大模型推理引擎vLLM(1): FlashAttention论文以及原理解析
大模型推理引擎vLLM(1): FlashAttention论文以及原理解析
文章目录
abstract
** S P O **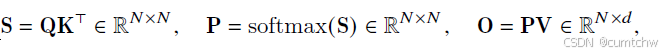
分块计算矩阵, 在线sotfmax就是分块处理,动态更新最大值和分母
HBM 太慢,而 GPU 的 SRAM / register 很快 ,所以flash attention通过减少attention计算过程中对HBM读写来加速。
分块计算、融合操作、减少缓存:通过分块计算,融合attention里面的多个操作,减少中间结果缓存
反向传播时,重新计算中间结果。
**** S P O ****
在线sotfmax就是分块处理,动态更新最大值和分母
分块计算、融合操作、减少缓存。
反向传播时,重新计算中间结果。
1 论文的Abstract–个人理解
我个人理解,论文这一段他就是说注意力的内存复杂度是跟序列长度成平方关系的,然后flashattention通过分块技术Tiling减少了 GPU 高带宽内存(HBM)和 GPU 芯片上 SRAM 之间的内存读写次数,降低了IO复杂度,然后在各种模型上表现很好。
2 不去看论文的复杂介绍,直接画图理解以及看伪代码流程
2.1 画图理解分块矩阵乘法的计算过程

上面是本来正常的注意力的计算过程,也就是没有进行分块的计算。
这里是分块计算过程,也就是每次只取矩阵的一小部分去计算,
2.2 画图理解online softmax的过程

这里能看出来,其实将softmax分块,然后每次计算的时候要去更新最大值以及分母,
3 论文里面的伪代码流程理解

-
1 这里就是分块,至于为什么除以4,是因为需要保存Q K V O这四个模块,但是其实真正使用的时候并不是真的按照这里的公式计算,有些程序里面就是用128.
-
2 初始化需要Q l m ,这里的O就是输出,l就是softmax的分母,m就是softmax时需要用到的最大值。
-
3 然后就是对Q KV分块
-
4 对O l m 进行分块
-
5 6 78 ,外层循环是kv,你村循环是q o l m ,
-
9 10 11 ,这些都是普通计算,
-
12 这里最开始不理解,重点说一下,
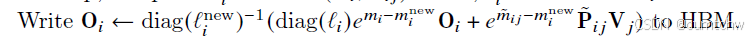
这里第12部的这个公式是什么意思呢,就是
-
前面括号外面的其实就是diag的逆运算,这里就是指softmax里面除以分母的操作,注意这里的是lnew,也就是用的新的分母,这个没什么疑问,
-
然后括号前半部分diag就是说乘以归一化因子,因为之前除过,现在乘,那么相当于求出来了之前的分子,然后还更新了最大值,
-
括号后半部分是这次新块计算的输出,然后跟以前的输出求和,那么就是总的分子。
-
- 前半部分:diag(ℓ_i)e^{m_i - m_i^{new}} O_i
diag(ℓ_i):乘以之前的归一化因子(即“除过”)
e^{m_i - m_i^{new}}:更新最大值后的缩放因子
O_i:之前的累积输出
本质:恢复之前的分子,因为:之前的 O_i = 分子 / ℓ_i
所以 分子 = ℓ_i × O_i
但最大值变了,需要重新缩放:e^{m_i - m_i^{new}} × 分子
- 前半部分:diag(ℓ_i)e^{m_i - m_i^{new}} O_i
-
- 后半部分:e^{ṁ_ij - m_i^{new}} Þ_ij V_j
e^{ṁ_ij - m_i^{new}}:将当前块的局部最大值转换到全局尺度
Þ_ij:当前块的未归一化注意力权重
V_j:当前块的 value 向量
本质:计算当前块的加权贡献,即 P_ij × V_j 的近似。
- 后半部分:e^{ṁ_ij - m_i^{new}} Þ_ij V_j
-
- 整体操作
将两部分相加:总分子 = 旧分子 + 新分子
除以 diag(ℓ_i{new}){-1}:总分母 = ℓ_i^{new}
结果就是:O_i = 总分子 / 总分母
- 整体操作
4 总结:FlashAttention里面本质上做了什么
分块计算矩阵,
在线sotfmax就是分块处理,动态更新最大值和分母
HBM 太慢,而 GPU 的 SRAM / register 很快 ,所以flash attention通过减少attention计算过程中对HBM读写来加速。
分块计算、融合操作、减少缓存:通过分块计算,融合attention里面的多个操作,减少中间结果缓存
反向传播时,重新计算中间结果。
参考文献:
Flash Attention 为什么那么快?原理讲解
论文精读——FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)