GWO - KELM回归预测在电厂运行数据中的MATLAB实现
GWO灰狼优化算法算法优化KELM核极限学习机(GWO-KELM)回归预测MATLAB代码代码注释清楚。main为主程序,可以读取EXCEL数据。很方便,容易上手。(电厂运行数据为例)温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。在电力系统领域,准确预测电厂运行数据对于优化发电过程、降低成本以及保障电力供应的稳定性至关重要。今天咱就唠唠利用GWO灰狼优化算法来优化KELM核极限学
GWO灰狼优化算法算法优化KELM核极限学习机(GWO-KELM)回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。

在电力系统领域,准确预测电厂运行数据对于优化发电过程、降低成本以及保障电力供应的稳定性至关重要。今天咱就唠唠利用GWO灰狼优化算法来优化KELM核极限学习机进行回归预测,并且用MATLAB实现,代码注释也会给大家写得明明白白。
1. 整体思路
GWO灰狼优化算法是一种基于群体智能的优化算法,模拟了灰狼群体的狩猎行为。KELM核极限学习机则是一种高效的单隐层前馈神经网络。将GWO和KELM结合,能够利用GWO的全局搜索能力来优化KELM的参数,从而提升回归预测的性能。
2. MATLAB代码实现
main主程序
% 主程序,读取电厂运行数据的EXCEL文件
function main()
% 读取EXCEL数据,假设数据文件名为'power_plant_data.xlsx'
data = xlsread('power_plant_data.xlsx');
% 假设前4列是特征,最后一列是目标值
input = data(:, 1:4);
target = data(:, end);
% 划分训练集和测试集,这里简单地按照70%训练,30%测试划分
train_ratio = 0.7;
train_num = floor(size(input, 1) * train_ratio);
train_input = input(1:train_num, :);
train_target = target(1:train_num);
test_input = input(train_num + 1:end, :);
test_target = target(train_num + 1:end);
% 调用GWO - KELM模型进行训练和预测
[predict_result] = gwo_kelm(train_input, train_target, test_input);
% 计算预测误差
mse = mean((predict_result - test_target).^2);
fprintf('均方误差MSE: %.4f\n', mse);
end代码分析:这个主程序主要负责读取EXCEL格式的电厂运行数据,然后对数据进行简单的划分,分成训练集和测试集。接着调用gwo_kelm函数进行模型训练和预测,最后计算预测结果和真实值之间的均方误差。
gwo_kelm函数
function [predict_result] = gwo_kelm(train_input, train_target, test_input)
% GWO算法参数设置
SearchAgents_no = 50; % 灰狼数量
Max_iteration = 100; % 最大迭代次数
dim = 2; % 待优化参数维度,这里假设KELM需要优化的参数有2个
lb = [0.1, 1]; % 参数下限
ub = [10, 100]; % 参数上限
% 初始化灰狼位置
Positions = initial_position(SearchAgents_no, dim, lb, ub);
% GWO算法优化KELM参数
[Best_pos, Best_fitness] = gwo(SearchAgents_no, Max_iteration, lb, ub, dim, train_input, train_target, Positions);
% 使用最优参数训练KELM模型
net = train_kelm(train_input, train_target, Best_pos(1), Best_pos(2));
% 进行预测
predict_result = predict_kelm(net, test_input);
end代码分析:此函数先设置了GWO算法的相关参数,包括灰狼数量、最大迭代次数、待优化参数的维度以及参数的上下限。接着初始化灰狼的位置,然后调用gwo函数来优化KELM的参数。得到最优参数后,利用这些参数训练KELM模型,最后对测试数据进行预测。
initial_position函数
function Positions = initial_position(SearchAgents_no, dim, lb, ub)
% 初始化灰狼位置
Positions = zeros(SearchAgents_no, dim);
for i = 1:SearchAgents_no
for j = 1:dim
Positions(i, j) = lb(j) + (ub(j) - lb(j)) * rand();
end
end
end代码分析:该函数用于随机初始化每只灰狼在搜索空间中的位置,每个位置的维度由dim决定,并且每个维度的取值在lb和ub之间。
gwo函数
function [Best_pos, Best_fitness] = gwo(SearchAgents_no, Max_iteration, lb, ub, dim, train_input, train_target, Positions)
% 初始化参数
a = 2; % 收敛因子
fitness = zeros(SearchAgents_no, 1);
for i = 1:SearchAgents_no
% 计算每只灰狼的适应度
fitness(i) = fitness_kelm(Positions(i, :), train_input, train_target);
end
[Best_fitness, best_index] = min(fitness);
Best_pos = Positions(best_index, :);
Alpha_pos = zeros(1, dim);
Alpha_score = inf;
Beta_pos = zeros(1, dim);
Beta_score = inf;
Delta_pos = zeros(1, dim);
Delta_score = inf;
% 迭代优化
for t = 1:Max_iteration
a = 2 - t * (2 / Max_iteration); % 更新收敛因子
for i = 1:SearchAgents_no
r1 = rand(); % 随机数r1
r2 = rand(); % 随机数r2
A1 = 2 * a * r1 - a; % 计算系数A1
C1 = 2 * r2; % 计算系数C1
D_alpha = abs(C1 * Alpha_pos - Positions(i, :));
X1 = Alpha_pos - A1 * D_alpha;
r1 = rand();
r2 = rand();
A2 = 2 * a * r1 - a;
C2 = 2 * r2;
D_beta = abs(C2 * Beta_pos - Positions(i, :));
X2 = Beta_pos - A2 * D_beta;
r1 = rand();
r2 = rand();
A3 = 2 * a * r1 - a;
C3 = 2 * r2;
D_delta = abs(C3 * Delta_pos - Positions(i, :));
X3 = Delta_pos - A3 * D_delta;
Positions(i, :) = (X1 + X2 + X3) / 3;
% 边界处理
for j = 1:dim
if Positions(i, j) < lb(j)
Positions(i, j) = lb(j);
elseif Positions(i, j) > ub(j)
Positions(i, j) = ub(j);
end
end
% 计算适应度
fitness(i) = fitness_kelm(Positions(i, :), train_input, train_target);
if fitness(i) < Alpha_score
Alpha_score = fitness(i);
Alpha_pos = Positions(i, :);
end
if fitness(i) > Alpha_score && fitness(i) < Beta_score
Beta_score = fitness(i);
Beta_pos = Positions(i, :);
end
if fitness(i) > Alpha_score && fitness(i) > Beta_score && fitness(i) < Delta_score
Delta_score = fitness(i);
Delta_pos = Positions(i, :);
end
end
Best_fitness = Alpha_score;
Best_pos = Alpha_pos;
end
end代码分析:gwo函数实现了GWO算法的核心逻辑。在每次迭代中,根据当前的收敛因子a以及随机数计算出系数A和C,然后更新每只灰狼的位置。位置更新过程中,参考了当前最优解(Alpha)、次优解(Beta)和第三优解(Delta)。每次更新位置后,进行边界处理,确保位置在设定的上下限内。接着重新计算适应度,并更新Alpha、Beta和Delta的位置和适应度值。
fitness_kelm函数
function fitness = fitness_kelm(params, train_input, train_target)
% 根据给定参数训练KELM并计算适应度
sigma = params(1);
lambda = params(2);
net = train_kelm(train_input, train_target, sigma, lambda);
predict = predict_kelm(net, train_input);
fitness = mean((predict - train_target).^2);
end代码分析:这个函数根据传入的参数训练KELM模型,然后用训练好的模型对训练数据进行预测,最后以预测值和真实值之间的均方误差作为适应度值返回。
train_kelm函数
function net = train_kelm(train_input, train_target, sigma, lambda)
% 训练KELM模型
n = size(train_input, 1);
H = gaussian_kernel(train_input, train_input, sigma);
I = eye(n);
net.beta = (H' * H + lambda * I) \ H' * train_target;
net.sigma = sigma;
net.lambda = lambda;
end代码分析:此函数用于训练KELM模型。首先计算高斯核矩阵H,然后通过正则化最小二乘法求解输出权重beta,并将模型参数sigma和lambda保存到net结构体中。
predict_kelm函数
function predict = predict_kelm(net, test_input)
% 使用KELM模型进行预测
H = gaussian_kernel(test_input, net.train_input, net.sigma);
predict = H * net.beta;
end代码分析:该函数利用训练好的KELM模型对测试数据进行预测。通过计算测试数据与训练数据之间的高斯核矩阵H,然后与训练得到的输出权重beta相乘,得到预测结果。
gaussian_kernel函数
function H = gaussian_kernel(X1, X2, sigma)
% 计算高斯核矩阵
n1 = size(X1, 1);
n2 = size(X2, 1);
H = zeros(n1, n2);
for i = 1:n1
for j = 1:n2
H(i, j) = exp(-norm(X1(i, :) - X2(j, :))^2 / (2 * sigma^2));
end
end
end代码分析:这个函数用于计算高斯核矩阵。对于输入的两个矩阵X1和X2,通过遍历每个元素,计算它们之间的高斯核值,填充到H矩阵中。
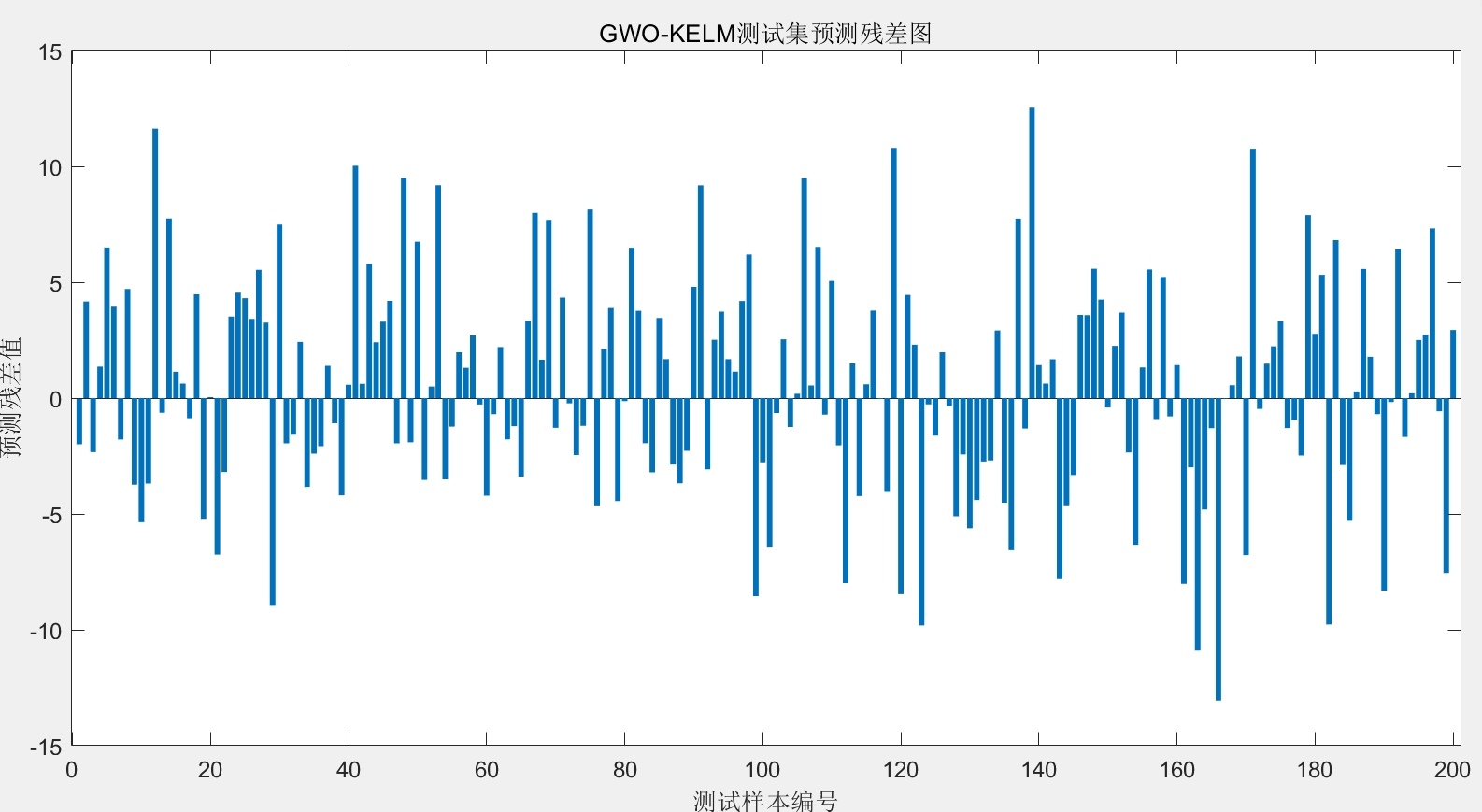
温馨提示:如果您对这些程序代码感兴趣,购买相关商品后,由于代码的特殊性,一经售出,概不退换哦。希望这篇文章和代码能帮助大家在电厂运行数据预测方面有所收获,欢迎大家一起交流探讨。
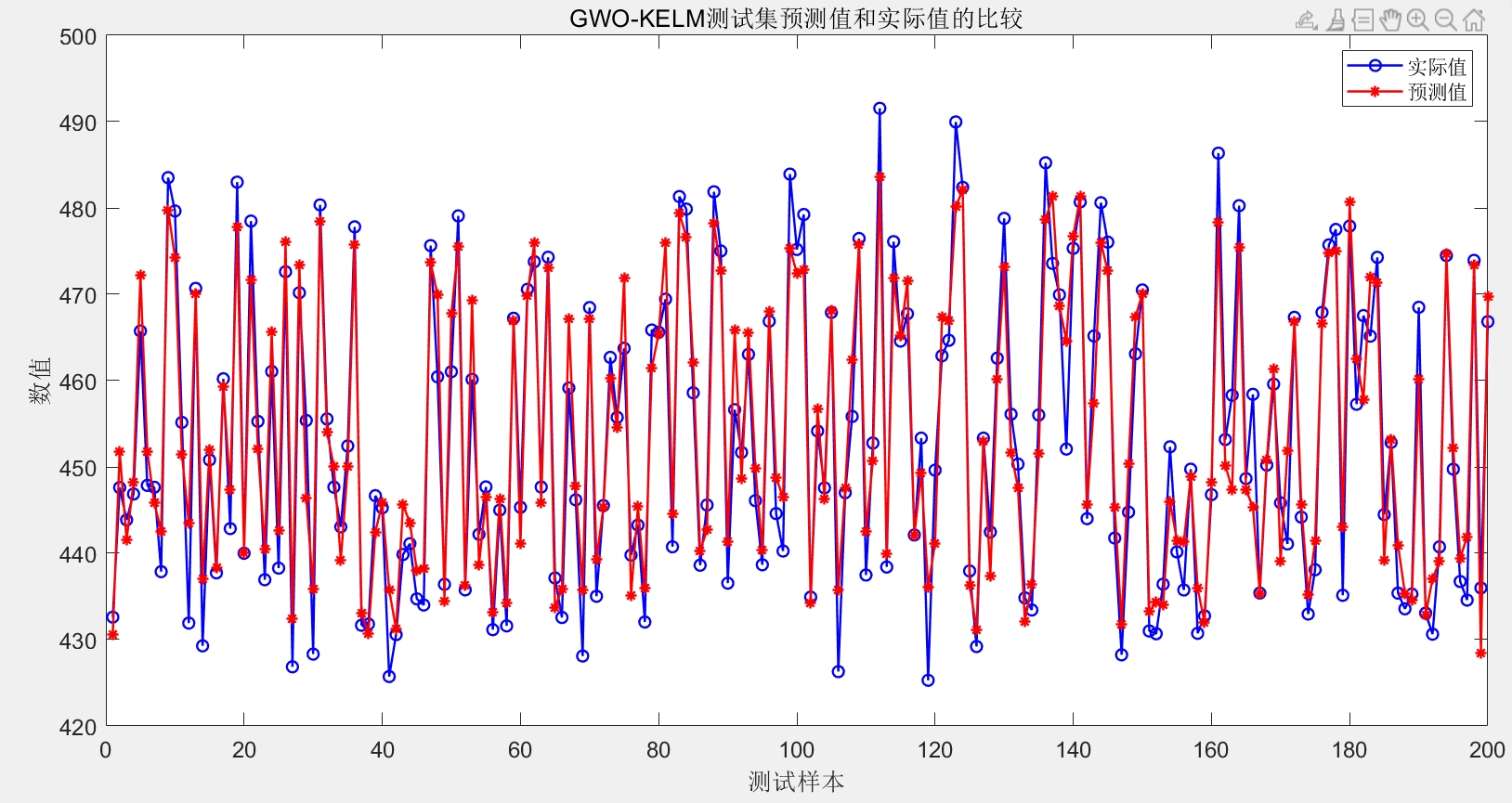

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)