SMOTE算法过采样 解决类不平衡问题,用于机器学习的分类问题 ===============...
SMOTE算法过采样解决类不平衡问题,用于机器学习的分类问题SMOTE是一种综合采样人工合成数据算法,用于解决数据类别不平衡问题(Imbalanced class problem),以Over-sampling少数类和Under-sampling多数类结合的方式来合成数据。案例数据中前9列为特征变量,最后一列为类别标签按相应格式准备自己数据即可,运行后输出新数据到excelMatlab代码,mai
SMOTE算法过采样 解决类不平衡问题,用于机器学习的分类问题 ======================== SMOTE是一种综合采样人工合成数据算法,用于解决数据类别不平衡问题(Imbalanced class problem),以Over-sampling少数类和Under-sampling多数类结合的方式来合成数据。 案例数据中前9列为特征变量,最后一列为类别标签 按相应格式准备自己数据即可,运行后输出新数据到excel Matlab代码,main为主程序,备注清晰,有助于新手使用(不适于不同类别差别太大的数据) (Example_22)
SMOTE(Synthetic Minority Oversampling Technique)算法是一种解决数据类别不平衡问题的过采样方法,简单理解就是给少数类制造一些人工数据,从而平衡少数类与多数类之间的数量差异。这种算法特别适合那些特征空间较为连续的数据集,比如那些可以通过插值方式生成新数据点的问题场景。
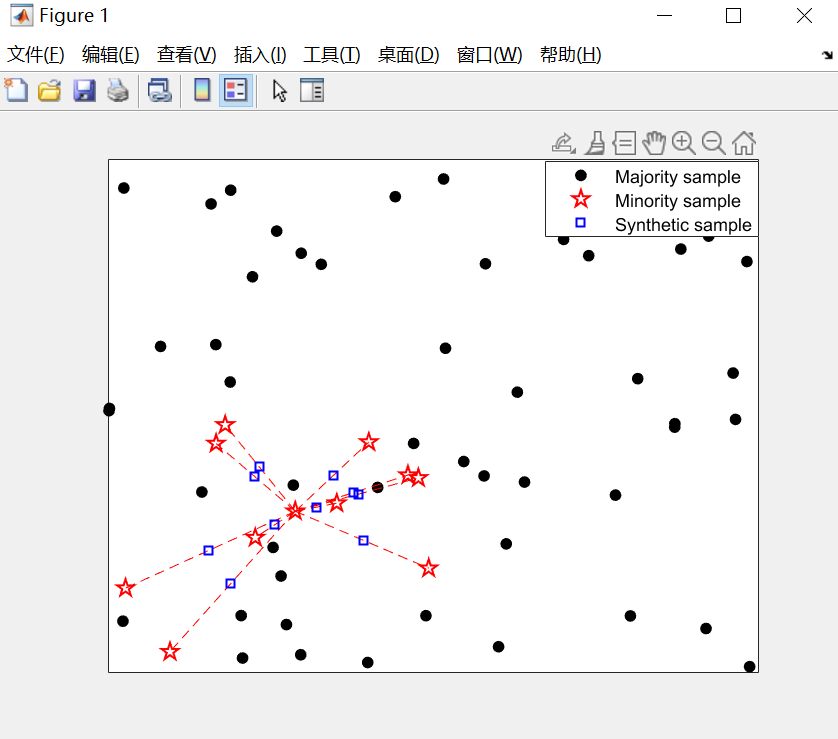
首先,什么是类不平衡问题?比如在分类问题中,如果一个类别有1000个样本,另一个类别只有100个样本,这时候模型训练时很容易偏向多数类,导致对少数类的预测能力很差。这种情况下就需要用到过采样或者欠采样的方法来调整数据集的类别分布。
SMOTE算法的大致逻辑
- 随机选一个少数类数据点
- 找到离这个点最近的k个少数类数据点
- 在这些近邻点之间随机插值生成新的数据点
这种插值方法的好处是能够在不大幅改变数据分布的情况下增加少数类的样本数量,还能一定程度上保留数据的多样性。
最简单的SMOTE实现思路
假设我们有一个数据集,每一行是一个样本,前9列是特征变量,最后一列是类别标签。我们的目标是通过SMOTE算法对少数类进行过采样。接下来是一个简化的实现思路:
% 读取数据
load('data.mat'); % 假设data.mat存储了我们的数据集
% 将数据分为多数类和少数类
major_class = data(data(:, end) == 1, :);
minor_class = data(data(:, end) == 0, :);
% 设置过采样的比例
ratio = 0.8; % 少数类与多数类的比例目标值
target_size = round(size(major_class, 1) * ratio);
% 计算需要生成的新样本数
need_samples = target_size - size(minor_class, 1);
% 开始生成新的合成样本
for i = 1:need_samples
% 随机选择一个少数类样本
idx = randi(size(minor_class, 1));
base_point = minor_class(idx, 1:end-1);
% 找到最近的k个邻居
distances = zeros(size(minor_class, 1), 1);
for j = 1:size(minor_class, 1)
if j ~= idx
distances(j) = norm(minor_class(j, 1:end-1) - base_point);
end
end
[sorted_dist, sorted_idx] = sort(distances);
neighbors = minor_class(sorted_idx(2:5), 1:end-1); % 取最近的4个邻居
% 随机选取一个邻居进行插值
random_neighbor = neighbors(randi(4), :);
synthetic_point = base_point + rand(1, 9) .* (random_neighbor - base_point);
% 添加新的合成样本
minor_class = [minor_class; synthetic_point, 0];
end
% 合并处理后的数据
balanced_data = [major_class; minor_class];
% 将处理后的数据保存到Excel
writematrix(balanced_data, 'balanced_data.xlsx');代码思路解释
- 读入数据:这里假设已经把数据存储为一个MAT文件,可以直接加载进来。
- 分类处理:将数据集按照类别分成两部分,方便后续操作。
- 设定比例:定义少数类和多数类需要达到的比例,这里的ratio可以根据实际需求调整。
- 计算需求:确定需要生成多少新样本才能满足设定的比例。
- 生成新样本:
- 每次从少数类中随机选择一个基点。
- 找到离这个基点最近的几个邻居,这里默认找4个邻居。
- 在这些邻居中随机选择一个,和基点之间随机插值生成一个新的样本点。 - 保存结果:最后将处理后的新数据保存到Excel文件中。
使用注意事项
- 数据特征的连续性:SMOTE算法更适合处理特征空间连续的数据,对于那些特征之间差异很大的数据,可能会生成很多不符合实际分布的样本。
- 过采样比例:过高的过采样比例可能导致过拟合,可以根据实际测试结果调整ratio参数。
- 特征空间的维度:特征维度太高可能会导致SMOTE的效果变差,建议在使用前做一些降维处理或者特征选择。
总之,SMOTE算法作为一种经典的过采样方法,在处理类不平衡问题时有着简单而有效的特点,特别适合特征空间较为连续的任务场景。不过在实际应用中,可能还需要结合其他方法一起使用,才能达到更好的平衡效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)