【AI课程领学】第八课 · 网络参数初始化(课时1) 全零初始化:为什么“看似合理,却几乎一定失败?”
【AI课程领学】第八课 · 网络参数初始化(课时1) 全零初始化:为什么“看似合理,却几乎一定失败?”
·
【AI课程领学】第八课 · 网络参数初始化(课时1) 全零初始化:为什么“看似合理,却几乎一定失败?”
【AI课程领学】第八课 · 网络参数初始化(课时1) 全零初始化:为什么“看似合理,却几乎一定失败?”
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
在刚接触神经网络时,一个非常自然的想法是:
- “既然不知道权重该取什么值,那就全部初始化为 0 吧。”
这在线性回归里是完全可行的,但在深度神经网络中却几乎一定会失败。本篇我们将从数学、优化、对称性破坏三个角度系统解释:
- 为什么全零初始化在深度学习中不可用,以及它在什么极少数场景下“勉强可以”。
1. 参数初始化在深度学习中的地位
在深度学习中,参数初始化直接影响:
- 梯度是否能有效传播(避免消失/爆炸)
- 网络是否能“打破对称性”
- 收敛速度与最终性能
- 不同层是否能学到不同功能
一句话总结:
- 初始化 = 决定你从哪条“优化轨道”开始下降。
2. 什么是全零初始化?
- 全零初始化指的是:
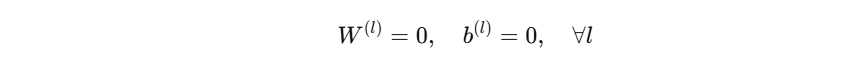
- 即所有层的权重矩阵与偏置项在训练开始时都设为 0。
在 PyTorch 中,这样做非常容易(但非常不推荐):
import torch
import torch.nn as nn
model = nn.Linear(10, 5)
nn.init.constant_(model.weight, 0.0)
nn.init.constant_(model.bias, 0.0)
3. 全零初始化为什么在深度网络中失败?
3.1 关键原因一:对称性无法打破(Symmetry Breaking Failure)
- 考虑一个最简单的两层网络(忽略偏置):
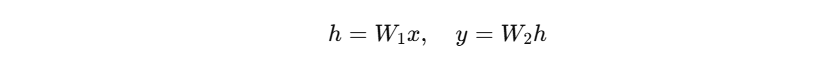
- 如果:
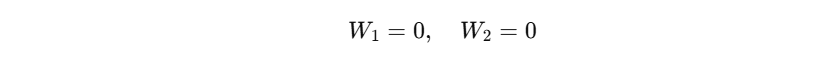
- 那么对于任意输入 x x x,都有:
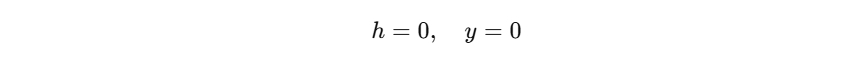
反向传播时发生什么? - 所有神经元的输出完全相同
- 所有神经元的梯度也完全相同
- 所有权重在更新后仍然保持相同
结果:
- 多个神经元等价于一个神经元,网络“塌缩”为低容量模型。
3.2 用梯度公式直观理解
- 以单层线性 + ReLU 为例:
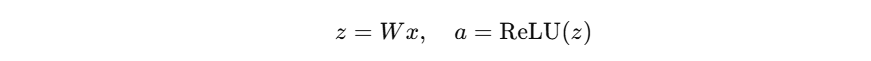
- 如果 W = 0 W=0 W=0,则:
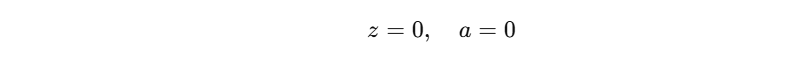
- 梯度为:
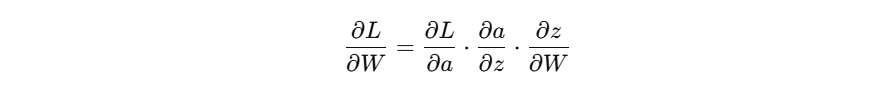
- 而 ReLU 在 z = 0 z=0 z=0 处梯度通常被实现为 0 或不稳定值:
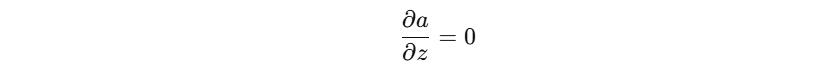
结论: - 梯度为 0
- 权重永远无法更新
- 网络彻底“死掉”
3.3 数值实验:全零初始化的网络几乎学不到任何东西
import torch
import torch.nn as nn
import torch.nn.functional as F
# 一个简单的二分类 MLP
class ZeroInitMLP(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(2, 16)
self.fc2 = nn.Linear(16, 2)
# 全零初始化
for p in self.parameters():
nn.init.constant_(p, 0.0)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
# 构造简单数据
x = torch.randn(128, 2)
y = (x[:, 0] + x[:, 1] > 0).long()
model = ZeroInitMLP()
opt = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(5):
logits = model(x)
loss = F.cross_entropy(logits, y)
opt.zero_grad()
loss.backward()
opt.step()
print(f"epoch {epoch}, loss={loss.item():.4f}")
你会观察到:
- loss 几乎不下降
- 输出 logits 始终接近常数
- 网络无法区分不同样本
4. 那为什么线性回归可以用零初始化?
- 对于单层线性模型:
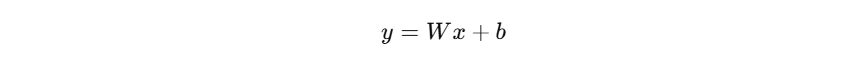
- 模型是凸的
- 所有参数共享一个全局最优
- 不存在“多个神经元功能重复”的问题
因此,线性模型 + 零初始化是数学上完全合理的。
👉 关键区别:
- 深度网络是非线性、非凸的,需要通过随机性打破对称。
5. 全零初始化“唯一可接受”的场景
虽然不推荐,但有几个特例:
5.1 偏置项(bias)可以初始化为 0
nn.init.zeros_(layer.bias)
- 这是常规做法,不会带来对称性问题。
5.2 BatchNorm 的参数初始化
- BatchNorm 通常设为:
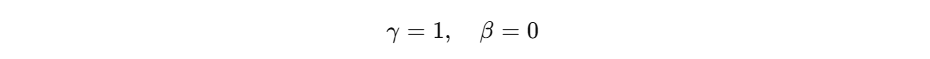
nn.init.ones_(bn.weight) # gamma
nn.init.zeros_(bn.bias) # beta
- 这是刻意设计的零初始化,但不属于网络主权重。
6. 本篇小结
你应该记住的三句话:
- 全零初始化在深度网络中会导致对称性无法打破
- 神经元会学到完全相同的功能,网络容量崩塌
- 除了 bias / BatchNorm,不要对权重使用零初始化
下一篇我们进入真正可用的初始化方式:随机初始化,并系统讲清楚:
- 为什么“随机”是必须的
- 均匀 vs 正态初始化
- 随机初始化仍然可能失败的原因

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)