“I love you“ 后面为什么是 “too“?一文读懂大语言模型的注意力机制
注意力机制:大语言模型的"思考"核心 摘要:注意力机制是Transformer架构的核心技术,它通过Query-Key-Value三元组让AI学会关注文本中的关键信息。当处理"I love you"时,模型将词语转换为向量,计算"you"的Query与上下文词的Key的匹配度,发现"love"相关性最高。通过Softm
“I love you” 后面为什么是 “too”?一文读懂大语言模型的注意力机制
一句话总结:注意力机制是大语言模型的"大脑",它通过Query-Key-Value三元组让AI学会"看重点",从而在海量词汇中精准预测下一个最合适的词。
🔑 核心概念速览
| 概念 | 通俗解释 | 技术作用 |
|---|---|---|
| 向量(Vector) | 用一串数字表示一个词的"身份证" | 让计算机理解词的含义 |
| Query(查询) | “我在找什么?” | 当前词想要寻找的信息 |
| Key(键) | “我能提供什么?” | 其他词能够被匹配的特征 |
| Value(值) | “我的实际内容是什么?” | 被提取的具体信息 |
| 点积(Dot Product) | 两个向量的"匹配度打分" | 计算词与词之间的相关性 |
| Softmax | 把分数变成百分比 | 确定每个词的重要程度 |
📖 引言:一个神奇的预测
想象你正在和AI聊天,你说:
“I love you”
AI几乎瞬间回复:
“I love you too”
为什么 next token 是"too"而不是"chair"(椅子)、“database”(数据库)或者其他50000个词中的任何一个?
这背后的秘密,就是注意力机制(Attention Mechanism)——大语言模型最核心的"思考"方式。
今天,我们就来深入浅出地解读这个改变了整个AI领域的技术。
🎯 第一部分:三个必须了解的基础工具
在理解注意力机制之前,我们需要先掌握三个基础概念。别担心,我会用最通俗的方式解释。
1. 向量:词的"数字身份证"
在计算机的世界里,文字是无法直接处理的。我们需要把每个词转换成一串数字,这串数字就叫向量。
"love" → [0.8, -0.3, 1.2, 0.5, -0.9, ...]
"hate" → [-0.7, 0.4, -1.1, 0.2, 0.8, ...]
"like" → [0.6, -0.2, 0.9, 0.4, -0.7, ...]
注意看:
- "love"和"like"的向量数值比较接近(都是正面情感)
- "love"和"hate"的向量数值差异较大(情感相反)
这就是**词向量(Word Embedding)**的魔力——语义相近的词,在向量空间中距离也相近。
┌─────────────────────────────────────────────────────────────────┐
│ 词向量空间示意图 │
│ │
│ ★ love │
│ / │
│ / (距离近) │
│ / │
│ ★ like │
│ │
│ │
│ ★ hate (距离远) │
│ │
│ ★ chair (完全无关) │
└─────────────────────────────────────────────────────────────────┘
2. 点积:计算"匹配度"的方法
点积是一种数学运算,用来计算两个向量有多"相似"。
# 简化示例
向量A = [1, 2, 3]
向量B = [4, 5, 6]
点积 = 1×4 + 2×5 + 3×6 = 4 + 10 + 18 = 32
点积的结果越大,说明两个向量越"匹配"。
用生活化的比喻:
- 点积就像两个人的"性格匹配度测试"
- 分数越高,说明两人越合拍
3. Softmax:把分数变成百分比
假设我们计算出三个词的匹配分数:
- “too”: 10分
- “back”: 5分
- “chair”: 1分
Softmax会把这些分数转换成概率:
- “too”: 92%
- “back”: 7%
- “chair”: 1%
所有概率加起来正好是100%,这样模型就知道应该选择哪个词了。
🔬 第二部分:注意力机制的完整流程
现在,让我们一步步看看当模型处理"I love you"并预测下一个词时,到底发生了什么。
第一步:词向量化
首先,每个词都被转换成向量:

词嵌入过程——每个词被转换成一个固定维度的向量(如512维)。(图源:Jay Alammar)
"I" → x_I = [0.1, -0.5, 0.3, ...]
"love" → x_love = [0.8, -0.3, 1.2, ...]
"you" → x_you = [0.2, 0.7, -0.4, ...]
这些向量包含了每个词的"氛围"、语法角色和语义信息。
第二步:三种角色的诞生(Q、K、V)
这是注意力机制最核心的部分。模型会给每个词分配三个"角色":
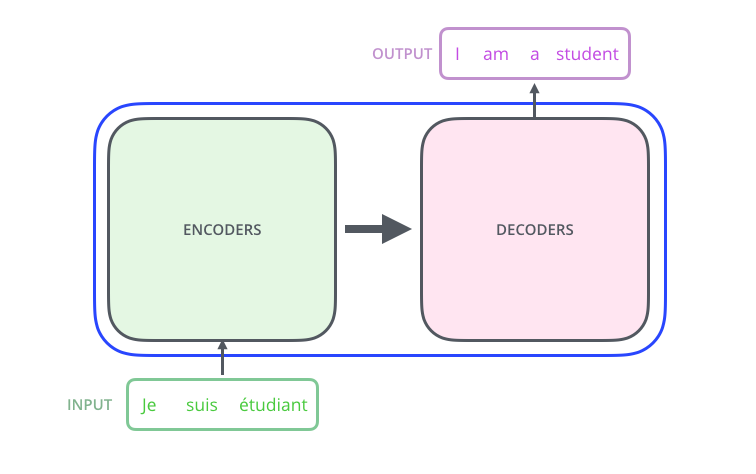
图1:Transformer模型整体架构——左侧是编码器堆栈,右侧是解码器堆栈,信息从编码器流向解码器。(图源:Jay Alammar)
| 角色 | 名称 | 问题 | 例子 |
|---|---|---|---|
| Q | Query(查询) | 这个词在寻找什么? | "you"正在寻找情感语境 |
| K | Key(键) | 这个词能提供什么? | "love"提供深厚的情感语境 |
| V | Value(值) | 它应该贡献什么信息? | "互惠情感"的具体数据 |
这三个角色是通过三个权重矩阵(WQW_QWQ, WKW_KWK, WVW_VWV)计算得到的:
Q=X⋅WQQ = X \cdot W_QQ=X⋅WQ
K=X⋅WKK = X \cdot W_KK=X⋅WK
V=X⋅WVV = X \cdot W_VV=X⋅WV
用一个生活化的比喻来理解:
想象你在图书馆找书。
- Query:你脑海中想要的书的特征(“我想找一本关于爱情的小说”)
- Key:书架上每本书的标签(“浪漫小说”、“科幻”、“历史”…)
- Value:书的实际内容
第三步:计算注意力分数
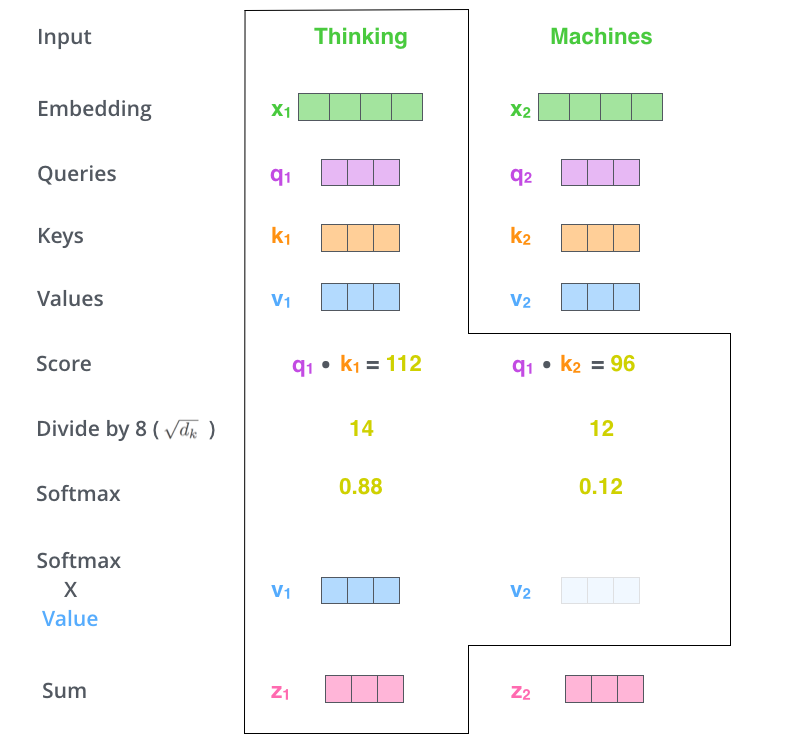
现在,模型想知道"you"后面应该跟什么词。它会用"you"的Query去和之前所有词的Key做点积:
score_I = q_you · k_I = 2.1 (匹配度低)
score_love = q_you · k_love = 8.7 (匹配度高!)
score_you = q_you · k_you = 4.3 (自我匹配)
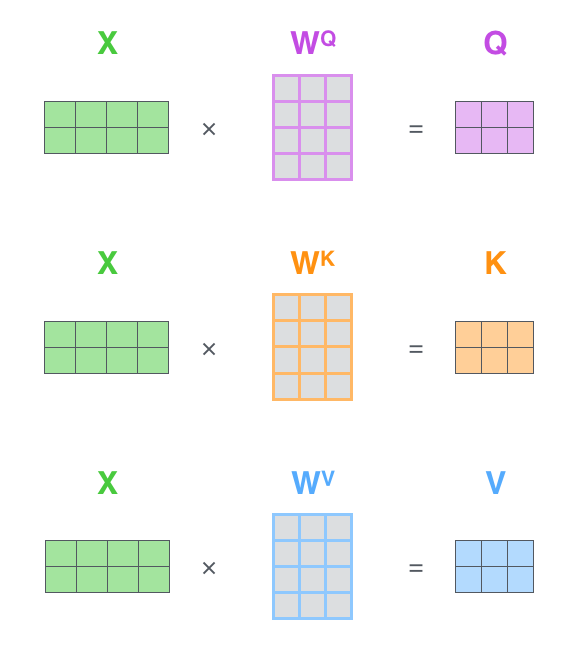
图2:自注意力的矩阵计算——Query矩阵与Key矩阵相乘得到注意力分数,经过Softmax后与Value矩阵相乘得到输出。(图源:Jay Alammar)
为什么"love"的分数最高?
因为模型通过阅读数十亿页文本,已经学会了:
- 当有人说"I love you"时,对方通常会回应情感
- "you"的Query向量被训练成能够"寻找"情感相关的词
- "love"的Key向量被训练成能够"提供"情感语境
第四步:Softmax归一化
接下来,用Softmax把分数转换成权重:
[wI,wlove,wyou]=softmax([2.1,8.7,4.3])[w_I, w_{love}, w_{you}] = \text{softmax}([2.1, 8.7, 4.3])[wI,wlove,wyou]=softmax([2.1,8.7,4.3])
结果可能是:
- wIw_IwI = 5%
- wlovew_{love}wlove = 80%
- wyouw_{you}wyou = 15%
第五步:加权混合
用这些权重对Value向量进行加权求和,得到上下文向量:
context=wI⋅vI+wlove⋅vlove+wyou⋅vyou\text{context} = w_I \cdot v_I + w_{love} \cdot v_{love} + w_{you} \cdot v_{you}context=wI⋅vI+wlove⋅vlove+wyou⋅vyou
这个上下文向量代表了整个句子的"氛围"——“指向听者的积极情感”。
自注意力的输出——每个位置的输出都是所有位置Value的加权和,权重由注意力分数决定。(图源:Jay Alammar)
第六步:预测下一个词
最后,模型把这个上下文向量和词典中所有50000+个词的嵌入向量进行比较:
score("too") = context · embedding_too → 非常高!
score("back") = context · embedding_back → 中等
score("chair") = context · embedding_chair → 非常低
score("database") = context · embedding_database → 几乎为零
转换成概率后:
- “too”: 92%
- “back”: 5%
- “database”: 0.0001%
模型选择概率最高的词——“too”!
🏗️ 第三部分:技术深度解析
缩放点积注意力的数学公式
完整的注意力计算公式是:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
其中:
- QQQ:查询矩阵
- KKK:键矩阵
- VVV:值矩阵
- dkd_kdk:键向量的维度
- dk\sqrt{d_k}dk:缩放因子
为什么要除以 dk\sqrt{d_k}dk?
这是一个非常重要的细节。当向量维度dkd_kdk很大时,点积的结果也会变得很大。这会导致:
- Softmax函数进入"饱和区"
- 梯度变得非常小
- 模型难以训练
除以dk\sqrt{d_k}dk可以让点积结果保持在合理范围内,确保训练稳定。
┌─────────────────────────────────────────────────────────────────┐
│ 缩放的作用示意 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 不缩放时: │
│ 点积结果 = [100, 50, 30] │
│ Softmax后 ≈ [99.99%, 0.01%, 0.00%] ← 过于极端,梯度消失 │
│ │
│ 缩放后: │
│ 点积结果 = [10, 5, 3] │
│ Softmax后 ≈ [85%, 12%, 3%] ← 分布合理,梯度正常 │
│ │
└─────────────────────────────────────────────────────────────────┘
多头注意力:从不同角度看问题
在实际的Transformer中,注意力机制被扩展为多头注意力(Multi-Head Attention)。
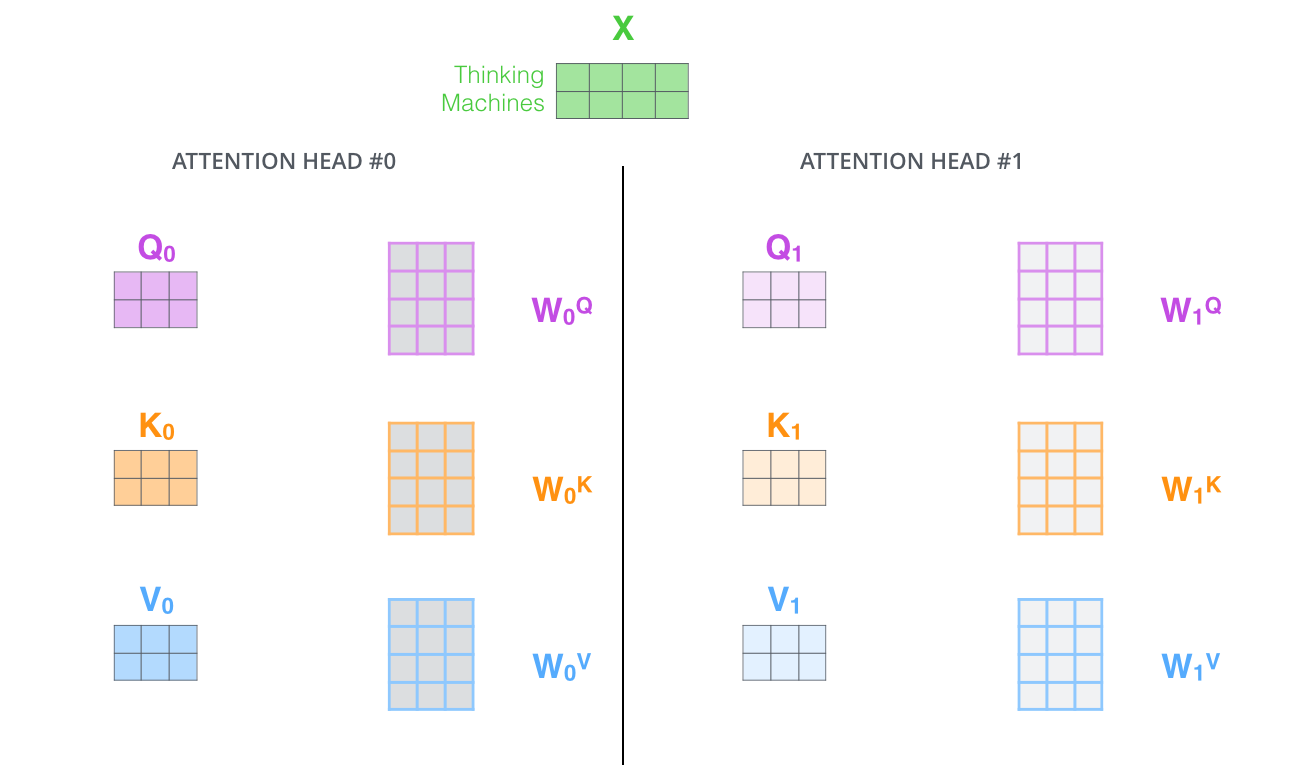
图3:多头注意力机制——每个"头"都有独立的Q、K、V权重矩阵,可以从不同角度理解句子。(图源:Jay Alammar)
为什么需要多个"头"?
想象你在分析一句话"The animal didn’t cross the street because it was too tired":
- 头1可能关注语法结构("it"指代什么?)
- 头2可能关注语义关系("tired"和什么相关?)
- 头3可能关注位置信息(词的顺序)
- …
每个头都能从不同的"视角"理解句子,然后把所有视角的理解综合起来。
# 多头注意力的计算过程
MultiHead(Q, K, V) = Concat(head_1, head_2, ..., head_h) × W_O
其中:
head_i = Attention(Q × W_i^Q, K × W_i^K, V × W_i^V)
在原始Transformer论文中,使用了8个头,每个头的维度是64(总维度512÷8=64)。
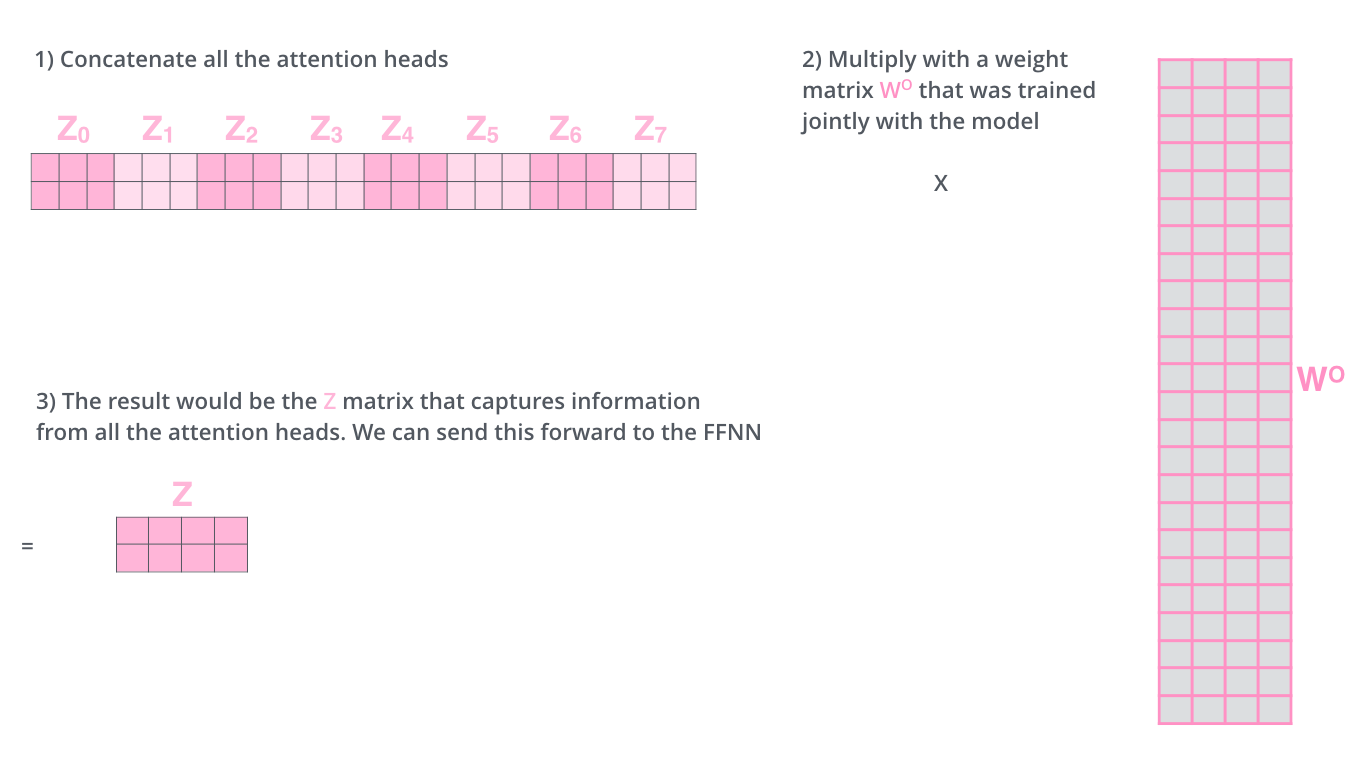
图4:多头注意力的输出——所有头的输出拼接后,通过一个线性变换得到最终结果。(图源:Jay Alammar)
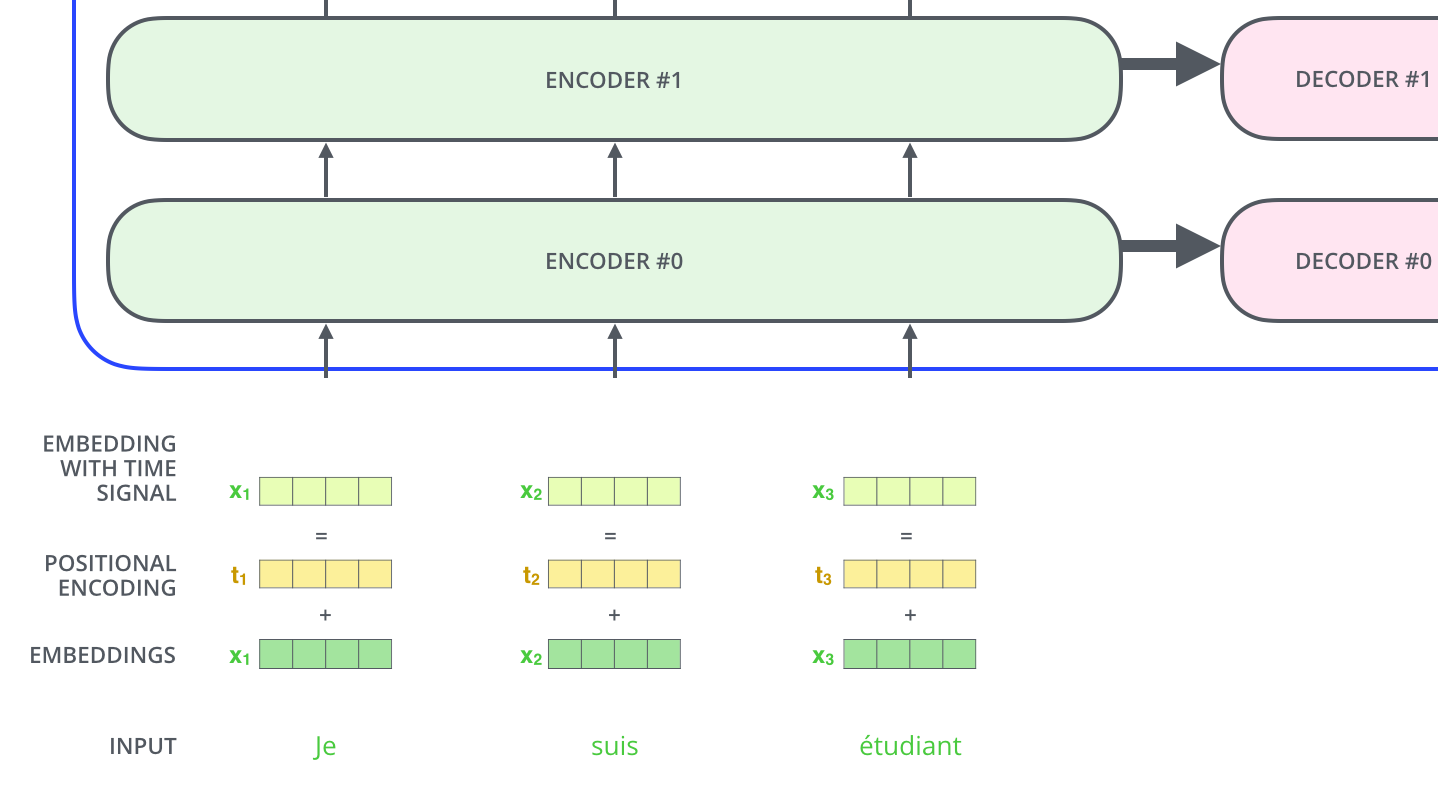
📊 第四部分:Transformer架构全景
注意力机制是Transformer的核心,但完整的Transformer还包含其他重要组件:
┌─────────────────────────────────────────────────────────────────────────┐
│ Transformer 架构全景图 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 输入: "I love you" │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 词嵌入层 │ ← 把词转换成向量 │
│ │ + 位置编码 │ ← 加入位置信息 │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 编码器 ×6 │ │
│ │ ┌───────────┐ │ │
│ │ │多头自注意力│ │ ← 理解词与词的关系 │
│ │ └─────┬─────┘ │ │
│ │ ↓ │ │
│ │ ┌───────────┐ │ │
│ │ │前馈神经网络│ │ ← 进一步处理信息 │
│ │ └───────────┘ │ │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 解码器 ×6 │ │
│ │ ┌───────────┐ │ │
│ │ │掩码自注意力│ │ ← 只看已生成的词 │
│ │ └─────┬─────┘ │ │
│ │ ↓ │ │
│ │ ┌───────────┐ │ │
│ │ │编解码注意力│ │ ← 关注输入句子 │
│ │ └─────┬─────┘ │ │
│ │ ↓ │ │
│ │ ┌───────────┐ │ │
│ │ │前馈神经网络│ │ │
│ │ └───────────┘ │ │
│ └────────┬────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 线性层+Softmax │ ← 输出概率分布 │
│ └────────┬────────┘ │
│ ↓ │
│ 输出: "too" │
│ │
└─────────────────────────────────────────────────────────────────────────┘
位置编码:让模型知道词的顺序
由于注意力机制本身不考虑词的顺序(它同时看所有词),我们需要额外加入位置编码:
位置编码示例——位置编码向量与词嵌入相加,为每个位置生成独特的"指纹"。(图源:Jay Alammar)
PE(pos,2i)=sin(pos/100002i/dmodel)PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}})PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}})PE(pos,2i+1)=cos(pos/100002i/dmodel)
这个看起来复杂的公式,本质上是用正弦和余弦函数为每个位置生成一个独特的"指纹"。
残差连接和层归一化
为了让深层网络更容易训练,Transformer使用了:
- 残差连接:output=LayerNorm(x+Sublayer(x))\text{output} = \text{LayerNorm}(x + \text{Sublayer}(x))output=LayerNorm(x+Sublayer(x))
- 层归一化:稳定训练过程
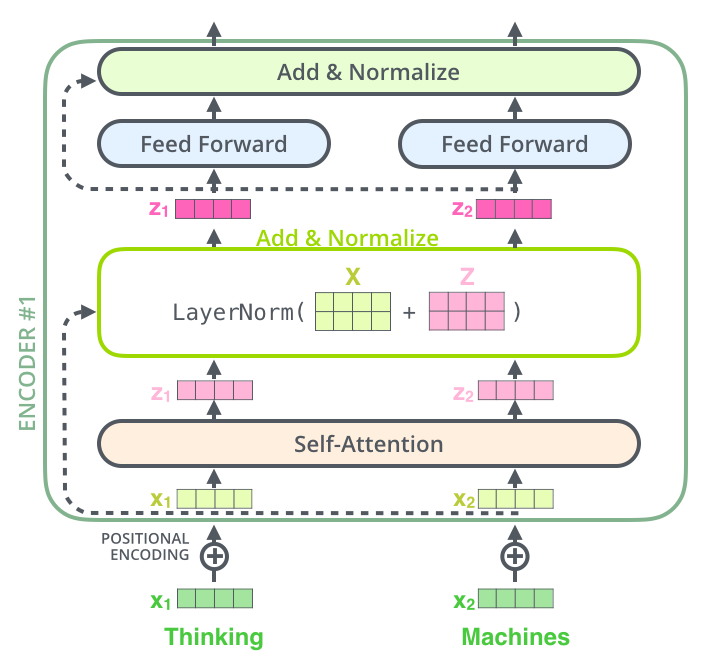
残差连接和层归一化——信息可以"绕过"子层直接传递,避免梯度消失问题。(图源:Jay Alammar)
💡 第五部分:为什么注意力机制如此重要?
对比传统方法
| 特性 | RNN/LSTM | CNN | Transformer |
|---|---|---|---|
| 长距离依赖 | 困难(信息逐步传递) | 需要多层堆叠 | 直接连接 |
| 并行计算 | 无法并行 | 可以并行 | 完全并行 |
| 计算复杂度 | O(n) | O(n/k) | O(n²) |
| 可解释性 | 低 | 低 | 高(可视化注意力) |
注意力机制的三大优势
- 长距离依赖:任意两个词之间的"距离"都是1,可以直接关注
- 并行计算:所有位置可以同时计算,训练速度大幅提升
- 可解释性:可以可视化模型在"看"哪些词

图5:注意力权重可视化——当处理单词"it"时,模型的注意力主要集中在"The animal"上,说明模型理解了代词的指代关系。(图源:Jay Alammar)
🧪 第六部分:实验结果与影响
原始论文的惊人成绩
《Attention Is All You Need》论文在2017年发表时取得了突破性成果:
| 任务 | 模型 | BLEU分数 | 训练时间 |
|---|---|---|---|
| 英德翻译 | Transformer (Big) | 28.4 | 3.5天 |
| 英法翻译 | Transformer (Big) | 41.8 | 3.5天 |
| 之前最佳 | 集成模型 | 26.0+ | 数周 |
Transformer不仅效果更好,训练速度还快了10倍以上!
深远影响
这篇论文奠定了现代大语言模型的基础:
Transformer (2017)
↓
BERT (2018) - 双向编码器
↓
GPT系列 (2018-2024) - 解码器架构
↓
ChatGPT, Claude, Gemini...
可以说,没有注意力机制,就没有今天的AI革命。
🤔 深度思考:注意力机制的本质
从信息检索的角度理解
注意力机制本质上是一个软性的信息检索系统:
- Query:你的搜索词
- Key:文档的索引/标签
- Value:文档的实际内容
- 注意力权重:搜索结果的排序
与传统搜索不同的是,注意力机制返回的是所有文档的加权混合,而不是单一结果。
从人类认知的角度理解
人类阅读时也在做类似的事情:
当你读到"The cat sat on the mat because it was tired"时,你的大脑会自动将"it"与"cat"关联起来,而不是"mat"。
这正是注意力机制在做的事情——选择性地关注相关信息。
📝 总结
让我们回顾一下注意力机制的核心流程:
┌─────────────────────────────────────────────────────────────────┐
│ 注意力机制四步曲 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 1️⃣ 转换:把每个词转换成 Query、Key、Value 三个向量 │
│ │
│ 2️⃣ 匹配:用 Query 和 Key 的点积计算相关性分数 │
│ │
│ 3️⃣ 混合:用 Softmax 权重对 Value 进行加权求和 │
│ │
│ 4️⃣ 预测:在词典中找到与上下文向量最匹配的词 │
│ │
└─────────────────────────────────────────────────────────────────┘
核心要点:
- ✅ 向量是基础——词被转换成数字向量,语义相近的词向量也相近
- ✅ Q-K-V是核心——Query寻找、Key被匹配、Value被提取
- ✅ 点积计算相关性——分数越高,两个词越相关
- ✅ Softmax归一化——把分数变成概率分布
- ✅ 多头看多角度——不同的头关注不同的语义关系
理解了注意力机制,你就理解了现代大语言模型的"思考"方式!
🔗 参考资料
核心论文
- Attention Is All You Need
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017)
- arXiv:1706.03762
- https://arxiv.org/abs/1706.03762
- 奠定Transformer架构的里程碑论文
技术博客
-
“I love you” “too”: LLM Attention Explained
- kaamvaam.com
- https://kaamvaam.com/machine-learning-ai/llm-attention-explanation/
- 本文的主要参考来源,用生动案例解释注意力机制
-
The Illustrated Transformer
- Jay Alammar
- https://jalammar.github.io/illustrated-transformer/
- 经典的Transformer可视化解读
-
自注意力机制详解:理解Transformer中的QKV
- CSDN博客
- https://blog.csdn.net/Fanstay985/article/details/141951464
- 中文技术解读
延伸阅读
-
Transformer自注意力机制详解
- CSDN博客
- https://blog.csdn.net/ahah12345678/article/details/144677222
-
从熵不变性看Attention的Scale操作
- 科学空间 (苏剑林)
- https://kexue.fm/archives/8823
- 深入分析缩放因子的数学原理
-
NLP中的Attention注意力机制Transformer详解
- 知乎专栏
- https://zhuanlan.zhihu.com/p/53682800
-
词向量Word2Vec模型详解
- CSDN博客
- https://blog.csdn.net/weixin_42504788/article/details/136045583
- 理解词嵌入的基础
💬 互动话题:你觉得注意力机制最神奇的地方是什么?欢迎在评论区分享你的理解!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)