AI 入门通俗读本:零代码玩转神经网络-零基础神经网络模型搭建基础原理及 Excel 手搓搭建课程
零基础学习神经网络第三节人工神经网络建立过程 #人工神经网络 是一种模拟生物神经网络的信息处理系统,它的目标是实现类似人工智能的 #机器学习 技术。它由大量的神经元(节点)相互连接组成,通过对大量数据的学习,调整神经元之间的连接权重,构建出能适应特定任务的网络模型。当有新的输入数据时,网络就能快速处理并输出结果,比如实现模式识别、数据分类、预测等功能。 一、生物神经元结构与功能的模拟,输入与信号累 - 抖音![]() https://www.douyin.com/video/7503550866578804004零基础学习神经网络第四课神经网络向前与反向传播及权重调整 #算机神经网络 :苹果价格预测示例解析 #权重调整 1. 神经网络基础概念回顾:1.1 神经网络基本构成 ①神经网络由大量神经元相互连接构成,神经元是其基本处理单元,就像人类大脑中的神经元一样,它们接收输入信号,经过处理后输出信号。 ② 神经元之间通过权重连接,权重决定了信号传递的强度和方向,是神经网络学习和调整的关键参数。 1 - 抖音
https://www.douyin.com/video/7503550866578804004零基础学习神经网络第四课神经网络向前与反向传播及权重调整 #算机神经网络 :苹果价格预测示例解析 #权重调整 1. 神经网络基础概念回顾:1.1 神经网络基本构成 ①神经网络由大量神经元相互连接构成,神经元是其基本处理单元,就像人类大脑中的神经元一样,它们接收输入信号,经过处理后输出信号。 ② 神经元之间通过权重连接,权重决定了信号传递的强度和方向,是神经网络学习和调整的关键参数。 1 - 抖音![]() https://www.douyin.com/video/7503876417101352231零基础学习神经网络第五节——误差函数的选取权重调整 #误差函数 #回归分析 #深度学习 #机器学习算法 #梯度下降 #模型优化 通过其导数(梯度 )直接影响 权重更新 方向和幅度,是 神经 网络 优化的核心驱动力; 核心差异总结: 一、导数连续性与可导性 1、差值误差:导数为常数,无法反映当前误差大小,优化过程无 “修正方向”。 2、绝对值误差:在 Yt=Yo 处导数不连续, - 抖音
https://www.douyin.com/video/7503876417101352231零基础学习神经网络第五节——误差函数的选取权重调整 #误差函数 #回归分析 #深度学习 #机器学习算法 #梯度下降 #模型优化 通过其导数(梯度 )直接影响 权重更新 方向和幅度,是 神经 网络 优化的核心驱动力; 核心差异总结: 一、导数连续性与可导性 1、差值误差:导数为常数,无法反映当前误差大小,优化过程无 “修正方向”。 2、绝对值误差:在 Yt=Yo 处导数不连续, - 抖音![]() https://www.douyin.com/video/7507649332133367076零基础神经网络第五课 零代码Excel表手搓神经网络模型计算 零基础神经网络第五课 零代码Excel表手搓神经网络模型计算过程及权重偏置数据调整 再上一节课程中我们详细讲解了均方误差作为神经网络的损失函数,在神经网络中,损失函数的选择需根据任务类型(如回归、分类)及数据特点决定。均方误差是回归任务中最常用的损失函数之一;回归任务和分类任务是机器学习中两种最基础的任务类型,核心区别在于目标变量的类型 - 抖音
https://www.douyin.com/video/7507649332133367076零基础神经网络第五课 零代码Excel表手搓神经网络模型计算 零基础神经网络第五课 零代码Excel表手搓神经网络模型计算过程及权重偏置数据调整 再上一节课程中我们详细讲解了均方误差作为神经网络的损失函数,在神经网络中,损失函数的选择需根据任务类型(如回归、分类)及数据特点决定。均方误差是回归任务中最常用的损失函数之一;回归任务和分类任务是机器学习中两种最基础的任务类型,核心区别在于目标变量的类型 - 抖音![]() https://www.douyin.com/video/7512094235508706614零基础神经网络第五课 零代码Excel表手搓神经网络模型计算 零基础神经网络第五课 零代码Excel表手搓神经网络模型计算过程及权重偏置数据调整 再上一节课程中我们详细讲解了均方误差作为神经网络的损失函数,在神经网络中,损失函数的选择需根据任务类型(如回归、分类)及数据特点决定。均方误差是回归任务中最常用的损失函数之一;回归任务和分类任务是机器学习中两种最基础的任务类型,核心区别在于目标变量的类型 - 抖音
https://www.douyin.com/video/7512094235508706614零基础神经网络第五课 零代码Excel表手搓神经网络模型计算 零基础神经网络第五课 零代码Excel表手搓神经网络模型计算过程及权重偏置数据调整 再上一节课程中我们详细讲解了均方误差作为神经网络的损失函数,在神经网络中,损失函数的选择需根据任务类型(如回归、分类)及数据特点决定。均方误差是回归任务中最常用的损失函数之一;回归任务和分类任务是机器学习中两种最基础的任务类型,核心区别在于目标变量的类型 - 抖音![]() https://www.douyin.com/video/7512094235508706614零基础神经网络第六课零代码Excel表手搓回归任务价格预测神 零基础神经网络第六课零代码Excel表手搓回归任务价格预测神经网络AI模型 零基础学习神经网络0603-Excel表手搓神经网络价格预测及数字0到9识别理解两者差异是机器学习建模的基础,合理选择任务类型和对应算法可显著提升模型效果。 基于神经网络回归分析车厘子价格体系 在商业活动中,价格体系的制定与分析至关重要。以车厘子销售为例,我们掌 - 抖音
https://www.douyin.com/video/7512094235508706614零基础神经网络第六课零代码Excel表手搓回归任务价格预测神 零基础神经网络第六课零代码Excel表手搓回归任务价格预测神经网络AI模型 零基础学习神经网络0603-Excel表手搓神经网络价格预测及数字0到9识别理解两者差异是机器学习建模的基础,合理选择任务类型和对应算法可显著提升模型效果。 基于神经网络回归分析车厘子价格体系 在商业活动中,价格体系的制定与分析至关重要。以车厘子销售为例,我们掌 - 抖音![]() https://www.douyin.com/video/7512096439846063372神经网络基础课程-零代码基于Excel表手搓数字零至九识别 神经网络基础教程-零代码基于Excel表手搓数字零至九识别 基于 7 段数码管的数字识别神经网络分类模型构建 一、背景与目标 在上一节课中,我们通过车厘子价格预测任务构建了神经网络回归模型,成功实现了价格预测。本节课将转向分类任务,通过学习 7 段数码管的数字显示原理,搭建一个能够识别数字 0~9 的神经网络模型。该模型将利用数码管的亮灭 - 抖音
https://www.douyin.com/video/7512096439846063372神经网络基础课程-零代码基于Excel表手搓数字零至九识别 神经网络基础教程-零代码基于Excel表手搓数字零至九识别 基于 7 段数码管的数字识别神经网络分类模型构建 一、背景与目标 在上一节课中,我们通过车厘子价格预测任务构建了神经网络回归模型,成功实现了价格预测。本节课将转向分类任务,通过学习 7 段数码管的数字显示原理,搭建一个能够识别数字 0~9 的神经网络模型。该模型将利用数码管的亮灭 - 抖音![]() https://www.douyin.com/video/7512681982040558888
https://www.douyin.com/video/7512681982040558888
目录
第一部分 认知奠基:神经网络原来这么简单
第 1 章 走进神经网络:AI 时代的核心技能
第 2 章 生物神经网络:智能的天然原型
第二部分 原理拆解:人工神经网络的底层逻辑
第 3 章 人工神经网络的基本结构:分层协作的 “智能团队”
第 4 章 核心组件解析:权重、偏置与激活函数
第 5 章 学习的本质:向前传播与反向优化
第三部分 实操实战:Excel 手搓神经网络
第 6 章 实操准备:Excel 必备基础操作
第 7 章 回归任务实战:车厘子价格预测模型
第 8 章 分类任务实战:数字 0-9 识别系统
第四部分 拓展提升:从入门到进阶
第 9 章 常见问题与调试技巧
第 10 章 神经网络的更多应用场景
第 11 章 进阶学习路径指南
第一部分 认知奠基:神经网络原来这么简单
第 1 章 走进神经网络:AI 时代的核心技能
-
- 生活中的神经网络:藏在身边的智能魔法
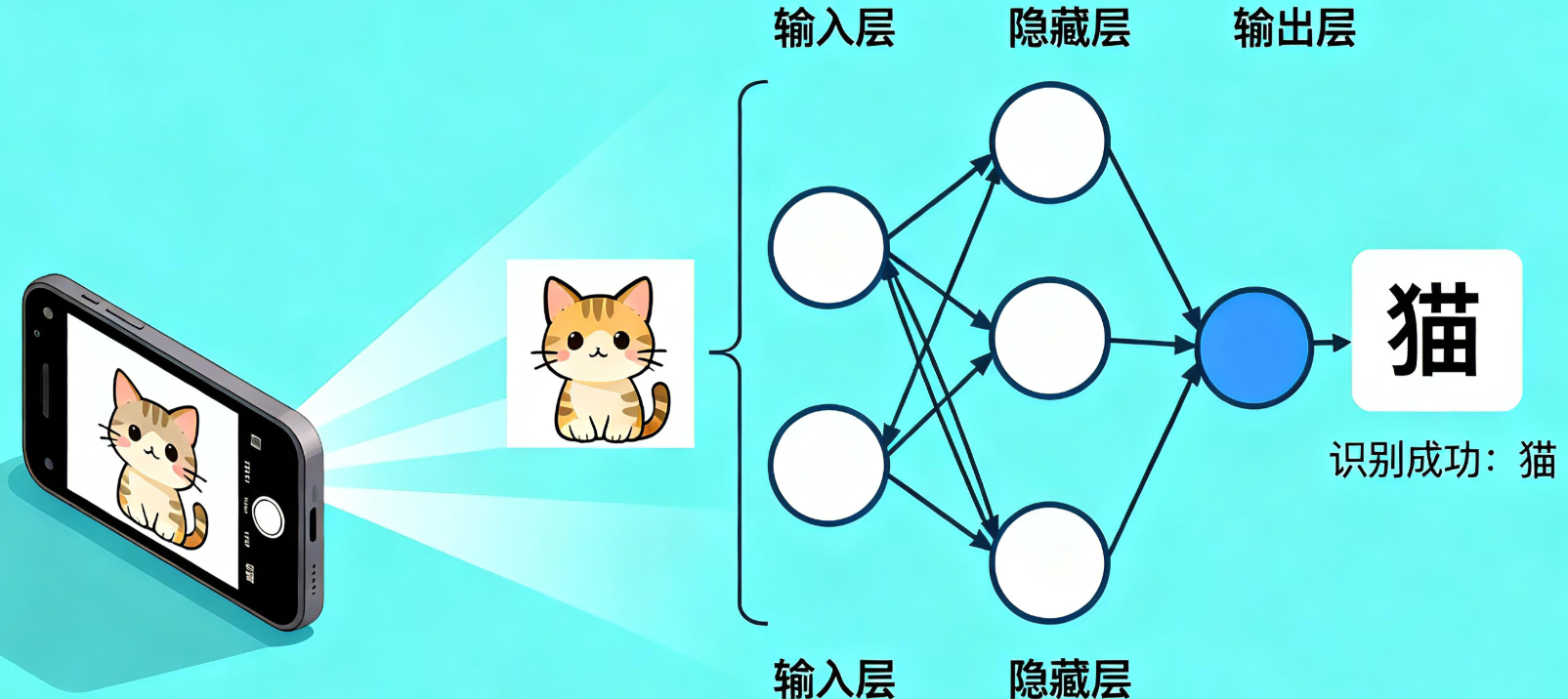
- 拍照识物如何快速认出 “猫”?语音助手为何能听懂你的指令?购物 APP 的精准推荐来自哪里?—— 答案都是神经网络。
- 神经网络是人工智能的 “核心骨架”,所有实现 “识别、判断、预测” 的智能应用,本质上都由它驱动。
- 神经网络≠复杂编程,不用掌握 Python、Java,用 Excel 就能搭建基础模型。
1.2 为什么要学神经网络?时代趋势下的能力升级
- 现实思考:工业机器替代了传统工人,而掌握 AI 工具的人总能占据优势 ——“抢走工作的不是 AI,而是掌握 AI 能力的人”。
- 学习价值:无论是职场提升(数据分析、预测决策)还是个人兴趣,神经网络都是理解 AI 的关键,且零代码学习门槛极低。
1.3 本书学习指南:零代码也能学透 AI
- 学习目标:掌握神经网络核心原理,能用 Excel 独立完成 “价格预测”“数字识别” 等实操任务。
- 学习路径:原理(生物→人工)→技术(传播→调参)→实操(回归→分类),循序渐进无压力。
- 工具准备:仅需 Microsoft Excel 2019 及以上版本或 WPS 表格,无需额外软件。
本章小结
本章通过生活场景让你感知神经网络的无处不在,明确其核心定位和学习价值,消除对 AI 的畏惧心理。记住:神经网络的本质是 “模仿人类学习过程的数学模型”,而 Excel 就是我们拆解这个模型的 “放大镜”。
第 2 章 生物神经网络:智能的天然原型
2.1 神经元:智能的基本单元
- 核心数据:人体约有 860 亿个神经元细胞,它们是构建智能的 “基础建材”。

- 功能解析:神经元像一个个 “信息处理器”,负责接收、处理和传递信号 —— 比如眼睛看到数字 “5”,就是通过神经元将视觉信号传递给大脑。
2.2 从 “孤立小岛” 到 “连接成网”:智能的形成过程

- 初始状态:新生儿的神经元如同大海中孤立的小岛,彼此没有连接,因此无法完成复杂的识别、判断任务。
- 连接逻辑:随着成长和学习,神经元通过 “突触”(类似桥梁)建立连接。每一次学习(如观察数字、练习技能)都会强化相关神经元的连接,就像在小岛之间架起更宽阔的桥梁。
2.3 案例具象化:数字 0-9 的识别密码
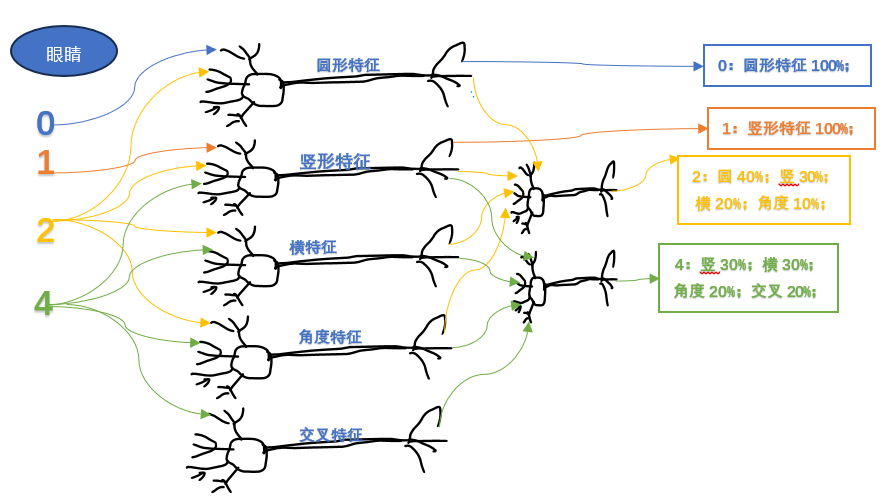
- 特征编码:大脑识别数字的核心是 “提取形状特征”—— 看到 “0” 会激活处理 “圆形” 的神经元,看到 “1” 会激活处理 “横、竖线” 的神经元,看到 “2” 会激活处理 “圆、横、竖、角度” 的神经元,看到 “4” 会激活处理 “横、竖、角度、交叉” 的神经元。
- 网络成型:反复观察数字后,处理同一数字特征的神经元连接会越来越稳固,形成专属 “识别模块”。哪怕数字的字体、大小、颜色变化,核心特征不变,对应的神经元网络就能被快速激活,实现准确识别。
2.4 神经可塑性:学习能力的底层密码
- 定义:生物神经网络通过 “学习和经验不断优化连接网络” 的能力,就是神经可塑性 —— 这是人类能终身学习的核心原因。
- 类比:就像肌肉越练越强,神经元连接越用越紧密。从小学习说话、走路,到长大后学开车、用电脑,本质都是神经元网络在 “升级优化”。

2.5 生物神经网络的启发:人工神经网络的设计原型

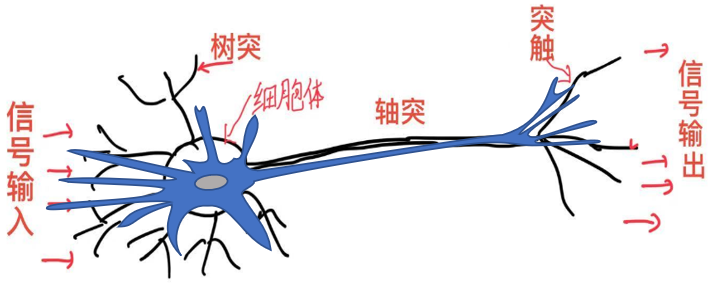
- 生物神经元的组成结构:
- 细胞体:包含细胞核,是神经元的代谢和控制中心。
- 树突(Dendrites):短而分支多的突起,用于接收其他神经元传递的信号(输入)。
- 轴突(Axon):长而单一的突起,用于将神经元的信号传递给其他神经元或效应器(如肌肉、腺体)。
- 突触(Synapse):神经元之间的连接结构。
神经元都是将电信号从一端传输到另一端,沿着轴突,将电信号从树突传到突触。然后,这些信号从一个神经元传递到另一个神经元。这就是身体感知光、声、触压、热等信号的机制。观察表明,神经元不会立即反应,而是会抑制输入,直到输入增强, 强大到可以触发输出。你可以这样认为,在产生输出之前,输入必须到达一个阈值。就像水在杯中——直到水装满了杯子,才可能溢出。
神经元不希望传递微小的噪声信号,而只是传递有意识的明显信号,单个神经细胞只有两种状态:兴奋和抑制;
- 核心映射:人工神经网络完全模仿生物神经网络的逻辑搭建:
|
生物神经网络 |
人工神经网络 |
|
神经元细胞 |
虚拟节点 |
|
突触连接强度 |
权重(W) |
|
神经可塑性 |
权重调整 |
|
特征识别模块 |
隐藏层处理 |
本章小结
本章是理解神经网络的 “钥匙”:生物神经网络的核心逻辑是 “连接成网 + 持续优化”,而人工神经网络就是对这一逻辑的数学模拟。记住 “860 亿神经元”“孤立的小岛”“神经可塑性” 三个关键词,后续理解人工神经网络的技术细节会事半功倍。
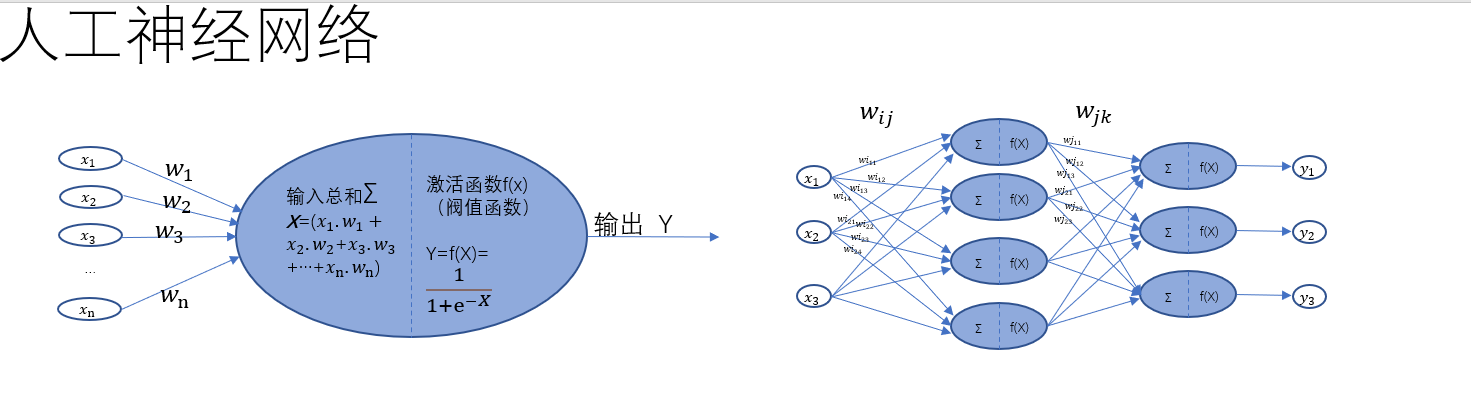
一、人工神经网络的核心定义与目标

- 定义:模拟生物神经网络的信息处理系统,由大量神经元(节点)连接组成,通过学习调整权重,构建适应特定任务的模型。
- 目标:实现类似人工智能的机器学习技术,如模式识别、数据分类、预测等。
二、生物神经网络的模拟维度

-
单个神经元层面
- 输入与信号累积:模拟生物神经元接收信号并累积的过程。
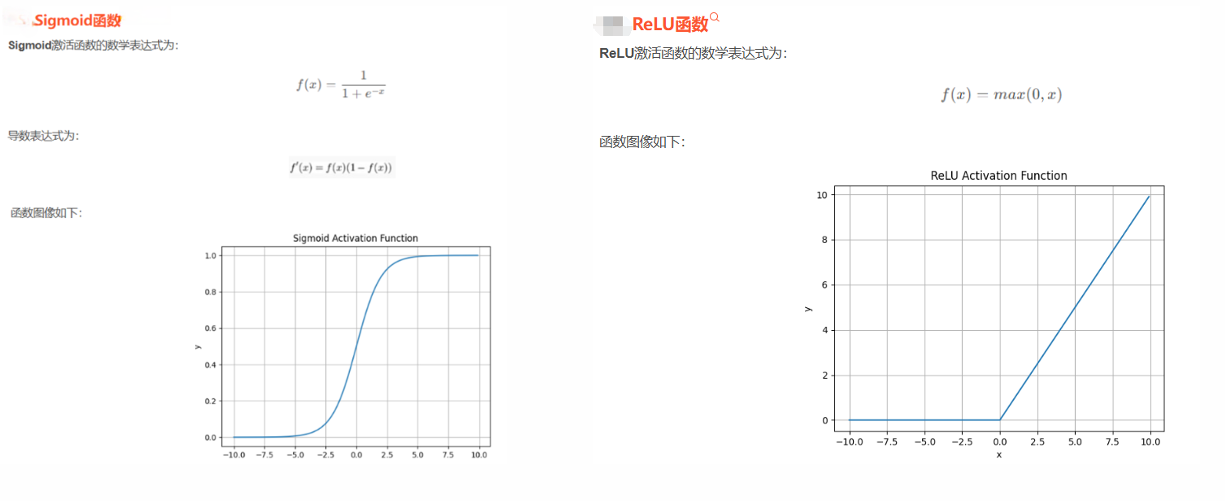
- 激活函数与阈值触发:类似生物神经元的阈值机制,通过激活函数决定是否触发输出。
-
系统网络层面
- 连接权重与神经可塑性:神经元间的连接权重对应生物突触强度,可通过学习调整(类似神经可塑性)。
-
学习机制层面
- 数据驱动的优化:通过大量数据训练调整权重,模拟生物神经网络通过经验强化连接的过程。
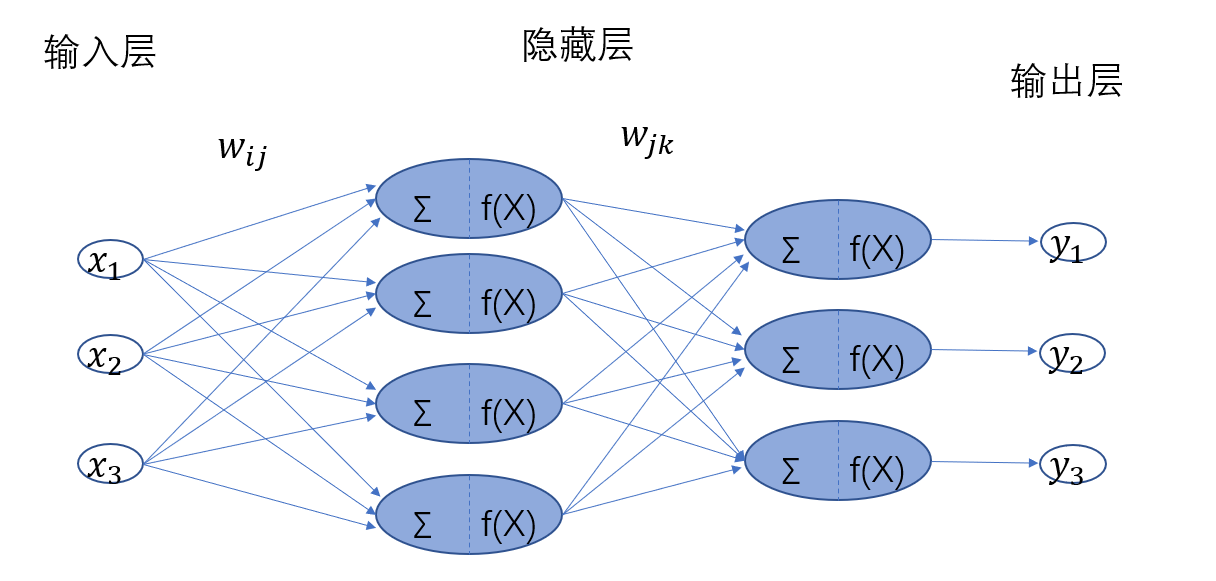
三、人工神经网络的架构组成
-
输入层
- 功能:接收原始数据(如图像像素、文本特征等),并进行预处理(向量化、归一化等)以提升训练效率。
-
隐藏层
- 位置:位于输入层与输出层之间,可有多层(深度神经网络中隐藏层更多)。
- 作用:对数据逐层抽象与特征提取,通过权重矩阵与前一层连接,并利用激活函数(如 ReLU、Sigmoid)引入非线性变换,学习复杂模式。
- 设计关键:神经元数量和层数需平衡,避免过拟合或欠拟合。
-
输出层
- 功能:根据任务生成预测结果,设计需匹配任务类型:
- 分类任务:神经元数量 = 类别数,常用 softmax 激活函数,输出分类概率。
- 回归任务:神经元数量为 1 或连续值,无激活函数或用线性激活。
- 其他任务(如生成、排序):结构依任务调整,输出需后处理(换算、解码等)。
- 功能:根据任务生成预测结果,设计需匹配任务类型:
四、核心特性与能力
-
灵活性与适应性:
- 通过新数据和算法不断优化权重,提升任务处理能力与准确性,是实现人工智能的关键。
-
模拟本质:
- 不仅模拟生物神经网络的物理结构(如树突 - 输入、突触 - 权重),更映射其学习逻辑,从简单信号处理向复杂任务求解升级。
权重调整是神经网络通过误差反向传播优化预测能力的核心过程,以下结合文档中的苹果价格预测案例,分步骤通俗解析其具体操作:
- 不仅模拟生物神经网络的物理结构(如树突 - 输入、突触 - 权重),更映射其学习逻辑,从简单信号处理向复杂任务求解升级。
五、初始化权重(随机赋值)
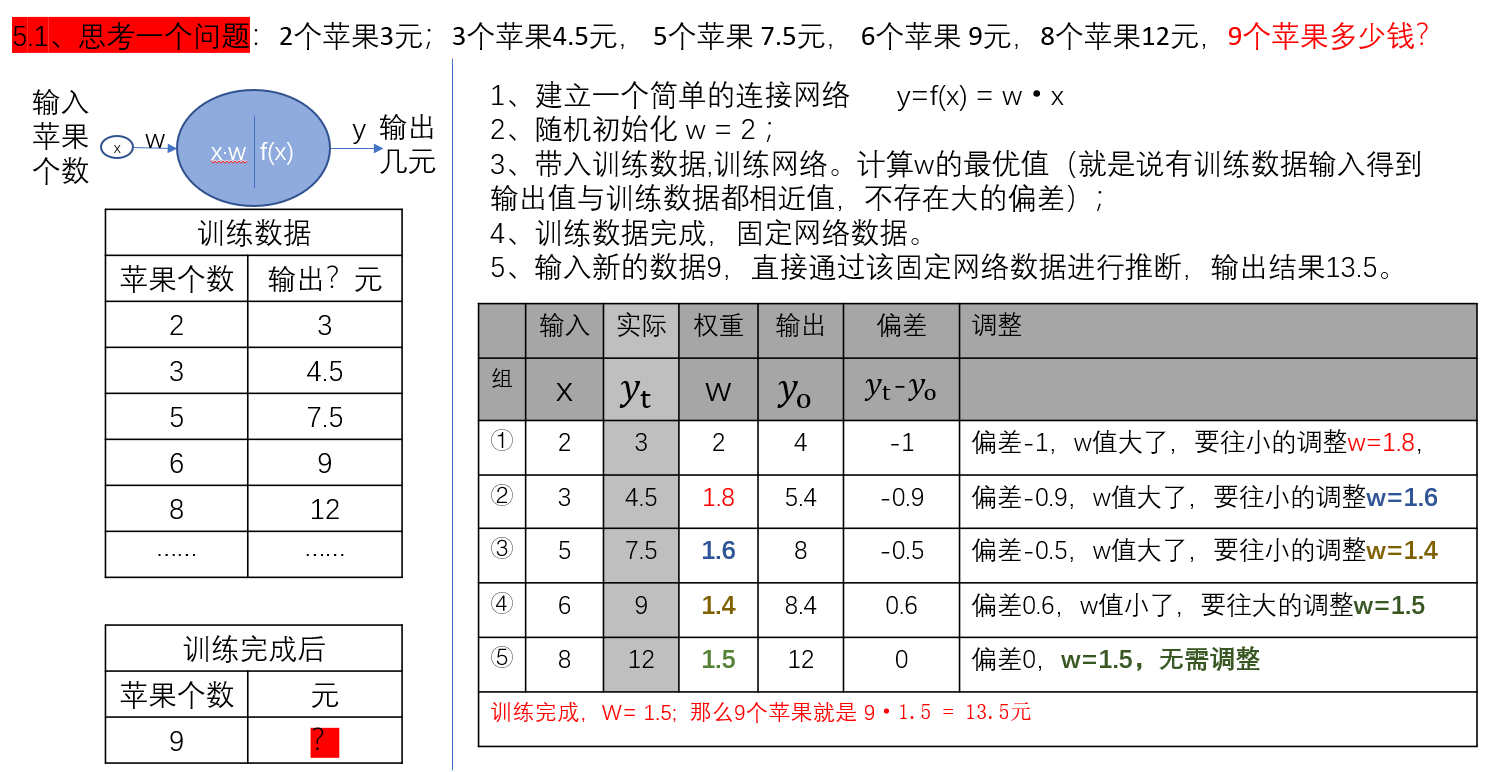
- 步骤:先给权重参数 w 随机设定一个初始值。
- 案例:预测苹果价格时,初始设 w=2。
- 目的:为后续训练提供起点,神经网络会从这个随机值开始 “试错” 学习。
- 步骤:将输入数据(如苹果个数 x)代入当前权重 w,计算输出预测值 yo。
- 案例:输入 x=2,w=2,前向传播算出 yo=2×2=4 元。
- 关键:此时预测值与实际值(如真实价格 yt=3 元)存在偏差,需通过偏差调整权重。
- 步骤:用实际值 yt 减去预测值 yo,得到误差 偏差=yt−yo。
- 案例:3−4=−1 元,说明预测值比实际值多 1 元,权重 w 设得太大。
- 作用:误差的正负和大小决定了权重调整的方向和幅度。
- 步骤:根据误差大小,按设定的步长(如 0.2)调整权重 w:
- 若误差为负(预测值 > 实际值),说明 w 偏大,需调小;
- 若误差为正(预测值 < 实际值),说明 w 偏小,需调大。
- 案例:
- 第一次误差 −1 元,w 从 2 调至 2−0.2=1.8;
- 第二次输入 x=3,误差 4.5−5.4=−0.9 元,w 调至 1.8−0.2=1.6;
- 第三次输入 x=5,误差 7.5−8=−0.5 元,w 调至 1.6−0.2=1.4;
- 第四次输入 x=6,误差 9−8.4=0.6 元(预测值 < 实际值),w 调至 1.4+0.2=1.6;
- 最终取中间值 w=1.5 时,误差为 0,确定最优权重。
- 核心逻辑:误差像 “指南针”,反向传播根据它指引的方向逐步修正权重,使预测值逼近实际值。
- 步骤:用多组训练数据重复 “前向传播→计算误差→反向调整权重” 的过程,直到误差足够小(如接近 0)或达到预设训练次数。
- 案例:用 5 组苹果价格数据反复训练,最终 w=1.5 时,对所有训练数据的预测误差为 0,模型收敛。
- 目的:通过多次迭代,让权重参数适应数据规律,使神经网络具备对新输入(如 9 个苹果)的准确预测能力。
六、问题背景:从苹果价格预测说起
之前用苹果价格预测时,我们靠手动根据偏差(比如预测 4 元实际 3 元)调整权重(w 从 2 调到 1.8),但这种方法有个问题:步长(0.2)固定,可能导致权重在 1.4 和 1.6 之间 “反复横跳”,找不到最精准的 1.5。这时候就需要一个更系统的工具 ——误差函数,来衡量预测值(yₒ)和实际值(yₜ)的差距,帮我们找到最优权重。
七、三种误差函数的对比:哪种调权重最靠谱?

1. 差值误差(e₁ = yₜ - yₒ)


- 做法:直接用实际值减预测值,比如苹果例子中误差是 3-4=-1 元。
- 问题:它的 “导数”(调整权重的方向指引)是个固定值(只和输入数据有关,比如苹果个数 x),就像瞎指挥 —— 不管误差多大,都让权重按固定方向调,永远调不到最优解。
- 比喻:像蒙眼走路,只知道 “左拐” 或 “右拐”,但不知道拐多少,永远走不到终点。
2. 绝对值误差(e₂ = |yₜ - yₒ|)


- 做法:取误差的绝对值,比如误差 - 1 元就当 1 元处理。
- 问题:当误差为 0 时(yₜ=yₒ),它的 “导数” 突然没方向了(数学上叫 “不可导”),就像开车遇到十字路口没路标,容易停在原地不动。
- 优点:对异常值(比如突然出现的天价苹果)不敏感,因为绝对值不会放大误差。
- 比喻:知道误差大小,但接近目标时容易 “刹车失灵”,停在附近兜圈子。
3. 均方误差(MSE,e₃ = (yₜ - yₒ)²)
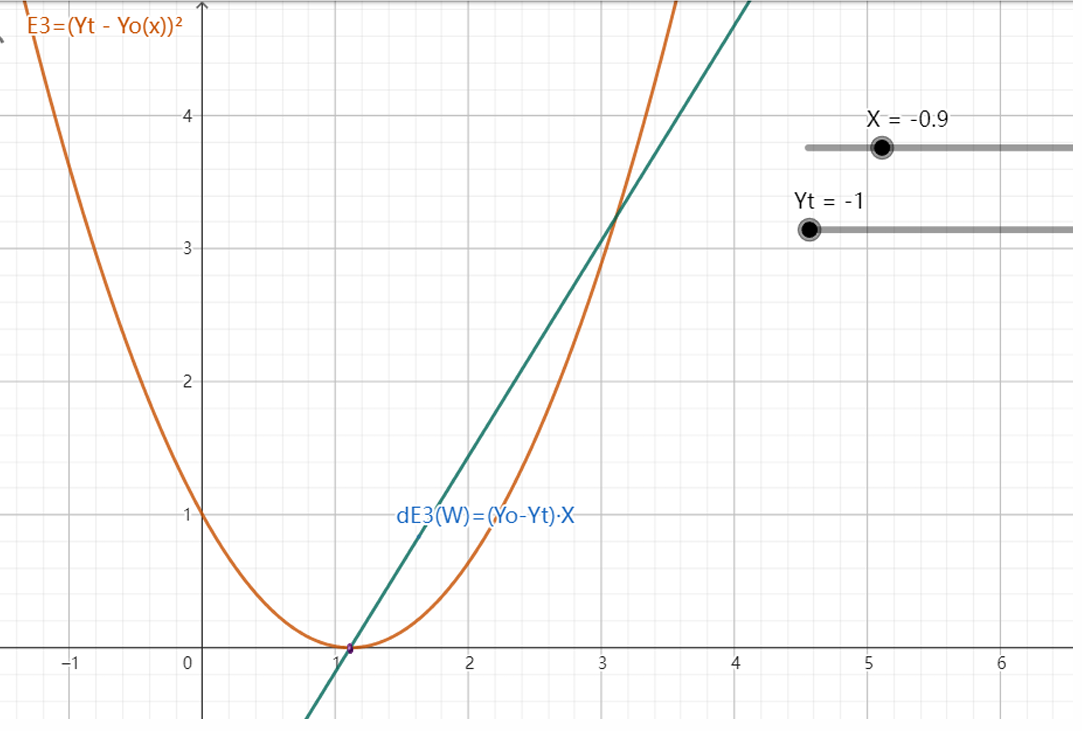

- 做法:把误差平方,比如误差 - 1 元就算 1²=1。
- 优点:
- 误差越大,平方后差距更明显(比如误差 2 元会算成 4,比误差 1 元的 1 大很多),能让模型在误差大时 “猛调” 权重,误差小时 “慢调”,像智能减速一样精准逼近目标。
- 数学上处处可导,导数(梯度)永远有明确方向,不会中途 “迷路”。
- 比喻:像开导航,误差大时提示 “快拐”,接近目的地时提示 “慢拐”,稳稳当当开到终点。
八、实际应用怎么选误差函数?
- 回归任务(比如房价、温度预测,数据干净没异常):优先用均方误差(MSE),因为它调权重最稳,能精准收敛。
- 回归任务但有异常值(比如数据里混了天价房):用绝对值误差或Huber 损失(结合前两者优点),避免异常值让模型跑偏。
- 分类任务(比如区分猫狗):别用 MSE,改用交叉熵损失,因为 MSE 在分类问题里可能 “反应迟钝”,调不动权重。
九、核心结论
误差函数就像神经网络的 “导航仪”,而均方误差(MSE)因为能根据误差大小智能调整权重方向和幅度,成为回归问题的首选。选对误差函数,神经网络才能像开了导航一样,精准找到最优解,让预测越来越准。
不用写代码,只用 Excel 表格就能搭建一个神经网络模型,来预测车厘子的价格,还对比了回归任务和数字识别的区别。具体内容如下:
十、数据准备:车厘子价格里的规律
- 已知数据:1 箱 249.79 元,2 箱 498.33 元,3 箱 744.42 元,10 箱 2310 元。发现买得越多,单箱价格越便宜(商家打折策略)。
- 输入与输出:输入 x 是购买箱数,输出 y 是总价,目标是用神经网络预测不同箱数的总价。
十一、模型搭建:用 Excel “搭积木” 做预测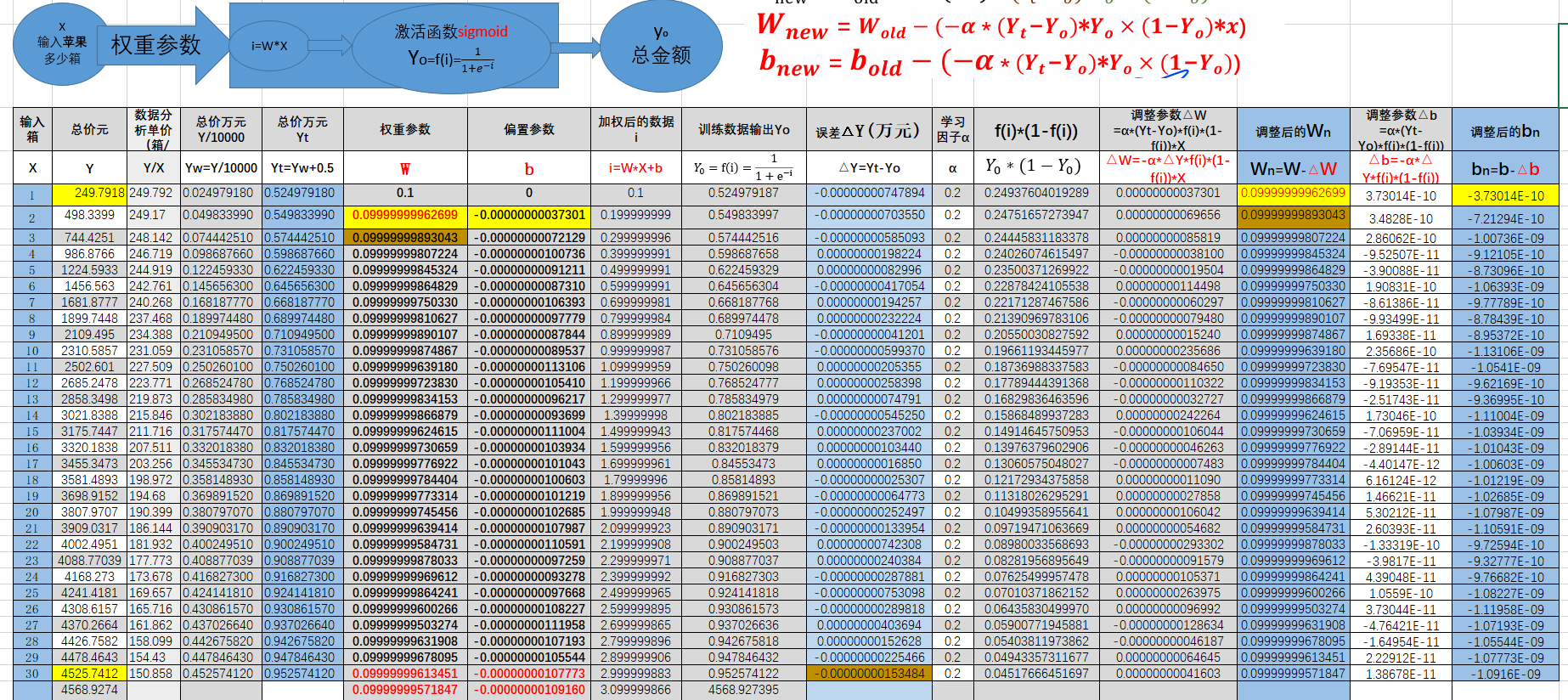
- 核心公式:预测值Yo = 权重 (w)× 箱数 (x) + 偏置 (b),再通过 sigmoid 函数 “加工” 结果。
- sigmoid 函数:像个 “过滤器”,把数值压缩到 0-1 之间,公式是
 。
。 - 误差计算:用均方误差(MSE),即 (实际价 - 预测价)²,误差越小说明预测越准。
- sigmoid 函数:像个 “过滤器”,把数值压缩到 0-1 之间,公式是
十二、Excel 操作:分分钟变 “AI 工程师”
-
数据预处理:
- 把总价除以 1 万,再加上 0.5,让数据落在 0.5-1 之间(适配 sigmoid 函数的输出范围)。
- 举例:1 箱 249.79 元→249.79/10000+0.5≈0.525。
-
设置公式:

- 在 Excel 里输入箱数 x,用公式算加权和 i=w*x+b,再算
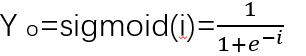 。
。 - 算误差
 实际价 - 预测价,再算中间值
实际价 - 预测价,再算中间值 (用于更新参数)。
(用于更新参数)。
- 在 Excel 里输入箱数 x,用公式算加权和 i=w*x+b,再算
-
调整参数:
- 学习率 α=0.2(控制调整幅度),权重更新公式:


- 偏置 b 的更新公式,只是不带 x。


- 学习率 α=0.2(控制调整幅度),权重更新公式:
-
迭代优化:重复用不同箱数数据计算,不断更新 w 和 b,直到误差 delta_y 接近 0。
- 比如初始 w=0.2,b=0,算完 1 箱后调整 w,再用 2 箱数据继续算,直到参数让预测价和实际价几乎一样。
十三、预测应用:算 31 箱多少钱?
- 找到最优 w 和 b 后,输入 x=31,算 i=w*31+b,再用 sigmoid 得到预测值,最后还原成实际价格(减去 0.5 再乘以 1 万)。
- 比如算出来 y_o=0.45,实际总价 =(0.45-0.5)*10000?不对,应该是反过来:预处理是 y=(实际价 / 10000)+0.5,所以还原时实际价 =(y_o-0.5)*10000。假设 y_o=0.45,实际价 =(0.45-0.5)*10000=-500,这显然不对,说明可能预处理步骤需要再确认,但核心逻辑是通过反向推导还原价格。
十四、核心总结
- 不用代码也能玩 AI:用 Excel 表格的公式功能,就能实现神经网络的 “前向传播算预测→反向传播调参数” 全过程。
- 关键技巧:数据归一化(让函数好用)、迭代调参(像拧螺丝一样慢慢调准)、均方误差(衡量好坏的标准)。
- 应用场景:适合商业价格预测,帮商家分析批量折扣策略,或者其他需要找 “数量 - 价格” 关系的场景。
教大家用 Excel 不用写代码,就能搭建一个识别数字 0-9 的神经网络模型,就像用电子表的数码管亮灭来认数字。具体咋做呢?往下看:

十五、数据准备:把数字变成 “灯语”
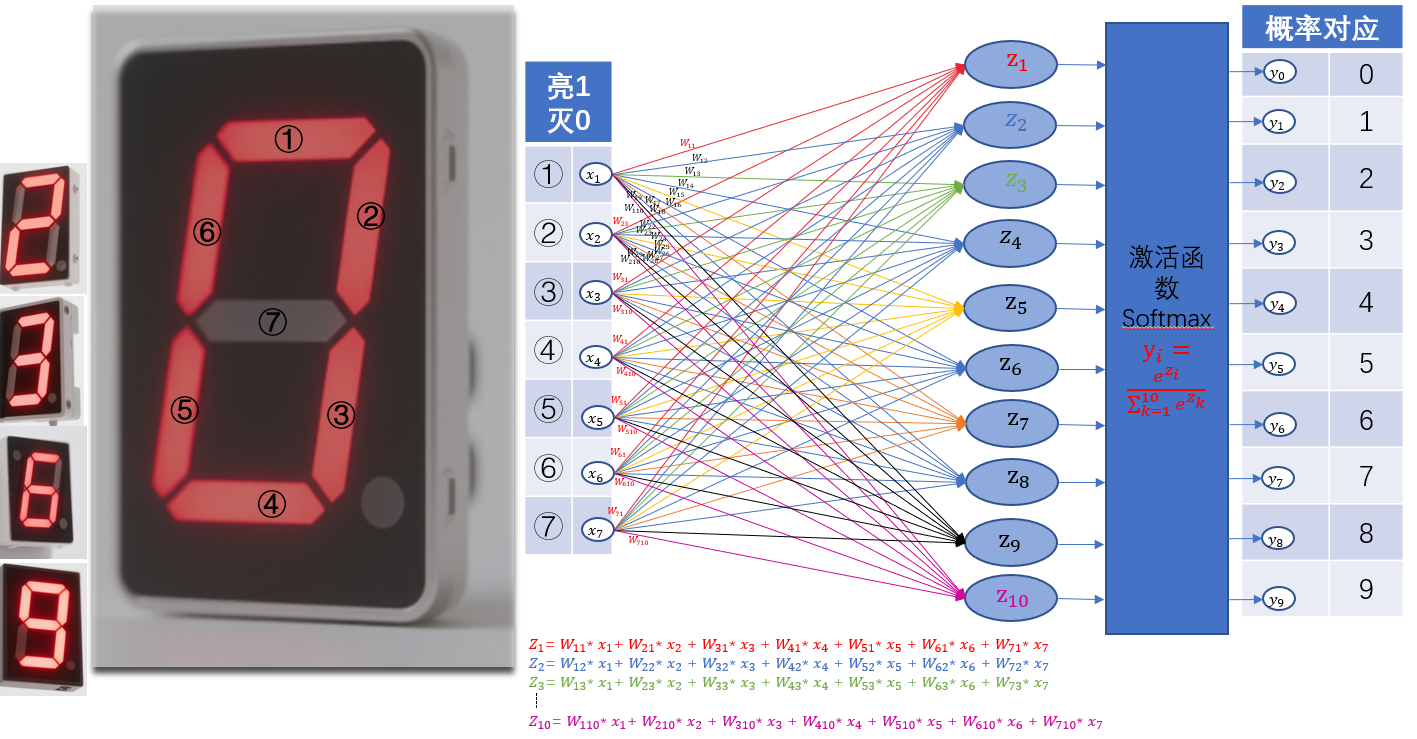
- 数码管长啥样? 像电子表上的数字,由 7 段 LED 灯(a 到 g)组成,不同段亮灭能拼出 0-9。比如:
- 数字 0:a、b、c、d、e、f 亮,g 灭→编码为1111110
- 数字 1:b、c 亮,其他灭→编码为0110000
- 输入数据:把每段亮灭转成二进制(亮 = 1,灭 = 0),形成 7 位 “灯语” 向量,比如数字 0 的输入就是 [1,1,1,1,1,1,0]。
十六、模型搭建:给 Excel 装上 “认数字大脑”
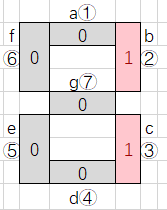


- 输入层:7 个 “入口”,对应 7 段灯的亮灭状态。


- 输出层:10 个 “出口”,对应 0-9 十个数字,用 Softmax 函数算每个数字的概率(比如输出 [0.1,0.8,0.05…],表示 80% 概率是数字 1)。
- 核心公式:
- 权重矩阵 W(10×7)× 输入向量 X(7×1)= 得分向量 Z(10×1)
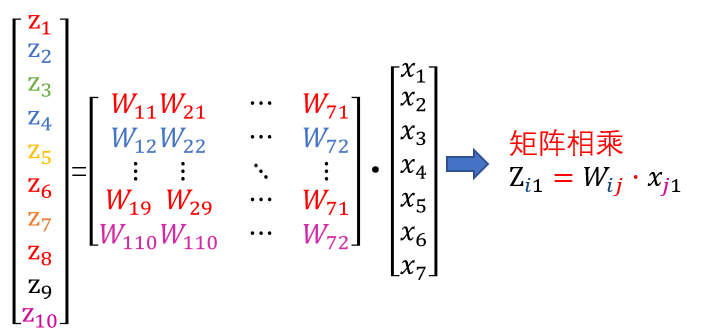
- Softmax (Z) 把得分转成概率,比如数字 i 的概率 = e^Z_i /(e^Z₀+…+e^Z₉)

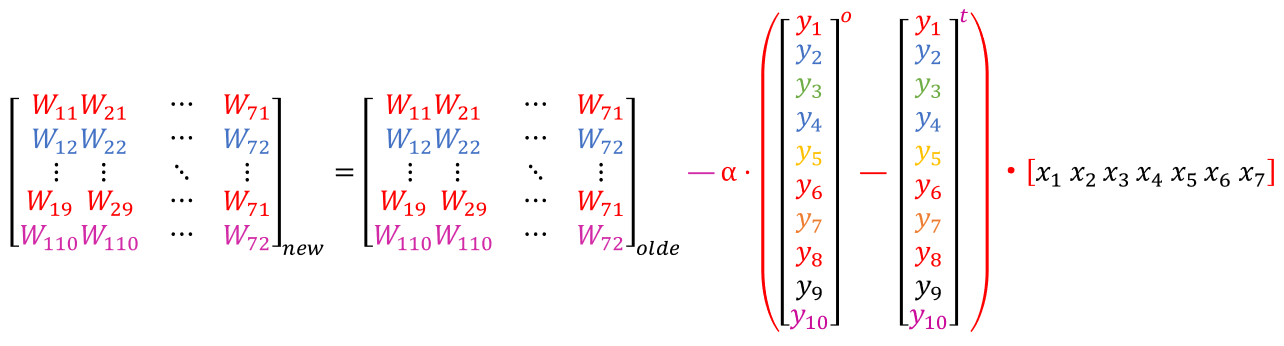
- 权重更新公式:(使用交叉熵损失函数)

- 权重矩阵 W(10×7)× 输入向量 X(7×1)= 得分向量 Z(10×1)
十七、关键技巧:让模型 “学” 得准
-
One-Hot 编码:
- 把数字变成 “独热向量”,比如数字 0 对应 [1,0,0,…,0],数字 1 对应 [0,1,0,…,0],像给每个数字发唯一 “身份证”,避免混淆。
-

-
损失函数:
- 用 “交叉熵” 衡量预测概率和实际数字的差距(比如预测数字 0 的概率是 0.3,实际是 1,交叉熵会算出差值,指导调整权重)。
-
权重更新:
- 像玩猜数字游戏,错了就调整 “线索”:
新权重 = 旧权重 - 学习率 ×(预测概率 - 实际 One-Hot 向量)× 输入向量转置
- 像玩猜数字游戏,错了就调整 “线索”:
十八、Excel 操作:手把手 “搓” 模型
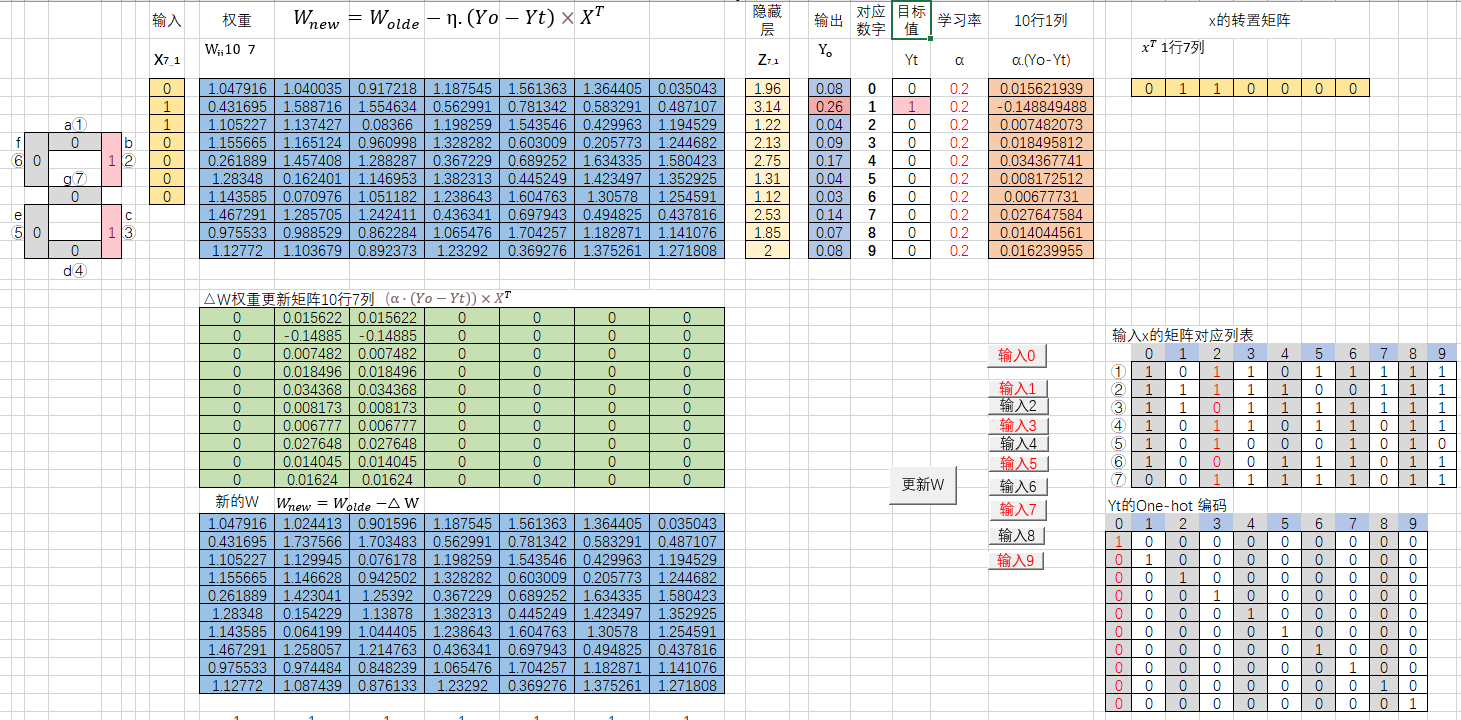
- 输入数据:在 Excel 里按编码规则输入 7 段灯的 1 和 0,比如数字 0 就输 6 个 1 和 1 个 0。
- 算概率:用 Softmax 公式算每个数字的概率,比如 = EXP (Z_i)/SUM (EXP (Z₀:Z₉))。
- 调权重:根据交叉熵算误差,用更新公式迭代调整 W,直到预测概率最高的位置对应正确数字(比如输入数字 7 时,输出向量第 7 位概率最大)。
- 理想的一组权重参数Wij
1.04792 1.04004 0.91722 1.18755 1.56136 1.3644 0.03504 0.43169 1.58872 1.55463 0.56299 0.78134 0.58329 0.48711 1.10523 1.13743 0.08366 1.19826 1.54355 0.42996 1.19453 1.15567 1.16512 0.961 1.32828 0.60301 0.20577 1.24468 0.26189 1.45741 1.28829 0.36723 0.68925 1.63433 1.58042 1.28348 0.1624 1.14695 1.38231 0.44525 1.4235 1.35292 1.14358 0.07098 1.05118 1.23864 1.60476 1.30578 1.25459 1.46729 1.2857 1.24241 0.43634 0.69794 0.49482 0.43782 0.97553 0.98853 0.86228 1.06548 1.70426 1.18287 1.14108 1.12772 1.10368 0.89237 1.23292 0.36928 1.37526 1.27181
十九、验证结果:模型靠谱吗?
- 用训练好的权重测试数字 7、8、9:
- 数字 7 输入后,输出向量第 7 位概率达 0.24(最高),正确!
- 数字 8 输出第 8 位概率 0.21(最高),正确!
- 数字 9 输出第 9 位概率 0.23(最高),正确!
- 说明模型通过调整权重,学会了根据数码管亮灭状态识别数字。
二十、和上节课的区别(车厘子价格预测)
- 回归任务(上节课):输出是连续数值(如价格),用均方误差算误差,权重调整看数值差。
- 分类任务(本节课):输出是类别(如数字 0-9),用交叉熵算概率差,Softmax 把得分转成概率,One-Hot 编码让类别更清晰。
总结
用 Excel 搭数字识别模型,就像教小孩认数字:先把数字拆成灯语(数据预处理),再用 Softmax 猜哪个数字可能性大(算概率),错了就根据交叉熵调整 “判断标准”(权重),最后小孩(模型)就能准确认数字啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)