ChatGPT发布后,为什么各大厂短时间内相继发布大模型产品
所以,情况并非“ChatGPT发布后,中国厂商技术就进步了”,而是:中国厂商的技术底蕴一直都在,只是ChatGPT的出现,像一盏探照灯,照亮了那条最有可能通往“通用人工智能”的道路,并引爆了全球性的竞争。大家从“暗中摸索”进入了“明牌竞赛”的阶段,因此你才在短时间内看到了如此密集的产品发布。
ChatGPT 发布后,为什么各个大厂在短时间内相继发布大模型产品,是技术进步了,还是学到了什么呢?

是技术取得突破了么
核心答案是:中国的技术不是“突然”进步的,而是ChatGPT的发布像一个“发令枪”,验证了一条正确的技术路线,让早已在起跑线上准备多年的中国厂商,终于可以朝着明确的方向全力冲刺了。
1. 起跑线:中国大厂早已“重兵布局”
在ChatGPT发布之前,AI大模型的研究在全球范围内早已是科技前沿的必争之地。中国的科技公司,特别是百度、阿里、腾讯、华为等,在这方面已经有了多年的技术积累。
- 百度:从2019年就开始研发“文心大模型”(ERNIE),在NLP(自然语言处理)领域底蕴深厚。它的初衷就是理解语言,而非仅仅生成语言。
- 阿里:同样在自然语言处理、多模态模型等领域有长期投入,其背后的“通义”大模型体系也酝酿已久。
- 科研机构:智源研究院、清华等机构也早有自己的“悟道”、“GLM”等大模型。
所以,技术底座和研发团队是现成的,并不是从零开始。
2. 路标:ChatGPT提供了“成功地图”
在ChatGPT之前,大家虽然都在研究大模型,但对于“如何让大模型如此好用、如此像人”的具体工程化路径并不完全清晰。ChatGPT的成功,清晰地展示了几个关键要素:
- “大力出奇迹”的规模效应:证明了模型参数越大、数据越多,能力可能越强。
- “对齐人类偏好”的技术:它成功应用了基于人类反馈的强化学习(RLHF) 这一关键技术,让模型的输出更符合人类的思维和价值观,而不仅仅是完成一个数学任务。这是它变得“智能”和“好用”的关键。
- “对话即接口”的范式:它证明了一个简单的对话框,可以成为未来人机交互的核心入口,这具有巨大的战略价值。
这就好比,大家都有造汽车的基本零件(技术积累),但特斯拉(OpenAI)第一个成功造出了一辆续航长、体验好的电动汽车并上市。其他车厂一看,立刻明白了:“哦!原来电池要这样布局,软件要这样优化,用户体验要这样设计!”
3. 冲刺:为什么能如此迅速地“跟上”?
当路线图清晰后,中国厂商做的事情是:
- 调整技术路径:迅速将RLHF等已被验证的关键技术整合到自己的大模型中。
- 集中资源发力:公司内部给予前所未有的资源和人力支持,全力攻坚。
- “抢跑”发布:为了抢占市场和生态,即使产品还不完美,也要先发布一个“可用”的版本。这就是为什么你看到文心一言、通义千问等在短时间内相继问世。它们是基于原有模型的快速迭代和优化,而不是凭空变出来的。
总结
所以,情况并非“ChatGPT发布后,中国厂商技术就进步了”,而是:
中国厂商的技术底蕴一直都在,只是ChatGPT的出现,像一盏探照灯,照亮了那条最有可能通往“通用人工智能”的道路,并引爆了全球性的竞争。大家从“暗中摸索”进入了“明牌竞赛”的阶段,因此你才在短时间内看到了如此密集的产品发布。
ChatGPT技术上的突破是什么
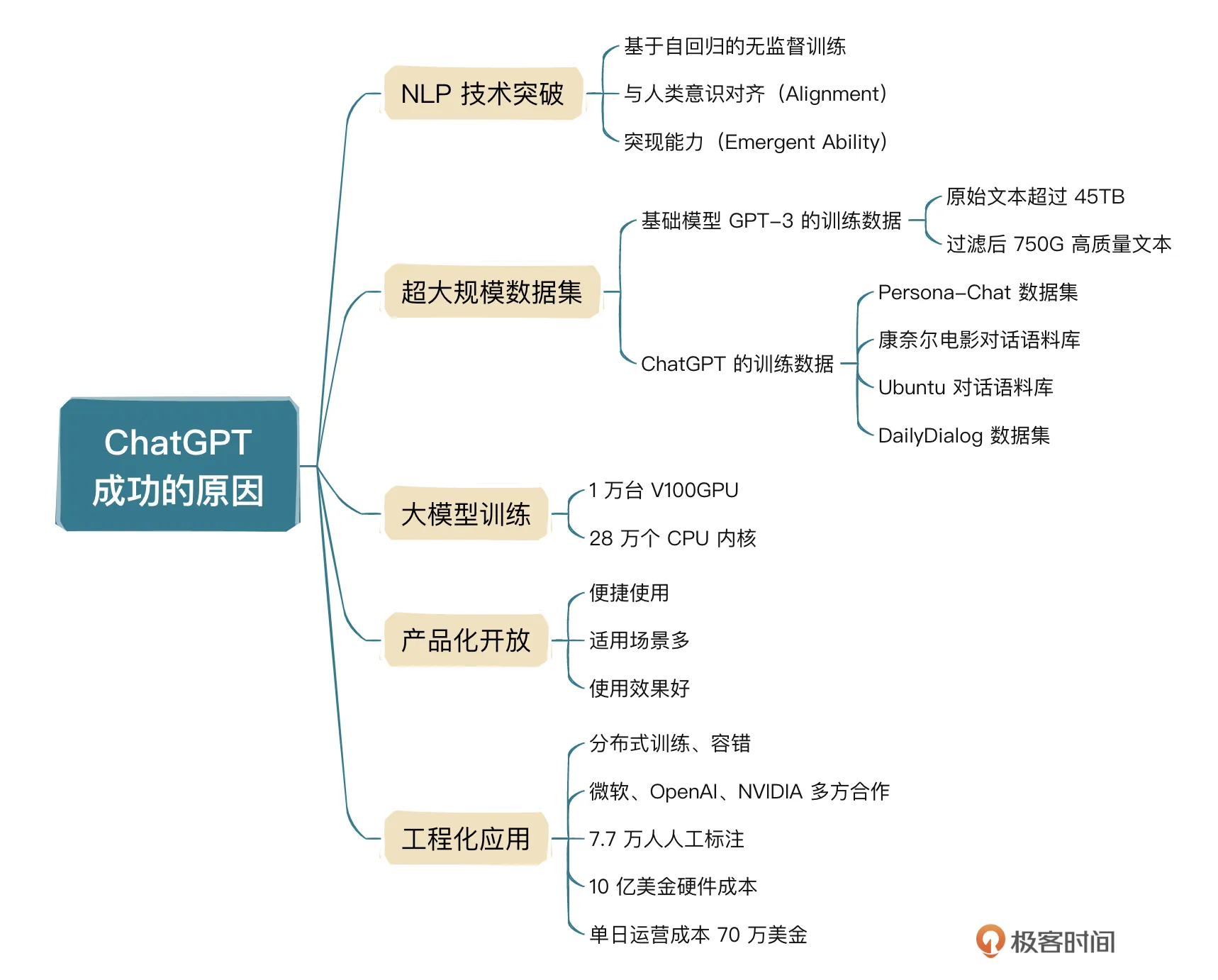
ChatGPT 在技术上的突破可以理解为:自回归语言模型+充分无监督训练+大量代码训练+有监督指令微调+RLHF
RLHF 就是 Reinforcement Learning From Human Feedback(人类反馈强化学习)
与人类意识对齐(Alignment)
我们知道,人类是有感情的,很多事物是有极限的,比如人再怎么能吃也不可能一顿饭吃 100 个馒头,万一大模型输出的内容有这类意识,那么肯定是不合理的,所以要进行微调对齐。
RLHF 目标很简单,就是让大模型的输出和人类保持一致,但是怎么理解这个一致性呢?毕竟正常情况下人与人很多时候都会出现各种不一致的现象。所以人们专门设计了几个原则。
- 有用性:大模型需要遵循指示、执行任务、提供答案。
- 真实性:大模型提供的信息必须是准确的事实,并有承认其自身不确定性和局限性的能力。
- 无害性:避免有毒、偏见或冒犯性的输出,以及拒绝协助危险活动。
如果大模型的输出能满足以上 3 点,那么我们就认为它的输出是与人类意图一致的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)