超分辨率重建 | CVPR DAT:图像超分新SOTA,超越 SwinIR 与 Restormer,融合空间细节与全局维度的 Transformer(论文精读)
本文提出了一种双重聚合Transformer(DAT)用于图像超分辨率重建。DAT通过块间和块内的双重方式在空间和通道维度上聚合特征:块间采用交替堆叠的空间-通道Transformer块实现信息互补,块内则通过自适应交互模块(AIM)和空间门控前馈网络(SGFN)实现特征融合。AIM通过双向交互操作(空间交互S-I和通道交互C-I)将全局自注意力与局部卷积特征深度融合;SGFN则利用空间门控机制增
论文名称:Dual Aggregation Transformer for Image Super-Resolution
论文原文 (Paper):https://arxiv.org/abs/2308.03364
官方代码 (Code):https://github.com/zhengchen1999/DAT
代码实践链接:超分辨率重建 | CVPR DAT:图像超分新SOTA,超越 SwinIR 与 Restormer,融合空间细节与全局维度的 Transformer(代码实践)
GitHub 仓库链接:https://github.com/AITricks/AITricks
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
1. 核心思想
本论文提出了一种新颖的图像超分辨率模型——双重聚合Transformer (DAT)。其核心思想是通过块间 (inter-block) 和块内 (intra-block) 的双重方式,同时在空间 (spatial) 和通道 (channel) 维度上聚合特征,以获得更强大的特征表示能力。块间聚合通过交替堆叠空间和通道自注意力模块实现;块内聚合则通过新颖的自适应交互模块 (AIM) 和空间门控前馈网络 (SGFN) 来实现,从而在Transformer的单个模块内部高效融合多维度信息。
2. 背景与动机
- CNN的局限性:传统的基于CNN的SR方法受限于卷积操作的局部感受野,难以捕捉全局依赖关系,这限制了模型重建高质量纹理和结构的能力。
- Transformer的潜力与挑战:Vision Transformer (ViT) 凭借其自注意力 (Self-Attention, SA) 机制,能够有效建立全局依赖。然而,在SR任务中,现有的Transformer方法通常只偏重于一个维度:
- 空间注意力:如SwinIR,在局部空间窗口内计算SA (SW-SA),擅长建模精细的空间关系,但缺乏全局通道上下文。
- 通道注意力:如Restormer,沿着通道维度计算SA (CW-SA),能捕捉全局通道相关性(即特征图之间的关系),但空间建模能力较弱。
- 动机:作者认为,空间信息和通道上下文对于图像重建都至关重要。如何设计一个Transformer架构,使其能够同时且高效地聚合这两个维度的特征,是亟待解决的问题。现有的方法要么只关注其一,要么简单相加,未能实现深度融合。因此,本文提出了DAT,旨在通过块间和块内的双重聚合策略,充分发挥空间和通道注意力的互补优势。
3. 主要贡献点
-
提出了双重聚合Transformer (DAT) 架构
DAT是一个专为图像SR设计的Transformer模型。其核心创新在于“双重聚合”策略,即在两个层面(块间与块内)同时对空间和通道信息进行建模和融合,实现了对特征的更全面利用,超越了以往只侧重于单一维度(空间或通道)的Transformer SR模型。 -
设计了“块间”交替聚合策略 (Inter-block Aggregation)
DAT的骨干网络由两种Transformer块(DATB)交替堆叠而成:双重空间Transformer块 (DSTB) 和双重通道Transformer块 (DCTB)。DSTB内部使用空间窗口自注意力 (SW-SA),而DCTB内部使用通道自注意力 (CW-SA)。这种交替排列的设计,使得信息流可以在空间和通道维度之间流动和互补:空间注意力(DSTB)丰富了每个特征图的空间表达,为后续的通道注意力(DCTB)提供了更好的输入;而通道注意力(DCTB)则为空间注意力(DSTB)提供了全局上下文,扩大了窗口注意力的感受野。 -
提出了“块内”自适应交互模块 (AIM) 以融合局部与全局特征
在单个Transformer块(DSTB或DCTB)内部,作者设计了AIM (Adaptive Interaction Module) 来实现“块内”聚合。AIM的核心是并行运行自注意力分支(捕捉全局依赖)和卷积分支(捕捉局部信息),并通过两个精心设计的交互操作(空间交互S-I 和 通道交互C-I)来双向融合这两个分支的特征。这解决了传统Transformer中SA和FFN串行、SA分支缺乏局部性的问题。基于AIM,论文提出了自适应空间自注意力 (AS-SA) 和自适应通道自注意力 (AC-SA),作为DSTB和DCTB的核心。 -
提出了“块内”空间门控前馈网络 (SGFN)
传统的Transformer FFN(前馈网络)仅使用全连接层,这在处理特征时忽略了空间信息,并且容易产生通道冗余。为此,作者提出了SGFN (Spatial-Gate Feed-Forward Network) 来替代标准的FFN。SGFN引入了一个**空间门控 (Spatial-Gate, SG)**机制:它将FFN的中间特征沿通道维度一分为二,一部分通过一个深度卷积(DW-Conv)分支来引入非线性的空间信息,另一部分作为门控信号。这种设计既补充了FFN缺失的空间建模能力,又通过门控机制缓解了通道冗余,同时保持了计算高效性。
4. 方法细节
DAT的整体架构遵循SR模型的经典三段式设计:浅层特征提取、深层特征提取和图像重建。其核心创新均在深层特征提取模块中。
1. 整体架构

- 浅层特征提取:一个3x3卷积层 (
Conv) 从LR输入 I L R I_{LR} ILR 中提取浅层特征 F S F_S FS。 - 深层特征提取:由 N 1 N_1 N1 个残差组 (Residual Group, RG) 堆叠而成,并辅以一个长跳跃连接。
- 每个RG内部包含 N 2 N_2 N2 对双重聚合Transformer块 (DATB)(即一个DSTB和一个DCTB),以及一个用于特征精炼的
Conv层。RG同样采用了残差连接。
- 每个RG内部包含 N 2 N_2 N2 对双重聚合Transformer块 (DATB)(即一个DSTB和一个DCTB),以及一个用于特征精炼的
- 图像重建:通过一个长跳跃连接融合浅层特征 F S F_S FS 和深层特征 F D F_D FD,最后使用
Pixel Shuffle(像素重组)进行上采样,并通过Conv重建出HR图像 I H R I_{HR} IHR。
2. 块间聚合:交替堆叠
DATB是DAT的核心。它分为两种类型,两者在深层特征提取模块中交替出现:
- DSTB (Dual Spatial Transformer Block):如图2(b)所示,其核心是 AS-SA (自适应空间自注意力),它基于 SW-SA (空间窗口自注意力) 构建。
- DCTB (Dual Channel Transformer Block):如图2©所示,其核心是 AC-SA (自适应通道自注意力),它基于 CW-SA (通道自注意力) 构建。
这种 (DSTB -> DCTB -> DSTB -> …) 的交替模式,实现了块间的空间与通道信息聚合。
3. 块内聚合 (一):自适应交互模块 (AIM)
AIM是AS-SA和AC-SA的基础,用于在块内融合全局自注意力 (SA) 和局部卷积 (Conv)。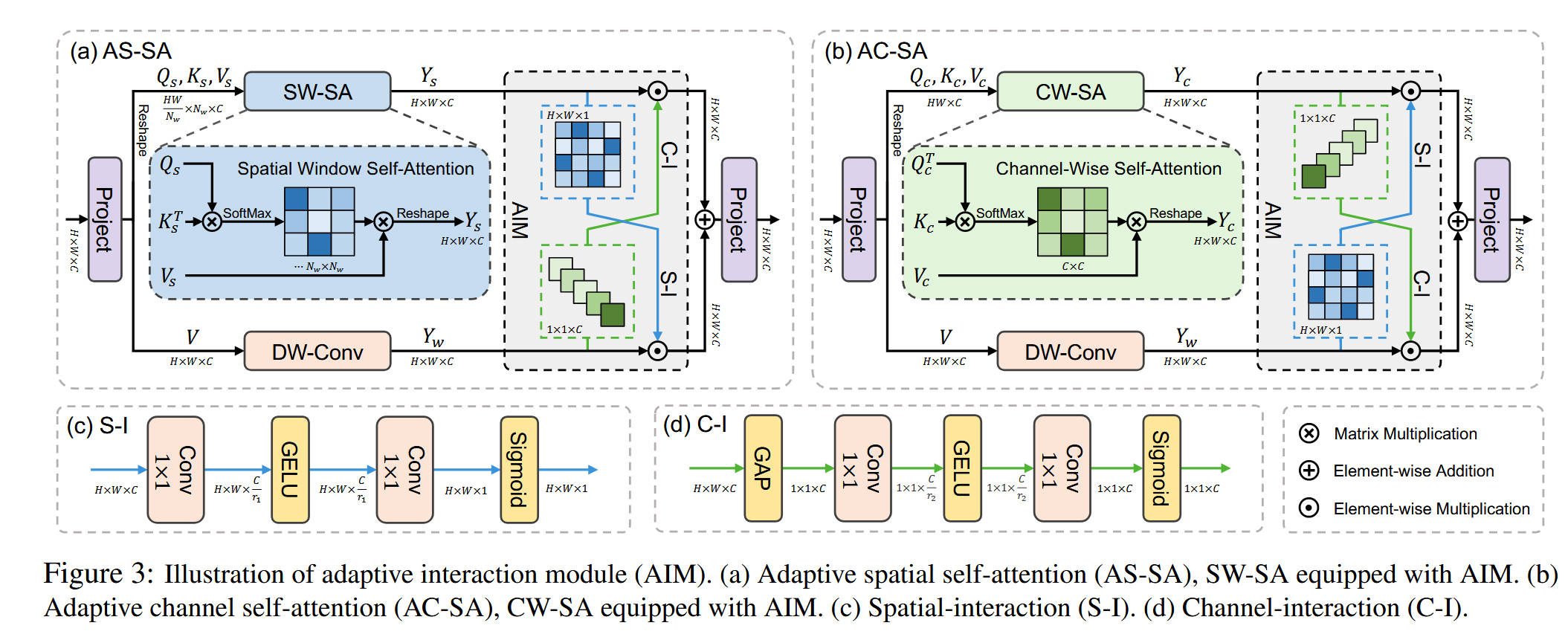
-
并行双分支:如图3(a)和3(b)所示,AIM具有两个并行分支:
- SA 分支:计算自注意力(SW-SA或CW-SA),输出特征 Y s Y_s Ys 或 Y c Y_c Yc。
- Conv 分支:对SA分支的输入 V V V (Value) 应用一个
DW-Conv(深度卷积),输出局部特征 Y w Y_w Yw。
-
双向交互 (S-I 和 C-I):AIM的核心是两个交互操作,用于在两个分支之间交换信息。
- 空间交互 (S-I, Spatial-Interaction) (Figure 3©):
- 理念:计算一个空间注意力图 (S-Map),并将其应用到另一个分支上。
- 公式: S - M a p ( B ) = f ( W 2 σ ( W 1 B ) ) S\text{-}Map(B) = f(W_2 \sigma(W_1 B)) S-Map(B)=f(W2σ(W1B))
- S - I ( A , B ) = A ⊙ S - M a p ( B ) S\text{-}I(A, B) = A \odot S\text{-}Map(B) S-I(A,B)=A⊙S-Map(B)
- 其中 A , B A, B A,B 为输入特征, W 1 , W 2 W_1, W_2 W1,W2 是1x1卷积, σ \sigma σ 是GELU, f f f 是Sigmoid。它利用B的空间信息去指导A。
- 通道交互 (C-I, Channel-Interaction) (Figure 3(d)):
- 理念:计算一个通道注意力图 (C-Map),并将其应用到另一个分支上。
- 公式: C - M a p ( B ) = f ( W 4 σ ( W 3 H G P ( B ) ) ) C\text{-}Map(B) = f(W_4 \sigma(W_3 H_{GP}(B))) C-Map(B)=f(W4σ(W3HGP(B)))
- C - I ( A , B ) = A ⊙ C - M a p ( B ) C\text{-}I(A, B) = A \odot C\text{-}Map(B) C-I(A,B)=A⊙C-Map(B)
- 其中 H G P H_{GP} HGP 是全局平均池化。它利用B的通道统计信息去指导A。
- 空间交互 (S-I, Spatial-Interaction) (Figure 3©):
-
AS-SA 和 AC-SA 的实现 (Eq. 7):
AIM通过交叉使用S-I和C-I,实现了空间和通道的互补。- AS-SA (Figure 3(a)):
- A S - S A ( X ) = ( C - I ( Y s , Y w ) + S - I ( Y w , Y s ) ) W p AS\text{-}SA(X) = (C\text{-}I(Y_s, Y_w) + S\text{-}I(Y_w, Y_s)) W_p AS-SA(X)=(C-I(Ys,Yw)+S-I(Yw,Ys))Wp
- 解读:对于空间注意力分支 ( Y s Y_s Ys),我们用卷积分支 ( Y w Y_w Yw) 的通道信息 (C-I) 来增强它;对于卷积分支 ( Y w Y_w Yw),我们用空间注意力分支 ( Y s Y_s Ys) 的空间信息 (S-I) 来增强它。这实现了“以通道补空间,以空间补局部”。
- AC-SA (Figure 3(b)):
- A C - S A ( X ) = ( S - I ( Y c , Y w ) + C - I ( Y w , Y c ) ) W p AC\text{-}SA(X) = (S\text{-}I(Y_c, Y_w) + C\text{-}I(Y_w, Y_c)) W_p AC-SA(X)=(S-I(Yc,Yw)+C-I(Yw,Yc))Wp
- 解读:对于通道注意力分支 ( Y c Y_c Yc),我们用卷积分支 ( Y w Y_w Yw) 的空间信息 (S-I) 来增强它;对于卷积分支 ( Y w Y_w Yw),我们用通道注意力分支 ( Y c Y_c Yc) 的通道信息 (C-I) 来增强它。这实现了“以空间补通道,以通道补局部”。
- AS-SA (Figure 3(a)):
4. 块内聚合 (二):空间门控前馈网络 (SGFN)
SGFN用于替代Transformer中的标准FFN。
-
SGFN 机制 (Eq. 8):
- 输入 X ^ \hat{X} X^ 经过第一个线性层 W p 1 W_p^1 Wp1 和GELU激活,得到中间特征 X ^ ′ \hat{X}' X^′。
- X ^ ′ \hat{X}' X^′ 沿着通道维度被分割 (Split) 为 X ^ 1 ′ \hat{X}'_1 X^1′ 和 X ^ 2 ′ \hat{X}'_2 X^2′ 两部分。
- X ^ 2 ′ \hat{X}'_2 X^2′ 经过一个
DW-Conv( W d W_d Wd),引入空间信息,得到 W d X ^ 2 ′ W_d \hat{X}'_2 WdX^2′。 - X ^ 1 ′ \hat{X}'_1 X^1′ 与 W d X ^ 2 ′ W_d \hat{X}'_2 WdX^2′ 进行逐元素相乘( ⊙ \odot ⊙),实现空间门控。
- 门控后的结果再通过第二个线性层 W p 2 W_p^2 Wp2 输出。
-
公式总结:
X ^ ′ = σ ( W p 1 X ^ ) \hat{X}' = \sigma(W_p^1 \hat{X}) X^′=σ(Wp1X^)
X ^ 1 ′ , X ^ 2 ′ = Split ( X ^ ′ ) \hat{X}'_1, \hat{X}'_2 = \text{Split}(\hat{X}') X^1′,X^2′=Split(X^′)
S G F N ( X ^ ) = W p 2 ( X ^ 1 ′ ⊙ ( W d X ^ 2 ′ ) ) SGFN(\hat{X}) = W_p^2 (\hat{X}'_1 \odot (W_d \hat{X}'_2)) SGFN(X^)=Wp2(X^1′⊙(WdX^2′)) -
总结:SGFN通过“分割-卷积-门控”三步操作,在标准FFN中高效地引入了空间上下文,并利用门控机制抑制了冗余的通道信息,实现了块内的另一种时空特征聚合。
5. 即插即用模块的作用与应用
本文中的两个核心创新 AIM 和 SGFN 都可以被视为高效的即插即用模块。
1. 自适应交互模块 (AIM)
-
模块作用:
AIM是一个通用的双分支特征融合模块。它不仅限于融合SA和Conv,而是可以推广到任意两个并行的特征提取分支(例如两个不同的卷积分支、两个不同的注意力分支等)。它通过交叉的维度交互(S-I和C-I),让两个分支相互“通气”,实现信息互补,最终输出一个融合后的强大特征。 -
适用场景与具体应用:
- 混合架构设计 (CNN-Transformer):在任何需要将CNN的局部性与Transformer的全局性相结合的模型中,AIM都可以用作二者的融合器。例如,在目标检测或语义分割的骨干网络中,可以并行运行一个CNN分支和一个Transformer分支,并使用AIM在多个阶段对它们进行融合。
- 多尺度特征融合:在U-Net或特征金字塔网络 (FPN) 中,AIM可以用于融合来自不同尺度的特征图,S-I可以帮助对齐空间结构,C-I可以帮助对齐通道语义。
- 多模态融合:例如在视觉-语言任务中,AIM可以用于融合视觉特征和文本特征,通过S-I和C-I的变体来对齐跨模态的空间和语义信息。
2. 空间门控前馈网络 (SGFN)
-
模块作用:
SGFN是一个即插即用的FFN/MLP替代模块。它旨在替代所有标准Transformer架构(如ViT, Swin, BERT等)中的MLP/FFN层。其核心作用是在不显著增加计算成本(使用高效的DW-Conv)的前提下,为原本只在通道间进行变换的FFN引入空间/局部建模能力。 -
适用场景与具体应用:
- 通用视觉骨干网络:可以直接替换ViT、Swin Transformer等模型中的FFN层。这对于所有下游的密集预测任务(如分割、检测)尤其有利,因为这些任务高度依赖空间信息的精确建模。
- 图像恢复/生成 (Restoration/Generation):在如去噪、去模糊、GAN等任务中,SGFN可以帮助FFN更好地处理空间纹理和结构信息,提升生成细节的质量。
- 视频理解:在视频Transformer中,可以将SGFN的2D DW-Conv扩展为3D DW-Conv,使其能够在FFN中同时建模时空局部关系。
- NLP (有待探索):虽然NLP主要处理1D序列,但SGFN中的“局部卷积”思想(即1D Conv)也可以被引入BERT等的FFN中,用于捕捉n-gram(局部词组)信息,作为对全局自注意力的补充。
到此,有关DAT的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
获取更多高质量论文及完整源码关注【AI即插即用】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)