AI大模型python爬虫实战:网易云音乐数据爬取分析可视化+数据清洗 matplotlib 计算机毕业设计(源码)✅
AI大模型python爬虫实战:网易云音乐数据爬取分析可视化+数据清洗 matplotlib 计算机毕业设计(源码)✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
Python网易云音乐评论数据爬取清洗可视化是一种结合Python编程语言和相关库的方法,可以帮助我们获取、处理、分析和可视化网易云音乐评论数据,从而更好地理解用户行为和市场趋势。
技术栈: Python语言、requests爬虫、数据清洗、numpy、pandas、matplotlib
摘 要
在数字化音乐蓬勃发展的当下,海量音乐评论数据蕴含着丰富的用户情感与观点,然而传统分析手段难以高效挖掘其中价值。本研究基于此背景展开,运用 Python 语言作为核心开发工具,借助requests爬虫技术突破平台壁垒,从网易云音乐、微博、豆瓣音乐等多平台广泛采集音乐评论数据,构建起涵盖多维度信息的数据集。在数据处理环节,利用pandas与numpy库完成数据清洗,精准剔除缺失值、重复值与异常值;通过jieba分词工具对评论内容进行细致分割,并结合nltk停用词表去除无意义词汇,同时采用人工标注与机器学习相结合的方式,实现数据的准确标注。在分析阶段,运用深度学习模型对标注后的数据进行训练,成功实现对音乐评论情感倾向(积极、消极、中性)的精准判断,以及对旋律、歌词、演唱技巧等多种评论主题的有效识别。通过词云图、交互可视化等手段,直观展示评论高频词汇,提供筛选、缩放、聚焦和信息提示等交互功能,帮助用户深入探索数据。该研究成果为音乐创作者把握创作方向、平台运营者优化运营策略等提供了有力的数据支撑,推动了音乐评论从定性描述向量化分析与可视化呈现的转变,在音乐产业发展及学术研究领域具有重要的应用价值与理论意义。
关键词:音乐评论分析;数据爬取;数据预处理;可视化
2、项目界面
(1)词云图分析
# 绘制词云图
def generate_wordcloud(text):
wordcloud = WordCloud(width=1000,
height=700,
background_color='white', # 背景颜色
font_path='simhei.ttf', # 字体
scale=15, # 间隔
contour_width=5, # 整个内容显示的宽度
contour_color='red', # 内容显示的颜色 红色边境
).generate(text)
# wordcloud = WordCloud(font_path="simhei.ttf", background_color='white')
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
(2)情感分析
# 根据情感倾向分数将评论分类为积极和消极
positive_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score > 0.5]
negative_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score <= 0.5]
# 积极消极评论占比
pie_labels = ['积极评论', '消极评论']
plt.pie([len(positive_comments), len(negative_comments)],
labels=pie_labels, autopct='%1.2f%%', shadow=True)
plt.title("积极和消极评论占比")
plt.show()
(3)评论词频图
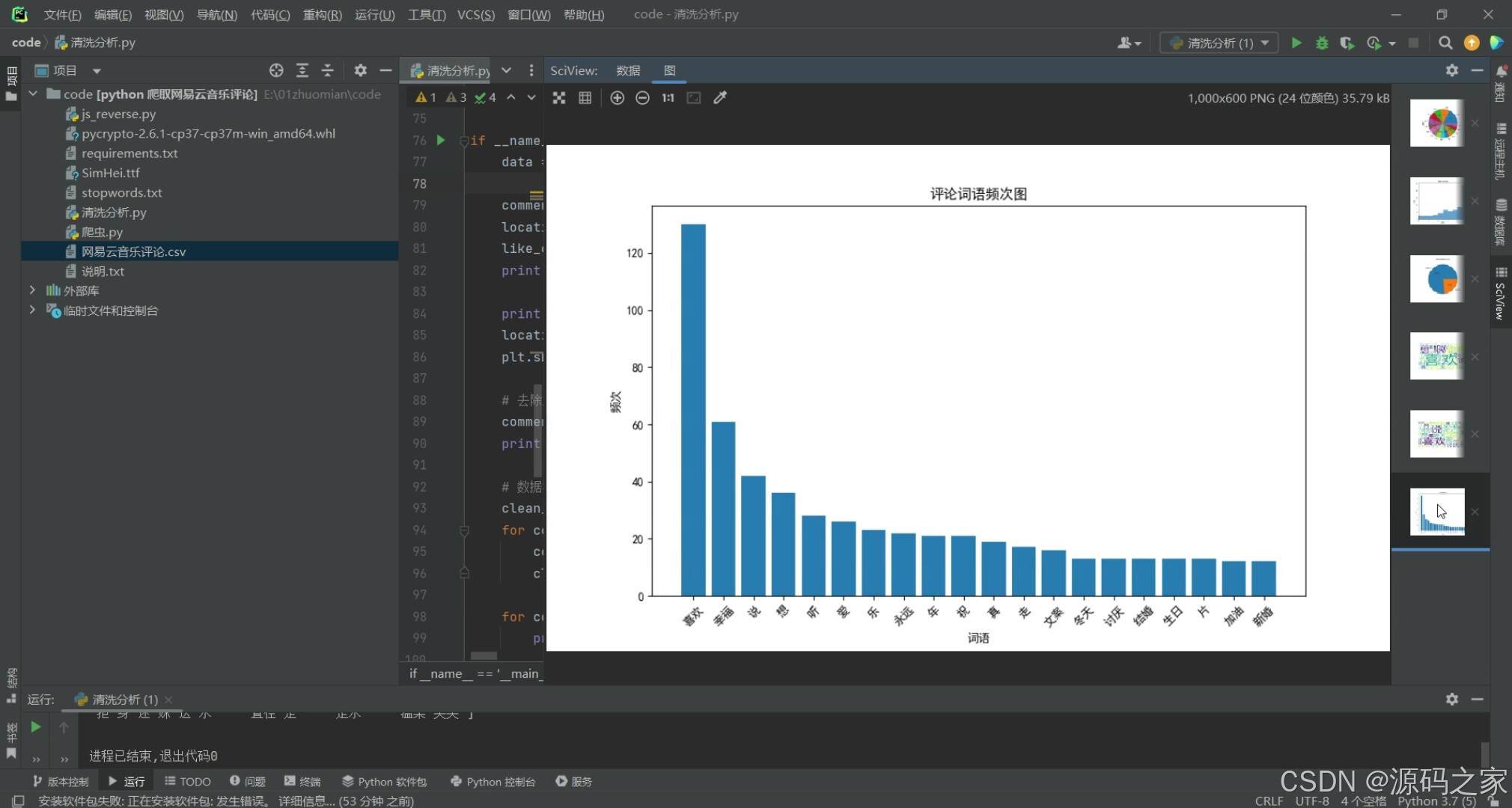
# 绘制词频图
def plot_word_frequency(text):
word_list = jieba.lcut(text)
word_counter = Counter(word_list)
word_freq = word_counter.most_common(21)[1:21] # 取出现频率最高的前20个词语及其频次
words, freqs = zip(*word_freq)
plt.figure(figsize=(10, 6))
plt.bar(words, freqs)
plt.xticks(rotation=45)
plt.xlabel('词语')
plt.ylabel('频次')
plt.title('评论词语频次图')
plt.show()
(4)评论IP属地分析
# 数据清洗
def clean(text):
text = re.sub(r"\[\S+\]", "", text) # 去除表情符号
URL_REGEX = re.compile(
r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',
re.IGNORECASE)
text = re.sub(URL_REGEX, "", text) # 去除网址
text = re.sub(r"\s+", " ", text) # 合并正文中过多的空格
# 去除停用词
for word in stopwords:
text = text.replace(word, '')
return text.strip()
3、项目说明
摘 要
在数字化音乐蓬勃发展的当下,海量音乐评论数据蕴含着丰富的用户情感与观点,然而传统分析手段难以高效挖掘其中价值。本研究基于此背景展开,运用 Python 语言作为核心开发工具,借助requests爬虫技术突破平台壁垒,从网易云音乐、微博、豆瓣音乐等多平台广泛采集音乐评论数据,构建起涵盖多维度信息的数据集。在数据处理环节,利用pandas与numpy库完成数据清洗,精准剔除缺失值、重复值与异常值;通过jieba分词工具对评论内容进行细致分割,并结合nltk停用词表去除无意义词汇,同时采用人工标注与机器学习相结合的方式,实现数据的准确标注。在分析阶段,运用深度学习模型对标注后的数据进行训练,成功实现对音乐评论情感倾向(积极、消极、中性)的精准判断,以及对旋律、歌词、演唱技巧等多种评论主题的有效识别。通过词云图、交互可视化等手段,直观展示评论高频词汇,提供筛选、缩放、聚焦和信息提示等交互功能,帮助用户深入探索数据。该研究成果为音乐创作者把握创作方向、平台运营者优化运营策略等提供了有力的数据支撑,推动了音乐评论从定性描述向量化分析与可视化呈现的转变,在音乐产业发展及学术研究领域具有重要的应用价值与理论意义。
关键词:音乐评论分析;数据爬取;数据预处理;可视化
Python网易云音乐评论数据爬取清洗可视化是一种利用Python编程语言爬取网易云音乐评论数据,然后对数据进行清洗和处理,最后使用可视化工具将数据呈现出来的方法。
首先,我们可以使用Python的爬虫库(如requests、BeautifulSoup等)来获取网易云音乐的评论数据。可以通过模拟用户登录、发送HTTP请求、解析HTML等步骤获取评论数据。
接下来,我们需要对获取到的评论数据进行清洗。这包括去除重复数据、去除无效数据、处理缺失值等步骤。可以使用Python的数据处理库(如pandas)来进行数据清洗。
最后,我们可以使用Python的数据可视化库(如matplotlib、seaborn等)来将清洗后的数据进行可视化。可以绘制柱状图、折线图、散点图等图表,以展示评论数据的分布、趋势等信息。
通过Python网易云音乐评论数据爬取清洗可视化,我们可以更好地理解和分析网易云音乐用户的评论行为。例如,我们可以通过可视化图表了解哪些歌曲受欢迎,哪些歌曲的评论数量最多,评论的情感倾向等等。
总之,Python网易云音乐评论数据爬取清洗可视化是一种结合Python编程语言和相关库的方法,可以帮助我们获取、处理、分析和可视化网易云音乐评论数据,从而更好地理解用户行为和市场趋势。
5、源码获取方式
biyesheji0005 或 biyesheji0001 (绿色聊天软件)

🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)