代码破晓:2014-第一集:穿越与第一个“注意力火花”
《代码破晓:2014》第一集摘要(150字) 2024年的AI工程师林枫意外穿越回2014年,遇见正为LSTM模型瓶颈发愁的研究生苏小雨。通过给硬件工程师老王用"查字典接力赛"等生活比喻,林枫逐步揭示注意力机制的核心思想:让每个词直接"关注"句子中的关键部分,而非强制顺序处理。三人通过计算"猫追老鼠"的简单示例,验证了注意力权重的合理性。

《代码破晓:2014》——当穿越者遇到天才少女,他们用比喻改变AI史,让深度学习不再有门槛。
“如果你曾觉得Transformer高不可攀,这个故事将为你点燃第一束光”
核心亮点
- 硬核知识软着陆:每集一个核心概念,通过生活比喻+剧情冲突自然展现
- 真实技术演进:从3×3矩阵手工计算到完整模型训练,再现技术发展全路径
- 多元角色共鸣:天才研究者+实践工程师+跨界学习者,总有一个像你
- 历史与未来交织:在改变历史的伦理困境中,思考技术本质
适合人群
- 🤔 对Transformer好奇但被公式吓退的初学者
- 🔧 想深入理解模型本质的实践工程师
- 🧠 热爱技术但讨厌枯燥讲解的跨界学习者
- 📚 寻找教学灵感的AI教育者
- 🚀 相信技术民主化的理想主义者
“最伟大的发明,是让复杂变得简单”——加入这场2014年的代码破晓,亲手点亮AI历史上的那个清晨。
现在,让我们回到第一集的开头,让故事正式开始……
下面是我写主题曲:
《代码破晓:2014》主题曲(大家评选一下):
破晓的公式: 歌曲地址

第一集:穿越与第一个“注意力火花”
第一幕:2024年的雷雨夜
林枫最后一次检查着屏幕上跳动的损失曲线。
“多模态对齐还是不够完美……”他揉了揉太阳穴,实验室里只有服务器散热风扇的低鸣。窗外闪电划破夜空,暴雨敲打着玻璃。他正在调试一个最新版本的视觉-语言Transformer模型,试图让AI更准确地理解“云层中透出的夕阳余晖将城市染成琥珀色”这样的诗意描述。
就在他伸手去调整一个松动的电源接口时——
刺眼的蓝光。
撕裂感。
像是被扔进了一个由破碎代码组成的漩涡。
第二幕:2014年的阳光
“同学?同学你没事吧?”
林枫睁开眼,首先看到的是一块白板,上面写满了数学公式。不是他熟悉的Transformer变体方程,而是……标准的LSTM推导。
他转过头,看见一个扎着马尾辫的女生正关切地看着他,手里拿着一支白色记号笔。她穿着简单的格子衬衫和牛仔裤,眼睛很亮。
“我是苏小雨,计算机系研二的。你刚才在实验室门口晕倒了。”她递过一瓶矿泉水,“你是来找王教授的吗?他今天不在。”
林枫猛地站起,环顾四周。笨重的液晶显示器、Windows 7的启动画面、桌上散落的论文打印稿——标题赫然是《基于LSTM的机器翻译模型改进》。
他冲向最近的一台电脑,右下角日期:2014年6月12日。
十年。
他回到了Transformer诞生前的世界。
“你……还好吗?”苏小雨的声音带着疑惑。
林枫深吸一口气,强迫自己冷静。他是个工程师,解决问题的人。“抱歉,可能低血糖了。你在做机器翻译?”
苏小雨的眼睛黯淡了一下:“嗯,但卡住了。我的LSTM模型在测试集上的BLEU值只有25.7,已经两个月没有提升了。”
她指向白板上的一行公式:“长句子一塌糊涂。比如翻译‘虽然昨天天气不好,但我们还是决定去爬山,因为天气预报说今天会放晴,结果真的出了太阳,山顶的风景美得令人窒息’这样的句子,到后半部分就完全乱码。”
第三幕:序列的困境
林枫走到白板前,本能地开始分析:“这是长期依赖问题。LSTM的记忆单元理论上能记住长期信息,但实际上随着序列增长,梯度会消失或爆炸,重要的早期信息在传递过程中被稀释了。”
苏小雨惊讶地看着他:“你懂这个?但……我的梯度裁剪和更好的初始化都试过了,效果有限。”
“因为根本问题不在工程技巧,而在架构。”林枫几乎脱口而出“Transformer”这个词,硬生生咽了回去。
这时,实验室门被推开,一个穿着工装服的中年男人探进头来:“小雨,你要的服务器内存条我找到了——哟,有客人?”
“王师傅!”苏小雨介绍道,“这是我们学院的硬件工程师老王,我模型训练全靠他维护机器。这是……呃,林枫。”
老王爽朗一笑:“叫我老王就行,大专毕业早,在这儿干了十几年了。你们聊啥高深话题呢?”
林枫心中一动——这正是他需要面对的“听众”,一个聪明但非理论背景的实践者。
“我们在聊怎么让机器更好地翻译长句子。”林枫说。
老王挠挠头:“这不就是让电脑记住前面说了啥吗?有啥难的?”
第四幕:第一个比喻——查字典的困境
“王师傅,我打个比方。”林枫拿起一支笔,“假设您要翻译一本英文手册,但只能用一个方法:从头开始读,读一个单词翻译一个单词,而且只能靠脑子记住前面所有内容。”
老王皱眉:“那读到后面,前面的早忘光了!”
“正是!”林枫在白板上画了一条长线,“这就是RNN和LSTM的核心问题——它们本质上是‘顺序处理器’。每个词必须等前一个词处理完才能处理,信息必须通过一个叫做‘隐藏状态’的狭窄通道传递。”
苏小雨点头:“就像接力赛,信息是一根接力棒,跑得越远,掉棒或变形的风险越大。”
“但人类不是这样工作的。”林枫说,“我们看书时,如果忘了前面的人物关系,会翻回去看。听到长句子时,我们会自动关注关键部分——‘谁’对‘谁’做了‘什么’。”
老王似乎明白了些:“你是说,得让电脑也能‘翻回前页’?”
第五幕:“注意力”的火花
苏小雨突然眼睛一亮:“等等,你刚才说的‘自动关注关键部分’……这让我想起认知心理学里的‘注意力机制’。但那是描述人脑的,怎么用在模型里?”
时机到了。
林枫的心跳加快。他知道2014年已经有初步的注意力思想,但还没有人将其系统化为模型的核心架构。
“如果我们不强迫模型必须通过一个固定通道传递所有信息呢?”他缓缓说道,“如果我们让每个词在处理时,都能直接‘看到’句子中所有其他词,但可以选择性地‘关注’其中某些词呢?”
苏小雨手中的记号笔停在了半空。
“你的意思是……”她声音有些颤抖,“打破序列的顺序处理?让每个位置都能直接访问所有位置的信息?”
“但这样计算量不会爆炸吗?”老王务实地说,“一句20个词的话,每个词都要看其他19个词,这组合也太多了。”
林枫笑了:“王师傅问到点子上了。关键是‘选择性’——不是平等看待所有词,而是快速判断哪些词更重要。就像您在仓库找零件,不会挨个查看每个货架,而是直接去对应编号的区域。”
第六幕:从直觉到公式
苏小雨已经扑到白板前,擦掉一部分公式,开始快速书写:“假设每个词有一个向量表示……当处理当前位置i时,我们需要一个方法计算i与所有位置j的‘相关度’……”
“相关度怎么定义?”林枫引导道。
“点积?”苏小雨尝试,“向量的点积可以衡量相似度。如果词向量经过良好训练,那么语义相关的词应该有更高的点积得分。”
“然后需要归一化,把得分变成权重。”林枫补充。
苏小雨写下softmax函数:“对,这样所有位置的权重加起来是1,就像概率分布……然后我用这些权重对所有词的向量做加权平均!”
她的笔迹越来越快:“所以位置i的新表示 = ∑[所有位置j的权重(i,j) × 位置j的原始向量]。”
白板上出现了一个简洁的公式:
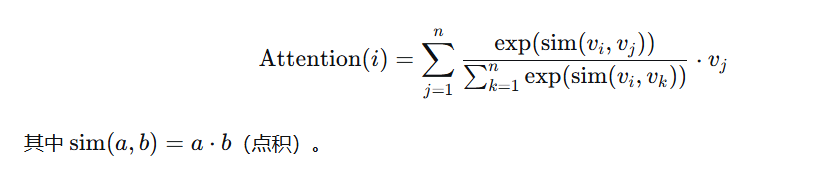
实验室里突然安静了。
第七幕:第一个具体例子
老王挠挠头:“看着还是有点抽象……”
“我们来实际算一下。”林枫说,“假设三个词:‘猫’、‘追’、‘老鼠’,它们的简单向量是——”
他在白板上写下:
- 猫 = [1, 0, 0.5]
- 追 = [0, 1, 0]
- 老鼠 = [0.5, 0, 1]
“现在计算‘追’对每个词的注意力权重。先算相似度:”
- sim(追, 猫) = [0,1,0]·[1,0,0.5] = 0
- sim(追, 追) = [0,1,0]·[0,1,0] = 1
- sim(追, 老鼠) = [0,1,0]·[0.5,0,1] = 0
“然后softmax:”
- 权重(追→猫) = exp(0)/(exp(0)+exp(1)+exp(0)) ≈ 0.2
- 权重(追→自己) = exp(1)/(…) ≈ 0.6
- 权重(追→老鼠) = exp(0)/(…) ≈ 0.2
“所以‘追’的新向量 = 0.2×[1,0,0.5] + 0.6×[0,1,0] + 0.2×[0.5,0,1] = [0.3, 0.6, 0.3]”
苏小雨盯着结果:“它保留了‘追’自己的核心特征(中间的1变成了0.6),但也融入了‘猫’和‘老鼠’的信息……这很合理!动词‘追’应该知道谁在追、追谁。”
老王凑近看了半天,突然一拍大腿:“我有点懂了!这就像……每个词都能开个小会,问问其他词:‘喂,你们谁跟我关系大?我多听点谁的。’”
林枫和苏小雨对视一眼,笑了。这个比喻意外地精准。
第八幕:风暴前的平静
窗外天色渐暗,实验室的灯自动亮起。
苏小雨已经写了三块白板,全是推导和问题:“但这是最简单的版本。实际中,向量维度很高,点积可能会过大或过小,需要缩放……还有,现在的计算是每个词独立进行的,但我们需要考虑位置信息,否则‘猫追老鼠’和‘老鼠追猫’就无法区分……”
她转身看着林枫,眼神复杂:“这些想法……你是怎么想到的?我读过几乎所有相关论文,没人提出过这样完整的框架。”
林枫无法回答真相。他只能说:“我……做过一些思考。但这还只是开始,苏同学。这个最简单的‘注意力’计算有很多问题需要解决:计算效率、位置信息、如何堆叠多层、怎么结合到编码器-解码器框架……”
老王看了看表:“得,六点半了。我先下班,你们俩继续‘革命’吧。不过小林啊,”他拍拍林枫的肩膀,“你这个想法有点意思。小雨这几个月愁眉苦脸的,今天头一回见她眼睛发亮。”
老王离开后,实验室里只剩下两人。
苏小雨轻声说:“如果这个方向真的能走通……可能会改变一切。机器翻译、语音识别、文本理解……所有序列任务。”
林枫望向窗外2014年的校园,远处有学生骑着自行车穿过林荫道。他知道,改变的不只是技术,还有这个时代的认知边界。
“我们需要一个名字。”苏小雨说,“叫它……‘自注意力’怎么样?因为是一个序列内部自己关注自己。”
林枫的心脏猛地一跳——历史在这里出现了微妙的偏差,但核心思想正朝着熟悉的方向前进。
“很好的名字。”他说,“但今晚先到这里吧。我们有了火柴,但要生起火焰,还需要更多东西:矩阵运算的并行化、位置编码、多头机制……”
苏小雨拿起背包,在门口停顿:“你明天还会来吗?”
“会。”林枫说,“我们刚刚点燃了第一颗火花,还有很多黑暗需要照亮。”
第一集知识点总结
-
序列建模的根本困境:
- RNN/LSTM的序列处理本质:必须逐词处理,信息通过狭窄的隐藏状态通道传递
- 长期依赖问题:梯度消失/爆炸导致模型难以记住远处信息
-
注意力的核心直觉:
- 人类处理信息不是严格的顺序,而是可以“翻回前页”
- 关键思想:让每个位置可以直接访问所有位置,但通过权重选择性关注
-
最简注意力计算:
- 步骤1:计算查询位置与所有位置的相似度(如点积)
- 步骤2:用softmax将相似度转为权重(和为1的概率分布)
- 步骤3:用权重对所有位置的向量做加权平均
- 公式: Output i = ∑ j softmax ( sim ( v i , v j ) ) ⋅ v j \text{Output}_i = \sum_j \text{softmax}(\text{sim}(v_i, v_j)) \cdot v_j Outputi=∑jsoftmax(sim(vi,vj))⋅vj
-
朴素注意力的问题(为下一集铺垫):
- 缺乏位置信息(“猫追老鼠” vs “老鼠追猫”)
- 点积可能数值不稳定
- 没有区分查询、键、值的概念
- 计算复杂度为 O ( n 2 ) O(n^2) O(n2),但实际有优化空间
当林枫独自走在2014年的夜色中时,他摸了摸口袋——没有手机,只有几张零钱。这个时代还没有PyTorch,没有TensorFlow,甚至CUDA生态都还在早期。他们可能要手写CUDA内核,要从零实现自动微分……
但当他抬头看见实验室窗口还亮着的灯时,他知道,苏小雨一定还在白板前演算着。
火柴已经点燃。接下来,他们需要用它点燃整个森林。
(第一集完)
下集预告:老王提出尖锐的计算效率问题,团队发现朴素注意力的致命缺陷。林枫将引入“查询-键-值”三元组,而苏小雨从数学上证明为什么需要缩放点积。第一个真正的注意力模块将在Python+NumPy中诞生……
版权声明
代码破晓:2014和主题曲和片尾曲以及相关封面图片等 ©[李林][2025]。本作品采用 知识共享 署名-非商业性使用 4.0 国际许可协议 进行授权。
这意味着您可以:
- 在注明原作者并附上原文链接的前提下,免费分享、复制本文档与设计。
- 在个人学习、研究或非营利项目中基于此进行再创作。
这意味着您不可以:
- 将本作品或衍生作品用于任何商业目的,包括企业培训、商业产品开发、宣传性质等。
如需商业用途或宣传性质授权,请务必事先联系作者。
作者联系方式:[1357759132@qq.com]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)