准还针对条件化和个性化合成。
MultiGen-20M [287] 提供来自 LAION-Aesthetics-V 2 [372], 的两千多万条图像-提示-条件三元组, 支持跨多样视觉条件的自动化评估。DreamBench [362] 使用 30 个参考对象、策划的提示词和人工保真度评分对个性化生成进行基准测试。DreamBench++ [363] 将其扩展到 150 个主体和 1,350 条提示, 使用先进的视觉-语言模型进行与人类一致的概念保留、构图和风格评分。总体而言, 这些数据集涵盖了针对条件生成的大规模自动化评估和精细的人类中心评估。
VTBench [364]为自回归图像生成中的视觉分词器评估提供了系统性的基准测试,涵盖图像重建、细节保留和文本保留等方面。
5.3针对交错生成的评估
交错评估基准挑战模型在多个回合中在文本与图像模态之间无缝切换,反映现实对话和讲故事场景的需求——
InterleavedBench [356] 是一个具有代表性的基准,经过精心策划用于评估交错文本与图像生成,包含丰富的任务以覆盖多样的真实用例,并在文本质量、感知保真度、多模态一致性和有用性等方面评估模型。基于此,ISG [358]引入了场景图注释,并在八种场景和21个子任务上的1K样本上实施了四层评估(整体、结构、块级和图像特定),以实现对交错文本—图像输出的细粒度评估。
其他基准测试强调开放域指令和端到端交错。
OpenING [360]汇集了5K人工标注实例,覆盖56个真实世界任务(例如:旅行指南、设计构思),并使用IntJudge来测试开放式多模态生成方法在任意指令驱动的交错生成上的表现。相比之下,OpenLEAF [357]收集了30条开放域查询,每条由标注者撰写并审核,用以探测基础的交错文本-图像生成,通过LMM评估器加上人工验证来测量实体与风格一致性。最后,MMIE [359]通过从12个领域和102个子领域抽样,提出了一个统一的交错测试套件,提供选择题与开放式问题格式的混合,以多样化方式评估模型。最近的工作UniBench [361]被引入作为评估统一模型的综合可组合性基准,提供81个细粒度标签以确保高度多样性。
6挑战与机遇:关于统一模型
目前,处于初级阶段的统一多模态模型面临若干需要解决的重大挑战,以实现稳健且可扩展的理解与生成能力。首先,视觉与文本数据的高维性导致极其长的代币序列。高效的分词与压缩策略对于在保持表示保真度的同时降低内存与计算成本至关重要。第二,随着图像分辨率和上下文长度的增加,跨模态注意力成为性能瓶颈。稀疏或层次化注意力机制等可扩展替代方案可能缓解该问题。第三,预训练数据集通常包含嘈杂或有偏的图文对,尤其是针对复杂图像合成和交错图文数据。可靠的数据过滤、去偏见和合成对于确保公平性与鲁棒性非常重要。第四,评估协议通常为孤立的单一任务而设计。亟需更全面的基准测试,以集成方式评估理解与生成,特别是诸如图像编辑和交错图文生成等复杂任务。除了架构、数据与评估方面的问题与挑战外,将思维链(CoT)推理和强化学习(RL)技术应用于统一的MLLM模型,以提升可解释性和性能[373],也是值得探索的方向。CoT可引导模型生成中间推理步骤,这对复杂的视觉问答或基于图像的生成尤为有益。同时,RL可以用于
images and 4K multi-step instructions across 16 editing dimensions. EditVal [344] offers a standardized benchmark with fine-grained edit annotations and an automated evaluation pipeline aligned with human judgment. EmuEdit [345] covers seven editing tasks including background changes, object-level edits, and style modifications, with paired instructions and I/O descriptions. Reason-Edit [346] is a diagnostic benchmark targeting causal and counterfactual reasoning, emphasizing object relations, attribute dependencies, and multi-step inference.
Offering masked input-reference pairs across varied objects, attributes, and scenes, EditBench [343] delivers a diagnostic benchmark for text-guided image inpainting that enables precise evaluation of editing quality. HumanEdit [348] includes 5,751 high-resolution images and open-form instructions spanning six edit types, with annotated masks and multi-stage human feedback. IE-Bench [349] provides a human-aligned benchmark for evaluating text-driven image editing quality with diverse edits and perceptual scores.
More recent benchmarks include GEdit-Bench [350] which features 606 real-world instruction-image pairs, CompBench [351] that decomposes edits into location, appearance, dynamics and object dimensions via large-scale MLLM-and-human collaboration, and GIE-Bench [352] which uses multiple-choice VQA and object-aware masking on over 1,000 examples to evaluate editing accuracy and content preservation. Following this trend, benchmarks like [276], [278], [353], [354] also undertake comprehensive evaluation of text-guided image editing, assessing vision consistency, artifact detection, instruction adherence, visual quality, and detail preservation.
Other benchmarks include ByteMorph-Bench [279] which tackles non-rigid image manipulation, RefEdit-Bench [277] which evaluates referring-expression-based edits in complex multi-entity scenes, and KRIS-Bench [355] which offers a cognitively grounded suite assessing factual, conceptual and procedural reasoning.
Other Types of Image Generation. Beyond text-to-image generation and editing, additional benchmarks target conditional and personalized synthesis. MultiGen-20M [287] provides over 20 million image-prompt-condition triplets from LAION-Aesthetics-V2 [372], supporting automated evaluation across diverse visual conditions. DreamBench [362] benchmarks personalized generation using 30 reference objects with curated prompts and human fidelity ratings. DreamBench++ [363] scales this to 150 subjects and 1,350 prompts, using advanced vision-language models for human-aligned scoring of concept preservation, composition, and style. Together, these datasets span large-scale automated and fine-grained human-centric evaluation of conditional generation.
VTBench [364] provides a systematic benchmark for evaluating visual tokenizers in autoregressive image generation across image reconstruction, detail preservation, and text preservation.
5.3 Evaluation on Interleaved Generation
Interleaved evaluation benchmarks challenge models to seamlessly alternate between text and image modalities across multiple turns, reflecting realistic dialogue and sto
rytelling scenarios. InterleavedBench [356] is a representative benchmark carefully curated for the evaluation of interleaved text and image generation, featuring a rich array of tasks to cover diverse real-world use cases and evaluating models on text quality, perceptual fidelity, multimodal coherence and helpfulness. Building on this, ISG [358] introduces scene-graph annotations and a four-tier evaluation (holistic, structural, block-level and image-specific) over 1K samples in eight scenarios and 21 subtasks, enabling fine-grained assessment of interleaved text-image outputs.
Other benchmarks emphasize open-domain instruction and end-to-end interleaving. OpenING [360] resembles 5K human-annotated instances across 56 real-world tasks (e.g. travel guides, design ideation) with IntJudge to test open-ended multimodal generation methods on arbitrary instruction-driven interleaved generation. In contrast, OpenLEAF [357] gathers 30 open-domain queries with each written and reviewed by annotators to probe foundational interleaved text-image generation, measuring entity and style consistency via LMM evaluators plus human validation. Finally, MMIE [359] proposes a unified interleaved suite by sampling from 12 fields and 102 subfields, offering a mix of multiple-choice and open-ended question formats to evaluate models in a diverse manner. In a more recent work, UniBench [361] was introduced as a comprehensive compositional benchmark for evaluating unified models, offering 81 fine-grained tags to ensure high diversity.
6 CHALLENGES AND OPPORTUNITIES ON UNIFIED MODELS
Currently, at its rudimentary stage, unified multimodal models face several significant challenges that should be addressed to achieve robust and scalable understanding and generation capabilities. First, the high dimensionality of visual and textual data leads to extremely long token sequences. Efficient tokenization and compression strategies are essential to reduce memory and computation costs while preserving representational fidelity. Second, cross-modal attention becomes a performance bottleneck as image resolution and context length increase. Scalable alternatives such as sparse or hierarchical attention mechanisms may potentially mitigate this issue. Third, pretraining datasets often include noisy or biased image-text pairs, particularly for complex image compositions and interleaved image-text data. Reliable data filtering, debiasing, and synthesizing are crucial to ensure fairness and robustness. Fourth, evaluation protocols are typically designed for single tasks in isolation. There is a growing need for comprehensive benchmarks that assess both understanding and generation in an integrated manner, especially for sophisticated tasks such as image editing and interleaved image-text generation. Apart from the issues and challenges on architecture, data, and evaluation, applying chain-of-thought (CoT) reasoning and reinforcement learning (RL) techniques into unified MLLM models to improve both interpretability and performance [373] is also worth exploring. CoT can guide the model to generate intermediate reasoning steps, which are particularly beneficial for complex visual-question answering or image-conditioned generation. Meanwhile, RL can be used
优化如事实一致性、用户满意度或超出代币级似然的长期目标。此外,探索现有统一MLLM模型的群体与社会偏见[374]是确保负责任部署的重要课题。随着这些模型在多样模态与任务上能力日益增强,预训练数据中潜在的文化刻板印象、性别偏见或地域不平衡可能被无意放大,导致有害输出。未来工作应研究有效的公平感知训练流程。最后,在统一MLLMs中实现个性化知识驱动的生成[375]是一个新兴且重要的方向。个性化模型旨在将用户提供的概念——例如特定对象、角色或风格——纳入模型的理解与生成能力。然而,目前的方法常常将理解与生成分开对待,为每项任务使用不同的概念嵌入。这种分离限制了模型对需要隐含知识的组合式提示的泛化能力,例如在未显式描述帽子的情况下生成“戴着它的帽子”。在共享的建模框架下统一个性化理解与生成,将有助于更好的语义落地与上下文泛化。
据我们所知,目前大多数统一多模态模型主要侧重于图像理解和文本到图像的生成,而诸如图像编辑等能力通常仅通过后续微调获得。此外,诸如空间可控图像生成、基于主体的图像生成和图文交错生成等高级功能在统一框架内仍然很大程度上未被探索。因此,我们认为通过解决架构设计、训练效率、数据集整理、评估方法、公平性和推理等关键问题,有大量机会推动该领域的发展。
7结论
我们提出了关于将视觉-语言理解与图像生成整合到单一框架中的统一多模态模型的全面观点。首先,我们简要回顾了多模态理解和文本到图像生成模型的基础知识与最新进展。随后,我们通过将统一多模态模型划分为三大范式——基于扩散、基于自回归和混合方法——对其进行了系统性综述。针对每一类,我们介绍了相关工作并进一步细分为不同子类,以帮助读者更好地把握该领域的全貌。此外,我们整理了相关数据集和基准,以便于实际实现和评估。最后,我们讨论了该领域的关键挑战与机遇,强调统一多模态模型的研究仍处于起步阶段。我们希望本综述能成为推进统一多模态模型研究与创新的有价值资源。
to optimize long-horizon objectives such as factual consistency, user satisfaction, or task success rate beyond token-level likelihoods. Moreover, exploring the demographic and social biases of existing unified MLLM models [374] is an important topic to ensure responsible deployment. As these models become increasingly capable across diverse modalities and tasks, unintentional amplification of cultural stereotypes, gender bias, or geographic imbalances embedded in pretraining data may result in harmful outputs. Future work should investigate effective fairness-aware training pipelines. Finally, enabling personalized knowledge-driven generation within unified MLLMs [375] is an emerging and important direction. Personalized models aim to incorporate user-provided concepts—such as specific objects, characters, or styles—into the model’s understanding and generation capabilities. However, current approaches often treat understanding and generation separately, using distinct concept embeddings for each task. This separation limits the model’s ability to generalize to compositional prompts that require implicit knowledge, such as generating “” wearing its hat" without explicitly describing the hat. Unifying personalized understanding and generation under a shared modeling framework would allow better semantic grounding and contextual generalization.
To the best of our knowledge, most of current unified multimodal models primarily emphasize image understanding and text-to-image generation, while capabilities such as image editing are only attained through postfinetuning. Moreover, advanced functionalities like spatially controlled image generation, subject(s)-driven image generation, and interleaved image-text generation remain largely unexplored in the unified framework. Consequently, we believe there are abundant opportunities to advance the field by addressing key areas such as architectural design, training efficiency, dataset curation, evaluation methodologies, fairness, and reasoning to achieve unified multimodal models.
7 CONCLUSION
We have presented a comprehensive view on unified multimodal models that integrate vision-language understanding and image generation within a single framework. Initially, we provide a concise overview of the foundational knowledge and recent advancements in both multimodal understanding and text-to-image generation models. Subsequently, we systematically survey unified multimodal models by categorizing them into three main paradigms: diffusion-based, autoregressive-based, and hybrid-based approaches. For each category, we introduce related works and further subdivide them into distinct subcategories to help readers better grasp the landscape of this field. Additionally, we curate relevant datasets and benchmarks to facilitate practical implementation and evaluation. Finally, we discuss the key challenges and opportunities in this domain, emphasizing that the study of unified multimodal models is still in its infancy. We hope that our survey will serve as a valuable resource to advance research and innovation in the development of unified multimodal models.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献169条内容
已为社区贡献169条内容

所有评论(0)