WCA 水循环算法优化 BP 神经网络(WCA - BPNN)回归预测在电厂运行数据中的应用
WCA水循环算法优化BP神经网络(WCA-BPNN)回归预测MATLAB代码(有优化前后的对比)代码注释清楚。main为运行主程序,可以读取本地EXCEL数据。很方便,容易上手。(以电厂运行数据为例)温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。在电力行业中,准确预测电厂运行数据对于优化生产流程、提高能源效率至关重要。
WCA水循环算法优化BP神经网络(WCA-BPNN)回归预测MATLAB代码(有优化前后的对比) 代码注释清楚。 main为运行主程序,可以读取本地EXCEL数据。 很方便,容易上手。 (以电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。

在电力行业中,准确预测电厂运行数据对于优化生产流程、提高能源效率至关重要。今天咱们就来探讨一下如何使用 WCA 水循环算法优化 BP 神经网络(WCA - BPNN)进行回归预测,并且通过 MATLAB 代码实现,还会给出优化前后的对比哦。
1. 整体思路
BP 神经网络(Back Propagation Neural Network)是一种广泛应用的神经网络模型,然而其自身存在容易陷入局部最优解的问题。而 WCA 水循环算法具有较强的全局搜索能力,将二者结合,可以有效提高预测的准确性和稳定性。
2. MATLAB 主程序代码实现
读取数据部分
% 从本地 EXCEL 读取电厂运行数据
data = xlsread('power_plant_data.xlsx');
% xlsread 函数用于读取 EXCEL 文件,这里假设文件名为 power_plant_data.xlsx
% 读取的数据存储在 data 变量中,这个数据文件应该包含了电厂运行相关的各种特征值以及对应的目标值
% 划分输入和输出数据
input_data = data(:, 1:end - 1);
% 取 data 数据的除最后一列之外的所有列作为输入数据,这里假设最后一列是目标输出值
output_data = data(:, end);
% 取 data 数据的最后一列作为输出数据BP 神经网络部分(未优化)
% 创建 BP 神经网络
net = newff(input_data, output_data, [10, 10]);
% newff 函数用于创建一个前馈神经网络,这里设置了两个隐藏层,每个隐藏层有 10 个神经元
% 输入数据是 input_data,目标输出数据是 output_data
% 设置训练参数
net.trainParam.epochs = 1000;
% 设置训练的最大代数为 1000 代,即神经网络在训练过程中最多进行 1000 次迭代
net.trainParam.lr = 0.01;
% 设置学习率为 0.01,学习率控制每次权重更新的步长大小
% 训练神经网络
[net, tr] = train(net, input_data, output_data);
% train 函数用于训练神经网络,返回训练好的网络 net 和训练记录 trWCA 优化 BP 神经网络部分
% 定义适应度函数,这里就是以 BP 神经网络预测误差作为适应度
fitness = @(x) wca_bp_fitness(x, input_data, output_data);
% wca_bp_fitness 是自定义的函数,用于计算适应度,x 是 WCA 算法中的个体编码
% 这里将 BP 神经网络的预测误差作为适应度值,误差越小,适应度越高
% 设置 WCA 算法参数
pop_size = 50;
% 设置种群大小为 50,即 WCA 算法中有 50 个个体参与搜索
max_iter = 200;
% 设置最大迭代次数为 200 次,算法在达到这个迭代次数后停止搜索
% 运行 WCA 算法优化 BP 神经网络权重
[best_x, best_fitness] = wca_algorithm(pop_size, max_iter, fitness);
% wca_algorithm 是自定义的水循环算法函数,输入种群大小、最大迭代次数和适应度函数
% 返回最优个体编码 best_x 和最优适应度值 best_fitness
% 使用优化后的权重更新 BP 神经网络
net = update_bp_weights(net, best_x);
% update_bp_weights 是自定义函数,将 WCA 算法得到的最优权重应用到 BP 神经网络中预测与对比部分
% 未优化 BP 神经网络预测
prediction_bp = sim(net, input_data);
% sim 函数用于使用训练好的 BP 神经网络进行预测,得到未优化时的预测结果
% WCA - BPNN 预测
net_optimized = update_bp_weights(newff(input_data, output_data, [10, 10]), best_x);
% 创建新的 BP 神经网络并应用优化后的权重
prediction_wca_bp = sim(net_optimized, input_data);
% 得到优化后的预测结果
% 计算误差
mse_bp = mse(prediction_bp - output_data);
% 计算未优化 BP 神经网络预测结果与实际输出数据的均方误差(MSE)
mse_wca_bp = mse(prediction_wca_bp - output_data);
% 计算 WCA - BPNN 预测结果与实际输出数据的均方误差(MSE)
% 显示对比结果
fprintf('未优化 BP 神经网络均方误差: %.6f\n', mse_bp);
% 格式化输出未优化 BP 神经网络的均方误差,保留 6 位小数
fprintf('WCA - BPNN 均方误差: %.6f\n', mse_wca_bp);
% 格式化输出 WCA - BPNN 的均方误差,保留 6 位小数3. 代码分析
数据读取部分
xlsread 函数简洁高效地读取了本地 EXCEL 文件中的数据。将数据划分为输入和输出,为后续神经网络的训练和预测奠定基础。这部分代码很直观,就是按照数据文件的结构,合理地提取特征和目标值。
BP 神经网络部分(未优化)
创建 BP 神经网络时,newff 函数定义了网络结构,这里设置的两个隐藏层及每个隐藏层的神经元数量是根据经验和尝试来定的,不同的设置可能会影响预测效果。训练参数的设置,比如训练代数 epochs 和学习率 lr 也很关键。训练代数决定了神经网络在训练过程中的迭代次数,如果设置过小,网络可能训练不充分;设置过大,可能会导致过拟合。学习率则控制每次权重更新的幅度,太大可能会错过最优解,太小则会使训练过程过于缓慢。
WCA 优化 BP 神经网络部分
适应度函数 fitness 将 BP 神经网络的预测误差作为衡量标准,这是整个优化过程的核心。WCA 算法以寻找最小化这个误差为目标进行搜索。种群大小 popsize 和最大迭代次数 maxiter 的设置也需要权衡。种群越大,搜索的范围越广,但计算量也会增加;迭代次数越多,越有可能找到全局最优解,但同样会消耗更多时间。
预测与对比部分
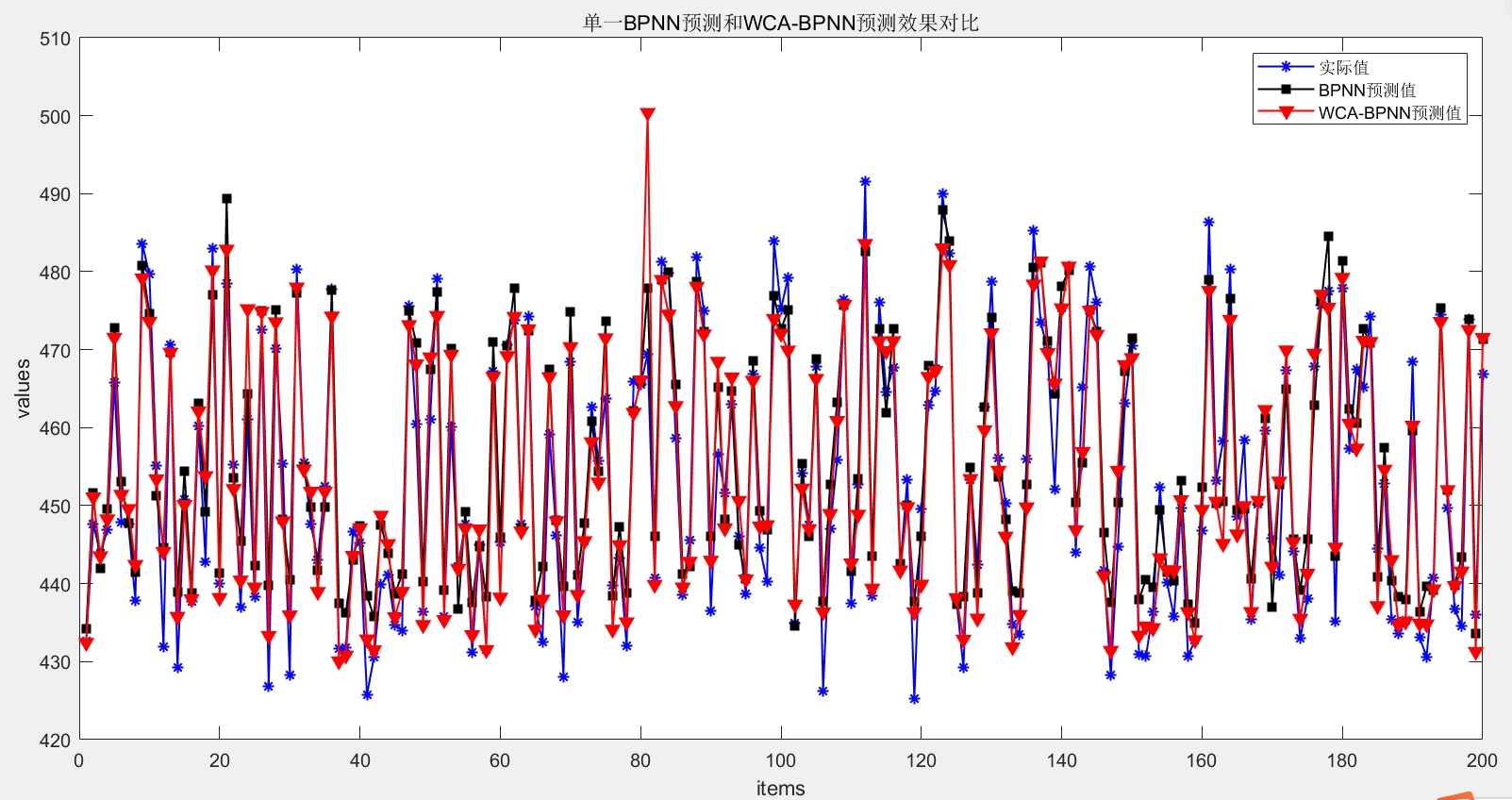
使用 sim 函数对未优化和优化后的 BP 神经网络分别进行预测,并通过计算均方误差 mse 来直观对比二者的预测精度。通过这种对比,能够清晰地看到 WCA 算法对 BP 神经网络的优化效果。
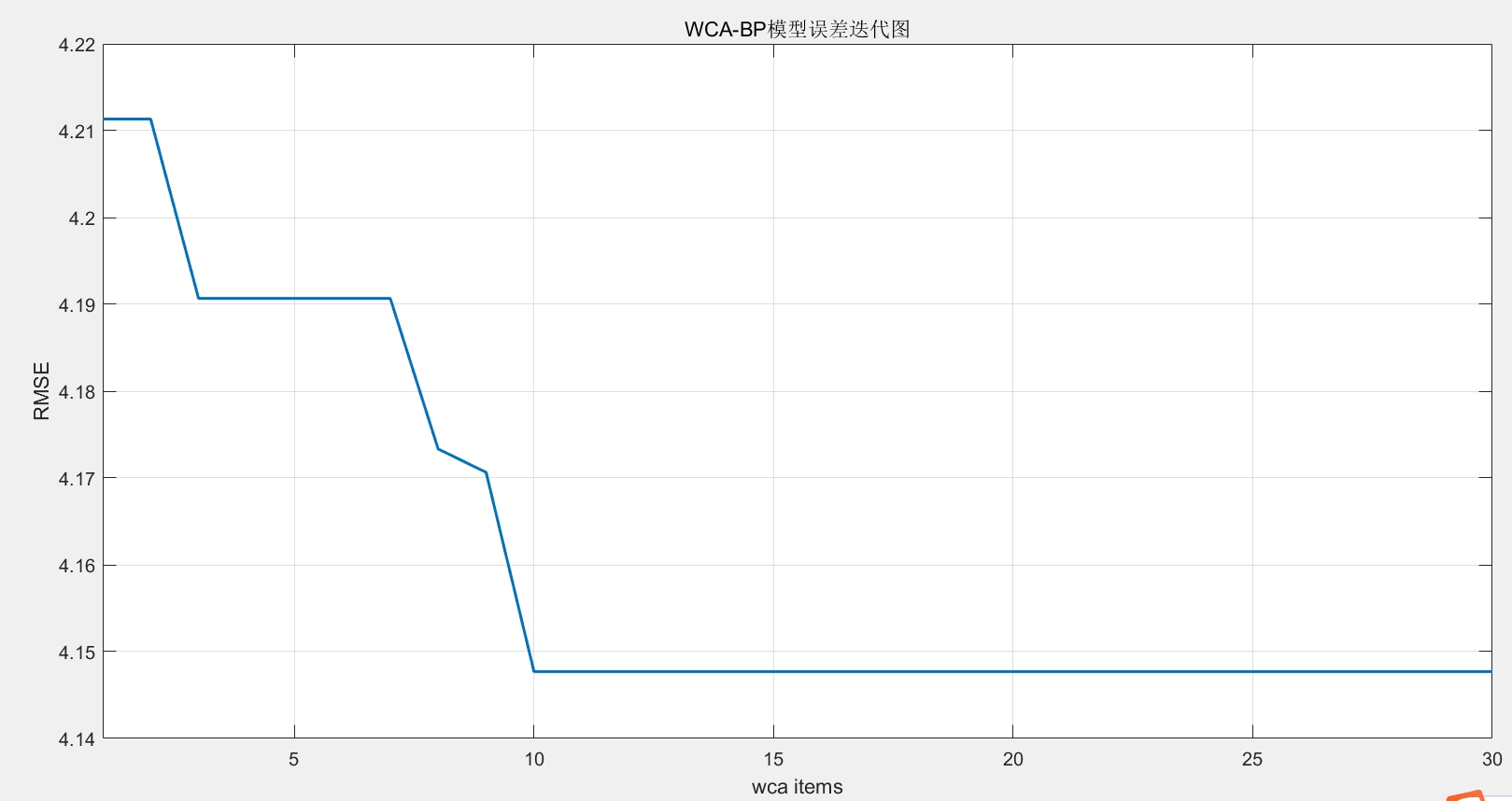
温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。希望大家在使用代码的过程中能够有所收获,通过 WCA - BPNN 模型更好地对电厂运行数据进行回归预测,为实际生产提供有价值的参考。
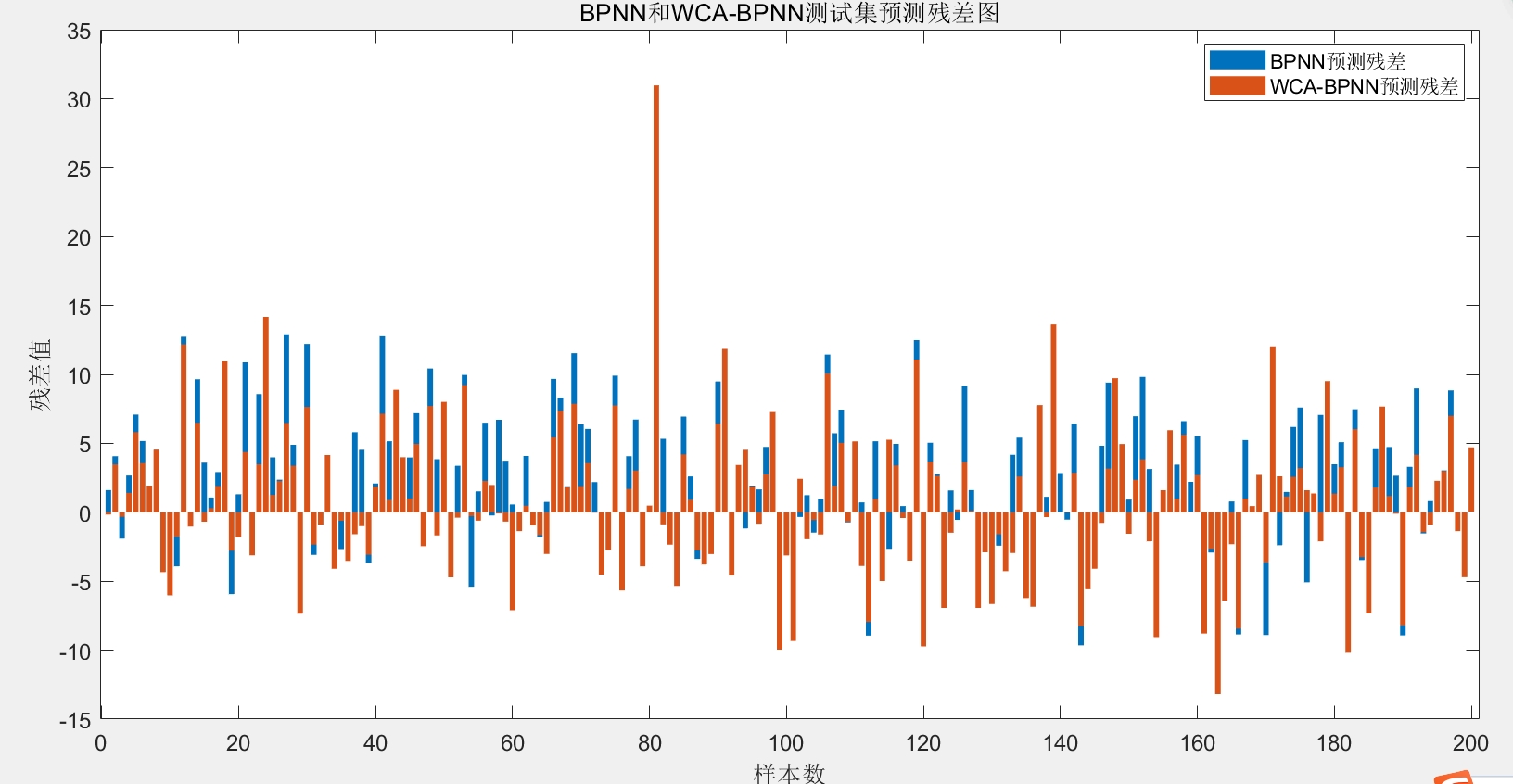
以上代码中的自定义函数 wcabpfitness、wcaalgorithm 和 updatebp_weights 需要根据具体的算法实现细节来编写,这里重点展示了整体的流程和主要部分的代码及分析。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)