Python爬虫实战:东方财富网股票数据采集
·
Python爬虫实战:东方财富网股票数据采集
技术栈
本爬虫项目使用以下Python库:
- requests: 用于发送HTTP请求,获取网页内容
- time 和 random: 用于控制请求频率,避免被反爬机制检测
- re: 正则表达式库,用于解析HTML内容中的JSON数据
- json: 处理JSON格式的数据
- fake_useragent: 生成随机User-Agent,模拟不同浏览器
- openpyxl: 操作Excel文件,保存爬取的数据
- tqdm: 显示进度条,提高用户体验
代码实现
1. 导入必要的库
import requests
import time
import random
import json
import re
from fake_useragent import UserAgent
from openpyxl import Workbook
from requests import RequestException
from tqdm import tqdm
2. 创建爬虫类
class Spider:
def __init__(self):
# 网址
self.url = 'https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37105460204350036134_1766485651718&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn={}&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=3349087659401996%7C0%7C1%7C0%7Cweb&_=1766485652135'
# 请求头
self.headers = {
'accept': '*/*',
'cookie': '' # 填写自己的cookie,
'User-Agent': UserAgent().random,
}
# 实例化工作薄
self.wb = Workbook()
# 激活默认表
self.ws = self.wb.active
# 写入头(股票的字段)
self.ws.append(
['股票代码', '股票名称', '最新价', '涨跌幅', '涨跌额', '成交量(手)', '成交额', '振幅', '最高', '最低',
'今开', '昨收', '量比', '换手率', '市盈率(动态)', '市净率'])
# 响应网页内容的列表
self.htmlContentList = []
# 股票信息列表
self.stockInfoList = []
在初始化方法中,我们设置了爬虫的基本参数:
- url: 东方财富网的API接口,其中
pn={}是页码占位符,用于分页获取数据 - headers: HTTP请求头,包含cookie和随机User-Agent,用于模拟浏览器行为
- Excel相关变量: 创建工作簿和工作表,并设置表头
- 数据存储列表: 用于存储爬取的网页内容和解析后的股票信息
3. 获取股票数据
def getStockData(self, urls):
"""
:param urls: 页面网址列表
:return: 响应内容的列表
"""
# tqdm - 显示当前进度
for url in tqdm(urls):
# 设置时间间隔
time.sleep(random.uniform(2, 3))
try:
# 向网页发起请求
response = requests.get(url, headers=self.headers)
# 将网页内容添加到列表中
self.htmlContentList.append(response.text)
# 请求错误
except RequestException as requests_e:
print(f'错误:{requests_e}')
# 其他错误
except Exception as e:
print(f'错误:{e}')
print(f'所有页面的数据获取完成!!!')
# 返回响应内容的列表
return self.htmlContentList
这个方法负责从东方财富网获取股票数据:
- 使用
tqdm显示爬取进度条 - 随机延时2-3秒,避免被网站的反爬机制检测
- 发送GET请求获取网页内容
- 异常处理确保程序不会因网络问题而中断
- 返回所有页面的响应内容列表
4. 解析股票数据
def parseStockData(self, StockContents):
"""
:param StockContents: 股票信息列表
:return:
"""
for StockContent in tqdm(StockContents):
try:
# 提取JSON数据
json_data = re.search(r'jQuery\d+_\d+\((.*?)\);', StockContent)
if json_data:
# 解析为字典
data = json.loads(json_data.group(1))
# 检查返回状态
if data.get('rc') == 0 and data.get('data'):
stockList = data['data'].get('diff', [])
# 遍历股票
for stock in stockList:
# 提取股票信息
stockInfo = [
stock.get('f12', ''), # 股票代码
stock.get('f14', ''), # 股票名称
stock.get('f2', ''), # 最新价
stock.get('f3', ''), # 涨跌幅
stock.get('f4', ''), # 涨跌额
stock.get('f5', ''), # 成交量(手)
stock.get('f6', ''), # 成交额
stock.get('f7', ''), # 振幅
stock.get('f15', ''), # 最高
stock.get('f16', ''), # 最低
stock.get('f17', ''), # 今开
stock.get('f18', ''), # 昨收
stock.get('f10', ''), # 量比
stock.get('f8', ''), # 换手率
stock.get('f9', ''), # 市盈率(动态)
stock.get('f23', '') # 市净率
]
# 将股票信息添加到股票信息列表中
self.stockInfoList.append(stockInfo)
# 将股票信息写入工作表中
self.ws.append(stockInfo)
else:
print(f'{json_data}为空')
except Exception as e:
print(f'错误: {e}')
这个方法负责解析获取到的网页内容:
- 使用正则表达式提取JSON数据
- 解析JSON数据,获取股票列表
- 遍历股票列表,提取每只股票的详细信息
- 将提取的信息添加到股票信息列表,并写入Excel工作表
- 异常处理确保程序不会因数据格式问题而中断
5. 保存Excel文件
def saveToExcel(self):
# 先判断是否成功获取到股票信息
if self.stockInfoList:
# 保存文件
self.wb.save('沪深京A股.xlsx')
print(f'数据已保存到沪深京A股.xlsx,共{len(self.stockInfoList)}条数据')
else:
print('没有数据需要保存')
这个方法负责将解析后的数据保存为Excel文件:
- 检查是否有数据需要保存
- 如果有数据,则保存为Excel文件,并显示保存成功信息
- 如果没有数据,则显示提示信息
6. 主程序
def start(self):
# 使用列表推导式生成所有的url
urls = [self.url.format(i) for i in range(1, 275)]
# 获取数据
stockData = self.getStockData(urls)
# 判断stockData中是否有数据
if stockData:
# 解析响应的网页内容
self.parseStockData(stockData)
# 保存到excel文件
self.saveToExcel()
else:
print(f'没有获取到数据')
if __name__ == '__main__':
# 实例化类
easyMoney = Spider()
# 运行程序
easyMoney.start()
主程序负责协调整个爬虫流程:
- 生成所有需要爬取的URL列表(共274页)
- 调用
getStockData方法获取所有页面的响应内容 - 调用
parseStockData方法解析响应内容 - 调用
saveToExcel方法保存解析后的数据 - 在
if __name__ == '__main__'条件下执行爬虫
技术解析
1. URL分析
东方财富网的股票数据API接口包含多个参数:
fs: 筛选条件,这里包含了沪深京A股的各种类型fields: 需要获取的字段,包括股票代码、名称、价格等信息fid: 排序字段,这里是按涨跌幅(f3)排序pn: 页码,用于分页获取数据pz: 每页数据量,这里是20条po: 排序方式,1表示正序,-1表示倒序dect: 涨跌排序,1表示从高到低
3. 反爬策略
为了避免被东方财富网的反爬机制检测,我们采取了以下措施:
- 使用随机User-Agent,模拟不同浏览器
- 设置随机延时,避免请求过于频繁
- 使用真实的cookie信息,模拟真实用户访问
使用说明
1. 环境准备
在运行本爬虫之前,需要安装以下Python库:
pip install requests fake_useragent openpyxl tqdm
2. 运行爬虫
直接运行Python脚本即可开始爬取数据:
python eastmoney_spider.py
3. 查看结果
爬虫运行完成后,会在当前目录下生成一个名为沪深京A股.xlsx的Excel文件,包含所有爬取的股票数据。
完整代码
import requests
import time
import random
import json
import re
from fake_useragent import UserAgent
from openpyxl import Workbook
from requests import RequestException
from tqdm import tqdm
class Spider:
def __init__(self):
# 网址
self.url = 'https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37105460204350036134_1766485651718&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn={}&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=3349087659401996%7C0%7C1%7C0%7Cweb&_=1766485652135'
# 请求头
self.headers = {
'accept': '*/*',
'cookie': 'qgqp_b_id=e8ba83921090c6053beecad4f3c88070; st_nvi=GUQ3FhlqtzOlDXJPH2xbA08b1; nid18=0960422f276dd5936ecd7ee29674407d; nid18_create_time=1765523847395; gviem=XDeICB7Jr3LMhPsvA__Q_54c8; gviem_create_time=1765523847396; ct=hDO_k-voxfRFYjmowng5dw0yh4ZCAUjnKKhp6bx9cZhhbWCmvRLZTu67FnCfx-qJmJHKtb3Mzc7UrVFmHgw1blyaEwB9AZazy-VJA4cPPpZXhQjNiTBrZbuue4-1isuKYJnyApm3kRvkXRUtfSHdCdq1T2kmFvF9cQYavCH_Kfw; ut=FobyicMgeV5FJnFT189SwCTD-afE_-o0WmQbb2XcesDknwkRU1nHfPuQ6ImQMkuM1-I4GK8CLM1w4U6_nJsSKZDcZh31bBKWs_mJDzZHIxRgTRq-dvO-HiBFlaajnOn7spRk834btMnyY1w9vVbzwsqcQiYN-XYEnlolURhbxJBvvyalHnSHDh4v34PlmuLmO0hA8VBhfmY1jIkfZHoK3es6-f8gRM9zme1Y5pXCrZjcqpqsOHigomP3H9eJiCNKhwOQu9NJSwbCTFkdN5wM6wmI9sWC5GGoe9EwOJpIulgySvWHpqBeV3saYBQDuijmOHocHDUlpGEhdDJz3TRfVGP0W-9q5Qq-; sid=; pi=3349087659401996%3Bc3349087659401996%3B%E8%82%A1%E5%8F%8B289113YC53%3BlzhPMNRbVMQfPjAOD8wMIMZ%2FAYcMCW9dI1rtSXto3VeHvDXYLSI3uO4D%2F7qSe4rWIYIVxNyxHp%2FRJ8oCCmB45OouezeZxqoqt%2Fo%2B1pF9lfQdFFzTO6y2R2XWX8vjpb9a%2FbsSNAJZxUSkZ7YLTPXUrfDX5NgtW%2FR8tGDmC0ZVuHQHydopmpQlv43MYRgKbSCAQGsOsPI1%3BNhZYMq9q6WYpQ0L3ix7wL9sjWHCyyTPmEV0wDIwT60NIcy%2BiU04HRyoduGR%2FTG7IMaM5RgCxZXbeuQAwEdT%2FVQeaqUfzSOuiWpEwPReW%2FFVbn0os2PbncNfcmPAk1RfPXZoOEpLz5aQH0PFbF01jwaTL2khkYw%3D%3D; mtp=1; vtpst=%7C; uidal=3349087659401996%E8%82%A1%E5%8F%8B289113YC53; st_si=01218701979006; fullscreengg=1; fullscreengg2=1; st_asi=delete; st_pvi=74614612474330; st_sp=2025-12-12%2015%3A17%3A26; st_inirUrl=https%3A%2F%2Fcn.bing.com%2F; st_sn=153; st_psi=20251222201116225-113200301321-4245617122',
'User-Agent': UserAgent().random,
}
# 实例化工作薄
self.wb = Workbook()
# 激活默认表
self.ws = self.wb.active
# 写入头(股票的字段)
self.ws.append(
['股票代码', '股票名称', '最新价', '涨跌幅', '涨跌额', '成交量(手)', '成交额', '振幅', '最高', '最低',
'今开', '昨收', '量比', '换手率', '市盈率(动态)', '市净率'])
# 响应网页内容的列表
self.htmlContentList = []
# 股票信息列表
self.stockInfoList = []
# 获取股票数据
def getStockData(self, urls):
"""
:param urls: 页面网址列表
:return: 响应内容的列表
"""
# tqdm - 显示当前进度
for url in tqdm(urls):
# 设置时间间隔
time.sleep(random.uniform(2, 3))
try:
# 向网页发起请求
response = requests.get(url, headers=self.headers)
# 将网页内容添加到列表中
self.htmlContentList.append(response.text)
# 请求错误
except RequestException as requests_e:
print(f'错误:{requests_e}')
# 其他错误
except Exception as e:
print(f'错误:{e}')
print(f'所有页面的数据获取完成!!!')
# 返回响应内容的列表
return self.htmlContentList
# 解析股票数据
def parseStockData(self, StockContents):
"""
:param StockContents: 股票信息列表
:return:
"""
for StockContent in tqdm(StockContents):
try:
# 提取JSON数据
json_data = re.search(r'jQuery\d+_\d+\((.*?)\);', StockContent)
if json_data:
data = json.loads(json_data.group(1))
# 检查返回状态
if data.get('rc') == 0 and data.get('data'):
stockList = data['data'].get('diff', [])
# 遍历股票
for stock in stockList:
# 提取股票信息
stockInfo = [
stock.get('f12', ''), # 股票代码
stock.get('f14', ''), # 股票名称
stock.get('f2', ''), # 最新价
stock.get('f3', ''), # 涨跌幅
stock.get('f4', ''), # 涨跌额
stock.get('f5', ''), # 成交量(手)
stock.get('f6', ''), # 成交额
stock.get('f7', ''), # 振幅
stock.get('f15', ''), # 最高
stock.get('f16', ''), # 最低
stock.get('f17', ''), # 今开
stock.get('f18', ''), # 昨收
stock.get('f10', ''), # 量比
stock.get('f8', ''), # 换手率
stock.get('f9', ''), # 市盈率(动态)
stock.get('f23', '') # 市净率
]
# 将股票信息添加到股票信息列表中
self.stockInfoList.append(stockInfo)
# 将股票信息写入工作表中
self.ws.append(stockInfo)
else:
print(f'{json_data}为空')
except Exception as e:
print(f'错误: {e}')
# 保存excel文件
def saveToExcel(self):
# 先判断股票信息列表是否为空
if self.stockInfoList:
# 保存文件
self.wb.save('沪深京A股.xlsx')
print(f'数据已保存到沪深京A股.xlsx,共{len(self.stockInfoList)}条数据')
else:
print('没有数据需要保存')
# 主程序
def start(self):
# 使用列表推导式生成所有的url
urls = [self.url.format(i) for i in range(1, 275)]
# 获取数据
stockData = self.getStockData(urls)
# 判断stockData中是否有数据
if stockData:
# 解析响应的网页内容
self.parseStockData(stockData)
# 保存到excel文件
self.saveToExcel()
else:
print(f'没有获取到数据')
if __name__ == '__main__':
# 实例化类
easyMoney = Spider()
# 运行程序
easyMoney.start()
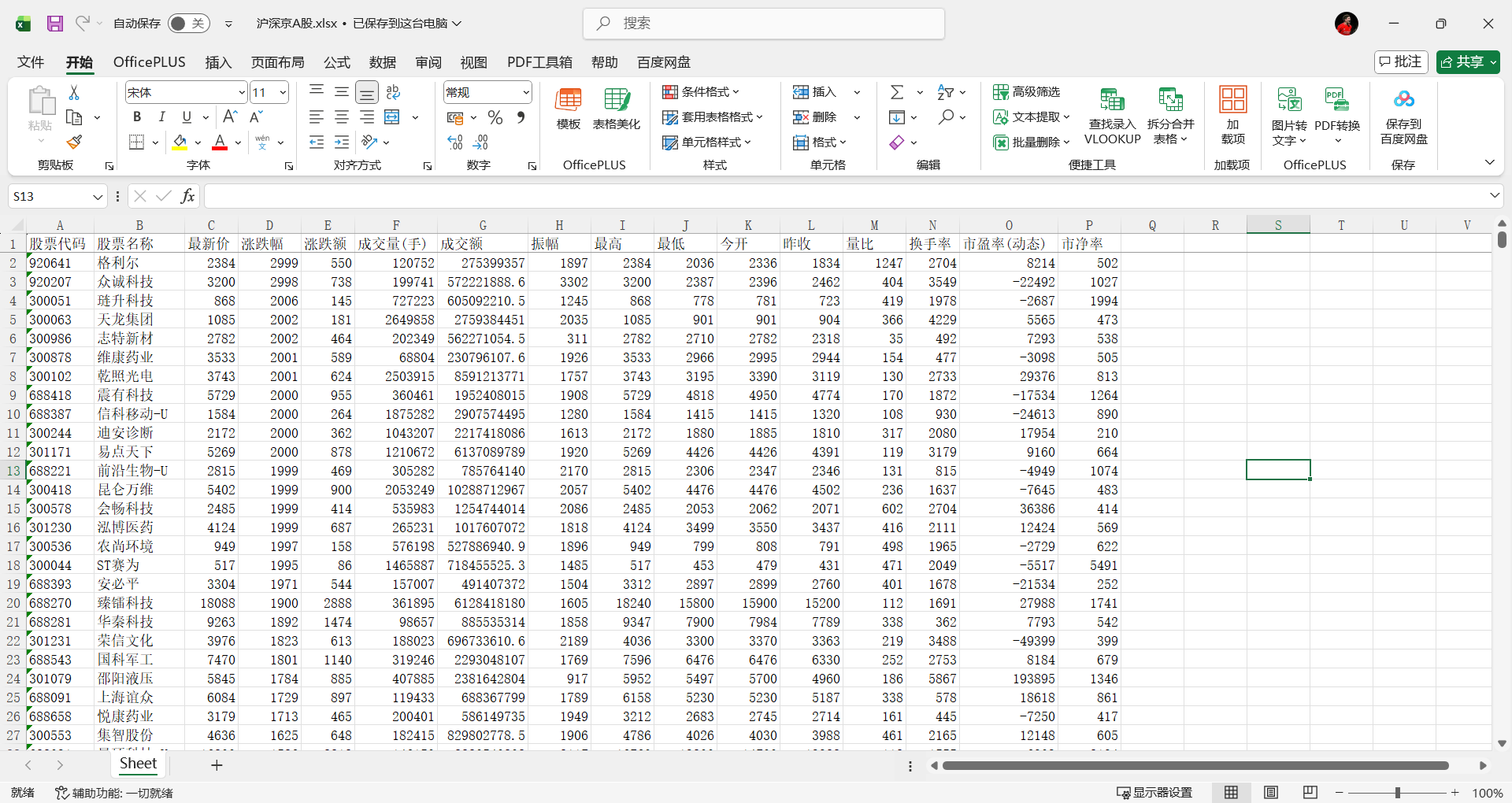
希望这篇文章对你学习Python爬虫有所帮助!如果你有任何问题或建议,欢迎在评论区留言讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)