MiroThinker 研究智能体数据集构建、三阶段渐进式训练方法
MiroThinker采用单智能体ReAct框架,以“思考(T)-行动(A)-观察(O)”三元组构成交互轨迹,形成迭代循环。图左侧三大工具:执行环境(执行Shell命令和Python代码等)、文件管理、信息检索:包含谷歌搜索工具(返回结构化结果)和网页抓取工具(结合轻量LLM提取任务相关信息)。
MiroThinker采用单智能体ReAct框架,以“思考(T)-行动(A)-观察(O)”三元组构成交互轨迹,形成迭代循环。运行逻辑:智能体维护历史轨迹,接收用户查询后,先生成内部思考上下文,再输出结构化工具调用指令,执行后获取环境反馈并更新轨迹,直至无后续行动时生成最终答案。
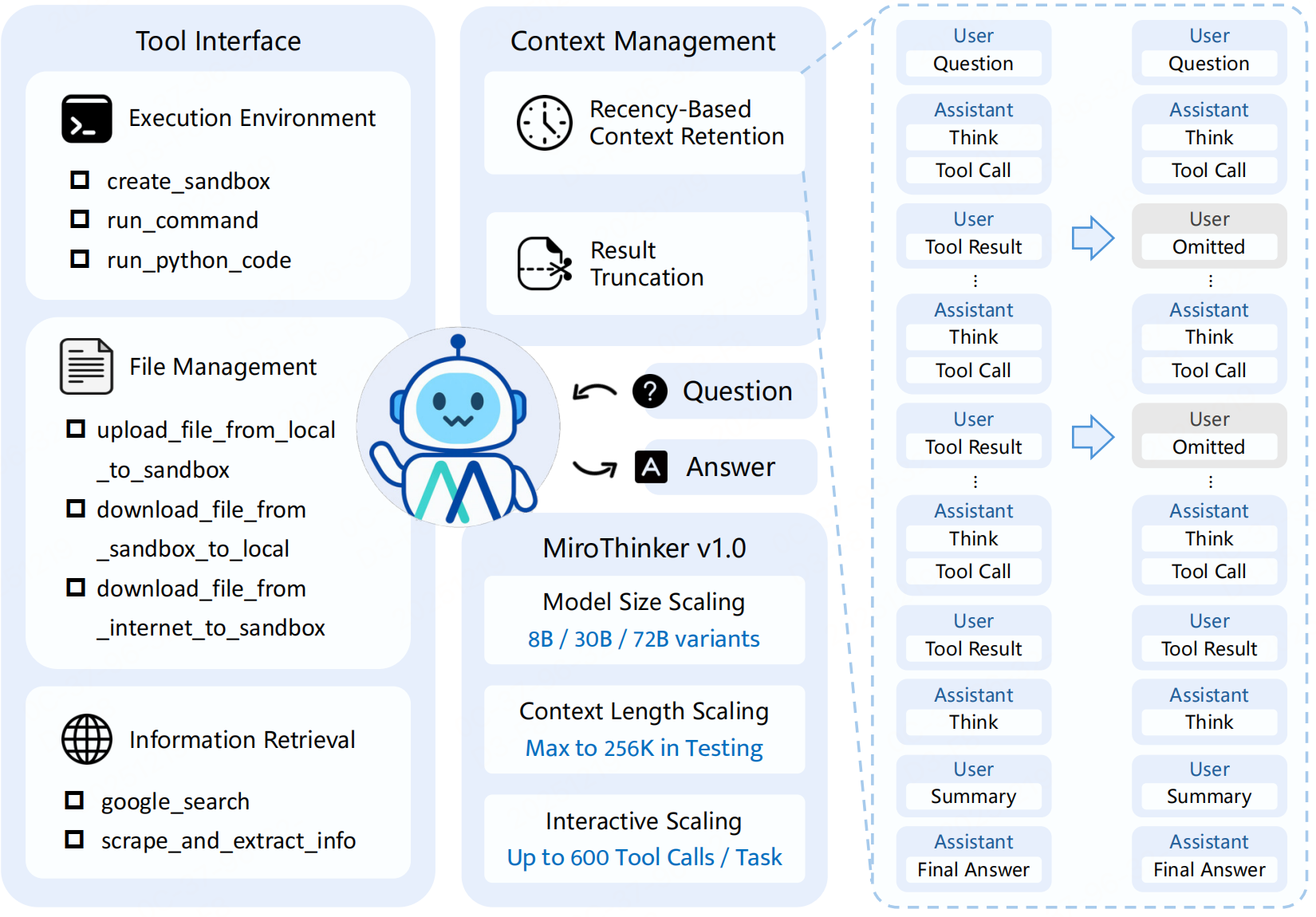
图左侧三大工具:执行环境(执行Shell命令和Python代码等)、文件管理、信息检索:包含谷歌搜索工具(返回结构化结果)和网页抓取工具(结合轻量LLM提取任务相关信息)。
数据构建
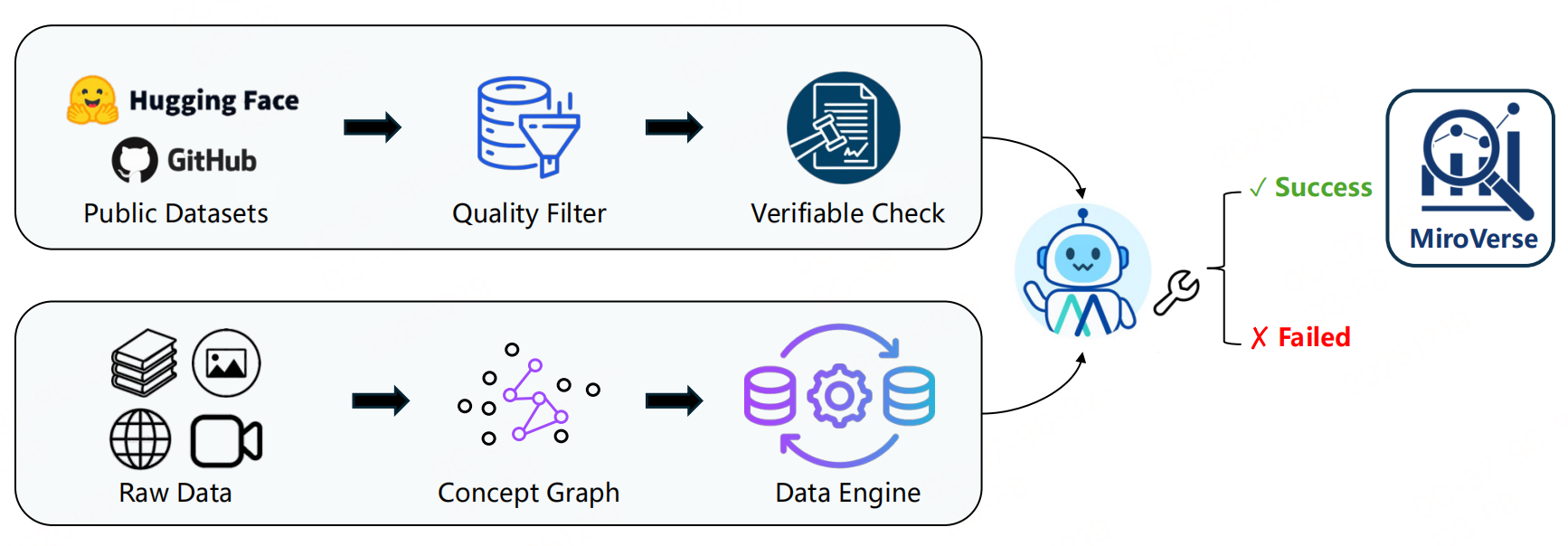
MiroThinker的数据构建覆盖「事实 grounding」和「智能体推理」两大核心能力,整体由「多文档问答(MultiDocQA)合成」「智能体轨迹合成」「开源数据收集」三部分构“合成数据为主、开源数据为辅”的数据集体系。
一、多文档问答(MultiDocQA)合成
该模块聚焦生成需要跨文档多跳推理的QA对,迫使模型整合多源信息而非依赖单文档检索,分为6个比较常规的数据合成步骤:
- 文档语料构建
- 文档采样与图构建
- 文档整合
- 事实提取
- 约束混淆
- 问题生成
二、智能体轨迹合成
重点看下该部分数据合成策略,目标是生成高质量、多样化的“思考(T)-行动(A)-观察(O)”智能体交互轨迹,训练模型的工具使用和迭代推理能力,分为3个维度:
1. 双智能体范式融合
- ReAct单智能体:通过“思考-行动-观察”迭代循环处理复杂任务,适配多步推理和自适应决策场景。
- MiroFlow多智能体:协调多个专业智能体分工协作,通过结构化协议通信,生成具备分工协作、集体推理特性的复杂轨迹。
2. 双工具调用机制
- 函数调用(Function Calling):结构化调用方式,通过预定义接口交互工具,输入输出规范,适配标准化场景。
- 模型上下文协议(MCP):灵活调用方式,通过上下文协商实现工具交互,支持复杂工具组合和动态工具发现,更贴近真实人机交互。
3. 多样化数据合成
采用GPT-OSS、DeepSeek-V3.1等多个顶尖模型生成轨迹,避免单一模型的风格偏差,提升数据丰富度和覆盖范围。确保轨迹涵盖不同推理路径、工具使用场景和交互模式,训练模型的泛化能力。
三、开源数据收集与补充
-
开源QA数据集整合:纳入MuSiQue、HotpotQA、WebWalkerQASilver、MegaScience、WikiTables等12+主流多跳QA数据集。仅保留QA对,通过上一节的轨迹合成流水线,将其转化为“思考-行动-观察”格式的智能体轨迹,统一训练范式。
-
后训练语料补充:加入AM-Thinking-v1-Distilled、Nemotron-Post-Training-Dataset等语料。保留模型的通用对话能力,覆盖更多样的推理风格和对话形式,避免过度专注于研究场景而丧失灵活性。
训练方法

MiroThinker的训练pipline基于Qwen2.5和Qwen3,采用“监督微调→偏好优化→强化学习”的三阶段递进架构,实现“基础智能体行为奠基→决策与任务目标对齐→真实环境泛化探索”。
阶段1:智能体SFT:目标是让模型学习基础智能体行为,模仿专家级的“思考-行动-观察”轨迹,建立工具使用和多跳推理的基本范式。数据集情况:构建大规模SFT数据集 DSFTD_{SFT}DSFT,每个样本包含“任务指令 xix_ixi”与“专家轨迹 HiH_iHi”,轨迹由“思考(T)-行动(A)-观察(O)”三元组组成。
阶段2:智能体偏好优化(PO):目标是优化模型决策偏好,让模型优先选择“更优的智能体轨迹”,而非单纯模仿专家行为,提升决策的有效性。
-
偏好数据集:构建成对偏好数据集 DPOD_{PO}DPO,每个样本包含“任务指令 xix_ixi”“偏好轨迹 Hi+H_i^+Hi+”“非偏好轨迹 Hi−H_i^-Hi−”,轨迹均为完整的“思考-行动-观察”交互序列。
-
偏好判断标准:
- 核心依据:以最终答案的正确性为首要准则,不强制固定推理长度、步骤数等结构约束,避免引入任务偏差。
- 质量控制:偏好轨迹需推理连贯、有明确规划且答案正确;非偏好轨迹也需产出有效答案,同时过滤重复、截断、格式异常等低质量样本。
-
优化框架:采用直接偏好优化(DPO),并引入偏好轨迹的辅助SFT损失,平衡“偏好对齐”与“行为稳定性”。鼓励模型对偏好轨迹分配更高概率,同时控制与参考模型(冻结的SFT模型)的偏差。
阶段3:智能体强化学习(RL):目标是让模型通过与真实环境的直接交互,探索创造性解决方案,提升在复杂真实场景中的泛化能力。采用分组相对策略优化(GRPO),通过“每轮提示采样多个轨迹,计算相对于组均值的优势”来更新策略,支持全在线训练(每个rollout轨迹仅用于一次模型更新)。
-
训练环境构建:
- 多能力环境:支持实时多源搜索、网页抓取与总结、Python代码执行、Linux虚拟机操作等,可承载数千个并发智能体交互。
- LLM评分系统:构建高效的LLM评判体系,低延迟验证模型预测结果与真实答案的一致性,为强化学习提供可靠反馈。
-
滚动加速机制:针对智能体交互轨迹的“长尾耗时”问题,采用流式滚动(Streaming Rollout)——智能体 worker 从任务队列流式获取提示,未完成任务回流至队列,确保高效收集足够训练样本。
-
奖励函数:综合“答案正确性”与“格式合规性”,公式为 R(x,H)=αcRcorrect(H)−αfRformat(H)R(x, H)=\alpha_{c} R_{correct }(H)-\alpha_{f} R_{format }(H)R(x,H)=αcRcorrect(H)−αfRformat(H)。其中 RcorrectR_{correct}Rcorrect 衡量答案准确性,RformatR_{format}Rformat 惩罚格式违规,αc\alpha_cαc 和 αf\alpha_fαf 用于平衡“探索创新”与“指令遵循”。
-
轨迹筛选:
- 过滤正确但噪声轨迹:剔除连续API调用失败(>5次)、重复执行相同动作、环境超时频繁等非有效解题策略的样本。
- 过滤无效错误轨迹:剔除因格式错误、动作循环、过早终止导致的错误样本,确保训练信号的高质量。
-
目标函数:最大化轨迹优势的同时,控制与参考模型(偏好优化阶段的模型)的KL散度,避免策略漂移,公式为:
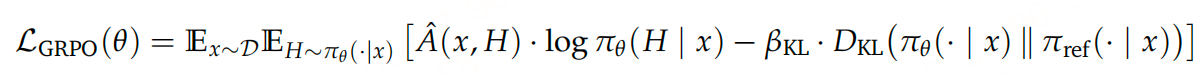
-
优势计算:对每个任务指令采样G条轨迹,某条轨迹的优势为其奖励与组内平均奖励的差值,即 A^i=R(x,Hi)−1G∑j=1GR(x,Hj)\hat{A}_{i}=R\left(x, H_{i}\right)-\frac{1}{G} \sum_{j=1}^{G} R\left(x, H_{j}\right)A^i=R(x,Hi)−G1∑j=1GR(x,Hj)。
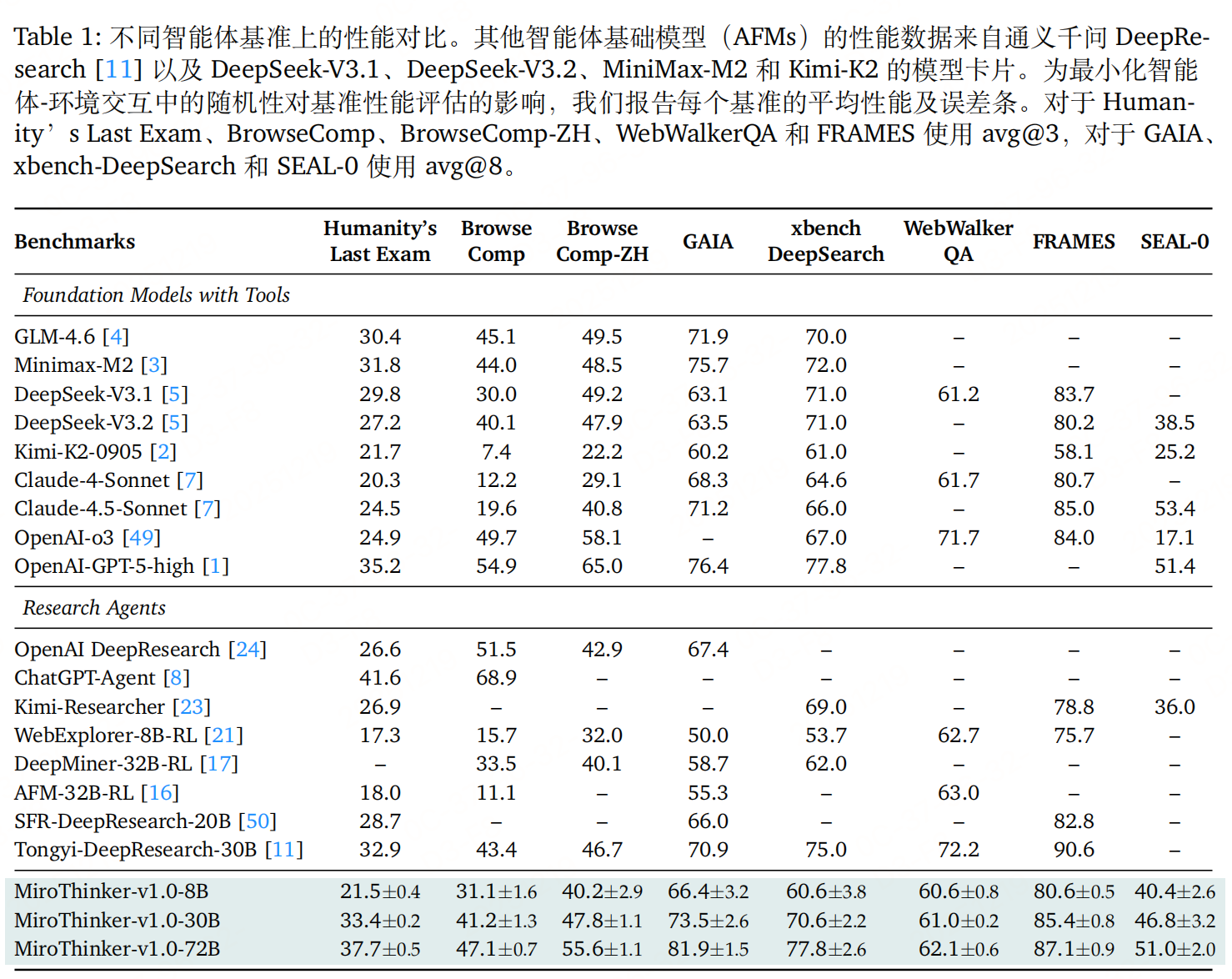
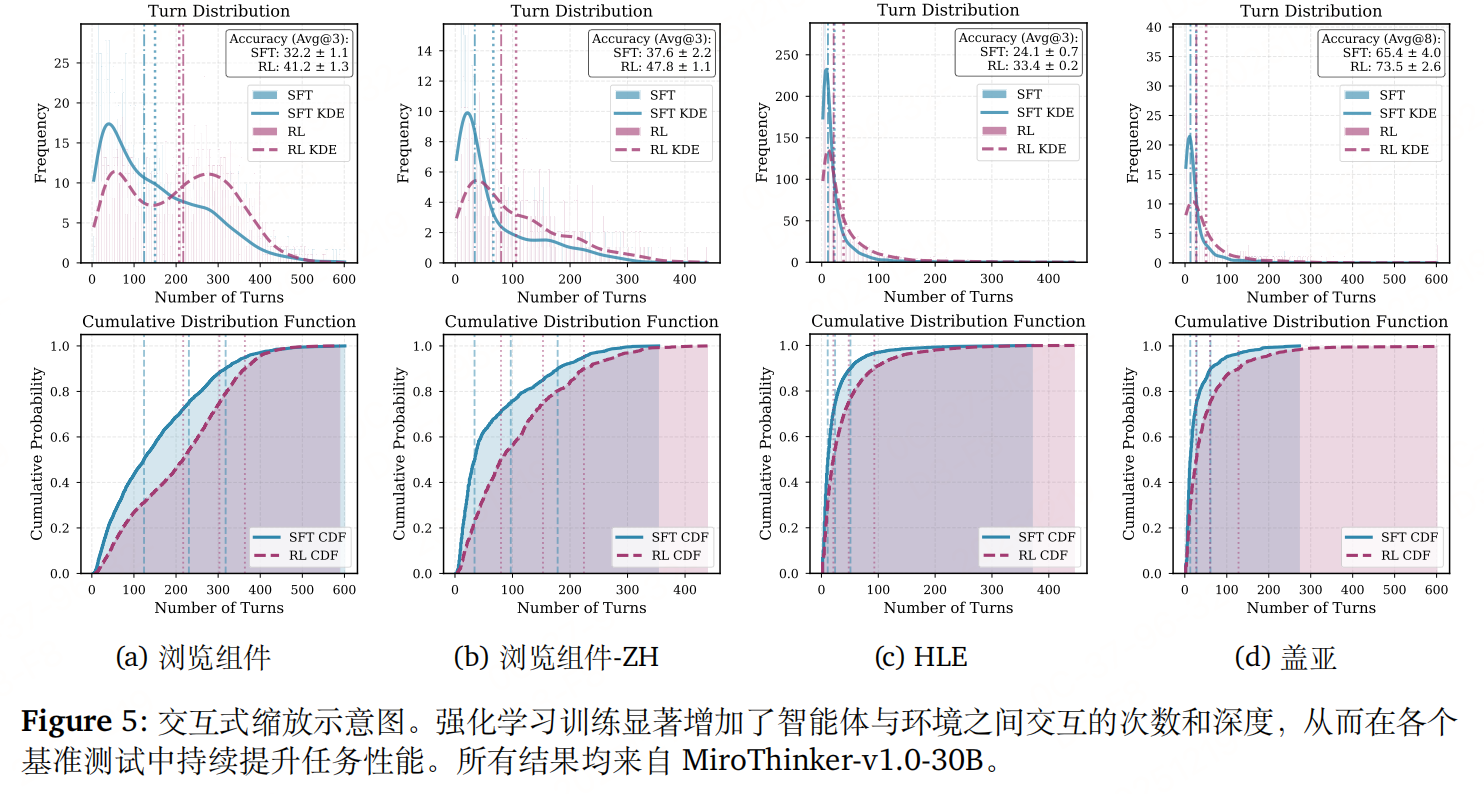
实验性能
参考文献
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling,https://arxiv.org/pdf/2511.11793

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)