突破显存极限!大模型优化秘籍:让你的72B模型在8卡80G上运行!
文章详细介绍了大模型显存的组成、优化意义及9种实用优化方法,包括算子融合、避免tensor拷贝、混合精度训练、激活优化等。作者通过实践,成功使72B模型在8卡80G显存上高效运行,与多卡训练的模型实用率相当。这些技巧对解决大模型训练中的显存瓶颈具有重要参考价值,特别适合显卡资源有限的研究者和团队。
一、大模型显存消耗
模型本身, 包括 weight,gradient,opt states(m & v & master weight),bf16 的话,三者比例为(1:1:6)。
DAG(计算图):很多人称之为激活,需要通过前向计算把计算图激活存储到显存中,以便实现自动求导。
临时栈变量:所有 op 的输入、输出以及中间 buffer,后续未用到,离开函数作用域被 python gc 回收,free 给 pytorch allocator。
二、优化显存的意义
使用更少的显卡来跑单个 dp,特别在团队显卡不足的情况下:
灵活配置 tp/pp/cp 策略,如果显存足够,可以减少 tp size,减少 allreduce 通信;
减少 pp,同样的 acc,可以减少 bubble;可以不采用 cp,cp 其实会把 weight copy 一份,显卡资源会 double;
减少 recompute layers,增加 mb size,如果计算 core 没有被打满的情况,且同时访存/通信不变(zero3),能很大程度提升 MFU。总之,好处多多。
三、大模型的显存优化办法
个人实践总结,总结如下:
(1)算子融合
减少中间变量和访存,譬如 lm head + cross entrophy loss,针对 vocab 特别大的 case 有用切必须,因为是执行一次,所以用 triton 即可,还有 RMSNorm 等。
(2)避免 tensor 拷贝
比如 reshape(非 contingous tensor 会 copy 一份)会产生拷贝,可以 permute,尽量用 inplace operator,譬如 div_(等)。
(3)混合精度训练
bf16,譬如 deepseek v3 用了 fp8,但是 fp8 一般人玩不了。
(4)pipeline 不均衡
对于 pp 模式,前面 stage、最后一个 stage 显存消耗多,需要自定义 pp layers 的分配。
(5)碎片优化
经常会发现 oom 的时候,reserved 显存远大于 allocated,就说明 allocator 碎片很严重,优先解决办法是要把大显存削掉。
大 tensor 诊断及削减:是否能分 chunk,或者靠 tp/cp 切 dag(megatron最大的价值),避免大的连续 tensor 申请,大的 tensor 会造成 allocator 严重碎片,这个问题难点,怎么找出框架/模型哪里的代码产生大的 tensor?
跨 stream block 复用:不同 stream block 复用,但会引发延迟释放,譬如 fsdp allgahter 会引发的显存放大,解决办法上层自己设置 event 来管理 block 的生命周期。
(6)激活优化
activation/gradient checkpoint,forward 期间不构建 dag,backward 多做一次 forward,把 dag 显存 size 收敛到单层,只需要存函数激活值,譬如 hidden states,是层数的整数倍;
对非计算密集型模块进行 recompute,前提你可以省很多显存,否则动不了,一动就 oom。
activation checkpoint offload:随着 seq/batch size 增加,hidden states 会非常大(1-2G),再乘以层数,size 可能有 100G,目前开源没有很好解决办法。
可以在前向时 d2h cpu memory,反向 h2d 到 gpu memory,可以把显存消耗到单层 dag,可以用新的 stream 来完成与计算 overlap。
但是这个很考验工程能力(据说快手玩过, 但是跟我思路不一样),特别 h2d/d2h 在 pagememory 下是阻塞(cuda 的坑),要用 pin memory,还 cpu memory 分配过程也很昂贵,同时 backward h2d overlap 可以跨层预取;
ac offload 做完之后就可以对 layer 分段 checkpoint,譬如 attention,mlp,把显存消耗收敛到更小的 block;
甚至使用 tensor offload,成本很高,基本不怎么用。
(7)优化器状态
优化器状态可以 chunk 为单位放 cpu,然后在 cpu 用 simd 去 update,最早见微信的 Patrick Star 实现;
(8)模型参数
模型 param 以 chunk 为单位进行 offload,我觉得价值不大,collosal ai 有做,因为卡数稍为多点,就可以 sharding 的。
(9)pytorch allocator
重写 pytorch allocator,这个实现很原始,造成碎片很严重,写的很糙,特别遇到很大的 tensor 基本瘫痪。
遇到过 80G 显存用一半就 oom 的,譬如 bfc allocator,至少显存池 chunk 要组成双向链表,并且及时恢复连续块。
pytorch expandable segment allocator,通过 vm mapping/ummap 来减小碎片影响,有效果但是有限,注意 gc 影响,莫名其妙变慢了,就改注意了。
笔者实践过后,72B 模型用 megatron 全量微调,8 卡 80G 显存就能训起来,而且跟 16/32 卡 MFU 无差别,只需要 weight/gradient 放得下即可,运行时显存开销只需要几 G。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
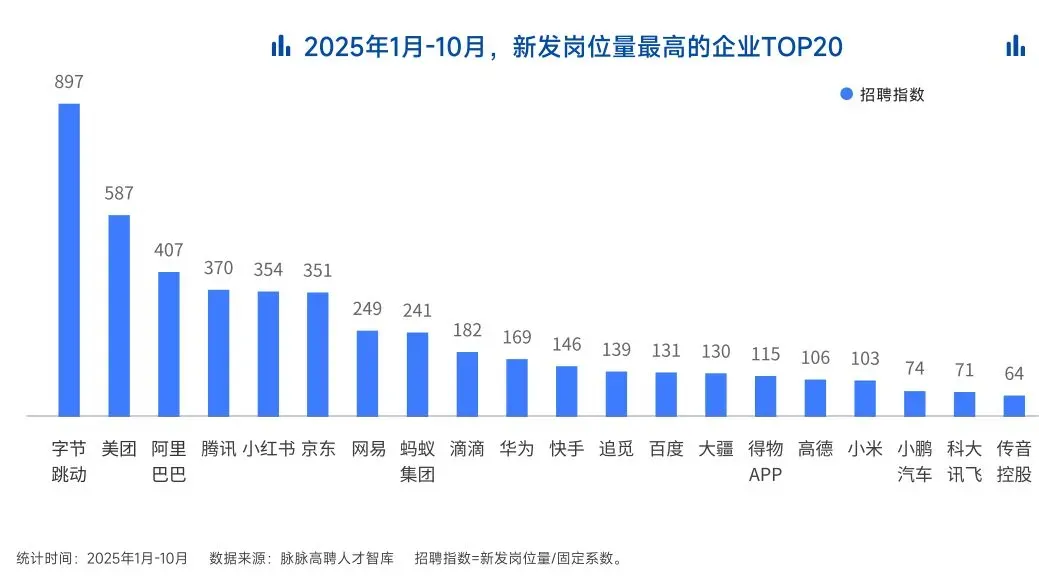
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献442条内容
已为社区贡献442条内容

所有评论(0)