大模型参数高效微调PEFT
本文全面详细讲述了大模型PEFT的发展路线、主要算法的原理,并基于Hugging Face库实现了通用大模型的LoRA微调流程。
当你需要微调开源大模型为自己所用,如调教出自己的对话模板,你需要进行全量SFT;或者给基座模型注入垂直领域的知识,你可能需要进行Continual Pre-training(CPT, 增量预训练),说白了就是找垂直领域的语料继续预训练。
然而上述这些操作需要将模型所有的参数加载进来,训练学习模型所有的参数。如果预训练可以完成,那么全量SFT也一定能够完成。然而,动辄几个B、几十个B、几百个B的参数量的大模型,是需要几张A100、几个T的数据、几周或者几个月才能预训练出来的。预训练的过程中消耗显存的大头在模型及其优化器,这两个都放不进显存的话,即便是数据的Batch降至1,结果都会是OOM。
所以早没有那么庞大的计算资源的情况下,怎么微调这些开源的基座大模型呢?PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)方法就是实现这一幻想的。其核心思想是:冻结预训练模型的大部分参数,仅更新或添加极少量的参数,以达到接近全量微调的效果。一般添加的参数量不到大模型参数量的1%。
1 Adapter Tuning
2019年,Google的Houlsby N等人将Adapter引入NLP领域,《Parameter-Efficient Transfer Learning for NLP》论文中,在Transformer结构的层与层之间插入了新的Adapter模块:
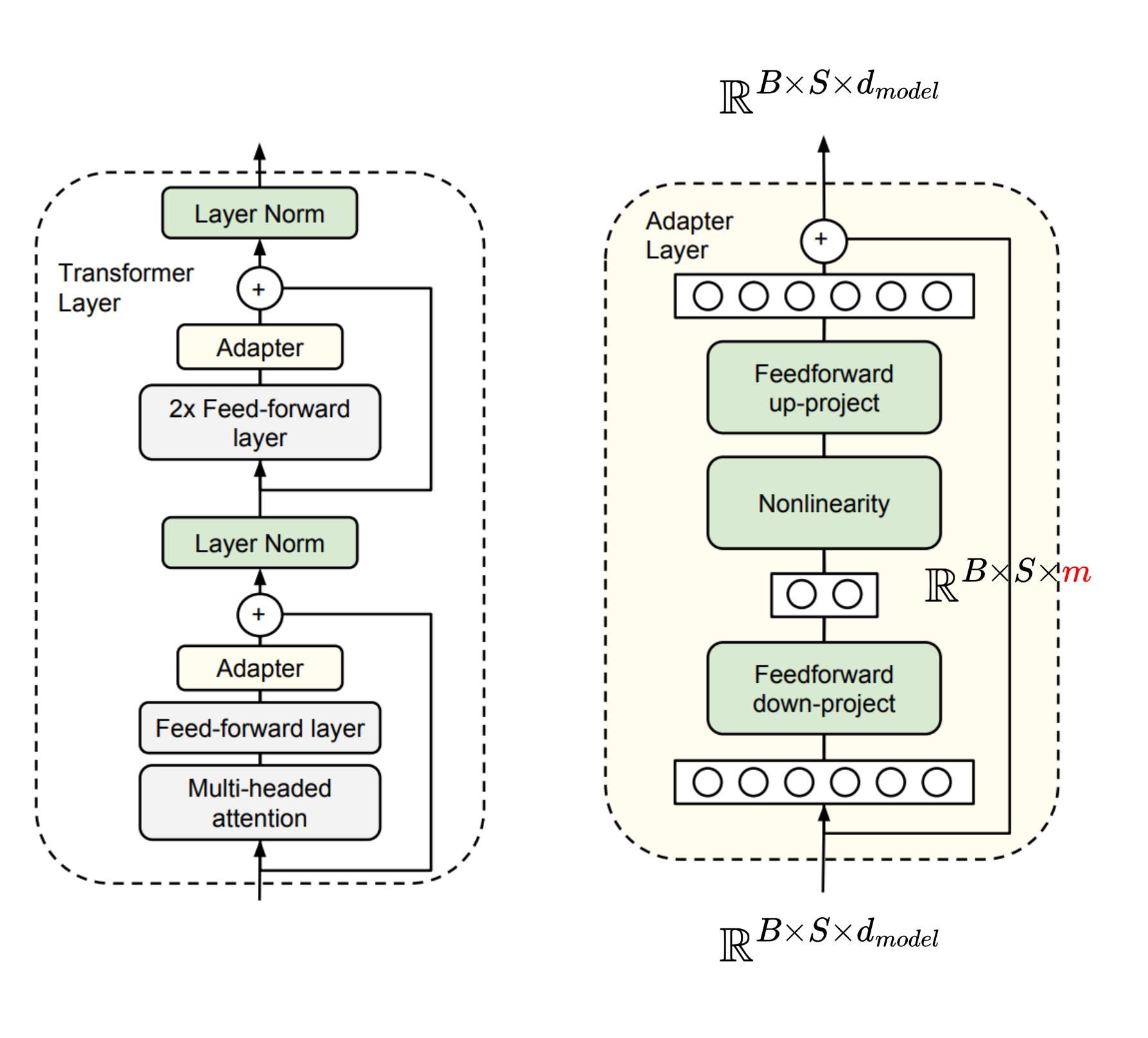
图中 B B B表示batch_size, S S S表示seq_len, d m o d e l d_{model} dmodel表示词嵌入维度(也可以叫做hidden_size等等)。Adapter Layer本质上就是一个下采样+上采样的过程,先将词嵌入层维度映射到低维度 m ( ≪ d m o d e l ) m\ (\ll d_{model}) m (≪dmodel),经过激活函数后再升维回 d m o d e l d_{model} dmodel,最后残差连接(skip connection),和FFN的过程是相反的(先升维,再降维)。
接下来是代码实现。我们首先定义一个Decoder-only框架的模型,它包含了Transformer的基本要素:
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d_model: int=768, n_heads: int=8, max_seq_len: int=1024):
super().__init__()
assert d_model % n_heads == 0
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.c_attn = nn.Linear(d_model, 3 * d_model, bias=False)
self.proj = nn.Linear(d_model, d_model, bias=False)
self.register_buffer("mask", torch.tril(torch.ones(max_seq_len, max_seq_len)).view(1, 1, max_seq_len, max_seq_len))
def forward(self, x):
B, S, d_model = x.shape
qkv = self.c_attn(x)
q, k, v = qkv.split(d_model, dim=2)
q = q.view(B, S, self.n_heads, self.head_dim).transpose(1, 2)
k = k.view(B, S, self.n_heads, self.head_dim).transpose(1, 2)
v = v.view(B, S, self.n_heads, self.head_dim).transpose(1, 2)
attn = (q @ k.transpose(-2, -1)) * (1.0 / (self.head_dim ** 0.5))
total_len = k.size(2)
curr_len = q.size(2)
mask = self.mask[:, :, total_len - curr_len : total_len, :total_len]
attn = attn.masked_fill(mask==0, float('-inf'))
attn = F.softmax(attn, dim=-1)
y = attn @ v
y = y.transpose(1, 2).contiguous().view(x.shape)
y = self.proj(y)
return y
class MLP(nn.Module):
def __init__(self, d_model: int):
super().__init__()
self.fc = nn.Linear(d_model, 4 * d_model)
self.proj = nn.Linear(4 * d_model, d_model)
self.act = nn.GELU()
def forward(self, x):
return self.proj(self.act(self.fc(x)))
class Block(nn.Module):
def __init__(self, d_model: int, n_heads: int, max_seq_len: int):
super().__init__()
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
self.attn = CausalSelfAttention(d_model, n_heads, max_seq_len)
self.mlp = MLP(d_model)
def forward(self, x):
attn_out = self.attn(self.ln1(x))
x = x + attn_out
x = x + self.mlp(self.ln2(x))
return x
class SimpleGPT(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, n_layers, max_seq_len: int=1024):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.pos_embedding = nn.Embedding(max_seq_len, d_model)
self.layers = nn.ModuleList([Block(d_model, n_heads, max_seq_len) for _ in range(n_layers)])
self.ln = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, vocab_size, bias=False)
def forward(self, input_ids):
B, S = input_ids.size()
pos = torch.arange(0, S, dtype=torch.long, device=input_ids.device)
x = self.token_embedding(input_ids) + self.pos_embedding(pos)
x = self.ln(x)
logits = self.head(x)
return logits
我们要微调的模型在绝大多数情况下不是像上面那样把结构清晰地罗列出来的,而都是包装在一个pt或者pth类型的参数文件中(惯例使用.pth、.pt或.ckpt作为后缀,它们本质上没有区别),那么情况2就是一般情况,即获取不到定义模型的代码。
import torch
########## 情况1 仅保存权重
torch.save(model.state_dict(), 'model_weights.pth')
# 加载
model = SimpleGPT()
state_dict = torch.load('model_weights.pth', weights_only=True)
model.load_state_dict(state_dict)
########## 情况2 权重+结构:使用pickle模块将模型对象序列化
torch.save(model, 'model_complete.pth')
model = torch.load('model_complete.pth')
接下来要替换的就是模型中的attention层和FFN层,替换为attention+adapter或者FFN+adapter模块,也就是如下代码中所展示的AdapterWrapper模块:
class Adapter(nn.Module):
def __init__(self, input_dim: int, bottleneck_dim: int):
super().__init__()
self.down_proj = nn.Linear(input_dim, bottleneck_dim, bias=False)
self.non_linear = nn.ReLU()
self.up_proj = nn.Linear(bottleneck_dim, input_dim, bias=False)
# 将up_proj初始化为0,保证初始状态是恒等映射
nn.init.zeros_(self.up_proj.weight)
# nn.init.zeros_(self.up_proj.bias)
def forward(self, x):
residual = x
out = self.down_proj(x)
out = self.non_linear(out)
out = self.up_proj(out)
return out + residual
class AdapterWrapper(nn.Module):
def __init__(self, original_layer, bottleneck_dim: int):
super().__init__()
self.original_layer = original_layer
self.adapter = Adapter(original_layer.out_features, bottleneck_dim)
def forward(self, *args, **kwargs):
# 经过原有层Attention或FFN
output = self.original_layer(*args, **kwargs)
# 如果输出是元组则处理第一个元素
if isinstance(output, tuple):
hidden_states = output[0]
hidden_states = self.adapter(hidden_states)
return (hidden_states,) + output[1:]
return self.adapter(output)
先构造一个model,假设下面的model就是通过torch.load或者AutoModel.from_pretrained加载进来的模型,如果不清楚模型的每一层结构,可以首先查看模型的每一层的名字:
def test():
vocab_size = 1000
d_model = 256
n_heads = 4
n_layers = 1
model = SimpleGPT(vocab_size, d_model, n_heads, n_layers)
for name, sub_module in model.named_modules():
print(name, end="\t")
print(type(sub_module))
""" 输出结果
<class '__main__.SimpleGPT'>
token_embedding <class 'torch.nn.modules.sparse.Embedding'>
pos_embedding <class 'torch.nn.modules.sparse.Embedding'>
layers <class 'torch.nn.modules.container.ModuleList'>
layers.0 <class '__main__.Block'>
layers.0.ln1 <class 'torch.nn.modules.normalization.LayerNorm'>
layers.0.ln2 <class 'torch.nn.modules.normalization.LayerNorm'>
layers.0.attn <class '__main__.CausalSelfAttention'>
layers.0.attn.c_attn <class 'torch.nn.modules.linear.Linear'>
layers.0.attn.proj <class 'torch.nn.modules.linear.Linear'>
layers.0.mlp <class '__main__.MLP'>
layers.0.mlp.fc <class 'torch.nn.modules.linear.Linear'>
layers.0.mlp.proj <class 'torch.nn.modules.linear.Linear'>
layers.0.mlp.act <class 'torch.nn.modules.activation.GELU'>
ln <class 'torch.nn.modules.normalization.LayerNorm'>
head <class 'torch.nn.modules.linear.Linear'>
"""
根据每一层模块的名字,找到attn和ffn的最后一层输出:layers.0.attn.proj和layers.0.mlp.proj。将其替换为AdapterWrapper即可:
def inject_adapters(model, bottleneck_dim=64):
# freeze
for param in model.parameters():
param.requires_grad = False
modules_to_replace = []
for name, module in model.named_modules():
# 替换所有的注意力投影层和MLP投影层的最后一层输出
if name.endswith('.attn.proj') or name.endswith('.mlp.proj'):
modules_to_replace.append((name, module))
for name, old_module in modules_to_replace:
# 拆分: layers.0.attn.proj -> layers.0.attn 和 proj
name_parts = name.split('.')
parent_name = '.'.join(name_parts[:-1])
child_name = name_parts[-1]
parent_module = model.get_submodule(parent_name)
new_module = AdapterWrapper(old_module, bottleneck_dim)
# 替换父模块中的旧层
setattr(parent_module, child_name, new_module)
return model
def test():
vocab_size = 1000
d_model = 256
n_heads = 4
n_layers = 1
model = SimpleGPT(vocab_size, d_model, n_heads, n_layers)
before_params = sum(p.numel() for p in model.parameters())
model = inject_adapters(model)
after_params = sum(p.numel() for p in model.parameters())
print(f"参数量之差 {after_params - before_params}")
这种微调方法影响了后续微调的技术思想:添加可训练的参数模块,而大模型原来的参数保持不变。
然而缺点是Adapter Tuning使得模型的层数加深了,推理过程需要额外经过这些Adapter Layer,在追求极致推理的场景中不适用。
还有其它的Adapter变体就不赘述了,因为本文的目的不是写一篇综述:
- 《AdapterFusion:Non-Destructive Task Composition for Transfer Learning》
- 《AdapterDrop: On the Efficiency of Adapters in Transformers》
2 从提示词角度微调
生成式模型专注于zero-shot和few-shot任务,进行下游任务的时候,在不微调的情况下,通过设置提示词模板也能应用到下游任务。如原始序列样本:这家店的服务态度太差了,再也不来了。
▲ 构造prompt模板:请分析以下评论的情感。 评论:这家店的服务态度太差了,再也不来了。情感:[MASK]
通过训练预测[MASK],完成文本情感分类任务。而BERT系列模型只需要映射到固定的分类空间中,预测一个[CLS]。
上面构造的提示词模板本质上就是指令微调,你可能会发现和全量指令微调中讲的有所区别。这是因为Prompt Tuning是2021年的研究产物,那个时候还是以BERT模型系列为基准,自然语言的下游任务划分比较明确,不像现在都被生成式模型给干掉、指令微调成为范式。因此这里仍旧拿以前的例子作说明。
像GPT这样的生成式大模型擅长写句子,并不是理解文本,而BERT擅长理解文本。通常来说,模型的参数量决定了一个模型的能力上限,相同参数量的情况下,GPT的理解能力却比BERT弱,那么是不是应该通过在提示词的角度激发GPT的理解文本的能力(论文《GPT Understands, Too》的想法)?
2.1 Prompt Tuning
根据上述思想,仅在输入层(Embedding层,layer 0),经过词嵌入的序列(大小为 R B × S × d m o d e l \mathbb{R}^{B\times S\times d_{model}} RB×S×dmodel)前面拼接一个提示词,设置prompt_tuning_init_text就能够通过微调适配不同的下游任务(下面的代码直接调用Hugging Face的peft库来实现的,可以作为微调的模板得到包装好的模型,只需要改动微调配置即可):
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 冻结原始模型参数, 但get_peft_model会自动完成
# for param in model.parameters():
# param.requires_grad = False
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=8, # 前缀长度
# 相当于添加的指令
prompt_tuning_init=PromptTuningInit.TEXT,
prompt_tuning_init_text="Classify if this is positive or negative:",
tokenizer_name_or_path=model_name,
)
# 包装模型
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
但是这种原始的方式可扩展性太弱了,不同的分类任务要设置不同的提示词模板。因为人工写的prompt(上述例子中的红色部分,P-Tuning v1论文中所指的Discrete Prompts / Hard Prompts,是不可训练的、固定的文本)终究要嵌入到词向量中,还不如让机器直接学习一种最优的prompt embedding(soft prompt / pseudo tokens)拼接到输入的prompt embedding的前面,替代人工写的prompt,这种prompt并不需要通过tokenizer转换成人类能够看懂的句子,大模型能够理解这种特征就行。
- Prompt Tuning:这种思想就是Google所提出的微调方法(《The Power of Scale for Parameter-Efficient Prompt Tuning》),只在输入序列的最前面添加一组可学习的Embedding向量。
- 其他方法,如《PPT: Pre-trained Prompt Tuning for Few-shot Learning》,略
- P-Tuning v1:《GPT Understands, Too》
- 用LSTM或MLP生成Prompt Embedding(重参数化,见2.2中的解释)。
- ❓ 存疑:保留了Discrete Prompts的结构,但把其中的部分或全部词替换成pseudo tokens。通过LSTM或者其它的网络生成这些pseudo tokens的Embedding向量,而被保留下的token(怎么选❓)仍经过预训练的
nn.Embedding映射为词嵌入向量。微调只需要调整LSTM或MLP的参数即可。
peft_config = PromptEncoderConfig(
task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=20,
# P-Tuning v1使用一个额外的编码器网络来生成Prompt向量: LSTM / MLP
encoder_reparameterization_type="MLP",
# MLP/LSTM 的隐藏层维度
encoder_hidden_size=128,
)
- P-Tuning v2(Deep Prompt Tuning):《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》。ChatGLM的官方微调代码默认就叫P-Tuning v2。
- P-Tuning v1只在第一层加,难以穿透模型的深层将信息传递过去。因此参考Prefix Tuning,每一层的输入都添加。不过论文倾向于直接训练参数(soft prompt的词嵌入向量),而不进行重参数化,这是因为在NLU任务上,作者发现重参数化的效果并不稳定,有时甚至更差。
- ❓ 存疑:和Prefix Tuning差不多,都是将soft prompt加到 K , V \boldsymbol K, \boldsymbol V K,V上。网上也有说加到每一层的Input Embedding上,看原论文的示意图也是这个意思。但是Input Embedding经过Q、K、V线性映射相当于直接加到这些矩阵 K , V \boldsymbol K, \boldsymbol V K,V上了,而加到 Q \boldsymbol Q Q上没用,因此本质上跟Prefix Tuning没多大差别(库的实现上也差不多?)。
peft_config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
# P-Tuning v2通常需要更长的Prompt
num_virtual_tokens=64,
prefix_projection=False,
)
2.2 Prefix Tuning
2021年《Prefix-Tuning: Optimizing Continuous Prompts for Generation》提出了一种PEFT方法,其核心思想是:保持预训练大模型的所有参数冻结,只在每一层Transformer的Attention机制中,在 K \boldsymbol K K和 V \boldsymbol V V向量前拼接(Prepend)一组可学习的连续向量(Continuous Vectors),这些向量被称为Prefix。相当于在每层都加了软提示(Soft Prompt),但和普通的Prompt Tuning不同:Prompt Tuning只在Embedding层添加Prefix,而Prefix Tuning是在每一个Transformer层添加。具体的做法是对每一层的 K \boldsymbol K K和 V \boldsymbol V V添加一组参数矩阵 P K , P V \boldsymbol{P_K}, \boldsymbol{P_V} PK,PV:
K n e w = concat ( P K , K ) , V n e w = concat ( P V , V ) . \boldsymbol{K}_{new}=\text{concat}(\boldsymbol{P_K},\boldsymbol K), \boldsymbol{V}_{new}=\text{concat}(\boldsymbol{P_V},\boldsymbol V). Knew=concat(PK,K),Vnew=concat(PV,V).
优化技巧:Reparameterization Trick,重参数化。论文中指出直接优化这些前缀向量参数往往不稳定,因此作者引入了一个MLP来生成这些前缀。具体来说就是输入input_ids通过一个小的Embedding层,nn.Embedding(self.num_virtual_tokens, self.hidden_size),num_virtual_tokens是虚拟token个数,即前缀的长度。然后再经过一个MLP层,输出Prefix向量,最后拼接到Attention中。
可以使用HF的peft库来实现:
peft_config = PrefixTuningConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False, # 训练模式而非推理模式
num_virtual_tokens=20,
prefix_projection=True, # 是否使用MLP重参数化
encoder_hidden_size=512 # MLP中间层的维度
)
不使用peft库实现的话,还是要利用Hugging Face的标准配置属性past_key_values注入虚假的历史记忆完成拼接(在seq_len这个维度,一般来说只要past_key_values不是None就会进行这个操作),只需要根据算法构造并注入即可。当然,从零手动实现还得考虑后续的推理,比如generate等。
大多数的开源大模型都是基于Hugging Face标准的,所以不如直接用HF的peft库。
Prefix Tuning论文侧重于生成任务(NLG);P-Tuning v2证明了这种结构在理解任务(NLU,如分类)上对小模型也极其有效。
3 👑LoRA
Low-Rank Adaptation《LoRA: Low-Rank Adaptation of Large Language Models》,工业界基本上都用这个微调技术来微调基座模型,这也是本文的主要内容。下面将从原理和实战展开。LoRA 是目前最主流的方法,它完美解决了Adapter的推理延迟问题,同时比P-Tuning更稳定。
首先来看它是怎么做的:假设模型预训练的权重矩阵为 W 0 ∈ R d × k \boldsymbol W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,这个 W 0 \boldsymbol W_0 W0可以是 W Q , W K , W V , W O \boldsymbol W^Q, \boldsymbol W^K, \boldsymbol W^V, \boldsymbol W^O WQ,WK,WV,WO,也可以是FFN层的参数矩阵,总之是具有较大参数量的线性层,可以通过target_modules来指定要更新的模块。不直接修改 W 0 \boldsymbol W_0 W0,而是引入两个更小的矩阵 A ∈ R d × r , B ∈ R r × k \boldsymbol A\in\mathbb{R}^{d\times r}, \boldsymbol B\in\mathbb{R}^{r\times k} A∈Rd×r,B∈Rr×k,且 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k), Δ W = A B \Delta \boldsymbol W=\boldsymbol A\boldsymbol B ΔW=AB。通过学习 A , B \boldsymbol A, \boldsymbol B A,B来得到新的权重矩阵
W = W 0 + Δ W ⋅ α , \boldsymbol W=\boldsymbol W_0+\Delta \boldsymbol W \cdot \alpha, W=W0+ΔW⋅α,
其中 α \alpha α是缩放因子,LoraConfig中的lora_alpha字段。上述的操作全都建立在一个假设之上:模型参数的变化量 Δ W \Delta \boldsymbol W ΔW存在一个低秩的内在维度。实际上,这个假设在2020年的《Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning》这篇论文中有所研究:预训练大模型具有极低的Intrinsic Dimension,这意味着大模型虽然参数巨大,但在这个庞大的参数空间中,解决特定任务所需的有效解其实分布在一个很小的子空间里。
其实微调的本质都是一样的,在原有的模型基础上,冻结所有的参数,自己另外定义一组参数模块,通过训练自定义的参数模块,添加到原有的大模型上。
方法改进
- QLoRA:量化加载,让更大的模型也能放进显存
- 作者采用一种专门针对正态分布权重优化的数据类型NF4(4-bit NormalFloat)对参数量化加载,比普通的FP4或Int4精度更高。Double Quantization:同时对量化所需的常数也进行量化,进一步节省显存。
- 分页优化器(Paged Optimizer):利用CPU内存来处理训练过程中的显存尖峰,就像虚拟内存那样管理
- 计算精度为BF16/FP16,存储权重的时候才压缩为4-bit
- LoRA+:调整 B \boldsymbol B B的学习率比 A \boldsymbol A A的学习率更大,通常大16倍。
- DoRA(Weight-Decomposed Low-Rank Adaptation):借鉴了Weight Normalization的思想。此处略过,不是本文的重点。
代码实践:微调和推理
下面就写一个LoRA配置代码,作为微调以及推理的模板:
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from datasets import load_dataset
import os
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
# 如果使用Llama系列模型,需要先登录Hugging Face Hub:
# from huggingface_hub import login
# login("YOUR_HF_TOKEN")
print(f"加载模型: {model_name}")
# QLoRA
# 4-bit量化加载模型以节省显存,不过必须下载bitsandbytes和accelerate包
# pip install bitsandbytes accelerate
# bnb_config = BitsAndBytesConfig(
# load_in_4bit=True,
# bnb_4bit_use_double_quant=True,
# bnb_4bit_quant_type="nf4",
# bnb_4bit_compute_dtype=torch.bfloat16 # 或torch.float16,取决于GPU类型
# )
model = AutoModelForCausalLM.from_pretrained(
model_name,
# quantization_config=bnb_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Llama系列分词器可能没有pad_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
lora_config = LoraConfig(
r=16,
lora_alpha=32, # 缩放因子,通常是r的2倍
lora_dropout=0.05,
bias="none", # "none", "all", "lora_only"
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM"
)
# 如果上面配置了量化
# model = prepare_model_for_kbit_training(model)
# 包装模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 8,798,208 || all params: 502,830,976 || trainable%: 1.7497
print("Loading and preparing dataset...")
# dataset = load_dataset("tatsu-lab/alpaca", split="train")
# 下面是简单的微调演示,数据集就随便搞一搞
from datasets import Dataset
data = {
'text': [
"### Human: Write a short story about a brave knight. ### Assistant: Sir Reginald was a knight of renown, known for his courage and unwavering loyalty...",
"### Human: Explain the concept of recursion. ### Assistant: Recursion is a method of solving a problem where the solution depends on smaller instances of the same problem.",
"### Human: What is the capital of France? ### Assistant: The capital of France is Paris.",
"### Human: Create a Python function to reverse a string. ### Assistant: ```python\ndef reverse_string(s):\n return s[::-1]\n```"
]
}
dataset = Dataset.from_dict(data)
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, max_length=512, padding="max_length")
tokenized_dataset = dataset.map(preprocess_function, batched=True)
tokenized_dataset = tokenized_dataset.remove_columns(["text"]) # 移除原始文本列
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
output_dir = "/kaggle/working/"
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=10,
save_steps=100,
fp16=True, # 如果GPU支持,使用fp16可以加速训练并减少显存
# bf16=True, # 如果GPU支持bfloat16 (Ampere及以上),效果可能更好
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="constant", # cosine
report_to="none" # 避免发送日志到外部服务
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
# eval_dataset=tokenized_dataset_val,
data_collator=data_collator,
)
print("🔥 开始LoRA微调")
trainer.train()
# adapter_model.safetensors
print(f"保存LoRA adapter权重到 {output_dir}")
model.save_pretrained(output_dir)
# tokenizer.save_pretrained(output_dir)
print("✅ 完成LoRA微调")
训练完成后,可以看到下次加载所需要的adapter_config和adapter_model两个文件。如果需要继续预训练,则可以加载checkpoint-X文件夹下的缓存。⚠ 至于如何加载checkpoint,这里懒得写了。


请注意,构造的模板建议使用大模型自带的,不要像代码中的例子那样新造模板,这里是为了快速演示。如果想要应用大模型分词器中的chat template,最好是使用trl库中的SFTTrainer,这个库可以自动完成Loss Masking和Padding以及短序列拼接,不需要手动处理。
from datasets import Dataset
from trl import SFTTrainer
# alpaca格式的数据
raw_data = [
{"instruction": "", "input": "", "output": ""},
]
def process_func(example):
"""
将 instruction/input/output 转换为 Qwen 的 Chat 模板格式
"""
# 构造Messages列表 (标准OpenAI格式)
# Qwen支持system prompt,可以在这里加一个默认的
messages = [
{"role": "system", "content": "你是一个有用的助手。"},
{
"role": "user",
"content": f"{example['instruction']}\n{example['input']}" if example['input'] else example['instruction']
},
{"role": "assistant", "content": example['output']}
]
# tokenize=False: 先变成字符串,再交给SFTTrainer去做分词
# add_generation_prompt=False表示这是训练数据,包含完整的对话,不需要模型接着写
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
return {"text": text}
# 创建数据集并映射处理
dataset = Dataset.from_list(raw_data)
dataset = dataset.map(process_func)
# 后面就是初始化训练配置TrainingArguments和实例化训练器SFTTrainer
trainer = SFTTrainer(...)
trainer.train()
为什么不写完整:上一篇文章讲过,而且kaggle上没有trl这个库,无法验证训练的正确性(主要是我本地电脑配置太拉垮了) 。如果用transformers的Trainer来实现,可以参考我的上一篇博客《大模型全量指令微调——Full Parameter SFT》手动构造数据集实现Loss Masking和Padding,然后像上上块的代码传入训练器,或者自己写一个训练循环即可(后续会完善)。
接着运用大模型自带的模板进行推理时的数据集构造:
messages = [
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": f"{instruction}\n{input_text}"}
]
# add_generation_prompt=True会自动添加<|im_start|>assistant
prompt_str = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(prompt_str, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=128,
temperature=0.1,
do_sample=False
)
加载训练好的 Δ W \Delta\boldsymbol W ΔW进行推理,有两种方法:
- 动态挂载:加载底座模型,再把LoRA权重挂上去。这种方式不需要修改底座模型文件。
- 权重合并:使用
model.merge_and_unload()将LoRA权重彻底融入到底座模型中,导出一个新的完整模型,新的模型再使用AutoModelForCausalLM.from_pretrained(新模型的路径)加载即可。这样推理速度更快,且不再依赖peft库。一般部署的时候这样做。
from peft import PeftModel, PeftConfig
# 和预训练一样加载基座模型base_model后
adapter_path = "..."
model = PeftModel.from_pretrained(base_model, adapter_path)
# 将\Delta W嵌入到基座模型中,保存后下次直接加载合并的大模型,不再需要PeftModel
# model = model.merge_and_unload()
model.eval()
prompt = "### Human: Write a short story about a space explorer. ### Assistant:"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=100,
num_beams=1, # beam search
do_sample=True, # temperature, top_k, top_p
temperature=0.7,
top_k=50,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
零代码平台
-
LLaMA-Factory
-
Hugging Face AutoTrain
-
阿里云百炼,集成千问系列
只需要点点点就能完成训练,这里就不必细讲了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)