OmniDrive-R1:基于强化学习的交错多模态思维链构建可信赖的视觉-语言自动驾驶系统
25年12月来自上海科技大学、清华、同济、上海交大、旷视科技和迈驰智行的论文“OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving”。在自动驾驶(AD)等安全关键领域部署视觉-语言模型(VLM)面临着
25年12月来自上海科技大学、清华、同济、上海交大、旷视科技和迈驰智行的论文“OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving”。
在自动驾驶(AD)等安全关键领域部署视觉-语言模型(VLM)面临着严重的可靠性挑战,其中最显著的问题是目标幻觉。这种故障源于它们依赖于缺乏实际依据的基于文本思维链(CoT)推理。虽然现有的多模态CoT方法试图缓解这一问题,但它们存在两个根本缺陷:(1)感知和推理阶段相互独立,阻碍端到端的联合优化;(2)依赖于昂贵且密集的定位标注。因此,提出OmniDrive-R1,一个专为自动驾驶设计的端到端VLM框架,它通过交错式多模态思维链(iMCoT)机制统一感知和推理。核心创新是强化驱动的视觉基础能力,使模型能够自主地引导其注意力,并“放大”关键区域进行细粒度分析。这种能力得益于纯粹的两阶段强化学习训练流程和Clip-GRPO算法。至关重要的是,Clip-GRPO引入一种无需标注、基于过程的基础奖励机制。这种奖励不仅消除对密集标注的需求,而且通过强制视觉焦点和文本推理之间的实时跨模态一致性,避免外部工具调用带来的不稳定性。在DriveLMM-o1数据集上的大量实验表明,模型取得显著的改进。与基线模型Qwen2.5VL-7B相比,OmniDrive-R1将整体推理分数从51.77%提高到80.35%,最终答案准确率从37.81%提高到73.62%。
OmniDrive-R1 是一种端到端的视觉-语言模型(VLM)框架,专为自动驾驶而设计。如图所示,OmniDrive-R1 通过交错式多模态思维链(iMCoT)机制赋予 VLM 自适应的主动感知能力。核心技术创新在于一种强化学习驱动的视觉定位能力,使模型能够在推理过程中自主地引导注意并聚焦于关键区域进行细粒度分析。这种能力的激活完全由基础 VLM 的内在定位潜力驱动,无需依赖任何外部工具。具体而言,这种能力是通过提出的 Clip-GRPO 纯两阶段强化学习(RL)训练策略实现的。Clip-GRPO 基于群体相对策略优化(GRPO)[32],引入一种无需标注的基于过程定位奖励。该奖励利用 CLIP 模型 [29] 的跨模态一致性来强制模型视觉焦点与其文本推理之间的实时对齐,从而消除对密集定位标签的需求,并避免外部工具调用带来的不稳定性。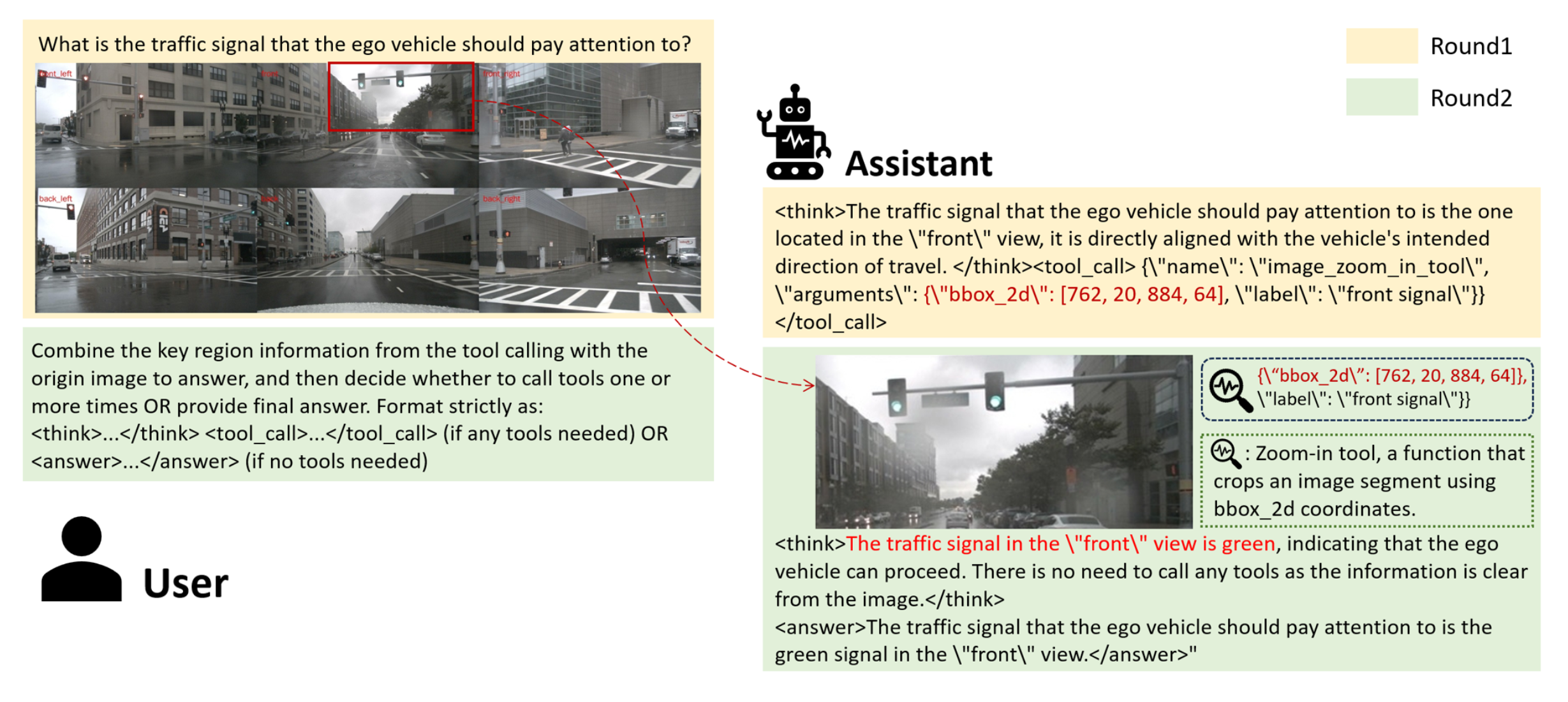
OmniDrive-R1
OmniDrive-R1 是一种多模态驾驶智体,它通过 iMCoT 推理过程实现“基于不同车载摄像头视角进行思考”。该模型的感知和推理能力通过端到端强化学习联合优化,使其能够利用其内在的感知能力来精确定位关键的任务相关信息。
如图所示,模型以问题 q 和由六个不同的车载摄像头视角生成的原始图像 I_0 作为输入。为了形式化迭代推理过程, iMCoT 在步骤 t 的状态 s_t 定义如下: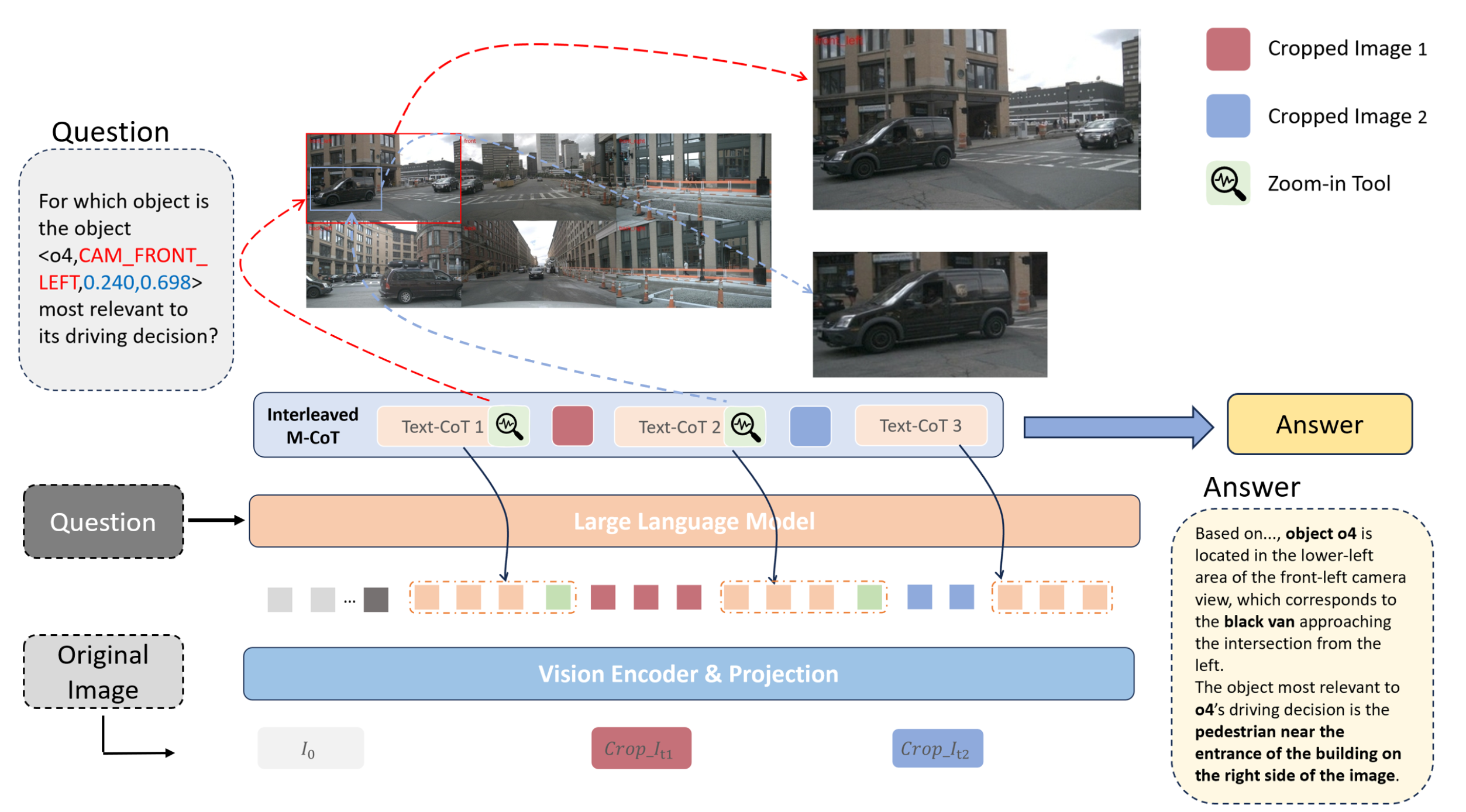
s_t =[(I_0,T_0),(I_1,T_1),(I_t,T_t)] = {I_≤t,T_≤t},
其中 I_≤t = {I_1, …, I_t} 表示步骤 t 之前裁剪后的图像tokens, T_≤t = {T_1, …, T_t} 表示文本tokens。在每个步骤t 中,OmniDrive-R1 自主决定是输出最终答案还是使用放大工具 Tool_t 从感兴趣区域获取信息,其中 Tool_t 表示在步骤 t 调用放大工具。该工具的输入包括边框 b_t 及其对应的类别标签 l_t,这些信息由模型在推理步骤 t 生成。成功调用放大工具 Tool_t 后,智体返回一个关键区域,该区域被其识别为对正在进行的推理过程至关重要,例如 I_t+1。给定状态 s_t,动作 a_t ∼ π_θ(a | s_t) 从策略模型 π_θ 中采样。这个交互过程可以自主迭代,直到得出最终答案或达到最大工具调用次数。值得注意的是,图像token I_≤t 和文本tokens T_≤t 在状态中交错排列。
两阶段训练流程
为了使模型能够以情境-觉察和及时的方式使用放大工具,提出一种两阶段强化学习策略(详情如图所示)。首先,模型在精心策划的数据集上进行训练,以学习工具使用的基本原理。随后,在自动驾驶数据集上对第一阶段的模型进行微调,使其适应真实的驾驶场景,并优化工具调用的时机。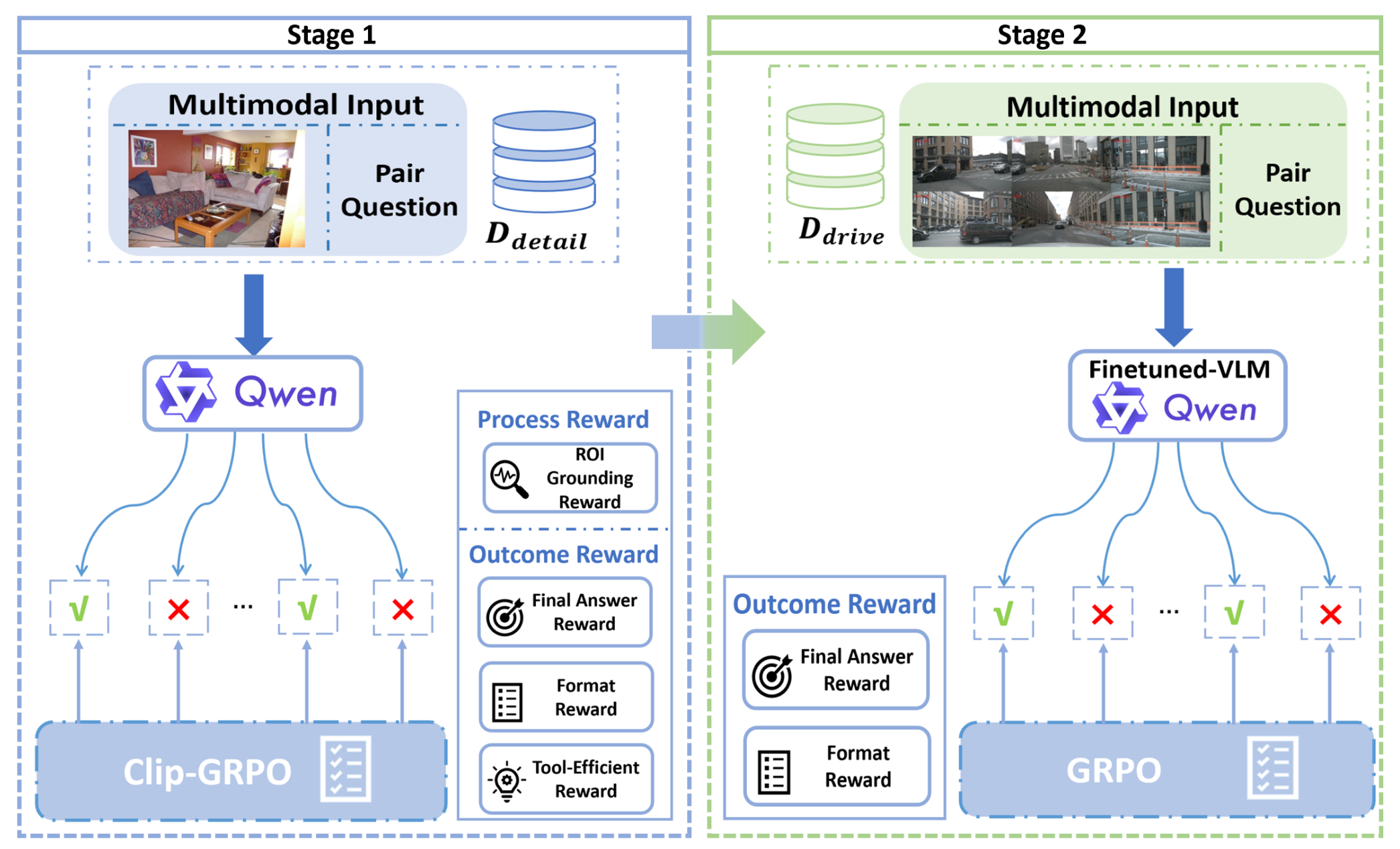
第一阶段:工具学习
为了有效地训练模型的工具调用能力,在第一阶段使用 DeepEyes 数据集 [27] 的精心策划的子集 D_detail 对模型进行微调。这些选定的数据点具有工具使用与准确性提高之间存在明显关联的特征,这有助于初步鼓励模型调用工具来解决问题。
然而,在推理过程中,模型表现出对基于文本推理的强烈偏好,导致工具调用频率较低。这种行为在训练早期阶段尤为明显,此时模型的内在基础能力尚不成熟。仅基于最终结果的奖励信号可能会阻碍模型探索必要的工具使用。此外,虽然为关键区域提供人工标注的边框可以指导这种探索,但这种方法成本高昂且耗时费力,严重限制训练方法的可扩展性。
因此,为了促进基础能力、推理和工具使用之间的协同作用,引入 Clip-GRPO 算法。该算法通过提出一种奖励机制来解决上述挑战,该机制包括基于过程的感兴趣区域 (ROI) 定位奖励和基于结果的工具效率奖励。
基于过程的奖励。引入 ROI 定位奖励作为瞬时奖励信号,以指导模型在步骤 t 成功调用工具后的定位行为。利用预训练的 CLIP 模型计算返回的区域图像 I_t 与其对应的预测标签 l_t 之间的相似度分数 sim_t。
这种设计具有两个关键优势:首先,它避免对关键区域进行耗时的人工标注,从而实现更具可扩展性的训练。其次,它确保裁剪后的视觉内容与生成的标签之间的语义相关性,从而在推理过程中促进高质量的定位。
为了防止模型通过频繁调用工具来滥用这种奖励,引入一个衰减系数 λ 来抑制这种行为。该系数会惩罚过多的工具调用,鼓励模型仅在真正有助于解决任务时才明智地使用工具。因此,对于包含 E 次工具调用的推理轨迹 τ,基于过程的奖励R_p可以计算得到。
基于结果的奖励。为了强化能够明智地使用工具的推理路径,采用三部分奖励策略,包括准确性奖励 R_acc、格式奖励 R_f 和适当工具使用奖励 R_tool。准确性奖励评估最终答案的正确性,而格式奖励则惩罚结构不良的输出。工具使用奖励 R_tool 仅在模型获得正确最终答案且在推理路径中至少调用一次工具时才会获得。给定推理路径 τ,对基于结果的奖励 R_o进行计算。
总之,对于包含 E 次工具调用的推理路径 τ,可以获得R_o和R_p 的总奖励 R(τ):R(τ) = R_o(τ) + R_p (τ)。
第二阶段:域学习
在第一阶段微调之后,视觉-语言模型(VLM)已经获得强大的基础能力,并熟练掌握工具的使用。因此,第二阶段的主要目标是使模型能够根据场景和查询的复杂程度,自主决定是否调用工具来捕获细粒度信息。
为此,用 GRPO 算法 [32] 在自动驾驶推理数据集上对第一阶段微调后的 VLM 进行优化,并采用包含准确性奖励 R_acc 和格式奖励 R_f 的奖励策略。给定推理轨迹 τ,第二阶段的奖励定义为:R(τ) = R_acc(τ) + R_f (τ)。
数据生成流程
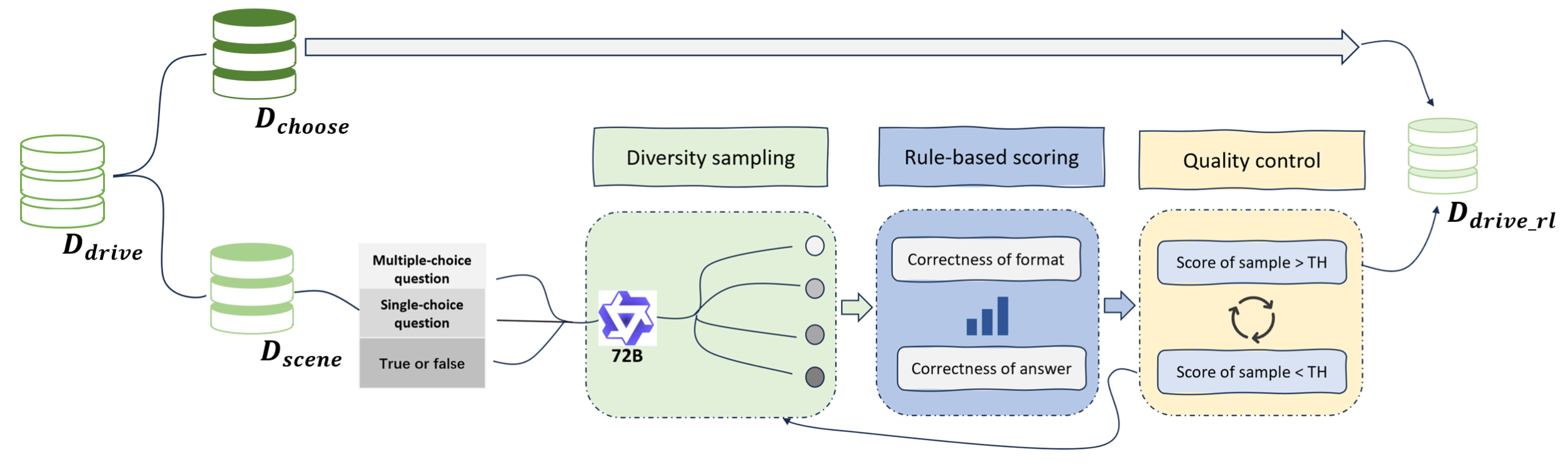
先前的研究表明,易于验证的奖励信号对于训练有效的强化学习智体至关重要 [32]。然而,现有的自动驾驶数据集采用开放式问答格式,在奖励验证的准确性和可扩展性方面存在显著挑战。
为了解决这一局限性并增强这些数据集在强化学习中的实用性,引入一种可验证的数据生成流程,如图所示。该流程将开放式场景问答数据集 D_drive 转换为易于验证的多项选择题或判断题。具体而言,首先利用先进的多模态大语言模型(例如 Qwen2.5VL-72B [3])进行多样化的候选样本生成。然后,根据一组预定义的规则对这些生成的样本进行评分。采用拒绝采样策略来过滤掉得分低于预定阈值的样本。最后,仅选择得分最高的样本,构成最终的高质量数据集 D_drive_rl。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)