cmu15445(2024fall) project4
做该项目之前建议先通读一遍整个项目指导文档。该协议中的存储模型类似于课程中讨论的增量表(delta table)架构。对于每个存储的元组,DBMS 还会额外存储元组的delta,项目中将其称为undo log。表堆中的元组及其对应的undo log/增量构成一个单向链表,称为版本链version chain。通过version chain,我们可以在逻辑上“存储”元组的每个先前版本。项目中并非存储
文章目录
前言
做该项目之前建议先通读一遍整个项目指导文档。
该协议中的存储模型类似于课程中讨论的增量表(delta table)架构。对于每个存储的元组,DBMS 还会额外存储元组的delta,项目中将其称为undo log。表堆中的元组及其对应的undo log/增量构成一个单向链表,称为版本链version chain。通过version chain,我们可以在逻辑上“存储”元组的每个先前版本。项目中并非存储元组的每个版本,而只是存储每个版本之间的增量。
undo log存储在特定事务的内存工作区中,事务本身存储在内存数据结构中,我们将其称为事务管理器(Transaction manager)。需要注意的是,在生产系统中,这些日志会持久化到磁盘,但 BusTub 无需这样做,暂时在Bustub中还没有涉及到日志和数据库崩溃恢复的project。
project的background部分还给出了两个project 4中可能会常用的语法:
- 将可选值映射到其他值。可以使用以下语法编写更简洁的代码(单子操作):auto x = opt.has_value() ? operation(*opt) : std::nullopt;
- C++14 元组解包语法:auto [meta, tuple] = iter->GetTuple();
一、Task #1 - Timestamps
在Bustub中事务有两个时间戳:read_ts和commit_ts,这和工业界的DBMS有一定的区别。双时间戳设计是一种优化的MVCC实现方式,这种设计在学术界和工业界都有广泛应用(如Google Spanner)。
- 双时间戳的基本作用
| 时间戳类型 | 英文全称 | 作用 |
|---|---|---|
read_ts |
Read Timestamp | 记录该数据版本最后一次被成功读取的时间戳(可见性截止时间) |
commit_ts |
Commit Timestamp | 记录该数据版本被创建时的事务提交时间戳(版本诞生时间) |
- 与单版本号系统的区别
传统MVCC系统(如PostgreSQL)通常只使用单一事务ID,而Bustub的双时间戳设计:
- 将版本可见性(read_ts)和版本创建时间(commit_ts)解耦
- 允许更灵活的并发控制策略
- 特别适合分布式数据库场景
同时Bustub中tuple和版本(undo log)中只有一个时间戳ts_,这与工业界中数据库的两个时间戳(一般为一个创建时间戳一个删除时间戳)有所不同。
1.1 Timestamp Allocation
在事务开始时,事务会被分配一个读取时间戳,该时间戳等于最近提交事务的提交时间戳。读取时间戳决定了事务可以安全正确地读取哪些数据。或者换句话说,读取时间戳决定了当前事务可以看到元组的最新版本。 TransactionManager通过维护last_commit_ts_来在Begin()中给予新的事务read_ts_。
当事务提交时,它会被分配一个单调递增的提交时间戳。提交时间戳决定了事务的序列化/串行化顺序顺序。 由于这些提交时间戳是唯一的,因此我们也可以通过提交时间戳来唯一地标识已提交的事务。同时事务还有一个事务ID,也是由TransactionManager分配。
这部分的基本实现就是在TransactionManager的Begin()和Commit()两个函数中实现对新建事务的read_ts_的设置和对提交事务的commit_ts_的设置。
1.2 Watermark
这部分主要实现watermark(水位线)。watermark是所有尚未提交或中止的事务(即活跃事务)中读取时间戳最小的那个。如果不存在这样的事务,则watermark是最新的提交时间戳。watermark用来判断DBMS中有哪些数据版本不再被所有活跃事务需要,在garbage collection中用于淘汰不被活跃事务需要的数据版本。
Watermark类中current_reads里面包括了当前所有活跃事务,记录了读取时间戳个数与读取时间戳的对应关系。watermark即current_reads中的时间戳最小值, 如果current_reads中没有数据则返回commit_ts_。
计算watermark最简单的方法是遍历事务管理器映射中的所有事务,并在所有正在进行的事务中找到读取时间戳最小的事务。当然有更好的方案,比如使用优先队列(堆),其插入和删除时间复杂度为O(log N),读取其首个元素便是watermark。
但是优先队列的问题是:不能弹出/删除指定元素,只能弹出头部元素。但在TransactionManager的Commit()和Abort()中均会进行watermark中活跃事务元素的删除。这里使用的解决方案为惰性删除 + 哈希表标记。
惰性删除(Lazy Deletion)是一种延迟删除策略,核心思想是:只在真正需要时(或合适时机)才执行删除操作,而非立即释放资源。
std::unordered_map<timestamp_t, int> current_reads_;
std::priority_queue<timestamp_t, std::vector<timestamp_t>, std::greater<>> min_heap_;
这里使用的惰性删除策略为:RemoveTxn 只更新哈希表计数不立即修改堆,只有当访问到无效堆顶时才清理(类似延迟删除)。删除时根据哈希表信息从堆顶进行删除。
auto Watermark::RemoveTxn(timestamp_t read_ts) -> void {
// TODO(fall2023): implement me!
if (current_reads_.count(read_ts) == 0) {
return;
}
if (current_reads_[read_ts] > 0) {
current_reads_[read_ts]--;
}
// 如果删掉的是watermark,则将优先队列更新,将其中的部分无效元素删除
// 采用惰性删除策略
if (read_ts == watermark_) {
while (!min_heap_.empty()) {
auto top_ts = min_heap_.top();
// 找到了有效堆顶元素,则更新watermark_并直接返回
if (current_reads_[top_ts] > 0) {
watermark_ = top_ts;
return;
}
min_heap_.pop();
}
// 如果最后min_heap_为空,则表示没有有效read_ts了,则使用commit_ts作为watermark_
watermark_ = commit_ts_;
}
}
二、Task #2 - Storage Format and Sequential Scan
task 2开始真正涉及到MVCC中的版本设计。课程文档中提供的示意图展示了各个版本undo_log与table heap中的最新元组的存储位置与链接关系。
BusTub 将事务数据存储在三个地方:表堆 table heap、事务管理器以及每个事务的工作区内。表堆始终包含最新的元组数据。事务管理器存储指向每个元组最新undo_log(PageVersionInfo) 的指针。事务存储它们创建的undo_log。
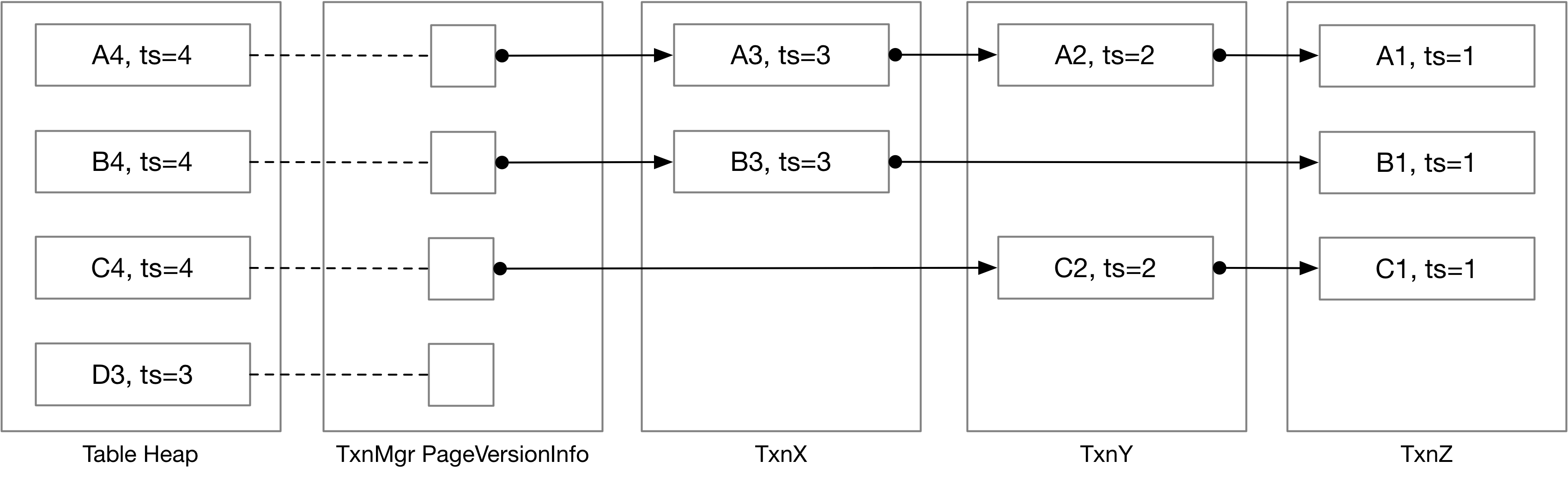
TransactionManager中哈希表version_info_可以通过table heap中最新的tuple的RID来哈希到该tuple对应的最近的undo_log的UndoLink,UndoLink可以视为UndoLog的指针。而在UndoLog中存有下一个UndoLog的UndoLink,相当于一个next指针。由此可以根据一个table heap tuple的RID得到对应的一整个UndoLog链。 以上便是undo_log基本的存储结构。
2.1 Tuple Reconstruction
这部分需要实现ReconstructTuple()函数,其可以实现从base_tuple(table heap tuple),根据按从最近修改到最旧修改的顺序排列的UndoLog列表,根据undo_log中的差异,重构得到之前某个UndoLog版本的tuple。
Bustub中使用的version storage为delta storage,根据文档delta的存储方式为反向delta,核心思想是记录数据修改前的旧值而非新值,用于支持回滚、版本重建。通过反向delta可以实现从table heap中tuple反向回到之前某个版本的tuple。

UndoLog的记录的是从目前版本回到旧版本的tuple值变化(delta),如下图。熟悉此结构即可实现tuple的重建。
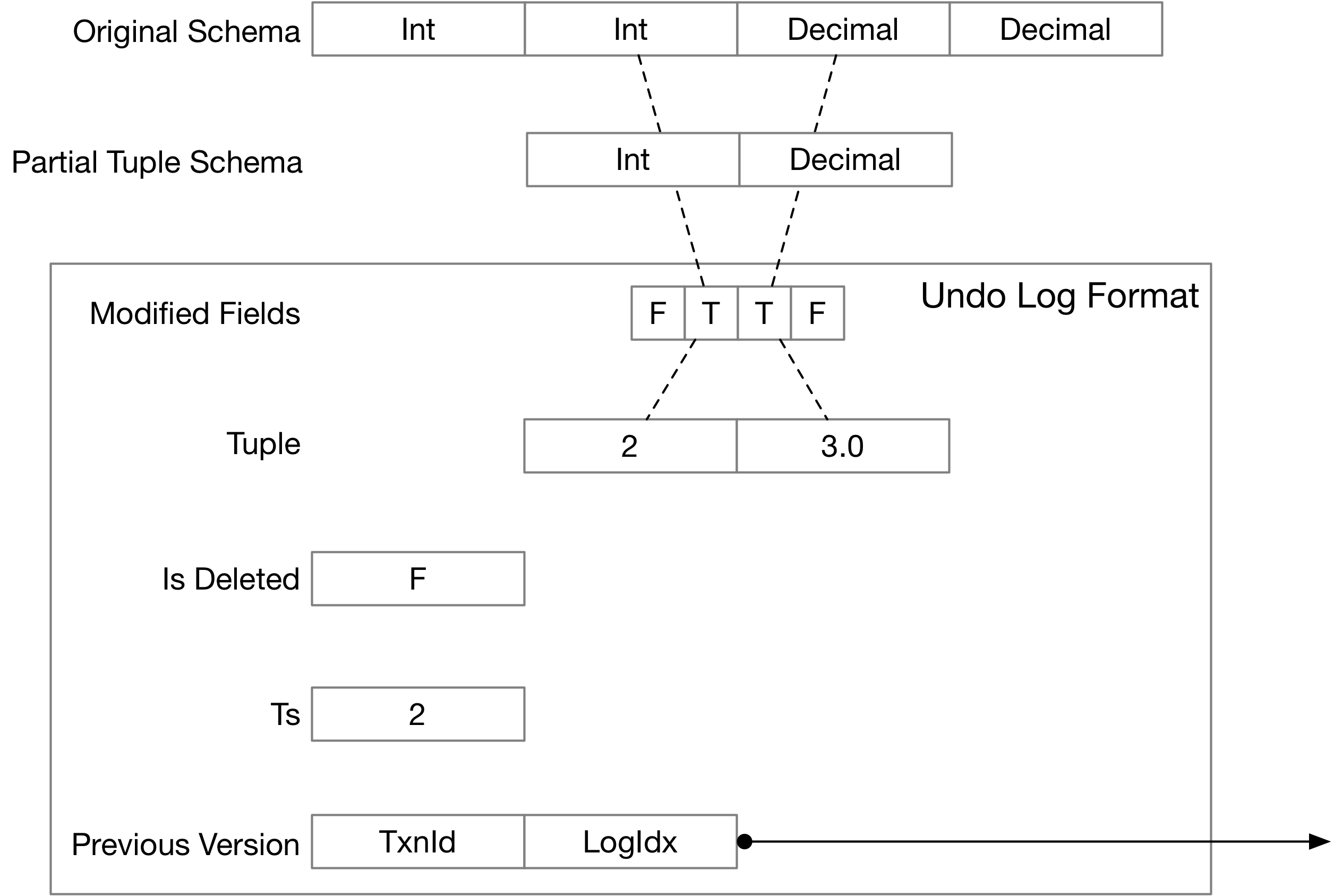
在指导文档中有这样一段:
As a reminder, you do not need to use or even examine the timestamp (ts_) field and the previous version (prev_version_) field in ReconstructTuple, as prev_version_ should only be used by the caller of ReconstructTuple to figure out what UndoLogs to place in the input vector.
这一段的大致意思是:ReconstructTuple()中不需要使用prev_version_这个next指针,直接通过遍历输入参数 std::vector< UndoLog > undo_logs即可。因为直接通过prev_version_指针遍历可能会遍历到version chain的最后,但是其实输入的UndoLog数组中并不一定是整个version chain中的所有UndoLog,其中是version chain中的哪部分UndoLog由ReconstructTuple()的调用者决定,即由调用者决定输入参数std::vector< UndoLog > undo_logs中有哪些UndoLog。undo_logs 中的所有日志都会被应用,无论时间戳如何。
2.2 Sequential Scan (Tuple Retrieval)
在此任务中,需要重写project 3中的顺序扫描执行器,以支持检索过去的数据(基于事务的读取时间戳)。
这里文档要求我们实现函数CollectUndoLogs,这个函数的功能便是2.1中最后提到的,决定哪些undo log被应用到ReconstructTuple()函数中来重建所需的tuple版本。此函数会根据事务的read ts返回重建可读元组所需的undo logs。
根据当前事务的读取时间戳,有以下三种情况:
- table heap中的元组是相对于读取时间戳的最新数据。可以通过检查元组元数据中的时间戳来确定这一点。在这种情况下,无需执行撤消操作,CollectUndoLogs 应该返回一个空向量。
- table heap中tuple被当前事务修改过。被修改但事务还没提交的tuple的ts均为修改事务的temporary transaction timestamp(实际为事务id),bustub中通过设计commit ts和txn id的大小限制,设置了commit ts < txn id的限制,所以可以通过比较table heap中tuple的ts和当前事务的txn id来判断是否当前事务是否修改了tuple。
- table heap中tuple被其他事务修改过 or table heap中tuple比当前事务read ts更新。这种情况下,需要通过迭代版本链来读取之前undo log,找到当前事务可以读取的版本。
2.1 中的tuple reconstruction在这部分中也会起到作用。简单来说就是seq scan应当根据txn的read ts读取到txn应当读取到的tuple version,使用ReconstructTuple还原所需版本的tuple。有了ReconstructTuple()和CollectUndoLogs两个函数,实现Seq Scan Executor很简单。
三、Task #3 - MVCC Executors
这部分会要实现Insert、Delete、Update三种涉及数据更新的Executor,实现在MVCC下的版本。在MVCC中,这几个Executor的实现需要涉及到UndoLog的生成。之前部分只是涉及到了利用UndoLog回溯版本,这部分将会涉及到UndoLog的生成。
3.1 Insert Executor
这部分的insert executor只需要实现直接在table heap生成一个new tuple,这种情况下无需生成undo log,因为此时tuple的RID为全新的RID。在4.2中涉及到主键索引时,会有插入到同RID下被删除tuple中的情况,这种情况下会要生成新的undo log。这部分只需要通过AppendWriteSet函数修改txn的写集,更新txn mgr中的undolink即可。
*rid = info->table_->InsertTuple(meta, *tuple).value();
// 在事务 write set 中加入插入tuple的rid
txn->AppendWriteSet(table_oid, *rid);
// 更新txn mgr中的undo_link
txn_mgr->UpdateUndoLink(*rid, std::make_optional(UndoLink{}), nullptr);
3.2 Commit
Commit通过commit_mutex_保证整个过程的线程安全性。
Commit中主要涉及到一些数据的更新,包括txn的commit ts等。我们需要实现的部分主要是对txn中WriteSet中所有修改过的tuple的ts_从临时ts变为当前事务的commit ts,由此完成了对table heap中对应tuple的实际修改。
3.3 Generate Undo Log
这部分是为了delete 和 update executor的实现做铺垫。delete和update对tuple进行修改后,需要生成undo log来记录之前的版本,文档推荐我们实现GenerateNewUndoLog和GenerateUpdatedUndoLog两个函数,前者可以通过新旧tuple来生成对应的new undo log,后者可以根据提供的undo log和新旧tuple生成更新后的undo log。
为何要有GenerateUpdatedUndoLog函数?主要是因为一个事务如果对某个tuple进行了多次更新,最终这个tuple也应当只增加了一个undo log,记录的是当前事务修改之前的版本。所以在每次修改后,如果不是第一次修改,需要通过GenerateUpdatedUndoLog函数合并undo log。
注意,这里不是一个事务只会生成一个undo log,而是一个事务对于一个table heap中的tuple只会生成一个undo log,undo log是与table heap中tuple相关联的。
GenerateNewUndoLog的基本思路:
- 如果 base_tuple == nullptr,为insert的情况,目前在insert_executor中,没有使用该函数,即在一般的insert时,不需要生成UndoLog,但是在将元组插入到被删除的tuple时,会需要生成UndoLog。所以这里生成一个空的UndoLog。
- 如果 target_tuple == nullptr,为delete的情况,则modified_fields全为true,将base_tuple直接复制到undo log中。
- 如果是update的情况,则根据tuple各列是否发生变化来生成undo log。
GenerateUpdatedUndoLog的思路更复杂,之前思路为根据提供的undo log生成原本旧的tuple,然后直接通过GenerateNewUndoLog生成新的undo log。但是根据文档要求,确保仅在撤消日志中添加/更新数据,而不要删除数据,即之前在undo_log中的modified_fields_中为true的一直保持true,不会被改为false。所以还是需要具体逻辑来处理。
3.4 Update & Delete Executor
这两个executor简单来说就是两部分:检测写-写冲突,执行对应操作。
写-写冲突的判断条件为:tuple的时间戳大于当前事务的read ts并且不等于当前事务的临时时间戳(即事务ID),则表示发生了写-写冲突,需要设置事务为TAINTED状态,并且抛出异常。
- Delete:
- 当tuple的时间戳为当前的事务ID:
- 如果原本tuple对应的最新undo_link为invalid,表示tuple为本txn通过insert插入,并没有生成undo_log。 这种情况下只需要修改tuple meta不需要修改和增加undo log。这种可以通过判断tuple对应的undo link是否为valid来判断,为invalid则表示该tuple没有undo log,则为该情况。
- 如果原本tuple对应的最新undo_link为valid,则表示该事务有生成undo log,那么就通过GenerateUpdatedUndoLog函数更新undolog,直接更新槽位处的元组即可。
- 如果tuple的时间戳小于等于当前事务read ts,以target为nullptr, 原元组为basetuple通过GenerateNewUndoLog函数构建undolog, 添加写集合与将undolog添加到当前事务中,最后更新当前槽位处元组。
- 如果tuple的时间戳大于当前事务read ts,这种情况按理来讲在写-写冲突判断时应该已经排除,但是在多线程情况下,可能在两个事务均通过了写写冲突检测,在之后某个事务先进行了tuple修改的情况。当然在之后加入了check函数判断时,这里的分支也可以不要。
- 当tuple的时间戳为当前的事务ID:
- Update:基本思路与delete一致。在tuple时间戳小于等于当前事务read ts时,以new tuple为target tuple,原元组为base tuple创建undolog, 并且更新undolog。然后更新table heap中tuple即可。
3.5 Stop-the-world Garbage Collection
垃圾回收机制用于回收不再需要的txn,之前计算的watermark在这里起到了作用。需要遍历表堆和版本链,以识别仍可被读取时间戳最小的事务访问的undo log(对该事务不可见的撤消日志应该对所有事务都不可见)。如果某个事务已提交/中止,并且不包含任何对读取时间戳最小的事务可见的撤消日志,则可以直接将其从事务图中删除。
这部分我实现的方法有些鸡肋,参考博客中博主的方法更科学。
四、Task #4 - Primary Key Index
4.1 Index Insert
加上了主键索引后,需要多注意的问题有:插入到已删除的tuple位置,主键索引的唯一性问题。
如果存在主键,此时进行插入要考虑插入数据的主键列所对应的Key是否已经存在主键索引中。 如果已经存在索引中, 则要拿到索引中Key指向的tuple,检查tuple是否为delete, 如果为delete,则更新该tuple的数据和元数据,undo log的处理则是在GenerateNewUndoLog和GenerateUpdatedUndoLog函数中参数base_tuple设置为nullptr,其他处理类似于之前的update executor。如果不为delete, 说明有数据, 那么就是主键索引的唯一性冲突,认定为写-写冲突。
如果不在主键索引中, 则为之前无主键索引情况的插入。
4.2 Index Scan, Delete
Index Scan与seq scan的实现类似。
delete中不需要加入主键索引entry的删除逻辑,保留删除tuple的主键索引entry,在insert中若有key相同的tuple插入,可以用之前的entry。总之主键索引中键值对不会被删除,只会添加与复用。
4.3 Primary Key Updates
update时,如果存在主键索引更改,那么要先将所有需要更改的元组删除, 然后再将所有新元组添加,并处理索引的插入。如果是删一个插入一个的话, 可能会导致新插入的元组与本应删除的但还没删掉的元组索引列冲突, 判断多余的写-写冲突。比如:UPDATE maintable SET col2 = col2 + 1。如果是删除一个插入一个,在更新时,删除col2 = 1的tuple,接着插入col2 = 2的tuple时,则会发生本不应当发生的写-写冲突。
4.4 Concurrency Control
并发控制主要是检测写-写冲突,包括几个executor开始时的写-写冲突检测,之后逻辑中的写-写冲突。这里主要是加入了UpdateTupleAndUndoLink()和UpdateTupleInPlace()函数中的check函数,check函数为绑定了当前txn的lambda函数,通过比较修改tuple的ts是否小于txn的read ts或者等于txn的temp ts,来检测多线程情景下的写-写冲突,如果有写-写冲突,则两个函数会返回false,则设置事务为tainted,抛出异常。
Bonus Task 1: Abort
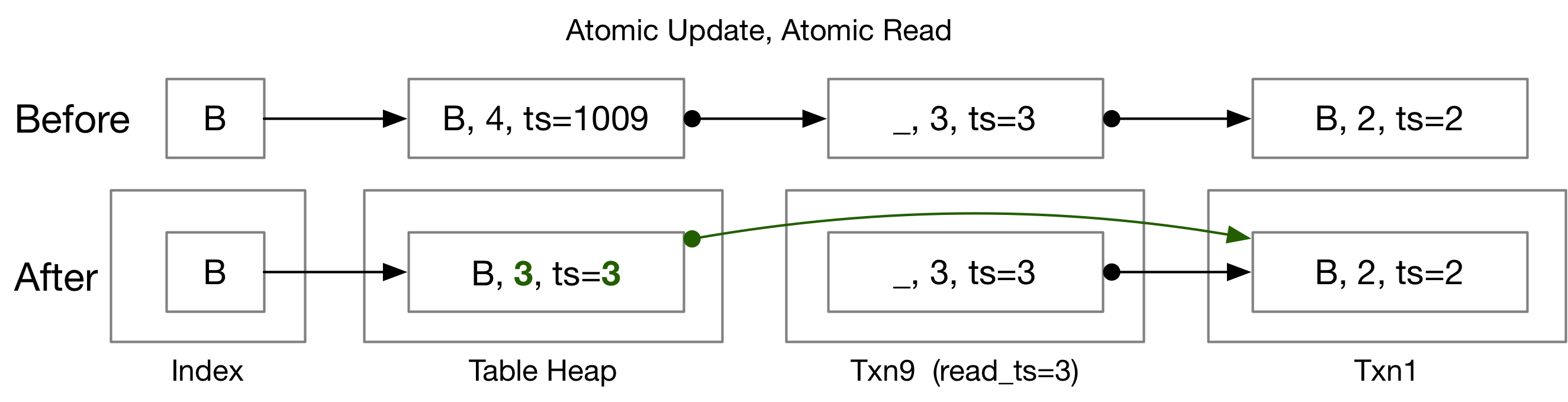
之前在发生写-写冲突时,是将事务设置为tainted,这里要实现事务回滚abort的逻辑。主要进行的操作为根据txn的WriteSet来将所有修改过的tuple回滚到最新undo log的版本,同时修改undo log链和txn mgr中的undo link。这里采用的是文档中提供的第二种实现方案Implementation #2。
总结
project 4是四个project中最难的一个,但是在实现了project 3的基础上,对于各个executor的修改并不复杂,难点在于对MVCC版本机制的理解,对undo log版本链的理解,以及对于多线程情况下写-写冲突的处理的理解。这部分参考了reference中的优秀博客。
Reference
[1] CMU15445-2024fall-project4踩坑经历 - 绵阳的脑内SSD的文章 - 知乎
https://zhuanlan.zhihu.com/p/1932549868683007217

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)