完胜字节veRL!港科大&阿里开源Agentic RL分布式训练系统,支持3000+异构GPU集群扩展
研究团队还与 StreamRL 进行了对比,并启用了一次性训练范式,该范式通过消耗上一步生成的轨迹,实现轨迹生成与训练的并行化。而有状态组件(如训练阶段)则部署在专用硬件资源上。训练步骤的详细分解显示,在成功运行中LLM生成占据54%时间,训练占23%,环境初始化占15%。而在包含环境失败的迭代中,环境初始化时间占比飙升至78%,凸显了环境管理的重要性。在Qwen3系列模型(8B-32B)和多任务
完胜字节veRL!港科大&阿里开源Agentic RL分布式训练系统,支持3000+异构GPU集群扩展
原创 关注AI智能体 智猩猩AI 2026年1月9日 12:41 北京 标题已修改
在小说阅读器中沉浸阅读
智猩猩AI整理
编辑:发发
智能体强化学习(Agentic RL)使大语言模型能够从被动的逻辑推理转向自主决策与长期规划。与传统LLM后训练不同,Agentic RL工作负载具有高度异构性:结合了计算密集的前填充阶段、带宽受限的解码阶段,以及状态化且CPU繁重的环境模拟。这种异构性导致单体化集群无法满足多任务智能体强化学习(multi-task agentic RL )训练的多样化资源需求。
尽管资源解耦架构能将不同阶段路由到最适合的硬件,但现有系统因复杂的阶段依赖关系而面临同步开销和资源利用率低下的问题。
为解决上述挑战,香港科技大学联合阿里提出了ROLLART,这是一个专为在解耦式基础设施上最大化多任务智能体强化学习训练吞吐量而设计的分布式系统。ROLLART基于三大核心设计原则:
(1)硬件亲和工作负载映射,动态路由任务至专属硬件池;
(2)轨迹级细粒度异步执行,掩盖通信延迟;
(3)状态感知计算,将无状态奖励模型卸载至无服务器平台。
在3000+GPU生产集群中,ROLLART实现1.35-2.05倍端到端训练加速,并支持数百亿参数MoE模型训练。

-
论文标题:
ROLLART: Scaling Agentic RL Training via Disaggregated Infrastructure
-
论文链接:https://arxiv.org/pdf/2512.22560
-
代码开源:https://github.com/alibaba/ROLL
01
方法
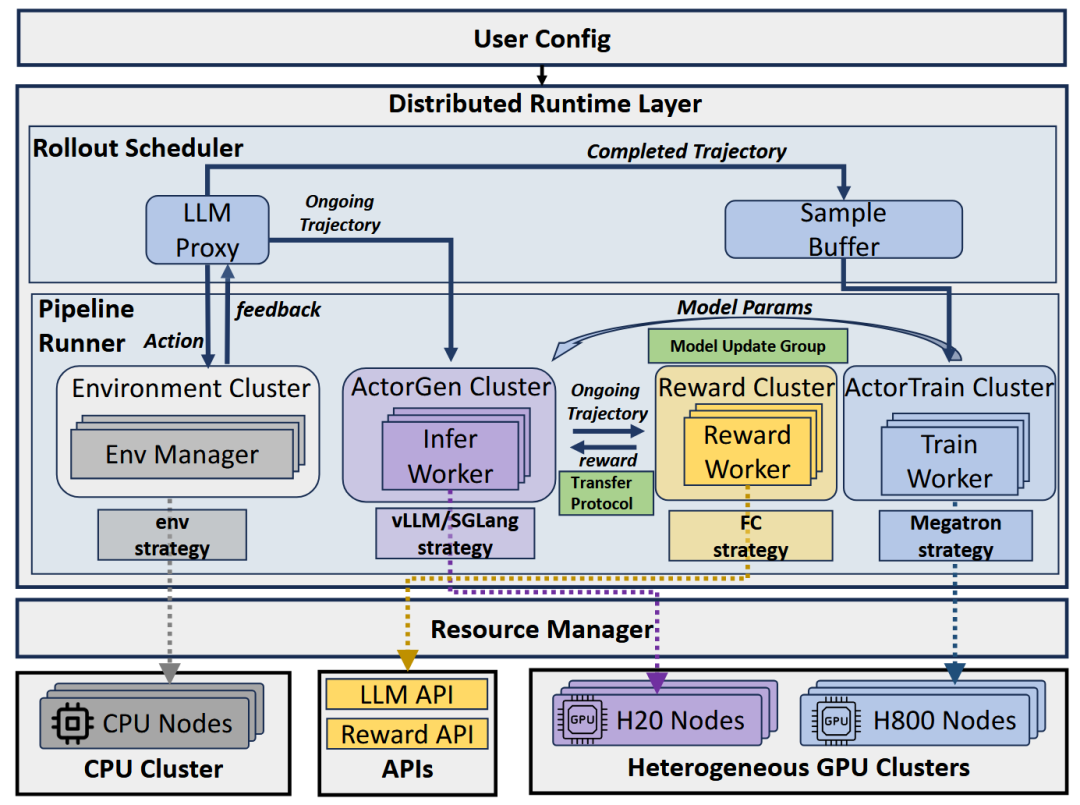
图1:ROLLART系统架构
如图1所示,ROLLART系统架构包含分布式运行时层和资源管理器,通过声明式编程模型实现细粒度资源分配。系统架构图展示了完整的组件关系和数据流。
(1)硬件亲和性任务调度

图2:同步vs异步训练
ROLLART系统通过精细化的硬件资源分配策略,实现计算资源的最优利用。系统支持在阶段级别和轨迹级别定义硬件亲和性,确保各类工作负载能够匹配最适合的硬件配置。解耦基础设施将训练、推理、环境模拟等阶段分配到专用资源池,通过标准网络织物互连。
在阶段级别,训练任务被分配到计算优化的GPU集群,而环境模拟任务则由Kubernetes管理的CPU集群处理。这种分离有效避免了资源争用,提高了整体系统效率。同步与异步训练模式的对比显示,异步训练能有效隐藏同步延迟,提升硬件利用率。
(2)细粒度异步执行机制
ROLLART通过轨迹级调度机制实现了LLM生成、环境交互与奖励计算的高度并行化。系统核心组件LLMProxy作为智能网关,负责非阻塞地处理LLM推理请求,而EnvManager则独立管理单个环境的完整生命周期。
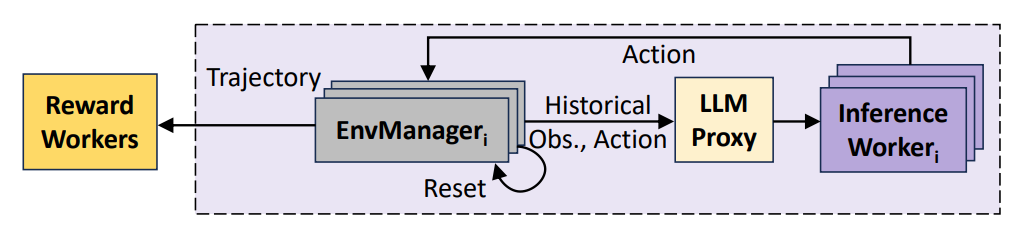
图3:轨迹级Rollout概述
轨迹级执行模式使得不同轨迹的处理能够完全重叠:当一个轨迹在进行LLM生成时,另一个轨迹可以同时执行环境交互,第三个轨迹则进行奖励计算。这种流水线设计有效掩盖了跨集群通信延迟,异步训练工作流展示了完整的执行流程。
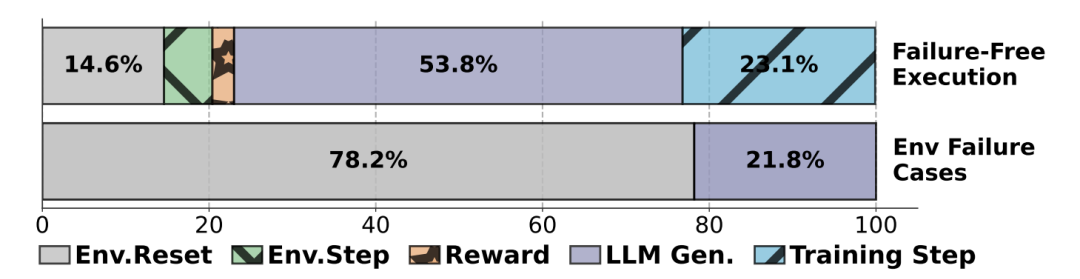
图4:训练步骤的详细分解:成功运行(上方)与存在环境故障的执行(下方)
训练步骤的详细分解显示,在成功运行中LLM生成占据54%时间,训练占23%,环境初始化占15%。而在包含环境失败的迭代中,环境初始化时间占比飙升至78%,凸显了环境管理的重要性。
(3)状态感知计算架构
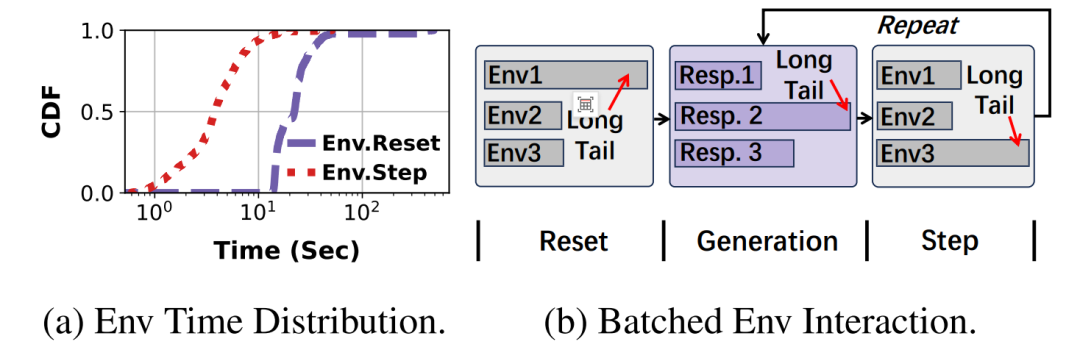
图5:环境交互分析
ROLLART创新性地采用状态感知的计算模型,明确区分各组件的状态需求。无状态组件(如奖励模型)被卸载到无服务器平台,实现弹性扩缩容;而有状态组件(如训练阶段)则部署在专用硬件资源上。
(4)编程与计算模型
ROLLART通过声明式编程模型实现硬件亲和性。用户使用@register装饰器定义执行函数,@hw_mapping指定任务路由策略,例如为解码密集型任务绑定H20 GPU。

图6:ROLLART的声明式编程模型
Cluster抽象作为分布式计算核心,管理多角色工作者(Worker),并通过Invocation Proxy绑定方法至集群实例,支持细粒度资源分配。
02
评估
由于现有开源系统均不支持全范围的智能体任务,因此研究团队采用 veRL 的同步强化学习实现(记为 veRL)作为基线方案。为增强该基线,研究团队额外启用了异步奖励计算、异步环境交互以及 “奖励即服务” 机制,将其记为 veRL+。
研究团队还与 StreamRL 进行了对比,并启用了一次性训练范式,该范式通过消耗上一步生成的轨迹,实现轨迹生成与训练的并行化。veRL+中采用的优化措施同样被应用于 StreamRL。
训练阶段采用 Megatron ,但它不支持异构 GPU 配置,StreamRL 在轨迹生成阶段同样不支持异构 GPU。为简化对比,两个基线方案均运行在 128 块 H800 GPU 上。因此,ROLLART 的每 GPU 小时成本约为这些基线方案的 83%。
(1)端到端性能评估
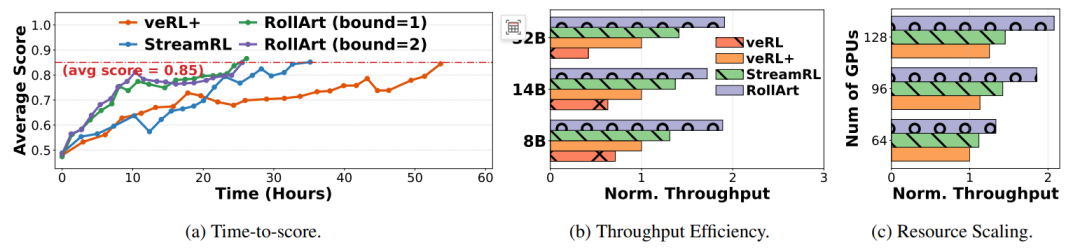
图7:(a)Qwen3-32B的端到端评分时间对比;(b)不同方法在各大型语言模型上的标准化吞吐量对比;(c)不同数量H800 GPU下Qwen3-14B的标准化吞吐量对比。
在Qwen3系列模型(8B-32B)和多任务环境(SWE-bench、WebShop等)上的实验显示,ROLLART在目标分数0.85时,端到端时间相较于veRL+和StreamRL分别缩短2.05倍和1.35倍。
吞吐量效率方面,ROLLART归一化吞吐量达同步基线2.65-4.58倍。资源扩展实验中(64-128 GPU),系统保持1.33-2.08倍吞吐量提升,证明优异可扩展性。
(2)硬件亲和性分析
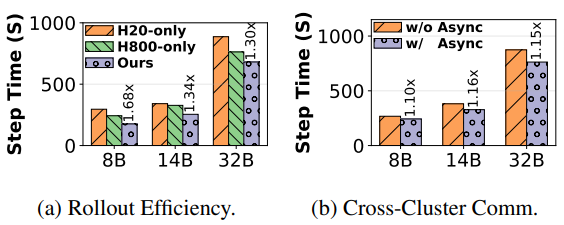
图8:(a)硬件亲和性的效率;(b)异步跨集群通信的优势
硬件亲和性配置(64 H800 GPU + 24 H20 GPU)相较于纯H20和纯H800配置,步长时间分别缩短1.30-1.68倍和1.12-1.37倍。异步跨集群通信技术减少端到端步长时间1.10-1.16倍。
(3)轨迹级异步执行评估
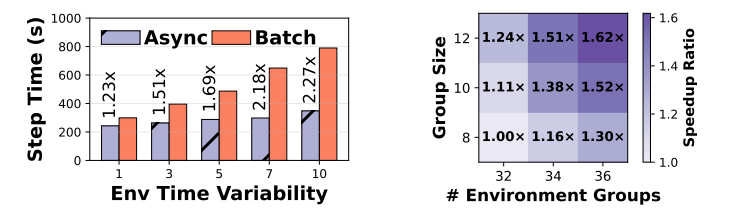
图9:轨迹级环境的优势
注入高斯延迟(σ=1-10)测试中,轨迹级交互相较于批处理模式性能提升1.23-2.27倍。冗余环境滚出机制在GEM-math任务中实现最大1.62倍轨迹生成加速。
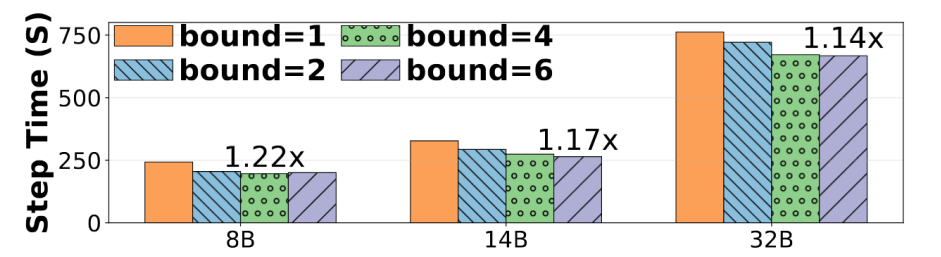
图10:不同大型语言模型(LLMs)在不同异步边界下的平均步骤时间比较
异步边界实验显示,α=1时在训练速度和稳定性间达到最优平衡,不同边界均能实现满意收敛性能。
(4)无服务器奖励计算优势
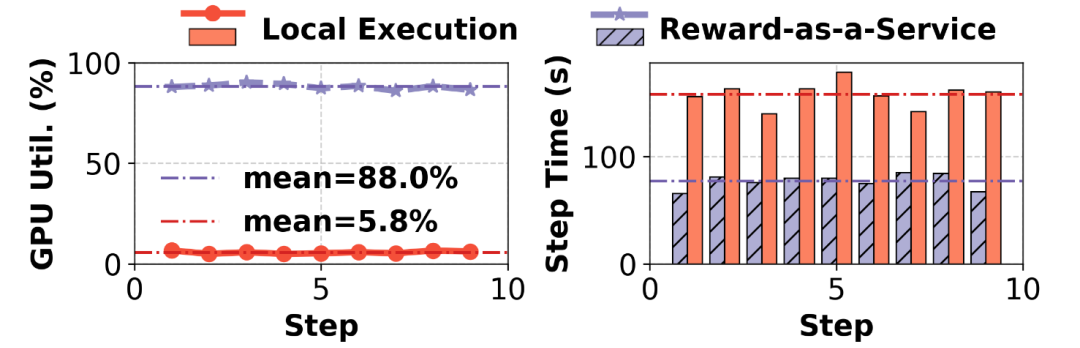
图11:专用本地GPU与使用Reward-as-a-Service的对比
无服务器奖励部署使GPU利用率从6%提升至88%,轨迹生成时间从158秒缩短至77秒,证明状态感知计算的高效性。
(5)生产环境验证

图12:生产级智能体强化学习工作负载特征分析
在3000+GPU集群中训练数百亿参数MoE模型,任务回合数分布1-48不等,验证预填充与解码任务共存。多层Docker缓存使env.reset成功率>99.99%,周级训练仅单次故障。
特征驱动优化实现1.66倍端到端加速,get_batch等待时间占比62%,优化后可减少22%训练时间。
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献238条内容
已为社区贡献238条内容

所有评论(0)