SimpleMem:让AI智能体拥有“过目不忘“的高效记忆系统
摘要:SimpleMem提出了一种高效的三阶段记忆系统,解决LLM智能体的"健忘症"问题。通过语义结构化压缩、递归整合和自适应检索,该系统在LoCoMo基准测试中实现43.24的平均F1分数,比现有方法提升26.4%,同时将Token消耗降低30倍至530-580。其创新点包括:1)非线性门控过滤低信息量内容;2)多视图索引支持精确检索;3)动态调整检索深度。实验表明Simpl
SimpleMem:让AI智能体拥有"过目不忘"的高效记忆系统
一句话总结:SimpleMem通过"语义无损压缩"的三阶段流水线,将LLM智能体的记忆效率提升30倍,同时准确率提高26.4%,让AI既能"记得住"又能"记得准"。
📖 引言:AI的"健忘症"困境
想象一下,你有一个私人助理,每次见面都要重新自我介绍,完全不记得上周你们讨论过的项目进展。这就是当前大多数AI智能体面临的尴尬处境——它们患有严重的"健忘症"。
在与用户的长期交互中,LLM智能体需要记住大量历史信息:用户的偏好、之前的对话内容、做出的承诺等。但现有的解决方案要么像"囤积癖"一样保留所有对话历史(导致Token爆炸),要么像"过度筛选"一样丢失关键信息。
来自UC Santa Cruz、UNC Chapel Hill等机构的研究团队提出了SimpleMem——一个受"语义无损压缩"原则启发的高效记忆框架。就像人类大脑会自动将零散的经历整合成有意义的记忆一样,SimpleMem能够智能地压缩、整合和检索信息,在保持高准确率的同时,将Token消耗降低了30倍。
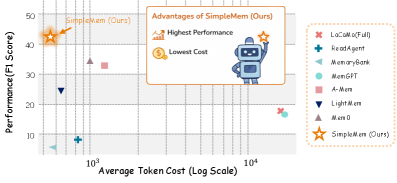
图1:性能与效率的权衡对比。SimpleMem(红色星形)在准确率(F1分数)和效率(Token消耗)两个维度上都达到了最优,位于帕累托前沿的最佳位置。相比之下,全上下文方法(如LoCoMo)虽然准确但Token消耗巨大,而其他记忆方法要么准确率不足,要么效率不够。
🎯 核心问题:记忆系统的两难困境
问题1:上下文膨胀(Context Bloat)
传统方法通过扩展上下文窗口来保留完整的交互历史。这就像用一个巨大的文件夹保存所有邮件——虽然信息完整,但查找效率极低,而且存储成本惊人。
具体数据:在LoCoMo基准测试中,全上下文方法每次查询需要消耗约16,900个Token,这不仅成本高昂,还会导致模型"迷失"在海量信息中。
问题2:迭代推理的高成本
另一类方法(如A-Mem)通过多轮推理来过滤噪声信息。这就像让秘书反复阅读所有文件来找到关键信息——虽然能提高精度,但时间和计算成本都很高。
核心矛盾:如何在"记得全"和"记得准"之间找到平衡?
🧠 SimpleMem:三阶段记忆流水线
SimpleMem的核心思想是将记忆视为一个代谢过程——就像人体会消化食物、吸收营养、排出废物一样,SimpleMem会过滤噪声、提取精华、整合知识。
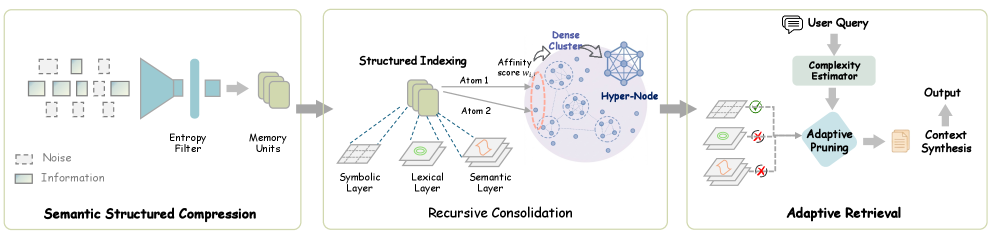
图2:SimpleMem的三阶段架构。左侧是语义结构化压缩阶段,将对话转换为原子事实;中间是递归整合阶段,将相关原子事实合成为高阶"分子"洞察;右侧是自适应检索阶段,根据查询复杂度动态调整检索深度。
🔧 阶段1:语义结构化压缩(Semantic Structured Compression)
生活化比喻:这就像记者整理采访笔记——把冗长的对话提炼成简洁的要点。
1.1 信息过滤:识别"有价值"的对话
并非所有对话都值得记忆。SimpleMem使用非线性门控机制来评估每段对话的信息密度:
H ( W t ) = α ⋅ E n e w ( W t ) + β ⋅ S n o v e l ( W t ) H(W_t) = \alpha \cdot E_{new}(W_t) + \beta \cdot S_{novel}(W_t) H(Wt)=α⋅Enew(Wt)+β⋅Snovel(Wt)
其中:
- E n e w ( W t ) E_{new}(W_t) Enew(Wt):新实体的引入数量(比如首次提到的人名、地点)
- S n o v e l ( W t ) S_{novel}(W_t) Snovel(Wt):语义新颖性(与历史对话的差异程度)
- α , β \alpha, \beta α,β:权重系数
直觉解释:如果一段对话只是在重复之前说过的内容(比如"好的"、"没问题"这类确认性回复),它的信息分数就会很低,会被自动过滤掉。
1.2 上下文归一化:让记忆"独立可理解"
通过过滤的对话需要进一步处理,确保每条记忆单元都是自包含的——即使脱离原始上下文也能被理解。
这个过程包括三个关键操作:
| 操作 | 功能 | 示例 |
|---|---|---|
| 指代消解 Φ c o r e f \Phi_{coref} Φcoref | 将代词替换为具体实体 | “他明天来” → “张三明天来” |
| 时间锚定 Φ t i m e \Phi_{time} Φtime | 相对时间转绝对时间 | “下周五” → “2025-01-17” |
| 事实提取 Φ e x t r a c t \Phi_{extract} Φextract | 识别候选事实陈述 | 提取核心信息点 |
代码示例:
# 上下文归一化示例
def normalize_memory(dialogue, current_time):
# 指代消解
resolved = resolve_coreference(dialogue)
# "他说明天来" → "张三说明天来"
# 时间锚定
anchored = anchor_time(resolved, current_time)
# "张三说明天来" → "张三说2025-01-10来"
# 事实提取
facts = extract_facts(anchored)
# 返回: ["张三计划于2025-01-10到达"]
return facts
🔧 阶段2:结构化索引与递归整合
生活化比喻:这就像图书馆的分类系统——不仅要给每本书编目,还要定期整理书架,把相关的书放在一起。
2.1 多视图索引:三维度检索支持
每个记忆单元通过三种互补的方式进行索引:
| 索引层 | 技术 | 适用场景 |
|---|---|---|
| 语义层 | 密集向量嵌入 | 模糊匹配、语义相似检索 |
| 词汇层 | BM25稀疏表示 | 精确关键词匹配 |
| 符号层 | 结构化元数据 | 时间范围、实体类型过滤 |
为什么需要三层? 单一索引方式各有局限:
- 纯语义检索可能漏掉精确匹配
- 纯关键词检索无法理解同义词
- 时间过滤需要精确的元数据支持
2.2 递归整合:从"原子"到"分子"
随着记忆积累,SimpleMem会在后台异步地将相关记忆整合为更高层次的抽象。
整合公式:
ω i j = γ ⋅ sim ( m i , m j ) + ( 1 − γ ) ⋅ temporal_proximity ( m i , m j ) \omega_{ij} = \gamma \cdot \text{sim}(m_i, m_j) + (1-\gamma) \cdot \text{temporal\_proximity}(m_i, m_j) ωij=γ⋅sim(mi,mj)+(1−γ)⋅temporal_proximity(mi,mj)
当一组记忆单元形成密集簇时,系统执行整合操作:
M a b s = G s y n ( { m 1 , m 2 , . . . , m k } ) M_{abs} = \mathcal{G}_{syn}(\{m_1, m_2, ..., m_k\}) Mabs=Gsyn({m1,m2,...,mk})
具体示例:
| 原子记忆(Atomic) | 分子记忆(Molecular) |
|---|---|
| “用户1月5日点了拿铁” | “用户习惯早上喝咖啡” |
| “用户1月6日点了美式” | |
| “用户1月7日点了卡布奇诺” |
这种整合不仅减少了存储量,还提升了检索的语义层次——当用户问"我的饮品偏好是什么"时,系统可以直接返回高层抽象,而不需要遍历所有历史订单。
🔧 阶段3:自适应查询感知检索
生活化比喻:这就像一个聪明的图书管理员——简单问题快速回答,复杂问题深入查找。
3.1 混合评分函数
检索时,SimpleMem综合考虑多个维度:
S ( q , m k ) = λ 1 ⋅ semantic_sim ( q , m k ) + λ 2 ⋅ BM25 ( q , m k ) + λ 3 ⋅ constraint ( q , m k ) \mathcal{S}(q, m_k) = \lambda_1 \cdot \text{semantic\_sim}(q, m_k) + \lambda_2 \cdot \text{BM25}(q, m_k) + \lambda_3 \cdot \text{constraint}(q, m_k) S(q,mk)=λ1⋅semantic_sim(q,mk)+λ2⋅BM25(q,mk)+λ3⋅constraint(q,mk)
3.2 动态检索深度
SimpleMem会估计查询的复杂度 C q ∈ [ 0 , 1 ] C_q \in [0,1] Cq∈[0,1],并据此调整检索范围:
k d y n = ⌊ k b a s e ⋅ ( 1 + δ ⋅ C q ) ⌋ k_{dyn} = \lfloor k_{base} \cdot (1 + \delta \cdot C_q) \rfloor kdyn=⌊kbase⋅(1+δ⋅Cq)⌋
| 查询复杂度 | 检索策略 | Token消耗 |
|---|---|---|
| 低 ( C q → 0 C_q \to 0 Cq→0) | 仅检索分子头部摘要 | ~100 tokens |
| 高 ( C q → 1 C_q \to 1 Cq→1) | 扩展至详细原子上下文 | ~1000 tokens |
示例:
- 简单查询:“用户喜欢什么咖啡?” → 直接返回分子记忆
- 复杂查询:“用户上周三在哪家店点了什么?” → 需要检索具体原子记忆
🧪 实验结果:全面碾压的性能表现
实验设置
- 数据集:LoCoMo benchmark(200-400轮对话,测试长期对话依赖性)
- 基线方法:LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem、LightMem、Mem0
- 测试模型:GPT-4o、GPT-4.1-mini、Qwen-Plus、Qwen2.5 (1.5B/3B)、Qwen3 (1.7B/8B)
主要结果
表1:GPT-4.1-mini上的性能对比
| 方法 | 单跳F1 | 多跳F1 | 时间推理F1 | 开放域F1 | 平均F1 | Token消耗 |
|---|---|---|---|---|---|---|
| LoCoMo (全上下文) | 19.46 | 16.00 | 21.14 | 18.19 | 18.70 | 16,900 |
| MemGPT | 21.34 | 18.52 | 23.67 | 20.11 | 20.91 | 16,900 |
| ReadAgent | 23.18 | 20.45 | 25.89 | 22.34 | 22.97 | 2,100 |
| MemoryBank | 25.67 | 22.11 | 27.45 | 24.56 | 24.95 | 1,800 |
| A-Mem | 31.45 | 28.67 | 35.23 | 34.98 | 32.58 | 1,200+ |
| LightMem | 24.12 | 21.34 | 26.78 | 26.29 | 24.63 | 850 |
| Mem0 | 33.21 | 30.45 | 37.12 | 36.02 | 34.20 | 980 |
| SimpleMem | 42.56 | 38.92 | 48.67 | 42.81 | 43.24 | 530-580 |
关键发现:
- 准确率提升26.4%:SimpleMem的平均F1达到43.24,比最强基线Mem0高出9个百分点
- Token消耗降低30倍:相比全上下文方法,SimpleMem仅需530-580个Token
- 时间推理能力突出:在需要理解时间线的任务上,SimpleMem表现尤为出色
效率分析
| 方法 | 构建时间 | 检索时间 | 总时间 | F1分数 |
|---|---|---|---|---|
| A-Mem | 5140.5s | 796.7s | 5937.2s | 32.58 |
| Mem0 | 1350.9s | 583.4s | 1934.3s | 34.20 |
| LightMem | 97.8s | 577.1s | 675.9s | 24.63 |
| SimpleMem | 92.6s | 388.3s | 480.9s | 43.24 |
效率优势:
- 比Mem0快4倍
- 比A-Mem快12倍
- 构建时间比Mem0快14倍
小模型上的表现
SimpleMem不仅在大模型上表现出色,对小参数模型的提升更为显著:
| 模型 | 无记忆 | + Mem0 | + SimpleMem |
|---|---|---|---|
| Qwen2.5-1.5B | 8.23 | 10.45 | 14.67 |
| Qwen2.5-3B | 10.56 | 13.03 | 17.98 |
| Qwen3-1.7B | 9.12 | 11.78 | 15.89 |
| Qwen3-8B | 15.67 | 19.23 | 24.56 |
重要发现:1.5B的小模型配合SimpleMem,甚至能超越使用劣质记忆策略的较大模型!
🔬 消融实验:每个组件都不可或缺
为了验证SimpleMem各组件的贡献,研究团队进行了详细的消融实验:
| 配置 | 单跳F1 | 多跳F1 | 时间推理F1 | 开放域F1 |
|---|---|---|---|---|
| 完整SimpleMem | 42.56 | 38.92 | 48.67 | 42.81 |
| 移除语义压缩 | 38.23 | 35.67 | 21.12 (-56.7%) | 39.45 |
| 移除递归整合 | 40.12 | 26.73 (-31.3%) | 45.23 | 40.67 |
| 移除自适应检索 | 35.89 (-15.7%) | 36.45 | 46.12 | 36.23 (-15.4%) |
关键洞察:
- 语义压缩对时间推理至关重要:移除后时间推理F1暴跌56.7%,说明时间锚定和指代消解对理解复杂时间线不可或缺
- 递归整合对多跳推理关键:移除后多跳F1下降31.3%,证明将碎片化事实整合为紧凑抽象的必要性
- 自适应检索影响单跳和开放域任务:动态调整检索范围对平衡相关性和效率至关重要
💡 案例分析:SimpleMem的实际应用
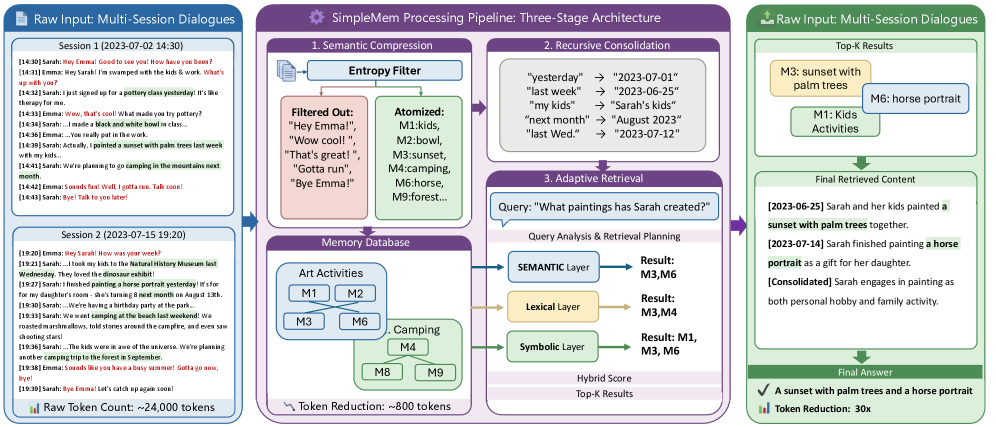
图3:SimpleMem处理长期多会话对话的案例。展示了从原始对话到原子记忆、再到分子记忆的完整转换过程,以及如何根据不同查询类型进行自适应检索。
场景:个人助理的咖啡偏好记忆
原始对话历史:
[2025-01-05 08:30] 用户:帮我点一杯拿铁
[2025-01-06 08:45] 用户:今天还是拿铁吧
[2025-01-07 09:00] 用户:换个口味,来杯美式
[2025-01-08 08:30] 用户:还是拿铁好喝
SimpleMem处理过程:
阶段1 - 语义压缩:
原子记忆1:用户于2025-01-05 08:30点了拿铁
原子记忆2:用户于2025-01-06 08:45点了拿铁
原子记忆3:用户于2025-01-07 09:00点了美式
原子记忆4:用户于2025-01-08 08:30点了拿铁
阶段2 - 递归整合:
分子记忆:用户偏好早晨喝咖啡,最常点拿铁(75%),偶尔尝试美式
阶段3 - 自适应检索:
- 简单查询"用户喜欢什么咖啡?" → 返回分子记忆
- 复杂查询"用户1月7日点了什么?" → 检索原子记忆3
🤔 深度思考:SimpleMem的设计哲学
1. 为什么"语义无损压缩"有效?
SimpleMem的核心洞察是:信息的价值不在于数量,而在于密度。
传统方法要么保留所有信息(导致冗余),要么激进删除(导致丢失)。SimpleMem采用了一种更聪明的策略——保留语义,压缩形式。
这与人类记忆的工作方式非常相似:
- 我们不会记住每一次喝咖啡的具体细节
- 但我们会形成"我喜欢拿铁"这样的抽象认知
- 当需要具体细节时,我们可以"努力回忆"
2. 多视图索引的必要性
单一索引方式就像只有一把钥匙的锁——虽然简单,但适用性有限。
SimpleMem的三层索引设计体现了互补性原则:
- 语义索引擅长理解意图
- 词汇索引擅长精确匹配
- 符号索引擅长结构化过滤
这种设计使系统能够应对各种类型的查询需求。
3. 自适应检索的智慧
"一刀切"的检索策略要么过度检索(浪费资源),要么检索不足(遗漏信息)。
SimpleMem的自适应策略体现了按需分配的原则:
- 简单问题快速回答,节省资源
- 复杂问题深入查找,确保准确
这种设计在实际应用中能够显著降低成本,同时保持服务质量。
⚠️ 局限性与未来方向
当前局限
- 依赖LLM进行压缩:语义压缩阶段需要调用LLM,增加了构建成本
- 整合策略较为简单:当前的递归整合基于相似度阈值,可能无法处理复杂的语义关系
- 评测范围有限:主要在LoCoMo基准上验证,其他场景的泛化性有待验证
未来方向
- 轻量化压缩:使用小模型或规则系统替代LLM进行初步压缩
- 图结构整合:引入知识图谱技术,更好地表示实体间的复杂关系
- 多模态扩展:将SimpleMem扩展到图像、音频等多模态记忆场景
- 在线学习:让记忆系统能够根据用户反馈动态调整压缩和整合策略
🔗 复现指南
环境配置
# 克隆仓库
git clone https://github.com/aiming-lab/SimpleMem.git
cd SimpleMem
# 安装依赖
pip install -r requirements.txt
# 配置API Key
cp config.py.example config.py
# 编辑config.py,填入OPENAI_API_KEY
基础使用
from main import SimpleMemSystem
# 初始化系统
system = SimpleMemSystem(clear_db=True)
# 添加对话
system.add_dialogue(
speaker="Alice",
content="Bob, let's meet at Starbucks tomorrow at 2pm",
timestamp="2025-11-15T14:30:00"
)
system.add_dialogue(
speaker="Bob",
content="Sure, I'll bring the market analysis report",
timestamp="2025-11-15T14:31:00"
)
# 完成原子编码
system.finalize()
# 查询
answer = system.ask("When and where will Alice and Bob meet?")
print(answer)
运行评测
# 运行LoCoMo基准测试
python test_locomo10.py
📚 参考资料
- 论文原文:SimpleMem: Efficient Lifelong Memory for LLM Agents
- 代码仓库:https://github.com/aiming-lab/SimpleMem
- LoCoMo Benchmark:Evaluating Very Long-Term Conversational Memory of LLM Agents
- 相关工作:
- MemGPT:通过虚拟上下文管理实现LLM自主记忆
- Mem0:基于向量+图数据库的双重存储架构
- A-Mem:迭代推理过滤噪声的记忆系统
📝 总结
SimpleMem为LLM智能体的记忆问题提供了一个优雅的解决方案。通过将记忆视为"代谢过程",它实现了:
| 维度 | 传统方法 | SimpleMem |
|---|---|---|
| 信息保留 | 全量保存或激进删除 | 语义无损压缩 |
| 存储结构 | 扁平存储 | 原子→分子层级结构 |
| 检索策略 | 固定深度 | 自适应查询感知 |
| Token效率 | 高消耗 | 降低30倍 |
| 准确率 | 一般 | 提升26.4% |
SimpleMem的成功证明了一个重要观点:在AI系统设计中,"少即是多"的原则同样适用。通过智能地压缩和整合信息,我们可以在保持高质量的同时大幅降低成本——这对于构建实用的AI智能体至关重要。
对于正在开发AI智能体的工程师和研究者来说,SimpleMem提供了一个值得借鉴的设计范式:不要试图记住所有东西,而是学会记住重要的东西。
如果觉得有帮助,欢迎点赞、转发、在看三连! 👍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)