AI辅助数据分析系统
1. 项目概述
AI辅助数据分析工具是一款基于Python开发的智能数据分析平台,通过自然语言交互实现自动化数据处理、分析和可视化。该工具旨在降低数据分析门槛,让非技术人员也能轻松进行复杂数据分析,提高数据分析效率和决策质量。
1.1 项目定位
- 目标用户:数据分析师、业务人员、学生及科研人员
- 核心价值:简化数据分析流程,降低技术门槛,提高分析效率
- 应用场景:业务报表生成、数据洞察挖掘、学术研究数据分析
1.2 主要功能
- 支持Excel和CSV格式数据上传与验证
- 自然语言查询解析,支持中文提问
- 多种数据分析类型:描述性统计、趋势分析、占比分析、相关性分析等
- 丰富的可视化图表:柱状图、折线图、饼图、散点图、热力图等
- AI驱动的智能洞察生成
- 分析结果导出功能
2. 技术架构
2.1 整体架构
该项目采用模块化设计,前后端分离架构,主要分为数据层、分析层、AI层和展示层四个核心层次。
2.2 核心模块
| 模块名称 | 主要功能 | 文件位置 | 依赖技术 |
|---|---|---|---|
| 数据上传模块 | 文件验证、读取、预处理 | src/data_upload.py | pandas, openpyxl |
| 自然语言接口 | 查询解析、AI洞察生成 | src/nl_interface.py | langchain, OpenAI API |
| 数据分析模块 | 各类数据分析算法 | src/data_analysis.py | pandas, numpy |
| 可视化模块 | 图表生成与导出 | src/visualization.py | plotly, matplotlib |
| 洞察生成模块 | AI驱动的分析结论 | src/insights.py | langchain, OpenAI API |
| 缓存模块 | 数据缓存机制 | src/cache.py | cachetools |
| 主应用 | 应用入口与UI | app.py | streamlit |
2.3 技术栈
- 后端框架:Streamlit
- 数据处理:Pandas, NumPy
- 可视化:Plotly, Matplotlib
- 自然语言处理:LangChain, OpenAI API
- 缓存机制:cachetools
- 环境管理:python-dotenv
- 开发工具:pytest, flake8, black
成果演示
3. 核心功能实现
3.1 数据上传与验证
class DataUploader:
def validate_file(self, file):
# 检查文件格式
file_ext = os.path.splitext(file.name)[1].lower()
if file_ext not in self.supported_formats:
return False, f"不支持的文件格式。请上传以下格式之一: {', '.join(self.supported_formats)}"
# 检查文件大小
file.seek(0, 2) # Move to end of file
file_size = file.tell()
file.seek(0) # Reset file pointer
if file_size > self.max_file_size:
return False, f"文件大小超过限制。最大允许大小为 {convert_size(self.max_file_size)}"
if file_size == 0:
return False, "文件为空"
return True, "文件验证成功"
def preprocess_data(self, df):
# 基本数据预处理
df = df.dropna(how='all').dropna(axis=1, how='all')
df = df.reset_index(drop=True)
# 自动转换日期列
for col in df.columns:
if df[col].dtype == 'object':
try:
df[col] = pd.to_datetime(df[col])
except:
continue
return df
3.2 自然语言查询处理
系统使用LangChain结合OpenAI API实现自然语言查询解析,将用户的中文问题转换为结构化的数据分析任务。
class NLInterface:
def __init__(self):
self.llm = ChatOpenAI(
model_name=get_env_variable("OPENAI_MODEL", "gpt-3.5-turbo"),
temperature=0.3,
api_key=get_env_variable("OPENAI_API_KEY"),
base_url=get_env_variable("OPENAI_BASE_URL")
)
# 分析任务生成提示模板
self.analysis_prompt = PromptTemplate(
input_variables=["question", "columns_list", "data_types"],
template="""你是一位专业的数据分析师。请根据用户的问题和提供的数据信息,生成对应的数据分析任务。
用户问题: {question}
数据信息:
- 列名: {columns_list}
- 数据类型: {data_types}
请将用户问题转换为明确的数据分析任务,格式如下:
1. 分析类型: [描述性统计/趋势分析/占比分析/相关性分析/其他]
2. 分析目标: [明确的分析目标]
3. 涉及列: [相关的列名列表]
4. 图表类型: [推荐的图表类型,如柱状图/折线图/饼图/散点图/热力图/其他]
5. 分析逻辑: [简要的分析步骤]
"""
)
# 使用新的Runnable语法创建链
self.analysis_chain = self.analysis_prompt | self.llm | StrOutputParser()
def process_query(self, question, data_info):
# 处理用户查询,生成分析任务
# ...
result = self.analysis_chain.invoke({
"question": question,
"columns_list": columns_list,
"data_types": data_types
})
# ...
3.3 数据分析引擎
数据分析模块支持多种分析类型,包括描述性统计、趋势分析、占比分析和相关性分析等。
class DataAnalyzer:
def execute_analysis(self, df, analysis_task):
# 检查缓存
cache_key = str(analysis_task)
cached_result = self.cache.get(df, cache_key)
if cached_result:
return cached_result
analysis_type = analysis_task.get("analysis_type", "")
columns = analysis_task.get("columns", [])
try:
# 大数据集采样处理
sample_size = min(100000, len(df))
if len(df) > sample_size:
df_sample = df.sample(sample_size, random_state=42)
else:
df_sample = df
if analysis_type == "描述性统计":
result = self.descriptive_stats(df, columns)
elif analysis_type == "趋势分析":
# 趋势分析逻辑
# ...
elif analysis_type == "占比分析":
# 占比分析逻辑
# ...
elif analysis_type == "相关性分析":
# 相关性分析逻辑
# ...
else:
result = self.descriptive_stats(df, columns)
# 缓存结果
self.cache.set(df, result, cache_key)
return result
except Exception as e:
return {"error": f"执行分析时出错: {str(e)}"}
3.4 可视化生成
可视化模块支持多种图表类型,基于Plotly库实现交互式图表生成。
class Visualizer:
def generate_chart(self, df, analysis_task, analysis_result):
chart_type = analysis_task.get("chart_type", "柱状图")
# 大数据集采样
sample_size_map = {
"散点图": 50000, # 散点图点太多会影响可读性
"折线图": 100000,
"柱状图": 100000,
"饼图": 100000,
"热力图": 100000
}
sample_size = sample_size_map.get(chart_type, 100000)
if len(df) > sample_size:
df = df.sample(sample_size, random_state=42)
if chart_type == "柱状图" or chart_type == "条形图":
return self._generate_bar_chart(df, analysis_task, analysis_result)
elif chart_type == "折线图":
return self._generate_line_chart(df, analysis_task, analysis_result)
elif chart_type == "饼图":
return self._generate_pie_chart(df, analysis_task, analysis_result)
elif chart_type == "散点图":
return self._generate_scatter_chart(df, analysis_task, analysis_result)
elif chart_type == "热力图":
return self._generate_heatmap(df, analysis_task, analysis_result)
else:
return self._generate_bar_chart(df, analysis_task, analysis_result)
3.5 AI洞察生成
洞察生成模块使用OpenAI API基于数据分析结果和可视化信息生成自然语言的分析结论。
class InsightGenerator:
def generate_insights(self, analysis_result, visualization_info, data_info, user_question):
try:
# 格式化输入
formatted_analysis_result = self._format_analysis_result(analysis_result)
formatted_visualization_info = self._format_visualization_info(visualization_info)
formatted_data_info = self._format_data_info(data_info)
# 生成洞察
result = self.insight_chain.invoke({
"analysis_result": formatted_analysis_result,
"visualization_info": formatted_visualization_info,
"data_info": formatted_data_info,
"user_question": user_question
})
return {
"success": True,
"insights": result
}
except Exception as e:
return {
"success": False,
"error": f"生成洞察时出错: {str(e)}"
}
4. 关键技术点解析
4.1 自然语言处理与LLM集成
系统采用LangChain框架集成OpenAI API,实现了从自然语言查询到结构化分析任务的转换。关键技术点包括:
- 使用PromptTemplate构建结构化的LLM提示
- 采用Runnable语法创建分析链,提高代码可读性和维护性
- 实现了LLM输出的结构化解析,确保生成的分析任务格式一致
- 针对不同任务优化了提示模板,提高了LLM响应质量
4.2 大数据集处理策略
为了处理大规模数据集,系统实现了多种优化策略:
- 动态采样机制:根据不同分析类型和图表类型采用不同的采样大小
- 缓存机制:对分析结果进行缓存,避免重复计算
- 渐进式数据加载:先加载数据元信息,再根据需要加载完整数据
- 高效的数据分析算法:利用Pandas和NumPy的向量化操作提高计算效率
4.3 模块化设计与扩展性
系统采用高度模块化的设计,各功能模块之间通过清晰的接口交互,便于扩展和维护:
- 分析类型可扩展:通过添加新的分析方法即可支持新的分析类型
- 图表类型可扩展:通过添加新的图表生成方法即可支持新的图表类型
- 数据源可扩展:通过实现新的文件读取器即可支持新的数据格式
- AI模型可扩展:支持替换为其他LLM模型,如Claude、Gemini等
4.4 交互式可视化设计
系统使用Plotly库实现了高质量的交互式可视化:
- 支持多种图表类型,满足不同分析场景需求
- 实现了图表的交互功能,包括缩放、平移、悬停提示等
- 支持图表导出为PNG等格式
- 响应式设计,适配不同屏幕尺寸
5. 开发环境配置
5.1 环境要求
- Python 3.8+ (推荐使用Python 3.10+)
- 操作系统:Windows/macOS/Linux
- 内存:至少4GB,推荐8GB以上
- 磁盘空间:至少1GB可用空间
5.2 安装步骤
5.2.1 克隆仓库
git clone https://github.com/tianyi6-6/AI-Assisted-Data-Analysis.git
cd ai-assisted-data-analysis
5.2.2 安装依赖
# 使用pip安装依赖
pip install -r requirements.txt
# 或使用虚拟环境(推荐)
python -m venv venv
source venv/bin/activate # Linux/macOS
venv\Scripts\activate # Windows
pip install -r requirements.txt
5.2.3 配置环境变量
创建.env文件,配置API密钥和其他环境变量:
# OpenAI API配置
OPENAI_API_KEY=your_openai_api_key
OPENAI_BASE_URL=https://api.openai.com/v1
OPENAI_MODEL=gpt-3.5-turbo
# 应用配置
MAX_FILE_SIZE=104857600 # 100MB
MAX_ROWS=100000000 # 1亿行(有效无限)
5.3 运行应用
streamlit run app.py
应用将在浏览器中自动打开,默认地址为 http://localhost:8501
6. 使用指南
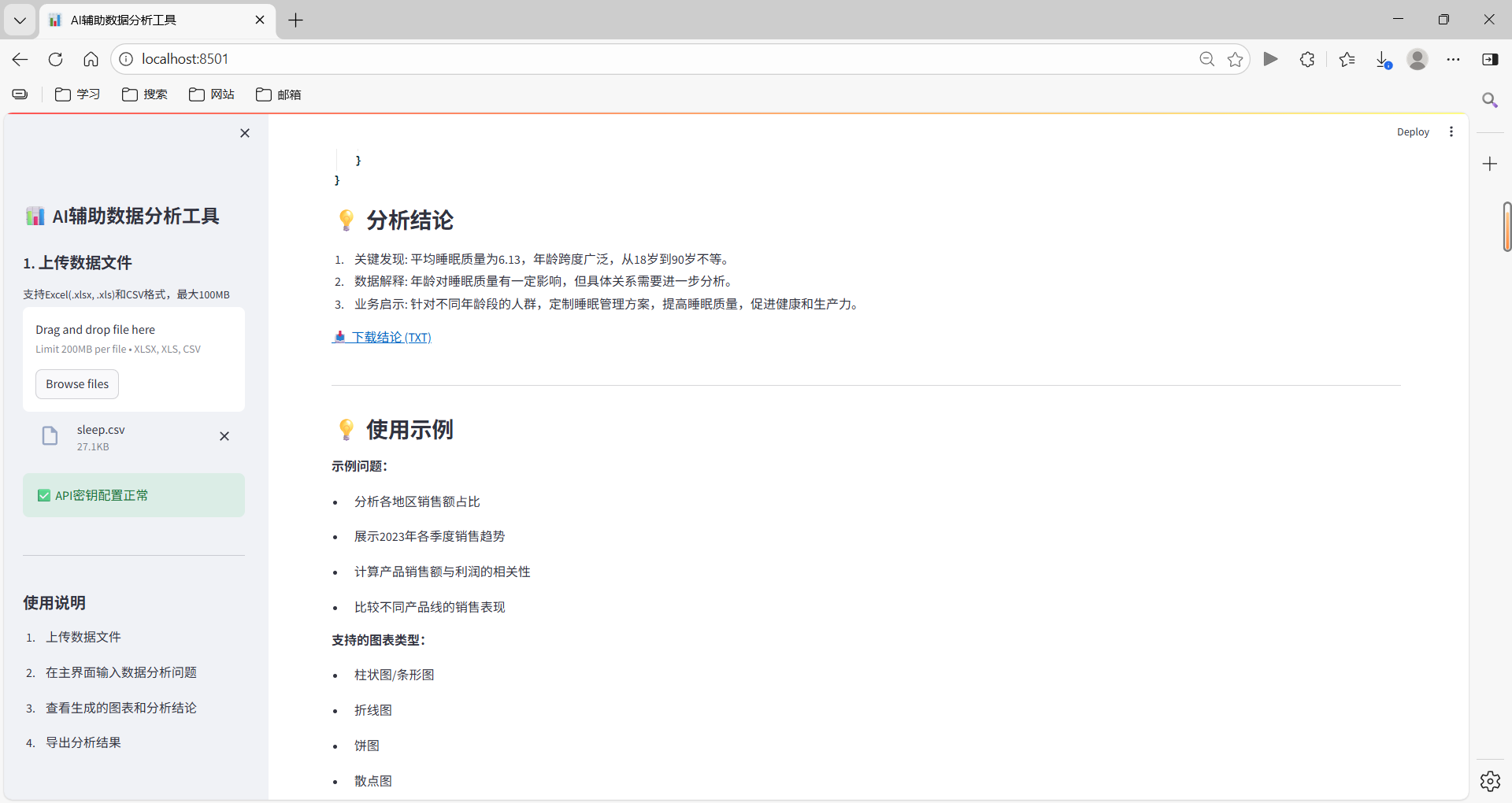
6.1 基本使用流程
- 上传数据:在左侧边栏上传Excel或CSV格式的数据文件
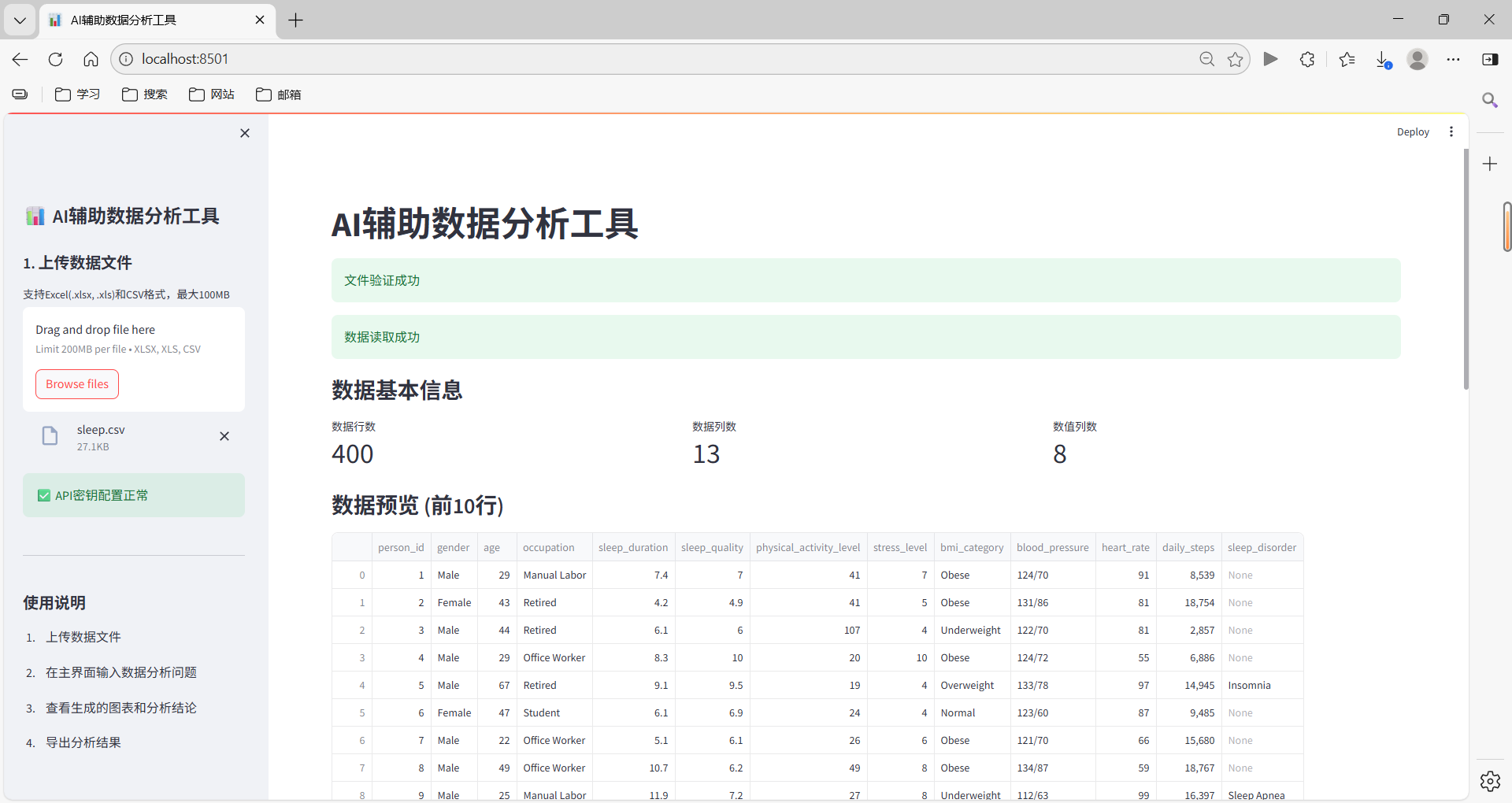
- 查看数据信息:系统自动显示数据基本信息和前10行数据预览
- 输入查询:在主界面输入数据分析问题,例如:“分析各地区销售额占比”
- 执行分析:点击"🚀 提问并分析"按钮,系统自动执行分析
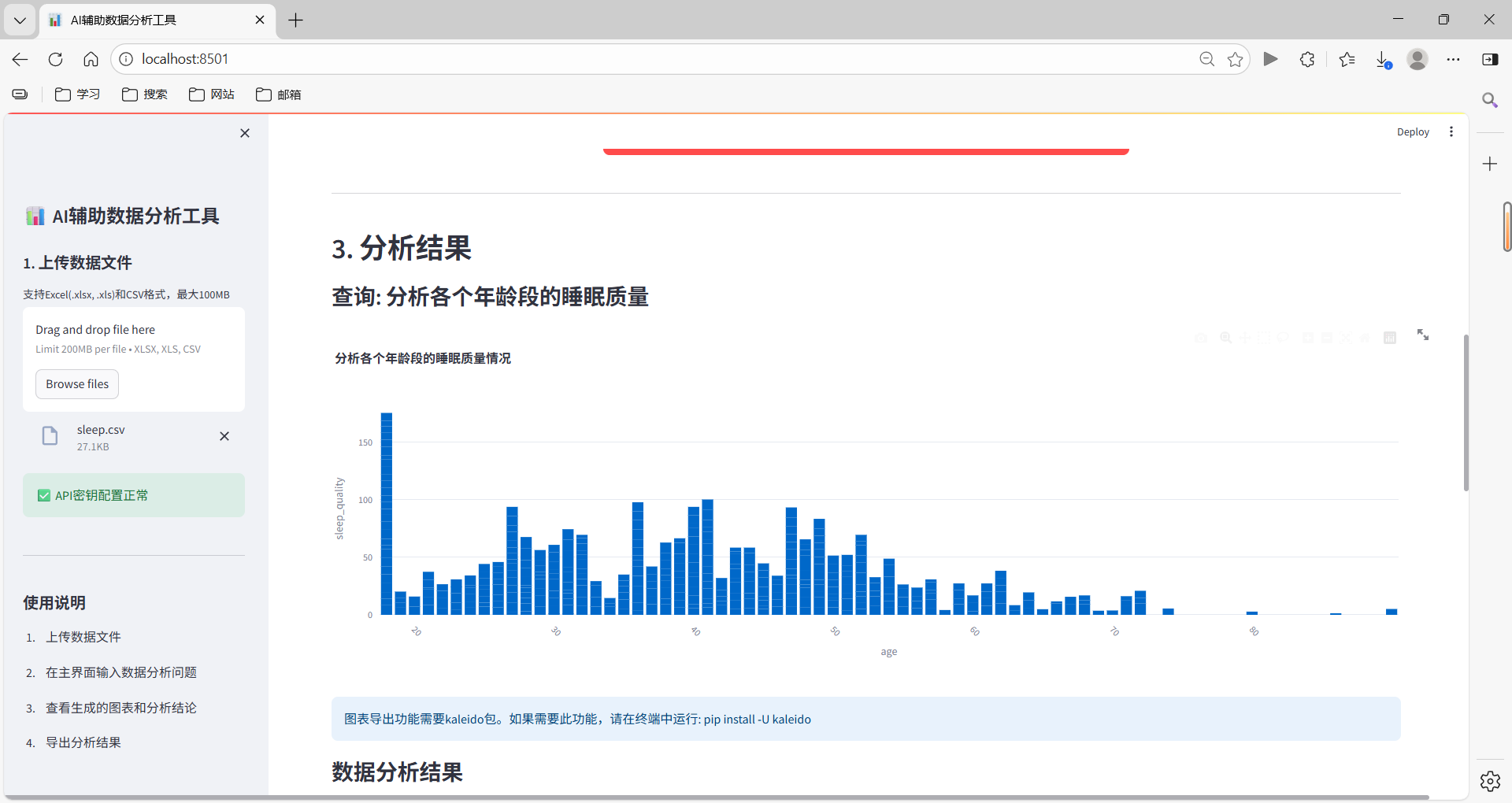
- 查看结果:系统生成图表和分析结论,可查看和导出
6.2 示例使用场景
场景1:销售数据分析
数据准备:包含销售日期、地区、产品、销售额等字段的销售数据
查询示例:
- “分析各地区销售额占比”
- “展示2023年各季度销售趋势”
- “计算产品销售额与利润的相关性”
- “比较不同产品线的销售表现”
预期结果:
- 饼图展示各地区销售额占比
- 折线图展示季度销售趋势
- 散点图或相关性矩阵展示销售额与利润的相关性
- 柱状图比较不同产品线的销售表现
场景2:用户行为分析
数据准备:包含用户ID、访问时间、页面类型、停留时长等字段的用户行为数据
查询示例:
- “分析用户访问时段分布”
- “展示不同页面类型的停留时长对比”
- “分析用户访问路径”
预期结果:
- 柱状图或折线图展示访问时段分布
- 箱线图或柱状图比较不同页面类型的停留时长
- 桑基图或流程图展示用户访问路径
6.3 高级功能
6.3.1 历史查询
系统会保存最近的查询历史,点击历史查询可快速重新执行分析。
6.3.2 结果导出
- 图表导出:支持PNG格式导出
- 分析结论导出:支持TXT格式导出
6.3.3 自定义分析
对于复杂的分析需求,可以通过详细描述分析逻辑来获得更精准的分析结果。例如:
“分析2023年每个月的销售额趋势,按产品类别分组,使用折线图展示,重点关注销售额最高的三个产品类别”
7. 常见问题解决方案
7.1 文件上传问题
问题1:上传文件时提示"不支持的文件格式"
解决方案:确保上传的文件是Excel(.xlsx, .xls)或CSV格式,检查文件扩展名是否正确。
问题2:上传文件时提示"文件大小超过限制"
解决方案:
- 压缩数据文件,删除不必要的列或行
- 修改
.env文件中的MAX_FILE_SIZE配置项,增加最大文件大小限制 - 对大数据集进行采样,只上传部分数据
问题3:上传文件时提示"文件中没有有效数据"
解决方案:
- 检查文件是否为空或只有表头
- 检查文件编码,确保使用UTF-8编码
- 对于CSV文件,检查分隔符是否正确
7.2 分析执行问题
问题1:分析时提示"没有找到数值列用于描述性统计"
解决方案:
- 检查数据中是否包含数值类型的列
- 确保查询中涉及的列是数值类型
- 对于需要数值列的分析,选择正确的列进行分析
问题2:分析时提示"生成洞察时出错"
解决方案:
- 检查OpenAI API密钥是否配置正确
- 确保网络连接正常
- 尝试简化查询,减少分析复杂度
问题3:图表显示异常或无法生成
解决方案:
- 检查查询中涉及的列是否存在于数据中
- 确保数据格式正确,特别是日期列
- 尝试使用不同的图表类型
7.3 性能问题
问题1:分析大型数据集时速度较慢
解决方案:
- 系统会自动对大数据集进行采样处理
- 可以尝试减少分析涉及的列数
- 关闭不必要的应用程序,释放系统资源
问题2:应用启动缓慢
解决方案:
- 确保Python版本为3.8+,推荐3.10+
- 检查网络连接,首次启动需要下载依赖资源
- 尝试升级依赖包到最新版本
8. 未来优化方向
8.1 功能增强
- 支持更多数据源:增加数据库连接、API接口等数据源支持
- 增强分析类型:增加预测分析、聚类分析、分类分析等高级分析功能
- 自定义可视化:允许用户自定义图表样式、颜色、布局等
- 多语言支持:支持中英文等多种语言
- 协作功能:支持多人协作分析和结果共享
8.2 性能优化
- 分布式计算:支持大规模数据集的分布式处理
- 更高效的缓存机制:实现基于磁盘的持久化缓存
- 并行计算:利用多核CPU和GPU加速数据分析
- 增量分析:支持数据更新后的增量分析
8.3 AI能力提升
- 模型优化:支持更多LLM模型,包括开源模型
- 微调模型:针对数据分析场景微调专用模型
- 上下文理解:增强LLM对数据上下文的理解能力
- 自动数据清洗:实现AI驱动的数据清洗和预处理
8.4 用户体验优化
- 更友好的界面设计:优化UI/UX设计,提升用户体验
- 更智能的查询建议:根据数据自动生成查询建议
- 交互式教程:提供内置的交互式教程和示例
- 移动端适配:支持移动端访问
9. 总结
AI辅助数据分析工具是一款功能强大、易于使用的智能数据分析平台,通过自然语言交互降低了数据分析门槛,提高了分析效率。该工具采用模块化设计,具有良好的扩展性和可维护性,支持多种数据分析类型和可视化图表。
未来,随着AI技术的不断发展和用户需求的不断变化,该工具将继续优化和增强功能,提供更强大、更智能的数据分析能力,为用户创造更大的价值。
10. 参考文献与资源
项目源码地址:https://github.com/tianyi6-6/AI-Assisted-Data-Analysis.git
作者:大新
发布日期:2026-01-09
版本:v1.0.0

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)