大模型训练_week2_day11_《穷途末路》
碎碎念:976目标:本节手撕attention。做到能够默写以及默写标注# Transformer伪代码x = x +# 残差连接x = layer_norm(x)# 层归一化x = x + feed_forward(x)# 残差连接x = layer_norm(x)# 层归一化残差连接会让不同层的特征直接相加,若特征分布差异大,相加后数值会失真;LayerNorm 先归一化特征,让残差连接的数值
目录
问题 1:为什么self.w_q = nn.Linear(d_model, d_model)而不是nn.Linear(d_model, 64)?
问题 2:q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) 怎么理解?维度如何匹配?
(1)self.w_q(q)的本质:调用 nn.Linear 的前向传播
(2)维度匹配的核心:nn.Linear 只作用于 “最后一维”
问题 3:前向传播(forward)没手动调用,为什么会运行?
问题4:为什么没有写q=k=v=X 这个代码就默认实现了 B, T, D = q.shape #解析输入形状, B批量大小,T 序列长度, D 特征维度
问题5 为什么矩阵乘法后形状是(B, n_head, T, T)?
问题 6 为什么要做这个 x_output = self.w_o(x_concate) 处理
2. 保持模块接口一致性(Transformer 的核心设计原则)
问题 7:怎么理解在最后一维做softmax和在最后一维归一化。有没有数据例子给我直观看一下。 还有方差是1是什么概念、
数据例子(shape=(1,3,2),dim=-1,ϵ=1e−12,γ=1,β=0)
步骤 2:对每个子向量单独算 LayerNorm(分步计算)
前言
碎碎念:976。 为什么都说盲目自信是错的。藏控修惜
目标:本节手撕attention。做到能够默写以及默写标注
# Transformer伪代码
x = x + multi_head_attention(x,x,x) # 残差连接
x = layer_norm(x) # 层归一化
x = x + feed_forward(x) # 残差连接
x = layer_norm(x) # 层归一化
残差连接会让不同层的特征直接相加,若特征分布差异大,相加后数值会失真;LayerNorm 先归一化特征,让残差连接的数值更稳定,避免数值漂移。
手撕attention
全部手敲真爽啊!!!
import torch #导入pytorch核心库,提供张量操作,矩阵运算等功能
from torch import nn #导入神经网络模块,用于定义层和模型
import torch.nn.functional as F #pytorch提供的函数式接口集合,包含神经网络层,激活函数,损失函数,归一化,注意力
import math #导入数学库,用于计算平方根
X = torch.randn(16,64,512) #符合正态分布的随机张量. 16句话,64个token,词向量为512维
"""
16 batchsize,代表批量的大小,一次处理16个样本
64 sequence 代表序列的长度,即每个样本包含64个token,简单说就是一句话有64个词
512 d_model 模型的维度,就是每个token的词向量维度
"""
print(X.shape)
d_model = 512 #模型的总维度,与x的最后一维一致
n_head = 8 #注意力头,要求d_model 能被n_head整除
n_d = d_model // n_head # 每个注意力头的维度 → 64
print(f"每个注意力头的维度n_d: {n_d}") # 输出:64
class multi_head_attention(nn.Module): #集成nn.module,是pytorch所有模型的父类
def __init__(self, d_model, n_head): # 初始化函数,d_model是模型的维度(词向量的维度)
super(multi_head_attention, self).__init__()#调用父类构造函数,初始化nn.Module的核心属性
self.n_head = n_head #保存注意力头的数量,比如8头,12头
self.d_model = d_model#保存模型的总维度
#定义模型的线性变换层:将输入的d_model维度映射到d_model维度上
self.w_q = nn.Linear(d_model, d_model) # Q的线性层 以下同理
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model) #多头拼接后的线性输出层
# 定义softmax函数,dim=-1表示在最后一维归一化( 作为注意力得分维度
self.softmax = nn.Softmax(dim=-1) # softmax会在最后一维(dim=-1)上操作
#向前传播: 输入Q/K/V 自注意力时 q=k=v=X
def forward(self, q, k, v):
# 获取输入查询(q),键(k),值(v)的形状
B, T, D = q.shape #解析输入形状, B批量大小,T 序列长度, D 特征维度
# 计算每个注意力头的维度,如( 512/8=64
n_d = self.d_model // self.n_head # 每个头的维度(d_model / n_head)
# q,k,v通过线性层投影,形状保持(B,T,d_model)
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 拆分并转置:将d_model维度拆分为(n_head,n_d),并调整维度顺序并行计算各头
#view拆分:(B,T,d_model)拆分成 (B,T,n_head,n_d)
#transpose(1,2)转置: (B,T,n_head,n_d) 变成(B,n_head,T,n_d) 目的是把头提到前面方便计算
q = q.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d)
k = k.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d)
v = v.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d)
# 计算缩放点积注意力得分 Q @ K^T / √n_d
#k.transpose(2,3) 形状从(B,n_head,T,n_d) 变成(B,n_head, n_d, T)
# 矩阵乘法后 形状为(B, n_head,T,T) (每个头的注意力得分矩阵)
#除以根号n_d是为了防止n_d过大导致分值溢出,softmax后梯度消失
score = q @ k.transpose(2, 3) / math.sqrt(n_d) # (B, n_head, T, T)
# 生成下三角掩码,:用于decoder任务中屏蔽未来token的信息
#torch.tril,生成下三角全1矩阵,其余为0,值是bool类型的形状为(T,T)
mask = torch.tril(torch.ones(T, T, dtype=bool)) # 生成一个下三角的布尔矩阵
#应用掩码,将mask为False(未来位置)得分置为-10000(softmax后趋近于0 就是无注意力的效果)
#masked_fill(mask==0,-10000) 按mask的布尔值填充 mask==0的位置置换为10000
score = score.masked_fill(mask == 0, -10000) # 把mask == 0的位置置为-10000
# softmax归一化,将注意力得分转化为权重(查询Q 的token 每行的和为1
score = self.softmax(score) # (B, n_head, T, T)
# 注意力权重与V相乘,得到每个头的加权值
score = score @ v # 加权后的权重(B, n_head, T, n_d)
#合并所有头的结果,恢复原始维度顺序并拼接
#transpose(1,2) 现在(B,n_head,T,n_d)变成原来(B,T,n_head,n_d)
#continguous() :保证张量连续内存,view需要连续的内存
#view(B,T,self.d_model):(B,T,n_head,n_d)拼接所有的头成(B,T,d_model)
x_concate = score.transpose(1, 2).contiguous().view(B, T, self.d_model) # (B, T, d_model)
x_output = self.w_o(x_concate) # (B, T, d_model)
# 返回最终的输出
return x_output
#示例化
attn = multi_head_attention(d_model, n_head)
Y = attn(X,X,X)
print(Y.shape)
'''
将每层输入的特征分布归一化为(均值为0,方差为1)避免梯度爆炸加速模型收敛
针对每个token的特征维度做归一化
深度学习模型训练时,随着网络层数加深,每层输入的特征分布会逐渐偏移(称为「Internal Covariate Shift」,内部协变量偏移),带来两个核心问题:
训练缓慢:特征分布偏移会导致学习率难以调整,模型需要更多轮次才能收敛;
梯度问题:特征值过大 / 过小会导致激活函数(如 ReLU、Softmax)饱和,梯度消失 / 爆炸,模型无法学习。
而归一化的本质是「将特征分布拉回标准正态分布」,解决上述问题 ——LayerNorm 是针对 NLP 场景优化的归一化方式,比 BatchNorm 更适配序列数据。
2. 稳定训练:避免梯度消失 / 爆炸,加速收敛
Transformer 的多头注意力、FFN 层会产生数值范围差异很大的特征:
注意力权重的数值可能在 0~1 之间,而 FFN 的输出可能在 ±100 之间;
若直接传入下一层,特征分布偏移会导致梯度要么太小(消失),要么太大(爆炸)。
LayerNorm 将特征归一化为「均值 0、方差 1」后:
特征值集中在 ±1 附近,激活函数(如 ReLU)不会饱和,梯度能正常回传;
学习率可以设置得更大,模型收敛速度提升数倍。
3. 可训练的缩放 / 偏移:保留模型表达能力
如果仅做「(x-mean)/√var」的归一化,会强制特征分布为标准正态分布,可能丢失模型学到的有用特征(比如某些维度的特征本就该有更大的数值)。
因此 LayerNorm 引入了两个可训练参数:
self.gamma:缩放参数(初始为 1),对归一化后的特征做 “放大 / 缩小”;
self.beta:偏移参数(初始为 0),对归一化后的特征做 “平移”。
这两个参数由模型训练学习,核心作用是:让模型在 “稳定分布” 和 “保留特征” 之间找到最优平衡—— 如果归一化后某维度特征需要更大的数值,模型会调大该维度的gamma;如果需要偏移均值,会调整beta。
'''
# layer norm 层归一化
class layer_norm(nn.Module):#继承nn.module 实现层归一化
def __init__(self, d_model, eps = 1e-12):#初始化d_model为归一化维度,防止除0的极小值
super(layer_norm, self).__init__() #调用父类的构造函数__call__, 初始化nn.module的核心属性
#可训练缩放参数gamma(初始为1)和偏移参数beta(初始为0),形状为d_model
self.gamma = nn.Parameter(torch.ones(d_model)) #一维向量 逐维度缩放可训练
self.beta = nn.Parameter(torch.zeros(d_model)) #逐维度偏移 可训练
self.eps = eps #保存eps,防止方差为0时候 除以0
def forward(self, x): #向前传播 输入形状为(B,T,d_model)
#计算最后一维(即为d)的均值mean(-1,keepdim=True)->形状为(B,T,1)保持维度方便广播
mean = x.mean(-1, keepdim = True)
#计算最后一维度的方差。用样本方差(除以N),x形状为(B,T,1)
var = x.var(-1, unbiased=False, keepdim = True)
#归一化处理(x-均值)/√(方差 + eps) ->均值0 方差为1
out = (x - mean) / torch.sqrt(var + self.eps)
#缩放+偏移:gamma*归一化out+self.beta (恢复模型的表达能力 )
out = self.gamma * out + self.beta
return out
#实例化
d_model = 512
X = torch.randn(2,5,512) # 2句话, 5个token,词向量512
ln = layer_norm(d_model)
print("d_model: ", d_model)
print(f"ln gamma: {ln.gamma.shape}")
print(f"ln beta: {ln.beta.shape}")
Y_ln = ln(X)
print(Y_ln.shape)import torch.nn.functional as F


问题总结
问题 1:为什么self.w_q = nn.Linear(d_model, d_model)而不是nn.Linear(d_model, 64)?
多头还要转置计算呢肯定是先保持成一个正方形 便于拆分
先给出结论:先整体投影到 d_model,再拆分多头,而非直接投影到单头维度(64),核心原因有 3 个:
(1)逻辑分层:“整体投影” 和 “多头拆分” 解耦
多头注意力的设计逻辑是:
- 第一步:先对整个输入(d_model=512)做全局线性变换(w_q/w_k/w_v),让模型先学习全局的特征映射;
- 第二步:再将全局特征拆分为 n_head 个独立的头(每个头 64 维),让每个头学习不同维度的注意力模式。
如果直接用nn.Linear(d_model, 64),只能得到单头的 Q/K/V,无法实现 “多头并行计算”—— 你需要为 8 个头定义 8 个 Linear 层(w_q1 到 w_q8),代码会极度冗余,而先投影到 512 再拆分,只需 1 个 Linear 层就能覆盖所有头的投影,逻辑更简洁。
(2)保证模块接口统一(输入输出维度一致)
Transformer 的核心设计原则是:每个子模块(注意力、FFN、LayerNorm)的输入输出维度必须一致(都是 d_model),这样才能无缝串联。
- 如果 w_q 是
Linear(512,64),输出维度会变成 64,拆分后无法再合并回 512(8×64=512,但直接投影到 64 会丢失全局映射); - 而
Linear(512,512)输出还是 512,拆分后合并回 512,最终通过 w_o 投影后仍保持 512 维,符合 Transformer 的接口规范。
(3)数学等价性(但工程更优)
从数学上,Linear(512,512)再拆分为 8 个 64 维头,等价于 8 个Linear(512,64)的拼接 —— 但前者只需维护 1 个层的参数,后者要维护 8 个,PyTorch 的实现效率更高,也更符合工业界的最佳实践。
问题 2:q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) 怎么理解?维度如何匹配?
(1)self.w_q(q)的本质:调用 nn.Linear 的前向传播
self.w_q = nn.Linear(d_model, d_model) 是实例化了一个线性层对象,当你执行self.w_q(q)时,并不是调用普通函数,而是调用 nn.Linear 的__call__方法,最终会执行线性层的前向传播逻辑:output=input×WT+b其中:
- W 是线性层的权重,形状为
(out_features, in_features)=(512,512); - b 是偏置,形状为
(512,); - 输入
q的形状是(B,T,d_model) = (16,64,512)。
(2)维度匹配的核心:nn.Linear 只作用于 “最后一维”
PyTorch 的nn.Linear有个关键特性:它只对输入张量的 “最后一维” 做线性变换,前面的维度(批量、序列长度)会被保留。用你的参数举例:
- 输入 q:
(16, 64, 512)→ 最后一维是 512(和 Linear 的 in_features=512 匹配); - 线性变换计算:
- 对每个 token 的 512 维向量,执行
x @ W.T + b(x 是 (512,),W.T 是 (512,512),结果是 (512,)); - 所有 token 和批量维度保留,最终输出形状还是
(16, 64, 512);
- 对每个 token 的 512 维向量,执行
- 输出最后一维是 512(和 Linear 的 out_features=512 匹配)。
简单说:nn.Linear(in_dim, out_dim) 要求输入的最后一维 = in_dim,输出的最后一维 = out_dim,前面的维度完全保留,这就是维度能对上的核心原因。
问题 3:前向传播(forward)没手动调用,为什么会运行?
这是 PyTorch nn.Module的核心机制,关键在于__call__方法的 “自动触发”:
(1)两个关键步骤的区别
| 操作 | 作用 | 是否执行 forward? |
|---|---|---|
attn = multi_head_attention(512,8) |
实例化模型对象,仅初始化参数(w_q/w_k 等) | ❌ 不执行 |
Y = attn(X,X,X) |
调用模型对象,触发前向传播 | ✅ 执行 forward |
(2)底层原理:nn.Module 的__call__方法
所有继承自nn.Module的类(比如你的multi_head_attention),都继承了__call__方法。当你执行attn(X,X,X)时,实际执行的是:
- 调用
attn.__call__(X,X,X); __call__方法内部会自动调用你定义的forward(X,X,X);- 同时还会处理梯度记录、设备迁移、钩子函数(hook)等底层逻辑。
你可以把forward理解为 “业务逻辑层”(定义模型计算规则),__call__是 “框架层”(PyTorch 自动处理的底层逻辑)—— 你只需要写forward,调用时直接用模型对象(输入),PyTorch 会自动触发forward。
问题4:为什么没有写q=k=v=X 这个代码就默认实现了 B, T, D = q.shape #解析输入形状, B批量大小,T 序列长度, D 特征维度
代码里没显式写q=k=v=X,但却能通过B, T, D = q.shape解析出输入的维度,这本质是「函数参数传递」和「自注意力的调用约定」共同作用的结果
代码里不是 “默认” 解析维度,而是:
forward函数定义了q, k, v三个形参(参数模板);- 调用模型时,你主动传入了
attn(X,X,X)(即把 X 分别传给 q、k、v); - 因此
forward内部的q本质就是你传入的 X,自然能通过q.shape解析出维度。
验证:如果传入不同的 q/k/v,维度解析会对应变化
如果调用时传入不同的张量(而非全传 X),q.shape会解析新的输入维度:
# 定义不同形状的q/k/v
q = torch.randn(8, 32, 512) # B=8, T=32, D=512
k = torch.randn(8, 32, 512)
v = torch.randn(8, 32, 512)
Y = attn(q,k,v) # 传入非X的张量
# forward内部B, T, D = q.shape → B=8, T=32, D=512(解析的是传入的q的维度)
第三步:为什么 “自注意力” 通常传 q=k=v=X?
代码里没写q=k=v=X,但你调用时这么传,是因为自注意力(Self-Attention)的定义就是 Q=K=V = 输入序列:
- 自注意力:让序列中的每个 token “关注” 序列内的其他 token,因此查询(Q)、键(K)、值(V)都来自同一个输入 X;
- 交叉注意力(Cross-Attention):比如 Transformer 解码器,Q 来自解码器,K/V 来自编码器,此时会传
attn(Q_dec, K_enc, V_enc),而非全传 X。
简单说:q=k=v=X是调用时的选择(自注意力的约定),不是代码 “默认” 的行为;B, T, D = q.shape解析的是你传入的 q 的维度,和是否等于 X 无关。
第四步:常见误区澄清
误区 2:“q/k/v 必须相等”
→ 完全不需要!只是自注意力场景下通常相等,代码本身支持传入任意形状匹配的 q/k/v(要求:q 的最后一维 = k 的最后一维,k 的倒数第二维 = v 的倒数第二维)。
你想理解注意力得分矩阵的形状为什么是(B, n_head, T, T),以及除以nd的核心作用,我会用直观的维度推导+数学原理+通俗类比讲清楚,确保新手也能理解。
问题5 为什么矩阵乘法后形状是(B, n_head, T, T)?
我们结合你之前的参数(B=16,nhead=8,T=64,nd=64),一步步推导维度变化:
步骤 1:明确矩阵乘法前 Q 和 K 的形状
- Q 的形状:
(B, n_head, T, n_d)=(16, 8, 64, 64)含义:16 个样本、8 个注意力头、每个头有 64 个 token、每个 token 的维度是 64。 - K 的形状:
(B, n_head, T, n_d)=(16, 8, 64, 64)但计算注意力得分时,需要先对 K 做转置(交换最后两个维度):KT 的形状:(B, n_head, n_d, T)=(16, 8, 64, 64)。
步骤 2:矩阵乘法的维度匹配规则
矩阵乘法(@)的核心规则是:前一个张量的最后一维 = 后一个张量的倒数第二维,结果的维度是「前张量的前 N-1 维 + 后张量的最后一维」。对 Q@KT 来说:
- Q 的维度:
(16, 8, 64, 64)→ 前 3 维是(16,8,64),最后一维是 64; - KT 的维度:
(16, 8, 64, 64)→ 倒数第二维是 64,最后一维是 64; - 相乘后维度:
(16, 8, 64, 64)=(B, n_head, T, T)。
步骤 3:形状的实际含义(关键)
(B, n_head, T, T) 这个形状的每一层含义:
| 维度位置 | 数值 | 含义 |
|---|---|---|
| 第 1 维 | 16 | 批量大小:16 个独立的样本(比如 16 句话),彼此独立计算注意力 |
| 第 2 维 | 8 | 注意力头数:8 个独立的注意力头,每个头学习不同的注意力模式 |
| 第 3 维 | 64 | 「查询 token」数量:每个 token 作为 “查询者”,要计算和所有 token 的相似度 |
| 第 4 维 | 64 | 「键 token」数量:每个 “查询者” 要和 64 个 token(键)计算相似度 |
简单说:这个矩阵里的每个元素 score[b, h, i, j] 表示 —— 第 b 个样本、第 h 个注意力头中,第 i 个 token(查询)对第 j 个 token(键)的注意力得分(相似度)。
问题 6 为什么要做这个 x_output = self.w_o(x_concate) 处理
第一步:先明确核心结论
self.w_o(Output Projection)是多头注意力的输出投影层,作用是:
- 将 “简单拼接的多头特征” 转化为 “融合后的全局特征”,而非单纯拼接;
- 保持 Transformer 模块 “输入输出维度一致” 的设计规范;
- 引入可训练参数,让模型学习如何最优组合多个头的注意力结果。
第二步:拆解 “为什么需要这一步”(结合维度和逻辑)
我们先回顾x_concate的由来:
python
运行
# score形状:(B, n_head, T, n_d) → 8个头,每个头64维
x_concate = score.transpose(1,2).contiguous().view(B, T, d_model)
# x_concate形状:(B, T, 512) → 只是把8个64维的头“简单拼接”成512维
x_concate本质是8 个独立注意力头结果的 “直接拼接”,而非 “融合”—— 每个头的 64 维特征是独立计算的,拼接后只是维度凑够了 512,但头与头之间的特征没有交互,模型无法学习 “哪些头的信息更重要”。
而self.w_o = nn.Linear(d_model, d_model)的作用就是解决这个问题:
1. 特征融合:让多头信息从 “独立” 变 “协同”
self.w_o的权重矩阵形状是(512, 512),对x_concate(B,T,512)做线性变换时:xoutput=xconcat⋅WoT+bo
- Wo 的每一行对应 “输出的一个维度”,每一列对应 “输入的一个维度”;
- 这意味着:输出的每个维度会融合所有 8 个头的特征(比如输出第 1 维可能包含头 1 的第 10 维、头 2 的第 20 维…… 头 8 的第 50 维的加权和);
- 模型可以通过学习Wo的参数,决定 “哪些头的特征更重要”“如何组合多头特征能得到最优结果”。
2. 保持模块接口一致性(Transformer 的核心设计原则)
Transformer 的所有子模块(注意力、FFN、LayerNorm)都遵循 “输入输出维度一致” 的规则:
- 注意力模块的输入是
(B,T,512),如果直接返回x_concate(512 维),虽然维度对了,但特征是 “未优化的拼接结果”; - 通过
self.w_o投影后,输出还是(B,T,512),既保持了接口一致性,又让特征得到了优化。
3. 弥补 “拆分 - 拼接” 的信息损失
多头注意力的 “拆分(d_model→n_head×n_d)→ 拼接(n_head×n_d→d_model)” 过程中,会丢失 “全局特征关联”:
- 拆分时,每个头只处理 64 维的局部特征,无法看到全局 512 维的信息;
self.w_o作为全局线性层,能把拆分后丢失的全局关联重新学习回来。
第三步:不做这一步会怎样?(反证法理解必要性)
如果去掉self.w_o,直接返回x_concate,会出现两个核心问题:
1. 模型表达能力大幅下降
多头注意力的优势是 “多个头学习不同的注意力模式”,但如果只是简单拼接,模型无法融合这些模式 —— 相当于 8 个专家各说各的,没有一个 “总负责人” 整合意见,最终效果甚至不如单头注意力。
2. 不符合 Transformer 的原始设计
Transformer 论文(Attention Is All You Need)中明确定义了多头注意力的公式:MultiHead(Q,K,V)=Concat(head1,...,headh)WO其中WO就是self.w_o的权重矩阵,是多头注意力的核心组成部分,去掉后就不是标准的多头注意力了。
第四步:结合代码实例验证(直观感受差异)
我们用你的参数做一个简单对比:
import torch
import torch.nn as nn
# 模拟x_concate(B=16, T=64, d_model=512)
x_concate = torch.randn(16, 64, 512)
# 定义输出投影层
w_o = nn.Linear(512, 512)
# 有投影层的输出
x_output = w_o(x_concate)
print(f"有w_o的输出形状:{x_output.shape}") # (16,64,512),维度不变但特征融合
# 无投影层的输出(直接返回x_concate)
x_no_o = x_concate
print(f"无w_o的输出形状:{x_no_o.shape}") # 维度相同,但特征是原始拼接
# 查看参数数量:w_o有512×512 + 512 = 262656个可训练参数
print(f"w_o的参数数量:{sum(p.numel() for p in w_o.parameters())}")
可以看到:
- 有无
w_o的输出维度完全一致,但w_o引入了 26 万 + 可训练参数,让模型能学习多头特征的最优组合; - 去掉
w_o后,这部分参数消失,模型失去了融合多头信息的能力。
- 核心作用:
self.w_o是多头注意力的 “输出投影层”,将多头拼接的特征做全局融合,而非简单拼接; - 设计逻辑:引入可训练参数,让模型学习如何最优组合多个头的注意力结果,提升表达能力;
- 工程意义:保持 Transformer 模块 “输入输出维度一致” 的规范,符合原始论文设计。
简单记:多头注意力的流程是「线性投影(w_q/w_k/w_v)→ 拆分多头 → 计算注意力 → 合并多头 → 输出投影(w_o)」,w_o是最后一步的 “特征升华”,缺一不可。
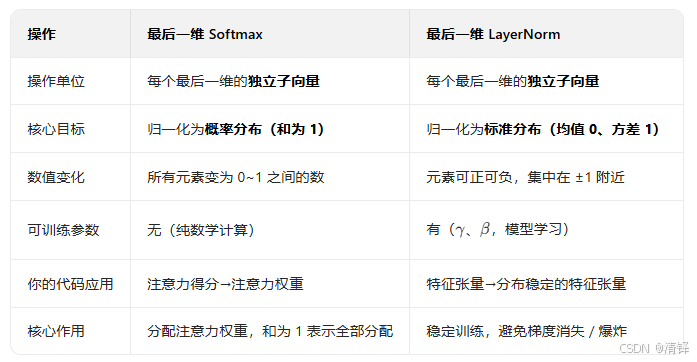
问题 7:怎么理解在最后一维做softmax和在最后一维归一化。有没有数据例子给我直观看一下。 还有方差是1是什么概念、
就是对每个token的词向量做softmax和归一化
LayerNorm(dim=-1):对张量中每个「最后一维的子向量」单独做 “均值 0、方差 1” 的归一化,再通过可训练参数缩放 / 偏移;和 Softmax 一样,先拆成独立子向量,每个子向量独立计算,再拼回原形状。LayerNorm 核心公式(和代码一致):x^=σ2+ϵx−μ;out=γ⋅x^+β
- μ:子向量的均值,σ2:子向量的样本方差(无偏 = False,除以元素个数);
- ϵ:极小值(1e-12),防止除 0;
- γ(初始 1)、β(初始 0):可训练的缩放 / 偏移参数。
数据例子(shape=(1,3,2),dim=-1,ϵ=1e−12,γ=1,β=0)
演示张量:x_layernorm = [[[1,3], [5,7], [9,11]]],手动计算更直观。
步骤 1:拆分最后一维的独立子向量
同样拆成 3 个 2 维子向量:[1,3]、[5,7]、[9,11]。
步骤 2:对每个子向量单独算 LayerNorm(分步计算)
子向量 1:[1,3]
- 均值μ:(1+3)/2=2;
- 方差σ2:[(1−2)2+(3−2)2]/2=(1+1)/2=1;
- 归一化:1+1e−121−2≈−1,1+1e−123−2≈1 → 结果
[-1, 1]; - 缩放偏移(γ=1,β=0):仍为
[-1,1]。
子向量 2:[5,7]
- 均值μ:(5+7)/2=6;
- 方差σ2:[(5−6)2+(7−6)2]/2=1;
- 归一化:15−6=−1,17−6=1 → 结果
[-1,1]。
子向量 3:[9,11]
- 均值μ:(9+11)/2=10;
- 方差σ2:[(9−10)2+(11−10)2]/2=1;
- 归一化:19−10=−1,111−10=1 → 结果
[-1,1]。
步骤 3:拼回原形状
最终 LayerNorm 结果:[[[-1,1], [-1,1], [-1,1]]],形状仍为(1,3,2)。
可视化对比
| 操作 | 张量数值(shape=(1,3,2)) | 关键特征 |
|---|---|---|
| 原始张量 | [[[1,3], [5,7], [9,11]]] | 子向量均值 / 方差不同 |
| LayerNorm 后 | [[[-1,1], [-1,1], [-1,1]]] | 每个子向量均值 0、方差 1,维度不变 |
拓展:加入缩放 / 偏移(γ=2,β=3)
如果设置γ=2(缩放 2 倍)、β=3(偏移 3),对上面的归一化结果再计算:out=2∗[−1,1]+3=[1,5],最终结果为[[[1,5], [1,5], [1,5]]]—— 这就是可训练参数的作用,让模型能调整归一化后的分布。
2. 「方差 = 1」的直观含义
数据围绕均值 0,以 “1 个单位” 为离散程度分布,结合上面的例子:
- 归一化后的数据
[-1,1]:均值 0,每个数据到均值的距离都是 1,方差 = 1; - 再举个例子:数据
[-0.5, 0.5]→方差 = 0.25(更集中),[-2,2]→方差 = 4(更分散); - 方差 = 1 是深度学习的 “黄金离散程度”:数据既不拥挤(方差太小,特征区分度低),也不分散(方差太大,激活函数饱和)。
用两张图直观对比(文字描述):
- 原始数据:均值 = 6,方差 = 10 → 数据分布在
[6-3,6+3]即[3,9]之间,范围大; - 归一化后:均值 = 0,方差 = 1 → 数据分布在
[0-1,0+1]即[-1,1]之间,范围固定。对模型来说,固定的分布意味着: - 激活函数(如 ReLU、Softmax)不会因数据值过大 / 过小饱和,梯度能正常回传;
- 学习率可以统一设置,不用因数据范围不同调整,训练更稳定

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)