百万数据证实:大模型的顿悟时刻是统计学幻觉,高熵触发重算才是关键!
普林斯顿大学研究通过百万条数据分析发现,大语言模型的"顿悟时刻"实为统计学幻觉,自发纠错罕见且常导致准确率下降。研究提出形式化"Aha!"时刻定义框架,证实模型在高度不确定(高熵)时缺乏自发反思能力。但实验显示,当监测到模型高熵状态时强制其重新思考,准确率可提升8%,揭示了当前推理模型缺乏元认知内驱力机制,为提升模型性能提供了新思路。
❝
一句话概括,本文通过百万条数据实锤,推理模型所谓的“顿悟时刻”纯属统计学幻觉,自发纠错不仅罕见而且越改越错,但只要你在它算得最不确定(高熵)时强行让它重算,准确率竟然能暴涨8%!(原论文题目见文末,点击阅读原文可直接跳转至原文链接, Published on arXiv on 02 Jan 2026, by Princeton University.)

第一阶段:识别核心概念
论文的motivation分析
大家最近都被推理模型(Reasoning Models),比如DeepSeek R1或者OpenAI o1系列的表现惊艳到了。这些模型最迷人的地方在于,它们会在思考过程中输出像“Wait… let me re-evaluate”(等等… 让我重新评估一下)这样的内容,然后修正之前的错误,最终给出正确答案。这种行为看起来太像人类的“顿悟”或“自我纠正”了。
但是,普林斯顿大学的研究团队提出了一个尖锐的问题:这种看似“顿悟”的行为,真的是模型产生了内在的智力飞跃吗?还是说这只是一种随机的、不稳定的表现? 目前大家主要依赖轶事证据(偶尔看到的几个好例子),缺乏大规模的定量分析。这篇论文的动机就是要把这种“玄学”变成可以测量的“科学”,对这种现象进行一次系统性的“泼冷水”式研究。
论文主要贡献点分析
- 提出了“Aha!”时刻的形式化定义:作者没有通过感觉来判断顿悟,而是提出了一套包含三个严格条件的数学框架来定义什么是真正的“Aha!”时刻。
- 大规模实证分析:作者分析了超过100万条推理轨迹(Reasoning Traces)。最重要的发现是:模型自发的“思维转变”非常罕见,而且通常与较低的准确率相关。也就是说,模型并不是因为“想通了”才改口,往往是因为“乱了方寸”。
- 揭示了不确定性(Entropy)的作用:作者发现,虽然模型自发的纠正大多没用,但在模型**高度不确定(高熵,High Entropy)**的时候,如果我们人为地强制模型去“反思”,准确率是可以显著提升的。这说明“顿悟”与其说是一种能力,不如说是一种可以被利用的不稳定状态。
理解难点识别
- 核心难点:如何量化“顿悟”?如何区分“无意义的啰嗦/犹豫”和“真正的策略性顿悟”?单纯检测关键词(比如检测有没有“Wait”)是不够的,因为模型可能只是在复读套话。
- 重点解释的核心概念:“形式化的 Aha! 时刻检测框架”(Formal “Aha!” Moment Detection Framework)。这是全篇的基石,它结合了自然语言处理(检测文本变化)和统计学标准(检测性能变化)。
概念依赖关系
- 推理轨迹(Reasoning Trace):这是基础数据,即模型的
<think>标签里的内容。 - 思维转变(Reasoning Shift):这是表象,指模型在思考过程中推翻了之前的想法。
- 形式化 Aha! 时刻(Formal “Aha!” Moment):这是本质,必须满足特定统计条件的思维转变。
- 熵(Entropy)与干预:这是应用,通过监测不确定性来利用上述现象。
我们将重点放在**“形式化 Aha! 时刻检测框架”及其背后的统计学原理**上。
第二阶段:深入解释核心概念
比喻中的关键元素
- 场景:学生正在参加一系列数学考试(训练过程)。
- 学生的行为:在草稿纸上解题(推理轨迹)。
- 涂改行为:划掉之前的步骤,写下“Wait…”并换方法(思维转变)。
- 真正的顿悟:不仅涂改了,而且必须满足特定条件的成功逆袭(形式化 Aha! 时刻)。
每个元素对应的实际技术概念
- 草稿纸上的涂改:对应模型生成的 Chain-of-Thought (CoT) 中出现了特定的关键词(如 “Wait”, “Actually”),并且经由一个 LLM 裁判(Judge)判定,它确实在语义上推翻了之前的计划。
- 以前从没做对过:对应框架中的先前的失败 (Prior Failures) 条件。
- 以前很执着:对应框架中的先前的稳定性 (Prior Stability) 条件。
- 这次逆袭了:对应框架中的性能增益 (Performance Gain) 条件。
深入技术细节与比喻映射
作者提出了三个条件来定义一个检查点(Checkpoint )上的某个问题()是否发生了“Aha!”时刻。
条件一:先前的失败 (Prior Failures)
必须确保这个问题对模型来说是很难的,不是瞎猫碰死耗子。就像老师说:“这个学生以前这道题从来没及格过。”
-
原始数学形式:
-
符号替换版本:
在当前时刻之前的所有检查点,模型答对该问题的概率设定的低分阈值(如)
条件二:先前的稳定性 (Prior Stability)
必须确保模型之前不是那种总是犹豫不决的状态,这样才能突显出这次转变的特殊性。就像老师说:“而且他以前解这道题从来不纠结,总是闷头算错。”(排除模型本身就不稳定、总是乱改答案的情况)。
-
原始数学形式:
-
符号替换版本:
在当前时刻之前的所有检查点,模型发生思维转变(涂改)的概率设定的频率阈值
条件三:性能增益 (Performance Gain)
这是最关键的,“顿悟”必须带来正确的结果,否则只是“瞎折腾”。就像老师说:“但就在今天,他突然改了方法,而且正是因为改了方法,他做对了!”
-
原始数学形式:
-
符号替换版本:
发生了思维转变时的答对概率该模型在当前时刻的整体平均答对概率显著的提升阈值
注意:这里计算的是差值,也就是说,发生思维转变那几次的平均分,要显著高于该模型在这个时刻的整体平均水平。
总结
并不是所有的“Wait… let me think”都是顿悟。绝大多数时候,模型说“Wait”只是在“胡言乱语”或者是“考场焦虑”(不确定性高)。真正的“Aha!”时刻必须是**“以前不会且不改” -> “现在改了且对了”**的稀有事件。
第三阶段:详细说明流程步骤
1. 数据准备与模型训练流程
- 输入:基础大模型(如 Qwen2.5-1.5B, Llama 3.1-8B)以及三个不同领域的推理数据集:数学题(MATH-500,象征多步计算)、填字游戏(Cryptic Crosswords,象征侧向思维)、华容道(Rush Hour,象征空间规划)。
- GRPO 微调:作者使用 GRPO(Group Relative Policy Optimization)算法对模型进行强化学习微调。这是一种让模型生成多个答案,然后根据答案的好坏来优化策略的方法。
- 关键操作:在训练的每50步(Step),作者都会保存一个模型检查点(Checkpoint)。这就像给模型的成长过程拍X光片,一共拍了20张(从Step 0 到 Step 950)。
2. 推理轨迹生成与标注流程
对于每一个检查点上的每一个问题,执行以下操作:
- 采样(Sampling):模型针对同一个问题生成 个不同的回答(Sampling temperature设为非0值以保证多样性)。
- 标签清洗:提取
<think>标签内的内容。 - 思维转变检测(Shift Detection Pipeline):
- 步骤 A(正则过滤):先用关键词列表(Whitelist)扫描。比如是否有 “Wait”, “Hold on”, “Let’s rethink” 等词。如果没有,直接判定为“无转变”。
- 步骤 B(LLM 裁判):如果有关键词,将这段文本喂给 GPT-4o。GPT-4o 作为裁判,需要判断:是否有明确的词汇线索?是否真的进行了实质性的策略修改(比如换了公式、换了单词解析)?只有两者都满足,才标记 (发生了 Shift)。
3. 统计分析与假设验证流程
有了上述数据(每个时间点、每个问题、是否Shift、是否答对),作者进行核心计算:
- 计算概率:计算每个检查点 上,问题 的答对率 和转变率 。
- 筛选 Aha! 时刻:应用 Definition 3.1 的三个不等式,筛选出真正的“Aha!”事件。
- 计算熵(Entropy Calculation):对于每一条生成的回答,计算其 token 级别的平均熵(Entropy)。熵越高,代表模型在这个位置越“迷茫”,对选哪个词越没把握。
- 关联分析:将“是否发生 Shift”与“是否答对”进行回归分析;将“熵的高低”与“Shift 的有效性”进行关联。
4. 干预实验流程(Intervention)
这是作者为了验证“怎么利用这种现象”设计的流程:
- 第一次尝试(Pass 1):让模型正常回答问题。
- 不确定性门控(Entropy Gate):计算 Pass 1 的熵。如果熵很高(Top 20%),说明模型自己也虚;如果熵很低,说明模型很自信。
- 第二次尝试(Pass 2 - Triggered):无论 Pass 1 结果如何,强制将 Pass 1 的输入加上一句提示词:“Wait, something is not right, let’s think step by step.”(等等,好像不对,让我们一步步想)。强制模型基于这个前缀继续生成。
- 对比:比较 Pass 2 和 Pass 1 的准确率差异。
第四阶段:实验设计与验证分析
1. 主实验设计解读:核心论点的验证
核心论点:自发的思维转变(Spontaneous Shifts)通常是无效的,真正的“Aha!”极其罕见。
- 数据集:作者选择了三个截然不同的领域(数学、填字、华容道)。如果只测数学,可能只是数学推理的特性;加上填字游戏(语言双关)和华容道(纯逻辑规划),覆盖了语义、符号和空间推理,证明了结论的普适性。
- 评价指标:Normalized Exact Match(归一化精确匹配)。推理题通常有标准答案,精确匹配是最客观的。
- 基线与对照:对照组是有 Shift 的轨迹 vs. 没有 Shift 的轨迹。
- 实验结果:在统计学上,包含 Shift 的轨迹准确率显著低于没有 Shift 的轨迹。例如在 Qwen2.5-1.5B 上,Shift 组准确率 2.57%,非 Shift 组 16.44%。
- 结论:这直接打脸了“模型通过自我反思变聪明”的直觉。模型只有在“搞砸了”或者“乱套了”的时候才会频繁 Shift。
2. 消融实验分析:内部组件的贡献
作者重点对**检测器(Detector)**进行了消融分析。
- 消融对象:Shift 的检测标准。
- 变体 1(仅词汇):只要出现 “Wait” 就算 Shift。
- 变体 2(GPT-4o 裁判):不仅有词,还得有实质改动(本文主要方法)。
- 变体 3(严格的形式化 Aha):不仅有改动,还要满足三个统计阈值。
- 实验结果:无论用哪种检测标准,Shift 的发生率都很低(小于7%),且对准确率的贡献大多是负面的。
- 论证作用:这证明了结论的鲁棒性。不是作者定义的“Aha”太苛刻导致找不到,而是无论怎么放宽标准,这种“自发纠错”带来的正面收益都微乎其微。
3. 深度/创新性实验剖析:熵控制的干预(Triggered Reconsideration)
这是论文最精彩的探究性实验,它回答了“如果模型不会自己顿悟,我们要怎么帮它?”
- 实验目的:探究能否利用“不确定性(Entropy)”作为信号,人为触发有效的反思。
- 实验设计:将问题根据模型第一次回答时的熵分为“高熵组”(困惑)和“低熵组”(自信)。操作是对两组都强制插入“Wait…”进行重生成。
- 可视化/数据分析:
- 结果显示,在低熵组(模型很自信时),强制它反思反而会把对的改成错的(有害)。
- 在高熵组(模型很困惑时),强制它反思能显著提升准确率(MATH-500 上提升了 8.41%)。
- 实验结论:这一点非常深刻:模型本身缺乏“元认知”(Metacognition)。它在困惑时(高熵)并不会自发地去反思(Shift 频率没有随熵增加而增加);但如果我们作为外部观察者,在监测到它困惑时推它一把(强制反思),就能激发出它的潜在能力。这揭示了当前的推理模型虽然有能力纠错,但缺乏启动纠错的内驱力机制。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
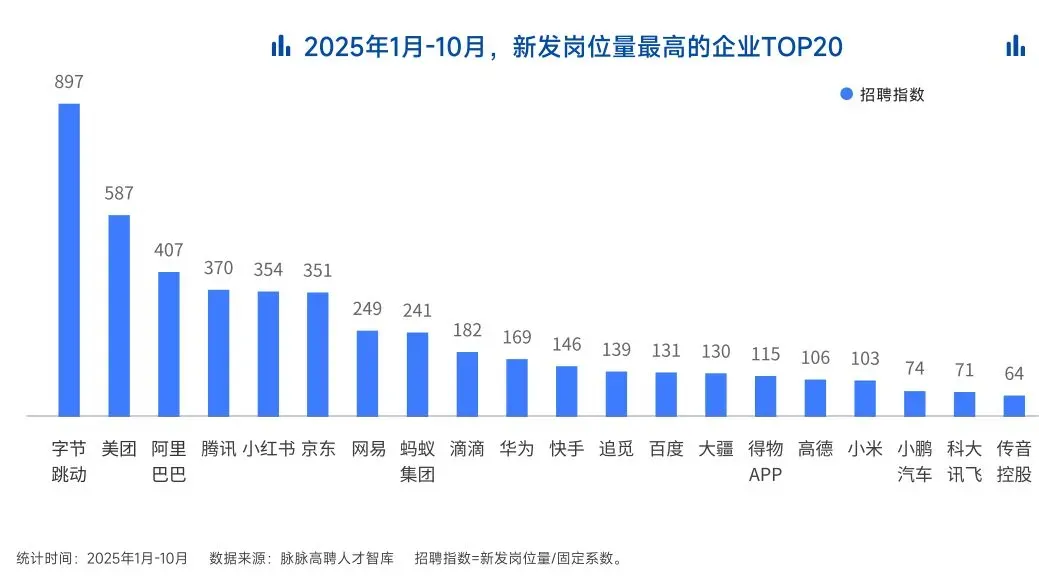
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献424条内容
已为社区贡献424条内容

所有评论(0)