Whisper Server - 本地语音转文字服务器 (Electron+Vue3+Python) 支持OpenAI API兼容接口
摘要:本工具是基于Electron+Vue3+Python开发的本地语音转文字服务器,内置OpenAI Whisper模型,提供与Whisper API兼容的HTTP接口。核心功能包括离线语音转文字(支持多语言)、高性能推理(CPU模式可用)、API兼容、现代化UI界面及灵活配置。技术栈采用Electron28+Vue3前端和Python+Flask后端,适用于本地语音处理、开发测试、会议纪要等场
Whisper Server 本地语音转文字服务器 - 完整安装与使用指南
本地部署的语音转文字服务器,提供 OpenAI Whisper API 兼容接口,无需联网,保护隐私!
📖 前言
在 AI 时代,语音转文字已经成为非常常见的需求。OpenAI 的 Whisper 模型是目前最强大的开源语音识别模型之一,但使用云端 API 存在以下问题:
- 隐私问题 - 音频数据需要上传到云端
- 费用问题 - 按使用量收费,长期使用成本高
- 网络依赖 - 需要稳定的网络连接
- 速度限制 - 受网络带宽和 API 限流影响
Whisper Server 正是为了解决这些问题而生!它将 Whisper 模型部署在本地,提供与 OpenAI API 完全兼容的接口,让你可以:
- 🔒 数据不出本机,完全保护隐私
- 💰 一次部署,永久免费使用
- ⚡ 本地推理,无网络延迟
- 🔧 灵活配置,按需选择模型

🎯 功能特性
| 功能 | 说明 |
|---|---|
| 🎤 语音转文字 | 基于 OpenAI Whisper 模型,支持中文、英文等多种语言 |
| ⚡ 高性能推理 | 使用 faster-whisper 加速,CPU 模式下也能快速转录 |
| � API 兼容 | 提供与 OpenAI Whisper API 兼容的 HTTP 接口 |
| 🎨 现代化界面 | 深色主题,实时日志显示,状态监控 |
| � 灵活管配置 | 支持 tiny/base/small/medium/large-v3 多种模型 |
| � 请求统计 | |
| 💾 日志管理 | 支持日志保存和清空 |
| 🚀 开机自启 | 支持开机自动启动服务 |
📦 安装步骤
第一步:下载安装程序
下载本文提供的 Whisper Server Setup 1.0.0.exe 安装程序。
第二步:安装软件
- 双击运行安装程序
- 按提示完成安装
- 安装完成后,桌面会出现 “Whisper Server” 快捷方式
第三步:配置 Python 环境
Whisper Server 的核心转录功能依赖 Python 环境,请按以下步骤配置:
1. 安装 Python
- 访问 Python 官网 下载 Python 3.8 或更高版本
- 安装时 务必勾选 “Add Python to PATH”
- 安装完成后,打开命令提示符验证:
python --version
# 应显示 Python 3.8.x 或更高版本
2. 安装依赖包
打开命令提示符(CMD),执行:
pip install faster-whisper flask opencc-python-reimplemented
依赖说明:
faster-whisper- Whisper 模型的高性能实现flask- Web 服务框架opencc-python-reimplemented- 繁简转换(可选)
3. 首次下载模型
首次启动服务时,会自动下载 Whisper 模型。模型文件较大,请确保网络通畅:
| 模型 | 大小 | 下载时间(参考) |
|---|---|---|
| tiny | ~75MB | 1-2 分钟 |
| base | ~150MB | 2-3 分钟 |
| small | ~500MB | 5-10 分钟 |
| medium | ~1.5GB | 15-30 分钟 |
| large-v3 | ~3GB | 30-60 分钟 |
模型文件缓存在 C:\Users\你的用户名\.cache\huggingface\ 目录,下载一次后无需重复下载。
国内用户加速下载:在命令提示符中执行后再启动软件:
set HF_ENDPOINT=https://hf-mirror.com
🚀 使用指南
启动服务
- 打开 Whisper Server 应用
- 选择模型(推荐
small,平衡速度和准确度) - 设置端口(默认 8000)
- 点击 “启动服务” 按钮
- 等待模型加载完成,看到 “服务已启动” 提示即可
界面说明
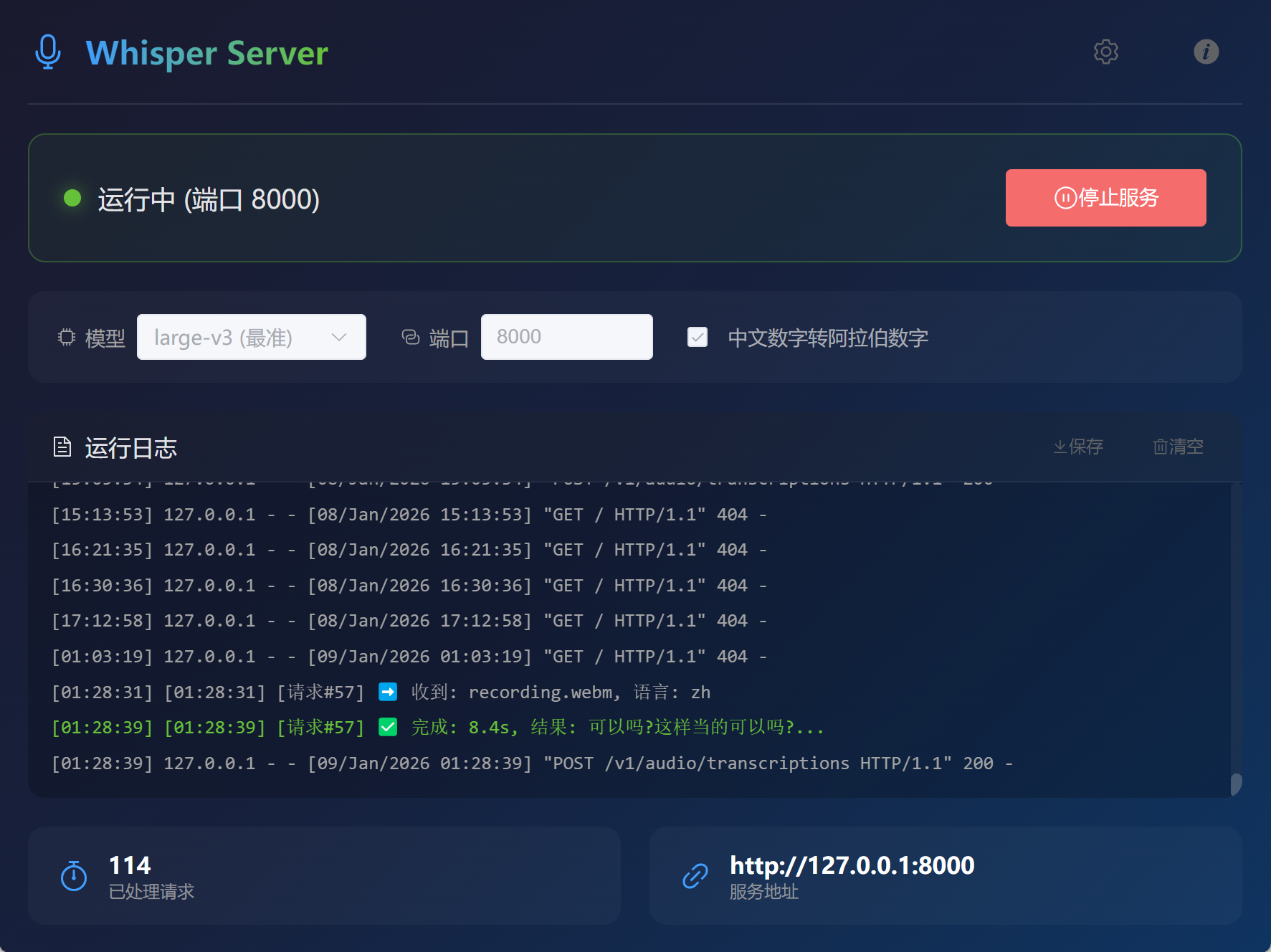
┌─────────────────────────────────────────────┐
│ Whisper Server [─][□][×]
├─────────────────────────────────────────────┤
│ 模型: [small ▼] 端口: [8000] │
│ ☑ 中文数字转换 ☐ 开机自启 │
│ │
│ [启动服务] [停止服务] │
├─────────────────────────────────────────────┤
│ 状态: ● 运行中 请求数: 42 │
├─────────────────────────────────────────────┤
│ 日志: │
│ [10:30:15] 服务已启动: http://127.0.0.1:8000│
│ [10:30:20] 收到请求: audio.webm │
│ [10:30:25] 转录完成: 你好世界... │
│ │
│ [保存日志] [清空日志] │
└─────────────────────────────────────────────┘
� API 接口文档
语音转文字接口
请求地址:
POST http://127.0.0.1:8000/v1/audio/transcriptions
请求格式: multipart/form-data
请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| file | File | 是 | 音频文件(支持 mp3, wav, webm, m4a, ogg) |
| language | String | 否 | 语言代码,默认 zh(中文) |
响应示例:
{
"text": "识别出的文字内容",
"language": "zh",
"duration": 3.5
}
错误响应:
{
"error": {
"message": "错误信息"
}
}
健康检查接口
请求地址:
GET http://127.0.0.1:8000/health
响应示例:
{
"status": "ok",
"model": "small",
"requests": 42
}
🔗 如何连接 Whisper Server
连接原理
Whisper Server 启动后会在本地开启一个 HTTP 服务,默认地址是:
http://127.0.0.1:8000
你的应用程序只需要向这个地址发送 HTTP 请求即可完成语音转文字。
连接流程图
┌─────────────────┐ HTTP POST ┌─────────────────┐
│ 你的应用程序 │ ───────────────────▶ │ Whisper Server │
│ (客户端) │ 音频文件 │ (本地服务) │
│ │ ◀─────────────────── │ │
│ │ JSON 结果 │ 127.0.0.1:8000 │
└─────────────────┘ └─────────────────┘
连接步骤
- 启动 Whisper Server,确保服务状态为"运行中"
- 记住服务地址(默认
http://127.0.0.1:8000) - 在你的应用中发送 POST 请求到
/v1/audio/transcriptions - 接收 JSON 格式的转录结果
连接配置参数
如果你的应用需要配置 Whisper 服务地址,通常需要填写:
| 配置项 | 值 | 说明 |
|---|---|---|
| API 地址 | http://127.0.0.1:8000 |
本地服务地址 |
| API 端点 | /v1/audio/transcriptions |
转录接口路径 |
| API Key | 留空或任意值 | 本地服务不需要认证 |
💻 完整调用案例
案例1:cURL 命令行测试
最简单的测试方式,打开命令提示符:
# Windows CMD
curl -X POST http://127.0.0.1:8000/v1/audio/transcriptions -F "file=@C:\Users\你的用户名\Desktop\test.mp3" -F "language=zh"
# Windows PowerShell
curl.exe -X POST http://127.0.0.1:8000/v1/audio/transcriptions -F "file=@C:\Users\你的用户名\Desktop\test.mp3" -F "language=zh"
返回结果:
{"text": "你好,这是一段测试音频", "language": "zh", "duration": 3.5}
案例2:Python 完整示例
"""
Whisper Server Python 调用示例
确保已安装: pip install requests
"""
import requests
import os
class WhisperClient:
"""Whisper Server 客户端"""
def __init__(self, base_url="http://127.0.0.1:8000"):
self.base_url = base_url
self.transcribe_url = f"{base_url}/v1/audio/transcriptions"
self.health_url = f"{base_url}/health"
def check_health(self):
"""检查服务是否正常运行"""
try:
response = requests.get(self.health_url, timeout=5)
if response.status_code == 200:
data = response.json()
print(f"✅ 服务正常 - 模型: {data['model']}, 已处理: {data['requests']} 个请求")
return True
except requests.exceptions.ConnectionError:
print("❌ 无法连接到 Whisper Server,请确保服务已启动")
except Exception as e:
print(f"❌ 连接错误: {e}")
return False
def transcribe(self, audio_path, language="zh"):
"""
转录音频文件
参数:
audio_path: 音频文件路径
language: 语言代码 (zh=中文, en=英文, ja=日语 等)
返回:
dict: {"text": "转录文字", "language": "zh", "duration": 3.5}
"""
if not os.path.exists(audio_path):
raise FileNotFoundError(f"音频文件不存在: {audio_path}")
with open(audio_path, "rb") as f:
files = {"file": (os.path.basename(audio_path), f)}
data = {"language": language}
print(f"📤 正在上传: {audio_path}")
response = requests.post(self.transcribe_url, files=files, data=data)
if response.status_code == 200:
result = response.json()
print(f"✅ 转录成功!")
print(f" 文字: {result['text']}")
print(f" 时长: {result['duration']:.1f}秒")
return result
else:
error = response.json().get("error", {}).get("message", "未知错误")
raise Exception(f"转录失败: {error}")
# ========== 使用示例 ==========
if __name__ == "__main__":
# 创建客户端
client = WhisperClient("http://127.0.0.1:8000")
# 1. 检查服务状态
if not client.check_health():
print("请先启动 Whisper Server!")
exit(1)
# 2. 转录音频文件
try:
result = client.transcribe("test.mp3", language="zh")
print(f"\n最终结果: {result['text']}")
except FileNotFoundError as e:
print(f"文件错误: {e}")
except Exception as e:
print(f"转录错误: {e}")
运行结果:
✅ 服务正常 - 模型: small, 已处理: 5 个请求
📤 正在上传: test.mp3
✅ 转录成功!
文字: 你好,欢迎使用语音转文字服务
时长: 3.2秒
最终结果: 你好,欢迎使用语音转文字服务
案例3:Python 批量转录
"""批量转录文件夹中的所有音频"""
import os
import requests
def batch_transcribe(folder_path, output_file="transcripts.txt"):
"""批量转录文件夹中的音频文件"""
url = "http://127.0.0.1:8000/v1/audio/transcriptions"
# 支持的音频格式
audio_extensions = {'.mp3', '.wav', '.webm', '.m4a', '.ogg', '.flac'}
# 获取所有音频文件
audio_files = [
f for f in os.listdir(folder_path)
if os.path.splitext(f)[1].lower() in audio_extensions
]
print(f"找到 {len(audio_files)} 个音频文件")
results = []
for i, filename in enumerate(audio_files, 1):
filepath = os.path.join(folder_path, filename)
print(f"\n[{i}/{len(audio_files)}] 处理: {filename}")
try:
with open(filepath, "rb") as f:
response = requests.post(url, files={"file": f}, data={"language": "zh"})
if response.status_code == 200:
text = response.json()["text"]
results.append(f"【{filename}】\n{text}\n")
print(f"✅ 完成: {text[:50]}...")
else:
results.append(f"【{filename}】\n转录失败\n")
except Exception as e:
results.append(f"【{filename}】\n错误: {e}\n")
# 保存结果
with open(output_file, "w", encoding="utf-8") as f:
f.write("\n".join(results))
print(f"\n✅ 完成! 结果已保存到: {output_file}")
# 使用示例
batch_transcribe("D:/音频文件夹", "转录结果.txt")
案例4:JavaScript/Node.js 示例
/**
* Whisper Server Node.js 调用示例
* 安装依赖: npm install axios form-data
*/
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
const WHISPER_URL = 'http://127.0.0.1:8000';
// 检查服务状态
async function checkHealth() {
try {
const response = await axios.get(`${WHISPER_URL}/health`);
console.log(`✅ 服务正常 - 模型: ${response.data.model}`);
return true;
} catch (error) {
console.log('❌ 无法连接到 Whisper Server');
return false;
}
}
// 转录音频文件
async function transcribe(audioPath, language = 'zh') {
const form = new FormData();
form.append('file', fs.createReadStream(audioPath));
form.append('language', language);
const response = await axios.post(
`${WHISPER_URL}/v1/audio/transcriptions`,
form,
{ headers: form.getHeaders() }
);
return response.data;
}
// 使用示例
async function main() {
if (!await checkHealth()) {
console.log('请先启动 Whisper Server!');
return;
}
const result = await transcribe('test.mp3', 'zh');
console.log('转录结果:', result.text);
}
main();
案例5:浏览器录音并转录(HTML 完整示例)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>语音转文字 Demo</title>
<style>
body { font-family: Arial; max-width: 600px; margin: 50px auto; padding: 20px; }
button { padding: 15px 30px; font-size: 16px; margin: 10px; cursor: pointer; }
#result { margin-top: 20px; padding: 20px; background: #f5f5f5; border-radius: 8px; min-height: 100px; }
.recording { background: #ff4444 !important; color: white; }
#status { color: #666; margin: 10px 0; }
</style>
</head>
<body>
<h1>🎤 语音转文字 Demo</h1>
<p>连接到: <code>http://127.0.0.1:8000</code></p>
<div>
<button id="recordBtn" onclick="toggleRecording()">开始录音</button>
<button onclick="checkServer()">检查服务</button>
</div>
<div id="status">点击"开始录音"按钮</div>
<div id="result">转录结果将显示在这里...</div>
<script>
const WHISPER_URL = 'http://127.0.0.1:8000';
let mediaRecorder = null;
let audioChunks = [];
let isRecording = false;
// 检查服务状态
async function checkServer() {
try {
const response = await fetch(`${WHISPER_URL}/health`);
const data = await response.json();
alert(`✅ 服务正常!\n模型: ${data.model}\n已处理: ${data.requests} 个请求`);
} catch (error) {
alert('❌ 无法连接到 Whisper Server\n请确保服务已启动');
}
}
// 切换录音状态
async function toggleRecording() {
if (isRecording) {
stopRecording();
} else {
await startRecording();
}
}
// 开始录音
async function startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
mediaRecorder = new MediaRecorder(stream, { mimeType: 'audio/webm' });
audioChunks = [];
mediaRecorder.ondataavailable = (event) => {
if (event.data.size > 0) audioChunks.push(event.data);
};
mediaRecorder.onstop = async () => {
stream.getTracks().forEach(track => track.stop());
await transcribeRecording();
};
mediaRecorder.start();
isRecording = true;
document.getElementById('recordBtn').textContent = '停止录音';
document.getElementById('recordBtn').classList.add('recording');
document.getElementById('status').textContent = '🔴 录音中...';
} catch (error) {
alert('无法访问麦克风: ' + error.message);
}
}
// 停止录音
function stopRecording() {
if (mediaRecorder && isRecording) {
mediaRecorder.stop();
isRecording = false;
document.getElementById('recordBtn').textContent = '开始录音';
document.getElementById('recordBtn').classList.remove('recording');
document.getElementById('status').textContent = '⏳ 正在转录...';
}
}
// 发送到 Whisper Server 转录
async function transcribeRecording() {
const audioBlob = new Blob(audioChunks, { type: 'audio/webm' });
const formData = new FormData();
formData.append('file', audioBlob, 'recording.webm');
formData.append('language', 'zh');
try {
const response = await fetch(`${WHISPER_URL}/v1/audio/transcriptions`, {
method: 'POST',
body: formData
});
const result = await response.json();
document.getElementById('status').textContent = `✅ 转录完成 (${result.duration.toFixed(1)}秒)`;
document.getElementById('result').innerHTML = `<strong>识别结果:</strong><br>${result.text || '(无内容)'}`;
} catch (error) {
document.getElementById('status').textContent = '❌ 转录失败';
document.getElementById('result').textContent = '错误: ' + error.message;
}
}
</script>
</body>
</html>
使用方法:
- 保存为
demo.html - 启动 Whisper Server
- 用浏览器打开
demo.html - 点击"开始录音"说话,再点击"停止录音"
- 等待转录结果
案例6:替代 OpenAI 官方 SDK
如果你的项目已经在使用 OpenAI 官方 SDK,只需修改 base_url 即可无缝切换:
"""使用 OpenAI 官方 SDK 连接本地 Whisper Server"""
from openai import OpenAI
# 创建客户端,指向本地服务
client = OpenAI(
api_key="not-needed", # 本地服务不需要 API Key,但参数必填
base_url="http://127.0.0.1:8000/v1" # 指向本地 Whisper Server
)
# 转录音频(与官方 API 用法完全一致)
with open("audio.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1", # 本地服务会忽略此参数
file=audio_file,
language="zh"
)
print(transcript.text)
切换对比:
# ❌ 原来使用 OpenAI 云服务(需要付费)
client = OpenAI(api_key="sk-xxxxxxxx")
# ✅ 改为使用本地 Whisper Server(免费)
client = OpenAI(
api_key="not-needed",
base_url="http://127.0.0.1:8000/v1"
)
# 后续代码完全不用改!
案例7:C# / .NET 示例
using System;
using System.IO;
using System.Net.Http;
using System.Text.Json;
using System.Threading.Tasks;
public class WhisperClient
{
private readonly HttpClient _httpClient;
private readonly string _baseUrl;
public WhisperClient(string baseUrl = "http://127.0.0.1:8000")
{
_baseUrl = baseUrl;
_httpClient = new HttpClient { Timeout = TimeSpan.FromMinutes(5) };
}
public async Task<string> TranscribeAsync(string filePath, string language = "zh")
{
using var content = new MultipartFormDataContent();
var fileBytes = await File.ReadAllBytesAsync(filePath);
content.Add(new ByteArrayContent(fileBytes), "file", Path.GetFileName(filePath));
content.Add(new StringContent(language), "language");
var response = await _httpClient.PostAsync(
$"{_baseUrl}/v1/audio/transcriptions", content);
var json = await response.Content.ReadAsStringAsync();
var result = JsonSerializer.Deserialize<JsonElement>(json);
return result.GetProperty("text").GetString();
}
}
// 使用示例
var client = new WhisperClient();
var text = await client.TranscribeAsync("test.mp3");
Console.WriteLine($"转录结果: {text}");
案例8:Java 示例
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.file.Files;
public class WhisperClient {
private final String baseUrl;
public WhisperClient() {
this.baseUrl = "http://127.0.0.1:8000";
}
public String transcribe(String filePath) throws Exception {
File file = new File(filePath);
String boundary = "----Boundary" + System.currentTimeMillis();
URL url = new URL(baseUrl + "/v1/audio/transcriptions");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "multipart/form-data; boundary=" + boundary);
try (OutputStream os = conn.getOutputStream();
PrintWriter writer = new PrintWriter(new OutputStreamWriter(os, "UTF-8"), true)) {
// 添加文件
writer.append("--").append(boundary).append("\r\n");
writer.append("Content-Disposition: form-data; name=\"file\"; filename=\"")
.append(file.getName()).append("\"\r\n");
writer.append("Content-Type: application/octet-stream\r\n\r\n");
writer.flush();
Files.copy(file.toPath(), os);
os.flush();
writer.append("\r\n");
// 添加语言参数
writer.append("--").append(boundary).append("\r\n");
writer.append("Content-Disposition: form-data; name=\"language\"\r\n\r\n");
writer.append("zh").append("\r\n");
writer.append("--").append(boundary).append("--\r\n");
}
// 读取响应
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(conn.getInputStream(), "UTF-8"))) {
StringBuilder response = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
response.append(line);
}
return response.toString();
}
}
public static void main(String[] args) throws Exception {
WhisperClient client = new WhisperClient();
String result = client.transcribe("test.mp3");
System.out.println("转录结果: " + result);
}
}
📊 模型选择指南
| 模型 | 大小 | 速度 | 准确度 | 内存需求 | 推荐场景 |
|---|---|---|---|---|---|
| tiny | ~75MB | ⚡⚡⚡⚡⚡ | ★★☆☆☆ | 1GB | 快速测试、实时字幕 |
| base | ~150MB | ⚡⚡⚡⚡ | ★★★☆☆ | 1GB | 日常使用、短音频 |
| small | ~500MB | ⚡⚡⚡ | ★★★★☆ | 2GB | 推荐!平衡之选 |
| medium | ~1.5GB | ⚡⚡ | ★★★★★ | 5GB | 高质量需求 |
| large-v3 | ~3GB | ⚡ | ★★★★★ | 10GB | 专业场景、多语言 |
选择建议:
- 🎯 一般用户:选择
small,准确度高,速度适中 - ⚡ 追求速度:选择
tiny或base - 🎯 追求质量:选择
medium或large-v3 - 💻 内存有限:选择
tiny或base
🌐 局域网访问配置
如果需要让局域网内其他设备访问 Whisper Server:
1. 开放防火墙端口
Windows 防火墙需要允许 8000 端口,以管理员身份运行 PowerShell:
netsh advfirewall firewall add rule name="Whisper Server" dir=in action=allow protocol=tcp localport=8000
2. 获取本机 IP
ipconfig
# 找到 IPv4 地址,如 192.168.1.100
3. 其他设备连接
# 其他设备使用服务器 IP 连接
client = WhisperClient("http://192.168.1.100:8000")
❓ 常见问题
Q1: 启动服务时提示 “Python 未安装”
解决方案:
- 确认已安装 Python 3.8+
- 确认安装时勾选了 “Add Python to PATH”
- 重启电脑后再试
Q2: 模型下载失败或很慢
解决方案:
- 检查网络连接
- 使用 HuggingFace 镜像(在 CMD 中执行后再启动软件):
set HF_ENDPOINT=https://hf-mirror.com
Q3: 转录结果不准确
解决方案:
- 尝试使用更大的模型(如
medium) - 确保音频质量清晰
- 减少背景噪音
Q4: 内存不足
解决方案:
- 使用更小的模型(如
tiny或base) - 关闭其他占用内存的程序
Q5: 端口被占用
解决方案:
- 在软件中修改端口号(如改为 8001)
- 或查找并关闭占用端口的程序
Q6: pip 安装依赖失败
解决方案:
使用国内镜像源:
pip install faster-whisper flask -i https://pypi.tuna.tsinghua.edu.cn/simple
🔧 配置说明
配置文件位置
配置自动保存在:%APPDATA%\whisper-server\config.json
配置项说明
| 配置项 | 说明 | 默认值 |
|---|---|---|
| model | 模型名称 | small |
| port | 服务端口 | 8000 |
| convertNum | 中文数字转阿拉伯数字 | true |
| autoStart | 开机自启动 | false |
| autoRun | 启动时自动运行服务 | false |
📝 更新日志
v1.0.0
- 🎉 首次发布
- ✅ 支持 Whisper 语音转文字
- ✅ 提供 OpenAI API 兼容接口
- ✅ 现代化界面
- ✅ 支持多种模型选择
- ✅ 支持开机自启动
如有问题或建议,欢迎在评论区留言交流!👋

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)