大模型训练_week2_day10_《穷途末路》
碎碎念:无相,喝水是一把利器。上海transformer简单来说就是一个函数,输入一个序列,预测下一个token是什么。
目录
对比encoder_only,encoder_decoder,decoder_only
前言
碎碎念:无相,喝水是一把利器。上海
transformer简单来说就是一个函数,输入一个序列,预测下一个token是什么
embedding
dense word embedding 本质上就是通过训练让相似的词在向量空间里距离更近。对比一下one-hot彼此正交无法,embedding余弦距离可以衡量语义相关性
在transformer的输入层有词嵌入模块。主要包括:token embedding词元嵌入,position embedding位置嵌入,segment embedding分段嵌入。

positional embedding 就是记录词的sequence 相对index
补充:word2vec
将单词映射为连续向量
架构:skip-gram, continuous-bag-of-words(cbow),
MHA:多头注意力机制。
衍生来了分组查询注意力GQA,多头潜在注意力MLA
每个注意力头在不同的子空间学习不同类型的相关性,例如不同的头关注(语法结构,长程依赖)最后将不同的头的输出拼接。(举个例子多头注意力就像专家团队,每个专家关注和解决不同的问题,最后汇总得到更全面的认识)。
局限性:重复计算和内存劣势。 用到kv缓存
具有transformer架构的模型:BERT,gpt,llama,T5
在注意力矩阵中,第i行第j列数值表示,位置i的token作为query对位置j的token(作为key)的注意力权重。高权重代表语义相关度高,反之。

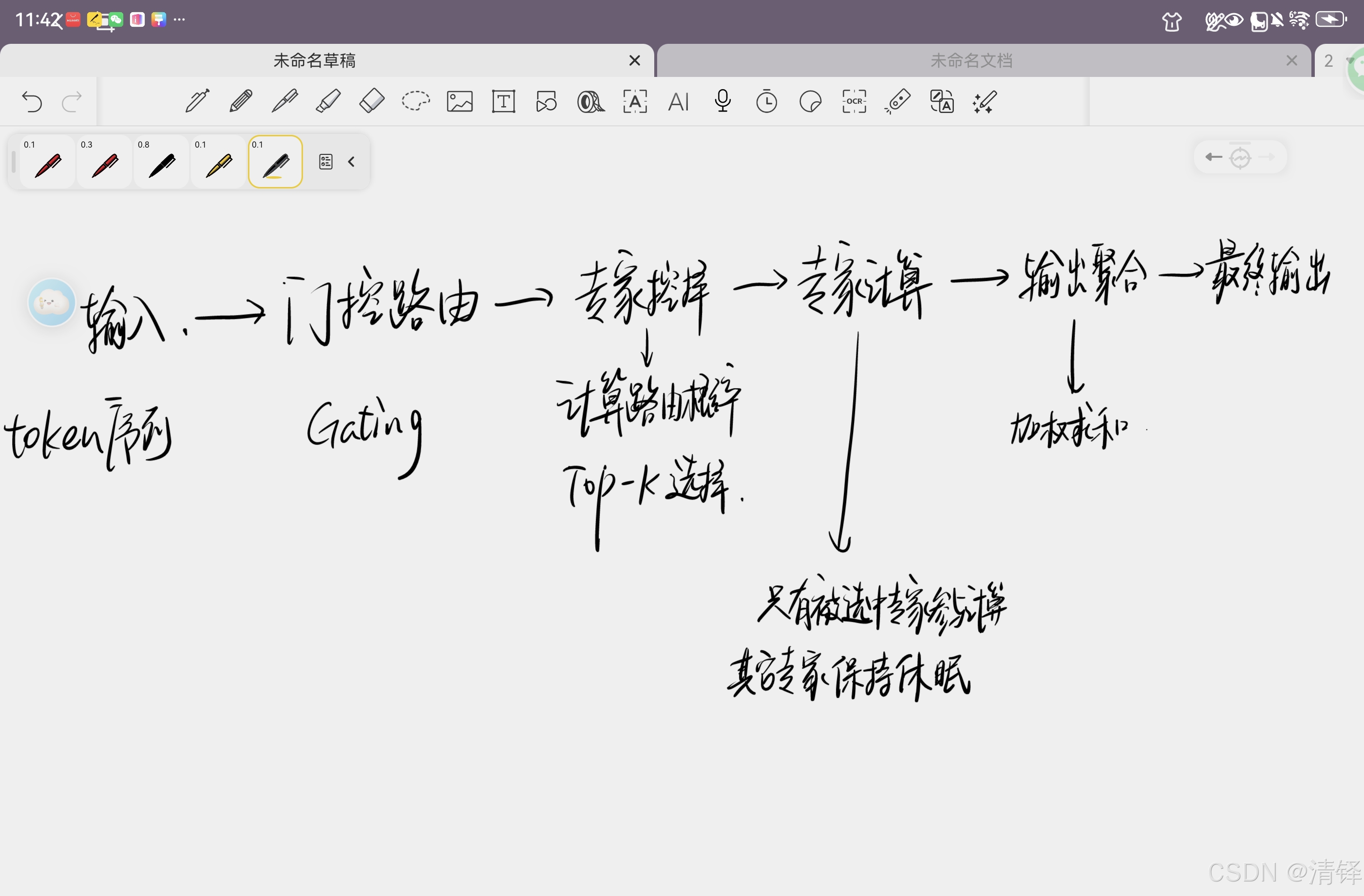
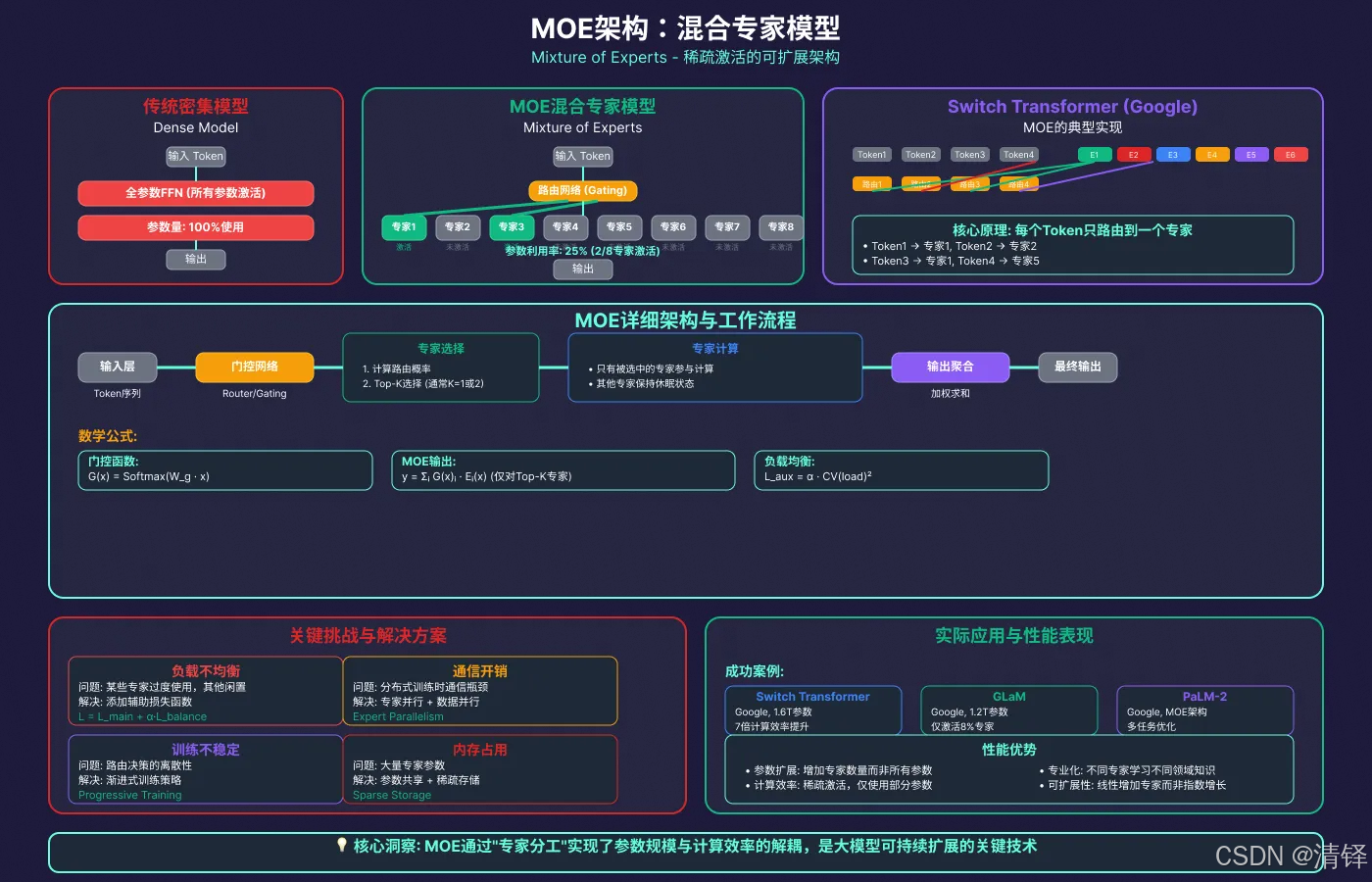
MOE架构
混合专家网络。mixture of experts
专家⽹络是指MoE模型中的多个⼦⽹络(即“专家”)。每个专家通常是功能相同结构类似的神经⽹络模 块(例如Transformer中前馈⽹络部分),但在训练过程中可各⾃学习不同的专⻓。在经典MoE中,这些 专家共同构成模型的⼀层或若⼲层,仅有⼀部分专家会针对每个输⼊样本被激活。通过这种⽅式,模型 参数规模可以⾮常庞⼤,但每次推理或训练仅计算⼀⼩部分参数,从⽽保持计算成本近似恒定。这种架 构提⾼了模型容量(参数数⽬巨⼤带来的表示能⼒)与计算效率的折中:例如Switch Transformer模型 具有⾼达1.6万亿参数,但其训练计算量与⼀个100亿参数的稠密模型相当。
MOE关键组件,决定每个输入应有哪一个或者那几个专家处理
⻔控⽹络通常是⼀个简单的前馈层,它根据输⼊特征计算针对每个专家的打分(logits),再通 过⼀定函数将打分转换为概率或权重分布,⽤以选择专家。按照路由决策的不同⽅式,可分为软路由和 硬路由两种:软路由(soft gating)会根据⻔控⽹络输出的概率加权融合多个专家的结果(极端情况下 可融合同层所有专家的输出,代价是计算开销巨⼤);⽽硬路由(hard gating)则只选择得分最⾼的⼏个专家,丢弃其他专家的输出,从⽽使每次仅激活少数专家参与计算。硬路由通常通过⾮零梯度近似或 辅助损失进⾏训练,代表性实例是Switch Transformer中每个token仅选取单⼀专家(相当于_top-1_路 由),这种硬选取⼤幅减少了计算与通信成本。软硬路由各有优劣:软路由更平滑但计算开销⼤,硬路 由更⾼效但需要应对离散选择带来的训练不稳定等问题。
对比encoder_only,encoder_decoder,decoder_only


transformer架构为什么好?
并行效率高,深入理解词与词之间的关系,架构通用(跨模态,标准化)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)