AI大模型:Python新能源汽车数据分析与个性化推荐系统 大数据毕业设计 情感分析 舆情分析 Python+Django+snowNLP+协同过滤+requests✅
AI大模型:Python新能源汽车数据分析与个性化推荐系统 大数据毕业设计 情感分析 舆情分析 Python+Django+snowNLP+协同过滤+requests✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
python语言、Django框架、snowNLP情感分析 基于矩阵分解的协同过滤推荐系统 requests爬虫
二、推荐 (model/index.py)
基于矩阵分解的协同过滤推荐系统。
它从数据库和CSV文件中获取用户对汽车的评分数据,构建用户-物品评分矩阵,然后通过矩阵分解模型(MF)进行训练,预测用户对未评分物品的评分,并为指定用户生成推荐列表。
代码首先通过 getAllCars 函数从数据库和CSV文件中提取用户评分数据,将用户ID、汽车ID和评分整合成一个列表。然后,getUIMat 函数根据这些数据构建用户-物品评分矩阵(UI_matrix),矩阵中的值表示用户对汽车的评分。
接下来,定义了一个矩阵分解类 MF,它通过随机梯度下降(SGD)优化算法训练模型,学习用户和物品的潜在特征向量,并计算评分预测值。训练完成后,full_matrix 方法生成完整的评分预测矩阵。modelFn 函数是整个推荐系统的入口,它调用上述函数和类,为指定用户(如用户ID为3)生成推荐列表。推荐列表是根据用户评分预测值从高到低排序的汽车ID列表,用于推荐用户可能感兴趣的汽车。
最后,代码在主函数中调用 modelFn,输出用户ID为3的推荐结果。
项目介绍
- 数据采集与预处理模块:基于requests爬虫获取汽车评分、价格、性能参数、舆情等多维度数据,整合数据库与CSV文件中的用户-汽车评分数据,完成数据清洗与格式规整,为后续分析和推荐提供数据支撑。
- 协同过滤推荐模块:构建基于矩阵分解的协同过滤推荐系统,通过构建用户-物品评分矩阵,结合随机梯度下降优化的矩阵分解模型(MF)训练潜在特征向量,预测用户对未评分汽车的喜好度,生成个性化车型推荐列表并展示在车型详情页。
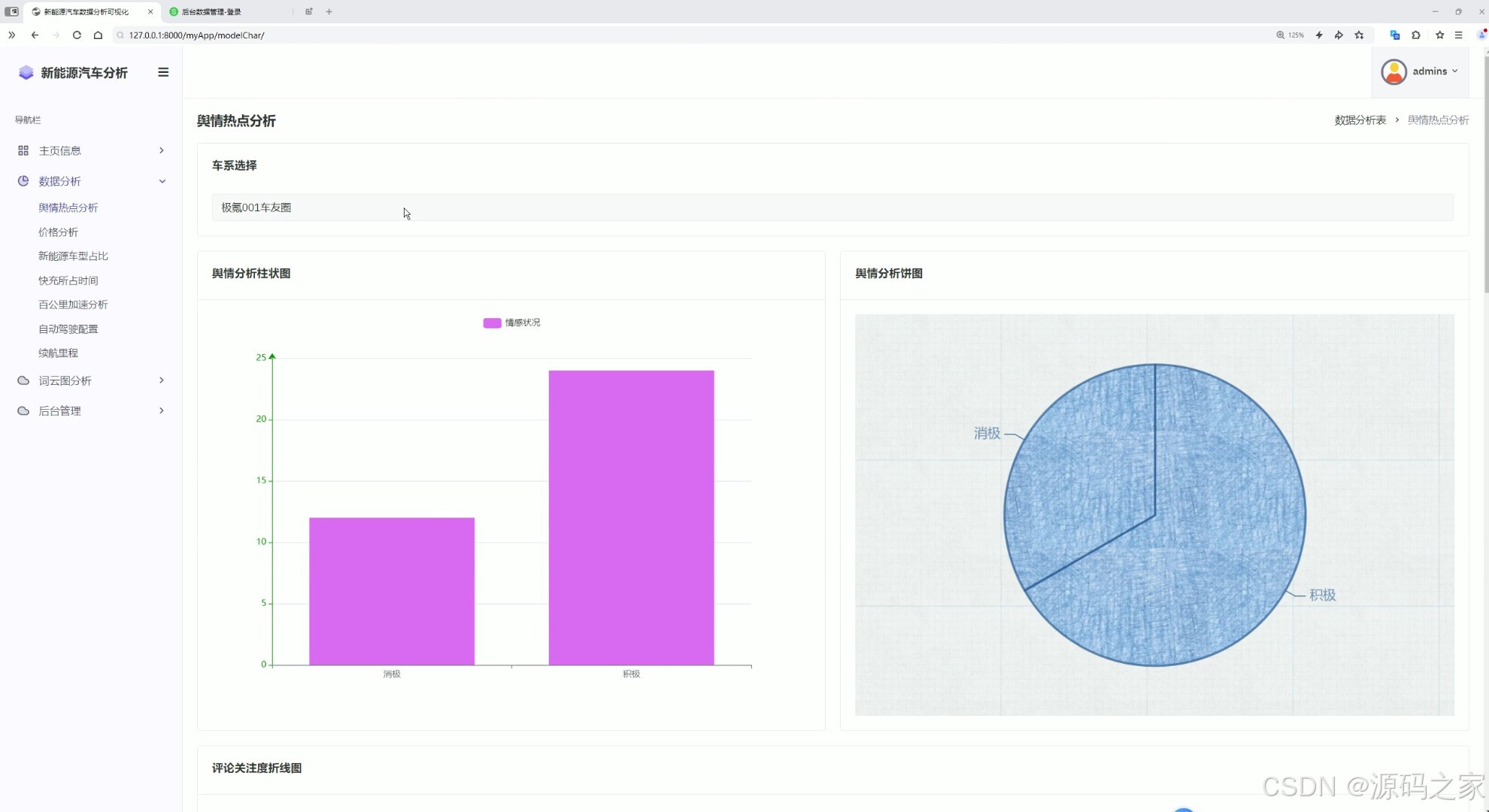
- 情感与舆情分析模块:借助snowNLP完成汽车舆情热点的情感分析,挖掘用户对不同车型、品牌的态度倾向,以可视化形式呈现舆情热点分布,辅助把握市场口碑趋势。
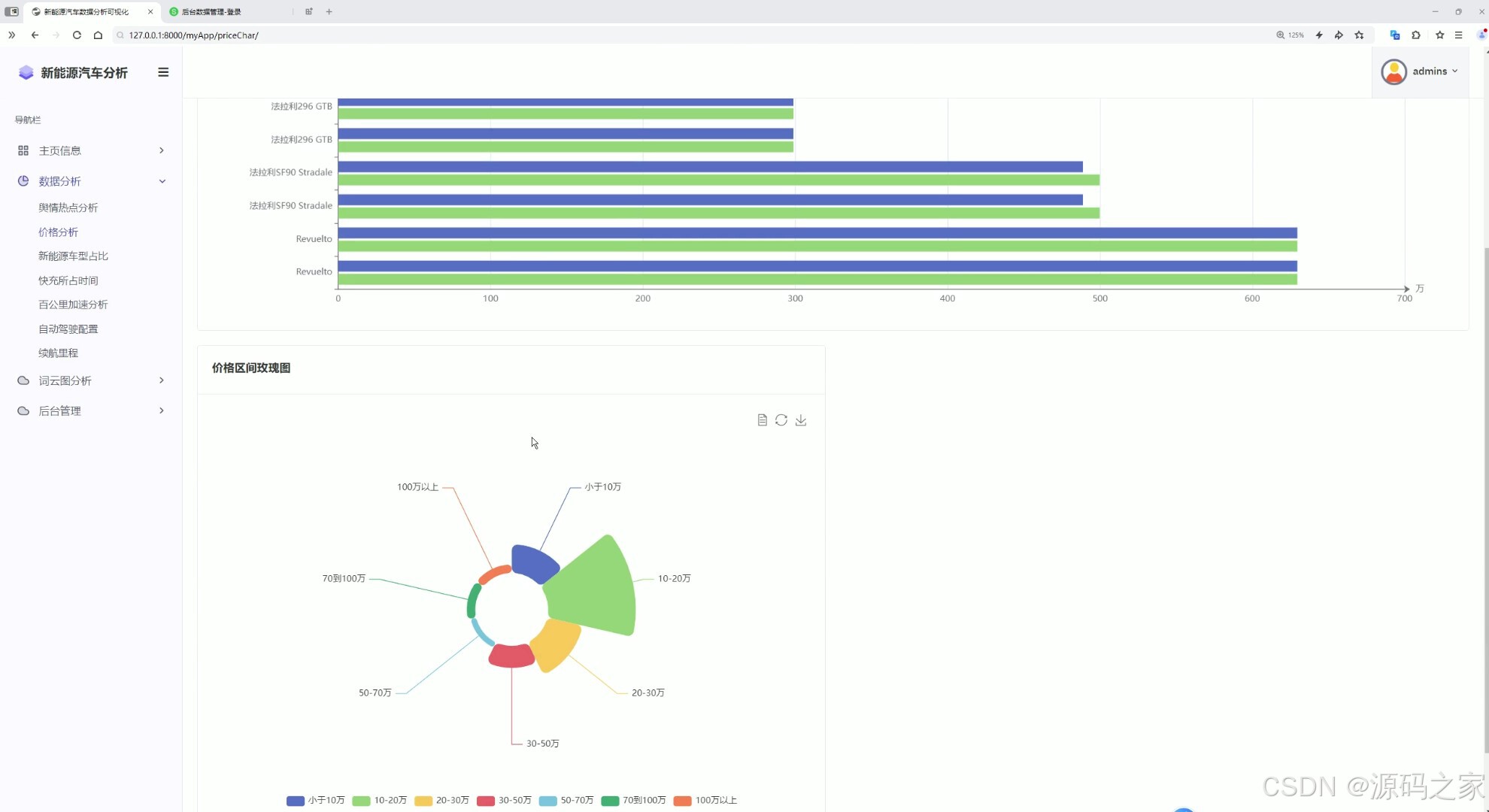
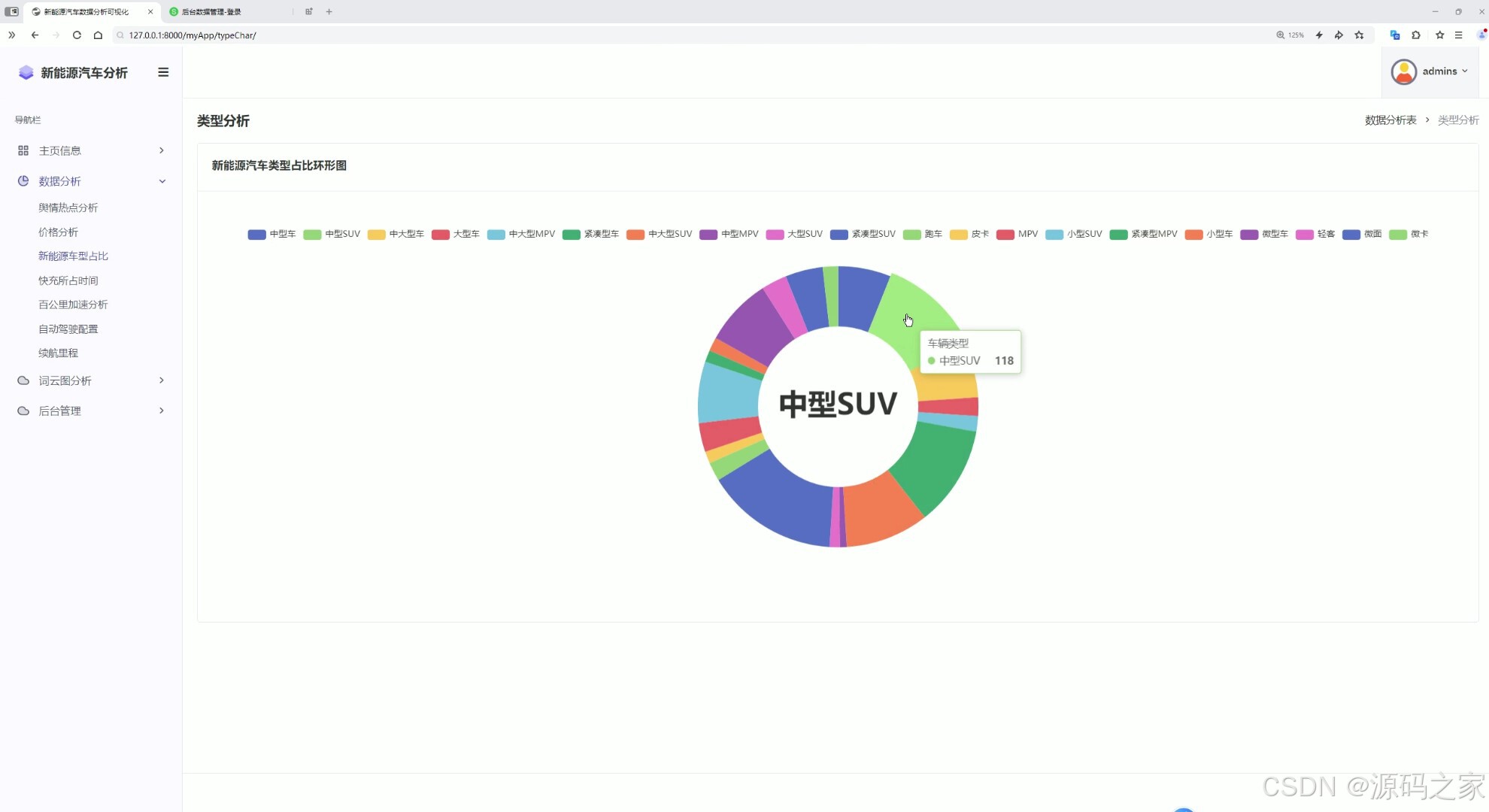
- 多维度数据分析模块:涵盖价格分析、车型占比、百公里加速性能分析等维度,通过数据统计面板、表格、词云图等形式直观展示分析结果,清晰呈现汽车市场各类特征规律。
- 系统管控模块:设计注册登录与后台管理功能,依托Django框架实现用户权限管控、数据增删改查等操作,保障系统数据安全与运维便捷性。
2、项目界面
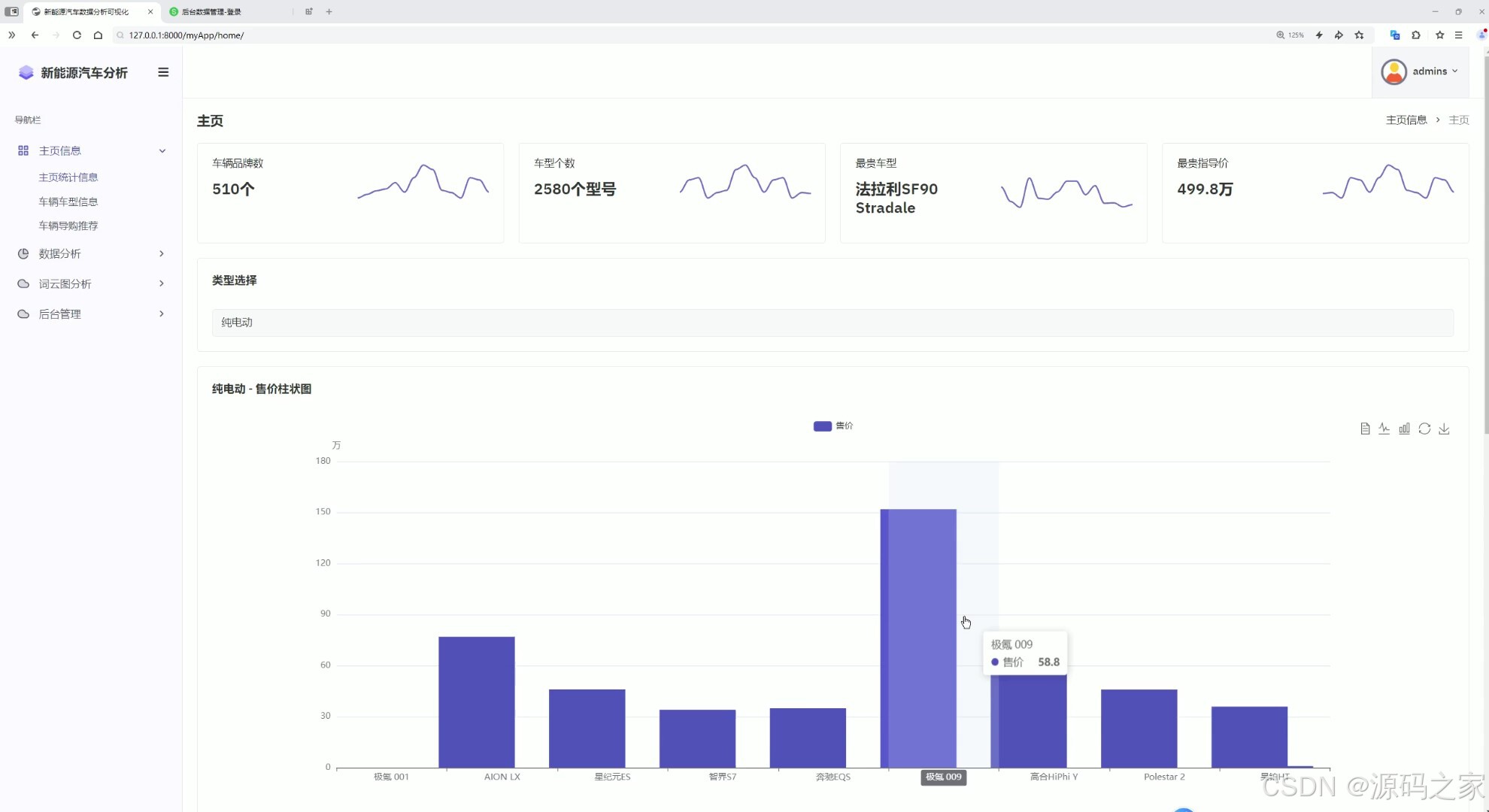
1数据统计面板
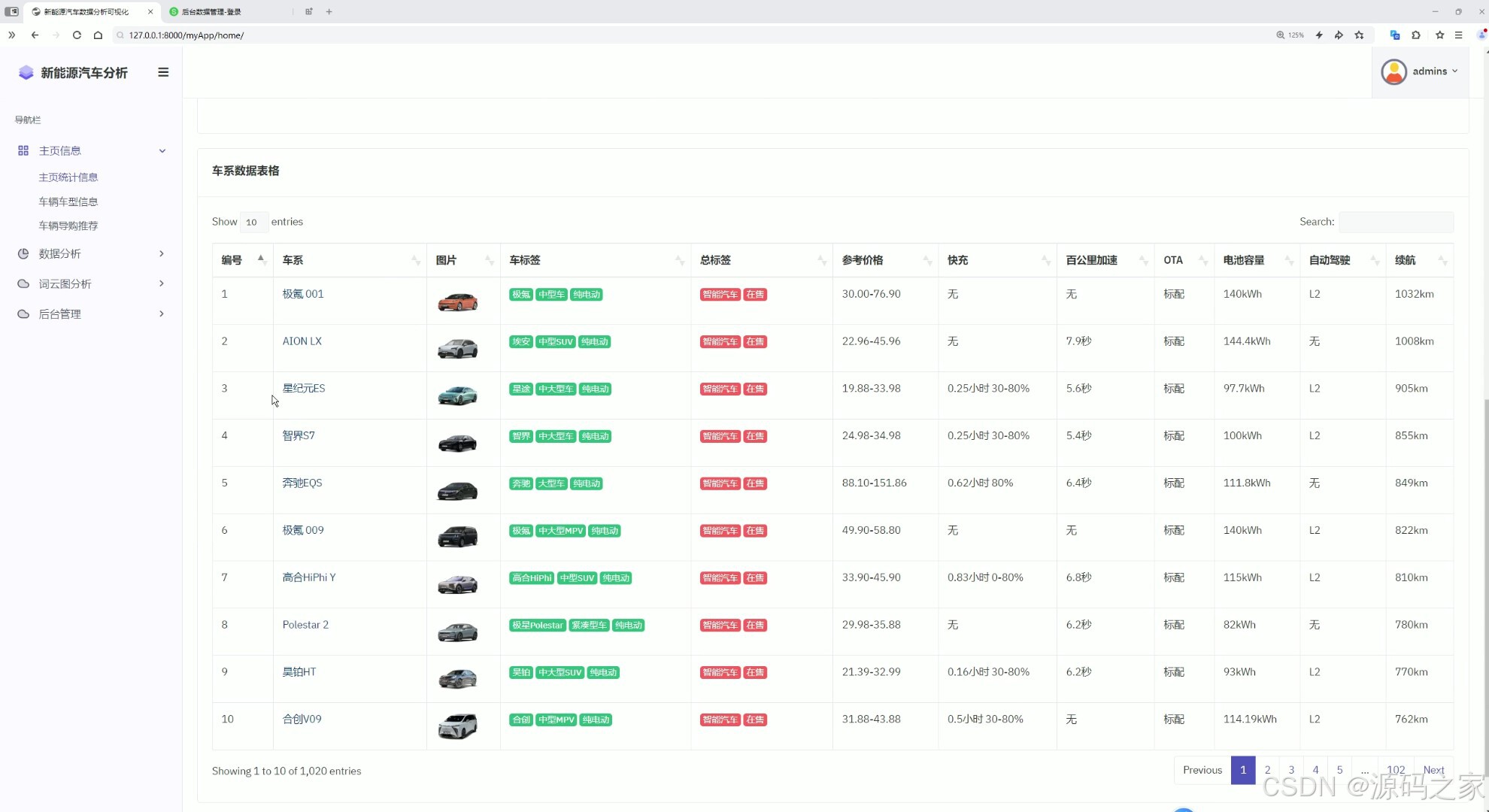
2数据表格
3车型详细页 车辆推荐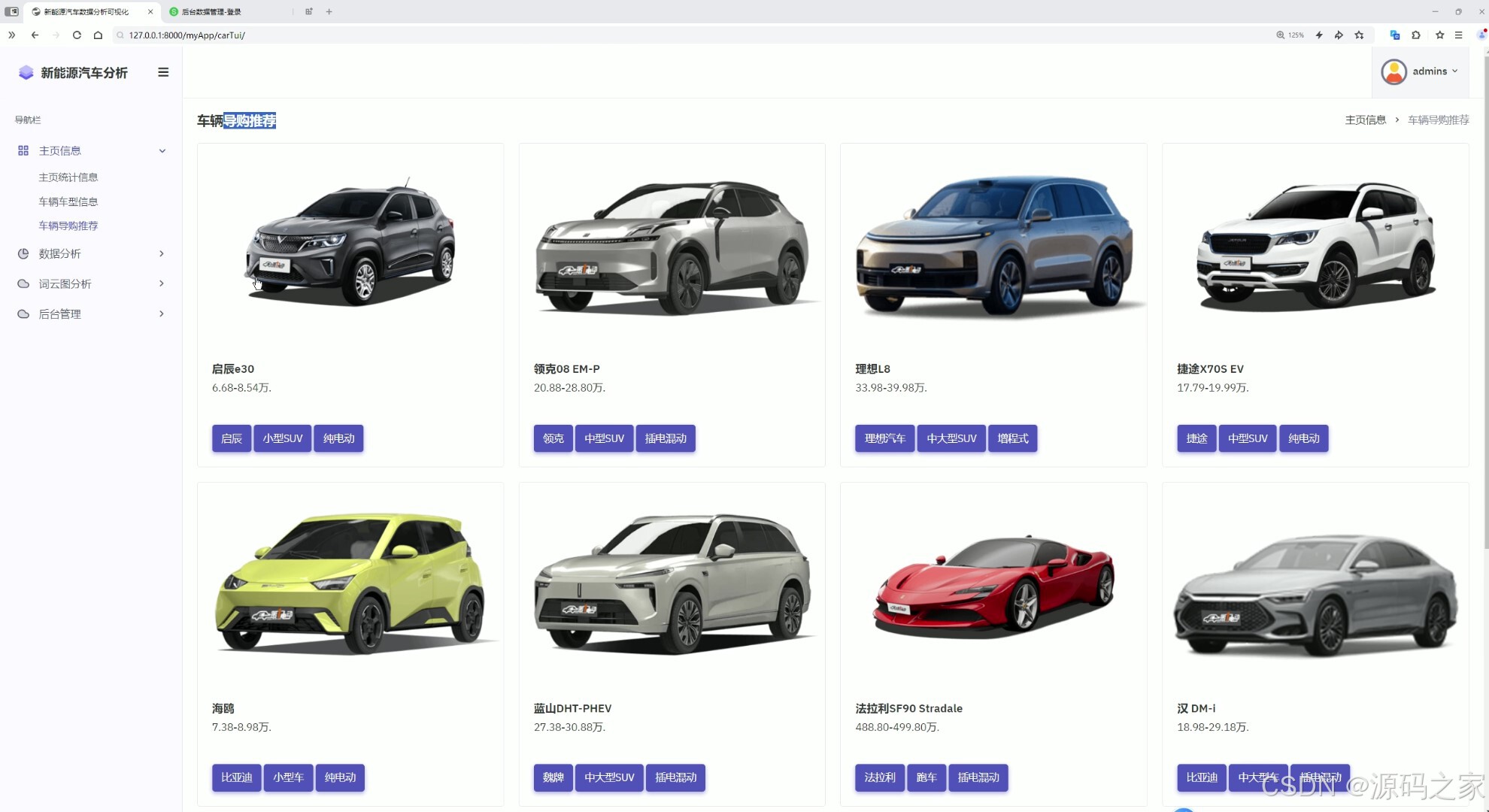
4 数据分析
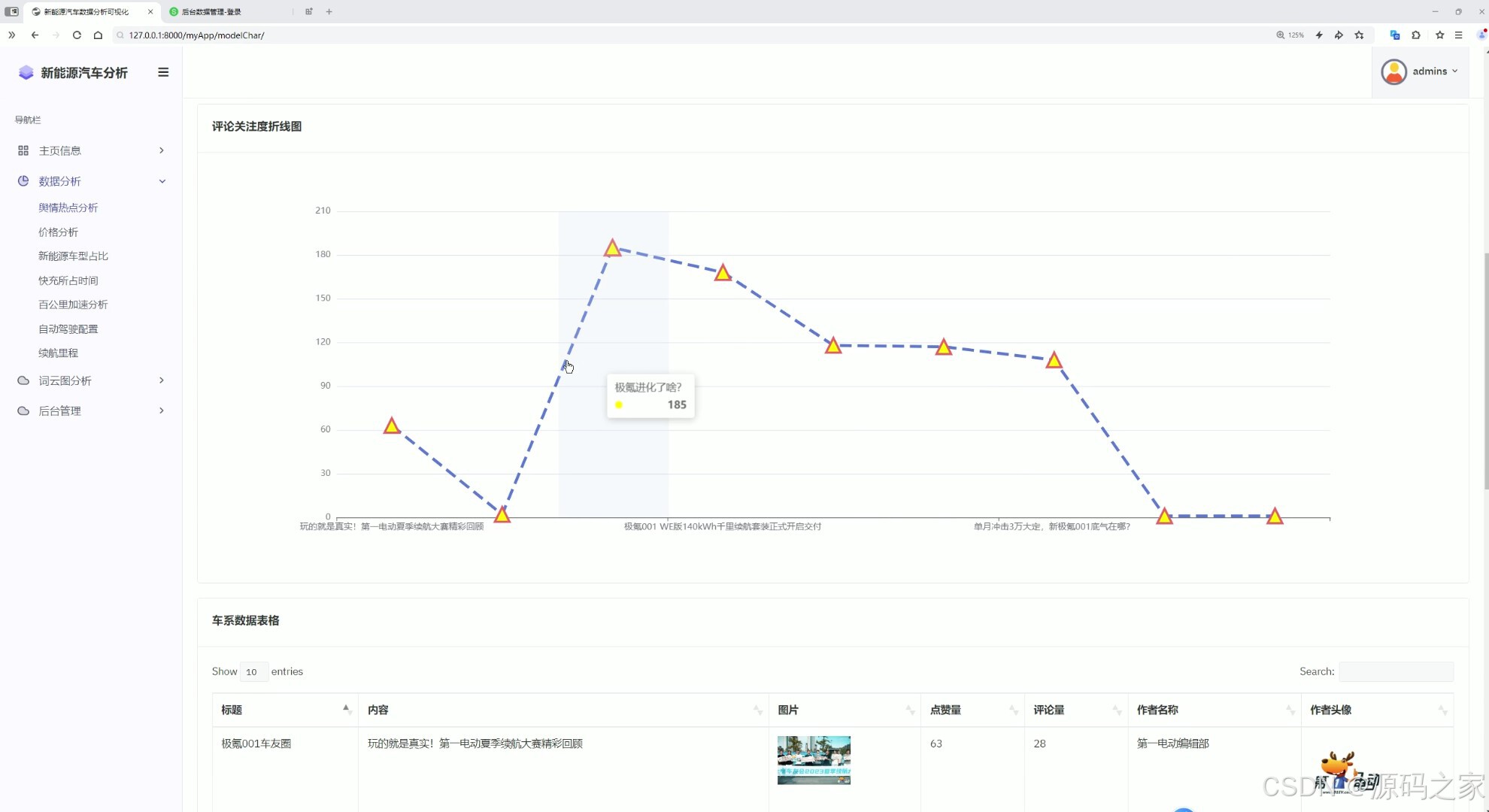
6舆情热点分析
7价格分析
8车型占比
10百公里加速分析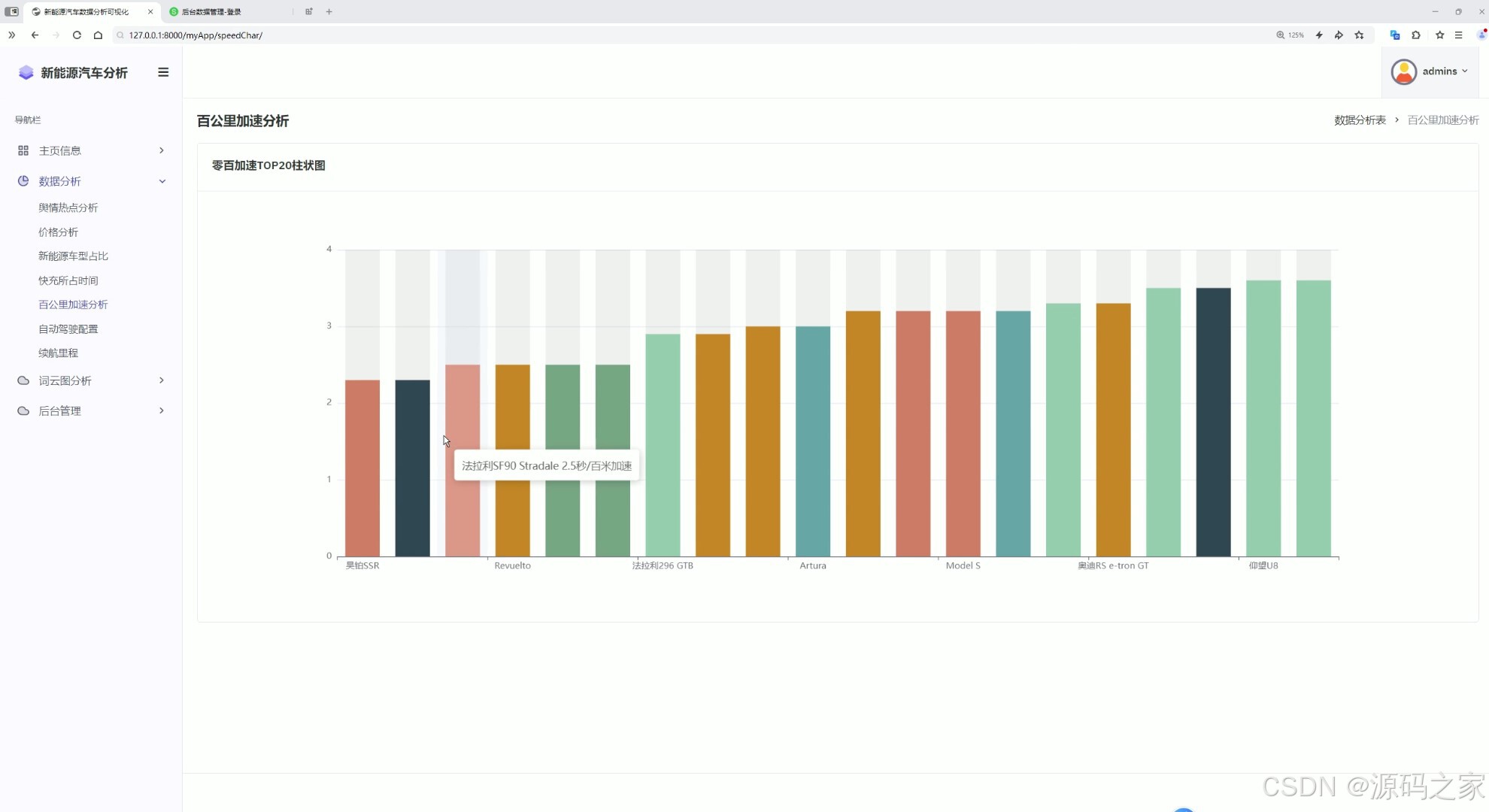
13车系词云图

14 注册登录

15 后台管理
3、项目说明
项目介绍
- 数据采集与预处理模块:基于requests爬虫获取汽车评分、价格、性能参数、舆情等多维度数据,整合数据库与CSV文件中的用户-汽车评分数据,完成数据清洗与格式规整,为后续分析和推荐提供数据支撑。
- 协同过滤推荐模块:构建基于矩阵分解的协同过滤推荐系统,通过构建用户-物品评分矩阵,结合随机梯度下降优化的矩阵分解模型(MF)训练潜在特征向量,预测用户对未评分汽车的喜好度,生成个性化车型推荐列表并展示在车型详情页。
- 情感与舆情分析模块:借助snowNLP完成汽车舆情热点的情感分析,挖掘用户对不同车型、品牌的态度倾向,以可视化形式呈现舆情热点分布,辅助把握市场口碑趋势。
- 多维度数据分析模块:涵盖价格分析、车型占比、百公里加速性能分析等维度,通过数据统计面板、表格、词云图等形式直观展示分析结果,清晰呈现汽车市场各类特征规律。
- 系统管控模块:设计注册登录与后台管理功能,依托Django框架实现用户权限管控、数据增删改查等操作,保障系统数据安全与运维便捷性。
标题
AI大模型:Python汽车数据分析与个性化推荐系统 大数据毕业设计 Python+Django+snowNLP+协同过滤+requests✅
4、核心代码
import os
import django
import pandas as pd
import numpy as np
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE','project.settings')
django.setup()
from myApp.models import *
def getAllCars():
carInfoList = list(carInfo.objects.all())
df = pd.read_csv('./commentNew.csv').values
dataList = []
for i in df:
if type(i[0]) == str:
title = i[0][0:2]
for j in carInfoList:
if j.carName.find(title) != -1:
dataList.append([
i[7], # userid
j.id,#itemid
i[3]
])
print(dataList)
return dataList
def getUIMat(data):
user_list = [i[0] for i in data]
item_list = [i[1] for i in data]
UI_matrix = np.zeros((max(user_list) +1,max(item_list) +1))
for eache_interation in tqdm(data,total = len(data)):
UI_matrix[eache_interation[0]][eache_interation[1]] = eache_interation[2]
return UI_matrix
class MF():
def __init__(self,R,K,alpha,beta,iterations):
self.R = R
self.num_users,self.num_items = R.shape
self.K = K
self.alpha = alpha
self.beta = beta
self.iterations = iterations
def train(self):
self.P = np.random.normal(scale=1./self.K, size=(self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K, size=(self.num_items, self.K))
self.b_u = np.zeros(self.num_users)
self.b_i = np.zeros(self.num_items)
self.b = np.mean(self.R[np.where(self.R != 0)])
self.samples = [
(i, j, self.R[i, j])
for i in range(self.num_users)
for j in range(self.num_items)
if self.R[i, j] > 0
]
training_process = []
for i in tqdm(range(self.iterations), total=self.iterations):
np.random.shuffle(self.samples)
self.sgd()
mse = self.mse()
training_process.append((i, mse))
if (i == 0) or ((i+1) % (self.iterations / 10) == 0):
pass
return training_process
def mse(self):
xs, ys = self.R.nonzero()
predicted = self.full_matrix()
error = 0
for x, y in zip(xs, ys):
error += pow(self.R[x, y] - predicted[x, y], 2)
return np.sqrt(error)
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_rating(i, j)
e = (r - prediction)
self.b_u[i] += self.alpha * (e - self.beta * self.b_u[i])
self.b_i[j] += self.alpha * (e - self.beta * self.b_i[j])
self.P[i, :] += self.alpha * (e * self.Q[j, :] - self.beta * self.P[i,:])
self.Q[j, :] += self.alpha * (e * self.P[i, :] - self.beta * self.Q[j,:])
# 数值检查和处理
if np.isnan(self.P[i, :]).any() or np.isnan(self.Q[j, :]).any():
self.P[i, :] = np.nan_to_num(self.P[i, :])
self.Q[j, :] = np.nan_to_num(self.Q[j, :])
def get_rating(self, i, j):
prediction = self.b + self.b_u[i] + self.b_i[j] + self.P[i, :].dot(self.Q[j, :].T)
if np.isnan(prediction) or np.isinf(prediction):
prediction = 0
return prediction
def full_matrix(self):
return self.b + self.b_u[:,np.newaxis] + self.b_i[np.newaxis:,] + self.P.dot(self.Q.T)
def modelFn(each_user):
startList = getAllCars()
obs_dataset = []
for i in startList:
obs_dataset.append([i[0],i[1],i[2]])
R = getUIMat(obs_dataset)
mf = MF(R,K=2,alpha=0.1,beta=0.8,iterations=3)
mf.train()
user_rating = mf.full_matrix()[each_user].tolist()
topN = [(i,user_rating.index(i)) for i in user_rating]
topN = [i[1] for i in sorted(topN,key=lambda x:x[0],reverse=True)]
return topN
if __name__ == '__main__':
# getAllCars()
getAllCars()
print(modelFn(3))
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)