Browser-Use 技术架构分析
Browser-Use (源码地址:https://github.com/browser-use/browser-use) 是一个基于 LLM(大语言模型)和 CDP(Chrome DevTools Protocol)的异步 Python 浏览器自动化库,旨在让 AI 智能体能够自主导航网页、与元素交互并完成复杂任务。该库采用事件驱动架构,通过 LLM 驱动的决策循环实现智能化的浏览器操作。Browser-Use 支持多种 LLM 提供商(OpenAI、Anthropic、Google、Groq 等),提供了完整的浏览器自动化能力,包括页面导航、元素交互、表单填写、文件上传等。该库特别适用于需要复杂 Web 交互的 AI 智能体场景,如自动化测试、数据抓取、任务自动化等。
核心特性:
- 基于 LLM 的智能决策,无需手动编写复杂的浏览器操作脚本
- 事件驱动的浏览器管理,通过 Watchdog 系统实现自动化监控和处理
- 完整的 DOM 处理和可访问性树支持,确保智能体能够准确理解页面结构
- 支持多种 LLM 提供商和自定义工具扩展
- 提供云端浏览器服务(Browser Use Cloud),支持隐身浏览器和代理轮换
应用场景:
- AI 智能体的浏览器自动化任务
- 复杂的 Web 表单填写和数据提取
- 自动化测试和端到端测试
- 网页数据抓取和信息收集
- 任务自动化和工作流自动化
核心概念和术语
- Agent(智能体):Browser-Use 的核心编排器,负责接收任务、管理浏览器会话并执行 LLM 驱动的动作循环
- BrowserSession(浏览器会话):管理浏览器生命周期、CDP 连接和多个 Watchdog 服务的协调
- CDP(Chrome DevTools Protocol):Chrome 浏览器提供的调试协议,用于程序化控制浏览器
- Watchdog(看门狗):事件驱动的监控服务,自动处理浏览器事件(如弹窗、下载、崩溃等)
- DomService(DOM 服务):提取和处理 DOM 内容,处理元素高亮和可访问性树生成
- Tools Registry(工具注册表):将 LLM 决策映射到浏览器操作的注册表系统
- EventBus(事件总线):基于
bubus的事件驱动通信机制,协调各个组件 - Structured Output(结构化输出):LLM 返回的结构化动作模型,包含动作类型和参数
- CodeAgent(代码智能体):类似 Jupyter Notebook 的执行环境,允许 LLM 编写 Python 代码控制浏览器
架构设计
Browser-Use 采用事件驱动的分层架构,核心是基于 CDP 的浏览器控制和 LLM 驱动的决策循环。系统将浏览器操作抽象为事件,通过事件总线协调各个组件,实现了高度的模块化和可扩展性。
设计原则
- 事件驱动架构:所有浏览器操作都通过事件系统进行,实现了松耦合的组件设计
- LLM 驱动的决策:智能体通过 LLM 分析页面状态并做出决策,无需手动编写操作脚本
- Watchdog 自动化监控:通过多个 Watchdog 服务自动处理常见浏览器事件,减少智能体负担
- 类型安全:使用 Pydantic 确保数据传递的类型安全,减少运行时错误
- 异步优先:全面采用异步编程模型,支持高并发和高效的资源利用
系统架构图
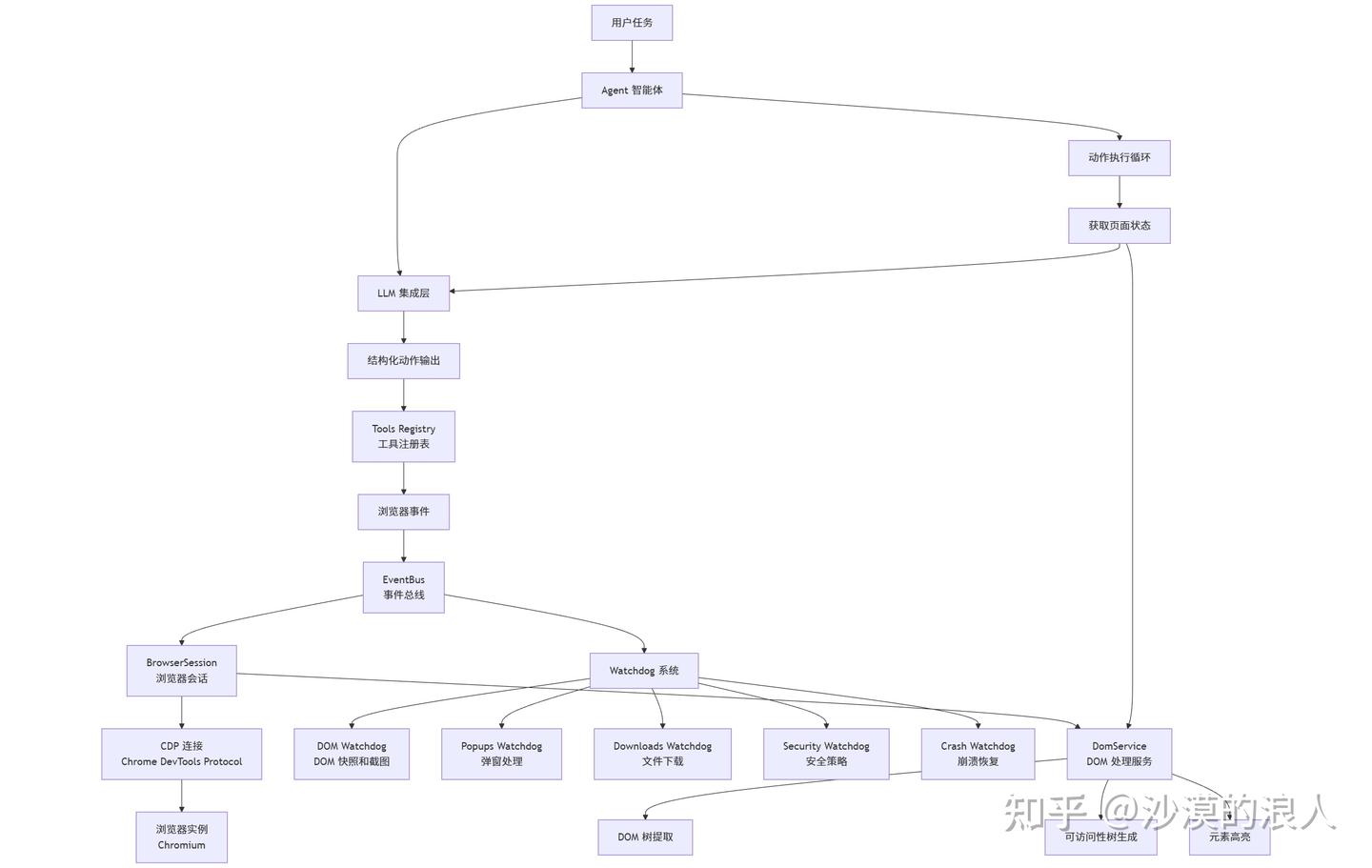
关键设计决策
事件驱动 vs 直接调用:Browser-Use 选择事件驱动架构而非直接 CDP 调用,这使得系统更加模块化,各个组件可以独立开发和测试,同时支持异步处理和并发操作。
Watchdog 系统设计:通过多个专门的 Watchdog 服务处理常见浏览器事件,将智能体从繁琐的事件处理中解放出来,专注于核心任务逻辑。
DOM 处理策略:采用增强的 DOM 快照和可访问性树,结合视觉截图,为 LLM 提供丰富的页面上下文信息,提高决策准确性。
核心流程
Browser-Use 的核心流程是一个迭代的动作执行循环,智能体通过分析页面状态、调用 LLM 获取动作决策、执行动作并观察结果,不断推进任务完成。
流程输入和输出
输入:
- 用户任务描述(自然语言)
- 浏览器配置(配置文件、代理设置等)
- LLM 配置(模型选择、API 密钥等)
输出:
- 任务执行历史(包含所有步骤和结果)
- 提取的内容(如果任务涉及数据提取)
- 浏览器状态快照(截图、DOM 树等)
核心流程图
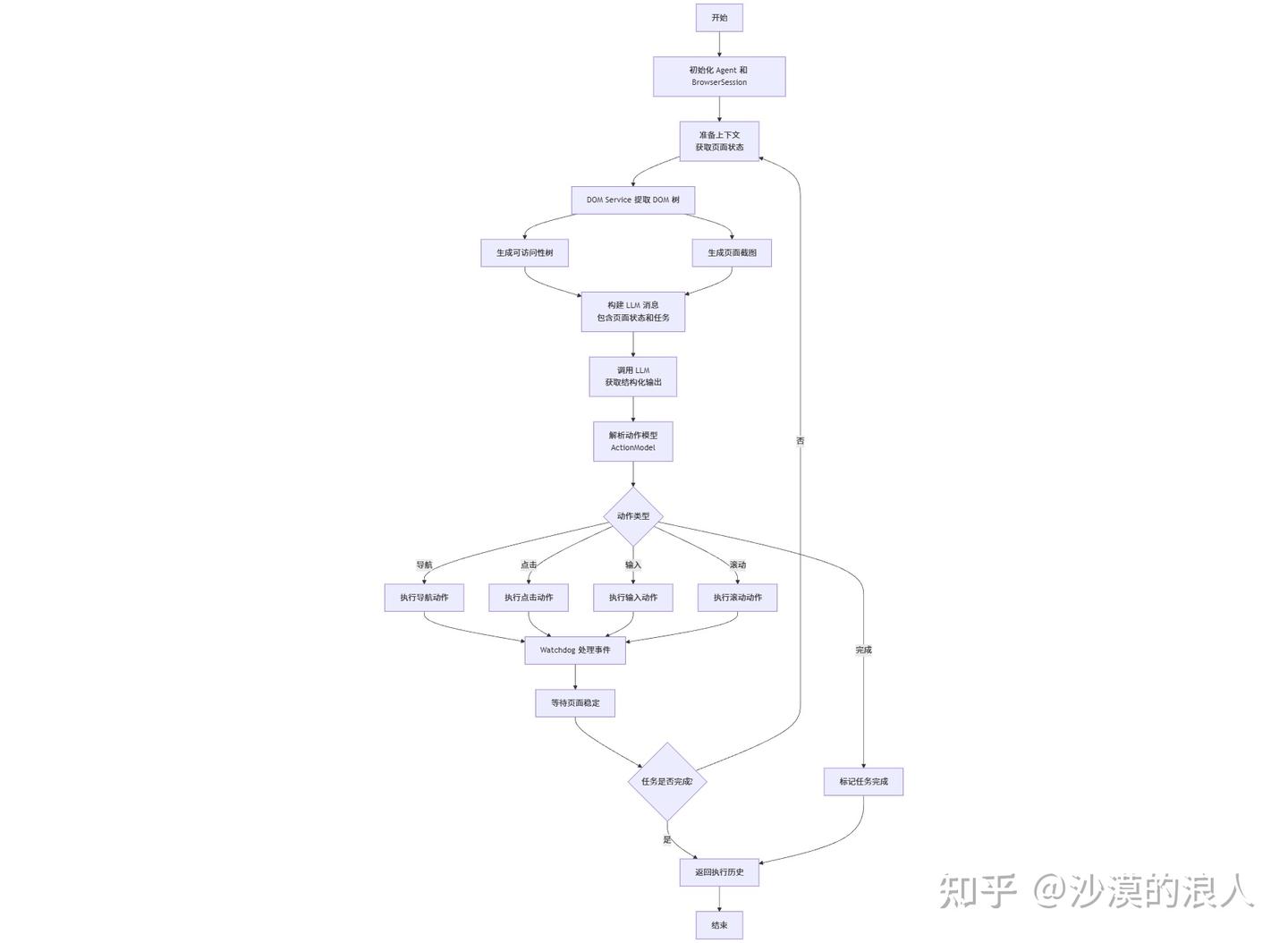
关键步骤说明
- 上下文准备阶段:
- Agent 调用 DomService 获取当前页面的 DOM 树和可访问性树
- 生成页面截图,为 LLM 提供视觉上下文
- 提取页面文本内容和交互元素信息
- LLM 决策阶段:
- 将页面状态、任务描述和历史动作构建为 LLM 消息
- 调用 LLM 获取结构化输出(ActionModel)
- LLM 分析页面状态,决定下一步动作(导航、点击、输入等)
- 动作执行阶段:
- Tools Registry 将结构化动作转换为浏览器事件
- BrowserSession 通过 CDP 执行浏览器操作
- Watchdog 系统监控并处理相关事件(弹窗、下载等)
- 状态观察阶段:
- 等待页面稳定(DOM 变化、网络请求完成等)
- 观察动作执行结果
- 更新执行历史
- 迭代循环:
- 如果任务未完成,返回步骤 1 继续执行
- 如果任务完成或达到最大步数,结束循环
决策点分析
- 动作类型决策点:LLM 根据页面状态和任务目标,决定执行哪种类型的动作
- 元素选择决策点:LLM 需要从多个可交互元素中选择最合适的元素进行操作
- 任务完成决策点:LLM 判断任务是否已完成,决定是否调用
done()动作 - 错误恢复决策点:当动作执行失败时,系统需要决定是重试、跳过还是终止任务
核心组件
Agent 智能体(Agent Service)
职责:作为系统的核心编排器,负责接收任务、管理浏览器会话、执行 LLM 驱动的动作循环,并维护执行历史。
工作原理:Agent 通过 step() 方法执行单步任务,每个步骤包括:准备上下文(获取页面状态)、调用 LLM 获取动作决策、执行动作、后处理。Agent 维护一个动作历史列表,记录所有执行的动作和结果,用于 LLM 的上下文理解。
关键实现:
class Agent(Generic[Context, AgentStructuredOutput]):
@time_execution_sync('--init')
def __init__(
self,
task: str,
llm: BaseChatModel | None = None,
# Optional parameters
browser_profile: BrowserProfile | None = None,
browser_session: BrowserSession | None = None,
browser: Browser | None = None, # Alias for browser_session
tools: Tools[Context] | None = None,
controller: Tools[Context] | None = None, # Alias for tools
# Initial agent run parameters
sensitive_data: dict[str, str | dict[str, str]] | None = None,
initial_actions: list[dict[str, dict[str, Any]]] | None = None,
# Cloud Callbacks
register_new_step_callback: (
Callable[['BrowserStateSummary', 'AgentOutput', int], None] # Sync callback
| Callable[['BrowserStateSummary', 'AgentOutput', int], Awaitable[None]] # Async callback
| None
) = None,
register_done_callback: (
Callable[['AgentHistoryList'], Awaitable[None]] # Async Callback
| Callable[['AgentHistoryList'], None] # Sync Callback
| None
) = None,
register_external_agent_status_raise_error_callback: Callable[[], Awaitable[bool]] | None = None,Agent 的核心执行循环:
@observe(name='agent.step', ignore_output=True, ignore_input=True)
@time_execution_async('--step')
async def step(self, step_info: AgentStepInfo | None = None) -> None:
"""Execute one step of the task"""
# Initialize timing first, before any exceptions can occur
self.step_start_time = time.time()
browser_state_summary = None
try:
# Phase 1: Prepare context and timing
browser_state_summary = await self._prepare_context(step_info)
# Phase 2: Get model output and execute actions
await self._get_next_action(browser_state_summary)
await self._execute_actions()
# Phase 3: Post-processing
await self._post_process()
except Exception as e:
# Handle ALL exceptions in one place
await self._handle_step_error(e)
finally:
await self._finalize(browser_state_summary)- 支持敏感数据注入,自动替换敏感信息避免泄露
- 实现执行历史管理,记录所有动作和结果
- 支持自定义工具扩展,通过 Tools Registry 注册新动作
- 提供回调机制,支持云端集成和外部监控
与其他组件的关系:Agent 协调 BrowserSession、DomService、Tools Registry 和 LLM 集成,是整个系统的核心控制器。
BrowserSession 浏览器会话
职责:管理浏览器生命周期、CDP 连接、事件总线和多个 Watchdog 服务的协调。
工作原理:BrowserSession 使用 cdp-use 库管理 CDP 客户端连接,通过事件总线(EventBus)协调各个 Watchdog 服务。它提供高级浏览器操作接口(导航、点击、输入等),同时支持直接 CDP 调用。BrowserSession 管理多个标签页和 CDP 会话,确保资源正确清理。
关键实现:
class BrowserSession(BaseModel):
"""Event-driven browser session with backwards compatibility.
This class provides a 2-layer architecture:
- High-level event handling for agents/tools
- Direct CDP/Playwright calls for browser operations- 事件驱动的浏览器管理,所有操作通过事件系统进行
- 支持本地浏览器和云端浏览器(Browser Use Cloud)
- 实现 CDP 会话缓存,提高性能
- 提供浏览器状态快照功能,包括截图和 DOM 树
与其他组件的关系:BrowserSession 是浏览器操作的基础设施,为 Agent、Tools 和 DomService 提供浏览器访问能力。
DomService DOM 处理服务
职责:提取和处理 DOM 内容,处理元素高亮和可访问性树生成。
工作原理:DomService 通过 CDP 获取 DOM 树和可访问性树,进行增强处理(计算样式、布局信息等),生成序列化的 DOM 状态供 LLM 使用。它支持 iframe 处理、跨域 iframe 限制、绘制顺序过滤等功能,确保 LLM 能够准确理解页面结构。
关键实现:
class DomService:
"""
Service for getting the DOM tree and other DOM-related information.
Either browser or page must be provided.
TODO: currently we start a new websocket connection PER STEP, we should definitely keep this persistent
"""
logger: logging.Logger
def __init__(
self,
browser_session: 'BrowserSession',
logger: logging.Logger | None = None,
cross_origin_iframes: bool = False,
paint_order_filtering: bool = True,
max_iframes: int = 100,
max_iframe_depth: int = 5,
):
self.browser_session = browser_session
self.logger = logger or browser_session.logger
self.cross_origin_iframes = cross_origin_iframes
self.paint_order_filtering = paint_order_filtering
self.max_iframes = max_iframes
self.max_iframe_depth = max_iframe_depth- 支持增强的 DOM 快照,包含计算样式和布局信息
- 生成可访问性树,提高 LLM 对页面结构的理解
- 实现元素高亮功能,可视化 LLM 选择的元素
- 支持 iframe 嵌套和跨域限制
与其他组件的关系:DomService 为 Agent 提供页面状态信息,是 LLM 决策的重要数据源。
Tools Registry 工具注册表
职责:将 LLM 的结构化动作决策映射到浏览器操作,管理所有可用的浏览器动作。
工作原理:Tools Registry 使用装饰器模式注册动作函数,每个动作函数接收动作参数和 BrowserSession,执行相应的浏览器操作并返回结果。Registry 维护一个动作模型到执行函数的映射,支持动作验证和错误处理。
关键实现:
class Tools(Generic[Context]):
def __init__(
self,
exclude_actions: list[str] | None = None,
output_model: type[T] | None = None,
display_files_in_done_text: bool = True,
):
self.registry = Registry[Context](exclude_actions if exclude_actions is not None else [])
self.display_files_in_done_text = display_files_in_done_text
"""Register all default browser actions"""
self._register_done_action(output_model)
# Basic Navigation Actions
@self.registry.action(
'',
param_model=SearchAction,
)
async def search(params: SearchAction, browser_session: BrowserSession):
import urllib.parse
# Encode query for URL safety
encoded_query = urllib.parse.quote_plus(params.query)
# Build search URL based on search engine
search_engines = {
'duckduckgo': f'https://duckduckgo.com/?q={encoded_query}',
'google': f'https://www.google.com/search?q={encoded_query}&udm=14',
'bing': f'https://www.bing.com/search?q={encoded_query}',
}
if params.engine.lower() not in search_engines:
return ActionResult(error=f'Unsupported search engine: {params.engine}. Options: duckduckgo, google, bing')
search_url = search_engines[params.engine.lower()]
# Simple tab logic: use current tab by default
use_new_tab = False
# Dispatch navigation event
try:
event = browser_session.event_bus.dispatch(
NavigateToUrlEvent(
url=search_url,
new_tab=use_new_tab,- 支持自定义动作注册,用户可以扩展工具能力
- 实现动作参数验证,确保类型安全
- 提供错误处理和结果格式化
- 支持敏感数据检测和替换
与其他组件的关系:Tools Registry 连接 LLM 决策和浏览器操作,是动作执行的关键桥梁。
Watchdog 系统
职责:自动监控和处理浏览器事件,减少智能体的负担。
工作原理:Watchdog 系统由多个专门的 Watchdog 服务组成,每个服务监听特定类型的事件并自动处理。例如,PopupsWatchdog 自动处理 JavaScript 弹窗,DownloadsWatchdog 管理文件下载,DOMWatchdog 处理 DOM 快照和截图生成。
主要 Watchdog 类型:
- DOMWatchdog:处理 DOM 快照、截图和元素高亮
- PopupsWatchdog:自动处理 JavaScript 对话框和弹窗
- DownloadsWatchdog:管理文件下载和存储
- SecurityWatchdog:强制执行域名限制和安全策略
- CrashWatchdog:监控浏览器崩溃并尝试恢复
- AboutBlankWatchdog:处理空白页重定向
- PermissionsWatchdog:处理权限请求(如地理位置、通知等)
与其他组件的关系:Watchdog 系统通过事件总线与 BrowserSession 集成,自动处理浏览器事件,为 Agent 提供稳定的执行环境。
LLM 集成层
职责:提供统一的 LLM 接口,支持多种 LLM 提供商。
工作原理:LLM 集成层定义了 BaseChatModel 抽象基类,各个提供商实现具体的聊天模型类。支持 OpenAI、Anthropic、Google、Groq、Ollama 等多种提供商,提供统一的接口和消息格式。
支持的 LLM 提供商:
- ChatBrowserUse:Browser-Use 优化的专用模型,针对浏览器自动化任务优化
- ChatOpenAI:OpenAI GPT 系列模型
- ChatAnthropic:Anthropic Claude 系列模型
- ChatGoogle:Google Gemini 系列模型
- ChatGroq:Groq 提供的快速推理模型
- ChatOllama:本地运行的 Ollama 模型
与其他组件的关系:LLM 集成层为 Agent 提供决策能力,是智能化的核心组件。
缺点
- 性能开销:每个步骤都需要调用 LLM,对于简单任务可能效率较低,Token 消耗较大
- 上下文窗口限制:长任务可能导致上下文窗口溢出,需要实现上下文压缩或总结机制
- LLM 决策不确定性:LLM 可能做出错误的决策,需要多次重试或人工干预
- 成本问题:频繁调用 LLM API 可能产生较高的成本,特别是使用高性能模型时
- 浏览器资源消耗:每个 Agent 实例需要独立的浏览器进程,并发执行时资源消耗较大
- CAPTCHA 处理:无法自动处理 CAPTCHA,需要依赖 Browser Use Cloud 的隐身浏览器功能
- 动态内容处理:对于高度动态的 Web 应用(如 SPA),可能需要等待较长时间才能稳定
- 错误恢复机制:当动作执行失败时,错误恢复策略可能不够智能,导致任务失败
- 调试困难:LLM 驱动的决策过程是黑盒的,调试和问题定位较为困难
- 依赖 CDP:完全依赖 Chrome DevTools Protocol,限制了浏览器兼容性
- 学习曲线:需要理解事件驱动架构和 Watchdog 系统,对新手不够友好
- 文档完整性:部分高级功能的文档可能不够完善,需要阅读源代码理解

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)