【AI实战日记-手搓情感聊天机器人】Day 12:彻底丢掉键盘!集成 OpenAI Whisper 实现高精度语音识别 (STT)
Day 11 我们实现了语音合成,今天我们将补全多模态交互的另一半拼图——STT (语音转文本)。我将引入 OpenAI 开源的 Whisper 模型(Base版本),它具备惊人的多语言识别能力和抗噪能力。本文将封装一个 AudioRecorder 模块用于麦克风录音,并构建 STTEngine 引擎,实现“听到声音 -> 转化为文字 -> 触发 RAG 对话”的完整闭环。
Day 11 我们实现了语音合成,今天我们将补全多模态交互的另一半拼图——STT (语音转文本)。我将引入 OpenAI 开源的 Whisper 模型(Base版本),它具备惊人的多语言识别能力和抗噪能力。本文将封装一个 AudioRecorder 模块用于麦克风录音,并构建 STTEngine 引擎,实现“听到声音 -> 转化为文字 -> 触发 RAG 对话”的完整闭环。
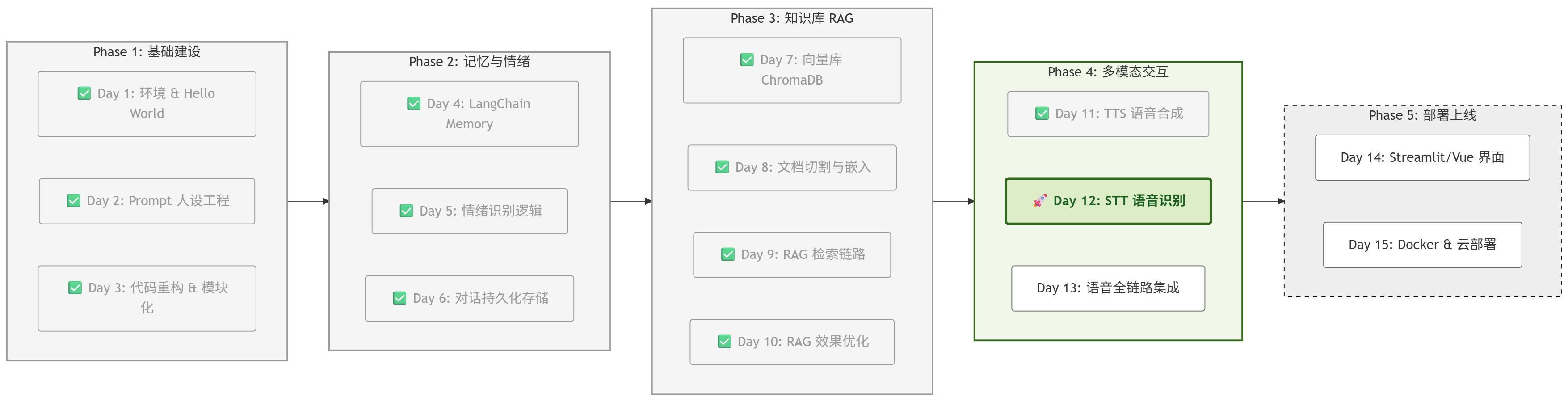
一、 项目进度:Day 12 启动
根据项目路线图,今天是 Phase 4 的攻坚战。
我们要打通“耳朵”到“大脑”的通路。
二、 核心原理:机器是如何“听懂”的?
1. 听觉系统的“三剑客”
为了实现“从麦克风到文字”的完整转换,我们需要三个 Python 库各司其职,它们就像一条精密的流水线:
(1) pyaudio —— 电子耳 (The Ears)
-
作用:它是 Python 与操作系统音频硬件(麦克风)之间的桥梁。
-
原理:它负责打开音频流(Stream),以二进制流的形式实时捕获麦克风采集到的模拟信号。
-
比喻:它就像是**“收音机”**,负责把空气中的声波抓取到电脑内存里。
(2) wave —— 录音带 (The Storage)
-
作用:它是 Python 的标准库,专门用来处理 .wav 格式的音频文件。
-
原理:pyaudio 抓取的是裸数据(Raw Bytes),如果不加处理直接存盘是无法播放的。wave 库负责给这些数据加上文件头(Header)(告诉播放器采样率是多少、声道是多少),将其封装成标准的 WAV 文件。
-
比喻:它就像是**“磁带”**,把收音机听到的声音永久保存下来,供后续读取。
(3) openai-whisper —— 大脑听觉区 (The Brain)
-
作用:这是 OpenAI 开源的通用语音识别模型。
-
原理:它读取 wave 生成的音频文件,将其转化为声谱图 (Spectrogram),然后通过 Transformer 模型进行推理,最终输出文本。它不关心录音过程,只关心音频文件里的内容。
-
比喻:它就像一位**“速记员”**,戴着耳机听录音带,并快速把听到的内容写在纸上。
2. 为什么选 Whisper?
语音识别领域曾长期被大厂 API 垄断(如百度、讯飞)。直到 OpenAI 开源了 Whisper。
-
强悍的抗噪性:哪怕背景有杂音,它也能听得清。
-
多语言支持:中英文混合识别能力极强(比如“我用 Python 写 Bug”)。
-
离线运行:我们可以把模型下载到本地,完全不需要联网,隐私性极佳。
三、 实战:环境准备
1. 安装系统级依赖 (FFmpeg)
Whisper 依赖 ffmpeg 处理音频。
-
Windows: 下载 ffmpeg.exe 并配置环境变量(或使用 winget install ffmpeg)。
-
Mac: brew install ffmpeg
-
Linux: sudo apt install ffmpeg
2. 安装 Python 库
我们需要 openai-whisper (模型) 和 pyaudio (录音)。
pip install openai-whisper pyaudio wave四、 实战:代码实现
1. 编写录音机 (src/core/recorder.py)
我们需要一个能够控制麦克风的类。为了简单起见,我们实现一个**“按回车开始,按回车停止”**的录音机。
import pyaudio
import wave
import threading
from src.utils.logger import logger
class AudioRecorder:
def __init__(self, filename="input_voice.wav"):
self.filename = filename
self.chunk = 1024
self.format = pyaudio.paInt16
self.channels = 1
self.rate = 44100
self.frames = []
self.is_recording = False
self.pyaudio_instance = pyaudio.PyAudio()
def start_recording(self):
"""开始录音 (非阻塞)"""
self.is_recording = True
self.frames = []
self.stream = self.pyaudio_instance.open(
format=self.format,
channels=self.channels,
rate=self.rate,
input=True,
frames_per_buffer=self.chunk
)
# 开启一个线程专门负责从麦克风读数据
self._thread = threading.Thread(target=self._record_loop)
self._thread.start()
logger.info("🎤 录音开始... (请说话)")
def _record_loop(self):
while self.is_recording:
data = self.stream.read(self.chunk)
self.frames.append(data)
def stop_recording(self):
"""停止录音并保存文件"""
self.is_recording = False
self._thread.join() # 等待线程结束
self.stream.stop_stream()
self.stream.close()
# 保存为 wav 文件
wf = wave.open(self.filename, 'wb')
wf.setnchannels(self.channels)
wf.setsampwidth(self.pyaudio_instance.get_sample_size(self.format))
wf.setframerate(self.rate)
wf.writeframes(b''.join(self.frames))
wf.close()
logger.info(f"💾 录音结束,已保存至 {self.filename}")2. 编写 STT 引擎 (src/core/stt.py)
封装 Whisper 模型。第一次运行时会自动下载模型(Base 模型约 140MB)。
import whisper
import os
from src.utils.logger import logger
class STTEngine:
def __init__(self, model_size="base"):
"""
初始化 Whisper 模型
model_size: tiny, base, small, medium, large
推荐使用 base,速度快且中文效果够用
"""
logger.info(f"⏳ 正在加载 Whisper ({model_size}) 模型,首次运行需要下载...")
# 自动利用 GPU,如果没有则使用 CPU
self.model = whisper.load_model(model_size)
logger.info("✅ Whisper 模型加载完毕")
def transcribe(self, audio_path="input_voice.wav"):
"""将音频转为文字"""
if not os.path.exists(audio_path):
logger.warning("未找到音频文件")
return ""
logger.info("🔄 正在识别语音...")
# 核心推理代码
# fp16=False 是为了兼容没有 GPU 的机器
result = self.model.transcribe(audio_path, fp16=False)
text = result["text"].strip()
logger.info(f"🗣️ 识别结果: {text}")
return text3. 集成到主程序 (main.py)
我们需要修改交互逻辑:不再等待 input(),而是等待录音指令。
修改 main.py:
# ==============================================================================
# Project Echo Day 9: Multi-Query RAG Integration
# 集成特性: Redis记忆 + 情绪识别 + Multi-Query知识库检索
# ==============================================================================
# LangChain LCEL 核心组件
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from operator import itemgetter # 【修复】用于从字典中提取字段
# 项目核心模块
from src.core.llm import LLMClient
from src.core.prompts import PROMPTS
from src.utils.logger import logger
from src.config.settings import settings
from src.core.emotion import EmotionEngine # Day 5: 情绪
from src.core.knowledge import KnowledgeBase # Day 7-9: 知识库
from src.core.reranker import RerankEngine # Day 10: 重排序
from src.core.voice import VoiceEngine # 导入语音引擎
from src.core.recorder import AudioRecorder
from src.core.stt import STTEngine
# --- Redis 历史记录工厂 (Day 6) ---
def get_session_history(session_id: str) -> BaseChatMessageHistory:
return RedisChatMessageHistory(
session_id=session_id,
url=settings.REDIS_URL,
ttl=3600 * 24 * 7 # 记忆保留 7 天
)
# --- 辅助函数:格式化文档 ---
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
def main():
logger.info("🚀 --- Project Echo: Day 9 集成版启动 ---")
# ==========================================
# 1. 初始化组件
# ==========================================
# 1.1 大模型 (Brain)
client = LLMClient()
llm = client.get_client()
# 1.2 情绪引擎 (Heart)
emotion_engine = EmotionEngine()
# 1.3 知识库 (Book)
kb = KnowledgeBase()
# 【Day 9 核心】获取多重查询检索器
# 这里我们将 LLM 传进去,让检索器具备"思考"能力
base_retriever = kb.get_multiquery_retriever(llm)
# 【Day 10 新增】重排序引擎:对粗排结果进行精排
reranker = RerankEngine(model_name="BAAI/bge-reranker-base", top_n=3)
# 封装成 LCEL Runnable:先粗排,再精排
def retriever_with_rerank(query: str):
docs = base_retriever.invoke(query)
return reranker.rerank(query, docs)
retriever = RunnableLambda(retriever_with_rerank)
# ==========================================
# 2. 构建 Prompt 模板
# ==========================================
sys_prompt_base = PROMPTS["tsundere"]
prompt = ChatPromptTemplate.from_messages([
("system", sys_prompt_base), # 1. 基础人设 (傲娇)
("system", "{emotion_context}"), # 2. 情绪指令 (动态注入)
("system", "【参考资料(必须基于此回答)】:\n{context}"), # 3. 知识库资料 (RAG)
MessagesPlaceholder(variable_name="history"), # 4. 历史记忆 (Redis)
("human", "{input}") # 5. 用户输入
])
# ==========================================
# 3. 组装 LCEL 流水线
# ==========================================
rag_chain = (
{
# 分支 A: 智能检索 (用户输入 -> 裂变3个问题 -> 并行检索 -> 汇总 -> 格式化)
"context": itemgetter("input") | retriever | format_docs, # 【修复】使用 itemgetter 提取 input
# 分支 B: 透传参数 (直接传递给 Prompt)
"input": itemgetter("input"), # 【修复】提取 input 字段
"emotion_context": itemgetter("emotion_context"), # 【修复】提取 emotion_context 字段
"history": itemgetter("history") # 【修复】提取 history 字段
}
| prompt # 填入模板
| llm # 大模型推理
)
# ==========================================
# 4. 挂载持久化记忆
# ==========================================
final_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
print("\n✨ 系统就绪!试试问得模糊一点,比如“那个写代码的人爱吃啥?”\n")
session_id = "user_day9_demo"
voice_engine = VoiceEngine(voice="zh-CN-XiaoyiNeural")
recorder = AudioRecorder()
stt_engine = STTEngine(model_size="base")
# ==========================================
# 5. 对话循环
# ==========================================
while True:
cmd = input(">>> 按回车开始说话 (输入 'quit' 退出): ")
if cmd.lower() in ["quit", "exit"]:
break
# --- Step 1: 录音 (Recording) ---
recorder.start_recording()
input(" 🔴 正在录音... (说完请按回车停止)")
recorder.stop_recording()
# --- Step 2: 识别 (STT) ---
user_input = stt_engine.transcribe()
if not user_input:
print("⚠️ 没听清,请再说一遍。")
continue
print(f"You (语音): {user_input}")
if user_input.strip():
# --- Phase A: 情绪侦探 ---
current_emotion = emotion_engine.analyze(user_input)
emotion_instruction = "用户情绪平稳。"
if "[愤怒]" in current_emotion:
emotion_instruction = "⚠️ 警告:用户很生气!请示弱道歉。"
elif "[悲伤]" in current_emotion:
emotion_instruction = "⚠️ 提示:用户很难过。请温柔安慰。"
try:
# --- Phase B: 执行 RAG 主链 ---
# 这一步会自动触发 Multi-Query 检索
logger.info("🔍 正在进行多重检索与思考...")
response = final_chain.invoke(
{
"input": user_input,
"emotion_context": emotion_instruction
},
config={"configurable": {"session_id": session_id}}
)
ai_text = response.content
print(f"Bot ({current_emotion}): {ai_text}\n")
voice_engine.speak(ai_text, emotion=current_emotion)
except Exception as e:
logger.error(f"❌ 调用失败: {e}")
if __name__ == "__main__":
main()五、 运行与体验
-
启动:python main.py
-
注意:第一次启动会下载 Whisper 模型,可能需要几分钟。
-
-
交互:
-
终端提示:>>> 按回车开始说话
-
你 (按下回车)
-
你 (对着麦克风说):“你好傲娇酱,你知不知道阿强最喜欢吃什么?”
-
你 (按下回车)
-
终端显示:🔴 正在录音... -> 💾 录音结束 -> 🔄 正在识别...
-
终端显示:🗣️ 识别结果: 你好傲娇酱,你知不知道阿强最喜欢吃什么?
-
-
反馈:
-
AI 经过思考,不仅输出了文字,还用傲娇的声音(Edge-TTS)回答了你。
-
六、 总结与预告
今天我们彻底打通了 耳朵 (Recorder) -> 大脑听觉区 (Whisper) -> 理解中枢 (LLM) -> 嘴巴 (TTS) 的完整回路。
现在已经可以被称为一个**“全双工语音助手”**的雏形了。你不需要再碰键盘,只需动动嘴就能和它交流。
明日预告 (Day 13):
现在的语音交互还有点傻:必须按回车开始,按回车结束。
明天 Day 13,我们将进行 语音全链路集成优化。虽然我们不做复杂的 VAD(语音活动检测),但我们要优化交互体验,让对话更加流利,并为最终的 Web 界面部署做准备。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)