AI也有“性格“?GPT-5.2 vs Claude Opus 4.5 个性大对决
AI模型展现稳定个性特征,Claude与GPT风格迥异 最新研究表明,大语言模型确实具有可区分的"个性"特征。Lindr团队通过系统化实验发现,GPT-5.2和Claude Opus 4.5展现出稳定的行为差异:Claude更具开放性(+4.5分)和好奇心(+3.7分),适合创意任务;而GPT更严谨尽责(+5.3分)且有进取心(+1.6分),适合结构化工作。研究创新性地采用行为
AI也有"性格"?GPT-5.2 vs Claude Opus 4.5 个性大对决
一句话总结:Lindr团队通过系统化的个性评估实验发现,不同的大语言模型确实具有稳定且可区分的"个性"特征——Claude更具创造力和好奇心,而GPT更加严谨和尽责。
🔑 核心发现速览
在深入解读之前,先看一眼研究的核心结论:
| 发现 | 关键数据 | 启示 |
|---|---|---|
| 模型有"内在个性" | 44.8%的个性差异来自模型本身 | 选模型≈选"性格" |
| Claude更开放 | 开放性+4.5分,好奇心+3.7分 | 适合创意、探索类任务 |
| GPT更严谨 | 尽责性+5.3分,进取心+1.6分 | 适合任务导向、结构化工作 |
| 个性可调节 | 31.2%来自提示词,8.4%来自上下文 | 可通过Prompt"调教"AI |
📖 引言:当AI成为产品的"脸面"
想象一下,你正在和两个不同的客服聊天。一个热情洋溢、充满好奇心,总是愿意探索新的解决方案;另一个则沉稳可靠、条理清晰,一步步带你解决问题。你可能没有意识到,这两个"客服"可能分别是Claude和GPT驱动的AI助手。
随着大语言模型(LLM)越来越多地成为产品与用户交互的"第一接触点",AI的"个性"正在悄然影响着我们的使用体验。但问题是:AI真的有个性吗?如果有,我们能测量它吗?不同的模型之间有什么区别?
Lindr团队最近发布的一项研究给出了令人惊讶的答案。
🎯 研究背景:为什么要测量AI的"个性"?
从工具到伙伴的转变
过去,我们评价AI模型主要看它的"能力"——能不能写代码、能不能做数学题、能不能通过各种benchmark测试。但随着AI越来越多地参与到日常交互中,一个新的问题浮出水面:
AI不仅要"能做事",还要"会做人"。
这就像招聘员工一样。你不仅需要看他的技术能力,还需要考虑他的性格是否适合团队文化、是否能和客户良好沟通。对于AI产品来说,道理是一样的:
- 一个过于激进的AI可能会让用户感到不舒服
- 一个过于保守的AI可能会让用户觉得无趣
- 一个情绪不稳定的AI可能会让用户失去信任
现有评估方法的困境
传统上,研究者们尝试用人类的心理学测试(如大五人格测试)来评估AI的个性。但一项来自UC Berkeley的研究指出了一个严重问题:
自评测试在衡量LLM个性时是不可靠的。
研究发现,仅仅改变问题的措辞方式,或者调整选项的排列顺序,就会导致AI的"个性评分"发生显著变化。这就像你问一个人"你觉得自己外向吗?“和"你喜欢社交吗?”,他给出了完全不同的答案——这显然不是一个稳定的个性特征。
这就是Lindr团队研究的出发点:我们需要一种更可靠的方法来评估AI的个性。
🔬 研究方法:如何科学地测量AI的"性格"?
实验设计
Lindr团队设计了一套系统化的评估方案:
| 评估维度 | 具体设置 |
|---|---|
| 测试模型 | GPT-5.2 和 Claude Opus 4.5 |
| 测试提示 | 500个独特的提示词 |
| 个性维度 | 10个维度 |
| 上下文环境 | 5种(专业、休闲、客户支持、销售、技术) |
| 生成参数 | 温度0.7,最大token数1024 |
十大个性维度
与传统的"大五人格"模型不同,Lindr定义了10个更适合评估AI的个性维度:
- 开放性(Openness):对新想法和创造性解决方案的接受程度
- 好奇心(Curiosity):主动探索和提问的倾向
- 尽责性(Conscientiousness):做事的条理性和可靠性
- 进取心(Assertiveness):表达观点和主导对话的倾向
- 自信心(Confidence):对自己回答的确定程度
- 韧性(Resilience):面对困难问题的坚持程度
- 神经质(Neuroticism):表现出不确定或焦虑的倾向
- 宜人性(Agreeableness):友好和合作的程度
- 外向性(Extraversion):热情和健谈的程度
- 情绪稳定性(Emotional Stability):回应的一致性和稳定性
评估方法的创新
与传统的自评测试不同,Lindr采用了行为分析的方法:
传统方法:直接问AI "你觉得自己外向吗?" → 不可靠
Lindr方法:给AI各种任务,观察它的回应模式 → 更可靠
这就像评价一个人的性格,不是问他"你觉得自己怎么样",而是观察他在不同场景下的实际表现。
📊 核心发现:Claude和GPT的"性格画像"
发现一:两个模型确实有不同的"性格"
研究最重要的发现是:GPT-5.2和Claude Opus 4.5确实展现出了稳定且可区分的个性特征。
下图展示了两个模型在10个个性维度上的差异热力图:
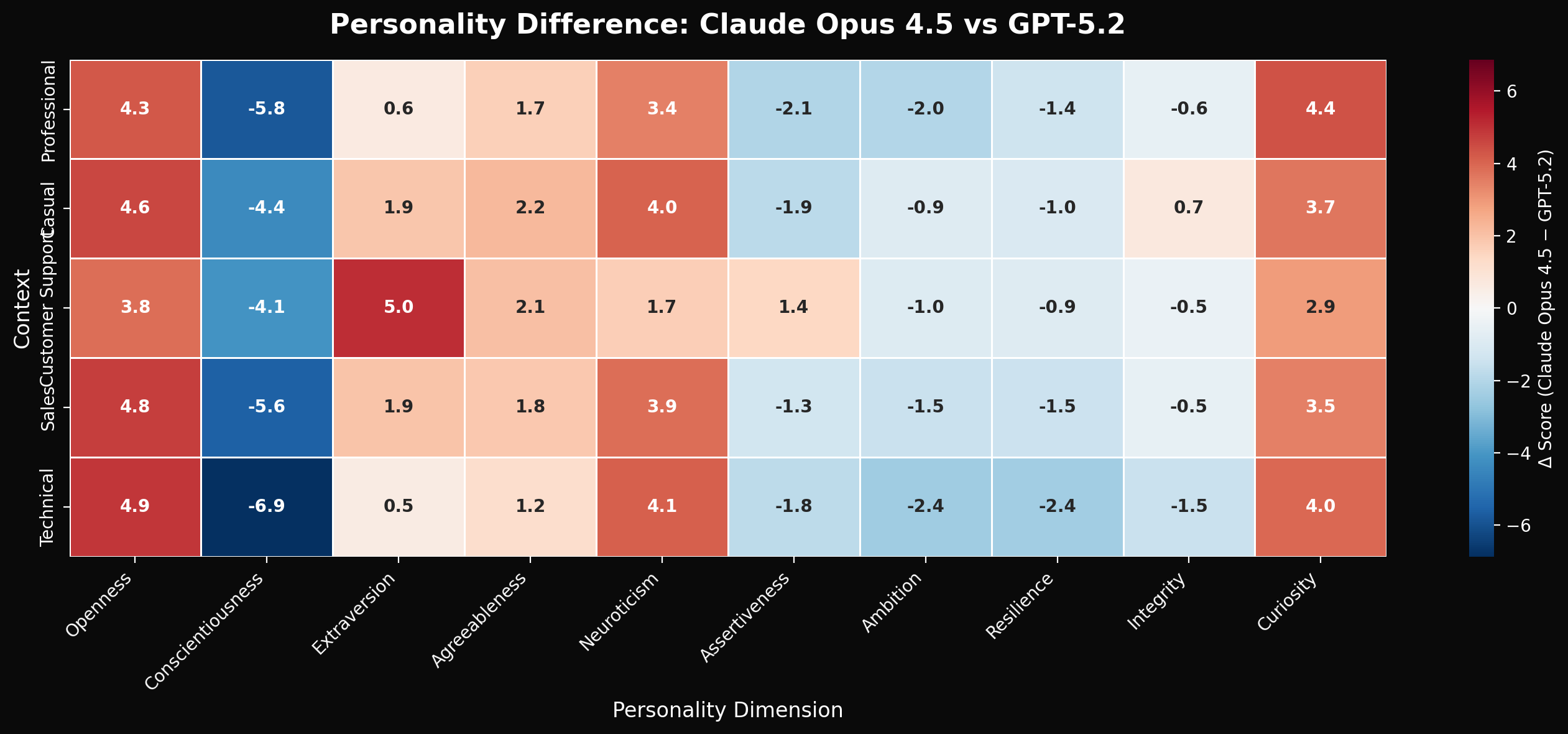
图1:个性差异热力图——红色表示GPT-5.2得分更高,蓝色表示Claude得分更高。颜色越深,差异越大。
从热力图可以清晰看出两个模型的个性差异:
Claude Opus 4.5 的个性特点:
- 📈 开放性更高(+4.5分)
- 📈 好奇心更强(+3.7分)
- 📈 神经质略高(+3.4分)
GPT-5.2 的个性特点:
- 📈 尽责性更高(+5.3分)
- 📈 进取心更强(+1.6分)
- 📈 韧性更好(+1.4分)
用一个生活化的比喻来说:
Claude像一个充满好奇心的艺术家,总是愿意探索新的可能性,思维开放,但有时候会显得有点"想太多"。
GPT像一个严谨的工程师,做事有条理、有计划,目标明确,但可能不那么愿意"跳出框框"思考。
┌─────────────────────────────────────────────────────────────────────────┐
│ GPT-5.2 vs Claude Opus 4.5 个性对比 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 开放性 Claude ████████████████████████████ +4.5 │
│ GPT ████████████████████████ │
│ │
│ 好奇心 Claude ███████████████████████████ +3.7 │
│ GPT ████████████████████████ │
│ │
│ 尽责性 GPT ████████████████████████████████ +5.3 │
│ Claude ███████████████████████████ │
│ │
│ 进取心 GPT ██████████████████████████ +1.6 │
│ Claude █████████████████████████ │
│ │
│ 韧性 GPT █████████████████████████ +1.4 │
│ Claude ████████████████████████ │
│ │
│ 神经质 Claude ████████████████████████ +3.4 │
│ GPT █████████████████████ │
│ │
└─────────────────────────────────────────────────────────────────────────┘
发现二:这些差异是统计显著的
研究使用了Hedges’ g效应量来验证差异的显著性。下图展示了各个维度的效应量:
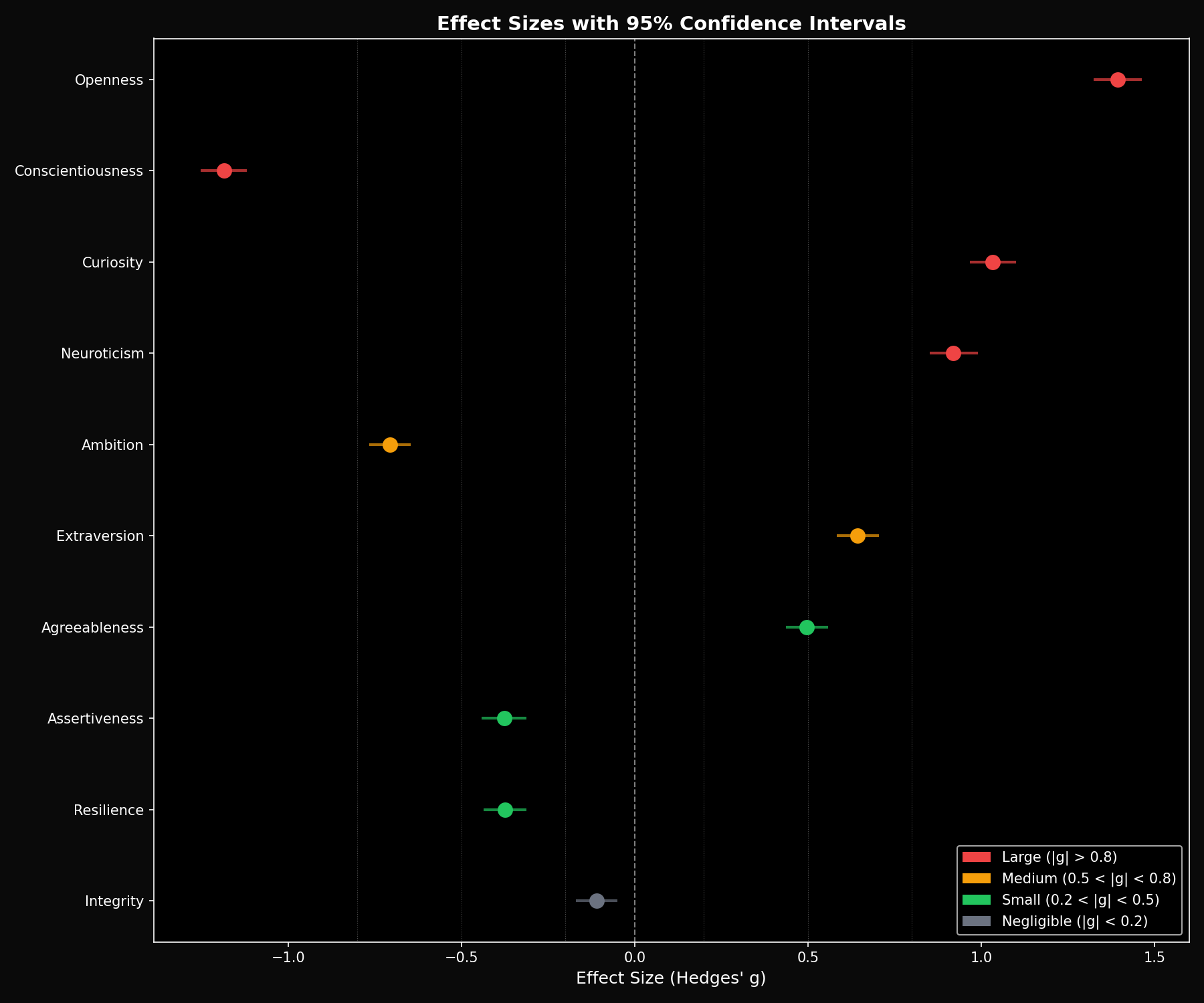
图2:Hedges’ g效应量分析——正值表示GPT-5.2更高,负值表示Claude更高。误差线表示95%置信区间。
| 个性维度 | 效应量 (Hedges’ g) | 哪个模型更高 |
|---|---|---|
| 尽责性 | 0.76 | GPT-5.2 |
| 开放性 | -0.62 | Claude |
| 好奇心 | -0.54 | Claude |
| 进取心 | 0.42 | GPT-5.2 |
效应量在0.4-0.8之间属于中等到大的效应,这意味着这些差异不是随机噪声,而是真实存在的模式。
发现三:个性的来源分析
研究进一步分析了个性评分的方差来源,这是本研究最重要的发现之一:
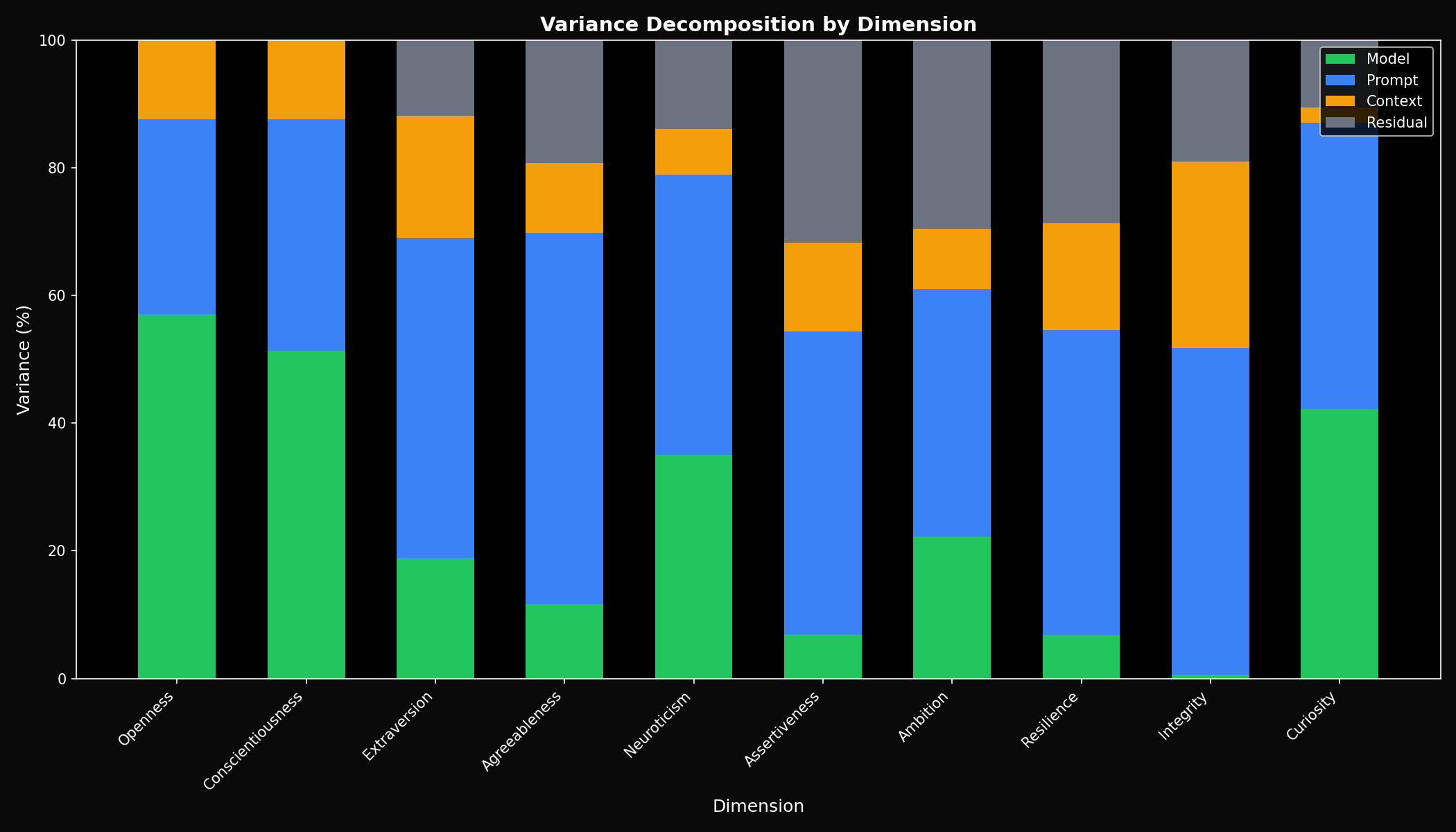
图3:方差分解分析——展示了个性评分差异的来源构成。模型本身贡献了近一半的方差。
从方差分解图可以看出:
| 方差来源 | 占比 | 含义 |
|---|---|---|
| 模型本身 | 44.8% | 不同模型确实有"内在个性" |
| 提示词 | 31.2% | 可以通过prompt调整AI表现 |
| 上下文环境 | 8.4% | AI会根据场景调整"人设" |
| 残差 | 15.6% | 随机变异和未解释因素 |
这个发现非常重要:
- 44.8%的个性差异来自模型本身——这说明不同模型确实有"内在个性"
- 31.2%来自提示词——这说明我们可以通过prompt来调整AI的表现
- 8.4%来自上下文环境——这说明AI会根据场景调整自己的"人设"
发现四:个性维度之间存在关联
研究还发现,某些个性维度之间高度相关:
- 进取心 ↔ 自信心:相关系数 r = 0.72
- 开放性 ↔ 好奇心:相关系数 r = 0.68
这符合我们的直觉:一个自信的人往往更敢于表达观点,一个开放的人往往更有好奇心。
🏗️ 技术深度解析:为什么会有这些差异?
RLHF训练的影响
大语言模型的"个性"很大程度上是在**RLHF(基于人类反馈的强化学习)**阶段形成的。
┌──────────────────────────────────────────────────────────────────────────┐
│ LLM训练流程与个性形成 │
├──────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌──────────┐ │
│ │ 1.预训练 │ → │ 2.监督微调 │ → │ 3.奖励建模 │ → │ 4.强化 │ │
│ │ (Pretrain) │ │ (SFT) │ │ (RM) │ │ 学习(RL) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └──────────┘ │
│ ↓ ↓ ↓ ↓ │
│ 获得基础语言 学习对话格式 学习人类偏好 优化以符合 │
│ 能力 和回答风格 ⭐个性形成关键⭐ 偏好 │
│ │
│ ════════════════════════════════════════════════════════════════════ │
│ │
│ 不同公司的标注团队有不同的偏好,导致模型"个性"差异: │
│ │
│ OpenAI标注员偏好: Anthropic标注员偏好: │
│ ✓ 条理清晰 ✓ 探索性思考 │
│ ✓ 任务导向 ✓ 开放性回答 │
│ ✓ 确定性表达 ✓ 承认不确定性 │
│ │
└──────────────────────────────────────────────────────────────────────────┘
在这个过程中,不同公司的人类标注员有不同的偏好,这就导致了模型个性的差异:
- OpenAI的标注团队可能更偏好条理清晰、任务导向的回答
- Anthropic的标注团队可能更偏好探索性、开放性的回答
系统提示词的作用
另一个重要因素是内置的系统提示词(System Prompt)。虽然这些提示词通常是保密的,但它们会显著影响模型的行为模式。
例如,如果系统提示词强调"要谨慎、要承认不确定性",模型就会表现出更高的"神经质";如果强调"要自信、要给出明确答案",模型就会表现出更高的"进取心"。
训练数据的影响
最后,训练数据的来源和组成也会影响模型的个性。如果训练数据中包含更多创意写作内容,模型可能会更有"开放性";如果包含更多技术文档,模型可能会更有"尽责性"。
💡 实践启示:这对产品设计意味着什么?
对产品经理的建议
1. 根据产品定位选择模型
| 产品类型 | 推荐模型 | 原因 |
|---|---|---|
| 创意写作助手 | Claude | 开放性和好奇心更高 |
| 代码助手 | GPT | 尽责性和韧性更好 |
| 客服机器人 | 需要测试 | 取决于品牌调性 |
| 教育助手 | Claude | 好奇心有助于引导学习 |
2. 通过上下文调整个性
研究发现,8.4%的个性变化来自上下文环境。这意味着你可以通过精心设计的系统提示词来"调教"AI的个性:
# 想要更专业严谨的回答
system_prompt = """
你是一位专业的技术顾问。请提供准确、结构化的回答。
避免猜测,如果不确定请明确说明。
"""
# 想要更活泼创意的回答
system_prompt = """
你是一位富有创意的头脑风暴伙伴。
欢迎探索各种可能性,不要害怕提出大胆的想法。
"""
3. 系统性地评估而非凭感觉
不要仅凭主观感受来选择模型。建立一套评估体系,在你的具体场景下测试不同模型的表现。
对安全研究者的启示
研究发现AI的个性会随环境变化,这引发了一个重要问题:
这是"适应性"还是"不一致性"?
如果AI在不同场景下表现出不同的个性,这是好事(因为它能适应不同需求)还是坏事(因为它不够稳定可预测)?
这个问题目前还没有定论,但它提醒我们:我们需要更好的方法来规范和验证AI的行为一致性。
🔬 方法论讨论:如何正确评估AI个性?
自评测试的局限性
正如UC Berkeley的研究所指出的,传统的自评测试存在严重问题:
| 问题类型 | 具体表现 | 影响 |
|---|---|---|
| 提示词敏感性 | 同一问题不同措辞,结果差异显著 | 评分不可复现 |
| 选项顺序偏差 | 改变选项顺序会改变选择 | 评分受格式影响 |
| 模型普遍性 | 问题在多个模型中都存在 | 不是个别现象 |
行为分析方法的优势
Lindr采用的行为分析方法通过观察AI在实际任务中的表现来推断其个性,这种方法更接近于我们评价人类个性的方式——看他做什么,而不是听他说什么。
未来的改进方向
- 更多样化的测试场景:目前只有5种上下文环境,未来可以扩展到更多场景
- 跨语言验证:当前研究主要基于英语,需要验证在其他语言中是否成立
- 时间稳定性:需要验证模型的个性是否随版本更新而变化
📚 相关研究与延伸阅读
学术论文
-
Self-Assessment Tests are Unreliable Measures of LLM Personality (Gupta et al., 2023)
- arXiv: 2309.08163
- 核心发现:传统自评测试在LLM上不可靠,存在提示词敏感性和选项顺序偏差问题
-
A Survey on Evaluation of Large Language Models (2023)
- 综述了LLM评估的各种方法和挑战
- 涵盖了能力评估、行为评估、鲁棒性评估等多个维度
-
Predicting the Big Five Personality Traits in Chinese Counselling Dialogues Using Large Language Models
- GitHub: kuri-leo/BigFive-LLM-Predictor
- 探索了使用LLM预测对话中人格特征的方法
大五人格模型简介
大五人格模型(Big Five / OCEAN)是目前心理学界公认最全面的人格分析模型:
| 维度 | 英文 | 高分特征 | 低分特征 |
|---|---|---|---|
| 开放性 | Openness | 富有想象力、好奇 | 务实、传统 |
| 尽责性 | Conscientiousness | 有条理、可靠 | 随意、灵活 |
| 外向性 | Extraversion | 健谈、精力充沛 | 内敛、独立 |
| 宜人性 | Agreeableness | 友好、合作 | 竞争、挑战 |
| 神经质 | Neuroticism | 敏感、情绪化 | 稳定、冷静 |
GPT-5 vs Claude 4 最新对比
根据2025年8月的最新评测数据:
| 测试项目 | GPT-5 | Claude Opus 4 |
|---|---|---|
| SWE-bench Verified(编程) | 74.9% | 72.5% |
| GPQA Diamond(科学推理) | 89.4% | 80.9% |
| AIME 2025(数学) | 94.6% | ~77.6% |
可以看到,在能力层面两者各有优势,但在"个性"层面的差异同样值得关注。
📝 总结
Lindr团队的这项研究为我们打开了一扇新的窗口:AI不仅有能力差异,还有个性差异。
核心发现回顾:
- ✅ AI确实有可测量的"个性"——不同模型展现出稳定且可区分的个性特征
- ✅ Claude更有创造力,GPT更加严谨——这反映了不同公司的训练理念
- ✅ 个性可以被调整——通过提示词和上下文可以影响AI的表现
- ✅ 需要新的评估方法——传统自评测试不可靠,行为分析更有效
对于产品设计者来说,这意味着选择AI模型不仅要看能力,还要看"性格"是否匹配。
对于AI研究者来说,这意味着我们需要更系统地理解和控制AI的行为模式。
对于普通用户来说,这意味着你和不同AI助手的交互体验差异,可能不仅仅是功能差异,还有"性格"差异。
🔗 参考资料
-
Lindr Blog - Measuring LLM Personality: GPT-5.2 vs Claude Opus 4.5 Benchmark
- https://www.lindr.io/blog/benchmark
-
Self-Assessment Tests are Unreliable Measures of LLM Personality
- Gupta, A., Song, X., & Anumanchipalli, G. (2023)
- arXiv:2309.08163
- https://arxiv.org/abs/2309.08163
-
大五人格模型介绍
- 知乎专栏:大五人格测试 big5(OCEAN模型)
- https://zhuanlan.zhihu.com/p/371435056
-
RLHF技术详解
- AWS官方文档:什么是RLHF?
- https://aws.amazon.com/what-is/reinforcement-learning-from-human-feedback/
-
GPT-5 vs Claude 4 对比评测
- 稀土掘金:GPT-5 vs Claude 4:2025年最强AI模型深度对比分析
- https://juejin.cn/post/7540879173180555300
-
BigFive-LLM-Predictor
- GitHub: kuri-leo/BigFive-LLM-Predictor
- https://github.com/kuri-leo/BigFive-LLM-Predictor
💬 互动话题:你在使用不同AI助手时,有没有感受到它们的"性格"差异?欢迎在评论区分享你的体验!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)