深度觉醒 — Deep Agents(三座大山 — Agent 的核心挑战)
摘要:Agent技术的核心挑战与突破方向 当前AI Agent技术面临三大核心挑战:规划不可靠性、交互体验局限和记忆系统缺陷。在规划方面,LLM自主决策能力存在范式错配,领域特化认知架构比通用Agent更有效。交互体验上,需突破"对话即交互"的局限,转向事件驱动的"Ambient Agents"模式。记忆系统则需通过上下文工程策略(写入/选择/压缩/隔离)优
目录
三座大山 — Agent 的核心挑战
2023 年,人们第一次意识到:LLM 不只是“更聪明的搜索引擎”,它似乎可以推理、写代码、规划任务。
2024 年,这种想象被进一步放大——Agent 成为新的共识词汇。仿佛只要给模型一点工具、一个循环,它就能自动完成复杂工作,替代人类执行长期任务。
但历史一再证明:共识出现的地方,往往也是幻觉最集中的地方。
在 2024 年中旬的 Sequoia AI Ascent 大会上,LangChain 创始人 Harrison Chase 用一种非常工程师的方式,给 Agent 热潮泼了一盆冷水。他没有谈愿景,也没有谈未来社会,而是直接指出:当下 Agent 只有三根“承重梁”,而且每一根都在承压——
Planning、UX、Memory。
第一座山:Planning
Agent 最诱人的地方,在于“自主规划”。
但现实恰恰相反:规划是 LLM 最不可靠的能力之一。
让模型自己决定「下一步该做什么」,意味着你把系统的控制权交给了一个概率驱动的语言模型。在 demo 中它可能看起来很聪明,但在长链路、复杂约束、失败重试的真实环境里,它会:
- 忘记目标
- 做出看似合理但实际错误的决策
- 在错误路径上越走越远
这并不是“模型还不够大”的问题,而是范式层面的错配。
于是,一个反直觉但极其重要的转向出现了:用代码,替代 LLM 做规划。
AlphaCodium 就是一个标志性例子。它在代码生成任务上达到 SOTA,并不是因为模型更强,而是因为它几乎不让模型自由规划:
- 先写测试
- 再写代码
- 运行测试
- 根据失败结果迭代
整个流程,是人类工程师设计好的认知框架,LLM 只是其中的执行与推理组件。
这也解释了一个常被忽略的事实:
所有真正跑在生产环境里的高级 Agent,几乎都是“领域特化的认知架构”,而不是通用 Agent。
第二座山:UX
Agent 的第二个幻觉,是“对话即交互”。
当所有系统都被包进一个 Chat 窗口里时,人们开始默认:
只要能聊,就能用。
但真实工作流并不是连续对话,而是事件驱动、状态变化、后台执行。
2025 年初,LangChain 提出了一个重要但被低估的概念:Ambient Agents。
它的核心思想是:
- Agent 不等待用户输入
- 而是监听事件流
- 在需要时自动行动
- 只有在必要的时候,才打断用户
这实际上是一次 UX 层面的“去 Chat 化”尝试,也隐含着一个判断:真正成熟的 Agent,应该尽量不可见。
第三座山:Memory
LLM 不会记事。所谓“记忆”,从来不是模型能力,而是应用设计问题:
- 记什么?
- 记多久?
- 用来做什么决策?
- 如何防止错误记忆反噬系统?
这些问题,没有任何通用答案。
上下文工程 — 被低估的核心能力
2025 年中,一个新术语开始流行:Context Engineering(上下文工程)。
Andrej Karpathy 把它定义为:
在每一步中,用恰到好处的信息填充上下文窗口的精妙艺术与科学。
为什么这个概念会突然火?因为大家终于意识到一个现实:Agent 失败,通常不是模型问题,而是上下文问题。
LLM 并不是万能的“智能黑箱”。它能输出的东西,完全依赖你喂给它的信息质量。你给它垃圾,它就输出垃圾——甚至表现得比直接暴露出来的错误更“可信”。
于是,如何管理、组织和传递上下文,成为了 Agent 系统设计中真正的瓶颈。这个思路逐渐被总结为四大策略:
| 策略 | 做什么 | 例子 |
|---|---|---|
| Write | 把上下文写到外部存储 | Scratchpad、Memory 文件、数据库 |
| Select | 从历史信息里选择最相关的部分 | RAG(Retrieval-Augmented Generation)、Memory 检索 |
| Compress | 压缩上下文,让核心信息突出 | 摘要、裁剪历史对话 |
| Isolate | 隔离上下文,避免干扰或信息泄露 | Multi-agent 协作、Sandbox 环境 |
现实中的实践早已证明这些策略的价值:
- Manus 团队是最早公开讨论这些策略的。他们的方法非常朴素:将工具返回的大量数据写入文件系统,而不是直接塞进对话历史。当 Agent 需要信息时,再用 grep 或 read 的方式调用。
- AlphaCodium 在代码生成中使用的“测试驱动迭代”,本质也是一种上下文工程:每次运行测试结果作为外部上下文,指导下一轮生成,而不是把所有信息堆进 prompt。
- RAG + LLM 的组合,在问答 Agent 或知识管理场景中几乎成为标准做法:检索相关文档作为上下文,而不是让模型从头记忆整个知识库。
可以看到,Agent 的能力上限,往往 = Context 的质量上限。
在生产环境里,最强的模型不一定是最可靠的 Agent,而是那些懂得巧妙填充、选择、压缩和隔离上下文的系统。
深度觉醒 — Deep Agents 的四大特征
2025 年 7 月,LangChain 正式提出了 Deep Agents 概念。
灵感来源包括 Claude Code、Manus、Deep Research 等前沿产品,它们展示了一种“深度”能力:不是简单的工具调用循环,而是真正能够深入处理复杂问题的智能体。
换句话说,Deep Agents 的核心,不在于模型本身有多强,而在于系统如何组织、管理和利用信息,让模型在复杂任务中持续有效地工作。
Deep Agents 有四大特征:
1. 详细的系统提示词(System Prompt)
Claude Code 的提示词有上千行,几乎是一个“小型手册”。它不仅包含 工具使用说明,还有 few-shot 示例、行为指南、错误处理规则等。
为什么如此重要?
因为这些提示词提供了对 Agent 行为的全局约束,防止模型在复杂任务中偏离预期。它们相当于 Agent 的“操作手册”,指导模型如何理解任务、调用工具、处理异常和维持上下文焦点。
2. 规划工具(Planning Tools)
Deep Agents 并不依赖模型自由规划,而是通过外部工具让规划可视化和可控。例如 Todo List 工具。乍一看,这个工具似乎没做什么——它本身不执行操作,只是让 Agent 把计划写下来。
有趣的是,这种做法非常有效:写下来的计划会保存在上下文中,帮助 Agent 保持专注,防止在复杂任务中跑偏。
从本质上讲,这正是一种上下文工程策略:规划与执行的分离,让上下文信息更清晰、更持久。
3. 子智能体(Sub-Agents)
处理复杂任务时,单个 Agent 往往无法兼顾所有细节。Deep Agents 借助 子智能体 来拆分任务,每个子 Agent 专注于特定子任务。
更重要的是,这带来了上下文隔离:
- 每个子 Agent 只需要关注自己任务相关的信息
- 避免了上下文窗口被无关信息占满
- 提高了整体效率和任务完成率
Anthropic 的研究表明,多个 Agent 各自处理子任务的效果明显优于单个 Agent 独自处理所有任务。这正是“深度”思路的体现:分而治之,让复杂问题可控。
4. 文件系统(File System as Memory)
这是 Deep Agents 中最被低估但却至关重要的特征。
文件系统提供了一个统一接口来存储、检索和更新几乎无限量的上下文。它不仅能保存中间结果,还能让 Agent 动态加载、更新任务相关信息。
Anthropic 的 Skills 系统就是一个典型例子:
- 每个 Skill 对应一个文件夹,包含
SKILL.md - Agent 可以在运行时动态发现和加载这些 Skill
- 文件系统让 Agent 的上下文不再局限于模型窗口,而是可以横跨任务、跨时间持久存在
换句话说,文件系统让 Deep Agent 从“短期记忆型模型”升级为可扩展、可持续学习的智能系统。
DeepAgent
什么是 Deep Agent ?
如果说,我们熟知的大语言模型(LLM)是一位学识渊博、对答如流的“金牌咨询师”,那么传统的 AI Agent,就是我们为这位咨询师配备的第一个“助理”。我们让他学会了使用工具:调用搜索引擎查资料、启动计算器做数学、打开代码解释器写程序……
这在处理那些“短平快”的单一任务时,确实表现惊艳,能做出几下漂亮的“花拳绣腿”。
然而,当我们试图将它应用于真正复杂的、需要多步骤推理和长期规划的现实世界工作时,这位“助理型” Agent 很快就后劲不足,陷入迷茫。它就像一个只会响应眼前指令的实习生,缺乏大局观和章法,常常“浅尝辄止”,难以托付重任。
真正的挑战在于:如何让这位咨询师从一个“单点问题解决者”,进化成一个能独立领导和完成复杂项目的“首席战略官”?
这就是 Deep Agent 框架所要讲述的核心故事。它不再满足于简单的工具调用循环,而是通过构建一个更高级、更严谨的智能体框架,赋予 AI 真正的深度思考与执行能力。
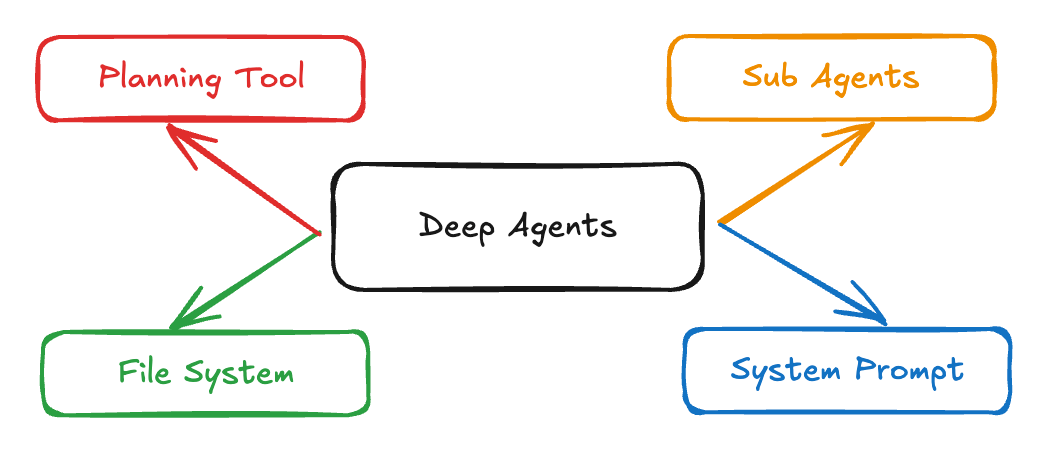
Deep Agent 的设计哲学:赋予 Agent “思考”与“纪律”
为了解决这些问题,新一代的 Deep Agent 的核心思想,不再是仅仅依赖LLM的“蛮力”,而是为其构建一个成熟的、结构化的工作体系,将“天才少年”培养成一个有目标、有团队、有记忆、有纪律的“成熟战略家”。
其优化方向正是对症下药:
1、引入“项目蓝图” —— 规划工具 (Planning Tool)
为了解决“短视”问题,Deep Agent 引入了规划工具。它就像一位经验丰富的项目经理,在行动前,会先利用大模型的推理能力,生成一份全局的任务计划(蓝图)。更关键的是,在执行每一步时,它都会重新审视这份蓝图和当前上下文,动态评估并校准下一步的最佳行动。这确保了它始终朝着最终目标前进,不会迷失方向。
2、组建“专家团队” —— 子智能体 (Sub-Agents)
针对“孤胆英雄”的困境,Deep Agent 的答案是组建一支“专家团队”——也就是子智能体。它将一个复杂的任务分解,分配给拥有不同“专长”的子智能体(如负责检索的、负责分析的、负责执行的、负责代码生成的等)。并通过一个“任务协调器”(Coordinator)来统一调度和管理,让它们高效协作。这就像一个高效的现代化工厂,拥有了负责不同工序的专家,流水线作业,效率和质量都得到了质的飞跃。
3、外挂“无限硬盘” —— 文件系统 (File System Access)
为了治愈“短期失忆症”,我们为 Deep Agent 外挂了一块“无限硬盘”——即赋予它读写文件系统的能力。任务过程中产生的任何中间结果、关键信息、甚至是思考日志,都可以被持久化地存储下来。当 Agent 需要时,可以随时读取,从而彻底解决了上下文窗口的限制,让执行长达数天甚至数月的复杂任务成为了可能。
4、下达“书面合同” —— 结构化提示 (Detailed Prompting)
最后,为了驯服这匹强大的“野马”,我们采用了结构化提示。通过精心设计的、模板化的 Prompt,我们能为 Agent 的每一步行动都设定明确的目标、约束条件和输出格式。这不再是模糊的口头指令,而是一份份权责清晰、目标明确的“书面合同”,极大地降低了任务的不确定性,让Agent的行为变得更加可靠和可控。
通过这些进化,Deep Agent 不再是那个充满不确定性的黑盒,而是真正开始成为我们能够信赖、能够委以重任的强大生产力伙伴。
这里我们使用langchain的deepagents库,首先安装环境:
# 安装 a deepagents 库
pip install deepagents
任务规划:Planning Tool
单纯依赖LLM完成复杂任务的长期规划与执行很容易发生偏离。各大模型厂商推出的“深度 Agent”(如 OpenAI Deep Research、Claude Code)背后除了训练特殊的Agent推理模型外,都采用了类似的策略:
在执行前先列步骤、做计划,然后逐一跟踪执行;并在必要时做调整
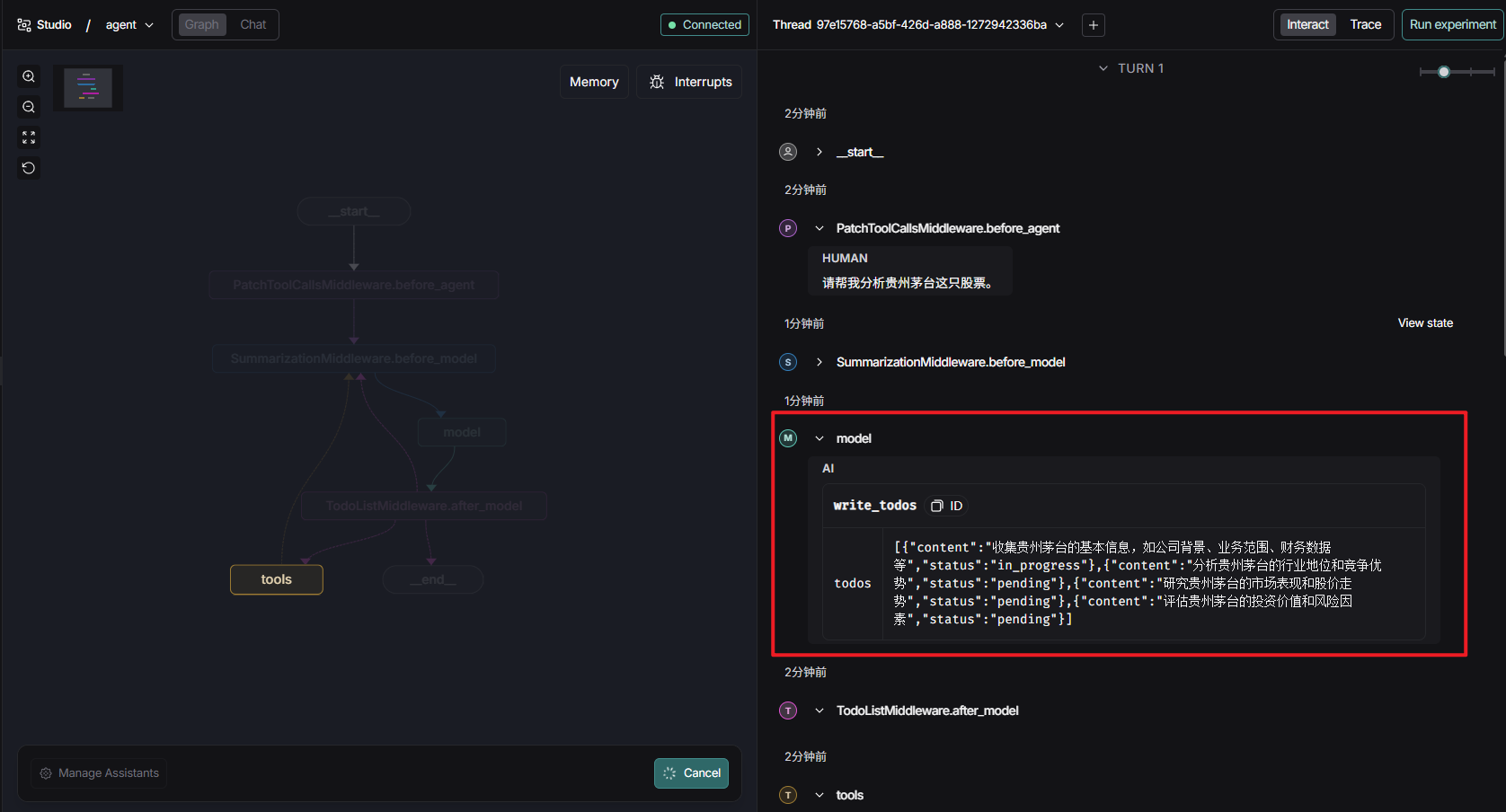
DeepAgents 中的任务规划能力是通过一个内置工具 write_todos 来实现的。它会在以下条件下触发:
-
任务目标比较复杂,特别是涉及较多的步骤
-
用户明确提示要求LLM先规划执行
-
每完成一个步骤,需要修订任务清单 - 标记状态或调整任务
我们将从构建一个最简单的Agent开始,并逐步细化与丰富其能力。在这个过程中你将可以清晰的看到,DeepAgents是如何在LangGraph与LangChain的基础上“添砖加瓦”,以适应更复杂的任务环境。
首先设计一个简单的场景:
构建一个借助于搜索与金融数据接口等工具进行股票分析的Agent。
from deepagents import create_deep_agent
from langchain.messages import HumanMessage
from agent.model import qwen3_8b
agents = create_deep_agent(model=qwen3_8b)
if __name__ == '__main__':
print(agents.invoke({"messages":[HumanMessage(content="请帮我分析贵州茅台这只股票")]}))
这里的模型我使用的是硅基流动的免费模型,为了更好的观测Agent运行,通过LangGraph命令行来部署与启动:
pip install --upgrade "langgraph-cli[inmem]"
langgraph dev
这里需要两个文件,env和langgraph.json,env文件记录langsmith的配置:
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_API_KEY=your api key
LANGSMITH_PROJECT="pr-tart-licorice-47"
langgraph.json记录项目配置
{
"dependencies": ["."],
"graphs": {
"agent": "./test.py:agents"
},
"env": ".env"
}
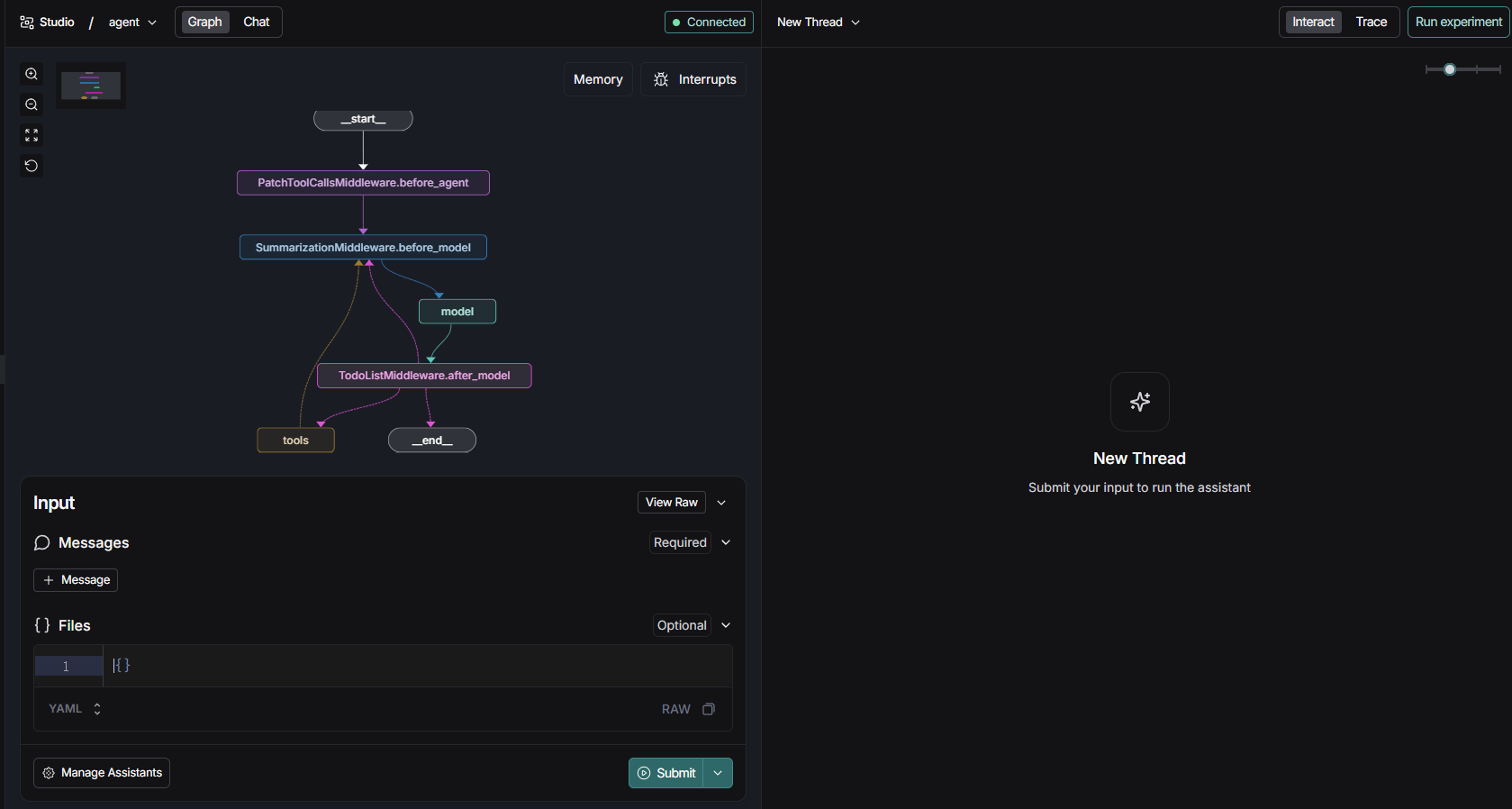
启动项目访问对应地址,我们可以看到一个deep agent的页面:
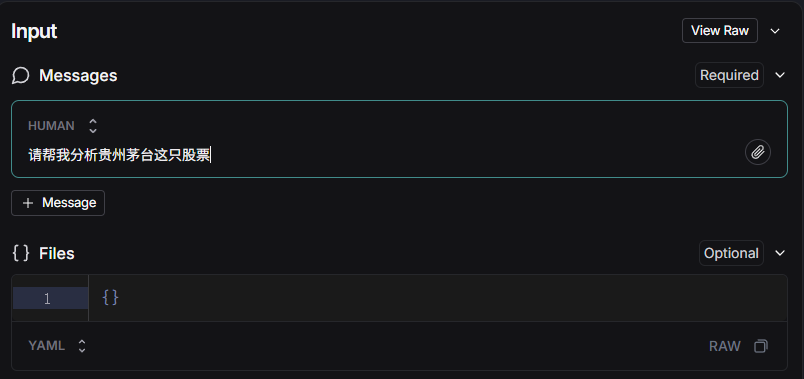
在出现的LangSmith Studio界面上输入消息:请帮我分析贵州茅台这只股票。
DeepAgents 中的任务规划能力是通过一个内置工具 write_todos 来实现的。它会在以下条件下触发:
-
任务目标比较复杂,特别是涉及较多的步骤
-
用户明确提示要求LLM先规划执行
-
每完成一个步骤,需要修订任务清单 - 标记状态或调整任务
文件系统:File System
想象一下,当领导交给你一个复杂任务时,你是否会需要一个笔记本来记录重要事项或工作成果,必要时可以随时翻阅?
Deep Agents 的另一个重要特性——“文件系统”,就类似这样的笔记本。
通过给 Agent 配备一套虚拟文件系统和读写工具,它可以随时记录、查询和持久化任务过程中的信息。
举例说明:
- 作为一个客服 Agent,它可以把每次与客户交互的摘要存放在虚拟文件系统中,例如
/memories/{user_id}/下。 - 当客户下次来访时,Agent 可以快速调取历史信息,从而提供连续、个性化的服务体验。
虚拟文件系统由**可插拔、可扩展的后端(Backend)**实现,常见架构如下:
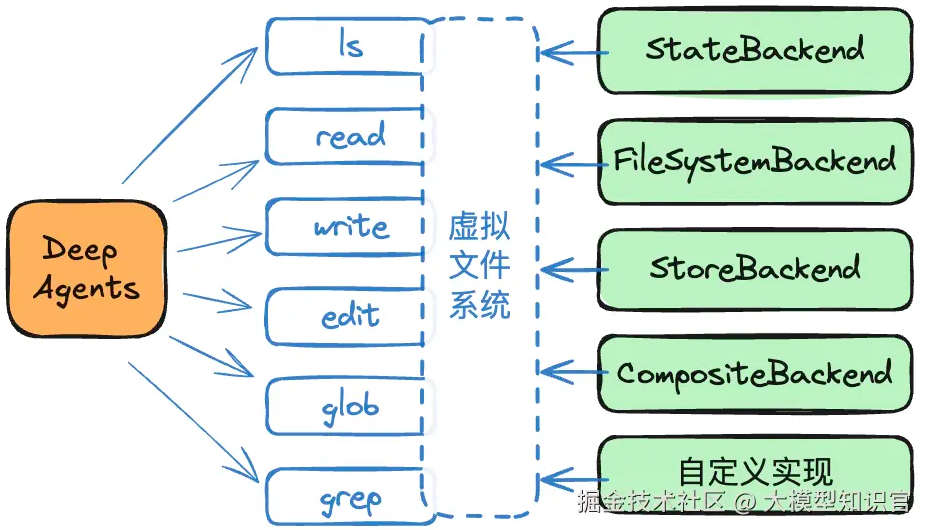
-
StateBackend
- Agent 的状态作为存储,仅在当前线程有效。
- 用于在一次对话中保存临时的中间结果,优化上下文空间。
-
FileSystemBackend
- 使用本地文件系统目录作为存储,可长期保存数据。
- 常用于保存 AI 生成的创作文档或代码文件。
-
StoreBackend
- Store 是 LangGraph 实现跨线程持久记忆的机制。
- 可使用 Redis、Postgres 等作为实现。
- 允许配置 Store 作为虚拟文件系统,实现跨线程的持久化存储。
-
CompositeBackend
- 复合后端方案。
- 例如:默认使用 StateBackend,但存储到
/memories/下的数据使用 StoreBackend,从而实现跨线程持久化。
此外,你可以编写自己的 Backend,例如将虚拟文件系统映射到阿里云 OSS;也可以扩展已有 Backend,比如给 FileSystemBackend 增加安全检查或访问控制。
接下来,我们继续用前面的 Agent 示例来体验这个特性。
State 作为 Backend(默认)首先,不做任何代码修改,只对任务稍作调整。
观察执行过程,你会看到 write_file 工具的调用:
- 由于没有指定其他 Backend,Agent 会使用默认的 StateBackend。
- 文件会被直接保存在 State 的
Files字段 中。 - 需要注意的是,这些“文件”并不是真实的文件,仅在本次线程有效,任务结束后即会消失。
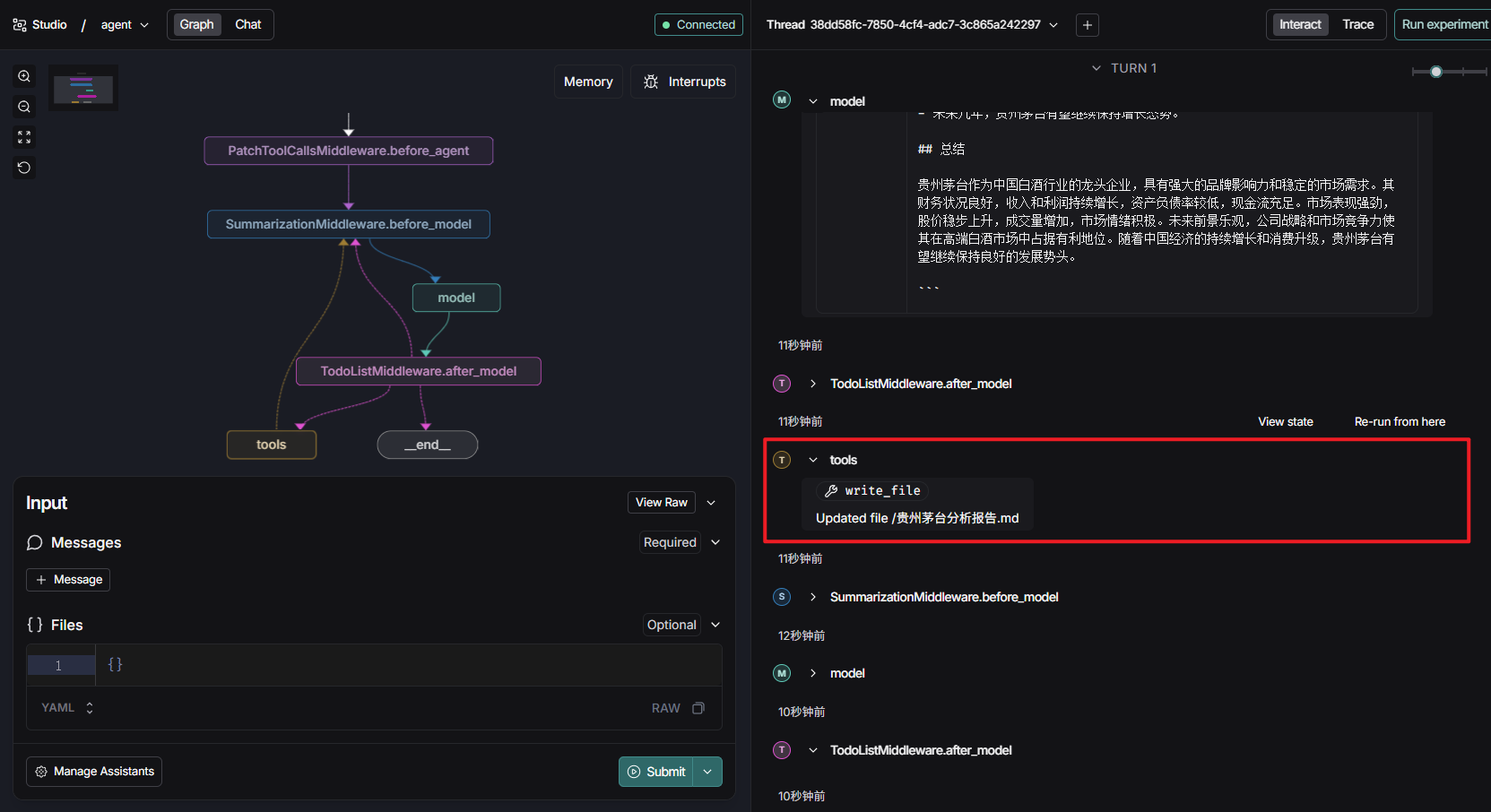
本地文件系统作为 Backend
现在,我们可以给 Agent 更换另一个 Backend 的实现,让文件写入真实的本地文件系统。
- 这样,Agent 生成的文件就可以长期保存,方便后续读取或跨任务使用。
- 也可以在此基础上扩展功能,例如添加安全检查、访问权限控制,或者与其他系统集成。
agents = create_deep_agent(
model=qwen3_8b,
backend=FilesystemBackend(
root_dir="./fs",
virtual_mode=True
),
)
相同的输入任务下,你将不会在State看到Files字段,而是生成了真实的文件:
LangGraph Store作为Backend
这是非常重要的一项能力。它可以让Deep Agents能够像访问文件系统一样,直接操作底层LangGraph的持久装置(Store),从而获得跨线程、跨会话、带向量检索能力的持续记忆能力。
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
agent = create_deep_agent(
backend=composite_backend,
store=InMemoryStore() # Store passed to create_deep_agent, not backend
)
这里创建了一个复合的Backend:默认使用本地文件系统做后端;但如果路由路径是/memories/,则使用LangGraph Store作为后端(默认类型InMemoryStore)。
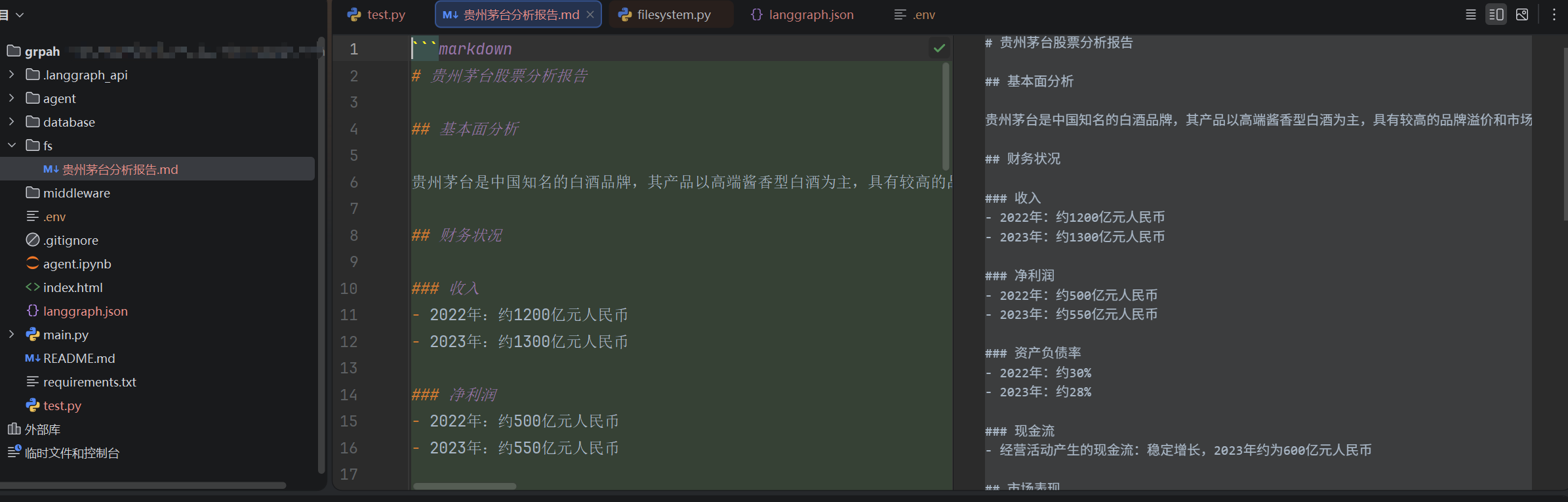
根据以上的设置:股票分析结果会被保存到本地文件系统;但分析过的股票名称将会被路由到LangGraph的持久记忆Store。
为了验证store中的“记忆”,我们开启一个新的线程任务询问:我分析过哪些股票?此时Agent会调用read_file工具来读取Store,并输出:贵州茅台!
这里就不再展示!
实际应用中,该功能可以用来实现诸如用户偏好记忆、知识积累、研究结果保存,以在不同会话中共享。
以上是DeepAgents内置的几种虚拟文件系统Backend实现。如果仍然无法满足你的需求,也可以自行实现BackendProtocol这个接口,将虚拟文件系统映射到你的OSS、数据库、向量库等。
扩展阅读:动态上下文发现
Cursor 刚发表了篇文章:《Dynamic context discovery》https://cursor.com/blog/dynamic-context-discovery(译文:https://baoyu.io/translations/cursor-dynamic-context-discovery),讲述了他们上下文管理的秘密。
之前 Manus 的 Peak 在访谈里面说:
所以 Peak 说当他们读到一些模型公司发布的研究博客时,心情是“既开心又无奈”。开心是因为这些博客验证了他们的方向,无奈是因为博客里写的东西,基本都是他们早就在做的。
Cursor 这篇文章又曾侧面印证了这个观点😂,不过也不能说 Cursor 是在抄袭 Manus 的技术,只能说 AI Agent 的最佳实践,就是怎么管理好上下文,而管理好上下文,就离不开文件系统。
言归正传,Cursor 这篇文章讲的是“动态上下文发现”,核心就是上下文管理。
给 AI 的上下文,不是越多越好,很多人用 AI,生怕 AI 不知道,怕 AI 记不住,恨不得把整个项目的文档、历史记录、工具说明一股脑全塞进去。
但随着模型变得越来越聪明,预先塞太多信息反而帮倒忙。一来浪费 token(上下文窗口是有限的),二来信息太杂可能干扰模型判断。就像你给一个能干的下属布置任务,不需要把公司所有制度文件都打印出来放他桌上,他需要什么,自己会去查。
这就是 Cursor 提出的"动态上下文发现"(Dynamic Context Discovery)模式:别急着把信息塞给模型,而是让模型在需要的时候自己去找。
【1】让 AI 自己找需要的信息。
听起来简单,但具体怎么做呢?Cursor 分享了五个他们实际在用的优化手段,每个都挺巧妙。
场景一:长输出变成文件
问题是什么?当 AI 调用外部工具(比如运行一个 shell 命令或者调用 MCP 服务),返回的结果可能很长——一大串日志、一整个网页的内容。常见做法是截断,只保留一部分。但截掉的那部分,说不定正好是后面要用的关键信息。
Cursor 的做法是:把长输出写成文件,然后给 AI 一个读文件的能力。AI 可以先用 tail 命令看看结尾,觉得需要再往前读。这样既不会塞满上下文,也不会丢信息。
场景二:聊天历史变成可查档案
当对话太长,超过上下文窗口限制时,Cursor 会触发一个"总结"步骤,把之前的内容压缩成摘要,给 AI 一个"新的起点"。
但压缩是有损的。重要细节可能在总结过程中丢失,导致 AI"失忆"。Cursor 的办法是把完整的聊天记录存成文件。AI 拿到的是摘要,但如果它意识到"这里好像漏了什么",可以自己去翻原始记录找回来。
这就像是你给员工发了一份会议纪要,但完整的会议录音也存着——有疑问随时可以回溯。
场景三:按需加载技能
Cursor 支持一种叫"Agent Skills"的扩展机制,本质上是告诉 AI 怎么处理特定领域任务的说明书。这些说明书可以有很多,但没必要每次都全部加载。
Cursor 的做法是只在系统提示里放一个"目录"——技能的名字和简短描述。AI 真正需要某个技能时,再用搜索工具把完整说明拉进来。就像你不会把整个图书馆背在身上,只带个索引卡片就够了。
场景四:MCP 工具的瘦身术
这个场景数据最有说服力。MCP 是一种让 AI 连接外部服务的标准协议,现在很火。问题是,有些 MCP 服务器提供几十个工具,每个工具的描述都很长,全塞进上下文窗口很占地方。更尴尬的是,大部分工具在一次任务中根本用不到。
Cursor 的优化方式是:只在提示词里放工具的名字,完整描述同步到一个文件夹。AI 需要用某个工具时,再去查具体怎么用。
效果怎么样?他们做了 A/B 测试,在调用 MCP 工具的场景下,这个策略减少了 46.9% 的 Token 消耗。接近一半的成本省下来了。
还有个附带好处:如果某个 MCP 服务需要重新认证,以前 AI 就会"忘记"这些工具的存在,用户一头雾水。现在 AI 能主动提醒用户"喂,你的 XX 服务需要重新登录了"。
关于 MCP 工具的优化,Anthropic 官方有一篇文章《Code execution with MCP: Building more efficient agents》 [图片] 网页链接,思路也是类似的,推荐看看。
场景五:终端会话也是文件
用过 AI 编程工具的人都知道,有时候你想问"我刚才那个命令为什么失败了",但 AI 根本不知道你运行过什么命令。你得手动把终端输出复制粘贴给它。
Cursor 现在把集成终端的输出自动同步到本地文件系统。AI 可以直接"看到"你的终端历史,需要的话还能用 grep 搜索特定内容。对于那些跑了很久的服务日志,这个功能特别实用。
【2】为什么是"文件"
你可能注意到了,Cursor 这五个优化有个共同点:都是把东西变成文件。
为什么是文件而不是别的抽象?
Cursor 的说法是:
我们不确定未来 LLM 工具的最佳接口是什么,但文件是一个简单、强大的基础单元,比发明一套新抽象要安全得多。
这个思路和 Manus 的理念不谋而合。Peak 在他们的技术博客《AI 智能体的上下文工程:构建 Manus 的经验教训》 [图片] 网页链接 里专门讲过:他们把文件系统当作"终极上下文"——容量无限、天然持久、而且 AI 自己就能操作。
Peak 举的例子很形象:一个网页的内容可以从上下文里删掉,只要 URL 还在,AI 随时能把内容找回来。一个文档的全文可以省略,只要文件路径在,需要时再读取就行。这种"可恢复的压缩",比简单的截断或删除聪明多了。
【3】几点思考
一个启示是:上下文工程的核心可能不是"怎么塞更多信息",而是"怎么让模型高效获取需要的信息"。随着模型能力提升,把主动权交给模型是一个趋势。
另一个启示是简单抽象的力量。在技术领域,我们经常迷恋复杂精巧的设计。但文件这个例子提醒我们:那些经过时间检验的简单抽象,往往比看起来高级的新发明更耐用。
模型够聪明的时候,少塞点东西、让它自己找,可能比硬塞一堆效果更好。有时候,less is more。
子智能体:Subagents
在现实中,复杂项目通常由多人分工合作完成,每个角色各司其职。
Deep Agents 引入的 Subagent(子代理)机制,正是让 AI Agent 也具备类似能力:
- 主 Agent 可以根据需要派生子 Agent 来负责特定的子任务。
- 本质上,这是一种 多智能体系统 机制。
Subagent 的主要优势
-
上下文隔离
- 复杂 Agent 任务需要处理大量中间步骤和信息,快速膨胀的上下文容易干扰主线思路。
- 引入子 Agent 后,主 Agent 可以将具体工作“外包”,仅接收最终结果,自身专注主线任务。
-
专长分离
- 不同的子 Agent 可以拥有不同的专业知识、提示词和工具集。
- 为每种任务定制子 Agent,比单个 Agent 试图囊括所有技能更高效、更可靠。
使用 Subagents 的两种方法
-
直接定义 Subagent 的职责
- 包括提示词、可用工具等。
-
新建或使用已有的 LangGraph 工作流
- 将整个工作流作为 Subagent 使用,实现任务拆分与复用。
我们继续对上面的例子进行增强——使用子 Agent 来协助完成任务。在这个示例中,我们设置了三个不同的“股票分析”专家 Subagent:
# 1. 基本面分析师 - 使用股票详细信息和财务报表工具
fundamental_analyst = {
"name": subagents_config["fundamental_analyst"]["name"],
"description": subagents_config["fundamental_analyst"]["description"],
"system_prompt": subagents_config["fundamental_analyst"]["prompt"],
"tools": [
get_stock_detailed_info, # 公司详细信息(主营、概况、筹码、分红)
get_financial_statements, # 财务报表(资产负债表、利润表、现金流量表)
],
"model": f"openai:{OPENAI_MODEL}",
}
# 2. 技术面分析师 - 使用技术指标和股票价格工具
technical_analyst = {
"name": subagents_config["technical_analyst"]["name"],
"description": subagents_config["technical_analyst"]["description"],
"system_prompt": subagents_config["technical_analyst"]["prompt"],
"tools": [
get_technical_indicators, # 技术指标
get_stock_price, # 股票历史价格数据
],
"model": f"openai:{OPENAI_MODEL}",
}
# 3. 消息面分析师 - 使用新闻和研报查询工具
news_analyst = {
"name": subagents_config["news_analyst"]["name"],
"description": subagents_config["news_analyst"]["description"],
"system_prompt": subagents_config["news_analyst"]["prompt"],
"tools": [
get_stock_news, # 个股新闻
get_stock_research_report, # 机构研究报告
],
"model": f"openai:{OPENAI_MODEL}",
}
这里通过 subagents_config 集中配置了三个 Subagent 的 提示词 与 工具集。不同于单纯通过搜索获取信息,这里使用了第三方金融数据接口。
接着,对主 Agent 的提示词进行适当修改,以便清晰说明如何使用 Subagent 协助完成任务。
在创建主 Agent 时,将三个 Subagent 通过 subagents 参数传入:
subagents = [fundamental_analyst, technical_analyst, news_analyst]
agent = create_deep_agent(
...
subagents=subagents
)
现在,当主 Agent 运行相同的任务时,你将能够观察到三个子 Agent 的参与过程:
- 基本面分析师负责财务数据和公司信息
- 技术面分析师负责股票价格与技术指标
- 消息面分析师负责新闻和研报信息
这样,主 Agent 就可以专注于整合分析结果、生成最终结论,而子 Agent 则各司其职,体现了 Deep Agents 的多智能体协作能力。

很显然,Subagents的内部机制是:主Agent根据需要使用名为“task”的工具,将不同的子任务派发给对应的Subagent来完成。
需要注意的是,当任务非常简单或需要全程共享上下文时,引入子Agent可能增加不必要的开销。但在多步骤复杂任务、需要不同专业知识或想保持主任务聚焦的场景下,子Agent无疑是强有力的工具。
总结
在前面的示例中,我们已经体验了 DeepAgents 在复杂任务中的核心能力。
那么,这些能力背后依托的机制是什么呢?
如果你打开 LangSmith Studio 查看 DeepAgent 的工作流图,会发现一个有趣的现象:
- DeepAgents 流程表面上与普通 ReAct Agent 并无本质区别。
- 本质上,它是在 LangChain 的 Agent 基础上挂载了多个中间件(Middleware)扩展。
Middleware 是在 LangChain 1.0 引入的 Agent 扩展机制,可以简单理解为:
插入到 Agent 主循环各个阶段的“钩子”,用于调整与扩展 Agent 的行为逻辑。
具体功能包括:
- 在 LLM 调用前后拦截消息
- 替换 LLM 请求或注入上下文
- 总结工具调用结果
通过中间件,开发者可以灵活定制 Agent 行为,而无需修改主循环逻辑。
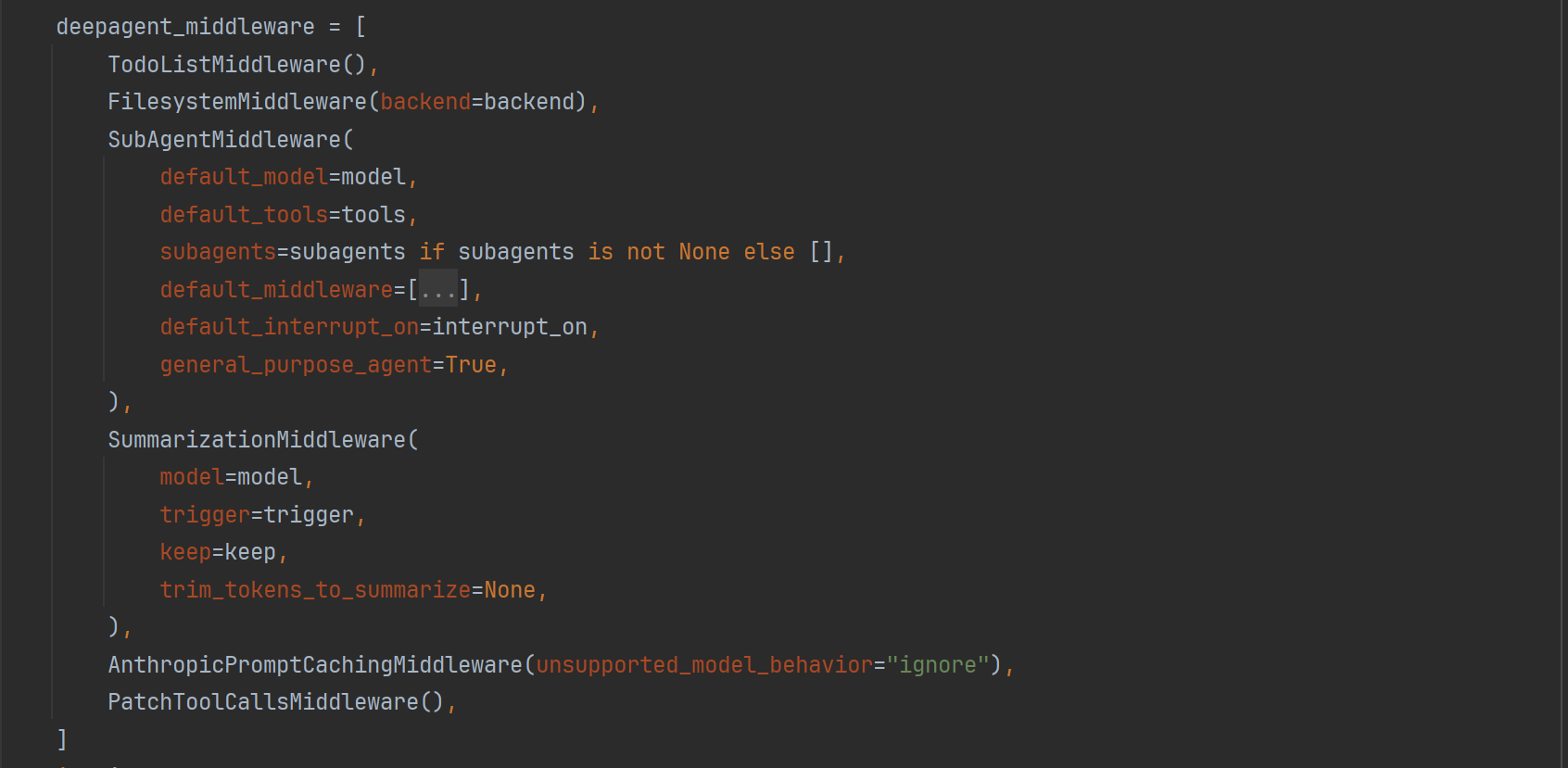
DeepAgents 利用中间件为普通 Agent 注入了多种新能力:
-
TodoListMiddleware
- 为 Agent 提供任务规划能力
-
FilesystemMiddleware
- 增加虚拟文件系统及相关工具
- 支持持久化和跨任务上下文管理
-
SubAgentMiddleware
- 支持子 Agent
- 实现任务拆分与分工协作模式
这种方式让 DeepAgents 内部清晰解耦:
- 每个中间件专注一个功能点
- 通过标准接口协作
- 开发者可以定制 DeepAgents 行为,例如更换规划策略(定制 TodoListMiddleware)
- 而无需修改整个 Agent 核心逻辑
DeepAgents 目前仍处于快速迭代阶段,官方透露了一些值得期待的发展方向:
- 系统提示的全面可定制
- 更灵活的多 Agent 协作模式
- 更高级的记忆检索与遗忘机制
- 与知识库和 RAG 技术的深度融合
- 更丰富的中间件生态
随着社区参与度提升和官方持续投入,DeepAgents 很有机会成长为下一代**“复杂任务智能体”**的标准化框架。
参考链接
[1] https://zhuanlan.zhihu.com/p/1987961895190290867
[2] https://juejin.cn/post/7573587915810652201

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)