RAG技术打造企业智能知识库
·
一、项目背景与简介
随着大语言模型(LLM)的快速发展,越来越多的企业开始探索如何将AI技术应用于知识管理和智能问答场景。然而,通用大模型存在两个核心问题:
- 幻觉问题:模型可能生成不准确或不存在的信息
- 数据隐私:企业敏感数据不能直接上传到公共API
为了解决这些问题,我们开发了基于RAG(Retrieval-Augmented Generation,检索增强生成)技术的企业级智能知识库系统。该系统通过将企业私有文档向量化存储,在回答问题时先检索相关文档片段,再基于检索结果生成答案,确保回答的准确性和数据安全性。
核心特性
- ✅ 多格式文档支持:PDF、Markdown、Word、TXT四种格式
- ✅ 智能语义检索:基于向量相似度的精准匹配
- ✅ 上下文感知:保持最近5轮对话的连贯性
- ✅ 引用溯源:每个回答都标注参考来源
- ✅ 用户友好界面:Streamlit构建的现代化Web界面
- ✅ RESTful API:完整的后端接口支持二次开发
成果演示
- 上传文件
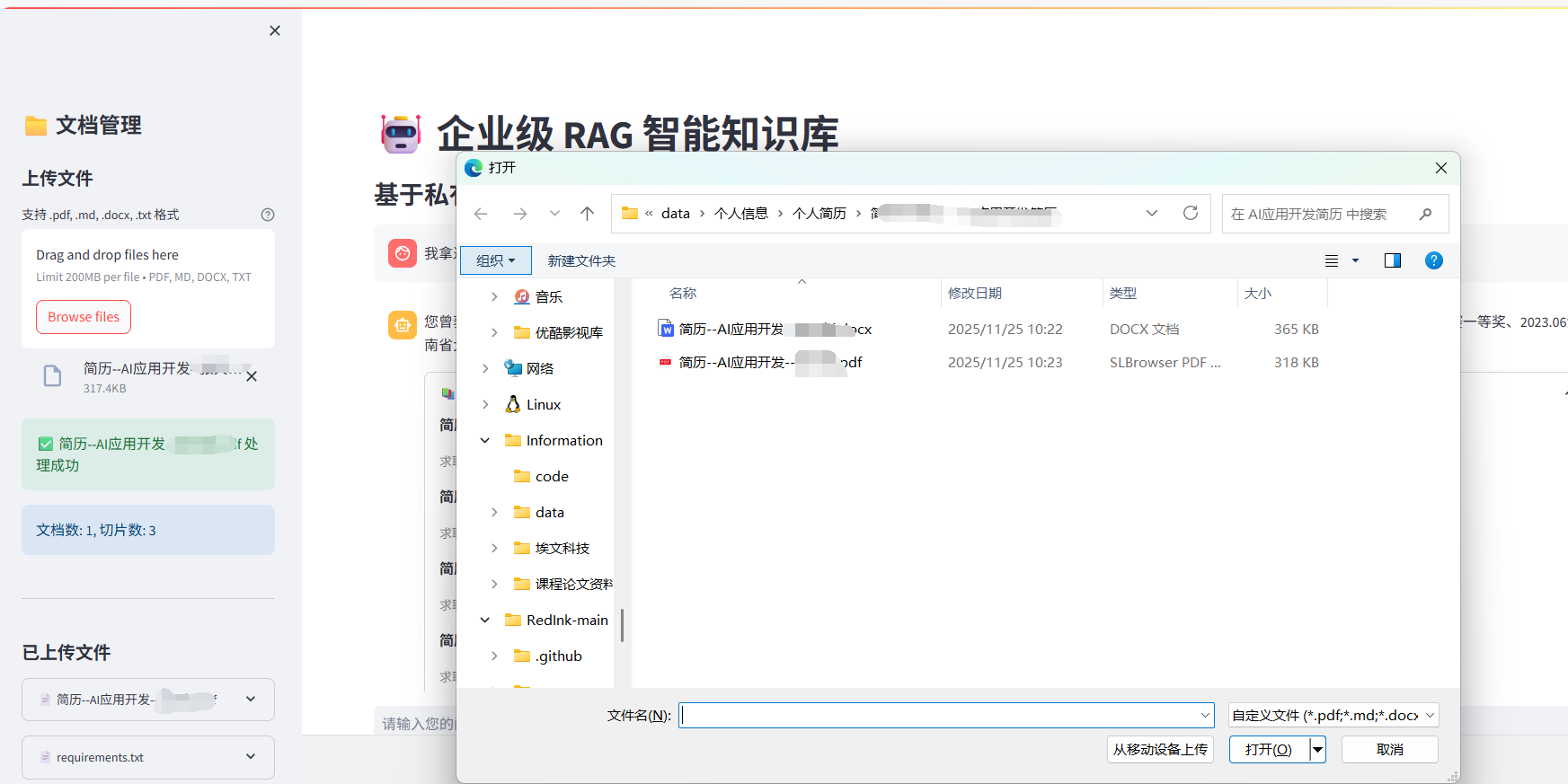
- 提问问题
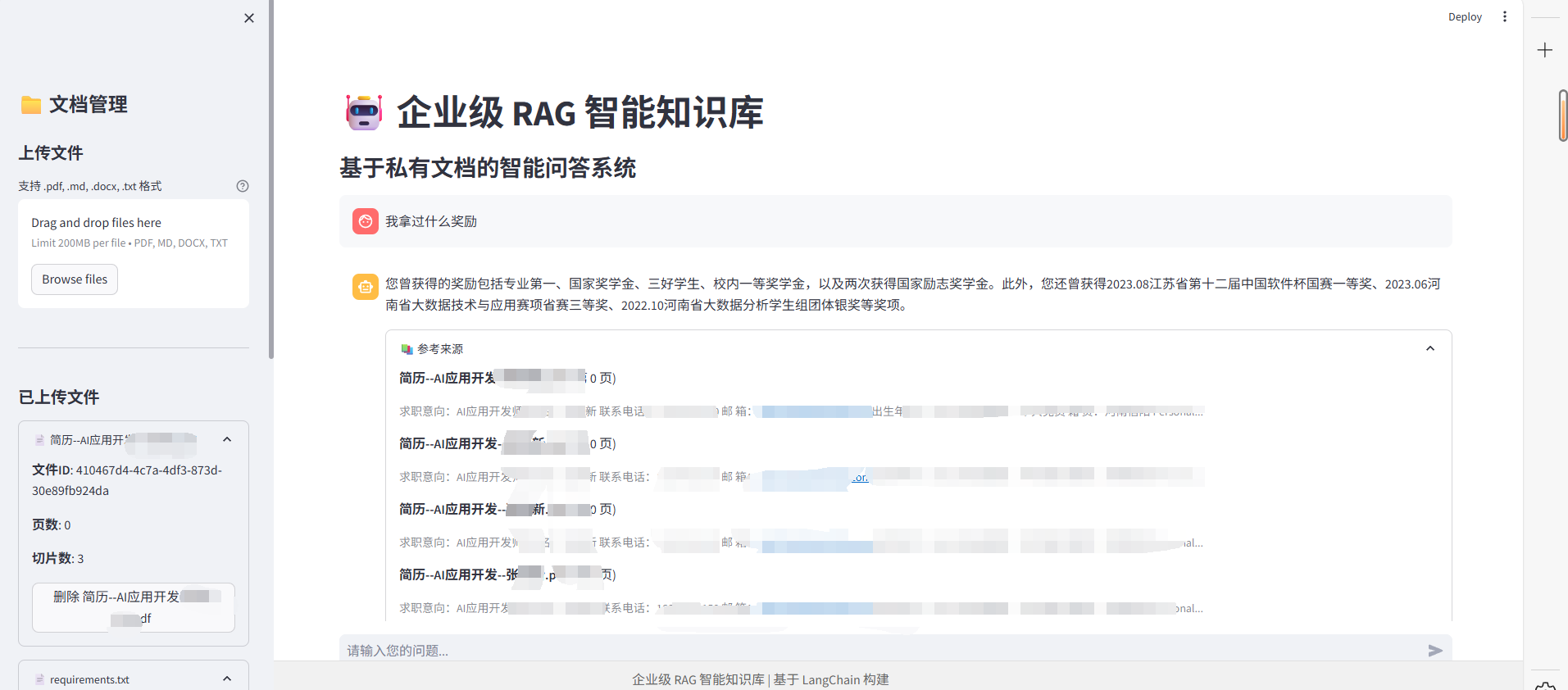
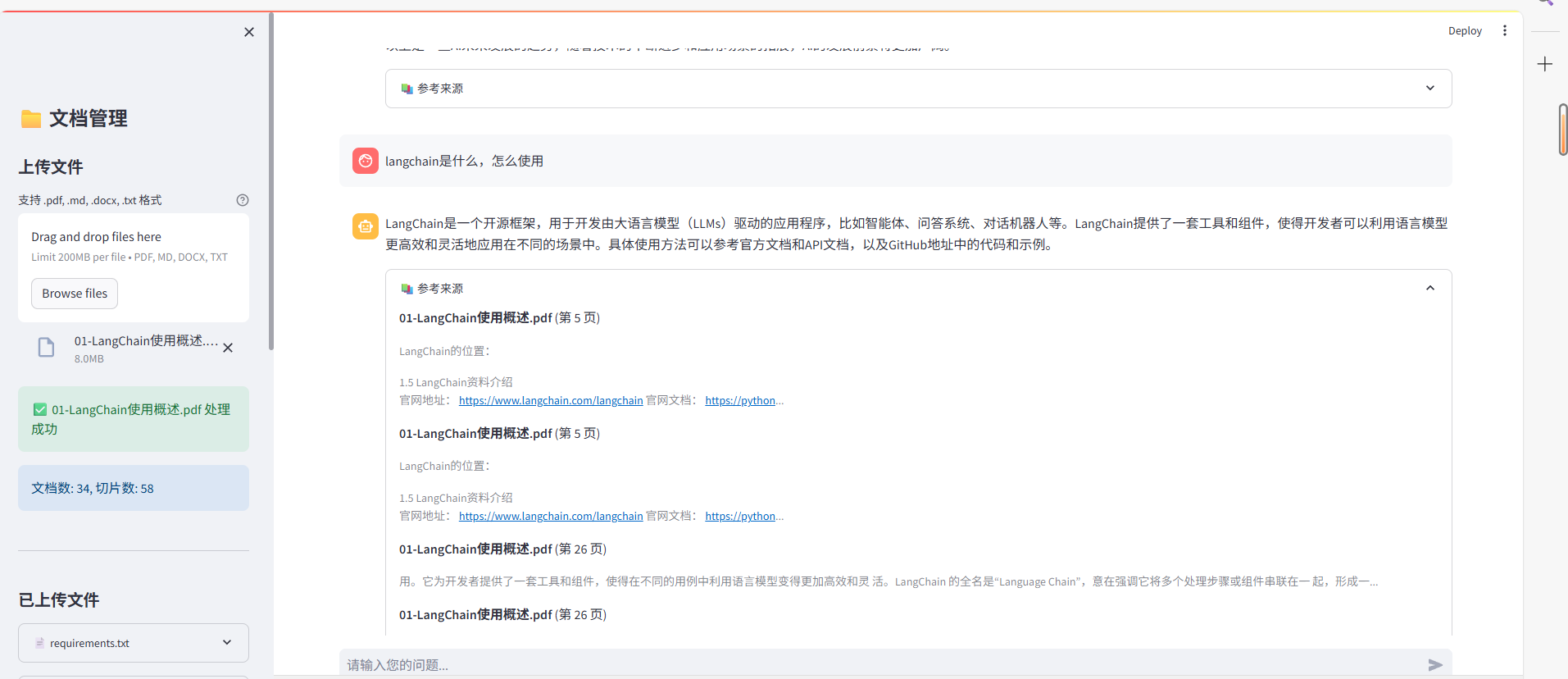
二、技术架构
2.1 技术栈选型
| 组件 | 技术选型 | 说明 |
|---|---|---|
| 核心框架 | LangChain 0.1.20 | 提供完整的RAG实现链路 |
| 向量数据库 | FAISS 1.13.2 | 高效的相似性搜索库 |
| 嵌入模型 | OpenAI text-embedding-3-small | 将文本转换为1536维向量 |
| 大语言模型 | DeepSeek-V3 / OpenAI GPT | 兼容OpenAI API格式 |
| 后端框架 | FastAPI 0.110.3 | 高性能异步Web框架 |
| 前端框架 | Streamlit 1.32.2 | 快速构建数据应用 |
2.2 系统架构图
┌─────────────────────────────────────────────────────────────┐
│ 用户交互层 (Streamlit) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 文档上传 │ │ 智能问答 │ │ 文档管理 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ API服务层 (FastAPI) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 文档上传API │ │ 问答API │ │ 搜索API │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 核心处理层 (RAGProcessor) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 文档加载器 │ │ 文本分割器 │ │ 向量化存储 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 相似性检索 │ │ 问答链 │ │ 对话记忆 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 数据存储层 (FAISS) │
│ 向量索引 + 文档元数据 │
└─────────────────────────────────────────────────────────────┘
2.3 核心模块设计
模块A:数据接入与处理
负责将各种格式的文档加载、分割并向量化存储。
# 核心代码片段
def load_document(self, file_path: str) -> List[Document]:
"""加载并解析文档"""
file_extension = Path(file_path).suffix.lower()
# 根据文件类型选择加载器
if file_extension == ".pdf":
loader = PyPDFLoader(file_path)
elif file_extension == ".txt":
loader = TextLoader(file_path, encoding="utf-8")
elif file_extension == ".docx":
loader = Docx2txtLoader(file_path)
elif file_extension == ".md":
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# 添加元数据(文件名、文件ID、页码)
file_name = Path(file_path).name
file_id = str(uuid.uuid4())
for doc in documents:
doc.metadata["file_name"] = file_name
doc.metadata["file_id"] = file_id
doc.metadata["page"] = doc.metadata.get("page", 1)
return documents
关键技术点:
- 多格式支持:使用LangChain的Document Loaders统一处理不同格式
- 元数据管理:为每个文档切片添加文件名、文件ID、页码等元数据
- 文本分割:使用
RecursiveCharacterTextSplitter进行语义切片
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=600, # 每个切片600字符
chunk_overlap=60, # 相邻切片重叠60字符
separators=["\n\n", "\n", " ", ""]
)
模块B:检索引擎
实现高效的向量相似性搜索。
def search_documents(self, query: str, k: int = 3) -> List[Document]:
"""搜索相关文档"""
if not self.vector_store:
return []
# 搜索相似文档
results = self.vector_store.similarity_search(
query=query,
k=k
)
return results
工作流程:
- 将查询文本转换为向量(使用OpenAI embedding模型)
- 在FAISS索引中查找最相似的k个向量
- 返回对应的文档切片
模块C:逻辑推理与安全机制
def get_qa_chain(self):
"""获取问答链"""
retriever = self.vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 10} # 获取前10个最相关片段
)
llm = ChatOpenAI(
temperature=0.1, # 低温度确保回答稳定
max_tokens=2000
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
return qa_chain
安全机制:
- 事实约束:模型只能基于检索到的文档片段生成答案
- 未知回答处理:当检索结果不足时,返回"在知识库中未找到相关内容"
- 对话记忆:使用
ConversationBufferWindowMemory保持上下文连贯性
模块D:用户交互界面
Streamlit实现的现代化Web界面。
# 聊天输入
if prompt := st.chat_input("请输入您的问题..."):
# 显示用户消息
with st.chat_message("user"):
st.markdown(prompt)
# 生成AI回答
with st.chat_message("assistant"):
result = rag_processor.answer_question(prompt)
st.markdown(result["answer"])
# 显示引用来源
if result.get("sources"):
with st.expander("📚 参考来源"):
for source in result["sources"]:
st.write(f"**{source['file_name']}** (第 {source['page']} 页)")
三、环境搭建与部署
3.1 环境要求
- Python 3.8+
- 4GB+ 内存
- 有效的OpenAI API密钥(或兼容的API服务)
3.2 安装步骤
步骤1:克隆项目
git clone https://github.com/tianyi6-6/RAG-Knowledge-Hub
cd RAG-Knowledge-Hub
步骤2:创建虚拟环境
python -m venv venv
# Windows
venv\Scripts\activate
# Linux/Mac
source venv/bin/activate
步骤3:安装依赖
pip install -r requirements.txt
步骤4:配置环境变量
创建.env文件:
# OpenAI API配置
OPENAI_API_KEY=sk-your-api-key-here
OPENAI_BASE_URL=https://api.openai.com/v1
# 或者使用DeepSeek API
DEEPSEEK_API_KEY=your-deepseek-api-key
DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
# 嵌入模型配置
EMBEDDING_MODEL=text-embedding-3-small
# 文本分割参数
CHUNK_SIZE=600
CHUNK_OVERLAP=60
# 向量存储路径
VECTOR_STORE_PATH=./data/vector_store
# LLM参数
LLM_TEMPERATURE=0.1
LLM_MAX_TOKENS=2000
3.3 启动服务
启动后端服务
uvicorn main:app --reload --host 0.0.0.0 --port 8000
访问API文档:
- Swagger UI: http://localhost:8000/docs
- ReDoc: http://localhost:8000/redoc
启动前端服务
streamlit run app.py --server.headless true
访问Web界面:http://localhost:8501
四、核心功能实现详解
4.1 文档上传与处理流程
# FastAPI端点实现
@app.post("/api/v1/documents/upload", response_model=ProcessFileResponse)
async def upload_file(file: UploadFile = File(...)):
"""上传并处理文档"""
# 1. 验证文件类型
allowed_extensions = {"pdf", "md", "docx", "txt"}
file_extension = os.path.splitext(file.filename)[1].lower().lstrip(".")
if file_extension not in allowed_extensions:
return ProcessFileResponse(
success=False,
message=f"不支持的文件类型,仅支持 {', '.join(allowed_extensions)} 格式",
file_name=file.filename
)
# 2. 保存到临时目录
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{file_extension}") as temp_file:
temp_file.write(await file.read())
temp_file_path = temp_file.name
# 3. 处理文件
result = rag_processor.process_file(temp_file_path)
# 4. 删除临时文件
os.unlink(temp_file_path)
return ProcessFileResponse(
success=result["success"],
message=result["message"],
file_name=result["file_name"],
document_count=result.get("document_count"),
chunk_count=result.get("chunk_count")
)
处理流程:
- 文件验证:检查文件类型是否在允许列表中
- 临时存储:将上传的文件保存到临时目录
- 文档解析:调用
RAGProcessor解析文档 - 文本分割:将文档分割成600字符的切片
- 向量化:使用OpenAI embedding模型将切片转换为向量
- 索引存储:将向量存储到FAISS索引中
- 清理临时文件:删除临时文件
4.2 智能问答实现
def answer_question(self, question: str) -> Dict[str, any]:
"""回答问题"""
try:
# 1. 获取问答链
qa_chain = self.get_qa_chain()
# 2. 执行问答
result = qa_chain({
"query": question,
"chat_history": self.memory.load_memory_variables({})
})
# 3. 更新对话记忆
self.memory.save_context(
{"input": question},
{"output": result["result"]}
)
# 4. 提取参考来源
sources = []
for doc in result["source_documents"]:
sources.append({
"file_name": doc.metadata.get("file_name", "未知文件"),
"page": doc.metadata.get("page", 1),
"content": doc.page_content[:100] + "..."
})
return {
"success": True,
"answer": result["result"],
"sources": sources,
"question": question
}
except Exception as e:
# 错误处理
return {
"success": False,
"answer": "抱歉,在知识库中未找到相关内容",
"sources": [],
"question": question
}
问答流程:
- 问题向量化:将用户问题转换为向量
- 相似性检索:在FAISS索引中查找最相关的文档片段
- 上下文构建:将检索到的片段组合成上下文
- LLM推理:将问题和上下文输入LLM生成答案
- 引用溯源:提取参考文档的元数据
- 对话记忆更新:将问答对保存到记忆中
4.3 错误处理与用户友好提示
def process_file(self, file_path: str) -> Dict[str, any]:
"""处理文件并添加到知识库"""
try:
documents = self.load_document(file_path)
chunks = self.split_documents(documents)
self.add_documents_to_vector_store(chunks)
return {
"success": True,
"message": f"文件处理成功",
"file_name": Path(file_path).name,
"document_count": len(documents),
"chunk_count": len(chunks)
}
except Exception as e:
error_msg = str(e).lower()
# 用户友好的错误提示
if "401" in error_msg or "invalid_api_key" in error_msg:
user_friendly_msg = "文件处理失败:无效的OpenAI API密钥,请检查.env文件中的配置"
elif "error code:" in error_msg or "api" in error_msg:
user_friendly_msg = "文件处理失败:API请求错误,请检查网络连接和配置"
elif "不支持的文件类型" in str(e):
user_friendly_msg = str(e)
else:
user_friendly_msg = "文件处理失败:请检查配置和网络连接"
return {
"success": False,
"message": user_friendly_msg,
"file_name": Path(file_path).name
}
五、使用示例
5.1 上传文档
- 打开Streamlit界面:http://localhost:8501
- 在左侧边栏点击"上传文件"
- 选择要上传的文档(支持PDF、MD、DOCX、TXT)
- 系统自动处理并显示处理结果
5.2 智能问答
- 在主界面的聊天输入框中输入问题
- 例如:“什么是RAG技术?”
- 系统基于知识库内容生成答案
- 答案下方显示参考来源(文件名和页码)
5.3 API调用示例
上传文档
curl -X POST "http://localhost:8000/api/v1/documents/upload" \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F "file=@document.pdf"
响应示例:
{
"success": true,
"message": "文件处理成功",
"file_name": "document.pdf",
"document_count": 10,
"chunk_count": 45
}
智能问答
curl -X POST "http://localhost:8000/api/v1/qa" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"question": "什么是RAG技术?"
}'
响应示例:
{
"success": true,
"message": "问答成功",
"answer": "RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索和生成的AI技术...",
"sources": [
{
"file_name": "RAG技术介绍.pdf",
"page": 3,
"content": "RAG技术通过检索相关文档片段,然后基于这些片段生成答案..."
}
],
"question": "什么是RAG技术?"
}
六、性能优化与扩展
6.1 性能优化建议
-
向量存储优化:
- 使用FAISS的GPU加速版本(
faiss-gpu) - 考虑使用更高效的索引类型(如IVF、HNSW)
- 使用FAISS的GPU加速版本(
-
缓存策略:
- 对embedding结果进行缓存
- 对常见问题的答案进行缓存
-
批处理:
- 批量处理文档上传
- 批量进行向量计算
6.2 功能扩展方向
-
多模态支持:
- 支持图片、视频等多媒体内容
- 使用多模态embedding模型
-
高级检索:
- 实现混合检索(关键词+向量)
- 添加重排序(Re-ranking)机制
-
用户管理:
- 添加用户认证和权限管理
- 支持多租户知识库
-
数据分析:
- 添加问答统计和分析功能
- 支持知识库质量评估
七、常见问题与解决方案
Q1: 文件上传失败,提示"无效的OpenAI API密钥"
原因:API密钥配置错误或已过期
解决方案:
- 检查
.env文件中的OPENAI_API_KEY配置 - 确认API密钥有效且有足够权限
- 如果使用DeepSeek,确保配置了
DEEPSEEK_API_KEY和DEEPSEEK_BASE_URL
Q2: 问答结果不准确
原因:检索到的文档片段不够相关
解决方案:
- 调整文本分割参数(
CHUNK_SIZE和CHUNK_OVERLAP) - 增加检索结果数量(修改
search_kwargs={"k": 10}) - 考虑使用更强大的embedding模型
Q3: 系统响应速度慢
原因:向量检索或LLM推理耗时较长
解决方案:
- 使用GPU加速FAISS
- 减少检索结果数量
- 使用更快的LLM模型(如GPT-3.5-turbo)
Q4: Streamlit界面显示异常
原因:Streamlit版本兼容性问题
解决方案:
- 确保Streamlit版本为1.32.2或更高
- 清除缓存:
streamlit cache clear - 重启Streamlit服务
八、总结与展望
8.1 项目总结
本项目实现了一个完整的企业级RAG智能知识库系统,具有以下特点:
- 技术先进:基于最新的LangChain框架和OpenAI API
- 功能完整:涵盖文档上传、管理、检索、问答全流程
- 用户友好:提供直观的Web界面和完整的API
- 安全可靠:确保企业数据隐私和回答准确性
8.2 未来展望
- 性能提升:引入更高效的向量数据库(如Milvus、Pinecone)
- 功能增强:添加文档版本控制、协作编辑等功能
- 部署优化:支持Docker容器化部署和Kubernetes编排
- 智能化升级:引入知识图谱和更先进的检索算法
九、参考资料
项目地址:https://github.com/tianyi6-6/RAG-Knowledge-Hub
作者:大新
本文首发于CSDN,转载请注明出处

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)