AI大模型:Python商品数据分析及预测系统 机器学习随机森林预测算法预测销量 爬虫 大数据分析 计算机毕业设计✅
AI大模型:Python商品数据分析及预测系统 机器学习随机森林预测算法预测销量 爬虫 大数据分析 计算机毕业设计✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:python语言、Django框架、Echarts可视化、机器学习随机森林预测算法预测销量、爬虫、HTML
Python 商品数据分析及预测系统介绍
本 Python 商品数据分析及预测系统,以 Python 语言为开发核心,依托 Django 框架搭建稳定后端架构,结合 Echarts 可视化工具与机器学习随机森林预测算法,搭配 HTML 构建前端交互界面,形成 “数据采集 - 分析 - 预测 - 应用” 的全流程商品数据服务体系,为企业精准把握商品运营动态、优化销量策略提供技术支撑。
技术层面,Python 不仅是算法实现与爬虫开发的基础(可爬取商品销量、用户评论、市场竞品等多源数据),还保障数据处理的高效性;Django 框架通过 MVC 模式实现前后端解耦,确保系统高可用性与可扩展性,支撑多界面协同运行;Echarts 则以丰富的图表类型(折线图、热力图、散点图等)将复杂数据可视化,让分析结果更易解读;随机森林算法凭借对多特征的精准拟合能力,结合历史销量、价格波动、促销活动等数据,实现销量的科学预测。
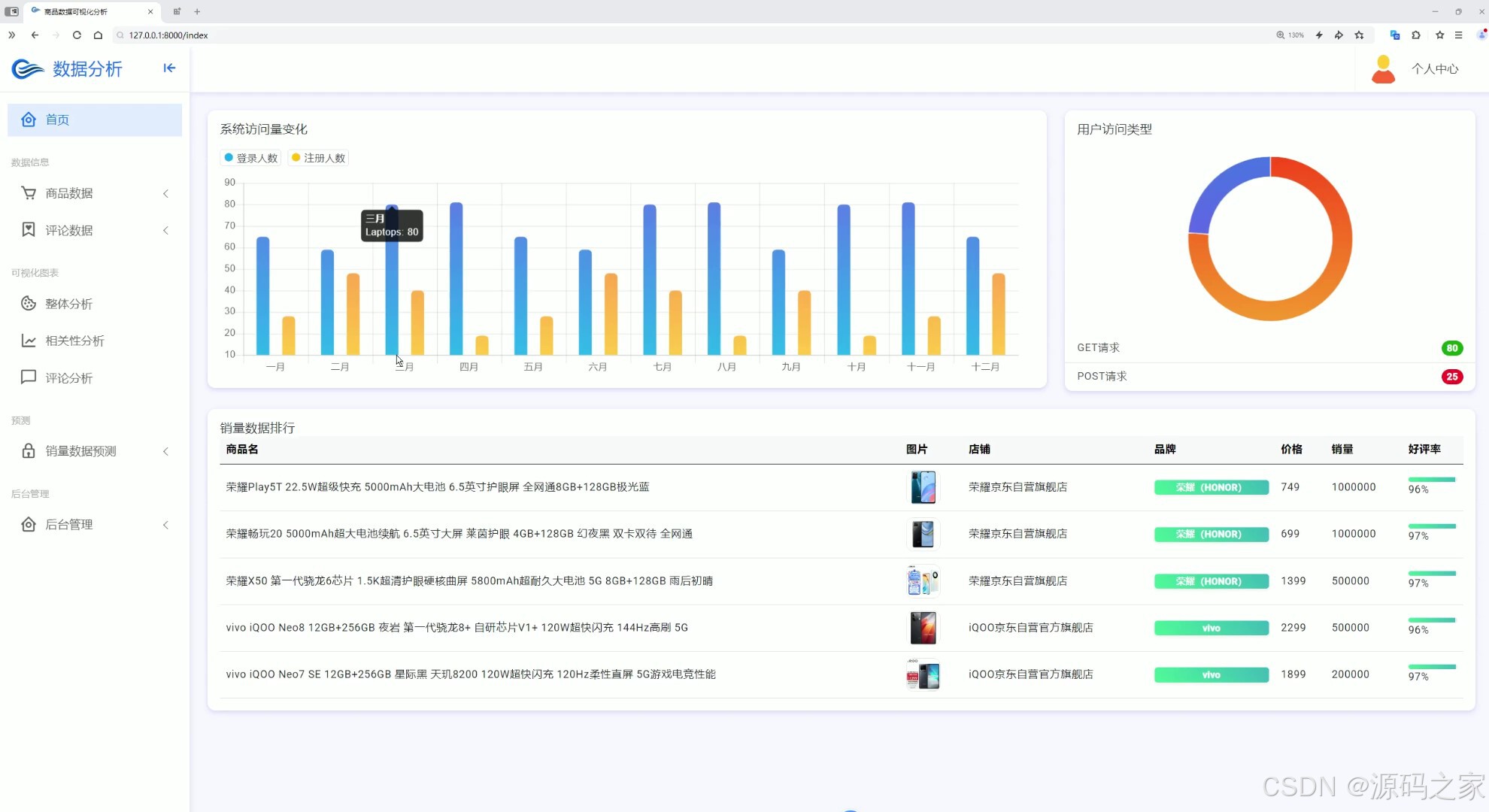
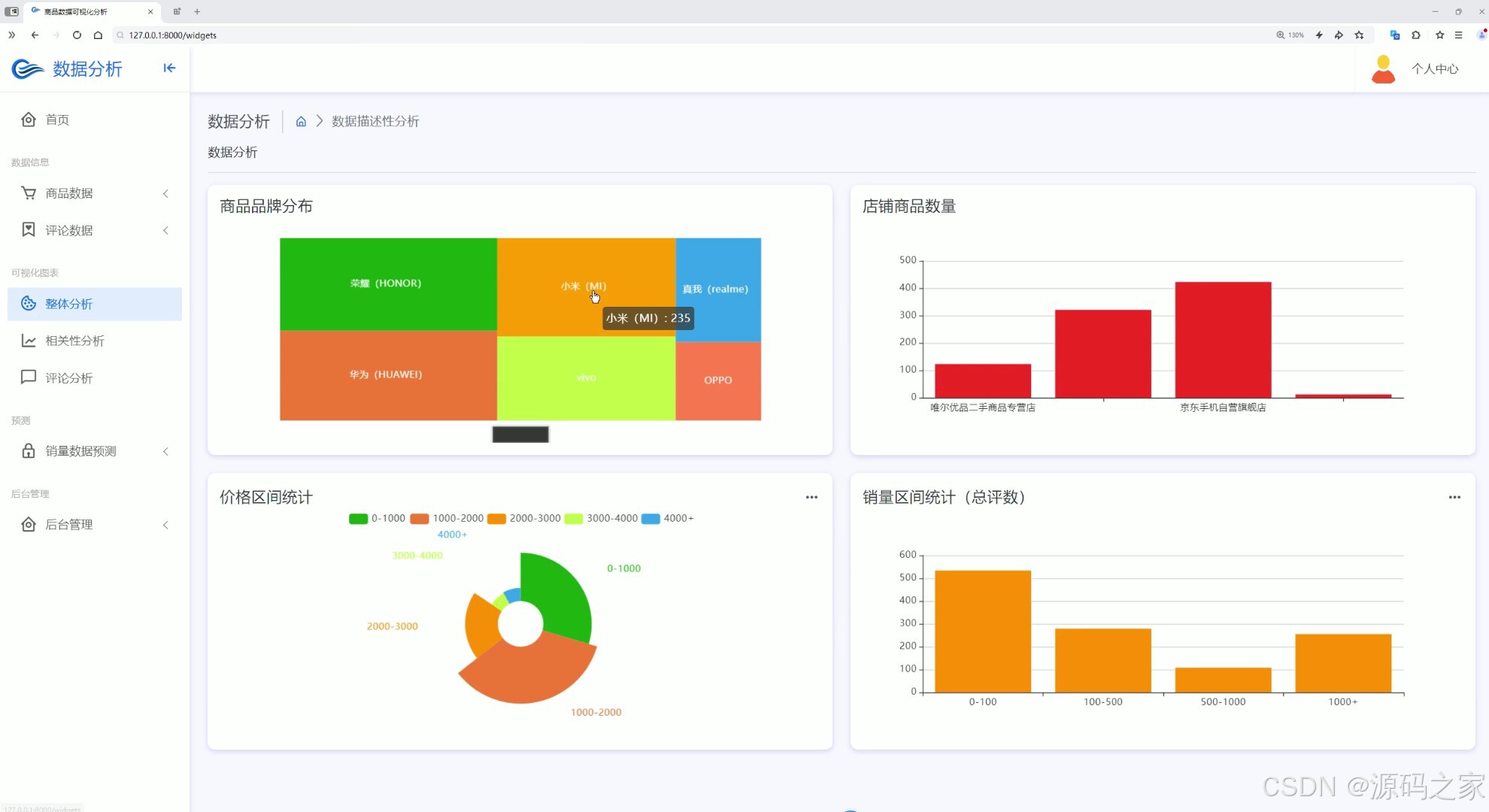
界面功能覆盖全业务场景:首页数据大屏作为核心总览入口,实时展示商品总销量、热门品类占比、用户访问量等关键指标,助力企业快速掌握运营全局;整体分析与两组相关性分析界面,通过 Echarts 图表深挖数据关联(如价格与销量、季节与品类需求的关系),为商品定价与选品提供依据;评论分析与评论列表界面,可提取用户评价中的情感倾向与核心需求(如品质反馈、功能建议),辅助产品优化;数据中心承担数据存储与管理职能,为后续分析预测提供可靠数据基础;商品详情页 + 推荐模块基于用户行为数据实现个性化推荐,提升用户转化;销量预测界面是系统核心,输入相关参数后,随机森林算法可输出未来周期销量预测结果,指导库存备货;注册登录界面通过角色权限管控保障数据安全,后台管理界面则支持数据维护、用户管理与系统配置,确保系统稳定运行。
整体而言,该系统打通了商品数据从采集到应用的闭环,帮助企业摆脱经验决策依赖,以数据驱动提升运营效率与销量转化。
2、项目界面
(1)首页数据大屏
(2)整体分析
(3)相关性分析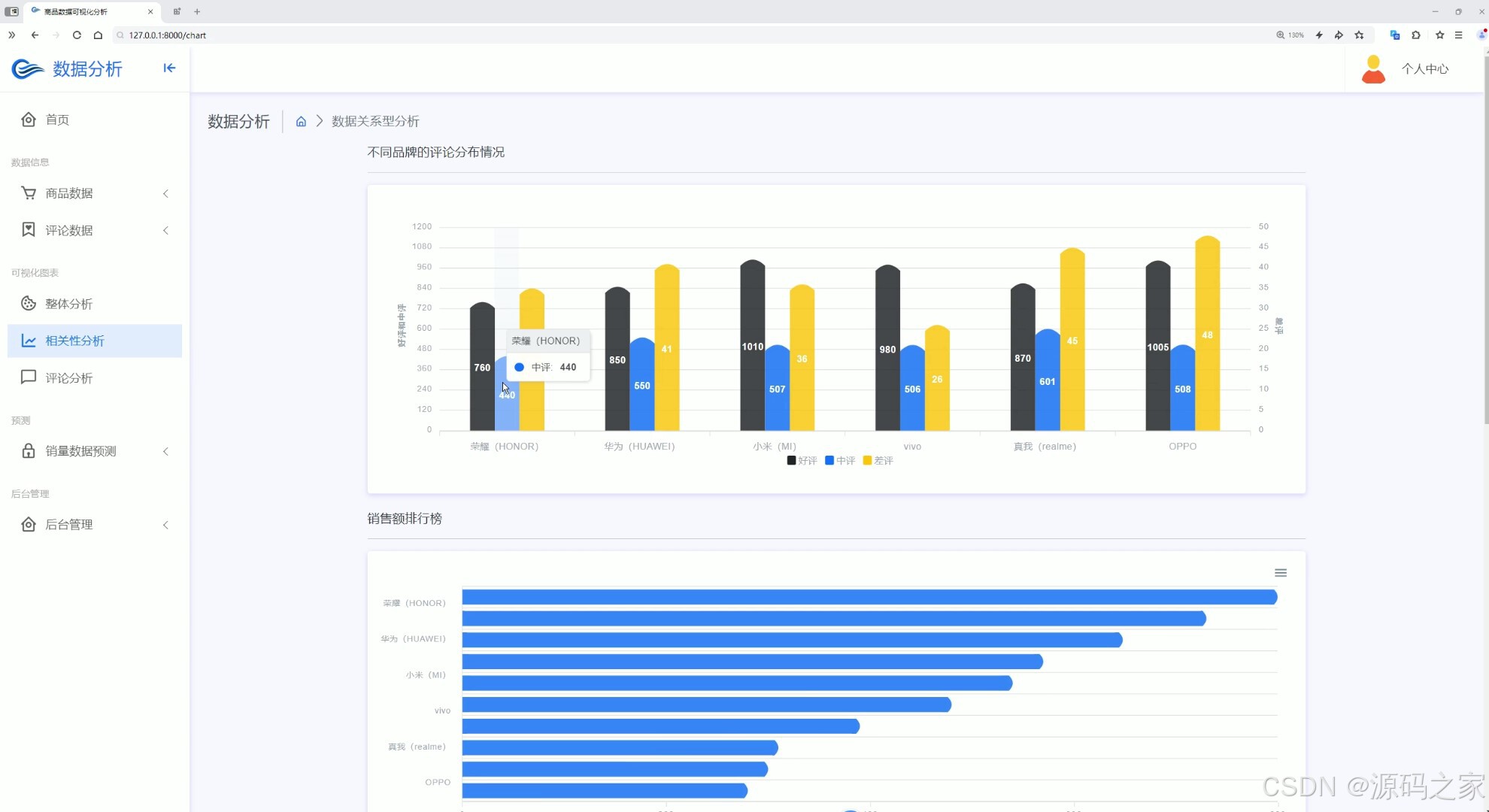
(4)相关性分析2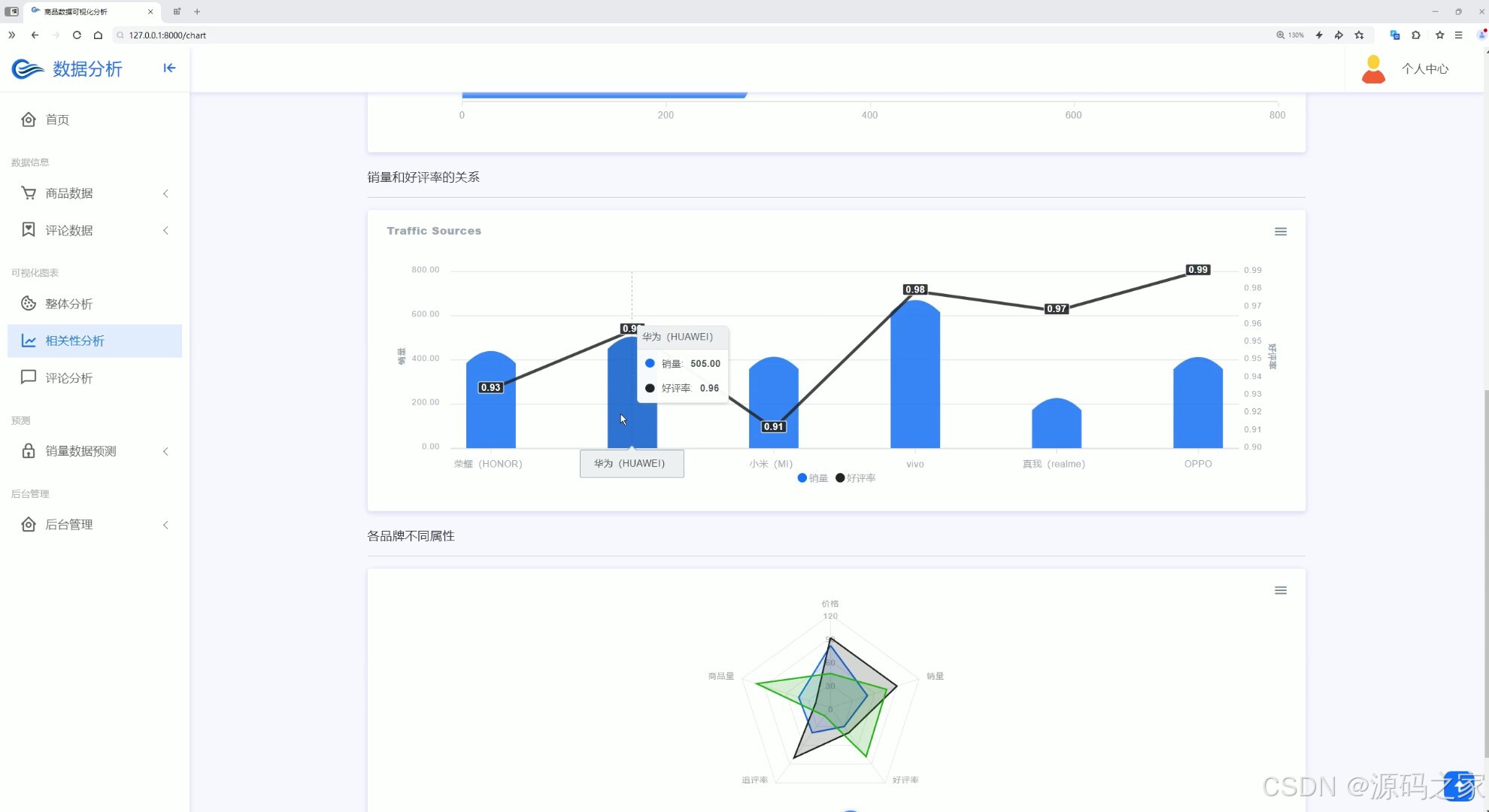
(5)评论分析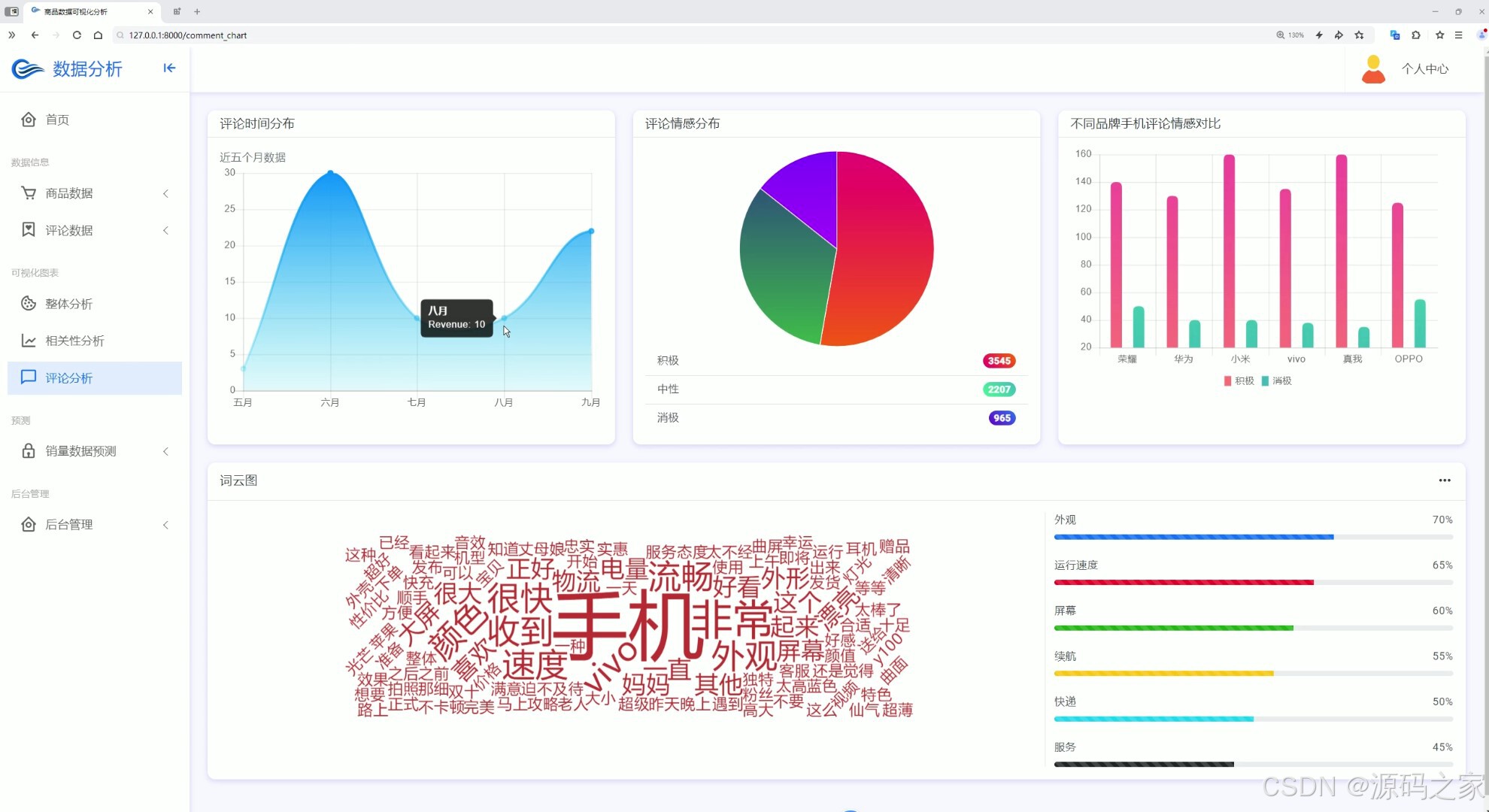
(6)数据中心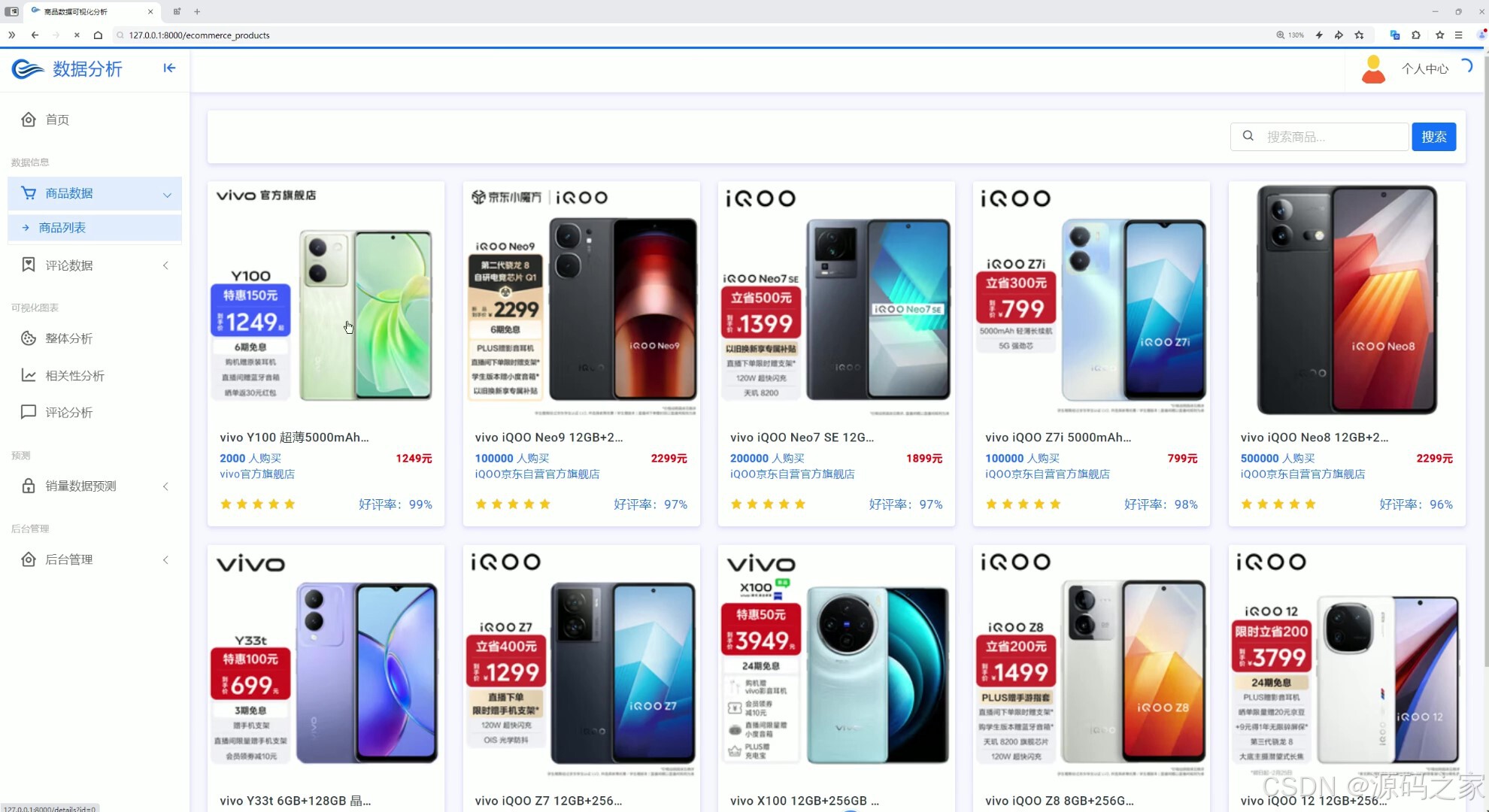
(7)商品详情页+推荐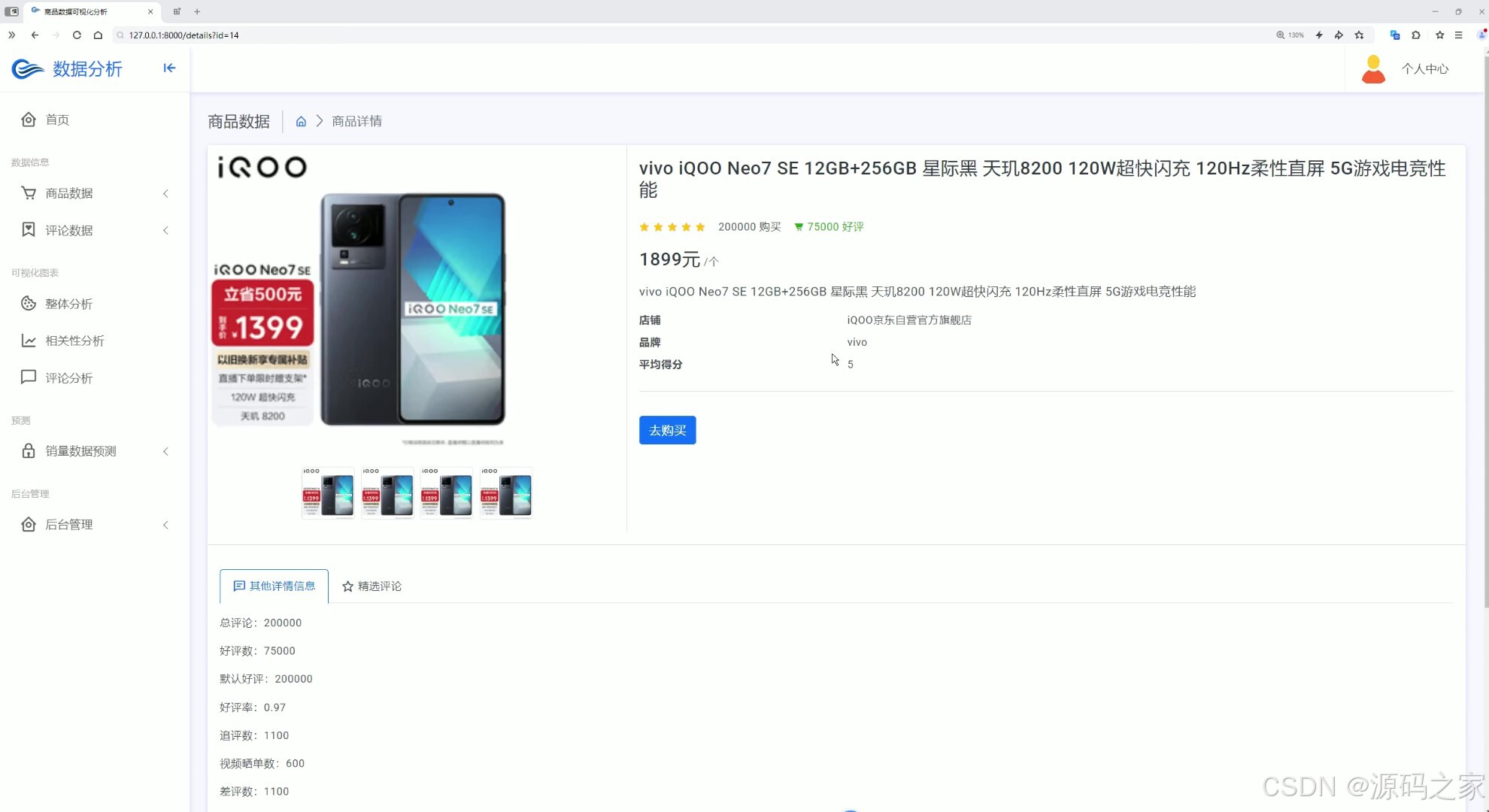
(8)评论列表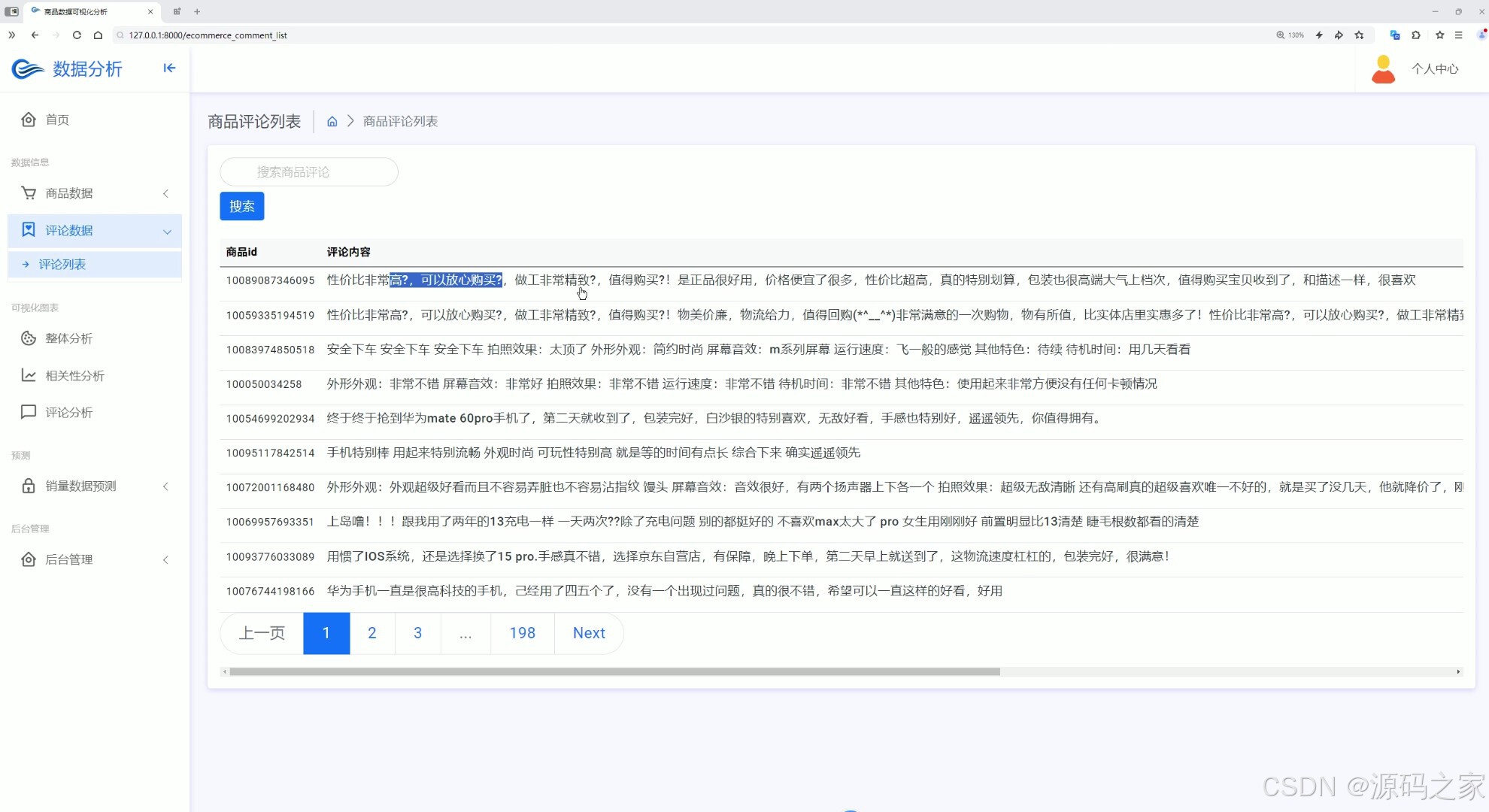
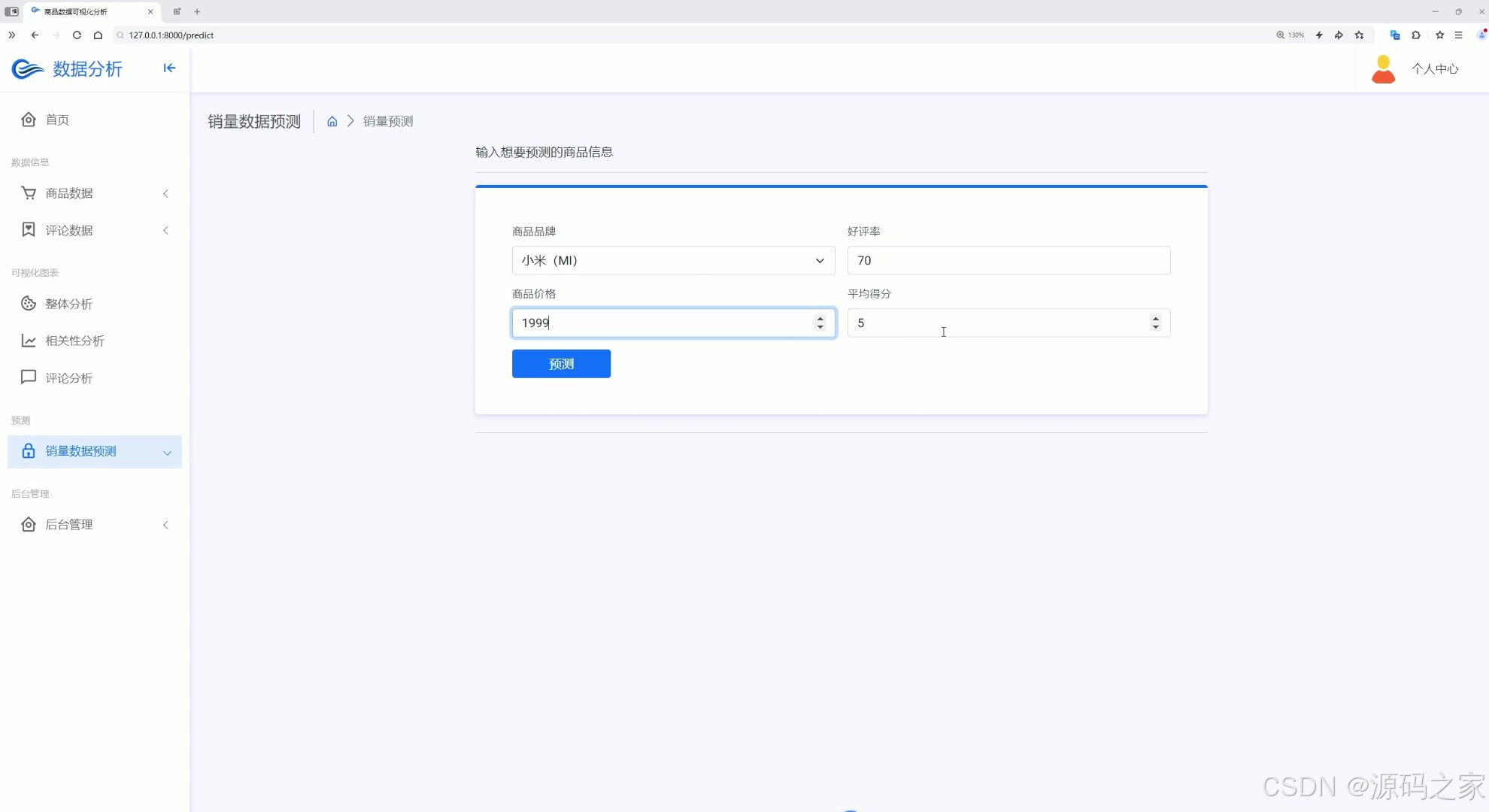
(9)销量预测
(10)注册登录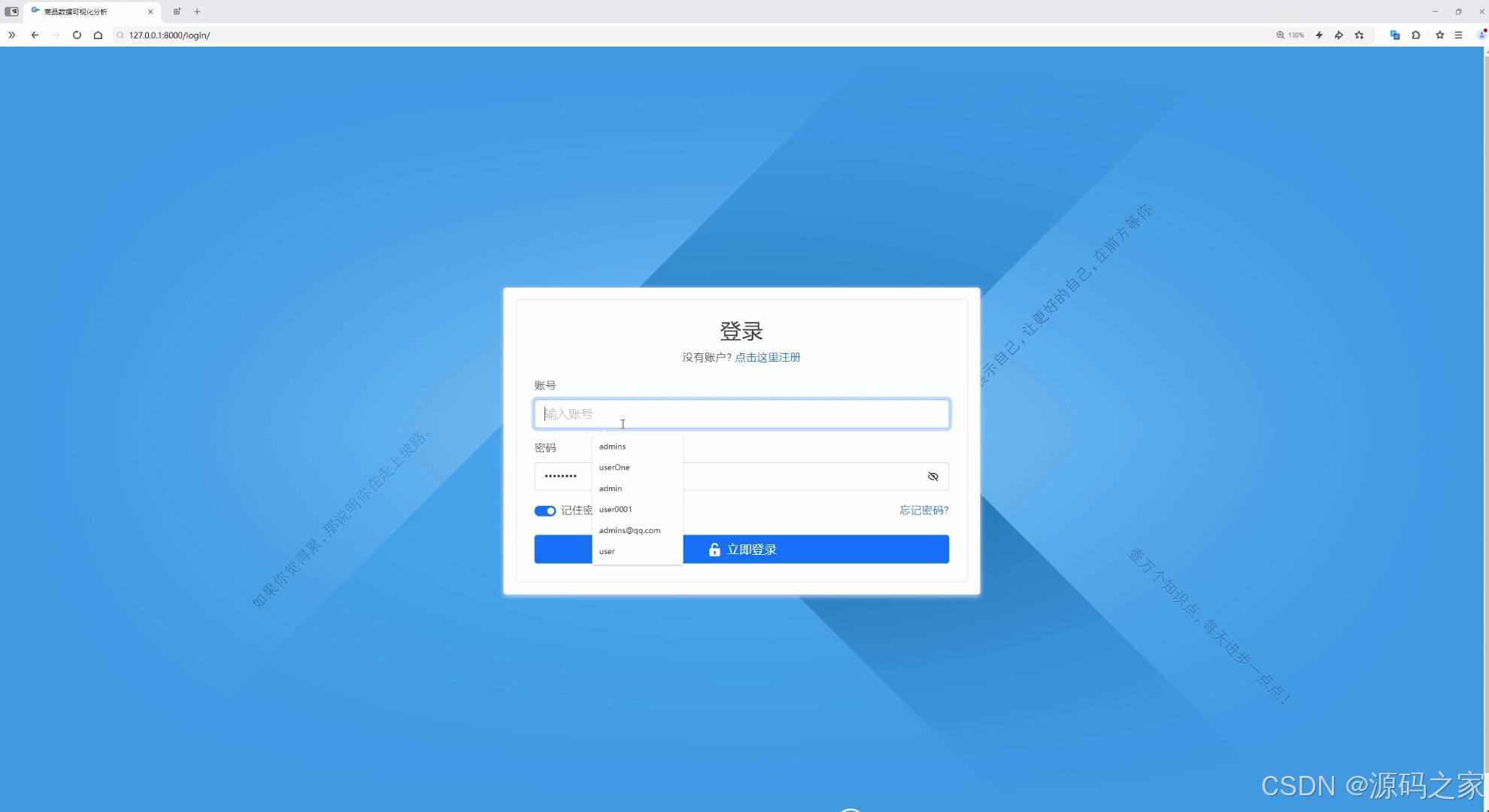
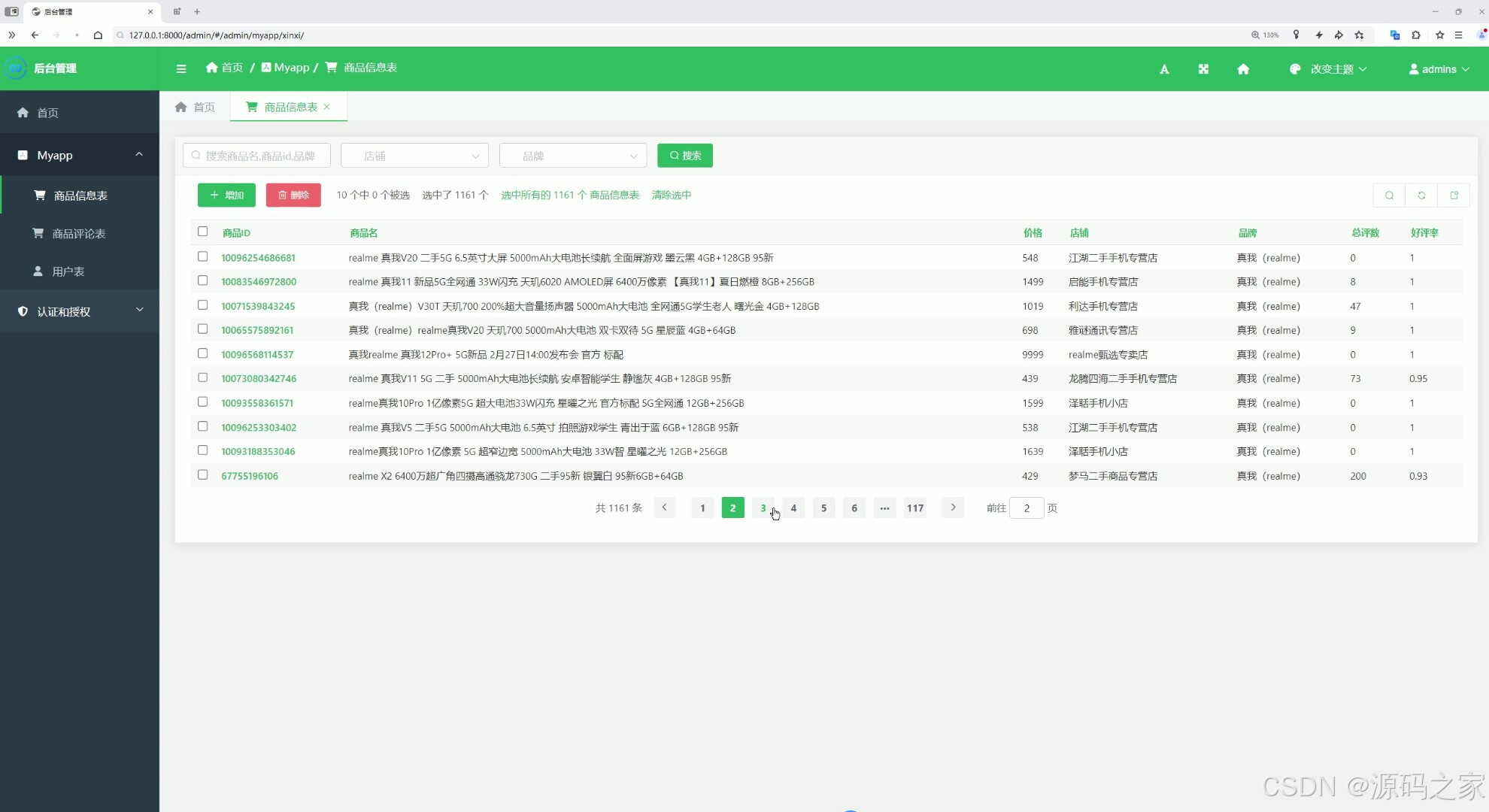
(11)后台管理
3、项目说明
Python 商品数据分析及预测系统介绍
本 Python 商品数据分析及预测系统,以 Python 语言为开发核心,依托 Django 框架搭建稳定后端架构,结合 Echarts 可视化工具与机器学习随机森林预测算法,搭配 HTML 构建前端交互界面,形成 “数据采集 - 分析 - 预测 - 应用” 的全流程商品数据服务体系,为企业精准把握商品运营动态、优化销量策略提供技术支撑。
技术层面,Python 不仅是算法实现与爬虫开发的基础(可爬取商品销量、用户评论、市场竞品等多源数据),还保障数据处理的高效性;Django 框架通过 MVC 模式实现前后端解耦,确保系统高可用性与可扩展性,支撑多界面协同运行;Echarts 则以丰富的图表类型(折线图、热力图、散点图等)将复杂数据可视化,让分析结果更易解读;随机森林算法凭借对多特征的精准拟合能力,结合历史销量、价格波动、促销活动等数据,实现销量的科学预测。
界面功能覆盖全业务场景:首页数据大屏作为核心总览入口,实时展示商品总销量、热门品类占比、用户访问量等关键指标,助力企业快速掌握运营全局;整体分析与两组相关性分析界面,通过 Echarts 图表深挖数据关联(如价格与销量、季节与品类需求的关系),为商品定价与选品提供依据;评论分析与评论列表界面,可提取用户评价中的情感倾向与核心需求(如品质反馈、功能建议),辅助产品优化;数据中心承担数据存储与管理职能,为后续分析预测提供可靠数据基础;商品详情页 + 推荐模块基于用户行为数据实现个性化推荐,提升用户转化;销量预测界面是系统核心,输入相关参数后,随机森林算法可输出未来周期销量预测结果,指导库存备货;注册登录界面通过角色权限管控保障数据安全,后台管理界面则支持数据维护、用户管理与系统配置,确保系统稳定运行。
整体而言,该系统打通了商品数据从采集到应用的闭环,帮助企业摆脱经验决策依赖,以数据驱动提升运营效率与销量转化。
4、核心代码
def products_details(request):
id = request.GET.get('id')
product = get_object_or_404(XinXi, id=id)
product.full_stars = ['bx bxs-star text-warning'] * int(product.AverageScore)
product.empty_stars = ['bx bxs-star text-secondary'] * (5 - int(product.AverageScore))
# 查询同一品牌的其他商品
brand = product.brand
other_products = XinXi.objects.filter(brand=brand).exclude(id=id)[:3]
# 如果不足三个商品,则随机选取
if len(other_products) < 3:
other_products = XinXi.objects.filter(brand=brand).exclude(id=id)
other_products = sample(list(other_products), min(len(other_products), 3))
# 计算评分星星
for product in other_products:
product.full_stars = ['bx bxs-star text-warning'] * int(product.AverageScore)
product.empty_stars = ['bx bxs-star text-secondary'] * (5 - int(product.AverageScore))
comments = Comment.objects.filter(product_id=product.product_id).order_by('-comment_date')[:5]
context = {
'product': product,
'other_products': other_products,
'comments': comments,
}
return render(request, 'ecommerce-products-details.html',context)
def ecommerce_comment_list(request):
query = request.GET.get('search', '')
page_number = request.GET.get('page') # 获取请求中的页码参数
if query:
comments = Comment.objects.filter(content__icontains=query)
else:
comments = Comment.objects.all()
# 创建分页器对象,设置每页显示的数量为 10
paginator = Paginator(comments, 10)
# 获取请求的页码对应的Page对象
page_obj = paginator.get_page(page_number)
context = {
'comments': page_obj,
'page_obj': page_obj,
'query': query, # 添加搜索参数到上下文中
}
return render(request, 'ecommerce_comment_list.html',context)
def widgets(request):
return render(request, 'widgets.html')
def chart(request):
return render(request, 'charts-apex-chart.html')
def preprocess_text(text):
text = re.sub(r'[^\w\s]', '', text)
text = text.lower()
words = jieba.lcut(text)
filtered_words = [word for word in words if len(word) > 1]
return filtered_words
def comment_chart(request):
df = pd.read_csv('spiders/comments.csv')
df = df[['评论']]
all_text = ' '.join(df.values.flatten().astype(str))
words = preprocess_text(all_text)
word_count = Counter(words)
top_50_words = word_count.most_common(200)
result = [{'name': word, 'value': count} for word, count in top_50_words]
context = {
'result': result,
}
return render(request, 'comment_chart.html',context)
from speculate import Speculate
def predict(request):
result = None # 初始化结果为 None
if request.method == 'POST':
brand = request.POST.get('brand')
rating = request.POST.get('rating', 0)
price = request.POST.get('price', 0)
average_score = request.POST.get('average_score', 5) # 获取平均得分
# 使用 Speculate 函数进行预测
# data = [, brand, rating, average_score]
print([])
data = [float(price),brand,float(rating),float(average_score)]
result = Speculate(data)
context = {
'result': result,
}
return render(request, 'predict.html', context)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 54
54 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)