大模型是如何“思考”的
本文介绍了大语言模型(LLM)如何通过嵌入(Embeddings)技术将文本转换为向量表示,从而实现智能问答。文章首先解释了Embeddings的概念,说明其通过将文本转换为高维向量来捕捉语义关系。随后详细阐述了LLM回答问题的流程:分词、词向量化、编码上下文、首词预测和自回归生成。作者指出LLM并非搜索答案,而是基于统计概率生成回答,其能力源于海量训练数据中学习到的语言模式。文章强调大模型通过自
写在前面:大家好!我是
晴空๓。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的博客更新地址是:https://ac-fun.blog.csdn.net/。最近也开始写公众号啦【知识拆箱手记】两边会同步更新,期待大家的关注,非常感谢大家的支持。一起加油,共同进步!
用知识改变命运,用知识成就未来!加油 (ง •̀o•́)ง (ง •̀o•́)ง
前言
为什么我们在使用 DeepSeek、kimi、ChatGPT等大模型的时候它可以流畅地回答我们的问题? 大模型到底是如何实现预测下一个词的?相信大家在使用大模型的时候或多或少的都会有这样的疑问,最近通过看一些资料以及文档对这些问题有了一些理解,如果有不同的理解或者文章有什么不对的地方欢迎大家在评论区评论或者私信博主,感谢大家的不吝赐教。
神奇的Embeddings
第一次看到 Embeddings 这个单词是在 Spring AI 官方文档里面,文档中对于 嵌入 进行了解释节选原文如下:
Embeddings are numerical representations of text, images, or videos that capture relationships between inputs.
嵌入 是对文本、图像或视频的数值化表示,能够捕捉输入内容之间的关联。
Embeddings work by converting text, image, and video into arrays of floating point numbers, called vectors. These vectors are designed to capture the meaning of the text, images, and videos. The length of the embedding array is called the vector’s dimensionality.
嵌入的工作原理是将文本、图像和视频转换为浮点数数组,称为向量。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度。
By calculating the numerical distance between the vector representations of two pieces of text, an application can determine the similarity between the objects used to generate the embedding vectors.
通过计算两段文本向量表示之间的数值距离,应用程序可以确定生成这些嵌入向量的对象之间的相似性。
Embeddings are particularly relevant in practical applications like the Retrieval Augmented Generation (RAG) pattern. They enable the representation of data as points in a semantic space, which is akin to the 2-D space of Euclidean geometry, but in higher dimensions.
嵌入在与检索增强生成模式相关的实际应用中尤为重要。它们使得数据能够表示为语义空间中的点,这种空间类似于欧几里得几何中的二维空间,但维度更高。
通过 Spring AI 官方文档里面可以了解到通过嵌入技术,大模型能够将人类可以理解的内容转换为可以计算的数学形式,从而支持更智能的数据处理。文档中也给出了通过嵌入模型将文本转换为向量的图示如下: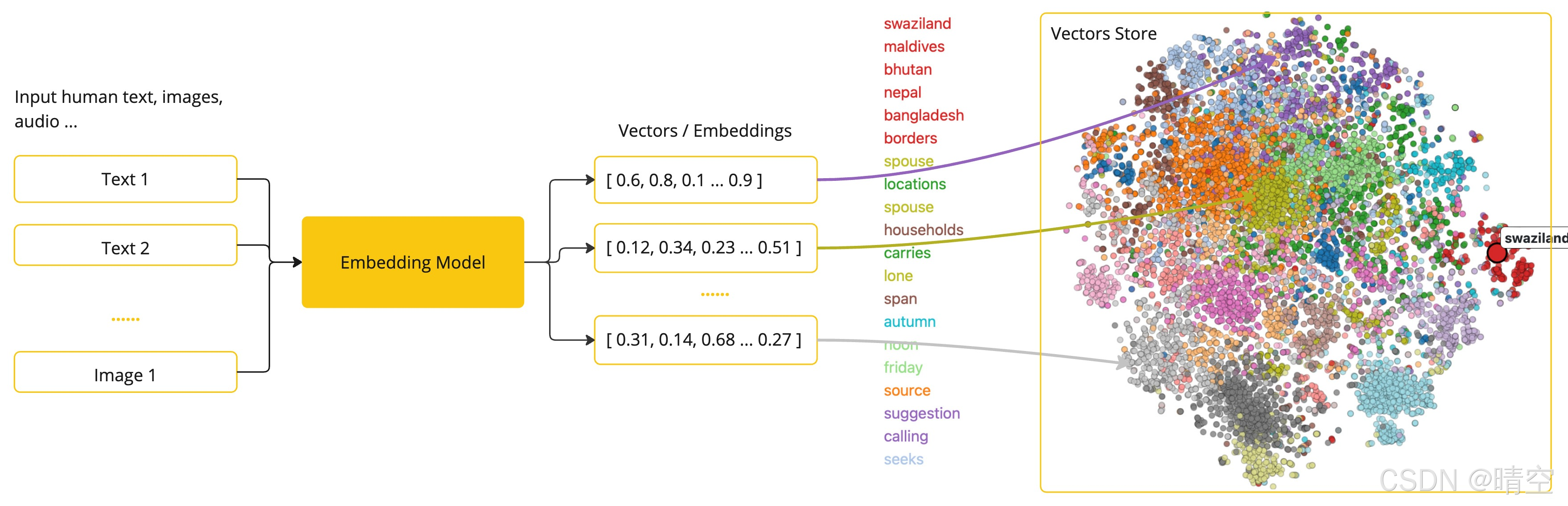
可见大模型就是通过嵌入技术将每一个token、每一个字、每一个词转换为数学形式,在大模型中每一个token、每一个词都有独一无二的向量。通过计算两个文本向量表示之间的数值距离来确定向量之间的相似性以及关联性。
大模型为什么可以回答问题
大模型回答问题本质上是一个极其复杂的基于概率的仿写过程,根据从海量的数据中学到的统计规律(也就是上面说的嵌入过程)计算出下一个最可能出现的词,进而组装成答案。那么大模型是如何预测出下一个词并给出回答的呢?大概会经过 分词,词向量化,编码上下文,首词预测,自回归生成几个步骤。
分词
当我们输入问题的时候大模型首先会将我们的输入的句子拆成一个一个的token(关于token在上一篇文章中已经讲过了这里就不在赘述了)。例如我们问大模型”人工智能是什么?“大模型可能会将这个句子拆解成 [人工, 智能, 是, 什么, ?] 这样。
词向量化
大模型通过上面说的 Embeddings 将每个 token 转换为一个高维向量,这个维度越高大模型对不同词的差异计算的就越精确,可以认为维度越高大模型对每个词的”理解“更深入,给出的回答也就更准确。例如”国王“和”君主“这两个词的向量很接近,通过词向量化大模型会”理解“这两个词的含义,向量的维度越高大模型对词的”理解“程度也就越高,在不同的语境中大模型计算这两个词哪个词会出现的概率就会更准确。
编码上下文
大模型通过 Transformer架构中的“自注意力机制”,分析句子中每一个词与所有其他词的关系。比如在处理“苹果公司发布了新手机”时,注意力机制会让“发布”强烈关注“公司”,让“手机”强烈关注“苹果”,从而明白这是科技公司行为,而不是水果。自注意力机制是大模型”理解“问题的关键,该机制能够让大模型在处理某个位置的信息的同时考虑整个序列中其他相关的信息,而不仅仅是该词附近的信息。大模型的自注意力机制就像我们在读一本书的时候,当读到某一个句子或者情景的时候大脑会将这些关键词与前面的信息联系起来,从而理解整个句子的含义。
首词预测
大模型将整个问题的编码表示为初始向量,通过这个初始向量计算出所有候选词出现的概率,所有候选词出现的概率加起来等于 1。计算出候选词出现的概率之后大模型会根据具体的 采样策略 选择出一个词作为回答的第一个词。例如我们问”人工智能是什么?“,它可能算出“人工”后面最高概率的词是“智能”(但它已经用过了),而整个问题的语境下,第一个词是“人工”的概率最高。
自回归生成
自回归生成是一个循环的过程,在 首词预测 之后大模型会将已生成的文本(初始问题是“人工智能是什么?”,已生成“人工”)再次输入模型。继续结合已有的上下文预测下一个词是什么。例如“人工智能是什么?”回答时在已经首词预测出”人工“之后会继续预测出下一个词是”智能“,“是”、“一”、“项”、“…” ,直到生成一个代表结束的特殊标记。
总结
大模型回答问题的原理可以总结为以下3点:
- 大模型不是通过在数据库中搜索答案,而是根据一系列的训练、计算等模式“生成”的答案。
- 大模型可以“思考”的基础是统计概率,大模型会根据训练的数据计算出下一个出现概率最高的词,其正确性依赖于训练数据的质量和规模。
- 大模型能写诗、编程甚至推理,不是因为大模型真的像人类一样理解了这些任务,而是因为大模型在训练的数据中见过这些文本模式,并学会了模仿复现和泛化这些模式。
大模型一切能力的基石就是海量的文本,或许终有一天大模型会从数以千亿的参数中找到人类语言的终极统计规律!
参考资料
[1] https://docs.spring.io/spring-ai/reference/concepts.html#_embeddings
[2] 从0实现并理解GPT

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)