Python + AI 时代来了!这 3 个大模型应用开发方向,薪资翻倍
2025年,大语言模型(LLM)已成为各行业核心生产力工具,Python开发者掌握大模型应用技能薪资涨幅达50%-100%。本文聚焦三大高薪方向:智能Agent开发、RAG企业知识库系统和大模型应用开发。以智能Agent为例,展示如何用Python+LangChain构建具备"感知-思考-行动"能力的AI程序,包括工具调用、记忆存储等核心功能。Python凭借丰富生态(Lang
2025 年,大语言模型(LLM)不再是实验室里的技术概念,而是真正渗透到各行各业的生产力工具。从企业级知识库到智能客服,从自主决策的 AI Agent 到垂直领域 SaaS 产品,基于大模型的应用开发正在重构软件开发的价值体系——懂 Python + 会落地大模型应用的开发者,薪资普遍比传统 Python 开发高出 50%-100%。
而 Python 之所以成为 AI 应用开发的绝对首选,核心原因有三:一是拥有最丰富的 AI 生态(LangChain、LlamaIndex、Transformers 等库均以 Python 为核心);二是简洁的语法降低了大模型集成的门槛;三是企业级应用开发链路完整(FastAPI、Django 等框架可快速落地)。
如果你已经掌握 Python 基础(函数、API 调用),接下来这 3 个高需求、高薪资的开发方向,就是你切入 AI 赛道的最佳路径。
一、智能 Agent 应用开发:打造自主执行任务的 AI 机器人
应用场景与市场需求
智能 Agent(智能代理)是具备“感知-思考-行动”能力的 AI 程序,能自主完成复杂任务:比如自动撰写周报、批量处理客户工单、跨平台数据整合、甚至自主进行市场调研。
2025 年企业对智能 Agent 开发的需求呈爆发式增长:
- 一线城市智能 Agent 开发工程师年薪 45W-80W
- 中小厂相关岗位薪资也达到 30W-50W
- 典型雇主:互联网大厂、金融科技公司、企业服务 SaaS 厂商
核心需求场景:电商智能运营 Agent、金融合规审查 Agent、企业自动化办公 Agent、科研数据整理 Agent。
核心技术栈
- 基础:Python 3.10+、FastAPI
- 核心框架:LangChain(Agent 核心逻辑)、AutoGen(多 Agent 协作)
- LLM 对接:OpenAI API / Ollama(本地部署 Llama 3)
- 工具调用:SerpAPI(搜索引擎)、Python 内置工具(计算器、文件操作)
- 记忆层:Chroma(向量存储)、Redis(短期记忆)
可运行的代码示例:ReAct 模式智能 Agent(能搜索+计算)
这个示例实现了一个能自主判断何时需要搜索、何时需要计算的 Agent,比如回答“2025年北京人均GDP是多少?这个数值的平方根是多少?”这类需要多步操作的问题。
第一步:安装依赖
pip install langchain langchain-openai langchain-community python-dotenv serpapi
第二步:核心代码
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tools import Tool
from langchain_community.tools import SerpAPIWrapper
import math
# 加载环境变量(需提前在 .env 文件配置 OPENAI_API_KEY 和 SERPAPI_API_KEY)
load_dotenv()
# 1. 定义工具:搜索引擎
search = SerpAPIWrapper(serpapi_api_key=os.getenv("SERPAPI_API_KEY"))
# 2. 定义工具:计算器(计算平方根)
def calculate_square_root(number: float) -> str:
"""计算一个数字的平方根,仅接受数字输入"""
try:
result = math.sqrt(number)
return f"平方根计算结果:{result:.2f}"
except ValueError:
return "错误:无法计算负数的平方根"
# 3. 整合工具列表
tools = [
Tool(
name="Search",
func=search.run,
description="当需要获取最新信息、实时数据、未知事实时使用,比如2025年北京GDP、最新政策等"
),
Tool(
name="Calculator",
func=calculate_square_root,
description="当需要计算平方根时使用,输入必须是数字"
)
]
# 4. 配置 LLM(使用 GPT-4o,也可替换为 Ollama 部署的 Llama 3)
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
api_key=os.getenv("OPENAI_API_KEY")
)
# 5. 定义 Agent 提示词(ReAct 模式)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个智能助手,能使用工具解决问题。请按照以下步骤操作:\n1. 分析问题,判断是否需要使用工具;\n2. 如果需要,选择合适的工具;\n3. 执行工具调用,获取结果;\n4. 基于结果回答原始问题。"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"), # 保存思考过程
])
# 6. 创建 Agent 并执行
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 测试:问一个需要搜索+计算的问题
if __name__ == "__main__":
response = agent_executor.invoke({
"input": "2025年北京市人均GDP是多少万元?请计算这个数值的平方根(保留2位小数)"
})
print("\n最终回答:", response["output"])
代码说明
Tool类:封装了可调用的工具,每个工具需明确名称、功能和使用场景,方便 Agent 判断何时调用;ReAct 模式:让 Agent 先“思考”(Reason)再“行动”(Act),通过agent_scratchpad保存思考过程;AgentExecutor:负责调度 Agent 的执行流程,处理工具调用和结果返回。
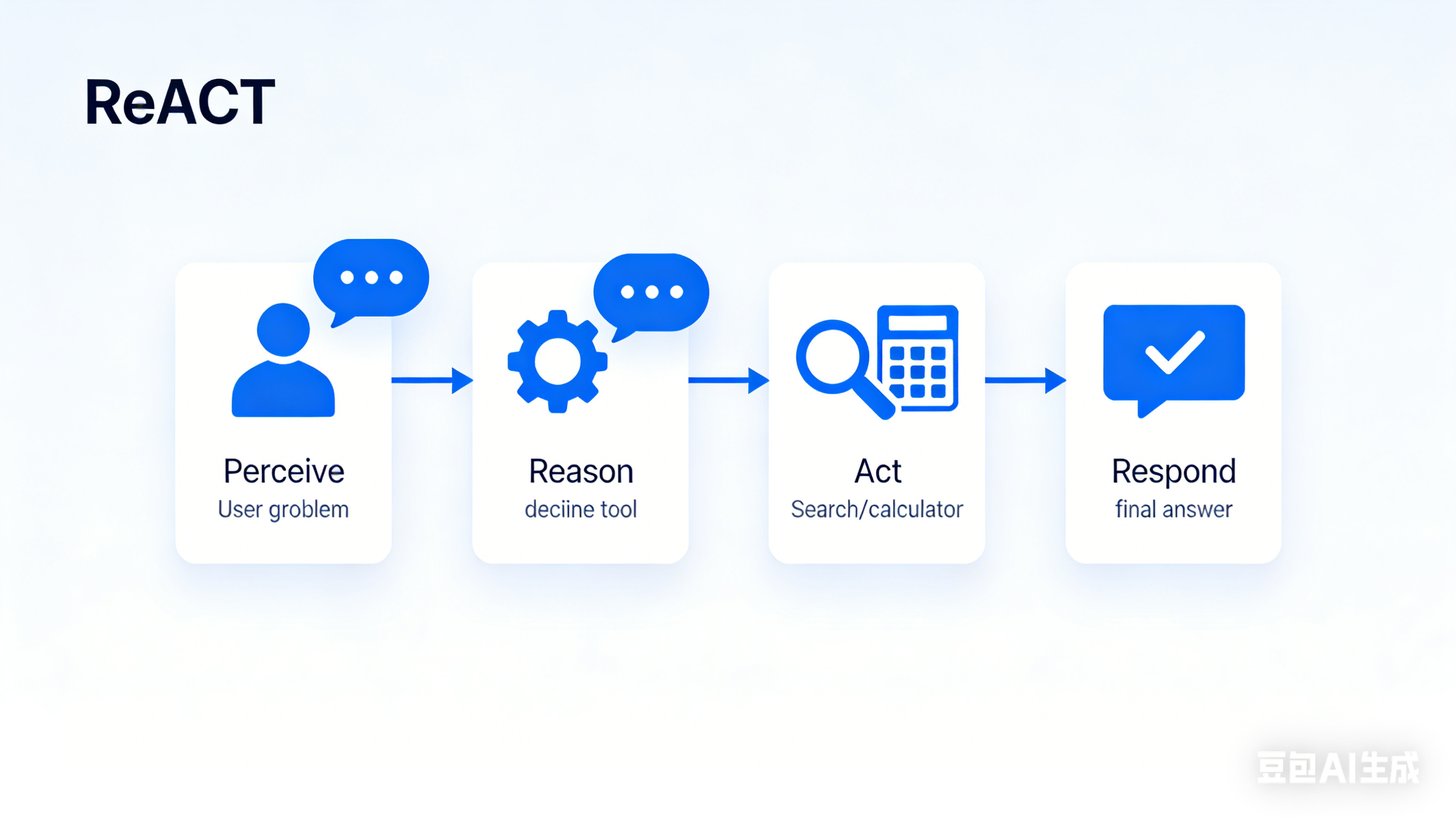
二、RAG 企业知识库系统:让大模型读懂你的私有数据
应用场景与市场需求
RAG(Retrieval-Augmented Generation,检索增强生成)的核心是:让大模型回答问题时,优先从企业私有数据(PDF、文档、数据库)中检索信息,再生成答案——解决了大模型“知识过时”“胡说八道”“不懂企业内部数据”的核心痛点。
这是目前企业落地最广泛的 AI 应用方向,几乎所有中大型企业都有相关需求:
- 一线城市 RAG 工程师年薪 40W-70W
- 二线城市 RAG 开发岗位薪资 25W-40W
- 典型雇主:金融机构、律所、制造企业、政府单位、教育机构
核心需求场景:企业内部问答机器人、产品文档智能客服、法规政策检索系统、研发文档助手。
核心技术栈
- 基础:Python 3.10+、Pandas
- 文档处理:PyPDF2、Unstructured(解析多格式文档)
- 核心框架:LangChain、LlamaIndex(RAG 核心逻辑)
- 向量存储:Chroma(轻量)、Milvus(企业级)、FAISS(Facebook 开源)
- 嵌入模型:OpenAI Embeddings / BGE Embeddings(开源)
- 部署:FastAPI(接口封装)、Docker(容器化)
可运行的代码示例:基于 PDF 的本地 RAG 问答系统
这个示例实现了一个能读取本地 PDF 文件,并用大模型回答关于 PDF 内容的问题的 RAG 系统,比如上传公司产品手册,提问“产品A的核心功能有哪些?”。
第一步:安装依赖
pip install langchain langchain-openai pypdf chromadb python-dotenv
第二步:核心代码
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 加载环境变量(配置 OPENAI_API_KEY)
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 加载并解析 PDF 文件
def load_pdf_document(pdf_path):
"""加载 PDF 文件并返回文档对象列表"""
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"PDF 文件不存在:{pdf_path}")
# 加载 PDF
loader = PyPDFLoader(pdf_path)
documents = loader.load()
# 分割文本(避免超过 LLM 上下文窗口)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个文本块大小
chunk_overlap=200, # 块之间重叠,保证上下文连贯
separators=["\n\n", "\n", "。", "!", "?", ",", ""] # 中文分割符
)
split_docs = text_splitter.split_documents(documents)
print(f"PDF 解析完成,分割为 {len(split_docs)} 个文本块")
return split_docs
# 2. 创建向量数据库并存储文本
def create_vector_db(documents, persist_directory="./chroma_db"):
"""将文档存入 Chroma 向量数据库"""
# 初始化嵌入模型(将文本转为向量)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 创建向量库
vectordb = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory=persist_directory # 持久化存储
)
vectordb.persist()
print(f"向量数据库创建完成,存储路径:{persist_directory}")
return vectordb
# 3. 创建 RAG 问答链
def create_rag_chain(vectordb):
"""创建检索增强生成的问答链"""
# 初始化 LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 创建检索器(返回最相关的 3 个文本块)
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
# 创建 RAG 链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 将检索到的文本全部传入 LLM
retriever=retriever,
return_source_documents=True, # 返回答案来源
chain_type_kwargs={
"prompt": """基于以下提供的上下文回答问题,只使用上下文里的信息,不要编造内容。
如果上下文里没有相关信息,直接说“无法从提供的文档中找到相关答案”。
上下文:
{context}
问题:
{question}
回答:"""
}
)
return qa_chain
# 主函数:运行 RAG 问答
if __name__ == "__main__":
# 替换为你的 PDF 文件路径
PDF_PATH = "./company_product_manual.pdf"
try:
# 步骤1:加载并分割 PDF
docs = load_pdf_document(PDF_PATH)
# 步骤2:创建向量库
vectordb = create_vector_db(docs)
# 步骤3:创建问答链
qa_chain = create_rag_chain(vectordb)
# 步骤4:提问并获取答案
question = "产品A的核心功能有哪些?"
result = qa_chain.invoke({"query": question})
# 输出结果
print("\n=== 问答结果 ===")
print(f"问题:{question}")
print(f"答案:{result['result']}")
# 输出答案来源(可选)
print("\n=== 答案来源 ===")
for i, doc in enumerate(result["source_documents"]):
print(f"来源 {i+1}:页码 {doc.metadata['page']},内容片段:{doc.page_content[:100]}...")
except Exception as e:
print(f"运行出错:{str(e)}")
代码说明
RecursiveCharacterTextSplitter:针对中文优化的文本分割器,避免切割完整语义;Chroma:轻量级向量数据库,无需额外部署,适合本地开发和小型应用;RetrievalQA:LangChain 封装的 RAG 核心链,负责“检索相关文本 + 传入 LLM 生成答案”;return_source_documents:返回答案来源,满足企业对“可解释性”的需求。
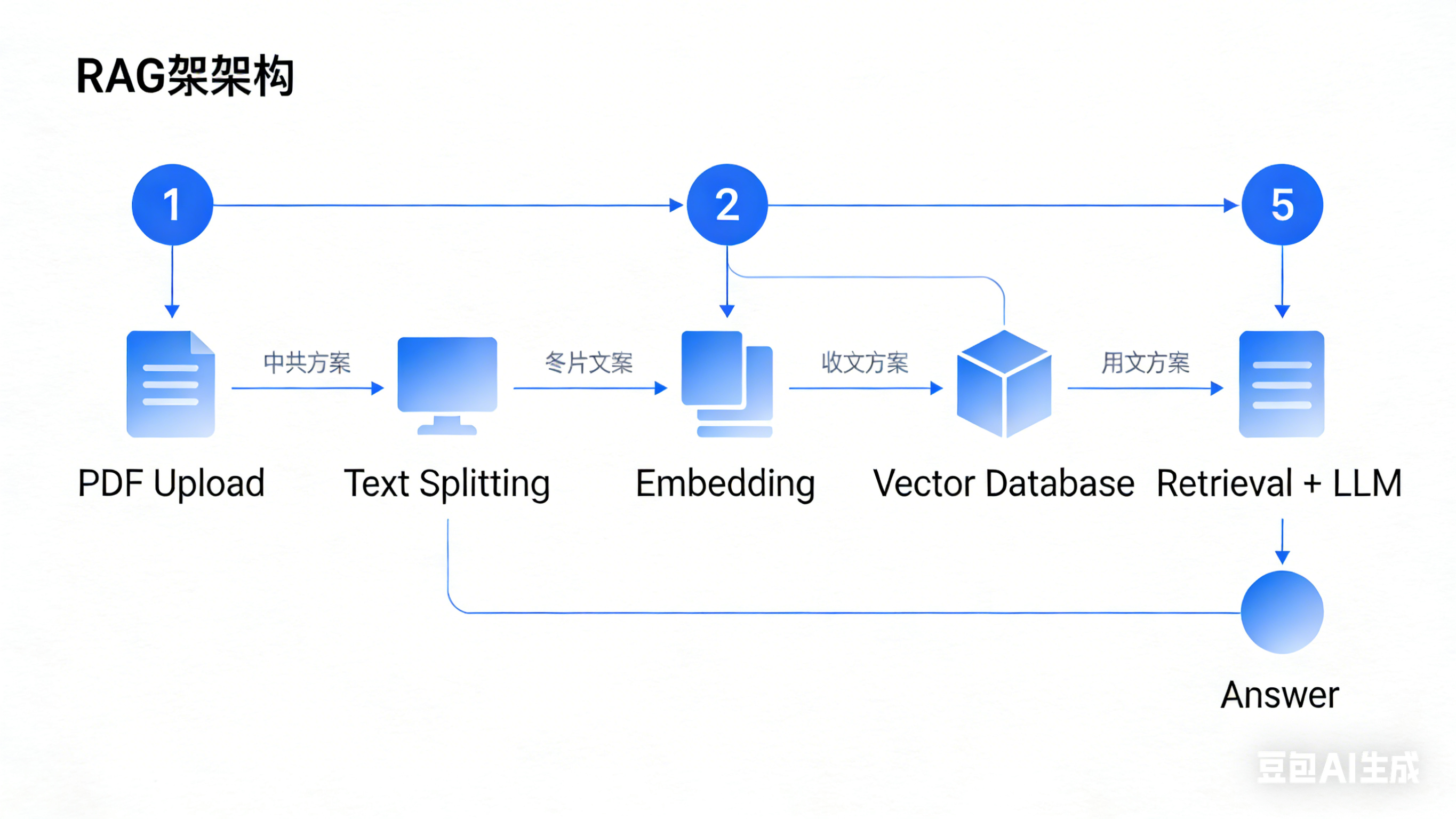
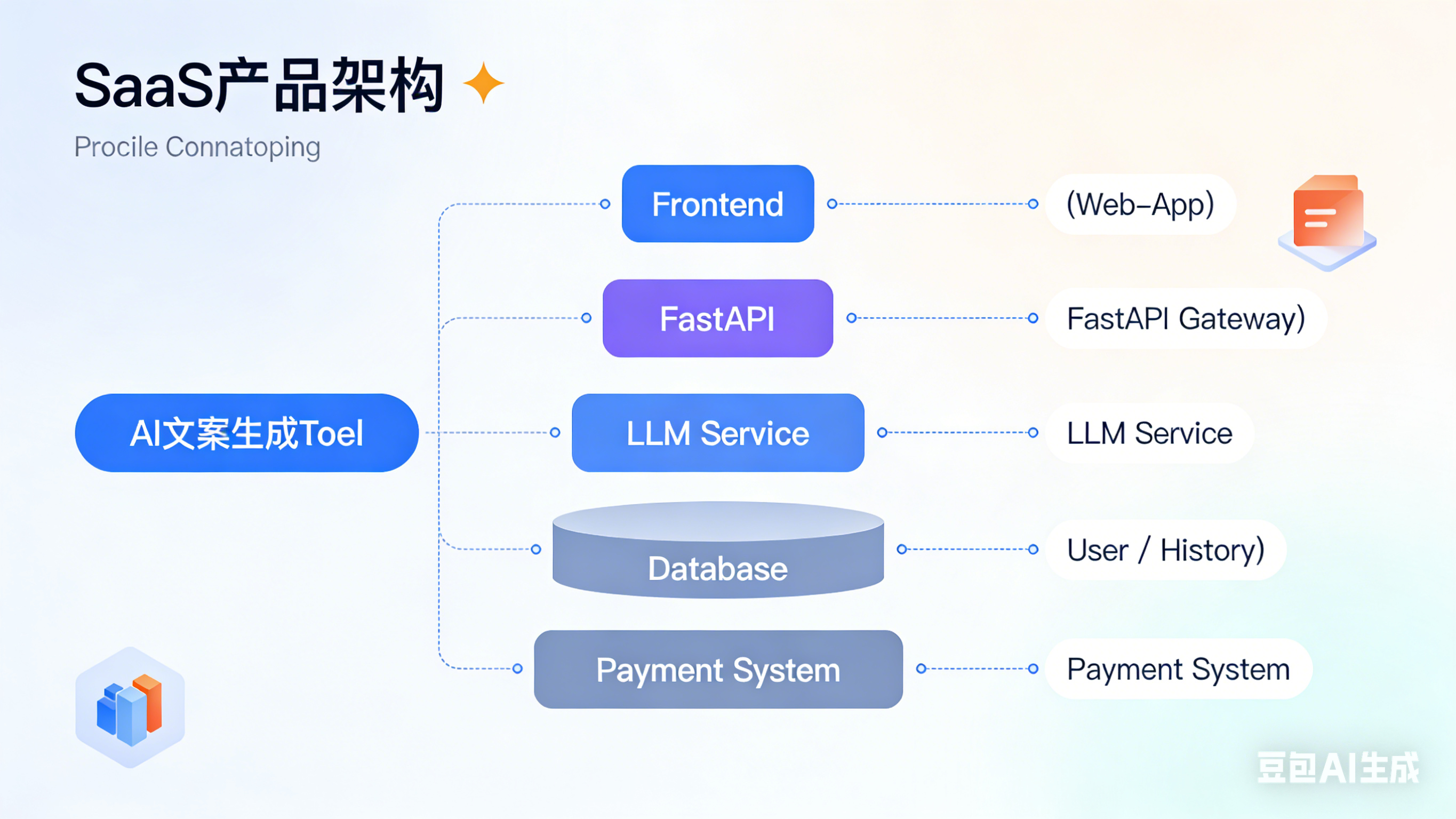
三、AI 原生 SaaS 工具开发:打造可商业化的智能产品
应用场景与市场需求
AI 原生 SaaS 是指从底层设计就融入大模型能力的 SaaS 工具,而非简单的“AI 插件”。这类工具解决的是具体的行业痛点,具备明确的商业化路径,也是创业和就业的热门方向。
2025 年 AI 原生 SaaS 开发人才缺口极大,薪资和收益都极具吸引力:
- 一线城市 AI SaaS 后端开发工程师年薪 45W-85W
- 独立开发的小型 AI SaaS 工具(如智能文案生成器)月收入可达 1W-10W
- 典型雇主:SaaS 创业公司、互联网大厂、垂直领域企业服务公司
核心需求场景:智能文案生成平台、AI 客服系统、简历/合同智能分析工具、营销内容自动生成工具、代码生成助手。
核心技术栈
- 基础:Python 3.10+
- Web 框架:FastAPI(高性能接口)、Streamlit(快速原型)
- LLM 对接:OpenAI API / 字节云雀 API / 本地化部署模型
- 数据存储:PostgreSQL(业务数据)、Redis(缓存)
- 支付/鉴权:Stripe(支付)、JWT(用户鉴权)
- 部署:Docker、阿里云/腾讯云服务器、Vercel(前端)
可运行的代码示例:FastAPI 封装 LLM 接口(AI 文案生成 SaaS 核心)
这个示例实现了一个可商用的 AI 文案生成接口,支持不同场景(朋友圈、小红书、公众号)的文案生成,可直接集成到 SaaS 产品中。
第一步:安装依赖
pip install fastapi uvicorn langchain-openai python-dotenv pydantic
第二步:核心代码
import os
from dotenv import load_dotenv
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
# 加载环境变量
load_dotenv()
# 初始化 FastAPI 应用
app = FastAPI(title="AI 文案生成 SaaS API", version="1.0")
# 解决跨域问题(前端调用接口需要)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境需替换为具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 初始化 LLM
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7, # 创意性调参,越高越灵活
api_key=os.getenv("OPENAI_API_KEY")
)
# 定义请求体模型(校验输入参数)
class CopywritingRequest(BaseModel):
topic: str # 文案主题
scene: str # 场景:wechat(朋友圈)、xiaohongshu(小红书)、gongzhonghao(公众号)
tone: str = "活泼" # 语气:活泼/正式/文艺/搞笑
length: int = 100 # 字数
# 定义不同场景的提示词模板
prompt_templates = {
"wechat": PromptTemplate(
template="""请为我生成一条朋友圈文案,要求如下:
主题:{topic}
语气:{tone}
字数:{length}字左右
风格:符合朋友圈社交场景,简洁有吸引力,避免广告感太重。
""",
input_variables=["topic", "tone", "length"]
),
"xiaohongshu": PromptTemplate(
template="""请为我生成一篇小红书文案,要求如下:
主题:{topic}
语气:{tone}
字数:{length}字左右
风格:符合小红书平台特性,包含合适的emoji,结尾带相关话题标签(3-5个)。
""",
input_variables=["topic", "tone", "length"]
),
"gongzhonghao": PromptTemplate(
template="""请为我生成一篇公众号文章开头文案,要求如下:
主题:{topic}
语气:{tone}
字数:{length}字左右
风格:符合公众号阅读场景,有吸引力,能引导读者继续阅读。
""",
input_variables=["topic", "tone", "length"]
)
}
# 定义文案生成接口
@app.post("/api/generate-copywriting", summary="生成AI文案")
async def generate_copywriting(request: CopywritingRequest):
try:
# 校验场景参数
if request.scene not in prompt_templates:
raise HTTPException(
status_code=400,
detail=f"场景参数错误,支持的场景:{list(prompt_templates.keys())}"
)
# 获取对应场景的提示词模板
prompt = prompt_templates[request.scene]
# 生成提示词
prompt_text = prompt.format(
topic=request.topic,
tone=request.tone,
length=request.length
)
# 调用 LLM 生成文案
response = llm.invoke(prompt_text)
# 返回结果
return {
"code": 200,
"message": "success",
"data": {
"topic": request.topic,
"scene": request.scene,
"tone": request.tone,
"copywriting": response.content
}
}
except HTTPException as e:
raise e
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"服务器内部错误:{str(e)}"
)
# 健康检查接口
@app.get("/health", summary="健康检查")
async def health_check():
return {"status": "healthy"}
# 运行服务
if __name__ == "__main__":
import uvicorn
uvicorn.run(
app="main:app",
host="0.0.0.0",
port=8000,
reload=True # 开发模式自动重载
)
代码说明
Pydantic:校验接口输入参数,保证数据合法性;CORSMiddleware:解决前端跨域调用问题,是 SaaS 接口的必备配置;PromptTemplate:按不同场景封装提示词,提高文案生成的精准度;FastAPI:高性能异步框架,支持自动生成接口文档(访问 http://localhost:8000/docs 即可测试)。
测试接口
运行代码后,访问 http://localhost:8000/docs,点击 /api/generate-copywriting 接口的“Try it out”,输入以下参数:
{
"topic": "春季新品咖啡上市",
"scene": "xiaohongshu",
"tone": "活泼",
"length": 200
}
即可生成符合小红书风格的咖啡新品文案。
结语:从入门到高薪的学习路径 + 避坑指南
学习路径建议
-
基础夯实阶段(1-2 周):
- 熟练掌握 FastAPI 接口开发、Python 异步编程
- 熟悉 LangChain/LlamaIndex 核心概念(Chain、Agent、Retriever)
- 掌握 Prompt 工程基础(如何写清晰的提示词)
-
单方向突破阶段(2-4 周):
- 选一个方向(比如 RAG)深入实践,完成 1-2 个完整项目(如 PDF 问答系统)
- 学习向量数据库的进阶用法(如 Milvus 部署、向量检索优化)
- 了解大模型本地化部署(Ollama 部署 Llama 3/DeepSeek)
-
工程化落地阶段(4-8 周):
- 学习 Docker 容器化部署、云服务器运维
- 掌握用户鉴权、支付集成、日志监控等 SaaS 必备能力
- 完成一个可商用的 AI 应用(如智能文案生成工具)
避坑指南
-
不要盲目追求模型微调:90% 的企业级应用无需微调模型,通过 RAG + 优质 Prompt 即可解决问题,微调成本高、落地难,新手优先掌握系统集成能力。
-
优先解决工程化问题:大模型应用的核心竞争力不是“调参”,而是“落地能力”——比如如何保证接口稳定性、如何处理海量文档、如何降低调用成本、如何满足用户体验。
-
避免过度依赖闭源 API:学习时可先用 OpenAI API 快速验证想法,但要掌握本地化模型部署能力(如 Ollama),降低商用成本和合规风险。
行动号召
2025 年是 Python + AI 应用开发的黄金窗口期,相比于研究大模型底层原理,落地大模型应用的能力更能直接转化为薪资和收益。
如果你已经掌握 Python 基础,现在就动手实现本文中的代码示例,完成第一个 RAG 系统、第一个 Agent、第一个 AI SaaS 接口——真正的高薪机会,永远属于“能把想法落地成代码”的开发者。
AI 时代不会淘汰程序员,但会淘汰不会用 AI 的程序员。用 Python 抓住大模型的红利,你的薪资翻倍,从今天开始就不是空谈。
总结
- 三大高薪方向核心:智能 Agent 侧重“自主任务执行”,RAG 侧重“私有数据问答”,AI 原生 SaaS 侧重“商业化产品落地”,均以 Python 为核心开发语言。
- 技术栈关键:LangChain/LlamaIndex 是大模型应用开发的核心框架,FastAPI 是接口封装的首选,向量数据库是 RAG/Agent 的基础组件。
- 落地优先原则:新手无需纠结模型微调,先通过 Prompt 工程 + 框架集成完成完整应用,工程化落地能力是薪资翻倍的核心竞争力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)