递归语言模型(RLM)——让大模型告别“上下文腐烂“,处理能力暴涨100倍!
MIT团队提出递归语言模型(RLM),突破大语言模型处理长文本的瓶颈。RLM创新性地将长文本作为外部环境变量,让模型通过编写代码递归调用子模型处理信息,实现10M+ token级别的超长文本处理能力。相比传统方法,RLM采用"分而治之"策略,避免了上下文窗口限制和二次方计算成本增长,性能提升可达100倍。该技术借鉴外存算法思想,使模型能像程序员一样按需查阅信息,而非硬记全部内容
递归语言模型(RLM)——让大模型告别"上下文腐烂",处理能力暴涨100倍!
一句话总结:MIT研究团队提出递归语言模型(RLM),通过将长文本作为外部环境变量,让LLM像程序员一样编写代码递归处理信息,成功突破上下文窗口限制,实现10M+ token级别的超长文本处理能力。
📖 论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Recursive Language Models |
| 作者 | Alex L. Zhang, Tim Kraska, Omar Khattab |
| 机构 | MIT CSAIL |
| 发布时间 | 2025年12月31日 |
| 论文链接 | arXiv:2512.24601 |
| 代码仓库 | GitHub: alexzhang13/rlm |
🎯 研究背景:大模型的"记忆困境"
你是否遇到过这样的场景?
想象一下:你给ChatGPT喂了一份500页的合同文档,然后问它第327页的某个关键条款是什么。结果呢?模型可能会"一脸茫然",甚至给你一个似是而非的答案。
这不是你的错,也不完全是模型的错——这是当前所有大语言模型都面临的一个根本性问题:上下文腐烂(Context Rot)。
什么是"上下文腐烂"?
就像人类阅读一本厚厚的小说时,读到后面可能会忘记前面的细节一样,大语言模型在处理超长文本时也会出现类似的"记忆衰退"现象。
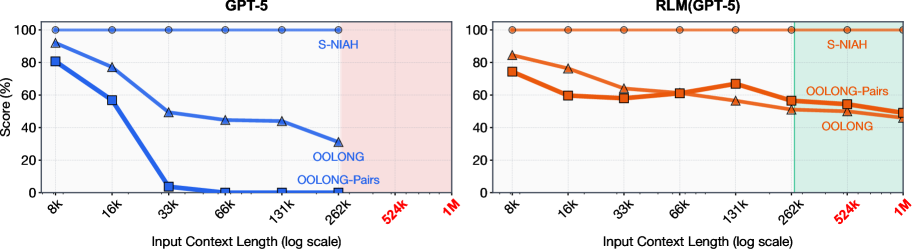
图1:GPT-5在不同长度输入下的性能表现。随着输入长度增加,模型性能急剧下降,这就是"上下文腐烂"现象。
MIT的研究团队发现,即使是像GPT-5这样的顶级模型,在处理超长文本时也难逃这一命运:
- 短文本:模型表现优秀,准确率高
- 中等长度:性能开始下滑
- 超长文本:性能断崖式下跌,几乎"失忆"
现有解决方案的困境
目前业界主要有两种应对策略:
| 方案 | 做法 | 问题 |
|---|---|---|
| 扩大上下文窗口 | 通过架构改进支持更长输入 | 计算成本呈二次方增长,且仍有上限 |
| 上下文压缩/摘要 | 先压缩再处理 | 信息损失,可能丢失关键细节 |
这就像是在问:我们是应该给大脑装一个更大的"硬盘",还是学会更聪明地"查资料"?
MIT的研究者们选择了后者——他们提出了一个革命性的思路:让大模型学会像程序员一样工作。
🧠 核心思想:从"死记硬背"到"按需查阅"
灵感来源:外存算法
RLM的核心思想借鉴了计算机科学中一个经典概念——外存算法(Out-of-core Algorithms)。
想象你是一个图书管理员,需要处理一个涉及图书馆所有藏书的复杂查询。你有两种选择:
- 传统方式:把所有书都搬到你面前的桌子上(显然桌子放不下)
- 聪明方式:根据需要去书架上取特定的书,看完放回,再取下一本
RLM选择的就是第二种"聪明方式"——不要把长文本硬塞进模型的"大脑",而是把它当作外部环境的一部分,让模型按需访问。
RLM的核心洞见
长提示词不应该直接输入神经网络,而应该被视为LLM可以进行符号化交互的环境的一部分。
这是一个范式转换:
| 传统方式 | RLM方式 |
|---|---|
| 文本 → 直接输入模型 | 文本 → 存储为环境变量 |
| 模型被动接收 | 模型主动查询 |
| 一次性处理 | 递归分解处理 |
| 受限于上下文窗口 | 理论上无限制 |
🏗️ 技术架构:RLM是如何工作的?
整体架构图
图2:递归语言模型(RLM)架构示意图。RLM将提示词加载到Python REPL环境中,允许LLM编写代码来检查、分解并递归调用自身。
工作流程详解
RLM的工作流程可以分为以下几个关键步骤:
步骤1:初始化REPL环境
当收到一个长提示词P时,RLM首先初始化一个**Python REPL(Read-Eval-Print Loop)**环境,并将提示词设置为一个变量的值。
# 伪代码示意
context = """
[这里是用户输入的超长文本,可能有几百万个token]
"""
步骤2:LLM编写代码进行探索
接下来,LLM被赋予了"程序员"的能力——它可以编写Python代码来:
- 查看上下文的特定部分
- 使用正则表达式过滤信息
- 对数据进行分析和处理
# LLM可能生成的代码示例
import re
# 查找所有包含"关键条款"的段落
matches = re.findall(r'.*关键条款.*', context)
print(f"找到 {len(matches)} 个相关段落")
# 查看第一个匹配
print(matches[0][:500])
步骤3:递归调用子LLM
这是RLM最强大的特性——递归调用。当遇到复杂问题时,LLM可以将任务分解,并调用"子LLM"来处理子任务。
# LLM可能生成的递归调用代码
def process_chunk(chunk, question):
# 调用子LLM处理这个片段
result = sub_llm.completion(f"根据以下内容回答问题:\n{chunk}\n\n问题:{question}")
return result
# 将长文本分块处理
chunks = split_into_chunks(context, chunk_size=10000)
results = [process_chunk(chunk, user_question) for chunk in chunks]
# 聚合结果
final_answer = aggregate_results(results)
步骤4:聚合结果并输出
最后,RLM将所有子任务的结果聚合起来,生成最终答案。
类比理解:RLM就像一个高效的研究团队
想象RLM是一个研究团队的负责人:
- 接收任务:老板给了一个涉及海量资料的研究课题
- 制定计划:负责人不会自己读完所有资料,而是制定研究计划
- 分配任务:将资料分给团队成员(子LLM),每人负责一部分
- 收集汇报:团队成员完成后汇报结果
- 综合结论:负责人综合所有汇报,给出最终答案
这种"分而治之"的策略,让RLM能够处理远超单个模型能力的超长文本。
🔧 实现细节:深入技术内核
REPL环境的设计
RLM的REPL环境提供了以下核心能力:
| 能力 | 描述 |
|---|---|
| 变量存储 | 将输入上下文存储为Python变量 |
| 代码执行 | 执行LLM生成的Python代码 |
| 状态持久 | 保持执行状态,支持多轮交互 |
| 子LLM调用 | 提供接口调用子语言模型 |
支持的运行环境
根据开源代码库,RLM支持多种运行环境:
┌─────────────────────────────────────────────────────────┐
│ RLM 运行环境 │
├─────────────────────────────────────────────────────────┤
│ 非隔离环境: │
│ └── Local: 在主进程中直接执行 (适合本地开发) │
│ │
│ 隔离环境: │
│ ├── Docker: 使用容器隔离执行 │
│ ├── Modal Sandboxes: 云端沙箱环境 │
│ └── Prime Intellect: Beta阶段 │
└─────────────────────────────────────────────────────────┘
代码使用示例
from rlm import RLM
# 初始化RLM
rlm = RLM(
backend="openai",
backend_kwargs={"model_name": "gpt-5-nano"},
verbose=True,
)
# 处理超长文本任务
long_document = open("500_page_contract.txt").read() # 假设有500页的合同
response = rlm.completion(
f"请分析以下合同,找出所有涉及违约责任的条款:\n\n{long_document}"
)
print(response.response)
系统提示词设计
RLM使用精心设计的系统提示词来引导LLM的行为。核心要点包括:
- 环境说明:告知LLM它处于一个Python REPL环境中
- 能力说明:说明可以编写代码、调用子LLM
- 策略引导:鼓励分解复杂任务、递归处理
🧪 实验设计:全方位的能力验证
评估任务设计
研究者精心设计了5个不同复杂度的任务来全面评估RLM:
| 任务 | 复杂度 | 描述 | 核心挑战 |
|---|---|---|---|
| S-NIAH | O(1) | 单针测试 | 在海量文本中找到特定信息 |
| BrowseComp-Plus | 多跳 | 1K文档问答 | 需要整合多个文档的信息 |
| OOLONG | O(n) | 长推理任务 | 需要对输入进行语义转换和聚合 |
| OOLONG-Pairs | O(n²) | 成对推理 | 需要处理所有数据对的关系 |
| LongBench-v2 CodeQA | 代码理解 | 代码库问答 | 理解大型代码库结构 |
任务复杂度的直观理解
- O(1) - 大海捞针:就像在一本1000页的书中找一个特定的句子
- O(n) - 线性聚合:就像统计一本书中所有人物的出场次数
- O(n²) - 二次复杂度:就像分析书中所有人物两两之间的关系
对比方法
研究者将RLM与以下方法进行了对比:
- Base Model:直接使用基础LLM处理
- CodeAct (+ BM25):在ReAct循环中执行代码,配备BM25检索器
- Summary Agent:迭代总结上下文的代理
- RLM (no sub-calls):消融实验,禁用递归调用
📊 实验结果:令人惊叹的性能提升
主要结果表格
图3:不同方法在各任务上的性能对比。RLM在所有任务上都显著优于基线方法。
表1:GPT-5和Qwen3-Coder-480B在各任务上的性能对比
| 模型 | 方法 | CodeQA | BrowseComp+ | OOLONG | OOLONG-Pairs |
|---|---|---|---|---|---|
| Qwen3-Coder-480B | Base Model | 20.00* | 0.00* | 36.00 | 0.06 |
| CodeAct | 24.00* | 12.66 | 38.00 | 0.28 | |
| Summary Agent | 50.00 | 38.00 | 44.06 | 0.31 | |
| RLM | 56.00 | 44.66 | 48.00 | 23.11 | |
| GPT-5 | Base Model | 24.00* | 0.00* | 44.00 | 0.04 |
| CodeAct | 22.00* | 51.00 | 38.00 | 24.67 | |
| Summary Agent | 58.00 | 70.47 | 46.00 | 0.01 | |
| RLM | 62.00 | 91.33 | 56.50 | 58.00 |
注:带号表示该方法因上下文限制无法处理完整输入*
关键发现
发现1:RLM可扩展至10M+ token级别
这是最令人兴奋的发现——RLM成功处理了超出模型上下文窗口两个数量级的输入!
传统模型上下文窗口:~100K tokens
RLM有效处理能力:10M+ tokens
提升倍数:100倍以上!
发现2:在复杂任务上性能提升惊人
特别是在OOLONG-Pairs这个O(n²)复杂度的任务上:
| 方法 | F1分数 | 提升 |
|---|---|---|
| Base Model (GPT-5) | 0.04% | - |
| RLM (GPT-5) | 58.00% | 1450倍 |
这意味着在需要处理复杂长程依赖的任务上,RLM实现了质的飞跃!
发现3:成本效益出色
图4:不同方法在各百分位数下的API成本对比。RLM的中位数成本与基础模型相当,甚至更低。
研究发现,RLM的推理成本与直接调用基础模型相当:
- 中位数成本:通常低于基础模型
- 尾部成本:由于轨迹长度差异,可能较高
- 整体评估:成本效益优秀
发现4:递归调用是关键
消融实验表明,递归子调用在信息密集型任务上提供了巨大优势:
| 配置 | OOLONG-Pairs F1 |
|---|---|
| RLM (no sub-calls) | 43.93% |
| RLM (with sub-calls) | 58.00% |
递归调用带来了14个百分点的提升!
🔬 涌现行为:RLM学会了什么?
研究者观察到RLM在解决问题时展现出了一些有趣的涌现行为模式:
模式1:基于先验知识的代码过滤
RLM会利用模型的先验知识,编写针对性的过滤代码:
# RLM生成的代码示例
import re
# 基于对任务的理解,使用正则表达式过滤
relevant_sections = re.findall(
r'第\d+条.*?(?=第\d+条|$)',
contract_text,
re.DOTALL
)
模式2:智能分块与递归调用
RLM会自动将大任务分解为小任务:
# RLM生成的分块处理代码
def analyze_document(doc, chunk_size=5000):
chunks = [doc[i:i+chunk_size] for i in range(0, len(doc), chunk_size)]
results = []
for i, chunk in enumerate(chunks):
# 递归调用子LLM处理每个块
result = sub_llm(f"分析第{i+1}部分:\n{chunk}")
results.append(result)
return aggregate(results)
模式3:答案验证
RLM会通过子调用或代码执行来验证答案的正确性:
# 验证答案
def verify_answer(answer, context):
# 在原文中查找支持证据
evidence = find_evidence(context, answer)
if not evidence:
# 重新分析
return re_analyze(context)
return answer
模式4:长输出任务的递归构建
对于需要生成长输出的任务,RLM会通过变量传递递归构建最终答案:
# 递归构建长输出
output = ""
for section in sections:
section_output = sub_llm(f"为以下内容生成摘要:\n{section}")
output += section_output + "\n\n"
# 最终整合
final_output = sub_llm(f"整合以下各部分摘要:\n{output}")
🔄 与相关工作的对比
长上下文处理方法分类
| 类别 | 代表方法 | 特点 | RLM的优势 |
|---|---|---|---|
| 架构改进 | RULER, LongLoRA | 需要重新训练模型 | 无需重训练,即插即用 |
| 上下文压缩 | MemWalker, ReSum | 显式内存管理 | 隐式管理,更自然 |
| 检索增强 | RAG, BM25 | 依赖检索质量 | 可编程,更灵活 |
| 代理方法 | CodeAct, ReAct | 固定工作流 | 自主决策,可递归 |
RLM的独特之处
- 模型无关:适用于任何LLM,不需要修改模型架构
- 任务无关:通用推理策略,不针对特定任务设计
- 自主决策:LLM自己决定何时、如何递归调用
- 符号化交互:通过代码与上下文交互,更精确可控
⚠️ 局限性与未来方向
当前局限性
-
同步调用开销
- 当前实现使用同步子调用
- 异步调用可能进一步降低延迟和成本
-
递归深度限制
- 目前主要探索了浅层递归
- 更深层次的递归策略有待研究
-
安全性考虑
- 执行LLM生成的代码存在安全风险
- 需要更完善的沙箱机制
未来研究方向
| 方向 | 描述 | 潜在影响 |
|---|---|---|
| 异步子调用 | 并行处理多个子任务 | 显著降低延迟 |
| 专门训练 | 训练专门的RLM模型 | 提升效率和性能 |
| 深度递归 | 探索更深层次的递归策略 | 处理更复杂的任务 |
| 安全沙箱 | 更完善的代码执行隔离 | 提高安全性 |
💡 深度思考:RLM对AI发展的启示
启示1:从"大脑扩容"到"工具使用"
RLM代表了一种思维方式的转变:与其不断扩大模型的"记忆容量",不如让模型学会更聪明地使用工具。这与人类的认知发展路径惊人地相似——我们不是靠记住所有知识,而是靠学会如何查找和使用知识。
启示2:递归是智能的关键特征
递归能力——将复杂问题分解为简单子问题的能力——是人类智能的核心特征之一。RLM将这种能力赋予了语言模型,这可能是迈向更通用AI的重要一步。
启示3:符号与神经的融合
RLM巧妙地结合了符号计算(代码执行)和神经计算(LLM推理),这种混合架构可能代表了AI系统设计的未来趋势。
对实践者的建议
- 不要盲目追求长上下文:更长的上下文窗口不一定带来更好的效果
- 考虑使用RLM范式:对于超长文本任务,RLM可能是更好的选择
- 关注成本效益:RLM在保持性能的同时可能降低成本
🔗 资源链接
| 资源 | 链接 |
|---|---|
| 📄 论文 | arXiv:2512.24601 |
| 💻 代码 | GitHub: alexzhang13/rlm |
| 📖 HTML版本 | arXiv HTML |
📝 总结
递归语言模型(RLM)是MIT CSAIL团队提出的一项突破性研究,它通过一个简单而优雅的思路——将长文本作为外部环境,让LLM通过编程方式递归处理——成功突破了大语言模型的上下文窗口限制。
核心贡献
- 范式创新:提出将长提示词视为外部环境的新范式
- 能力突破:实现10M+ token级别的超长文本处理
- 性能飞跃:在复杂任务上实现数十倍甚至上千倍的性能提升
- 成本可控:在提升性能的同时保持甚至降低成本
- 开源贡献:提供完整的开源实现,方便社区使用和改进
一句话评价
RLM告诉我们:让AI学会"查资料",比让AI"死记硬背"更聪明。
这项研究不仅解决了一个实际问题,更重要的是,它为我们展示了一种思考AI系统设计的新方式。在追求更大模型、更长上下文的浪潮中,RLM提醒我们:有时候,聪明地使用工具比单纯扩大能力更重要。
如果觉得有帮助,欢迎点赞、转发、在看三连! 👍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)