AI系统的Scale Up与Scale Out
一、Scale Up与Scale Out系统的区别
先以简易方式说明Scale Up与Scale Out系统的区别,虽非绝对严谨(总有一些技术会模糊二者的界限),但有助于建立基本概念:
Scale Up系统:
简单来说,就是让单个系统变得更强大,类似于将一个人训练成大力士。具体方式包括使用更强、更快的CPU、IO设备(如GPU、网络、存储等),以及更大更快的内存。图中右侧的绿色CPU框比左侧更大,即表示性能提升。此外,也可以在单个系统内通过内部总线连接更多CPU或GPU等设备,以数量补充性能不足。这些设备仍处于同一个系统内,由一个主操作系统(或虚拟化技术中的Hypervisor等)统一管理,相当于只有一个“大脑”,调度管理相对简单。
Scale Out系统:
简单来说,就是通过多个系统协作,以数量优势取胜,类似于多人协作可以战胜单个大力士。多个独立的系统通过网络连接组成一个更大的系统,对外提供统一服务。从硬件结构上看,Scale Out的网络连接比Scale Up的内部总线更简单,且扩展上限更高。但从软件层面看,由于每个系统拥有独立的主操作系统(即每个节点有各自的“大脑”),协调多个系统协同工作是一项较大的技术挑战,这也是分布式系统需要解决的核心问题。
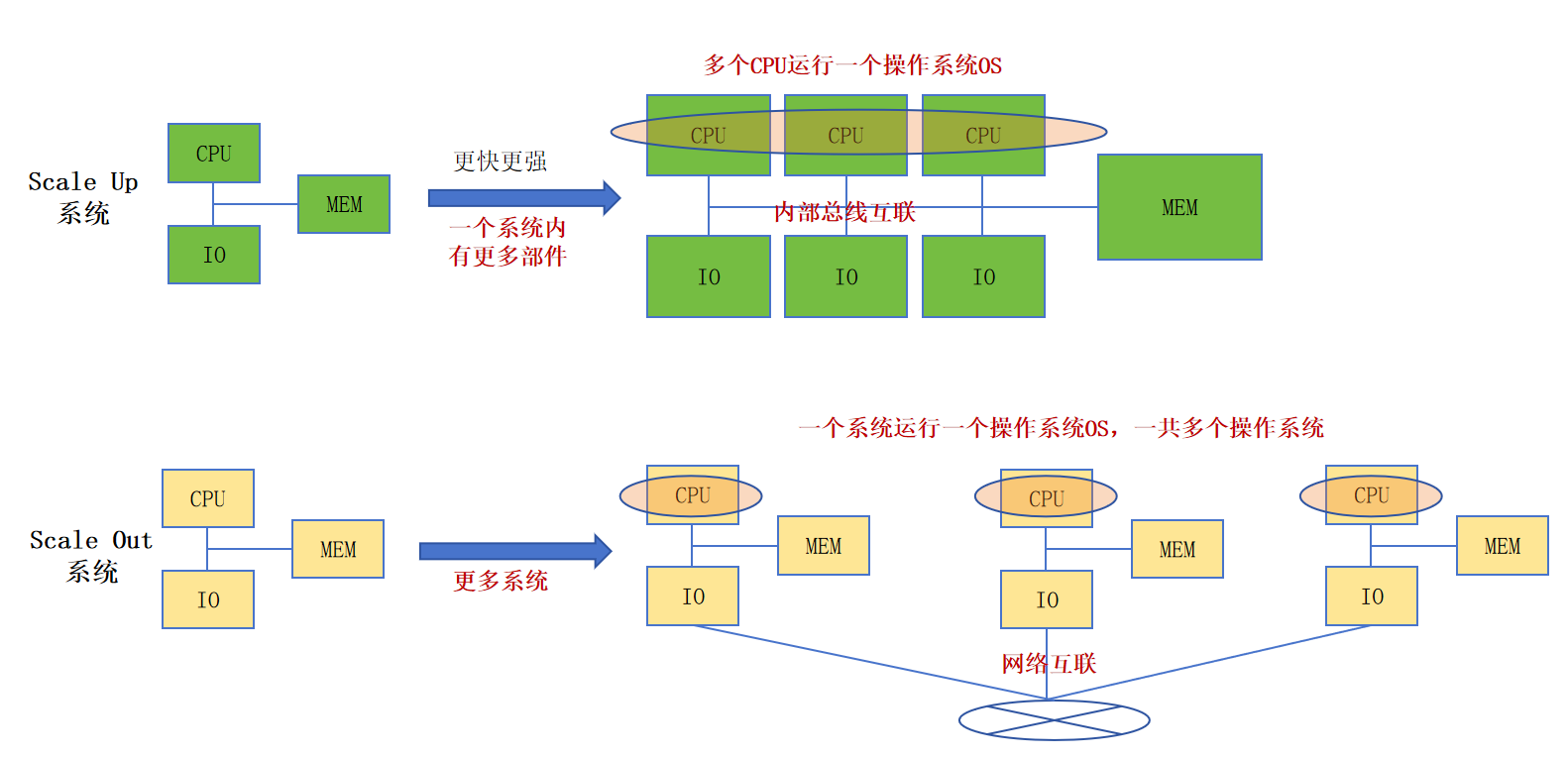 图1 Scale Up与Scale Out系统的区别
图1 Scale Up与Scale Out系统的区别
说明:图1中的IO框代表一个IO设备,可以是GPU、存储、网络等,这些都是当前AI系统中不可或缺的资源。
进一步对比Scale Up的内部总线与Scale Out的网络互联在设备定位上的差异:
对于Scale Up的内部总线:
系统内不同设备会被分配不同的物理地址。现代CPU采用64位地址总线,可为所有设备分配独立的物理地址,依靠这些物理地址来实现不同设备的定位。
对于Scale Out的网络互联:
不同系统依赖网络路由进行定位。例如IB协议有自己的网络层来进行路由,RoCE V2包含IP层,可通过IP路由定位;而RoCE V1(已废弃)无IP层,只能基于MAC地址在子网内定位。因此,访问设备时需先通过网络找到目标系统,再通过该系统内部地址访问具体设备(如GPU)。
因此,对于Scale Out系统的分布式软件而言,需要实现两个层面的资源定位与管理:一是在多个系统中定位目标系统,二是在该系统内定位具体设备(如GPU)。这是一项较大的技术挑战。
从底层软件开发的角度补充Scale Up与Scale Out的区别,如图2所示:
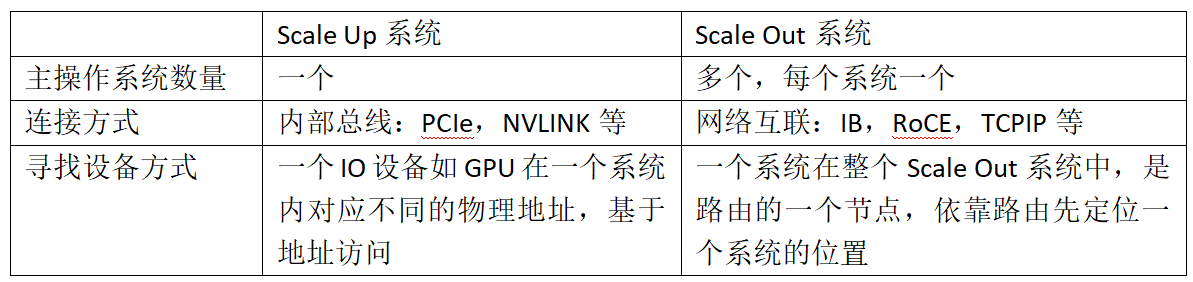 图2 Scale Up与Scale Out从底层软件开发角度的补充
图2 Scale Up与Scale Out从底层软件开发角度的补充
图3为DeepSeek总结的Scale Up与Scale Out系统区别,总体上描述较为清晰:
 图3 Scale Up与Scale Out系统的总体对比(图片来源:DeepSeek)
图3 Scale Up与Scale Out系统的总体对比(图片来源:DeepSeek)
二、Scale Up系统
目前已知最大的Scale Up系统是NVIDIA GB300 NVL72,如图4所示。虽然外观为多个机柜,但仍属一个系统。
 图4 NVIDIA GB300 NVL72系统(图片来源:NVIDIA官网)
图4 NVIDIA GB300 NVL72系统(图片来源:NVIDIA官网)
关键特性如下:
NVIDIA GB300 NVL72
Key Features
- 36颗NVIDIA Grace CPU
- 72颗NVIDIA Blackwell Ultra GPU
- 17 TB LPDDR5X内存(支持ECC)
- 20 TB HBM3E内存
- 高达37 TB高速访问内存
- NVLink域:130 TB/s低延迟GPU通信带宽
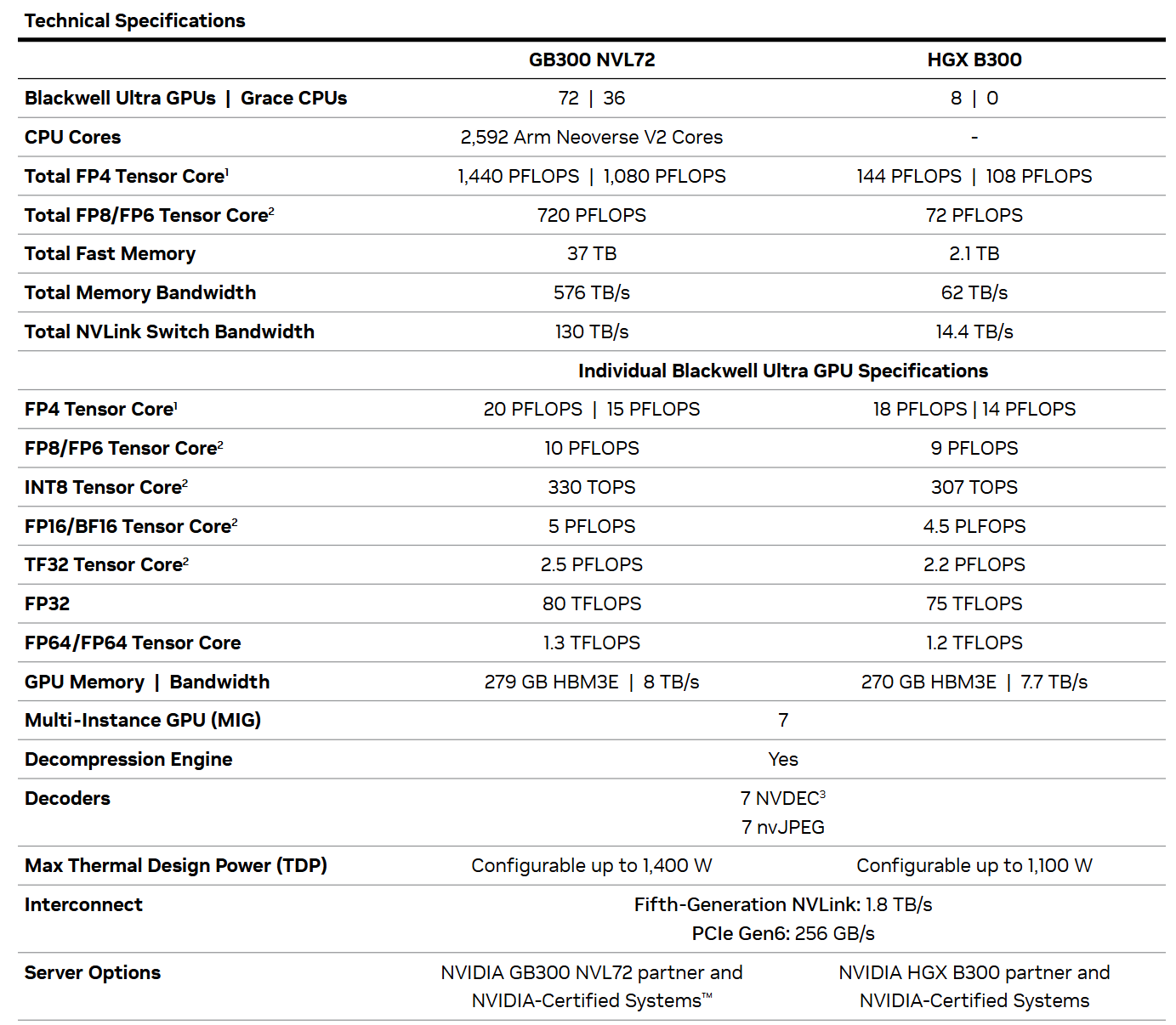 图5 NVIDIA GB300 NVL72系统关键特性(图片来源:nvidia网站)
图5 NVIDIA GB300 NVL72系统关键特性(图片来源:nvidia网站)
如此庞大的系统如何协同工作?根据千问和DeepSeek的说明:
物理机视角:一个巨型服务器
- 理念:NVIDIA通过NVLink-C2C一致性互联,将36颗Grace CPU和72颗B200 GPU在硬件上紧密连接为一个单一的大规模非一致性内存访问(NUMA)系统。
- 结果:系统启动时,一个主控OS内核引导整个硬件集合,识别所有CPU、GPU、内存及互联设备,并将其纳入统一资源池管理。
- 类比:如同在一台拥有36个CPU插槽、72个加速卡和数TB内存的巨型服务器上安装Linux系统,该OS能够“看见”并管理全部硬件。
- 底层运行统一、精简的宿主操作系统(Host OS)。
- 上层通过容器化技术(如Docker、NVIDIA Container Toolkit)及编排系统(如Kubernetes),动态分配系统计算资源(CPU核心、GPU)给不同AI作业。
- 用户视角:用户提交一个需64个GPU的训练任务时,Kubernetes调度器与底层OS协作,从72个GPU中分配连续的64个,并为任务启动容器。在容器内,任务仿佛运行在一个拥有64个GPU的独立服务器上。这种体验正是通过底层统一OS与虚拟化/容器化技术共同实现的。
操作系统说明:
- 数量:并非36个独立OS,而是一个统一但分布式执行的OS。
- 本质:高度定制化的Linux,集成NVIDIA全套加速计算软件栈。
- 协作机制:通过单一内核全局视图 + 分布式守护进程 + 硬件一致性互联 + 容器化编排,实现无缝协作。内核和驱动将36个CPU和72个GPU抽象为“巨型单机”,上层服务与编排系统则在其上高效、安全地并行运行多个AI工作负载。
这种设计完美平衡了硬件紧耦合(追求性能)与软件灵活管理(支持多租户隔离)这两个看似矛盾的需求,体现了NVIDIA从单一GPU到DGX服务器再到NVL72机柜的全栈技术能力。
合作战略:
尽管GB300 NVL72是高度集成的“机架级系统”,内含72颗Blackwell Ultra GPU与36颗Grace CPU,但它并非“开箱即用”的完整服务器,仍需合作伙伴(OEM/ODM)完成多项关键集成与部署工作。
合作伙伴的核心价值在于将NVIDIA芯片与架构转化为可靠、可部署、可运维的数据中心级产品。因此,没有合作伙伴,GB300 NVL72无法真正进入数据中心——这正是NVIDIA“生态系统战略”的关键所在。
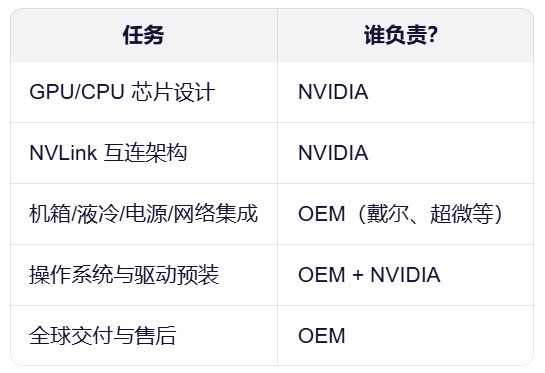
图6 GB300 NVL72的交付分工(图片来源:千问)
以下链接为前代产品的相关博客,可供进一步了解:
<https://developer.nvidia.cn/blog/enabling-multi-node-nvlink-on-kubernetes-for-gb200-and-beyond/>
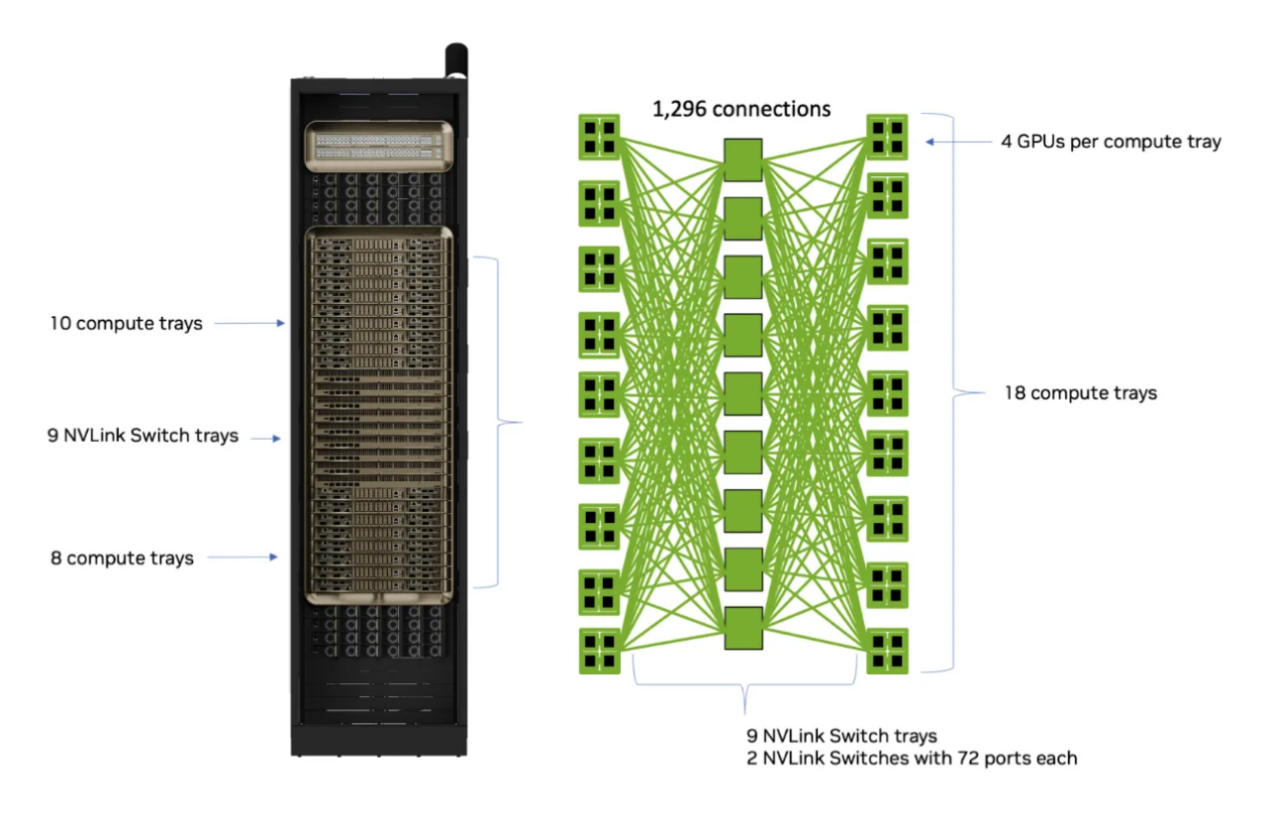 图7 GB200的NVLink说明(图片来源:nvidia网站)
图7 GB200的NVLink说明(图片来源:nvidia网站)
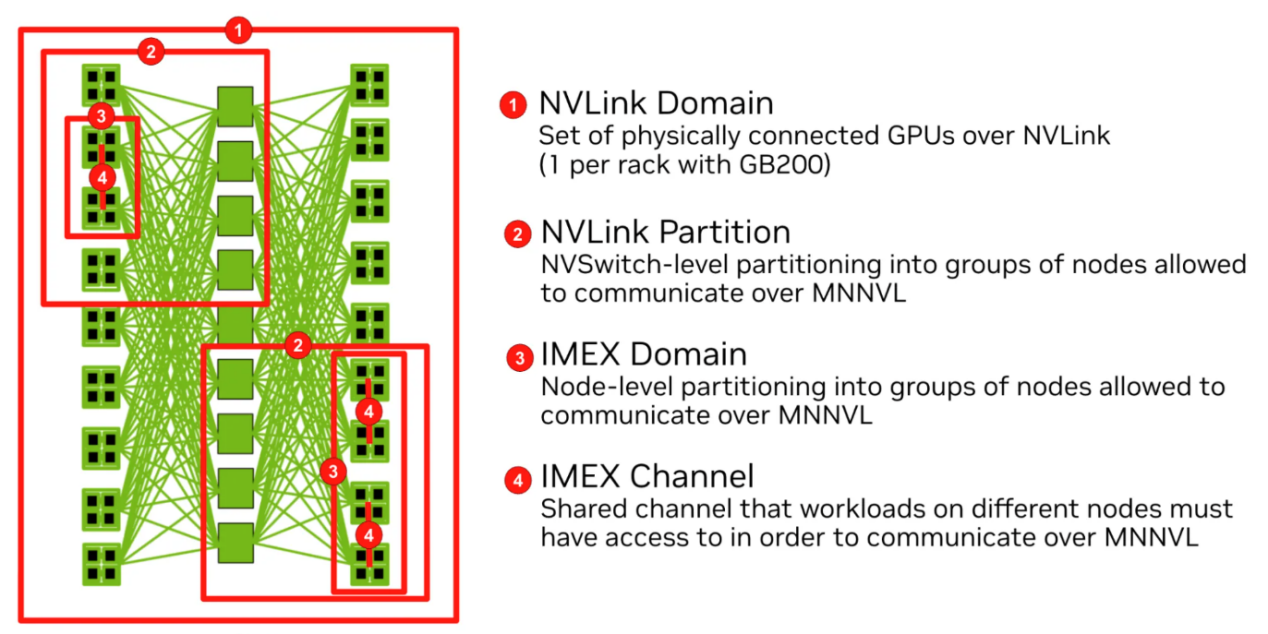 图8 NVLink的管理方式(图片来源:nvidia网站)
图8 NVLink的管理方式(图片来源:nvidia网站)
Kubernetes需具备理解并管理现代GPU系统拓扑的能力。通过将NVLink与IMEX域等底层结构与Kubernetes原生调度及DRA机制集成,计算域有效应对了这一挑战。
三、Scale Out系统
构建Scale Out系统主要有两种思路:
- 经济型方案:使用多个成本较低的硬件系统组合,达到与昂贵Scale Up系统相近的性能。
- 高端扩展方案:由于技术限制,Scale Up系统的内部扩展存在上限,不如Scale Out系统易于扩展。若需构建更大规模的AI系统,可将多个Scale Up系统进一步通过网络互联,组成顶级AI集群。
实际应用中常结合两种思路:选择成本合理的Scale Up系统,购买多台,再通过Scale Out方式连接,以实现成本与性能的平衡。
高端NVL72系统的Scale Out集群配置示例如下:
典型超大规模AI集群采用“三层互联”结构:
- 第一层:NVLink(机柜内Scale-Up)
- 作用:在单个NVL72机柜内,36颗Grace CPU与72颗B200 GPU通过NVLink-C2C/NVSwitch实现全互联,形成带宽达数TB/s的统一计算设备。
- 带宽:GPU间双向带宽高达130 TB/s,延迟极低(纳秒级)。
- 目的:使万亿参数模型的大部分计算可在单机柜内完成,减少跨机柜通信。
- 第二层:InfiniBand(机柜间Scale-Out)
- 作用:每个NVL72机柜通过多个(通常8个或更多)InfiniBand ND网卡接入IB交换网络。
- 带宽:当前主流为NVIDIA Quantum-2 InfiniBand(400 Gb/s),最新的Quantum-X800 InfiniBand(800 Gb/s)已开始部署。每个NVL72机柜可提供超过6.4 TB/s(8端口×800 Gb/s)的对外聚合带宽。
- 目的:处理机柜间模型并行通信、数据并行梯度同步(All-Reduce)及检查点读写。
- 第三层:存储/管理网络(以太网)
- 用于集群管理、监控、数据加载等任务。
互联实现方式:
每个NVL72机柜内,CPU通过PCIe连接多个InfiniBand网卡。
软件层面:
- 使用NVIDIA集体通信库(NCCL)进行通信优化。
- NCCL自动识别拓扑:机柜内走高速NVLink,跨机柜走InfiniBand。
- GPUDirect RDMA技术允许数据直接在跨机柜的GPU内存间传输,绕过CPU和主机内存,显著降低延迟与CPU开销。
扩展挑战与解决方案:
- 挑战:跨机柜带宽(TB/s级)远低于机柜内带宽(PB/s级),易成为性能瓶颈。
- 解决方案:
1. 模型并行策略优化:将通信密集层(如注意力层)尽量置于同一机柜内;通信较少层(如MLP层)跨机柜分割。
2. 通信与计算重叠:在计算同时异步执行跨机柜数据预取与梯度发送。
3. 分层All-Reduce:先在机柜内执行All-Reduce,再在机柜间进行第二次,大幅减少跨机柜通信量。
图9是当前的2代GPU集群的对比:
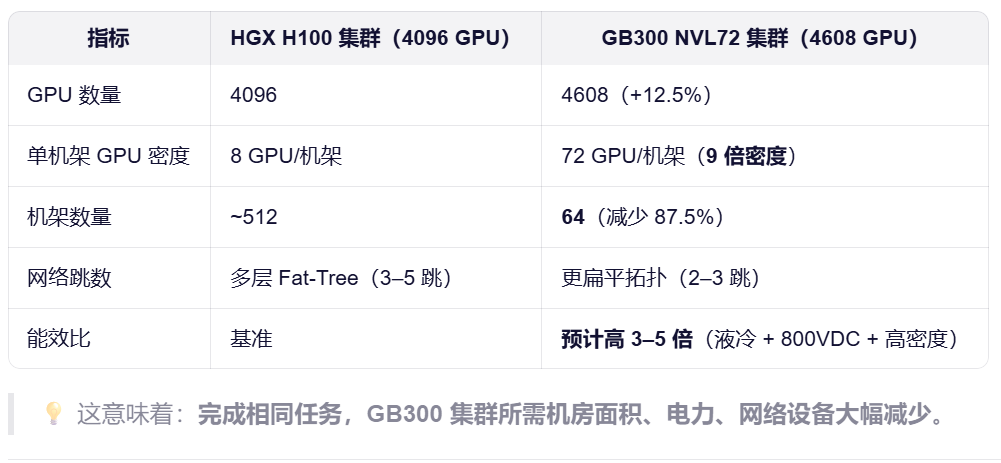 图9 高端AI集群架构示意图(图片来源:千问)
图9 高端AI集群架构示意图(图片来源:千问)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)