2025 年 LLM 的六项范式转变——Andrej Karpathy 的观察
我们今天为大家带来的文章,作者的核心观点是:2025 年大语言模型的真正突破不在于参数规模的扩张,而在于训练范式、智能形态与应用架构的深层转变 —— 尤其是基于可验证奖励的强化学习(RLVR)、AI 作为“幽灵”而非“动物”的认知重构,以及面向垂直场景的新型 LLM 应用层的崛起。
编者按: 我们今天为大家带来的文章,作者的核心观点是:2025 年大语言模型的真正突破不在于参数规模的扩张,而在于训练范式、智能形态与应用架构的深层转变 —— 尤其是基于可验证奖励的强化学习(RLVR)、AI 作为“幽灵”而非“动物”的认知重构,以及面向垂直场景的新型 LLM 应用层的崛起。
文章系统回顾了 2025 年 LLM 领域的六大关键趋势:首先,RLVR 成为新训练核心,通过可自动验证的奖励信号,模型自发演化出类推理行为;其次,作者提出“召唤幽灵”隐喻,强调 LLM 智能与生物智能在底层逻辑上的根本差异,并解释了其“锯齿状智能”——在某些任务上超人,在另一些任务上却异常脆弱;第三,以 Cursor 为代表的新型 LLM 应用层,通过上下文工程、多调用编排与“自主性滑块”,正在重塑人机协作范式;此外,Claude Code 展示了本地化 AI 智能体的潜力,vibe coding 让编程走向大众化,而 Google Gemini Nano banana 则预示了 LLM 图形用户界面(GUI)的未来方向。
作者 | Andrej Karpathy
编译 | 岳扬
2025 年是大语言模型(LLM)发展势头强劲、进步显著的一年。以下是我个人认为值得关注且略感意外的几项“范式转变”,这些改变技术格局的概念性突破让我印象深刻。
01 基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)
2025 年初,各大实验室的 LLM 生产训练流程大致如下:
1)预训练(GPT-2/3,~ 2020 年)
2)监督微调(InstructGPT,~ 2022 年)以及
3)基于人类反馈的强化学习(RLHF,~ 2022 年)
这套成熟方案曾长期被视为生产级 LLM 的训练标准。然而到了 2025 年,基于可验证奖励的强化学习(RLVR) 成为被广泛接受和采用的新核心训练阶段。通过在多种环境中(例如数学题或编程题这类场景)让 LLM 针对可自动验证的奖励进行训练,模型会自发地发展出一些在人类看来像是“推理”的策略 —— 它们学会将问题求解过程拆解为一系列中间计算步骤,并掌握多种来回试探、逐步厘清问题的解题策略(参见 DeepSeek R1 论文中的示例)。在原有范式下,这类策略极难实现,因为 LLM 并不清楚“最优的推理路径”或“对错误的修正方式”究竟长什么样 —— 它必须通过针对奖励信号的优化过程,自己摸索出对自己有效的方法。
与 SFT 和 RLHF 这两个计算量相对较小、训练周期较短的阶段不同,RLVR 依赖于客观(不可作弊)的奖励函数,因此支持更长时间的优化。事实证明,RLVR 在单位算力下的能力提升(capability / $)非常高,导致原本用于预训练的计算资源被大量转移至此。 因此,2025 年大部分模型能力的提升,主要来自于各大 LLM 实验室集中算力“消化”这一新训练阶段(RLVR)所释放出的潜力。总体来看,我们看到的模型参数规模大致相当,但强化学习(RL)的训练时长显著增加。此外,这一新阶段还带来了一个全新的“调节旋钮”(以及与之对应的缩放规律):通过生成更长的推理轨迹、增加“思考时间”,即可在推理时以更多计算换取更强能力。OpenAI 的 o1 模型(2024 年底)首次展示了 RLVR 的效果,但真正让人直观感受到质变的拐点,是 2025 年初发布的 o3 版本。
02 Ghosts vs. Animals / Jagged Intelligence
2025 年是我(而且我认为整个行业也是如此)第一次开始以更直觉、更切身的方式,理解 LLM 智能的“形态”。我们并非在“进化/培育动物”,而是在“召唤幽灵”。LLM 技术栈的方方面面 —— 包括神经网络架构、训练数据、训练算法,尤其是目标函数对模型行为的塑造力(Optimization pressure)都与生物智能截然不同,因此我们所获得的智能体在智能空间中自然也大不相同,用动物的视角去理解它们是不恰当的。 如果从监督信号的底层信息单位来看,人类的神经网络是为了在丛林中保障部落生存而优化的,而 LLM 的神经网络则是为了模仿人类文本、在数学难题中获取可验证奖励,以及在 LM Arena 上赢得人类的一个点赞而优化的。随着可验证的领域支持 RLVR,大语言模型在这些领域及其周边任务上的能力会出现“尖峰式”跃升,从而整体呈现出一种令人忍俊不禁的、起伏剧烈的锯齿状性能特征,它们可能同时是一位通晓万物的天才,又是一个充满困惑且认知能力受限的小学生,甚至在几秒内就被越狱攻击(jailbreak)诱骗,导致你的数据被窃取。
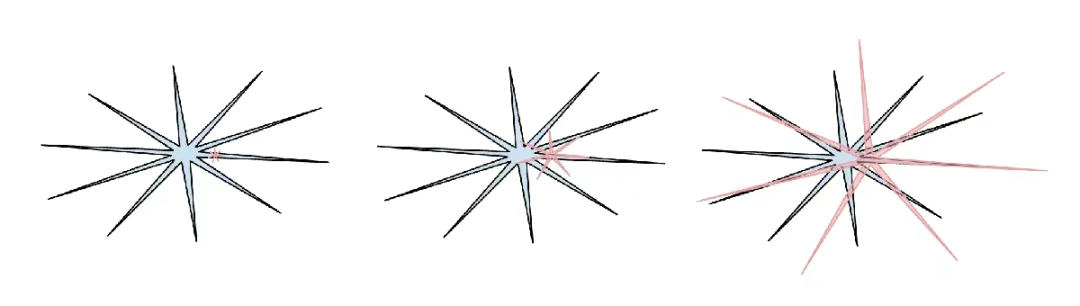
(人类智能:蓝色,AI 智能:红色。我很喜欢这个梗图(很抱歉我找不到了它最初在 X 上的原始出处),因为它指出人类智能本身也以自己独特的方式呈现出“锯齿状”。)
与上述现象密切相关的是,我在 2025 年对各类基准测试(benchmarks)普遍感到冷漠,并且不再信任它们。核心问题在于,基准测试(benchmarks)在设计上几乎天然就是可验证的环境,因此很容易被 RLVR(以及通过合成数据生成的较弱形式)进行针对性优化。现在的 LLM 团队为了刷高 benchmark 分数,会围绕那些测试题在模型“理解空间”里的位置,大量生成类似题目来训练模型,让它只在这些点上变得超强,别的地方先不管。结果就是模型能力像锯齿一样 —— 榜单上分数爆表,实际用起来漏洞百出。而“变相在测试集上训练”这件事,已经玩出了花,成了行业潜规则。
如果在碾压所有基准测试(benchmark)的同时,却仍未实现通用人工智能(AGI),那将会是一种什么景象?
03 Cursor / 新的 LLM 应用层
关于 Cursor(除了它今年以火箭般的速度崛起之外),我觉得最值得注意的是:Cursor 不仅自己成功了,更重要的是它开创了一种新模式,大家突然意识到:“哦,原来 LLM 应用可以这样做!”于是开始设想各行各业的“Cursor”。正如我今年在 Y Combinator 演讲中所强调的(附有文字稿[1]和视频[2]),像 Cursor 这样的 LLM 应用,会为特定垂直领域(如编程、法律、设计等)将多次 LLM 调用打包并编排成一个整体工作流:
- 它们负责 “上下文工程”(context engineering)
- 它们在后台将多次 LLM 调用编排成日益复杂的 DAG(有向无环图) ,并在此过程中精细权衡性能与计算成本
- 它们为“human-in-the-loop”中提供面向特定应用场景的图形界面(GUI)
- 它们提供一个 “自主性滑块”(autonomy slider) —— 允许用户动态调节 AI 的决策自由度
2025 年,业界大量讨论都围绕着这个新出现的应用层的“厚度”,LLM 实验室(如 OpenAI、Anthropic 等)会吃掉所有上层应用,还是说 LLM 应用领域仍是广阔天地,大有作为?我个人认为,LLM 实验室会倾向于培养出一个“通才型的大学生”,而 LLM 应用则会通过注入私有数据、传感器、执行器和反馈回路,对这些“大学生”进行组织、微调,并真正激活成部署在具体垂直领域的“专业从业者”。
04 Claude Code / 驻守在我们计算机的 AI
Claude Code(CC)成为首个令大家信服的 LLM 智能体(Agent)范例 —— 它以循环迭代方式将工具使用与推理串联起来,用于解决需要长时间、多步骤的复杂问题。此外,对我而言,CC 的另一个特点是:它运行在我们的本地计算机上,并直接利用我们本地的私有环境、数据和上下文。我认为 OpenAI 在这一点上判断有误,因为他们早期在 Codex / 智能体(agent)方面的尝试,聚焦于通过 ChatGPT 编排云端容器中的智能体,而不是直接在用户的本地机器(localhost)上运行。尽管云端运行的智能体集群(agent swarms)听起来像是“AGI 的最终形态,但我们正处在一个能力“锯齿状”、演进缓慢的中间阶段,在这种背景下,让智能体直接运行在开发者本机上反而更合理。
需要注意的是,真正关键的区别并不在于“AI 运算”(AI ops)到底跑在哪儿(云端、本地,或其他地方),而在于其他因素 —— 那台已经开机并运行着的电脑,以及它上面已安装的软件、当前上下文、数据、密钥、配置,还有低延迟的交互体验。
Anthropic 正确把握了这一优先级,并将 Claude Code(CC)打造成一个精巧的、极简的命令行(CLI)形态,这种形态彻底改变了人们对 AI 的认知:它不再只是一个像 Google 那样需要你主动打开浏览器去访问的网站,而更像是一个“寄居”在你电脑里的小精灵(或幽灵)。这是一种与 AI 交互的全新且截然不同的范式。
05 Vibe coding
2025 年,AI 的能力达到了一个质变的临界点:人们现在能仅通过自然语言就构建出各种令人为之惊叹的程序,甚至完全不用去想“代码”本身的存在。说来好笑,我是在一条思绪如泉涌的推文[3]中随口创造了 “vibe coding”(氛围编程)这个词,当时根本没想到它居然火了 😃。通过 vibe coding,编程就不再是经过大量训练的专业人士的专属领域,而是任何人都能上手的事情。从这个角度看,它再次印证了我在《Power to the people: How LLMs flip the script on technology diffusion》[4]中写到的观点:与迄今为止几乎所有其他技术都不同,普通大众从 LLM 中的获益远大于专业人士、企业和政府。
但 vibe coding 的意义不仅在于帮助普通人接触编程 —— 它也让受过专业训练的开发者能够写出大量原本根本不会被实现的(vibe coded)软件。
在 nanochat 中,我用 vibe coding 自己写了一个高度定制的、高效的 Rust 版 BPE tokenizer,且无需依赖现成的库,也无需深入学习 Rust。今年我用 vibe coding 快速做出了许多小应用原型,只为实现我脑中那些一闪而过的想法(例如:menugen[5]、llm-council[6]、reader3[7]、HN time capsule[8])。我甚至用 vibe coding 写过一整个临时应用,只为定位一个 bug —— 为什么不呢?毕竟代码突然变得成本极低(free)、短暂(ephemeral)、可塑(malleable)、用完即可丢弃(discardable after single use)。Vibe coding 将重塑软件生态,并彻底改变开发相关岗位的职责描述。
06 Nano banana / LLM GUI
Google Gemini Nano banana 是 2025 年最具颠覆性、最能推动范式变革的模型之一。在我的世界观中,大语言模型(LLMs)是继 1970、80 年代计算机之后的下一个重大计算范式。因此,出于本质上相似的原因,我们将会见证类似类型的创新。我们将看到类似于“个人计算”、“微控制器”(认知核心)或“互联网”(智能体网络)等事物在 AI 时代的对应形态。
尤其是在 UI/UX 方面,“与 LLM 对话”有点像在 1980 年代向计算机终端输入命令。文本是计算机(以及 LLM)的原始/首选数据表示形式,却并非人类偏好的交互格式 —— 尤其是在输入端。事实上,人们并不喜欢阅读大段文字,因为这既慢又费力。相反,人们更倾向于以视觉化、空间化的方式接收信息,这正是传统计算(traditional computing)中图形用户界面(GUI)被发明的原因。
同理,LLM 也应该用我们偏好的格式与我们对话 —— 比如:图片、信息图、幻灯片、白板、动画/视频、网页应用等。
当然,这种理念的早期形态和当前版本,是像 emoji 和 Markdown 这样的东西 —— 它们本质上是通过标题、加粗、斜体、列表、表格等方式对文本进行“视觉装饰”和排版,来提升可读性。
但究竟谁会真正构建出 LLM 的 GUI(图形用户界面)?
在这一世界观下,Nano banana 是对此未来形态的一次早期预示。更重要的是,Nano Banana 的意义,不在于它能进行图像生成,而在于文本生成、图像生成与世界知识在模型权重中深度融合所产生的联合能力。
END
本期互动内容 🍻
❓如果像 Nano Banana 预示的那样,未来的 AI 不再只用文字回复你,而是自动生成图表、流程图、甚至交互界面 —— 你最希望它在哪种场景下以“非文字”的方式与你协作?
文中链接
[1]https://www.donnamagi.com/articles/karpathy-yc-talk
[2]https://www.youtube.com/watch?v=LCEmiRjPEtQ
[3]https://x.com/karpathy/status/1886192184808149383
[4]https://karpathy.bearblog.dev/power-to-the-people/
[5]https://karpathy.bearblog.dev/vibe-coding-menugen
[6]https://github.com/karpathy/llm-council
[7]https://github.com/karpathy/reader3
[8]https://github.com/karpathy/hn-time-capsule
原文链接:
https://karpathy.bearblog.dev/year-in-review-2025/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)