JAVA中的Map集合,零基础入门到精通,收藏这篇就够了
Map 是 Java 中一种非常重要的集合类型,用于存储键值对(key-value pairs)。它的常见实现类包括 HashMap、TreeMap、LinkedHashMap 等,主要区别在于它们对键值对的存储和顺序管理方式。添加一个键值对到 Map 中,键已存在则更新对应的值。map.put("手表", 100);map.put("手表", 220);// 更新"手表"的值map.put("手
文章目录
- 前言
- 一、Map集合常用方法
- 二、方法详细介绍
-
- 1. put(K key, V value)
- 2.size()
- 3. clear()
- 4. isEmpty()
- 5. get(Object key)
- 6. remove(Object key)
- 7. containsKey(Object key)
- 8. containsValue(Object value)
- 9. keySet()
- 10. values()
- (拓展)11. putAll(Map<? extends K, ? extends V> m)
- 三、实现类解释
-
- 1 .HashMap
- 2 LinkedHashMap
- 3. TreeMap
- 总结
前言
Map 是 Java 中一种非常重要的集合类型,用于存储键值对(key-value pairs)。它的常见实现类包括 HashMap、TreeMap、LinkedHashMap 等,主要区别在于它们对键值对的存储和顺序管理方式。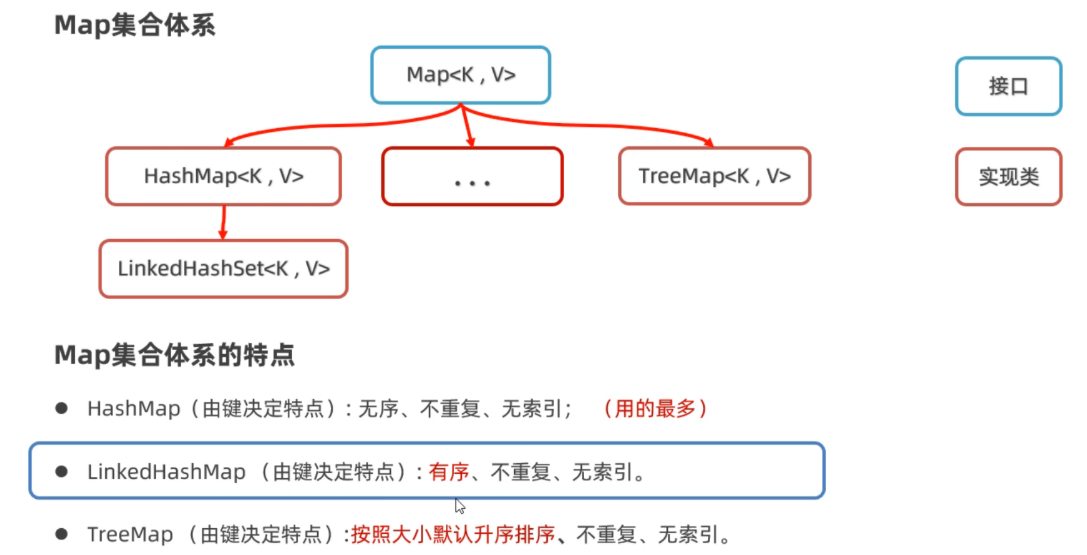
一、Map集合常用方法
由于Map是所有双列集合的父接口,所以我们只需要学习Map接口中每一个方法是什么含义,那么所有的Map集合方法你就都会用了。
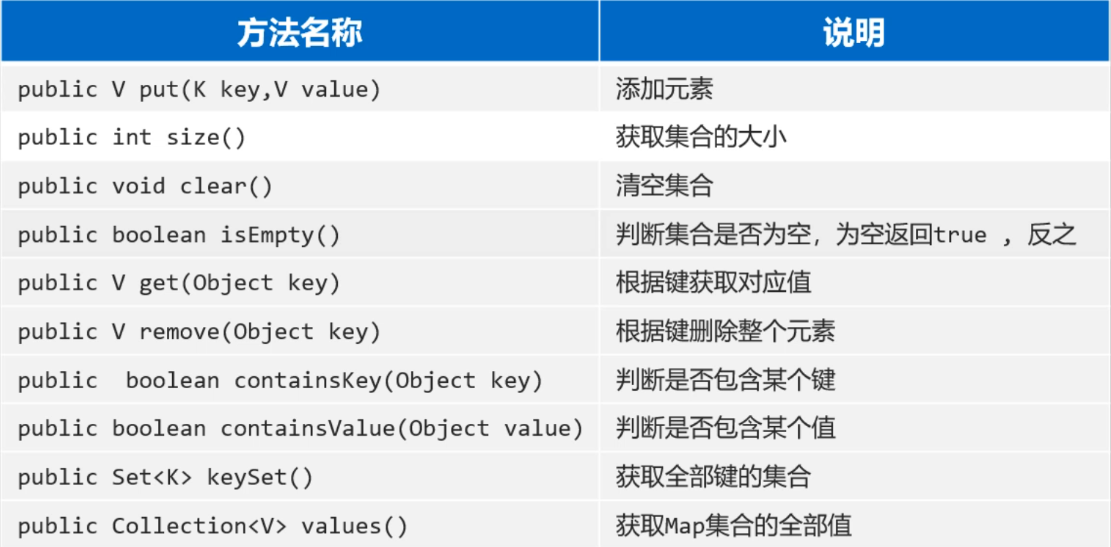
二、方法详细介绍
1. put(K key, V value)
添加一个键值对到 Map 中,键已存在则更新对应的值。
Map<String, Integer> map = new HashMap<>();
map.put("手表", 100);
map.put("手表", 220); // 更新"手表"的值
map.put("手机", 2);
System.out.println(map); // 输出: {手表=220, 手机=2}
2.size()
获取集合的大小
System.out.println(map.size()); // 输出: 2
3. clear()
清空集合
map.clear(); // 清空集合
System.out.println(map); // 输出: {}
4. isEmpty()
判断集合是否为空
System.out.println(map.isEmpty()); // 输出: true
5. get(Object key)
根据键获取对应的值
int v1 = map.get("手表"); // 获取"手表"的值
System.out.println(v1); // 输出: 220
System.out.println(map.get("手机")); // 输出: 2
System.out.println(map.get("张三")); // 输出: null
6. remove(Object key)
根据键删除键值对,并返回该键的值
System.out.println(map.remove("手表")); // 输出: 220
System.out.println(map); // 输出: {手机=2}
7. containsKey(Object key)
判断Map是否包含某个键
System.out.println(map.containsKey("手表")); // 输出: false
System.out.println(map.containsKey("手机")); // 输出: true
System.out.println(map.containsKey("java")); // 输出: false
System.out.println(map.containsKey("Java")); // 输出: false
8. containsValue(Object value)
判断Map是否包含某个值
System.out.println(map.containsValue(2)); // 输出: true
System.out.println(map.containsValue("2")); // 输出: false
9. keySet()
获取Map中所有键的集合
Set<String> keys = map.keySet();
System.out.println(keys); // 输出: [手机]
10. values()
获取Map中所有值的集合
Collection<Integer> values = map.values();
System.out.println(values); // 输出: [2]
(拓展)11. putAll(Map<? extends K, ? extends V> m)
将另一个Map的所有元素添加到当前Map
Map<String, Integer> map1 = new HashMap<>();
map1.put("java1", 10);
map1.put("java2", 20);
Map<String, Integer> map2 = new HashMap<>();
map2.put("java3", 10);
map2.put("java2", 222);
map1.putAll(map2); // 把map2的元素添加到map1中
System.out.println(map1); // 输出: {java1=10, java2=222, java3=10}
System.out.println(map2); // 输出: {java3=10, java2=222}
三、实现类解释
1 .HashMap
HashMap底层数据结构: 哈希表结构
JDK8之前的哈希表 = 数组+链表
JDK8之后的哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能相对都较好的数据结构
往HashMap集合中键值对数据时,底层步骤如下
第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组
第2步:把键然后将键和值封装成一个对象,叫做Entry对象
第3步:再根据Entry对象的键计算hashCode值(和值无关)
第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置
第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置
如果不为null,则还需要进行第6步的判断
第6步:继续调用equals方法判断两个对象键是否相同
如果equals返回false,则以链表的形式往下挂
如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。
HashMap底层需要注意这几点:
1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍
数组扩容的加载因子是0.75,意思是:16*0.75=12
2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储
JDK7版本:链表采用头插法(新元素往链表的头部添加)
JDK8版本:链表采用尾插法(新元素我那个链表的尾部添加)
3.数组的同一个索引位置有多个元素、并且超过了8个,则以红黑树形式存储
2 LinkedHashMap
LinkedHashMap的底层原理,和LinkedHashSet底层原理是一样的。底层多个一个双向链表来维护键的存储顺序。
public class Test2LinkedHashMap {
public static void main(String[] args) {
// Map<String, Integer> map = new HashMap<>(); // 按照键 无序,不重复,无索引。
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); // 按照键 有序,不重复,无索引。
map.put("手表", 100);
map.put("手表", 220);
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map);
}
}

3. TreeMap
-
TreeMap集合的特点也是由键决定的,默认按照键的升序排列,键不重复,也是无索引的
-
TreeMap集合的底层原理和TreeSet也是一样的,底层都是红黑树实现的。所以可以对键进行排序。
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
//无参数构造方法
public Student(){}
//全参数构造方法
public Student(String name, int age, double height){
this.name=name;
this.age=age;
this.height=height;
}
//...get、set、toString()方法自己补上..
//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。
/*
原理:
在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的
结果是正数、负数、还是零,决定元素放在后面、前面还是不存。
*/
@Override
public int compareTo(Student o) {
//this:表示将要添加进去的Student对象
//o: 表示集合中已有的Student对象
return this.age-o.age;
}
}
排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/**
* 目标:掌握TreeMap集合的使用。
*/
public class Test3TreeMap {
public static void main(String[] args) {
Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o1.getHeight(), o2.getHeight());
}
});
// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));
map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");
map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");
map.put(new Student("至尊宝", 23, 163.5), "水帘洞");
map.put(new Student("牛魔王", 28, 183.5), "牛头山");
System.out.println(map);
}
}
这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
总结
Map提供了丰富的功能来管理键值对。常见操作包括添加、查找、删除、检查、遍历等。不同的实现类(如HashMap、TreeMap、LinkedHashMap)在特性上有所不同,选择合适的实现类有助于提升程序的性能和可维护性。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献279条内容
已为社区贡献279条内容

所有评论(0)