(2万字硬核长文)大模型强化学习完全指南:从基础到Agentic RL实战技术解析!
本文系统介绍强化学习在大模型中的应用,从基础理论到核心算法(Q-learning、PPO、DPO等),重点解析Agentic RL与LLM-RL的本质区别。强调Agentic RL在多步决策、工具调用中的必要性,并详述Hugging Face TRL、ms-swift等主流框架及业界实践。文章指出,Agentic RL已成为智能体时代的标配技术,能赋予模型自主执行与持续进化能力,是构建复杂AI系统
在当前人工智能领域,尤其是强化学习(Reinforcement Learning)持续演进的背景下,学界对强化学习基础算法已有大量系统性研究。
然而,关于强化学习如何赋能智能体(Agent)、并推动其在实际场景中落地应用的综合性介绍与实战案例解析仍相对有限。
本章节将从强化学习技术出发,探讨其如何驱动智能体在复杂环境中学习和决策,从而真正将大模型的决策能力转化为现实世界中的生产力,顺便总结下这段时间的工作。
一、RL 基础知识
1、什么是 RL?
强化学习是机器学习的三大核心分支之一(另外两个是监督学习、无监督学习),核心逻辑是:智能体(Agent)通过与环境(Environment)的持续交互,通过 “试错” 学习最优行为策略,以最大化长期累积奖励(Reward)。
其流程图如下所示:
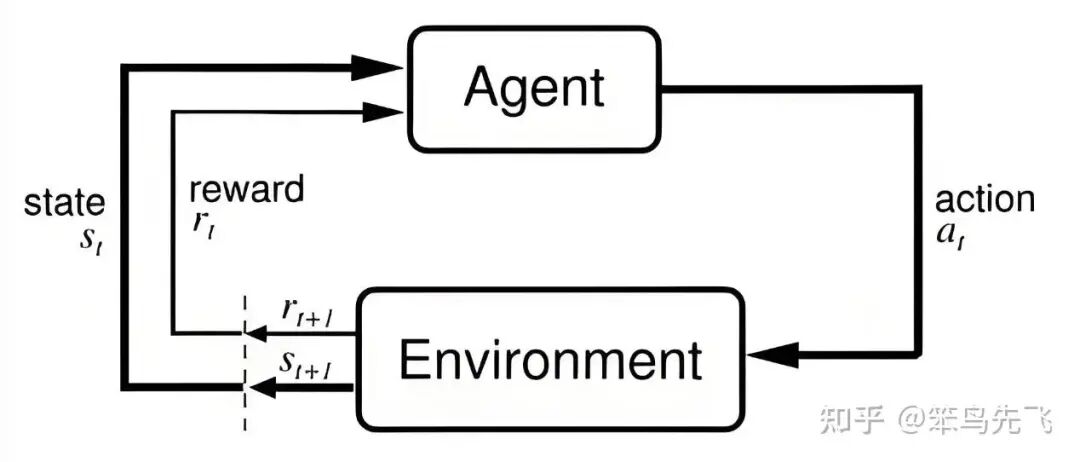
图 1. RL 基本流程
可以用一个通俗的类比理解:
- 智能体(Agent) = 正在学习的 “机器人 / 模型”(比如自动驾驶汽车、大模型、工业机械臂);
- 环境(Environment) = 智能体所处的场景(比如城市道路、对话场景、工厂生产线);
- 状态(State)= 环境的实时情况(比如道路拥堵、用户的提问、机械臂的位置);
- 动作(Action)= 智能体的决策(比如刹车、模型的回复、机械臂的抓取动作);
- 奖励(Reward)= 环境对动作的反馈(比如安全通过路口得正奖励、用户满意回复得正奖励、抓取失败得负奖励);
- 策略(Policy)= 智能体学到的 “决策规则”(比如 “看到红灯就刹车”“用户问事实就输出准确答案”)。
2、RL 的核心特点(区别于其他机器学习)
无监督标注:不需要提前准备 “输入 - 输出” 的标注数据(比如监督学习需要的 “图片 - 标签”),数据通过智能体与环境的交互实时生成;
长期视角:不追求单次动作的 “即时奖励”,而是最大化 “长期累积奖励”(比如自动驾驶不会为了短期加速而忽视长期安全);
探索与利用(Exploration vs Exploitation):智能体需要在 “尝试新动作(探索未知策略)” 和 “使用已知有效动作(利用已有经验)” 之间平衡,避免陷入局部最优。
3、为什么需要 RL?
物理世界中,很多真实问题本质上就是「序列决策」,凡是符合以下几种情境的场景下,强化学习都天然适用:
- 机器人控制:机械臂抓取、无人机飞行、自动驾驶。
- 游戏 & 对弈:围棋、星际争霸、Dota2(AlphaGo、AlphaStar)。
- 推荐与广告:不是只看「这一条推荐是否被点」,而是看 长期用户价值:留存、生命周期价值、多次交互。
- 运筹 & 调度:仓储选址、路径规划、资源调度(多少机器处理多少任务)。
- 对话系统 & Agent:一个 Agent 多轮对话、调用工具、写代码、检查结果,这些都是 「长链路、多步反馈」的过程。
这些场景共性就是:当下的选择会影响「未来能走到的状态」,而我们关心的是整体长期收益,不是某一步的得失。
这类问题,用纯监督学习往往很难建一个特别合理的目标函数,RL 则是为这种情形量身定做的。
4、举例说明
下面使用一个悬崖漫步的例子说明一下强化学习。从 4X12 的网格左下角状态(Initial State)出发,目标是右下角的旗帜状态(Goal State)。
智能体(Agent)可以采取 4 种动作(Action):上、下、左、右,环境(Environment)中有一段是悬崖。
智能体每走一步奖励(Reward)是 -1,掉入悬崖是 -100,掉入悬崖和到达终点都是终止态,会回到起点,而最终从起点到终点的最优路径就是策略(Policy)。
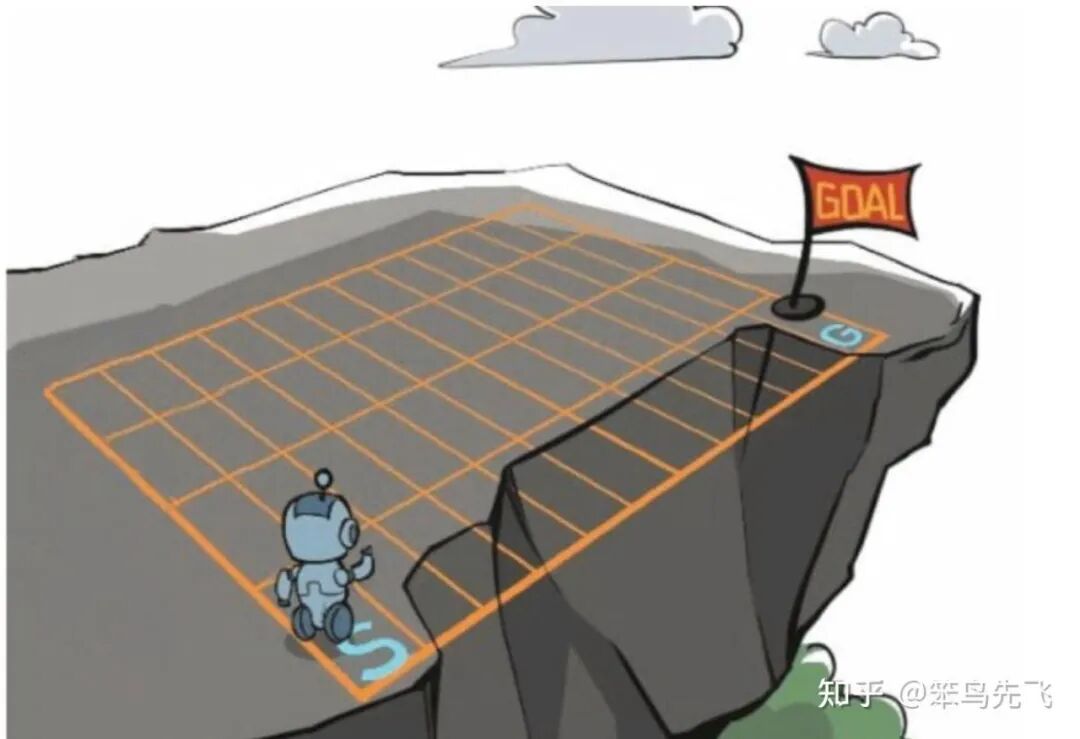
图 2. RL 示例
物理世界中,很多真实问题本质上就是「序列决策」,凡是符合以下几种情境的场景下,强化学习都天然适用:
除此之外,对大模型/Agent 来说,RL更是「后训练」阶段的核心工具,其带来的好处包括:
- 能直接优化「任务成功率」而不是「和标注相似度」。
- 能允许模型在一些场景里探索新的策略,而不是拘泥于人类示范。
- 天然适合「Agent + 工具 + 环境」的一整套闭环。
综上,强化学习的核心价值在于它是解决 “决策型 AI 问题” 的唯一有效技术,并且能降低数据成本、适应动态环境。
二、RL 核心理论
1、问题建模:马尔可夫决策过程(MDP)
强化学习到底在学习什么?要想回答这个问题,我们可以将其抽象成一个经典MDP(Markov Decision Process,马尔可夫决策过程),一个(折扣)马尔可夫决策过程通常写成一个 5 元组:
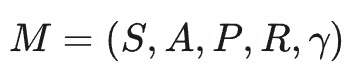
其核心要素如下:
- 状态空间 𝑆 :当前环境的刻画,比如棋盘布局、机器人位置、当前对话历史等。
- 动作空间 𝐴 :在这个状态下,智能体能做的选择:走一步、说一句话、推荐一个商品、买/卖/不动…
- 转移概率 𝑃 :给定当前状态和动作,下一状态的分布,其体现了系统的物理/业务演化规律,通常对智能体是未知的,表达形式如下:
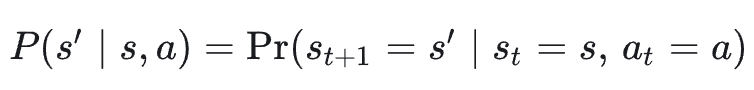
奖励函数 𝑅:环境给的一句「好/不好」的反馈,可以是立即的,也可以是很延迟的,常见写法如:
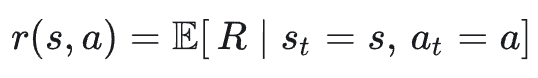
折扣因子 𝛾 ∈ ( 0 , 1 ) :用来定义「未来奖励」的重要程度,𝛾 越接近 1 越重视长期收益,𝛾 越小越「短视」,只在乎眼前利益。
给定一个 MDP,要解决的核心问题是:选什么动作? 选取什么动作执行往往由策略 Policy 𝜋(𝑎 ∣ 𝑠) 决定,即给定状态下智能体选择动作的分布——这就是我们要学到的东西。
在策略 𝜋 下,一次从开始到结束的交互形成一条轨迹(trajectory):
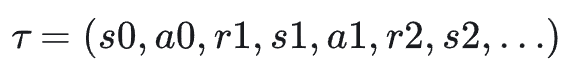
生成过程如下:
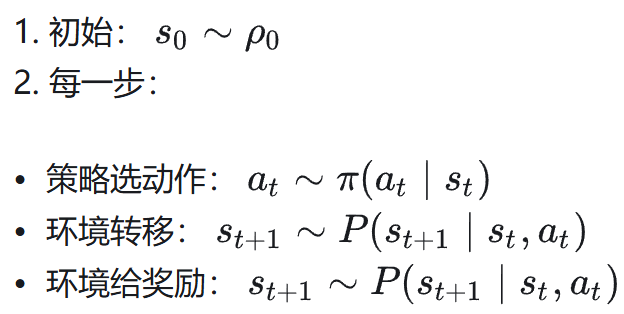
这条轨迹的概率:
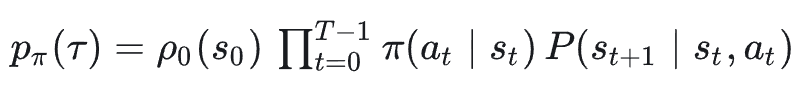
回报 Return 𝐺 定义为从当前时刻往后看的「总收益」,比如:
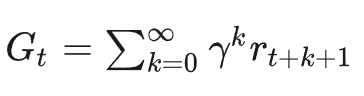
其最终目标是:找到一个策略 𝜋_{𝜃} ,最大化「期望回报」。
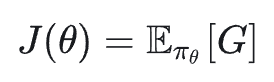
2、核心概念:值函数
为什么需要值函数?在前面的 MDP 里,我们的目标是最大化期望回报,但这个目标是「整条轨迹」级别的,不够“局部化”。
为了能对“当前在某个状态/做某个动作”进行评估,我们引入值函数(value function):值函数 = 在某个状态(或状态 + 动作)下,未来能拿到的“好处”的期望。
它把「整条未来」压缩成一个标量,方便比较、优化和做动态规划。
值函数有以下几种定义形式:
状态价值函数:在状态 𝑠 上,如果之后一直按策略 𝜋 走下去,从现在开始往后能拿到的折扣总奖励的期望:

**状态-动作价值函数:**在状态 𝑠 下先执行一次动作 𝑎 ,然后以后都按策略 𝜋 走下去,能拿到的折扣总奖励期望:
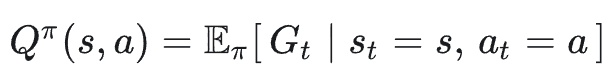
优势函数:在状态 𝑠 下,做动作 𝑎 比起「随便按策略 𝜋 正常走」到底好多少/差多少:

3、核心概念:Bellman 期望方程
总体上,任何状态的回报都可以被拆解为两个部分:一是从当前状态到下一个状态的即时奖励;二是从下一个状态开始,按照特定策略行动,未来的折扣回报。
值函数的关键性质是满足递归关系,而这种递归关系就是Bellman 期望方程(Bellman Expectation Equation)。

再展开条件期望(先对动作再对下一个状态求期望):
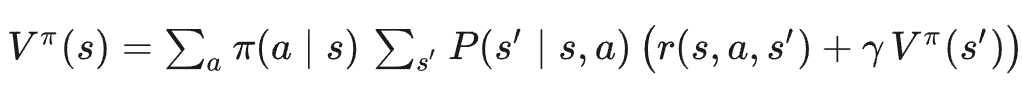
这就是 Bellman 期望方程的离散形式。
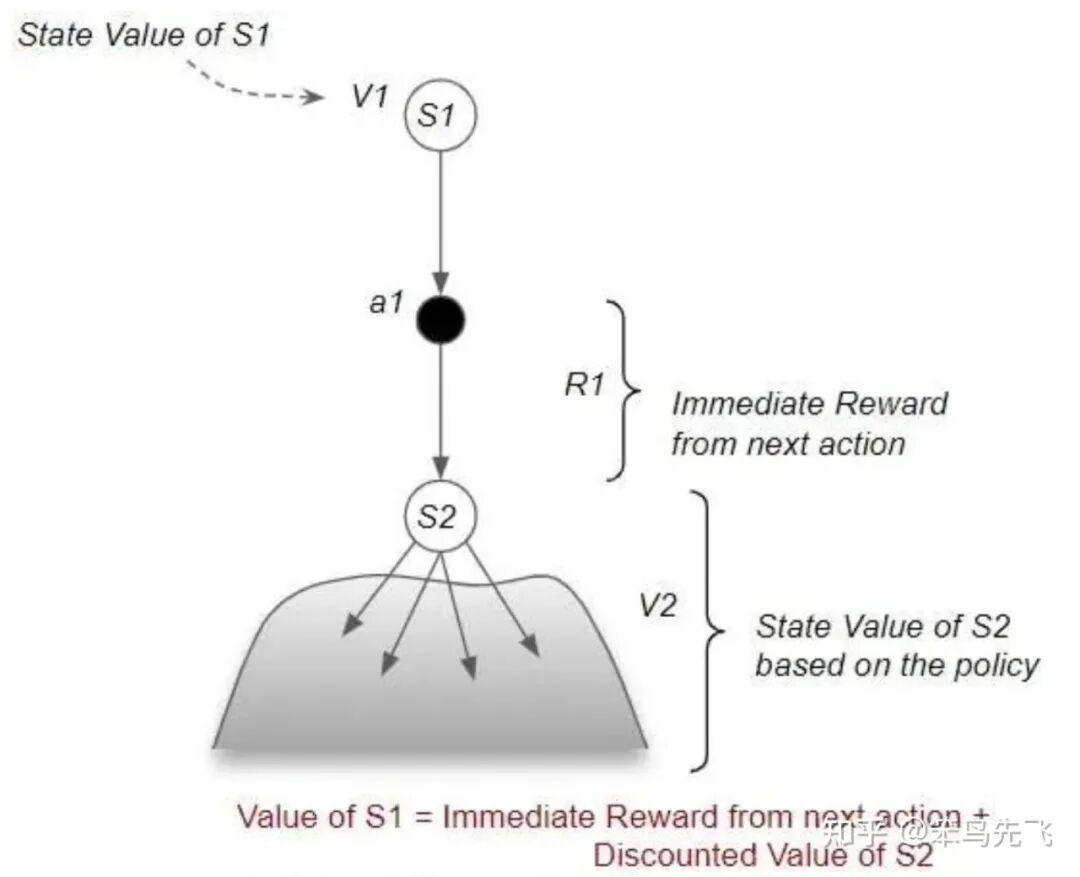
图 3. 状态价值函数 Bellman 方程图例

展开成求和形式:
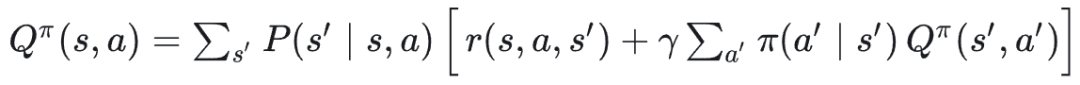
Bellman 最优方程(Bellman Optimality Equation)
上面是「给定策略」时的值函数方程,如果我们关心的是最优策略 𝜋^* ,则对应有最优值函数:

利用“最优策略在每一步都选那时最优动作”的直觉,可以写出 Bellman 最优方程。

进一步可以得到最优策略的显式形式:

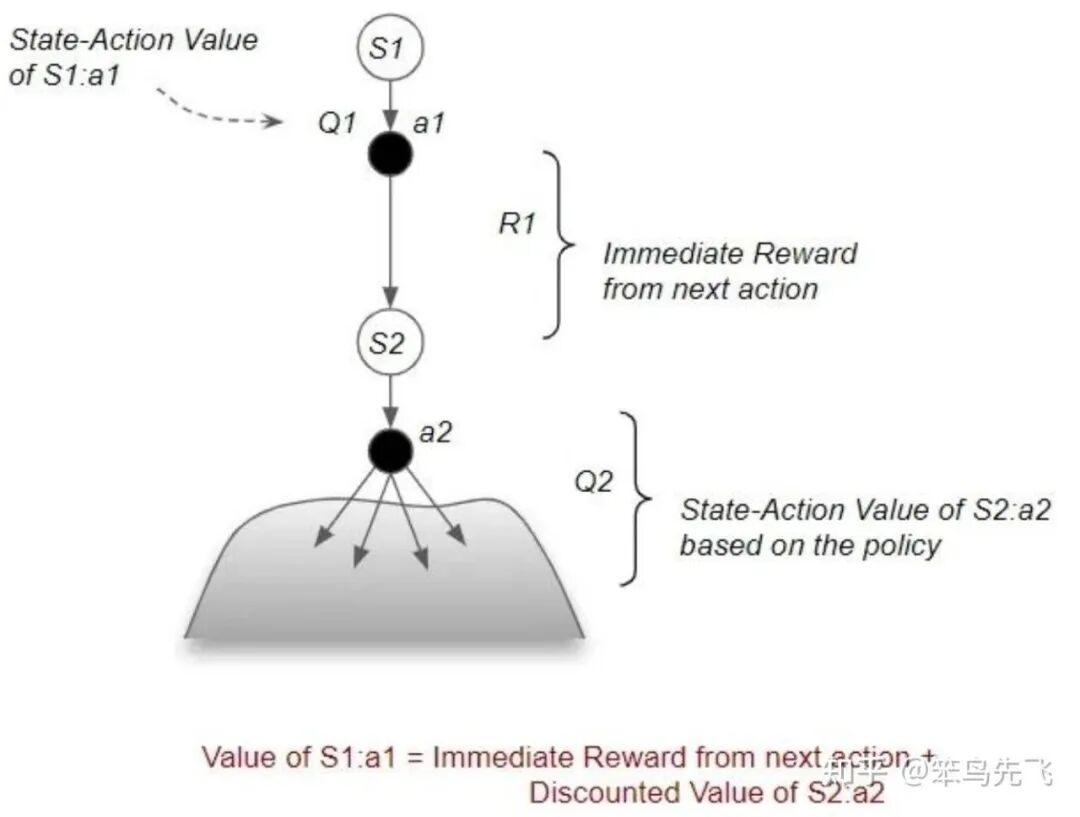
图 4. 状态-动作价值 Bellman 方程图例
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

三、RL 常用算法
1、常用算法分类
从优化目标来看,常用 RL 算法包括以下几个类别:
基于价值函数的方法(Value-Based):基于价值函数的方法,就是先学会“每个状态/动作有多好”(价值),再用这个价值函数去导出策略。
其典型做法为学一个状态价值函数 𝑉(𝑠) 或动作价值函数 𝑄(𝑠,𝑎) ,而在深度 RL 时代,一般都学 Q 函数(因为更容易直接导出策略),常用算法有 Q-learning 等。
基于策略的方法(Policy-Based):直接学一个 𝜋_𝜃**(𝑠,𝑎),把策略本身当成参数化模型,直接最大化期望回报 𝐽(𝜃),常用算法有 REINFORCE 等。**
策略价值并行方法(Actor-Critic):同时学习策略(Actor)和价值函数(Critic),用价值函数做「baseline」减小方差,常用算法有 PPO 等。
从数据来源来看,常用 RL 算法可分为以下两个类别:
- On-Policy:训练数据由需要训练的策略本身通过与环境的互动产生,用自己产生的数据来进行训练(可以理解为需要实时互动)。
- Off-Policy:同训练数据预先收集好(人工或者其它策略产生),策略直接通过这些数据进行学习。
2、典型算法详解
本章节聚焦了一些深度 RL 领域的常见算法并介绍其理论依据,公式推导和代码实现。
2.1 Q-learning

Q-learning 的基本思想如下:
我们无法直接算期望,于是用采样到的单步经验:

其中:𝛼 是学习率;括号里的量叫 TD 误差(Temporal-Difference error):
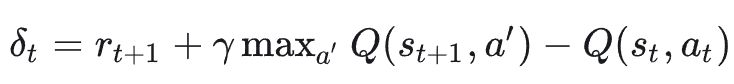
Q-learning 每步都在用「目标 = 立即奖励 + 折扣后的下一状态最大 Q」来更新当前 Q。
假设:
- 状态空间 𝑆 和动作空间 𝐴 都是离散且可枚举;
- 用一个二维表 Qs 存储每个状态-动作对的 Q 值;
则 Q-learning 算法的伪代码如下:
输入:学习率 α ∈ (0,1],折扣因子 γ ∈ [0,1),
探索系数 ε(可随时间衰减),
状态空间 S,动作空间 A
初始化:对所有 s ∈ S, a ∈ A,令 Q(s, a) ← 任意值(例如 0)
for episode = 1, 2, ... do
从环境中初始化状态 s ← s_0
while s 不是终止状态 do
# 1. 使用 ε-greedy 策略选动作
以概率 ε:从 A 中随机选择动作 a
以概率 1 - ε:令
a ← argmax_{a'} Q(s, a')
# 2. 与环境交互,获得下一步
执行动作 a,观察到即时奖励 r 和下一个状态 s'
# 3. 计算 TD 目标和更新 Q
令
y ← r + γ * max_{a'} Q(s', a') (若 s' 为终止状态,则 y ← r)
更新:
Q(s, a) ← Q(s, a) + α * (y - Q(s, a))
# 4. 状态前移
s ← s'
end while
end for
2.2 REINFORCE
REINFORCE 算法核心在于不建任何价值函数 / Q 函数,只把策略 𝜋_𝜃(𝑎∣𝑠) 当成一个可微模型,用「采样 + 回报」直接估计 ∇_𝜃𝐽(𝜃),然后做梯度上升。
核心公式推导如下:
一条长度为 𝑇 的轨迹:
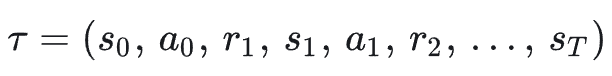
在策略 𝜋_𝜃 下的概率:
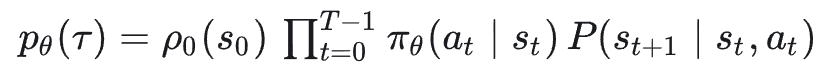
目标函数:
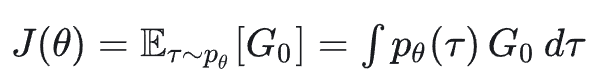
对 𝐽(𝜃) 求梯度:


这就是 REINFORCE 的核心策略梯度公式,即在某个状态下,如果这次行为后面的回报 G_t 很高,就增大它的 log 概率;反之就减小。
该算法伪代码实现如下:
算法 REINFORCE(α, γ)
初始化策略参数 θ(例如随机)
loop: # 训练迭代
# 1. 采样一条完整的 episode
s ← env.reset()
记录列表: states = [], actions = [], rewards = []
while episode 未结束:
根据当前策略 π_θ(·|s) 采样动作 a
执行动作 a,获得 r, s'
将 s, a, r 追加到各自列表
s ← s'
# 2. 计算每个时间步 t 的折扣回报 G_t
G ← 0
returns = 空列表
对 rewards 从后往前遍历:
G ← r + γ * G
将 G 插入 returns 头部 # 得到 [G_0, G_1, ..., G_{T-1}]
# 3. 计算梯度并更新 θ
梯度估计 g ← 0
对每个时间步 t:
g ← g + G_t * ∇_θ log π_θ(a_t | s_t)
θ ← θ + α * g
2.3 PPO
近些年来非常流行对大语言模型做 “基于人类反馈” 的强化学习微调(RLHF)。
其核心流程是:先有一个预训练语言模型(或初步监督微调好的 SFT 模型),再结合人类偏好或自动奖励模型,对其进行策略优化,PPO就是该系列的主力算法。
PPO(Proximal Policy Optimization)是 OpenAI 在 2017 年提出的一种策略优化(Actor-Critic)算法,专注于简化训练过程,克服传统策略梯度方法(如 TRPO)的计算复杂性,同时保证训练效果。
问题:在强化学习中,直接优化策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。
解决方案:PPO 通过限制策略更新幅度,使得每一步训练都不会偏离当前策略太多,同时高效利用采样数据。
假设你是一个篮球教练,训练球员投篮:
- 如果每次训练完全改变投篮动作,球员可能会表现失常(类似于策略更新过度)。
- 如果每次训练动作变化太小,可能很难进步(类似于更新不足)。
- PPO 的剪辑机制就像一个“适度改进”的规则,告诉球员在合理范围内调整投篮动作,同时评估每次投篮的表现是否优于平均水平。
PPO 遵从 On-Policy 的策略,On-Policy 的策略一般由四个关键组件组成训练的 pipeline:
- Actor:产生动作的策略,最终需要学习得到的model。
- Critic:评估动作或状态的价值的网络,预测生成一个token后, 后续能带来的收益。
- Reward Model:对状态转移给出即时的奖励的模型或者函数,输入query 和response,输出一个得分。
- Reference Model:参考模型,通常是 sft 后的 model,这是为了防止在训练过程中,策略网络在不断的更新后,相对于原始策略偏移地太远(避免它训歪了)。
PPO RLHF pipeline 可分为以下三步走:

PPO 的完整损失函数使用的是一个联合损失:
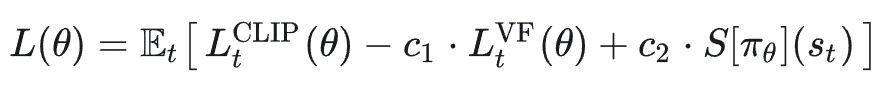
实现时一般是最大化上述公式,或者最小化其负数。
损失函数可拆解为以下三项 Actor + Critic + Entropy:
策略损失(Actor):
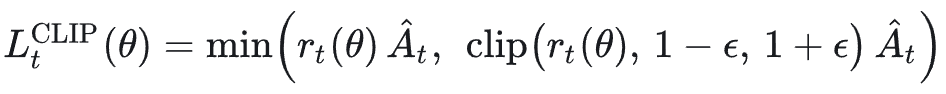
这是 PPO 提出的核心目标函数 clipped surrogate objective,其目的在于用 clip 替代显式 KL 约束;
其中:

直觉上可分为以下两种情况来看:

核心思想为在比率偏离旧策略太远时,进一步优化会被截断,损失不再鼓励大步更新。
价值函数损失(Critic):
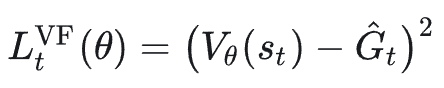
PPO 不是只优化策略,还会同时学习上述 value function;
熵奖励(Entropy Bonus):

PPO 不是只优化策略,还会同时学习上述 value function;
实际代码里,一般写成最小化如下 loss:
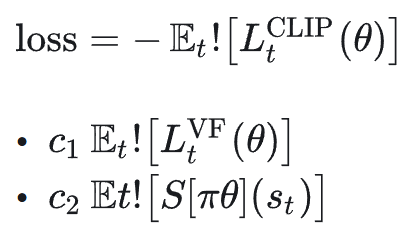
PPO 算法伪代码实现如下:
初始化参数 θ(actor)和 φ(critic)
loop: # 每一轮迭代
# ===== 1. Rollout 收集数据 =====
trajectories = []
for env_step in range(T): # 也可以多环境并行
s_t = 当前状态
a_t ~ π_θ(·|s_t)
执行 a_t 得到 (r_{t+1}, s_{t+1}, done)
记录 (s_t, a_t, r_{t+1}, done, log π_θ(a_t|s_t), V_φ(s_t))
if done: 重置环境
# ===== 2. 计算优势和回报 =====
用 GAE(γ, λ) 从后往前计算 A_t
用 G_t = A_t + V_φ(s_t) 作为回报目标
对 A_t 做归一化
# ===== 3. 多 epoch,小批次优化 =====
for k in range(K): # K 个 epoch
对 trajectories 打乱并按 batch_size 分组
for 一个 minibatch B:
从 B 中取出 s, a, A, G, logπ_old, V_old
# 重新算当前策略的 log prob
logπ_new = log π_θ(a | s)
r = exp(logπ_new - logπ_old)
L_clip = mean( min( r * A, clip(r, 1-ε, 1+ε) * A ) )
V_new = V_φ(s)
value_loss = mean( (V_new - G)^2 )
entropy = mean(策略熵)
loss = -L_clip + c1 * value_loss - c2 * entropy
对 (θ, φ) 进行一次梯度下降
2.4 DPO
鉴于经典 RLHF pipeline(以 PPO 为例),在 RL 优化策略的步骤同时要在线采样、计算 value function、advantage、clip…工程上比较重。
DPO(Direct Preference Optimization)算法提出其核心主张:KL 正则的 RLHF 目标,其实可以在闭式下解出「最优策略的形式」,然后直接用分类损失 / logistic loss去拟合这个最优策略,完全不用显式 reward model,也不用 RL 采样。
DPO 与 RLHF 算法对比如下:
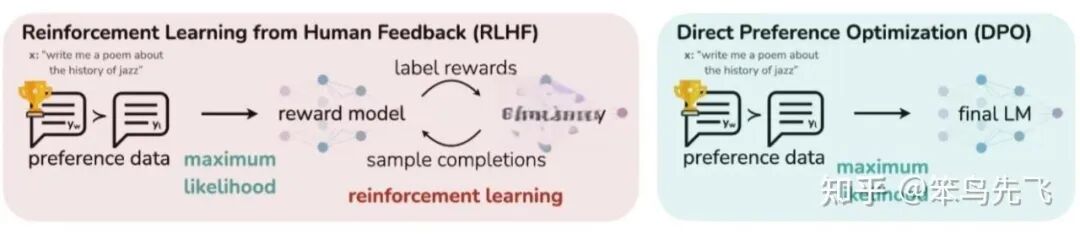
图 5. DPO 与 RLHF 算法对比
DPO 的核心特点如下:

归根结底本质是一个 offline preference-based 分类微调。
DPO 算法核心公式推导如下:首先从标准 KL 正则 RLHF 目标出发, 我们希望找一个策略 𝜋_𝜃(𝑦∣𝑥),最大化。
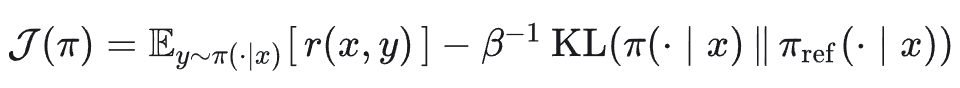
展开成显式求和:
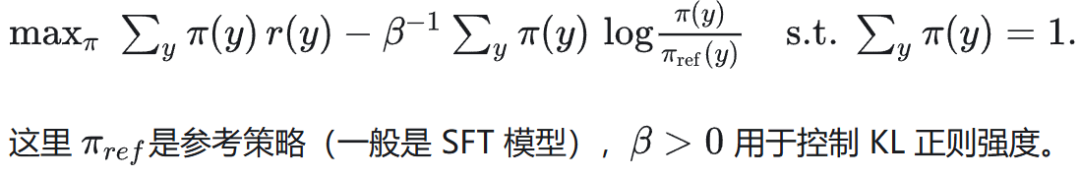
对 𝜋 做变分求解 → 最优策略形式。
对每个 𝑦 令偏导为 0,可以得到:
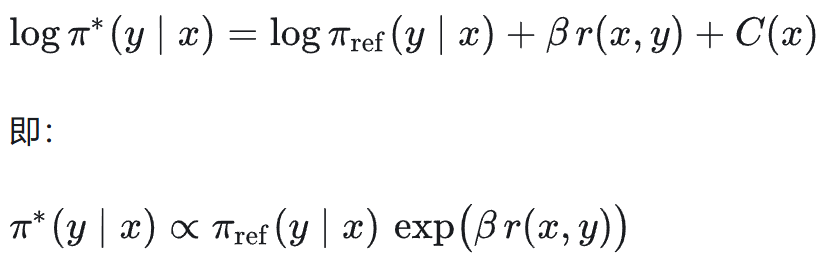
从上式反推 reward 与 log 概率差的关系:
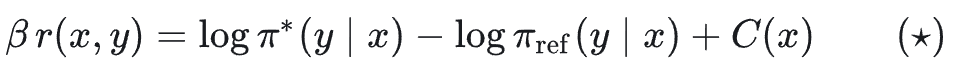
偏好数据 + Bradley–Terry 模型构建 DPO 损失。
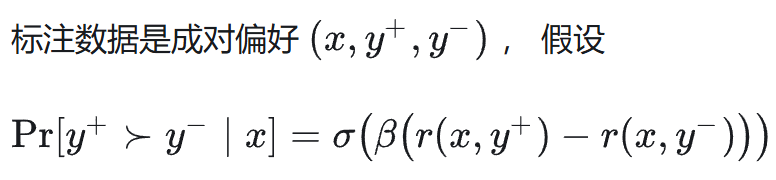
用 (★) 写成「log 概率差」形式(常数抵消):
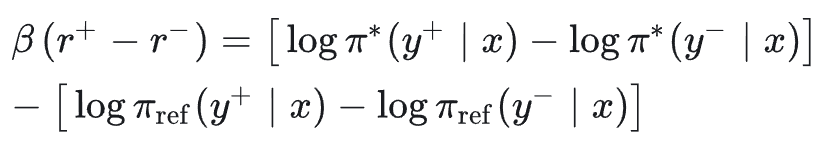
用当前模型 𝜋_𝜃 逼近 𝜋* 求解 DPO 损失。
用 𝜋_𝜃 逼近 𝜋* ,得到偏好概率近似:

这就是 DPO 的核心公式,思想是直接在偏好对上,用「模型相对参考模型的 log 概率差」做一个 logistic 分类损失,隐式实现了 KL 正则 RLHF 的优化。
DPO 算法伪代码实现如下:
输入:
- 参考模型 π_ref(冻结参数)
- 可训练模型 π_θ(初始参数 = π_ref)
- 偏好数据集 D = {(x, y_pos, y_neg)}
- 超参数:β, learning_rate, batch_size, num_epochs
for epoch in 1..num_epochs:
对 D 打乱并按 batch_size 划分
for (x_batch, y_pos_batch, y_neg_batch) in mini-batches:
# ----- 1. 计算 log prob -----
# 对正样本
logp_pos_theta = log π_θ(y_pos | x) # shape: [B]
logp_pos_ref = log π_ref(y_pos | x) # shape: [B]
# 对负样本
logp_neg_theta = log π_θ(y_neg | x) # shape: [B]
logp_neg_ref = log π_ref(y_neg | x) # shape: [B]
# ----- 2. 构造 Δ log prob -----
delta_theta = logp_pos_theta - logp_neg_theta # Δlogπ_θ
delta_ref = logp_pos_ref - logp_neg_ref # Δlogπ_ref
# ----- 3. DPO logistic loss -----
logits = β * (delta_theta - delta_ref) # shape: [B]
# 概率目标:P( y_pos 被选中 ) = σ(logits)
# 负对数似然:
dpo_loss = - mean( log σ(logits) )
# (有些实现会再加一个对称项 -log(1-σ(logits)),本质等价)
# ----- 4. 反向传播 & 更新 -----
loss = dpo_loss
对 θ 做一次梯度下降更新
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
2.5 GRPO
GRPO(Group Relative Policy Optimization)是DeepSeek提出的强化学习算法,专为优化大语言模型(如DeepSeek-V3)设计。
它通过组内相对奖励代替传统价值模型,降低训练成本,同时保持策略稳定性。
GRPO 与 PPO 算法的流程对比如下:
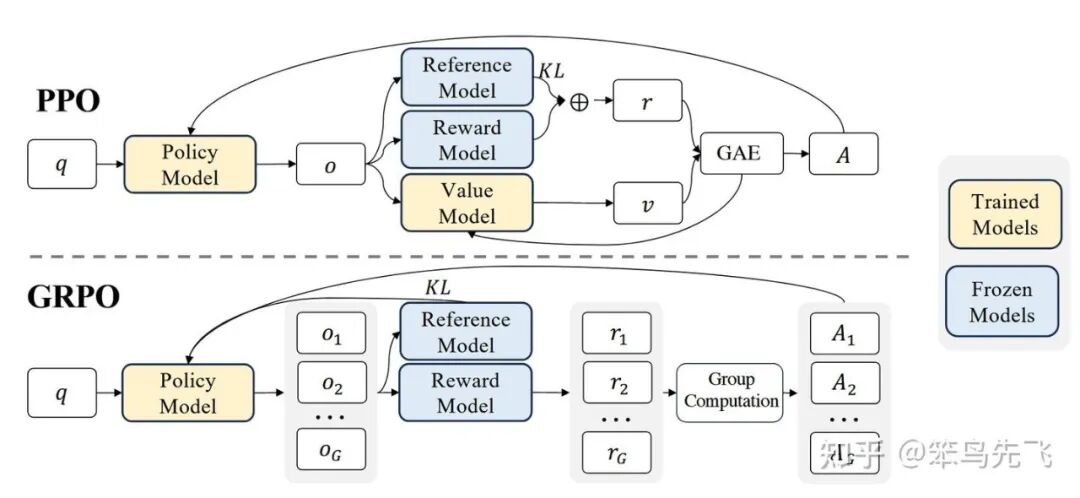
图 6. GRPO VS PPO
相较于 PPO,GRPO 的核心 idea 如下:
- 干掉 Critic,不再训练 value function;
- 每个 prompt 一次采样一组输出(group),用组内的平均 reward 当 baseline;
- 优势 𝐴 完全由「相对于组平均的 reward」来计算;
- 仍然保留 PPO 的 clip 比例 和 KL 正则,更新稳定性不丢。
GRPO 的最终目标:group + 无 critic + KL 直接进 loss。
相较于 PPO,GRPO 做了三件关键改动:

GRPO 优化主目标如下:
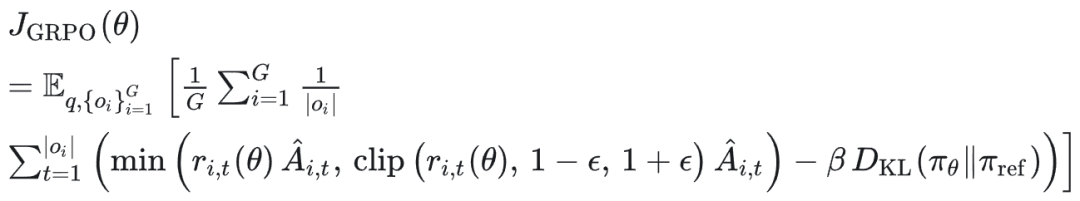
其中:

KL 项使用一个无偏估计:
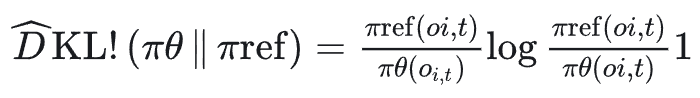
保证非负。

使用过程监督对这组 reward 做 group 标准化(目的是为了对数学/推理任务进行精细的监督,每一步推理都给 reward)

对任意一个 token 𝑡 ,它所属输出 𝑖 的优势是该 token 之后所有 step 的标准化 reward 之和:

GRPO 算法伪代码实现如下:
给定:
- 初始策略模型 π_θ_init (通常是 SFT checkpoint)
- 奖励模型 r_φ
- 参考模型 π_ref (初始 = π_θ_init)
- 任务 prompt 集合 D
- 超参数: ε (clip), β (KL), G (group size), μ (每批上内循环步数)
初始化 θ ← θ_init
for outer_iter = 1..I:
设置参考模型 π_ref ← π_θ # 冻结一份
for step = 1..M:
从 D 采一批 prompt:{q}
设 π_old ← π_θ # 用当前策略作 roll-out 策略
# ----- 1. 采样 group 输出 -----
对每个 q:
采样 G 个输出 {o_i} ~ π_old(· | q)
# ----- 2. 计算 group reward -----
用 r_φ 对所有 (q, o_i) 打分,得到 {r_i} 或 step-level reward
# ----- 3. 计算组相对优势 A_hat_{i,t} -----
- outcome RL: Â_{i,t} = (r_i - mean(r)) / std(r)
- process RL: 用所有 step reward 标准化后,令
Â_{i,t} = sum_{future steps} normalized_reward
# ----- 4. policy update: 多次 GRPO 内循环 -----
for k = 1..μ:
对这一批 (q, {o_i}) 计算:
- 比率 r_{i,t} = π_θ / π_old
- PPO-style clip surrogate using Â_{i,t}
- KL(π_θ || π_ref)
形成 J_GRPO(θ),对 -J_GRPO(θ) 做一次梯度下降
四、LLM-RL VS Agentic-RL
1、LLM-RL(目前主流的 RLHF/PPO 微调)
LLM-RL 典型形态如下:
- 模型:一个大语言模型 𝜋_𝜃,输入 prompt,输出一整段回答;
- 环境:几乎没有显式环境,更多是“离线日志 + 打分器(RM)”模式;
- 奖励:人类偏好/排名(RM 输出的标量)或者简单功能性 reward(例如 code 能运行、数学题对不对);
- 算法:PPO/DPO/RPO/GRPO 一类的「对整段回答的概率分布做调整」。
可以粗暴理解为:把 LM 当成一个大 policy,每次行动就是“生成一整个回答”,然后根据这次回答的评分,整体推一下参数。
基本特征如下:
- 单轮或短上下文;
- 没有显式状态转移(环境不会因为你这次回答改变「可观测状态」);
- 没有真正意义上的探索策略,只是从现在的 LM 采样几条候选。
如下图所示,LLM-RL 的架构更像是一个被严密监控的“内部自我博弈”系统。
它的核心不在于使用工具的能力,而在于在“奖励模型”和“参考模型”的双重约束下,提升文本输出Token的结果。
环境其实就是 Reward Model + Reference Model,这是一个虚拟的、静态的数学环境,优化的是文本的概率分布。
简单举个例子,LLM-RL 架构就是一个“带私教的模拟考试”系统:
- 学生(Actor): 也就是我们要训练的 LLM,负责答题。
- 考官(Reward Model):代表人类喜好,只在最后打一个总分(比如:这篇 80 分)。
- 紧箍咒(Ref Model): 防止学生为了刷分而走火入魔(乱凑字数),强迫它保持正常说话的习惯。
- 私教(Critic):因为考官只给总分,私教负责实时预测分数,一步步告诉学生:“刚才那句写得好,继续保持;这句写得烂,下次改掉”。
一句话总结: 学生(Actor)在私教(Critic)的指点下,努力讨好考官(Reward)拿高分,同时还得戴着 紧箍咒(Ref)别乱写。
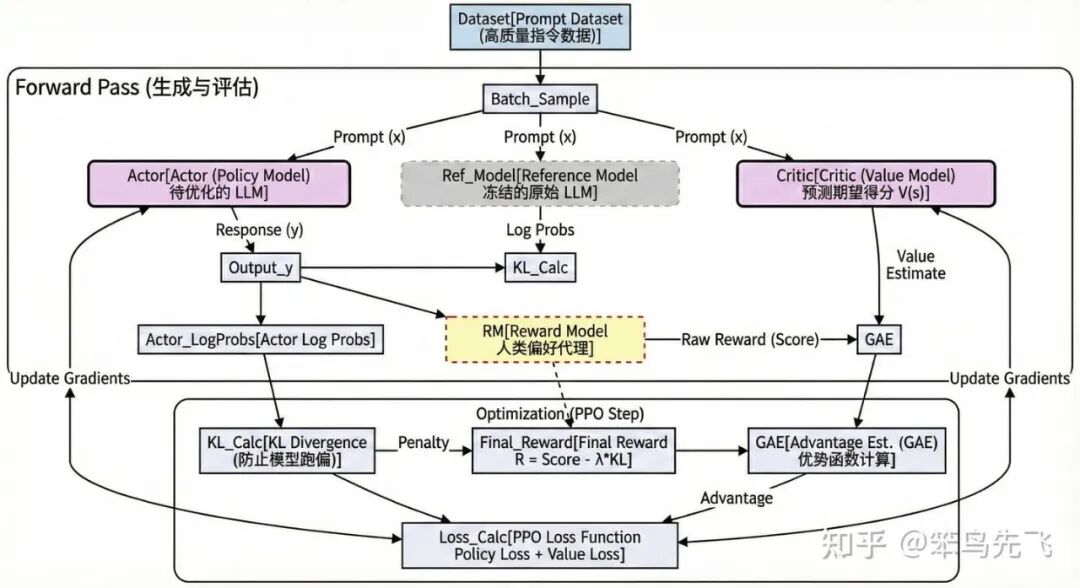
图 7. LLM-RL 流程图
2、Agentic-RL(基于智能体的强化学习)
这里的「Agent」指的是:

一句话总结,Agentic RL = 在“状态–动作–环境反馈”这个闭环上做 RL,LLM 只是这个闭环里实现策略的一部分。
这时候 LLM 不再仅仅是“嘴巴”(生成文本),而是成了“大脑”(决策中心),它通过操纵“四肢”(工具/API)与“世界”(环境)交互,并根据“绩效指标”(Reward)来优化自身的决策逻辑,如下图所示。
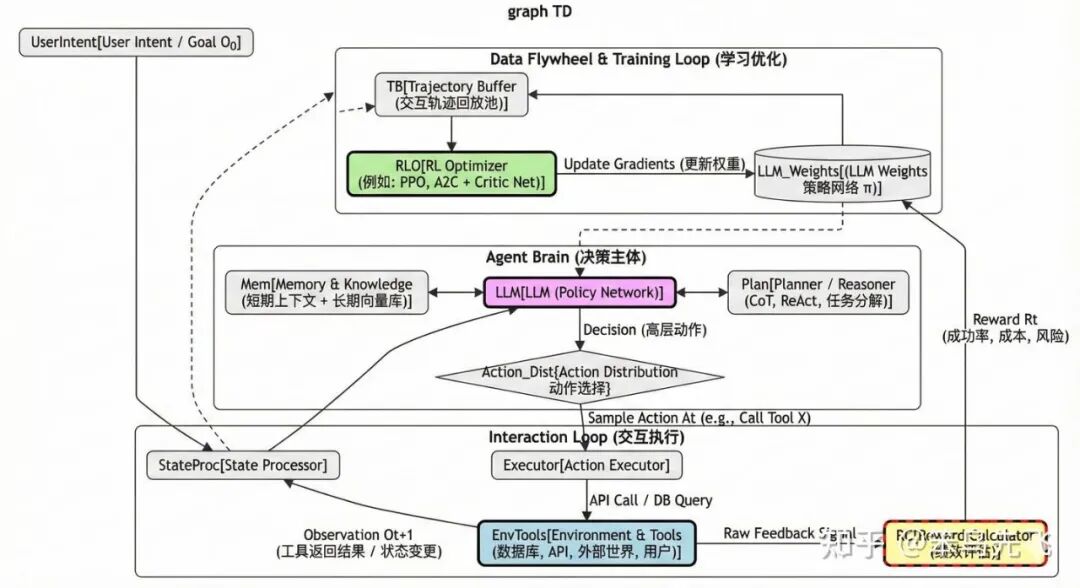
图 8. Agentic-RL 流程图
3、LLM-RL vs Agentic-RL 关键差异
3.1 环境 & 交互形式
LLM-RL:
- 环境基本是静止的:给你一个 prompt,你吐一个回答,结束;
- reward 在“episode 终点”给(整条回答一个分);
- 不存在“对同一个任务多轮试错”这个概念。
Agentic-RL:
- 环境是动态的:查询数据库会改变上下文;调用 API 可能改变外部世界;用户下一句话取决于你刚刚的回答;
- 回合可以很长,多步骤、多工具、多轮对话;
- 需要通过多轮 trial-and-error 去发现更好的策略;
换句更尖锐的话:LLM RL 优化的是「一次性吐答案」的质量;而 Agentic RL 优化的是「多步交互过程」本身。
3.2 行动粒度 & 信用分配(credit assignment)
LLM-RL:
- 行动粒度 = token 或整段回答;
- reward 通常只在「最后」给一次(正确/错误、人类偏好分);
- 信用分配基本是「把奖励摊到所有 token 上」,最多用 GAE 平滑一下;
Agentic-RL:
- 行动是高层决策:调用哪个 tool、读哪张表、如何规划子问题、是否结束任务;
- reward 可以在流程中的多个关键节点给(找到正确子问题、选中对的表/API、成功更新知识库等等);
- 信用分配可以精准到「哪一步决策让任务走向成功/失败」;
对「数据 Agent/工具 Agent」来说:真正重要的是“每一步选的工具和操作是否对任务有贡献”,这个粒度上,单纯对最终回答打个分再 PPO 一下,是很难学到东西的。
3.3 优化目标:输出分布 vs 任务绩效
LLM-RL:
- 目标多是「对齐」,而且在 给定 prompt、一次回答 这个框架里;
- reward 模型学的是「用户更喜欢哪种回答」;
Agentic-RL:
- 目标更接近「系统级 KPI」,包括成功率(任务完成/召回率/正确率)、成本(调用工具次数、API 费用、延迟)、稳定性 & 安全性(不会乱改数据、不会泄露隐私);
- 甚至是多目标加权:𝑅=𝛼⋅成功率−𝛽⋅成本−𝛾⋅风险
也就是说,LLM-RL 优化的是「回答好不好」;而 Agentic RL 优化的是「整个系统做事情做得好不好」。
3.4 数据来源 & 学习范式
LLM-RL:
- 典型 RLHF 是「离线数据 + 少量在线采样」;
- 主数据是标注好的对话/偏好对,环境不会变;
- 很多时候更像「加了 KL 正则的监督学习」→ DPO、IPO 等。
Agentic RL:
- 必须和环境「长期在线交互」才能形成 data flywheel,包括收集成功/失败信号、用户显式/隐式反馈,以及on-policy 或 off-policy 地持续更新策略;
- 会涉及:探索、分布偏移、off-policy 修正等更“正统”的 RL 问题。
五、为什么 Agentic RL 是“必要的”
1、真实业务任务大多是“长过程+多工具”的
目前广泛关注的数据 Agent,本质就是:给模型一个复杂任务(报表、诊断、数据质检…),它需要自己规划步骤、查表、连接 DB、抽取字段、写回结果,有时还要问人、有时要回滚操作。
而这些任务的成功与否:
- 完全取决于一连串决策的组合(选对/错工具、读对/错表、update 对/错字段……);
- 单次自然语言回答的 reward,只能部分反映这些决策好坏。
如果只在“最后一句回复”上做 PPO/RLHF:
- 模型学会的是「如何描述自己正在做什么」,
- 不一定学会「真正正确地做什么」。
这也就是为什么在 agent 场景里容易出现:嘴上说得天花乱坠,实际上工具调用乱来。
2、靠静态偏好数据,无法逼出“结构化策略”
很多 Agent 能力是「结构」而不是「风格」:
- 如何把一个复杂 query 分解成子任务;
- 如何根据 schema 选择合适的表;
- 如何在工具失败时重试/fallback;
- 如何在 budget 约束下做最优查询计划。
这些东西:一方面很难事先写成「成对偏好数据」;另一方面更难靠标注几条“正确轨迹示例”去做 SFT 就学会泛化;
Agentic-RL 的必要点在于:
- 你必须让 Agent 在环境里大量试错;
- 让 reward 针对「任务结构」给反馈;
- 这样策略才会自动发现「哪些规划/工具使用模式更成功」;
3、数据飞轮&在线学习:只有 Agentic-RL 能真正闭环
想象你有大量真实用户在用你的数据 Agent :
- 每天海量的对话 + 工具调用日志;
- 每条任务最终要么成功要么失败,并带有一些可观测 signal(用户是否继续追问、是否导出报表、是否投诉…);
如果只做 LLM RL:
- 这些 log 大多被当成“提示工程素材”或者“再标注一点偏好对”;
- 更新节奏很慢,反馈利用率极低;
如果做 Agentic RL:

在竞争场景下,这个“自动变聪明”的闭环是决定性差异,单纯 LLM-RL 做不到。
总结一下,传统的 LLM RL(例如 PPO-based RLHF)本质上仍然是一种“分布对齐”技术:它在离线偏好数据和静态 prompt 环境中,调整语言模型的输出概率分布,使单轮回答更符合人类偏好。
然而,在现实应用中,真正具有商业价值的智能系统往往是 Agent 化的:它们需要在一个动态环境中进行多步决策、调用多种工具、维护长期记忆,并对任务成功率、成本、安全约束等系统级指标负责。
这种情况下,仅仅针对单轮输出做 LLM RL 已经不够,我们需要将 RL 扩展到整个 “状态–动作–环境反馈” 的闭环上,用 Agentic RL 直接优化智能体的行为策略。
换言之,LLM RL 让模型“说得更好”,而 Agentic RL 让系统“做得更好”;只有两者结合,才能支撑未来复杂的数据智能体和企业级 Agent 应用。
六、热门 Agentic RL 训练框架
1、Hugging Face TRL:LLM 强化学习的工业标准
https://github.com/huggingface/trl
图 9. Hugging Face TRL 库
定位:Hugging Face TRL(Transformer Reinforcement Learning)是一个面向大语言模型“后训练(post-training/对齐(alignment)”的库。
几乎所有 RLHF 研究与论文(包括 OpenAI DPO、Anthropic HH 模型)都可在 TRL 上复现。
其设计目标是将强化学习与 Transformers 生态无缝结合,为模型提供从 SFT → Reward Model → PPO/DPO 优化的全流程工具链。
核心功能:
- 算法支持:完整支持 PPO、DPO、KTO、RLOO 等主流强化学习优化算法。
- 模型适配:可基于任何因果语言模型进行训练,并提供 AutoModelForCausalLMWithValueHead 模块,用于附加价值头以估计生成序列的回报。
- 流程整合:内置标准 RLHF 示例管线,能够一体化执行从奖励模型训练到策略微调的全过程。
技术特点与用途:
- 研究基线:被广泛视为 RLHF 研究的基线框架,OpenAI、Anthropic 等相关研究均可在其上复现。
- 模块化设计:支持高度灵活的模块化实验配置,便于自由替换奖励模型、参考模型及优化算法组件。
- 稳定与生态:训练稳定性高,且依托活跃的 Hugging Face 社区,非常适合需要可靠实现的前沿科研与企业级 LLM 对齐任务。
2、ms-swift:ModelScope 开源的轻量化微训练部署框架
https://github.com/modelscope/ms-swift
图 10. ms-swift 库
定位:ms-swift(Scalable lightWeight Infrastructure for Fine-Tuning)是ModelScope(魔搭)社区开源的一个全链路、轻量化、可扩展的大模型训练部署框架。
目标是通过参数高效训练技术,让研究者和开发者在有限资源下(如单张消费级显卡)也能高效地进行模型定制、对齐和部署。
核心功能:
- 丰富训练范式:支持全参数、轻量微调、人类对齐及强化学习训练。
- 广泛模型与数据集支持:支持超 600 个纯文本和 300 个多模态模型,内置超 150 个数据集。
- 全流程工具链:覆盖训练、推理、评测、量化、部署全流程,并提供 Web-UI 界面。
- 多硬件与分布式支持:支持从消费级显卡到 A100/H100 及国产硬件的广泛环境,集成多种并行训练技术。
技术特点与用途:
- 在 Agentic RL 方面的优秀实践:内置了 GRPO 算法族,并针对训练效率进行了多项优化,是实践 Agentic RL 的重要工具。
- 专项优化技术:采用多实例并行采样、异步采样、多轮更新等技术,显著提升强化学习训练速度。
- 支持多模态与 Agent 训练:支持图文、视频等多模态模型的强化学习训练,并提供 Agent 训练模板,方便构建工具调用能力。
3、verl:字节跳动的生产级强化学习框架
https://github.com/volcengine/verl
图 11. verl 库
定位:veRL(Volcano Engine Reinforcement Learning)是字节跳动火山引擎于 2024 年底开源的分布式大模型强化学习训练框架。其设计目标是将 RLHF 的科研实现转化为可规模化部署的生产级系统。
核心功能:
- 提供覆盖完整训练流程的核心模块,包括 Rollout 生成器、奖励建模器、策略更新器和分布式调度器。
- 支持 PPO、DPO 以及其自研的 DAPO(动态对齐策略优化)和 GRPO 等多种算法,并通过异步流水线架构提升整体训练效率。
- 其设计借鉴了工业级 RL 系统的思想,具备在数百张 GPU 集群上进行分布式训练的能力。
技术特点与用途:
- 生产级分布式训练:专为企业和研究机构的大规模模型后训练场景设计,采用任务并行、异步更新与奖励缓存等机制,显著降低 GPU 闲置率,优化资源利用率。
- 高效的算法与应用:其内置的 DAPO 算法已被广泛应用于 Qwen 等主流模型系列中,有效优化了模型的推理稳定性和语言一致性,体现了其生产落地价值。
4、ART(Agent Reinforcement Trainer):智能体行为优化框架
https://github.com/OpenPipe/ART
图 12. ART 库
定位:ART 是由 OpenPipe 团队在 2025 年推出的开源框架,专门面向 Agent 场景下的强化学习训练。
它让语言模型在动态环境中执行任务、收集交互轨迹、基于反馈优化策略,是“从 LLM 到 Agentic RL” 转变的典型代表。
核心功能:
- 该框架以部分可观测马尔可夫决策过程为基础对智能体行为进行建模,支持 GRPO、RLVR 等算法。
- 其核心训练循环能够连接并调用外部工具与环境,如 Web API、文件系统或浏览器模拟器,使模型能在接近真实的任务场景中学习并优化其行动策略。
用途与特点:
- 专注任务执行能力:与侧重文本对齐的框架(如 TRL)不同,ART 专注于培养模型的外部工具操作与任务执行能力,特别适用于构建网页浏览、代码调试、信息提取等需要与环境交互的“实干型”智能体。
- 灵活可扩展的环境接口:提供可插拔的环境接口,允许用户灵活定义任务环境与奖励机制,从而便捷地为智能体在各种定制化任务中提供训练反馈信号。
5、Microsoft Agent-Lightning:企业级 Agentic RL 平台
https://github.com/microsoft/agent-lightning
图 13. Agent-Lightning 库
定位:Agent-Lightning 是微软于 2025 年推出的一个面向企业的多智能体强化学习统一平台。
其设计灵感源于 PyTorch Lightning 的模块化理念,旨在为不同的智能体系统(如 LangChain、AutoGen 等)无缝嵌入标准化强化学习训练机制,提供集训练、评估于一体的解决方案。
核心功能:
- 框架的核心由 Trainer(训练器)、Rewarder(奖励器)、Environment(环境)和 Orchestrator(编排器) 四大模块构成。
- 支持 PPO、DPO、RLVR 等多种算法,并能在多智能体协作任务中实现奖励信号的共享与自适应优化。
- 框架内置 MCP 协议接口,便于灵活连接外部大语言模型服务进行协同训练。
技术特点与用途:
- 工业级多智能体协作:专为多智能体系统的复杂协作训练提供生产级支持,适用于任务自动化、AI 编程助手、搜索规划等需要动态协同的场景。
- 先进的训练与分析:具备自动奖励归因能力,并能对训练过程进行可视化分析,从而优化多智能体间的策略与协作效率。
七、Agentic-RL 业界优秀实践
本章节将介绍一些 Agentic-RL 在业界优秀实践,通过实际案例可以看出,Agentic-RL 绝非“加入几轮强化学习训练”这般简单,而是一套深度融合的 “智能体行为规划-工具调用执行-实时反馈循环-持续线上迭代” 的完整运作机制。
1、GPT-5-Codex
OpenAI 明确指出 GPT-5-Codex 的训练流程专注于真实编程环境中的复杂任务,例如“多文件重构”“运行测试套件”与“提交 PR”。
这意味着,该模型并非仅仅生成一次性回答,而是扮演一个真正的编程智能体,主动贯穿“编写代码→运行代码→修正代码→提交代码”的完整工作流。
其中体现出几个关键特征:
- 以任务完成为导向:模型的训练目标不仅是输出中间答案,更强调“持续执行直至任务完成”,并以系统验证(如测试通过)作为成功的最终标志。
- 深度集成的工具调用能力:能够调用 IDE 接口、版本控制系统、运行时调试器等工具,这正是 Agentic RL 中“代理行为”核心能力的具体体现。
- 闭环学习与持续优化:在任务执行过程中实时接收反馈、进行纠错,并基于此类交互不断迭代与自我提升。
由此可见,Agentic RL 在该系统中的实践,实质上将模型转化为一个能够自主行动、持续适应环境的“活”智能体,而不再是一个仅被动应答的聊天机器人。
2、Tongyi DeepResearch
在阿里通义的技术报告中,Tongyi DeepResearch 明确强调其模型“专为智能体任务训练”而设计:训练流程涵盖了“Agentic 持续预训练”与“冷启动 SFT + 同策略 RL”等关键环节。
具体而言,该模型适配了以下典型的智能体能力:
- 长周期、跨任务的研究型行为:可执行检索、多源知识融合、自动报告生成等一系列研究动作,实现端到端的研究任务闭环。
- 深度融合的工具调用与交互:不仅限于文本生成,更能主动调用网络检索、知识库查询、结构化报告生成等外部工具与环境交互。
- 反馈驱动的训练与策略优化:在监督微调基础上引入强化学习机制,使模型能够基于任务执行反馈持续优化其决策策略。
3、Cursor 2.0 Composer
在Cursor官方介绍中,Cursor 2.0 Composer被定义为一种“AI原生的代码编辑环境”,其设计目标是将自然语言直接转化为可运行、可维护的完整项目。
该工具以持续的、交互式的代码生成与编辑为闭环,融合了意图理解、代码生成与动态调试等多个环节。
具体体现为以下特征:
- 端到端的项目级生成能力:能够依据自然语言描述,自主完成从项目框架搭建、模块划分到具体代码实现的完整流程,超越传统片段式代码补全。
- 交互式、迭代式的编程工作流:生成代码后仍可与用户进行多轮对话,支持基于反馈进行实时调整、重构与优化,形成“描述‑生成‑修改”的持续协作循环。
- 反馈驱动的代码演化机制:在编写过程中不断根据用户意图、语法检查与运行结果调整输出,逐步贴近真实工程需求,体现出学习型智能体的适应能力。
由此可见,Cursor 2.0 Composer 同样内嵌了以 Agentic RL 为代表的智能体技术范式,将代码编辑器从“辅助工具”转变为能够理解意图、主动构建并持续演进的编程协作者,进一步强化了 Agentic RL 在专业工具智能化进程中作为基础架构的普遍性。
综上所述,当前顶尖的智能体系统普遍将 Agentic RL 作为核心实现路径,旨在赋予模型自主执行与环境持续协同进化的能力,而非仅依赖静态的模型微调。
这也进一步印证了“Agentic RL 已成为智能体时代的标配技术”这一趋势判断。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
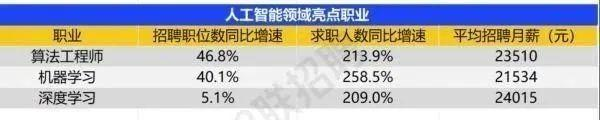
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献442条内容
已为社区贡献442条内容

所有评论(0)