深度学习 第六节 无监督学习 Unsupervised learning
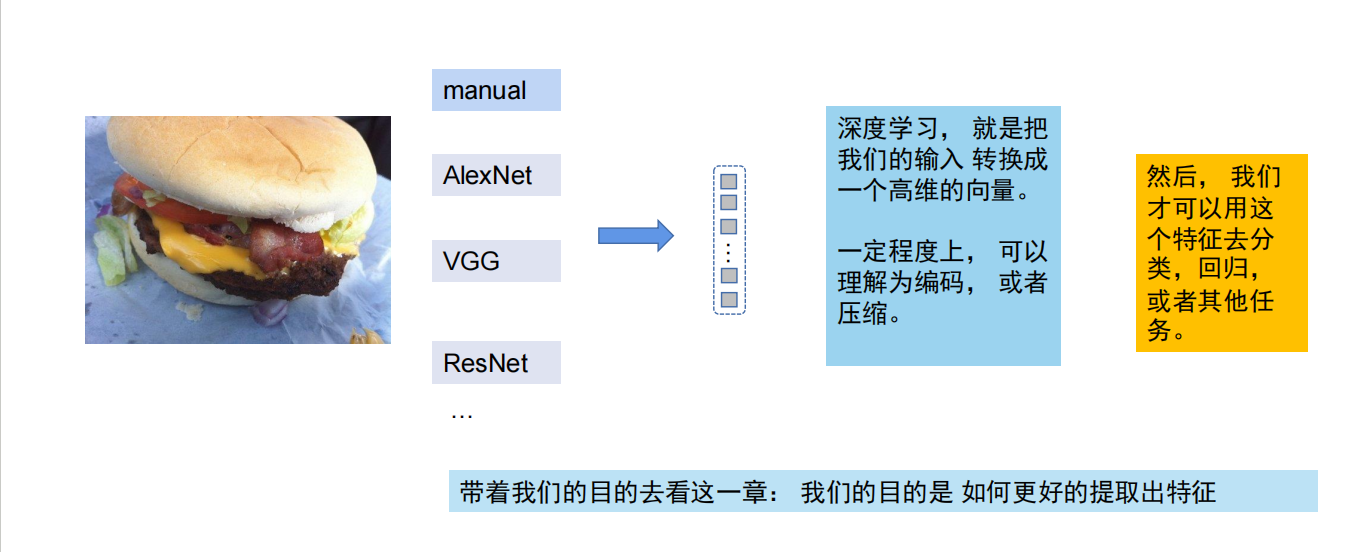
AI学习人类 其实是 AI在学习特征
无监督学习的核心意义在于摆脱对人工标注数据的依赖,让模型从海量无标签数据中自主发现隐藏结构与模式,降低数据使用门槛、拓展 AI 的应用边界,同时为探索通用人工智能提供关键路径。以下从多个维度展开说明:
核心价值与意义
- 降低数据使用成本与门槛
- 现实中 90% 以上数据无标注,人工标注耗时、耗力且易出错,无监督学习可直接利用这些原始数据,避免高昂标注成本,尤其适合标注困难的领域(如基因测序、天文观测、工业传感器数据)。例如,在金融风控中,无需人工标注正常 / 异常交易,通过聚类或密度估计就能识别欺诈行为,大幅提升效率。
- 挖掘未知模式与隐藏价值
- 无监督学习以 “数据为中心”,不受预设标签限制,能发现人类难以察觉的深层关联,比如用户行为的潜在群体划分、基因数据中的致病片段关联、文本数据的主题聚类等。例如,电商平台用聚类算法分析用户购买记录,可发现交叉销售机会,如购买婴儿奶粉的用户常搭配辅食工具,从而优化推荐策略。
- 数据预处理与特征工程的核心工具
- 降维算法(如 PCA、t-SNE、UMAP)可压缩高维数据、保留核心信息,解决 “维度灾难”,同时实现数据可视化、去噪和加速计算。例如,将 100 维的用户行为数据降为 3 个核心维度,便于后续监督学习模型训练,提升性能与效率。聚类结果还可作为新特征输入监督模型,如用户分群 ID 用于精准营销预测。
- 赋能 AI 自主认知与通用智能探索
- 无监督学习让模型自主构建数据的内在表示,是大模型预训练的核心(如 BERT、GPT 的自监督预训练),使其从海量文本中学习语言规律,为下游任务提供强大基础。同时,生成式无监督模型(如 GAN、VAE)能创造新数据,推动图像生成、文本合成等任务发展,为通用人工智能提供 “从经验中自主学习” 的路径。
- 适配复杂场景的灵活解决方案
- 在缺乏先验知识的探索性场景中(如宇宙学研究、社会学调查),无监督学习可作为 “数据侦探”,快速梳理数据结构,为后续研究提供方向。此外,异常检测能力在网络安全、设备预测性维护中至关重要,如通过分析服务器日志的异常模式,提前预警入侵或故障。
- 与监督学习互补,提升整体效能
- 无监督学习与监督学习形成 “探索 - 验证” 闭环:先用无监督发现数据结构、生成假设,再用监督学习验证并优化预测精度。例如,先用聚类划分客户群体,再针对不同群体训练个性化推荐模型,兼顾效率与精准度。
下游任务(Downstream Tasks)指在预训练模型基础上,通过微调(Fine-tuning)或迁移学习(Transfer Learning)解决的特定问题。这些任务通常依赖于预训练模型提取的通用特征,并针对具体场景(如文本分类、目标检测等)进行优化。
常见下游任务类型
自然语言处理(NLP)
- 文本分类:情感分析、新闻主题分类。
- 序列标注:命名实体识别(NER)、词性标注。
- 生成任务:机器翻译、文本摘要。
计算机视觉(CV)
- 图像分类:识别物体类别。
- 目标检测:定位并识别图像中的多个物体。
- 图像分割:像素级分类(如语义分割)。
多模态任务
- 图文匹配:判断文本与图像的相关性。
- 视觉问答(VQA):根据图像回答文本问题。
下游任务实现步骤
数据准备
标注数据需与任务匹配,例如分类任务需标注类别标签,检测任务需标注边界框。
模型选择
基于预训练模型(如BERT、ResNet)初始化,根据任务调整输出层。例如:
- 文本分类任务在BERT后接全连接层。
- 目标检测任务在ResNet后接FPN(特征金字塔网络)。
微调策略
- 学习率调整:下游任务通常使用更低的学习率(如预训练的1/10)。
- 分层训练:先微调顶层,逐步解冻底层参数。
评估指标
- 分类任务:准确率(Accuracy)、F1值。
- 检测任务:mAP(平均精度均值)。
- 生成任务:BLEU(机器翻译)、ROUGE(文本摘要)。
典型应用案例
- BERT微调:通过添加分类层实现情感分析。
- ResNet迁移:替换ImageNet预训练模型的最后一层,用于医学图像分类。
下游任务的核心在于利用预训练模型的通用能力,通过少量标注数据实现高性能的特定场景应用。
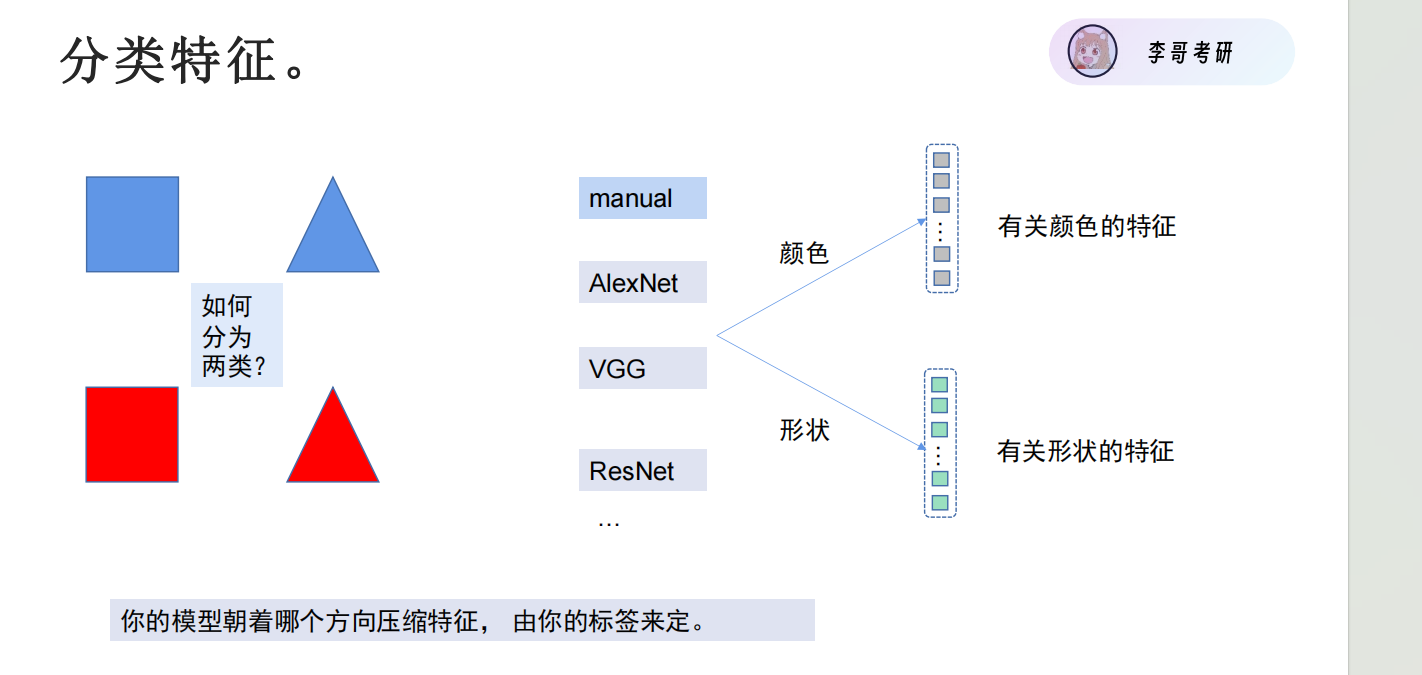
刚开始的分类回归是有监督 也就是有x 有 y 半监督是 x中有一些有y 有一些无y 无监督:没有人工标注的 y(标签)
一、机器学习类无监督方法
-
PCA(主成分分析)
用来压缩数据维度:比如把几百个特征的高维数据,简化成几个核心特征(保留主要信息),方便后续分析 / 建模(比如高维图像数据降维后可视化)。 -
聚类
用来给数据分组:比如把用户按消费行为分成 “高活跃”“低活跃” 群,或把商品按属性分成不同类别(不需要提前给标签)。
二、深度学习类无监督方法
-
生成对抗网络(GAN)
用来生成新数据:比如生成逼真的图片、文本(例:AI 画头像、自动写文案),或修复模糊图像。 -
自监督学习(对比学习 / 生成式自监督)
用 “数据本身当标签”训练模型提取特征:比如让模型自己学 “同一张图的不同裁剪是相似的”,再用这个模型去做分类 / 检测(省掉人工标标签的成本)。
![]()
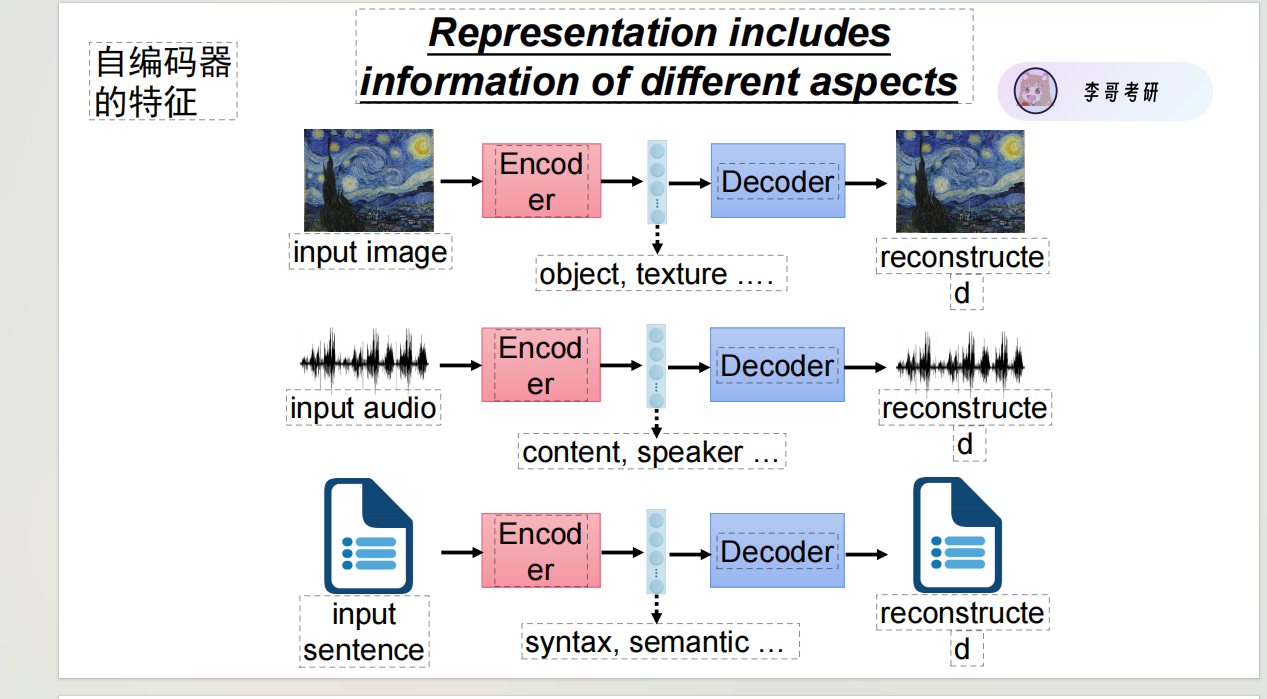
模型:必须拥有某种提取特征的能力
Simsaim 是自监督学习里的对比学习方法,核心逻辑可以简单总结为:
给同一张图做两次不同的随机变换(比如裁剪、翻转、调色),让模型把这两个 “版本” 的特征学得尽可能像(拉近距离),同时不用额外的负样本 —— 靠 “自己监督自己” 学会提取通用的图像特征,之后能直接用到分类、检测等任务里。
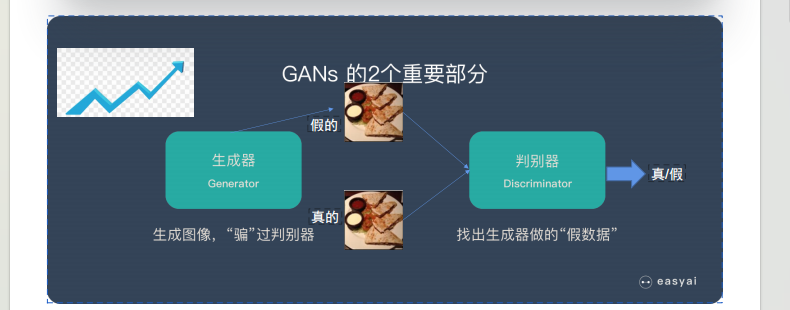
GAN(生成对抗网络)是一种用 “两个模型互相对抗” 来生成逼真数据的方法,核心逻辑:
一个 “生成器”:负责造假数据(比如假图片、假文本);
一个 “判别器”:负责区分 “生成器造的假数据” 和 “真实数据”;
两者互相博弈、不断升级,最终生成器能造出和真实数据几乎一样的内容(比如 AI 画的逼真人像、模拟的真实语音)。
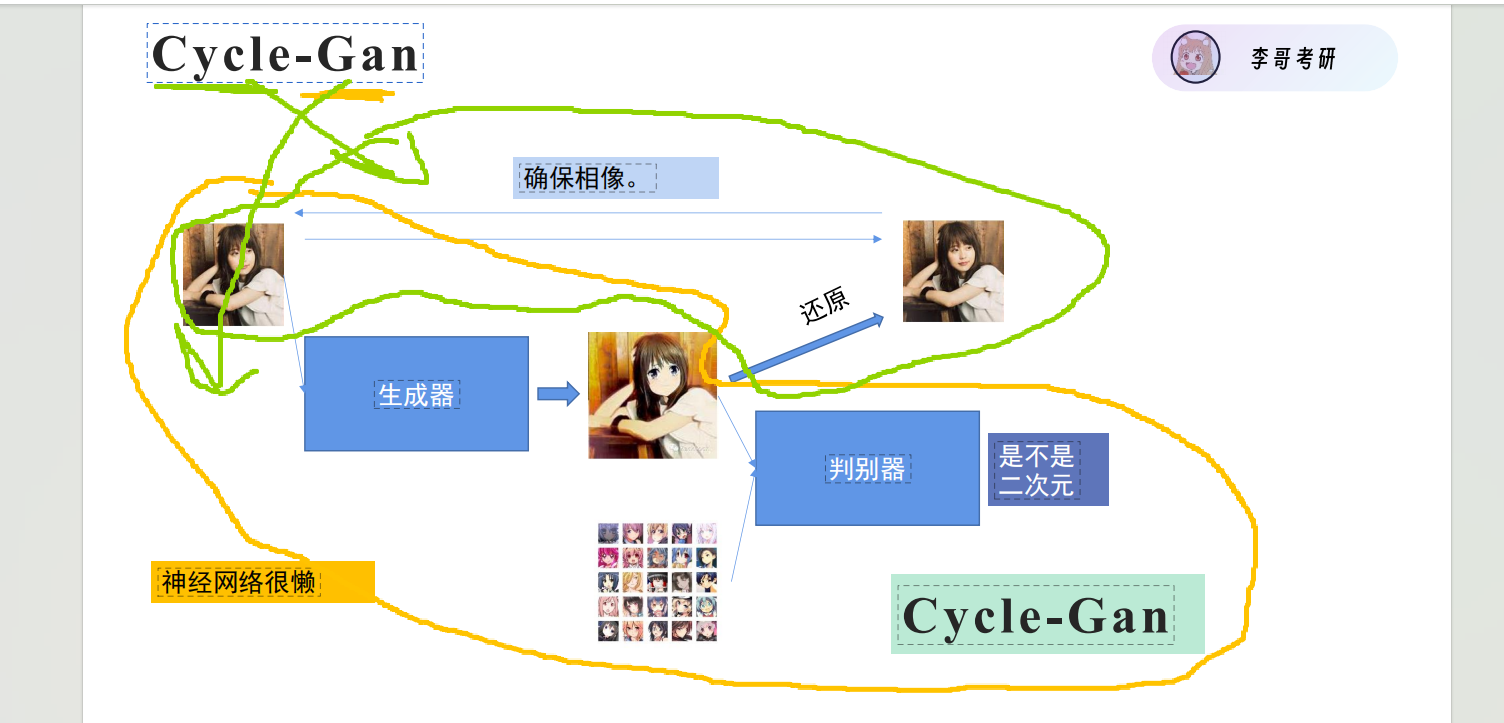
Cycle GAN 是 专门做 “跨域数据转换”的 GAN,核心逻辑:
比如要把 “照片转成手绘”“猫图转成狗图”—— 它用两个生成器(A→B、B→A)+ 两个判别器(判 B 真假、判 A 真假),通过 “循环一致性”(A 转 B 再转回 A,得和原 A 差不多)来保证转换后既像目标域,又不丢原数据的核心特征。
典型场景:风格迁移(照片转油画)、图像翻译(白天转夜景)
无监督学习后,核心就 3 件事,简单说:
- 看结果找意义:比如聚类出的 “用户群”,贴业务标签(如 “高活跃用户”);异常数据查原因(是真问题还是数据错);
- 帮后续任务省劲儿:用无监督先练模型(如 BERT 预训练),再用少量标注数据做分类 / 识别;或给无标签数据标 “伪标签”,辅助监督学习;
- 优化模型本身:用指标(如轮廓系数)评聚类 / 异常检测效果,调参数;数据 / 业务变了,就更新模型。
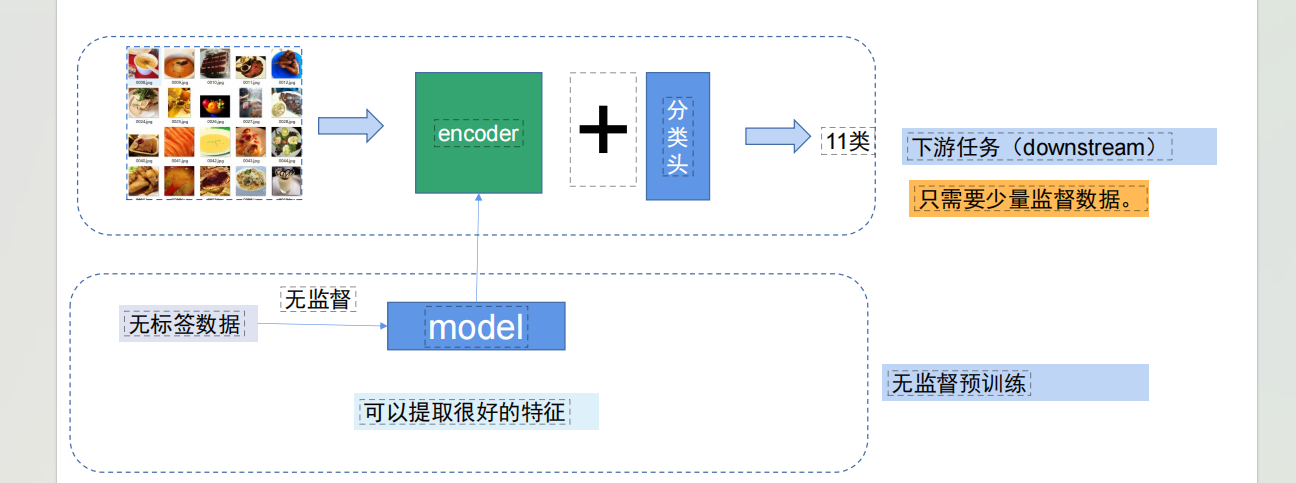
先用大量无标签数据做无监督预训练,让model(对应图里的encoder)学会提取通用的好特征;之后给encoder接上 “分类头”,只用少量带标签的数据微调,就能完成 11 类分类这样的下游任务。
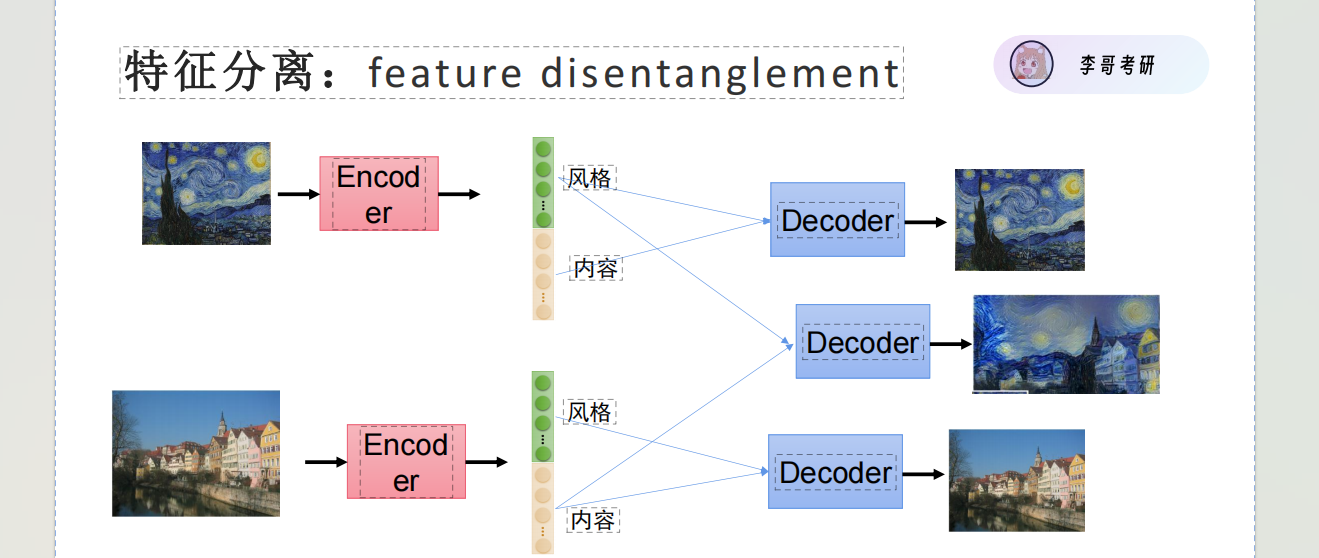
通过特征提取 分离 得到想要的目标

词编码核心就是把计算机看不懂的文字词汇,转换成它能处理的数字(向量/整数),
简单分两类,核心信息如下:
1. 无语义,只做简单映射:独热编码、标签编码,只解决“文字转数字”的问题,不理解词汇含义。 比如“猫”→ 1、“狗”→ 2,计算机不知道它俩都是动物,也无法区分“苹果(水果)”和“苹果(品牌)”。
2. 带语义,懂词汇关联 也叫“词嵌入,核心是让语义相近的词,对应的数字向量更“像”(距离更近)。 分两种:
- 静态(如Word2Vec):一个词只有一个固定向量,比如“猫”和“狗”的向量始终相似;
- 动态(如BERT):词的向量随上下文变化,能区分“吃苹果”和“苹果电脑”里的“苹果”。
3. 核心用途 支撑所有NLP任务(如情感分析、机器翻译、智能对话等),是NLP的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)