代码Agent效率革命:Cursor动态上下文发现技术,减少46.9%token消耗!
Cursor引入动态上下文发现技术,通过将长工具响应转为文件、引用聊天历史、支持Agent Skills、按需加载MCP工具、将终端会话视为文件等方法,减少token使用量46.9%。这种动态获取所需信息的方式,相比静态上下文能提升代码Agent的效率和回复质量,使AI编程助手更加智能高效。
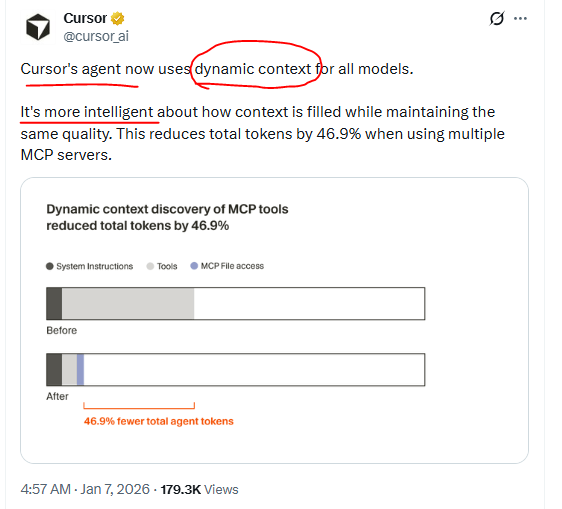
Cursor 的 agent 现在为所有模型使用动态上下文(dynamic context)。它在保持相同质量的同时,更智能地填充上下文。使用多个 MCP 服务器时,这可将总 token 数量减少 46.9%。
代码 Agent正在迅速改变软件的开发方式。它们的快速进步既来自更强的 Agent 模型,也来自更好的上下文工程,用于引导其行为。
随着模型在充当 Agent 方面的能力不断提升,我们发现,预先提供更少的细节,反而能让 Agent 更容易自主地按需提取相关上下文。我们将这一模式称为 动态上下文发现(dynamic context discovery),与始终被包含的 静态上下文(static context) 相对。
用于动态上下文发现的文件
动态上下文发现的 token 使用效率要高得多,因为只会将必要的数据引入上下文窗口。同时,它还能通过减少上下文窗口中可能造成混淆或互相矛盾的信息量来提升 agent 的回复质量。
以下是在 Cursor 中使用动态上下文发现的做法:
-
将较长的工具响应转化为文件
-
在总结时引用聊天记录
-
支持 Agent Skills 开放标准
-
高效地仅加载所需的 MCP 工具
-
将所有集成终端会话视为文件
-
将较长的工具响应转换为文件
工具调用可能会因为返回体积巨大的 JSON 响应而显著增加上下文窗口的大小。
对于 Cursor 中的自研工具,比如编辑文件和搜索代码库,我们可以通过合理的工具定义和精简的响应格式来避免上下文膨胀,但第三方工具(如 shell 命令或 MCP 调用)并不能天然享受同样的优化。
常见的做法是,代码 Agent 会截断较长的 shell 命令输出或 MCP 结果。这可能导致数据丢失,其中可能包括你希望保留在上下文中的重要信息。在 Cursor 中,我们则是把输出写入文件,并赋予 Agent 读取该文件的能力。Agent 会调用 tail 来检查末尾内容,如有需要再继续向后读取更多内容。
这样在接近上下文上限时,就能减少不必要的额外总结。
- 在摘要过程中引用对话历史
当模型的上下文窗口被填满时,Cursor 会触发一次摘要步骤,为 Agent 提供一个全新的上下文窗口,其中包含它迄今为止工作的摘要。
但由于这是对上下文的有损压缩,Agent 的掌握情况在摘要之后可能会变差,可能会忘记任务中的关键细节。在 Cursor 中,我们将对话历史作为文件提供,以提升摘要的质量。

在达到上下文窗口上限后,或者用户决定手动进行摘要时,我们会给 Agent 一个指向历史文件的引用。如果 Agent 发现自己需要的更多细节没有包含在摘要中,它可以在历史中搜索以找回这些信息。
- 支持 Agent Skills 开放标准
Cursor 支持 Agent Skills,这是一种用于为编码 Agent 扩展专用能力的开放标准。与其他类型的 Rules 类似,Skills 由文件定义,这些文件会告诉 Agent 如何执行特定领域的任务。
Skills 还包括名称和描述,可以作为"静态上下文"包含在系统提示词中。随后,Agent 可以进行动态上下文发现,使用诸如 grep 和 Cursor 的 语义搜索 等工具自动引入相关的 Skills。
Skills 还可以打包与任务相关的可执行文件或脚本。由于它们本质上只是文件,Agent 可以轻松找到与某个特定 Skill 相关的内容。
- 高效地仅加载所需的 MCP 工具
MCP 有助于访问受 OAuth 保护的资源,比如生产环境日志、外部设计文件,或企业内部的上下文和文档。
有些 MCP 服务器包含很多工具,且往往带有很长的描述,这会显著膨胀上下文窗口。即使这些工具始终被包含在提示中,其中大部分实际上并不会被使用。如果你使用多个 MCP 服务器,这个问题会被进一步放大。
指望每个 MCP 服务器都为此进行优化并不现实。我们认为,降低上下文占用是编码 Agent 的责任。在 Cursor 中,我们通过将工具描述同步到一个文件夹,为 MCP 提供了动态上下文发现能力。
Agent 现在只会收到一小段静态上下文(包括工具名称),并在任务需要时再去查找具体工具。在一次 A/B 测试中,我们发现:在会调用 MCP 工具的运行中,这一策略 将 Agent 的总 token 消耗减少了 46.9%(这一结果在统计上显著,但会随已安装 MCP 的数量产生较大波动)。

这种基于文件的方案还带来了一个好处:可以向 Agent 传达 MCP 工具的状态。比如,以前如果某个 MCP 服务器需要重新认证,Agent 会完全"遗忘"这些工具,让用户摸不着头脑。现在,它可以主动提示用户进行重新认证。
- 将所有集成终端会话视为文件
过去你需要把终端会话的输出复制粘贴到 Agent 的输入中,Cursor 现在会自动将集成终端的输出同步到本地文件系统。
这样你就可以轻松询问"为什么我的命令失败了?",并让 Agent 理解你具体在引用什么。由于终端历史可能很长,Agent 可以只对相关输出进行 grep,这对于像服务器这类长时间运行的进程所产生的日志尤其有用。
这与基于 CLI 的编码 Agent 所看到的情况相似:它们同样可以在上下文中访问先前的 shell 输出,但这里是动态发现的,而不是静态注入的。
简单抽象
目前还不清楚,文件是否会成为基于 LLM 的工具的最终接口形式。
不过,随着编码 Agent 的快速发展,文件一直是一种简单而强大的原语,相比再造出一种无法充分兼顾未来的抽象层,也是更安全的选择。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
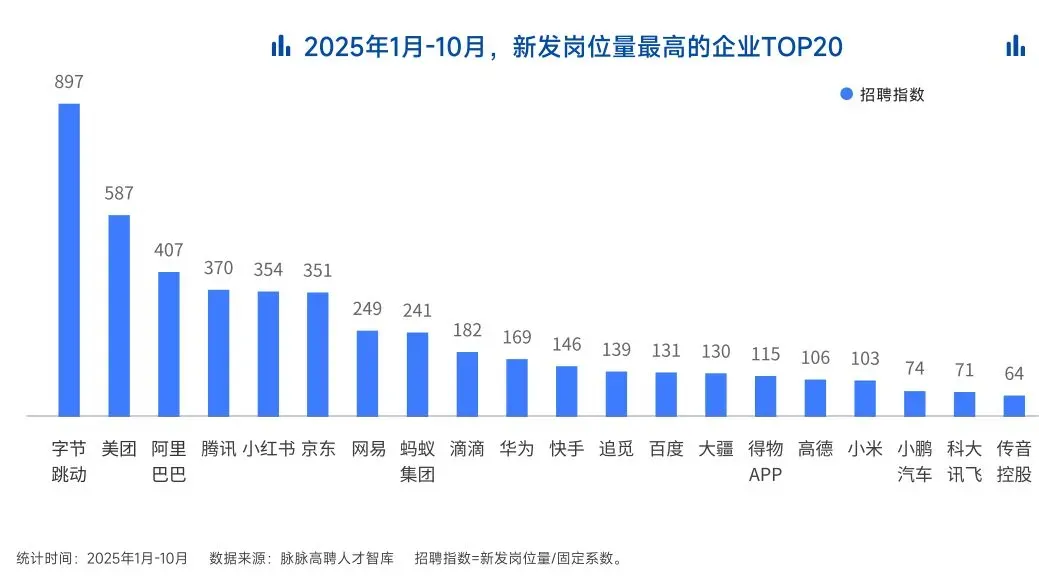
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献454条内容
已为社区贡献454条内容

所有评论(0)