HHO - KELM回归预测在电厂运行数据中的MATLAB实现
HHO哈里斯鹰算法算法优化KELM核极限学习机(HHO-KELM)回归预测MATLAB代码代码注释清楚。main为主程序,可以读取EXCEL数据。很方便,容易上手。(电厂运行数据为例)温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。在电力行业,对电厂运行数据进行精准预测至关重要。今天咱们聊聊用HHO(哈里斯鹰算法)优化KELM(核极限学习机)来做回归预测,还会分享MATLAB代码,
HHO哈里斯鹰算法算法优化KELM核极限学习机(HHO-KELM)回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。

在电力行业,对电厂运行数据进行精准预测至关重要。今天咱们聊聊用HHO(哈里斯鹰算法)优化KELM(核极限学习机)来做回归预测,还会分享MATLAB代码,并且注释清楚,方便大家上手。
1. 哈里斯鹰算法(HHO)
哈里斯鹰算法是一种新型的元启发式优化算法,模拟了哈里斯鹰群在捕食过程中的协作行为。简单来说,就像一群哈里斯鹰围捕猎物,它们会根据猎物的状态调整策略,有的负责包围,有的负责攻击,通过这样的协作来捕获猎物。在优化问题里,猎物就是我们要找的最优解。
2. 核极限学习机(KELM)
核极限学习机是极限学习机的改进版本,它通过引入核函数,能够处理非线性问题。极限学习机原本就训练速度快,但在面对复杂非线性数据时效果可能欠佳,KELM则通过核函数将数据映射到高维空间,让模型有更好的非线性拟合能力。
3. HHO - KELM的结合
把哈里斯鹰算法和核极限学习机结合起来,HHO就可以去搜索KELM模型中的最优参数,比如核函数的参数等,让KELM在回归预测中发挥更好的性能。这就好比给KELM配备了一个智能导航,能更快更准地找到最优解。
4. MATLAB代码实现
主程序main.m
% 主程序,用于读取EXCEL数据并进行HHO - KELM回归预测
% 以电厂运行数据为例
clear all;
clc;
% 读取EXCEL数据
data = xlsread('power_plant_data.xlsx'); % 假设数据保存在power_plant_data.xlsx文件中
% 这里简单粗暴地读入数据,实际应用中可能需要对数据格式等做更多处理
input_data = data(:, 1:end - 1); % 输入数据,假设最后一列是目标值
target_data = data(:, end); % 目标数据
% 数据归一化处理,让数据在同一尺度,提升模型性能
[input_norm, input_ps] = mapminmax(input_data, 0, 1);
[target_norm, target_ps] = mapminmax(target_data, 0, 1);
% 划分训练集和测试集
train_ratio = 0.7; % 70%的数据用于训练
train_num = round(size(input_norm, 1) * train_ratio);
train_input = input_norm(1:train_num, :);
train_target = target_norm(1:train_num, :);
test_input = input_norm(train_num + 1:end, :);
test_target = target_norm(train_num + 1:end, :);
% 调用HHO - KELM算法进行训练和预测
[predicted_norm, best_params] = hho_kelm(train_input, train_target, test_input, test_target);
% 反归一化,得到实际预测值
predicted = mapminmax('reverse', predicted_norm, target_ps);在这个主程序里,首先读取了电厂运行数据的EXCEL文件。接着对数据进行归一化处理,这一步很关键,不同特征的数据如果尺度差异大,模型可能会偏向尺度大的特征,归一化能避免这个问题。然后按照设定的比例划分训练集和测试集。最后调用hho_kelm函数进行训练和预测,并且把预测结果反归一化回原始尺度。
hho_kelm.m函数(简化示例)
function [predicted, best_params] = hho_kelm(train_input, train_target, test_input, test_target)
% 这里简单设定HHO和KELM的一些参数范围,实际应用可调整
dim = 2; % 假设要优化的参数维度为2,比如KELM核函数的两个参数
lb = [0.1, 0.1]; % 参数下限
ub = [10, 10]; % 参数上限
max_iter = 50; % 最大迭代次数
population = 20; % 种群数量
% 初始化哈里斯鹰种群
positions = repmat(lb, population, 1) + rand(population, dim).*(repmat(ub, population, 1) - repmat(lb, population, 1));
fitness = zeros(population, 1);
for i = 1:population
% 根据当前参数构建KELM模型并计算适应度
current_params = positions(i, :);
model = kelm(train_input, train_target, current_params(1), current_params(2));
predicted_train = kelm_predict(model, train_input);
fitness(i) = mean((predicted_train - train_target).^2); % 这里用均方误差作为适应度函数
end
[best_fitness, best_index] = min(fitness);
best_params = positions(best_index, :);
% 哈里斯鹰算法主循环
for t = 1:max_iter
% 各种哈里斯鹰算法的更新策略这里简化没写全
% 更新哈里斯鹰位置
for i = 1:population
% 更新位置的具体计算省略
new_positions(i, :) = new_position_calculation(positions(i, :), best_params, t, max_iter);
new_model = kelm(new_positions(i, :), train_input, train_target);
new_predicted_train = kelm_predict(new_model, train_input);
new_fitness = mean((new_predicted_train - train_target).^2);
if new_fitness < fitness(i)
positions(i, :) = new_positions(i, :);
fitness(i) = new_fitness;
end
end
[new_best_fitness, new_best_index] = min(fitness);
if new_best_fitness < best_fitness
best_fitness = new_best_fitness;
best_params = positions(new_best_index, :);
end
end
% 用最优参数构建最终KELM模型并进行预测
final_model = kelm(train_input, train_target, best_params(1), best_params(2));
predicted = kelm_predict(final_model, test_input);
end这个hho_kelm函数里,先初始化了哈里斯鹰的种群位置和适应度。通过循环计算每个个体的适应度,这里的适应度就是KELM模型在训练集上的均方误差。然后进入哈里斯鹰算法的主循环,每次循环更新哈里斯鹰的位置,并根据新位置计算新的适应度,更新最优解。最后用最优参数构建KELM模型对测试集进行预测。
kelm.m函数(构建KELM模型示例)
function model = kelm(input, target, param1, param2)
% 简单的RBF核函数KELM模型构建
num_samples = size(input, 1);
hidden_neurons = 50; % 假设隐藏层神经元数量为50
W = randn(size(input, 2), hidden_neurons); % 随机生成输入层到隐藏层的权重
b = randn(1, hidden_neurons); % 随机生成隐藏层偏置
H = zeros(num_samples, hidden_neurons);
for i = 1:num_samples
for j = 1: hidden_neurons
H(i, j) = exp(-param1 * norm(input(i, :) - W(:, j))^2 + param2); % RBF核函数计算隐藏层输出
end
end
beta = pinv(H) * target; % 计算输出层权重
model.W = W;
model.b = b;
model.beta = beta;
model.param1 = param1;
model.param2 = param2;
endkelm函数构建了一个简单的基于RBF核函数的KELM模型。先随机初始化输入层到隐藏层的权重和隐藏层偏置,通过RBF核函数计算隐藏层输出矩阵H,然后用伪逆计算输出层权重beta,最后把模型相关参数保存到model结构体里。
kelm_predict.m函数(KELM预测示例)
function predicted = kelm_predict(model, input)
num_samples = size(input, 1);
hidden_neurons = size(model.W, 2);
H = zeros(num_samples, hidden_neurons);
for i = 1:num_samples
for j = 1: hidden_neurons
H(i, j) = exp(-model.param1 * norm(input(i, :) - model.W(:, j))^2 + model.param2); % 用训练好的模型参数计算隐藏层输出
end
end
predicted = H * model.beta; % 计算预测值
endkelm_predict函数用训练好的KELM模型对新的输入数据进行预测。同样根据模型参数计算隐藏层输出,再与输出层权重相乘得到预测值。
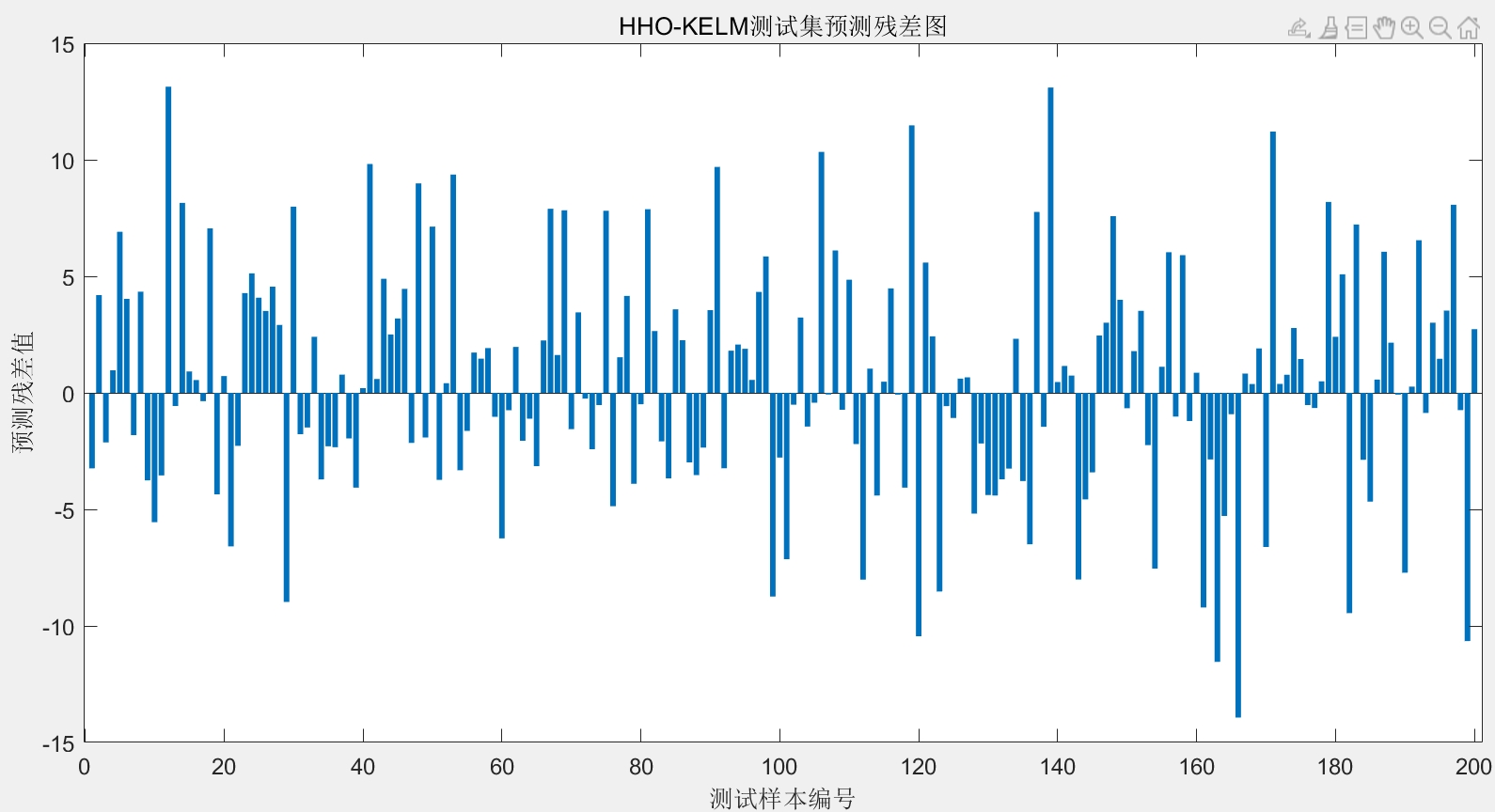
温馨提示一下,这个程序代码如果作为商品,一旦售出,是概不退换的哦。希望大家能通过这些代码和讲解,在电厂运行数据预测或者其他类似回归预测任务中有所收获。
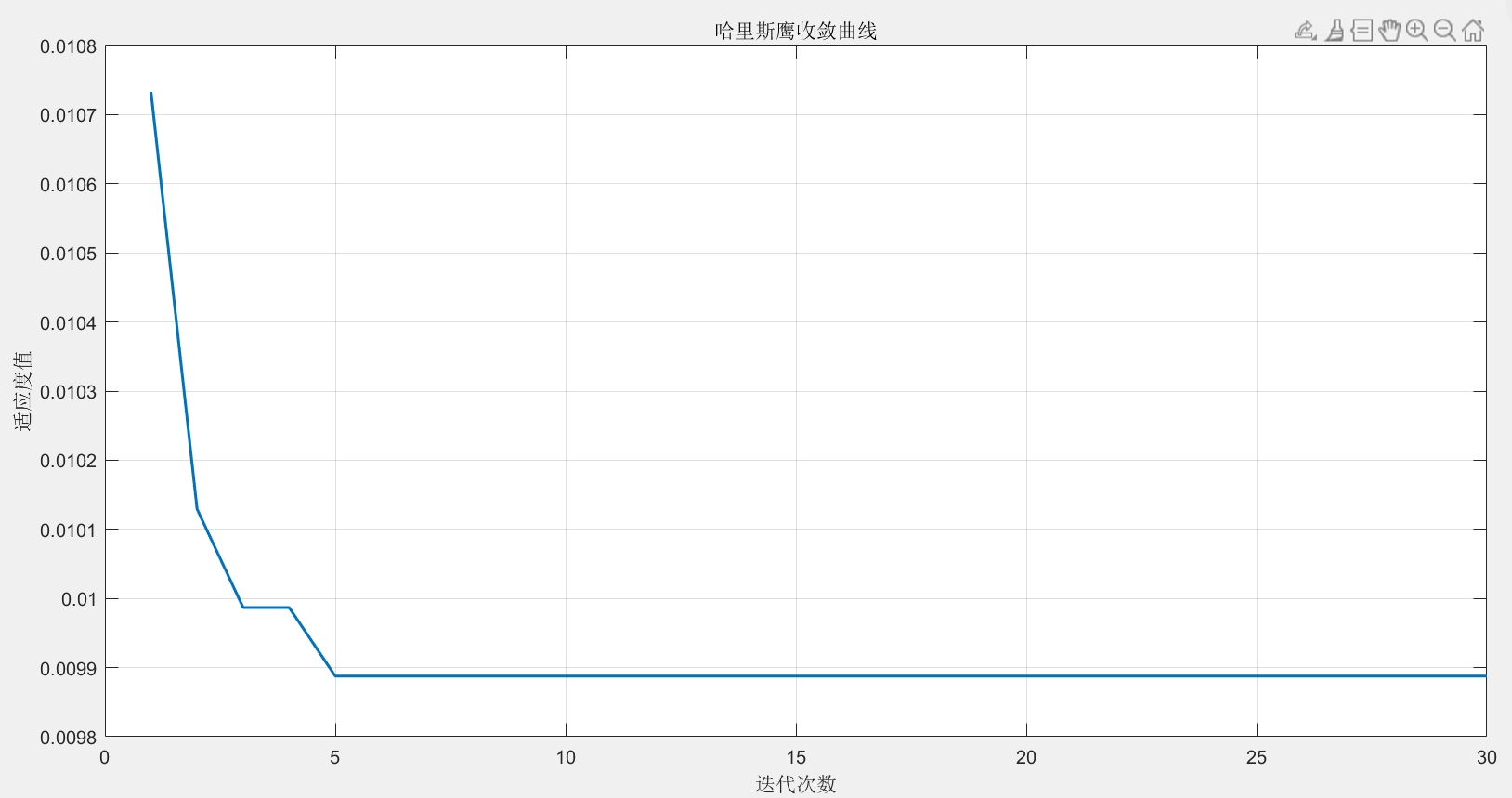
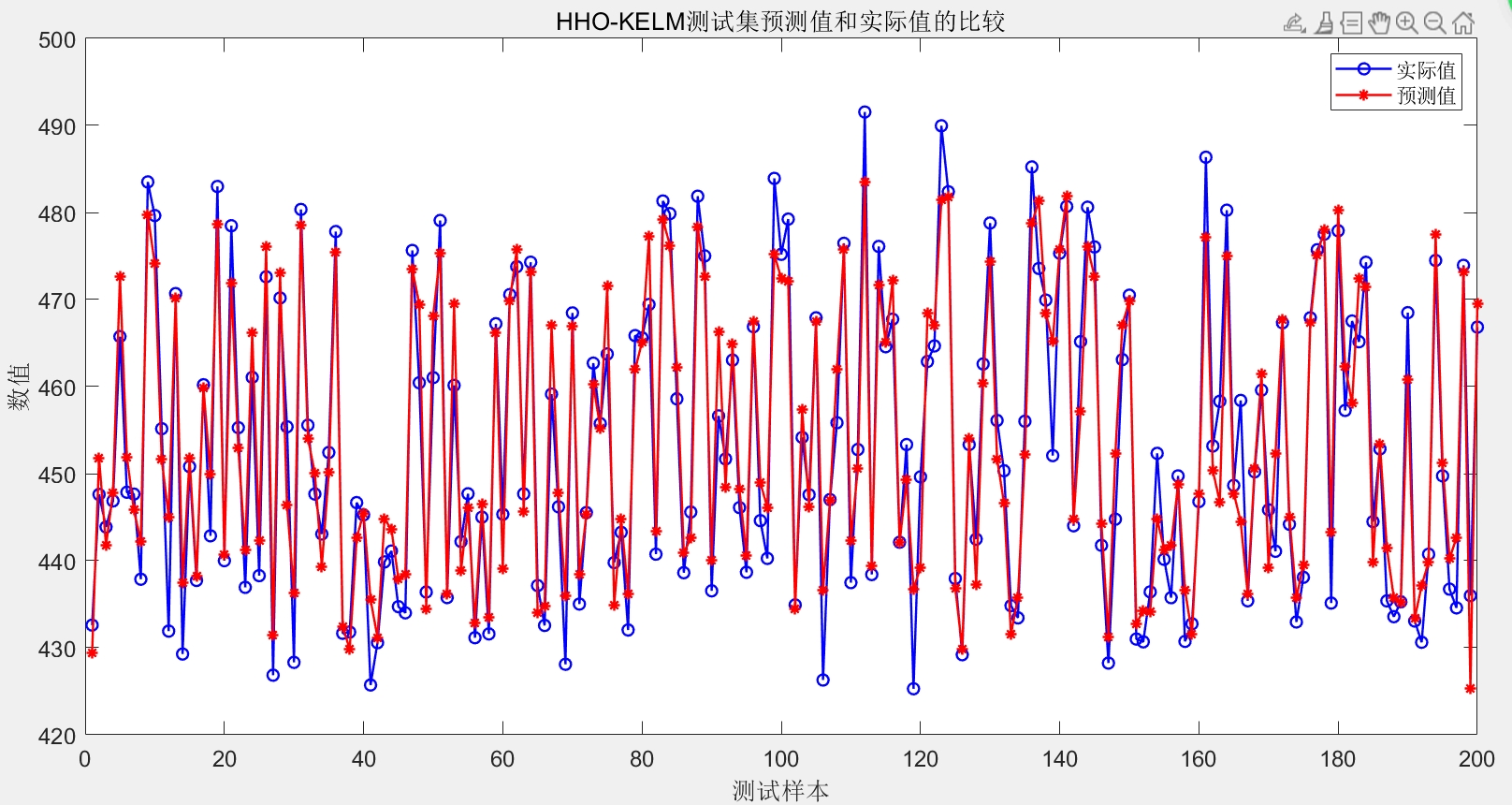
以上代码只是一个简化示例,实际应用中可能需要根据具体数据和问题进行更多调整和优化。比如数据预处理部分可能要处理缺失值、异常值等,哈里斯鹰算法和KELM模型的参数也需要更细致地调优。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)