大模型微调发展现状
看下来,大模型微调领域范式创立时期是 2021-2023 年:LoRA (2021)、P-Tuning v2 (2021)、QLoRA (2023) 解决了大模型微调的根本问题:如何在有限硬件上高效且不牺牲太多性能地微调模型。是到23年之后,就没有大的变化,基本上都是在基石基础上缝缝补补的小改进。在工程领域,研究的更多的是把 QLoRA/LoRA 运行得更快、更稳定的问题。比如,FlashAtte
让大模型从通用领域过渡到垂类领域,往往需要采用大模型微调。
本文将汇总大模型中参数高效微调(PEFT,parameter-efficient fine-tuning)的主流方法,以此了解当前该领域的发展现状。
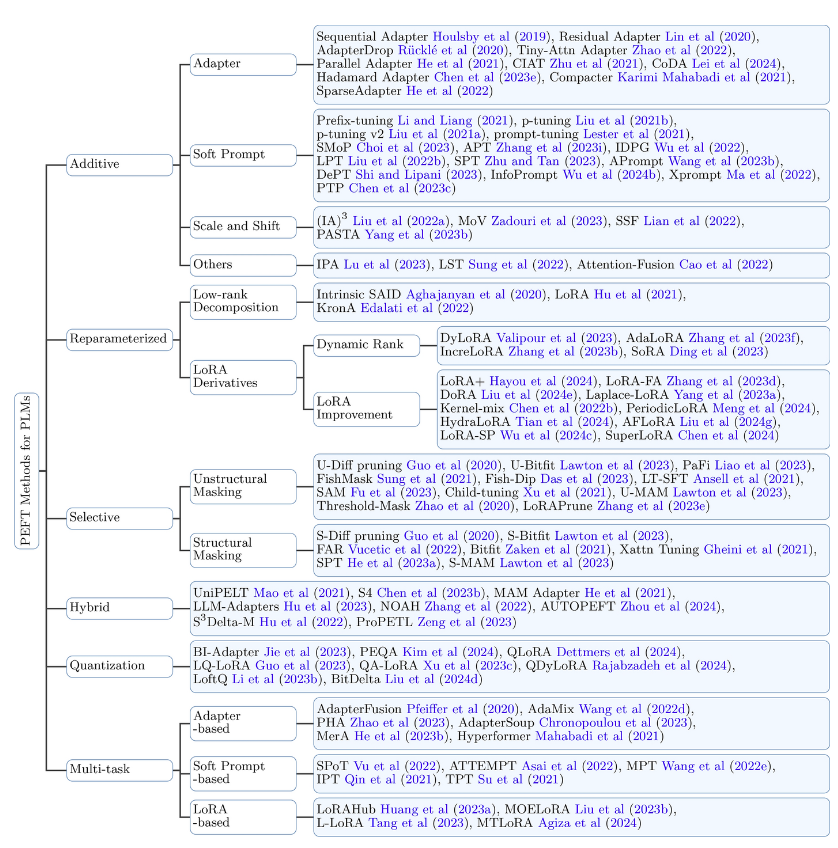
整体来看,主要分以下六大派系。
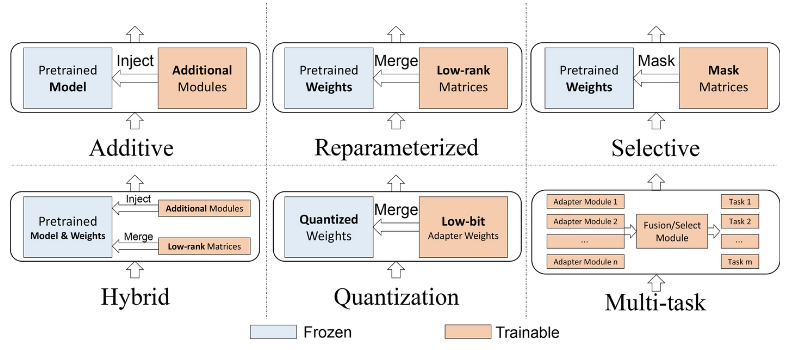
添加派(Additive)
添加派的方法是将一小组可训练参数添加到预训练模型中,并仔细集成到其架构中。
在对特定下游任务进行微调时,仅调整这些额外的组件或参数,保持原始预训练的模型参数不变。
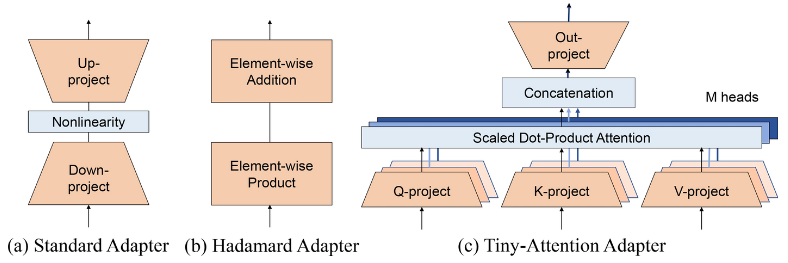
适配器(Adapter)
将小型适配器层插入到预先训练的模型中。
一些经典的方法包括:
- Standard Adapter:由下投影、非线性激活函数和上投影层组成
- Hadamard Adapter:采用权重向量和偏置向量,将 Hadamard 乘积(逐元素乘法)和逐元素加法应用于自注意力输出,从而产生新的自注意力输出
- Tiny-Attention Adapter:通过在 Adapter 中嵌入一个低维、低头数的注意力机制,对隐藏特征进行局部建模与动态重加权。
软提示(Soft prompt)
软提示是指将一系列可训练连续向量(称为软提示)附加到预训练语言模型的输入中。这些软提示充当附加上下文,引导模型获得特定任务所需的输出。
在训练过程中,软提示被优化以促进模型适应新任务,而模型的其余部分基本保持不变。
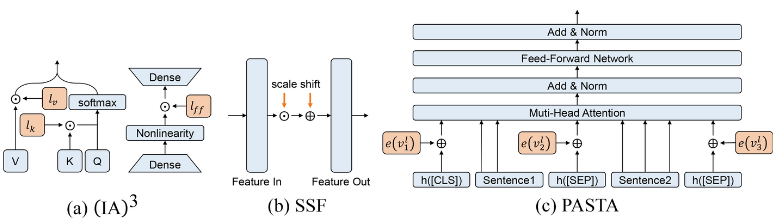
缩放和平移(Scale and Shift)
缩放和平移是指通过对模型内部激活或权重施加可学习的缩放与偏移参数,实现对特征分布的轻量调整,有点类似于BN层里面的缩放和平移参数。
一些经典的方法包括:
- (IA)3:添加三个缩放向量来分别缩放键、值和前馈激活
- SSF:通过线性变换修改预训练模型提取的深层特征
- PASTA:修改了预训练模型中的特殊令牌表示
重参数化派(Reparameterized)
重参数化派主要是构建低秩可学习参数矩阵以适应特定的下游任务。
训练时,仅对低秩参数矩阵进行微调,而在推理时,将学习到的矩阵与预训练的参数相结合,以确保推理速度不受影响。
低秩分解(Low-rank Decomposition)
通过低秩矩阵分解(LoRA)的方式,将原本高维的权重更新压缩为少量可训练参数。
这个方法估计是最有名的,不必多言。
LoRA 衍生方法(LoRA Derivatives)
在LoRA基础上,引入动态秩、自适应更新或结构改进机制,以进一步提升参数利用效率、稳定性或任务泛化能力。
以下是一些经典的改进方法:
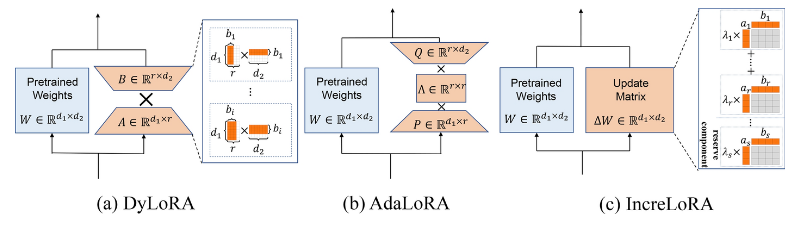
- DyLoRA:通过在训练期间针对一系列等级训练低等级适配器(LoRA)块,按不同等级排序,使模型能够灵活并在更广泛的等级范围内表现良好
- AdaLoRA:根据权重矩阵的重要性得分动态分配权重矩阵之间的预算,其中增量更新以奇异值分解的形式参数化
- IncreLoRA:在训练过程中根据每个模块的重要性分数增量分配可训练参数
选择派(Selective)
选择派是选择预训练模型参数的一个非常小的子集进行微调。
根据参数选择的方式不同,可分为非结构化选择和结构化选择。
非结构化选择(Unstructured Selection)
通过掩码、剪枝或参数重要性评估,仅更新模型中对任务最关键的参数子集,而不对整体结构施加约束,灵活性高但可解释性相对较弱。
一些经典的方法:
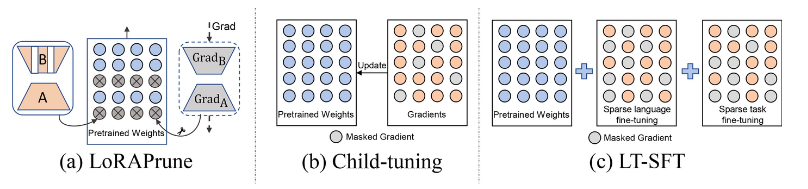
- LoRAPrune:利用低秩矩阵A和B的梯度来近似预训练模型权重W0中每个参数的重要性,然后使用低秩矩阵A和B以迭代和渐进的方式执行结构化剪枝,在保持性能的同时有效地减小模型的大小
- Child-tuning:在微调期间仅更新参数子集(称为子网络),同时屏蔽后向传递中剩余参数的梯度
- LT-SFT:根据彩票假设 (LTH) 的变体学习稀疏的实值掩码,以实现零样本跨语言迁移
结构化选择(Structured Selection)
以模块、层级或特定功能单元为粒度进行参数选择性更新,强调结构一致性,比非结构化选择会更有解释性。
比如,Xattn Tuning仅更新机器翻译 Transformer 模型中的交叉注意力参数,表明它可以实现与微调整个模型几乎相同的性能,同时还可以实现跨语言对齐的嵌入,从而减轻灾难性遗忘并实现零样本翻译功能。
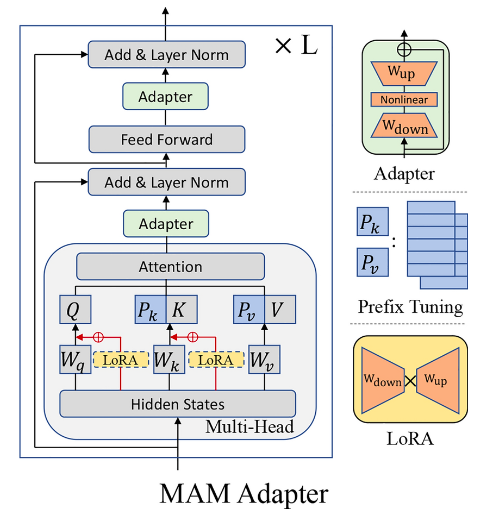
混合派(Hybrid)
通过组合多种参数高效微调范式(如 Adapter、Prompt、低秩分解或选择性更新),在表达能力与参数效率之间取得更优平衡。
换句话说,就是把前面的哪些方案做了融合。
量化派(Quantization)
通过低比特表示或量化感知训练,对可训练参数或权重更新过程进行压缩,使超大规模模型能够在受限硬件条件下完成微调与部署。
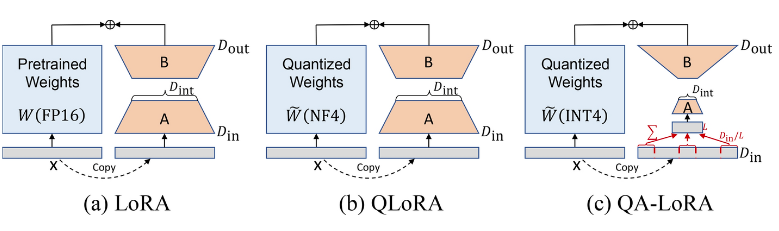
比较出名的工作是QLoRA,利用 4 位 NormalFloat (NF4) 精度来量化预训练模型,并通过双量化和分页优化器进行增强,以防止梯度检查点内存峰值。
QA-LoRA通过采用分组操作来解决量化和自适应之间的不平衡,增加了低比特量化的灵活性。它在微调期间,LLM 权重被量化以节省时间和内存,微调后,LLM 和辅助权重无缝集成到量化模型中,而不会损失准确性。
多任务派(Multi-task)
上面的各方法都是为下游单任务服务,多任务派就是用下游多个任务去共同学习,对于方法的类型上,没有大的区别:
- 基于 Adapter:通过共享或融合多个任务对应的适配器模块,实现跨任务知识迁移与高效复用。
- 基于软提示(Soft Prompt):为不同任务分配独立或可组合的提示向量,在共享主干模型的同时实现多任务适配。
- 基于低秩分解(LoRA):在低秩参数空间中引入任务条件或模块化设计,使模型能够在多个任务之间进行高效切换与联合训练。
总结
看下来,大模型微调领域范式创立时期是 2021-2023 年:
LoRA (2021)、P-Tuning v2 (2021)、QLoRA (2023) 解决了大模型微调的根本问题:如何在有限硬件上高效且不牺牲太多性能地微调模型。
是到23年之后,就没有大的变化,基本上都是在基石基础上缝缝补补的小改进。
在工程领域,研究的更多的是把 QLoRA/LoRA 运行得更快、更稳定的问题。比如,FlashAttention 等技术实现了训练效率的提升,以及内存管理策略的优化。
一句话总结,如果要工程应用,采用Adapter/LoRA,足够解决问题;如果要做学术研究,可挖掘的空间不大。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
作为一名老互联网人,看着AI越来越火,也总想为大家做点啥。干脆把我这几年整理的AI大模型干货全拿出来了。
包括入门指南、学习路径图、精选书籍、视频课,还有我录的一些实战讲解。全部免费,不搞虚的。
学习从来都是自己的事,我能做的就是帮你把路铺平一点。资料都放在下面了,有需要的直接拿,能用到多少就看你自己了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以点击文章最下方的VX名片免费领取【保真100%】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)